【机器学习实战】Datawhale夏令营2:深度学习回顾
#DataWhale夏令营 #ai夏令营
文章目录
- 1. 深度学习的定义
- 1.1 深度学习&图神经网络
- 1.2 机器学习和深度学习的关系
- 2. 深度学习的训练流程
- 2.1 数学基础
- 2.1.1 梯度下降法
- 基本原理
- 数学表达
- 步骤
- 学习率 α
- 梯度下降的变体
- 2.1.2 神经网络与矩阵
- 网络结构表示
- 前向传播
- 激活函数
- 反向传播
- 批处理
- 卷积操作
- 参数更新
- 优化算法
- 正则化
- 初始化
- 2.2 激活函数
- Sigmoid 函数:
- Tanh 函数:
- ReLU 函数 (Rectified Linear Unit):
- Leaky ReLU 函数:
- ELU 函数 (Exponential Linear Unit):
- Softmax 函数:
- Swish 函数:
- GELU 函数:
- 2.3 权重与误差
- 计算误差
- 计算梯度:
- 更新权重:
- 实例说明
- 激活函数对误差和权重计算的影响
- 2.4 输入层、隐含层和输出层
- 2.4.1. 输入层 (Input Layer)
- 2.4.2 隐含层 (Hidden Layer)
- 2.4.3 输出层 (Output Layer)
- 3. 图神经网络结构
- 3.1 AlexNet
- 3.2 ResNet
- 3.2.1 核心概念:残差学习
- 3.2.2 残差块(Residual Block)
- 3.2.3 网络架构
- 3.2.4 主要特点
- 3.2.5 ResNet的变体
- 3.3 EfficientNet
- 3.3.1 核心思想:复合缩放(Compound Scaling)
- 3.3.2 基础网络:EfficientNet-B0
- 3.3.3 缩放方法
- 3.3.4 EfficientNet 系列
- 3.3.5 主要特点
- 4. 迁移学习
- 5. 改进思路
- 5.1 帧提取
- 5.2 音频fake
- 5.3 特征提取
1. 深度学习的定义
1.1 深度学习&图神经网络
首先,我们需要明确深度学习的定义。深度学习是构建多层的神经网络,从而构建起一个大的模型,通过这个模型去学习复杂的特征表示。简单地说,这些层包含输入层、隐含层和输出层(特别像是LSTM),然而像是DCN这样的网络,实际的深度学习模型的层设可能更富创造性。
我认为深度学习可以概括为这样的一个流程:输入就像是神经信号(外部刺激),通过中间的神经元和通路进行加工和处理,最终化为模型(人体)的反应。深度学习正是借鉴了人体神经元处理信号的过程。
在数学意义上,深度学习的全流程至少涉及了所有的大一公共数学课。您需要通过处理权重矩阵和数据向量(线性代数)、梯度下降法计算(微积分)、不确定性计算(概率论)。通常它是这样一个流程:通过确定阈值,将输入加权求和,计算激活函数值,送入多层神经网络;前向传播,多层神经网络继续加权(和偏置)计算;计算损失函数,在输出层,比如通过均方误差(MSE)、交叉熵损失来计算;反向传播,在输出层,基于链式法则计算梯度,送还多层神经网络来调整权重(类似于控制系统的反馈),以便获得更好的结果;对优化器(优化算法)进行改进,比如Baseline用到的Adam优化器;进行正则化,防止过拟合;批处理和迭代,每一批被称为一个epoch;进行超参数调优,比如贝叶斯超参数优化。当然,实际的深度学习模型改进是一个更有趣的过程,也涉及更多的数学过程。
1.2 机器学习和深度学习的关系
机器学习包含深度学习,深度学习是机器学习的一个子方向。它涉及使用神经网络,特别是深度神经网络(即具有多层隐藏层的神经网络)来进行学习和预测。这个子方向处理大量数据和复杂模式识别方面表现出色,尤其在图像识别、自然语言处理和语音识别等领域取得了显著的成果。
2. 深度学习的训练流程
2.1 数学基础
2.1.1 梯度下降法
基本原理
梯度下降法的核心思想是沿着函数的梯度(即函数在各点的方向导数)的反方向,以求找到函数的局部极小值。在机器学习中,我们通常用它来最小化损失函数。

数学表达
假设我们有一个目标函数 J(θ),其中 θ 是参数向量。梯度下降的更新规则可以表示为:
θ = θ - α∇J(θ)
其中 α 是学习率,∇J(θ) 是 J(θ) 的梯度。
步骤
a) 初始化参数 θ
b) 计算当前参数下的梯度 ∇J(θ)
c) 更新参数: θ = θ - α∇J(θ)
d) 重复步骤 b 和 c,直到收敛或达到预定的迭代次数
学习率 α
学习率决定了每次参数更新的步长。太大可能会导致算法发散,太小则会导致收敛速度过慢。选择合适的学习率是一个重要的超参数调整过程。
梯度下降的变体
a) 批量梯度下降(Batch Gradient Descent): 使用所有训练数据来计算梯度。
b) 随机梯度下降(Stochastic Gradient Descent, SGD): 每次只使用一个样本来计算梯度。
c) 小批量梯度下降(Mini-batch Gradient Descent): 每次使用一小批样本来计算梯度,是前两者的折中。
2.1.2 神经网络与矩阵
网络结构表示
每一层神经元的权重可以表示为一个矩阵。
例如,如果第一层有m个神经元,第二层有n个神经元,那么连接它们的权重可以表示为一个 n × m 的矩阵。
前向传播
使用矩阵乘法可以高效地计算每一层的输出。
如果输入是 X,权重矩阵是 W,偏置是 b,那么输出 Y 可以表示为:Y = WX + b
激活函数
激活函数通常是按元素操作的,可以直接应用于矩阵的每个元素。
反向传播
误差的反向传播也可以用矩阵运算来表示。
梯度的计算涉及到矩阵的转置和矩阵乘法。
批处理
通过将多个输入样本组合成一个矩阵,可以同时处理一批数据。
这大大提高了计算效率,尤其是在GPU上。
卷积操作
在卷积神经网络中,卷积操作可以表示为特殊的矩阵乘法。
参数更新
权重和偏置的更新可以表示为矩阵加法和减法。
优化算法
许多优化算法,如Adam、RMSprop等,都涉及到矩阵操作。
正则化
L1、L2正则化等可以表示为对权重矩阵的操作。
初始化
权重初始化方法(如Xavier、He初始化)通常涉及到对矩阵的操作。
2.2 激活函数
Sigmoid 函数:
公式:f(x) = 1 / (1 + e^(-x))
特点:将输入压缩到 (0, 1) 的范围内,适用于二分类问题,但在深度神经网络中容易出现梯度消失问题。
Tanh 函数:
公式:f(x) = (e^(2x) - 1) / (e^(2x) + 1)
特点:将输入压缩到 (-1, 1) 的范围内,解决了 Sigmoid 函数的零中心问题,但仍存在梯度消失问题。
ReLU 函数 (Rectified Linear Unit):
公式:f(x) = max(0, x)
特点:简单有效,在正区间上是线性函数,在负区间上输出为0,解决了梯度消失问题。但存在神经元死亡问题(输出为0时,梯度为0,权重无法更新)。
Leaky ReLU 函数:
公式:f(x) = max(ax, x),其中 a 是小于1的常数。
特点:解决了 ReLU 函数的神经元死亡问题,允许小的负值通过,但需要额外调整 a 的值。
ELU 函数 (Exponential Linear Unit):
公式:f(x) = x, x >= 0;f(x) = α(e^x - 1), x < 0,其中 α 是大于零的常数。
特点:引入了指数函数,允许负值,解决了 ReLU 的一些问题,但计算量稍大。
Softmax 函数:
公式:f(x_i) = e^(x_i) / Σ(e^(x_k)),其中 i 表示输出层的第 i 个神经元,k 表示所有输出神经元。
特点:通常用于多分类问题,将输出转化为概率分布。
Swish 函数:
公式:f(x) = x · sigmoid(x)
特点:由Google提出,表现良好且易计算。
GELU 函数:
公式:f(x) = x · sigmoid(1.702x)
特点:用于深度神经网络,具有更强的拟合性。
2.3 权重与误差
计算误差
神经网络的目标是通过调整权重来最小化误差。网络的预测输出与真实标签之间的差距通过损失函数计算出来。
误差反向传播:
梯度下降算法利用误差反向传播算法来更新权重:
计算梯度:
误差的梯度是指误差相对于网络中每个权重的变化率。反向传播算法通过链式法则计算每层误差对权重的梯度:
∂ L ∂ w i j \frac{\partial L}{\partial w_{ij}} ∂wij∂L
更新权重:
使用梯度下降法来调整权重,以最小化损失函数。权重更新公式为:
w i j ( n e w ) = w i j ( o l d ) − α ∂ L ∂ w i j w_{ij}^{(new)} = w_{ij}^{(old)} - \alpha \frac{\partial L}{\partial w_{ij}} wij(new)=wij(old)−α∂wij∂L
其中, α \alpha α 是学习率。
实例说明
假设我们有一个简单的前馈神经网络:
前向传播:
输入: x x x
权重: w w w
输出: y ^ = f ( w ⋅ x + b ) \hat{y} = f(w \cdot x + b) y^=f(w⋅x+b)
计算误差: L ( y , y ^ ) L(y, \hat{y}) L(y,y^)
反向传播:
计算误差对输出的梯度: ∂ L ∂ y ^ \frac{\partial L}{\partial \hat{y}} ∂y^∂L
计算输出对加权输入的梯度: ∂ y ^ ∂ z \frac{\partial \hat{y}}{\partial z} ∂z∂y^
计算误差对权重的梯度: ∂ L ∂ w = ∂ L ∂ y ^ ⋅ ∂ y ^ ∂ z ⋅ ∂ z ∂ w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial w} ∂w∂L=∂y^∂L⋅∂z∂y^⋅∂w∂z
更新权重: w n e w = w o l d − α ⋅ ∂ L ∂ w w_{new} = w_{old} - \alpha \cdot \frac{\partial L}{\partial w} wnew=wold−α⋅∂w∂L
激活函数对误差和权重计算的影响
不同的激活函数会对误差的计算和权重的更新产生不同的影响:
Sigmoid 和 Tanh: 容易导致梯度消失问题,因为它们的导数在极端值时趋近于零。
ReLU: 提高了梯度的稳定性,但可能会出现神经元死亡的问题。
Leaky ReLU 和 ELU: 解决了 ReLU 的问题,改进了负值的传递。
Softmax: 在分类问题中将输出转换为概率分布,用于多分类任务的损失计算。
2.4 输入层、隐含层和输出层
输入层、隐含层和输出层共同构成了神经网络的基本结构。通过这些层的组合和层与层之间的连接(通过权重和偏置),神经网络能够学习复杂的数据模式并进行有效的预测和分类。每一层的设计和激活函数的选择都会对网络的性能和训练过程产生重要影响。
2.4.1. 输入层 (Input Layer)
定义和功能:
输入层是神经网络的第一层,负责接收原始数据或特征作为输入。
每个输入层节点对应输入数据的一个特征或维度。
输入层的节点数通常由输入数据的特征数确定。
数学表示:
如果输入数据是一个向量 ( x ),则输入层可以表示为 ( x = [x_1, x_2, …, x_n] ),其中 ( n ) 是特征数量。
2.4.2 隐含层 (Hidden Layer)
定义和功能:
隐含层位于输入层和输出层之间,负责处理输入数据并提取其高级特征。
每个隐含层由多个神经元(节点)组成,每个神经元接收来自上一层的输入,并应用激活函数产生输出。
数学表示:
对于第 ( l ) 层的第 ( j ) 个神经元,其输入可以表示为:
[ z_j^{(l)} = \sum_{i} w_{ij}^{(l)} x_i^{(l-1)} + b_j^{(l)} ]
其中 ( w_{ij}^{(l)} ) 是从第 ( l-1 ) 层的第 ( i ) 个神经元到第 ( l ) 层的第 ( j ) 个神经元的权重,( b_j^{(l)} ) 是第 ( l ) 层的第 ( j ) 个神经元的偏置。
2.4.3 输出层 (Output Layer)
定义和功能:
输出层是神经网络的最后一层,负责生成最终的输出。
输出层的节点数通常由任务的要求确定,例如分类任务的类别数量或回归任务的输出维度。
数学表示:
输出层的每个节点对应于神经网络的一个输出值。
在分类问题中,输出层通常会经过 softmax 函数以生成类别概率分布。
在回归问题中,输出层可以直接输出预测的连续值。
3. 图神经网络结构

3.1 AlexNet

首先,AlexNet是一个卷积神经网络架构(CNN)。
它包含8个层:5个卷积层和3个全连接层。
使用ReLU(Rectified Linear Unit)激活函数。
采用重叠池化(Overlapping Pooling)。
使用数据增强和Dropout技术来减少过拟合。
它的意义在于首次成功使用GPU进行网络训练,大大加快了训练速度。并引入了Local Response Normalization(LRN)层。
3.2 ResNet
没错,这就是辣个男人的作品,残差网络。
残差网络最重要的突破在于它克服了梯度消失和梯度爆炸问题,这对于使用梯度下降法的传统神经网络是一个非常重要的改进。
3.2.1 核心概念:残差学习
残差学习的核心思想是学习残差函数F(x),而不是直接学习所需的底层映射H(x)。具体来说:
传统方法:直接拟合H(x)
ResNet方法:拟合F(x) = H(x) - x,然后通过F(x) + x 得到H(x)
这种方法使得网络可以更容易学习恒等映射,从而使得非常深的网络也能够有效训练。
3.2.2 残差块(Residual Block)
ResNet 的基本构建块是残差块,其结构如下:
输入 x
经过几层卷积操作(通常是两到三层)
将输出与输入 x 相加(称为跳跃连接或短路连接)
经过 ReLU 激活函数
数学表示:y = F(x, {Wi}) + x
3.2.3 网络架构
ResNet 有多个版本,最常见的有 ResNet-18、ResNet-34、ResNet-50、ResNet-101 和 ResNet-152。以 ResNet-50 为例:
初始卷积层和池化层
4个阶段的残差块堆叠,每个阶段包含多个残差块
全局平均池化
全连接层
Softmax 输出层
3.2.4 主要特点
深度:ResNet 可以训练非常深的网络(如 152 层),而不会出现性能下降。
批量归一化(Batch Normalization):在每个卷积层后使用批量归一化,有助于稳定训练过程。
瓶颈结构:在更深的版本中(如 ResNet-50 及以上),使用了 1x1 卷积的瓶颈结构来减少计算量。
全局平均池化:替代了传统的多层全连接层,减少了参数数量。
参数效率:尽管网络很深,但由于设计巧妙,参数数量并不会过度增加。
3.2.5 ResNet的变体
ResNet 之后出现了许多变体,如:
Wide ResNet:增加了网络的宽度
ResNeXt:引入了分组卷积
DenseNet:在残差连接的基础上进一步增加了密集连接
3.3 EfficientNet
EfficientNet 是由 Google 研究团队在 2019 年提出的一系列卷积神经网络模型,旨在通过平衡网络的宽度、深度和分辨率来提高模型效率。EfficientNet 在保持较低计算成本和参数量的同时,实现了优秀的性能。
3.3.1 核心思想:复合缩放(Compound Scaling)
EfficientNet 的主要创新在于提出了复合缩放方法,同时按照一定比例缩放网络的宽度、深度和分辨率。
网络宽度(Width):增加通道数
网络深度(Depth):增加层数
图像分辨率(Resolution):增加输入图像的尺寸
3.3.2 基础网络:EfficientNet-B0
EfficientNet-B0 是该系列的基础网络,主要由移动倒置瓶颈结构(Mobile Inverted Bottleneck ConvBlock,MBConv)组成,这是从 MobileNetV2 借鉴的结构。
3.3.3 缩放方法
假设总计算量增加 N 倍,EfficientNet 使用如下缩放系数:
深度:d = α^φ
宽度:w = β^φ
分辨率:r = γ^φ
其中 α, β, γ 是通过小网格搜索确定的常数,φ 是用户指定的系数,控制模型大小。
3.3.4 EfficientNet 系列
基于 EfficientNet-B0 和复合缩放方法,研究者提出了 EfficientNet-B1 到 EfficientNet-B7 的一系列模型,每个后续模型都比前一个更大、更强大。
3.3.5 主要特点
高效性:在相同的计算复杂度和参数量下,EfficientNet 系列模型通常能够达到更高的准确率。
可扩展性:复合缩放方法使得模型可以根据可用资源灵活调整大小。
移动友好:基础结构 MBConv 设计轻量,适合在移动设备上部署。
自动搜索:基础网络 EfficientNet-B0 是通过神经架构搜索(NAS)得到的。
注意力机制:使用 Squeeze-and-Excitation(SE)块增强特征表示。
4. 迁移学习
迁移学习是一种机器学习技术,它将已在一个任务上学到的知识(如模型参数、特征表示等)应用到另一个相关任务上。
通常使用在大规模数据集上预训练的模型作为起点,例如在ImageNet数据集上预训练的卷积神经网络(CNN)。
在预训练模型的基础上,使用少量标记数据对模型进行微调,以适应新任务。

一般我们使用强大的ImageNet来进行数据标记。ImageNet 包含超过1400万张注释过的图像,这些图像分布在超过2.2万个类别中。它的规模之大使得它成为深度学习模型训练和评估的理想数据集。ImageNet 数据集中的图像包含了各种场景、物体、背景和遮挡情况,这为算法提供了极大的挑战。这种多样性使得在 ImageNet 上训练的模型能够学习到鲁棒的特征,从而在现实世界应用中表现良好。

微调是我们进行迁移学习的主要手段之一。它允许我们利用预训练模型对特定任务进行优化。
其基本原理是,首先在一个大规模的数据集上预训练一个深度学习模型,捕捉通用的特征表示,然后将这个预训练模型作为起点,在目标任务上进行进一步的训练以提升模型的性能。
微调的过程通常开始于选择一个在大型数据集上预训练的模型,这个预训练模型已经学到了丰富的特征表示,这些特征在广泛的领域内都是通用的。接着,我们将这个预训练模型适配到新的目标任务上。适配过程通常涉及以下步骤:
- 我们会替换模型的输出层,以匹配目标任务的类别数量和类型。例如,如果目标任务是图像分类,而预训练模型原本用于不同的分类任务,我们就需要将模型的最后一层替换成适合新任务类别数的新层。
- 【可做可不做】我们冻结预训练模型中的大部分层,这样可以防止在微调过程中这些层学到的通用特征被破坏。通常情况下,只对模型的最后一部分层进行解冻,这些层负责学习任务特定的特征。
- 使用目标任务的数据集对模型进行训练。在这个过程中,我们会用梯度下降等优化算法更新模型的权重,从而使模型能够更好地适应新的任务。训练时,可能会使用比预训练时更低的学习率,以避免过度拟合目标数据集。
在下面代码中,timm.create_model(‘resnet18’, pretrained=True, num_classes=2)这行代码就是加载了一个预训练的ResNet-18模型,其中pretrained=True表示使用在ImageNet数据集上预训练的权重,num_classes=2表示模型的输出层被修改为有2个类别的输出,以适应二分类任务(例如区分真实和Deepfake图像)。通过model = model.cuda()将模型移动到GPU上进行加速。
import timm
model = timm.create_model('resnet18', pretrained=True, num_classes=2)
model = model.cuda()
5. 改进思路
我们可以对视频进行帧提取,面部识别、相似比较这样的手段。
5.1 帧提取
使用openCV能快速进行帧提取:
import cv2video = cv2.VideoCapture('video.mp4')
success, frame = video.read()
count = 0while success:cv2.imwrite(f"frame{count}.jpg", frame) # 保存帧为JPEG文件success, frame = video.read()count += 1video.release()
或是我们在baseline曾用到的moviePy:
from moviepy.editor import VideoFileClipclip = VideoFileClip("video.mp4")for t in range(int(clip.duration)):clip.save_frame(f"frame{t}.png", t)
5.2 音频fake
对音频做fake工作,会比对整个视频简单的多,当然,我们之前抽帧也是单独对图像fake的思路:

这个就是频谱图:

这个是上次笔记没有见到的梅尔图:

5.3 特征提取
- chroma_stft
- rms
- spectral_centroid
- spectral_bandwidth
- rolloff
- zero_crossing_rate
- mfcc
相关文章:
【机器学习实战】Datawhale夏令营2:深度学习回顾
#DataWhale夏令营 #ai夏令营 文章目录 1. 深度学习的定义1.1 深度学习&图神经网络1.2 机器学习和深度学习的关系 2. 深度学习的训练流程2.1 数学基础2.1.1 梯度下降法基本原理数学表达步骤学习率 α梯度下降的变体 2.1.2 神经网络与矩阵网络结构表示前向传播激活函数…...

开发扫地机器人系统时无法兼容手机解决方案
在开发扫地机器人系统时,遇到无法兼容手机的问题,可以从以下几个方面寻求解决方案: 一、了解兼容性问题根源 ① 操作系统差异:不同手机可能运行不同的操作系统(如iOS、Android),且即使是同一操…...

Elasticsearch 角色和权限管理
在大数据和云计算日益普及的今天,Elasticsearch 作为一款强大的开源搜索引擎和数据分析引擎,被广泛应用于日志分析、全文搜索、实时监控等领域。随着业务规模的扩大和数据敏感性的增加,对 Elasticsearch 的访问控制和权限管理也变得越来越重要…...

华为HCIP Datacom H12-821 卷42
42.填空题 如图所示,MSTP网络中SW1为总根,请将以下交换机与IST域根和主桥配对。 参考答案:主桥1468 既是IST域根又是主桥468 既不是又不是就是25 解析: 主桥1468 既是IST域根又是主桥468 既不是又不是就是25 43.填空题 网络有…...

【精品资料】物业行业BI大数据解决方案(43页PPT)
引言:物业行业BI(Business Intelligence,商业智能)大数据解决方案是专为物业管理公司设计的一套综合性数据分析与决策支持系统。该解决方案旨在通过集成、处理、分析及可视化海量数据,帮助物业企业提升运营效率、优化资…...
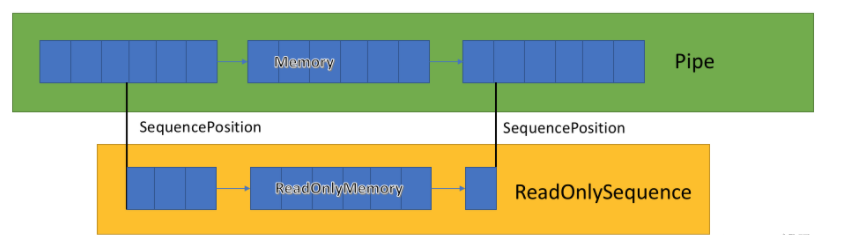
推荐一款处理TCP数据的架构--EasyTcp4Net
EasyTcp4Net是一个基于c# Pipe,ReadonlySequence的高性能Tcp通信库,旨在提供稳定,高效,可靠的tcp通讯服务。 基础的消息通讯 重试机制 超时机制 SSL加密通信支持 KeepAlive 流量背压控制 粘包和断包处理 (支持固定头处理,固定长度处理,固定字符处理) 日志支持Pipe &…...

2、电脑各部件品牌介绍 - 计算机硬件品牌系列文章
笔者是一个电脑IT达人,对于电脑硬件挺感兴趣,今天有必要讲讲关于电脑各部件的品牌问题。关于电脑硬件介绍,见博文版块:计算机硬件系列 。下面对电脑的各部件品牌等进行介绍,便于大家选购电脑的时候做参考。 1、 CPU&am…...

Git【撤销远程提交记录】
在实际开发中,你是否遇到过错误的提交了代码,想要删掉本次提交记录的情况,你可以按照如下方法实现。 1、使用 git revert 如果你想要保留历史记录,并且对远程仓库其他使用者的影响最小,你可以使用 git revert 命令。这…...

java基础学习:序列化之 - Fast serialization
在Java中,序列化是将对象的状态转换为字节流的过程,以便保存到文件、数据库或通过网络传输。Java标准库提供了java.io.Serializable接口和相应的机制来进行序列化和反序列化。然而,标准的Java序列化机制性能较低,并且生成的字节流…...

Microsoft Build 2024 推出 .NET 9:Tensor<T>、 OpenAI Collaboration和.NET Aspire
在 Microsoft Build 2024 上,.NET 9 4 发布,引入了用于深度学习的 Tensor 类型以及与 OpenAI Collaboration实现GPT4o和Assistants v2等功能。这些最新改进还带来了 .NET Aspire,简化了云原生应用开发。更新涵盖 ASP.NET Core、Blazor 和 .NE…...

【Neural signal processing and analysis zero to hero】- 2
Nonstationarities and effects of the FT course from youtube: 传送地址 why we need extinguish stationary and non-stationary signal, because most of neural signal is non-stationary. Welch’s method for smooth spectral decomposition Full FFT method y…...

好用的AI搜索引擎
1. 360AI 搜索 访问 360AI 搜索: https://www.huntagi.com/sites/1706642948656.html 360AI 搜索介绍: 360AI 搜索,新一代智能答案引擎,值得信赖的智能搜索伙伴,为复杂搜索提供专业支持,解锁更相关、更全面的答案。AI…...
十、Java集合 ★ ✔(模块18-20)【泛型、通配符、List、Set、TreeSet、自然排序和比较器排序、Collections、可变参数、Map】
day05 泛型,数据结构,List,Set 今日目标 泛型使用 数据结构 List Set 1 泛型 1.1 泛型的介绍 ★ 泛型是一种类型参数,专门用来保存类型用的 最早接触泛型是在ArrayList,这个E就是所谓的泛型了。使用ArrayList时,只要给E指定某一个类型…...

阿里云开源 Qwen2-Audio 音频聊天和预训练大型音频语言模型
Qwen2-Audio由阿里巴巴集团Qwen团队开发,它能够接受各种音频信号输入,对语音指令进行音频分析或直接文本回复。与以往复杂的层次标签不同,Qwen2-Audio通过使用自然语言提示简化了预训练过程,并扩大了数据量。 喜好儿网 Qwen2-Au…...

SpringBoot集成MQTT实现交互服务通信
引言 本文是springboot集成mqtt的一个实战案例。 gitee代码库地址:源码地址 一、什么是MQTT MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe&…...

python实现插入排序、快速排序
python实现插入排序、快速排序 算法步骤: Python实现插入排序快速排序算法步骤: Python实现快速排序算法时间复杂度 插入排序是一种简单直观的排序算法。它的基本思想是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫…...
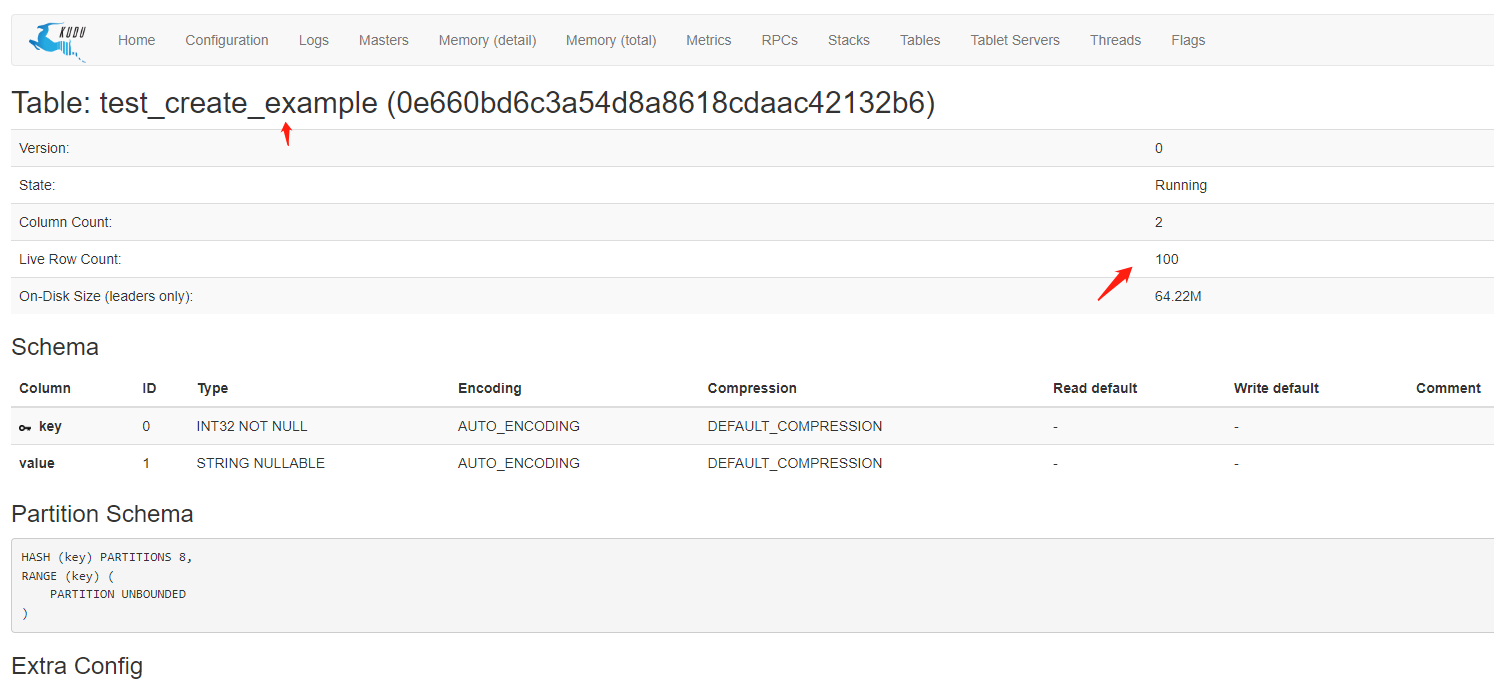
Spring Boot集成kudu快速入门Demo
1.什么是kudu 在Kudu出现前,由于传统存储系统的局限性,对于数据的快速输入和分析还没有一个完美的解决方案,要么以缓慢的数据输入为代价实现快速分析,要么以缓慢的分析为代价实现数据快速输入。随着快速输入和分析场景越来越多&a…...

html超文本传输协议
在今天的Web开发学习中,我掌握了一些HTML和CSS的基础知识,下面我将分享我的学习笔记,帮助大家快速构建一个简单的Web界面。 一、HTML基础标签 1. 网站头 使用<title>标签定义网页的标题。 html <title>我的第一个网页</t…...

利用AI辅助制作ppt封面
如何利用AI辅助制作一个炫酷的PPT封面 标题使用镂空字背景替换为动态视频 标题使用镂空字 1.首先,新建一个空白的ppt页面,插入一张你认为符合主题的图片,占满整个可视页面。 2.其次,插入一个矩形,右键选择设置形状格式…...

【spring boot】初学者项目快速练手
一小时带你从0到1实现一个SpringBoot项目开发_哔哩哔哩_bilibili 一、简介 二、项目结构 三、代码结构 1.生成框架 Spring Initializr 快速生成一个初始的项目代码,会生成一个demo文件 打开intellj idea,导入demo文件 2.目录结构 源码都放在src-ma…...

如何极速获取金融市场数据:5分钟实战指南
如何极速获取金融市场数据:5分钟实战指南 【免费下载链接】qstock qstock由“Python金融量化”公众号开发,试图打造成个人量化投研分析包,目前包括数据获取(data)、可视化(plot)、选股(stock)和量化回测(策…...

5步释放Win11潜能:用Win11Debloat让系统性能提升60%的实战指南
5步释放Win11潜能:用Win11Debloat让系统性能提升60%的实战指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

从线索到成交,陀螺匠帮我打通了客户管理全流程
作为一个从业多年销售,我觉得我在管理客户过程中遇到的这些问题,很多企业多多少少也出现过。比如销售小王跟了一个月的客户,最后发现小李早就联系过了,经常白忙活;好不容易谈成的单子,合同改来改去…...

好写作AI:利用多轮人机交互迭代实现深度降AIGC的方法论
改一遍不够?那就改三遍——但每遍都要改对地方很多同学用AI辅助写论文,流程是这样的:用AI生成一段文字 → 觉得“AI味儿”有点重 → 手动改几个词 → 提交。然后被检测系统打回来。于是困惑:我都改了,怎么还是不行&…...

Ubuntu系统资源监控实战:从命令行到图形化工具全解析
1. 为什么需要监控Ubuntu系统资源? 刚装好的Ubuntu系统跑得飞快,用着用着突然发现电脑变卡了?浏览器开多几个标签页就开始转圈?这种情况我遇到过太多次了。后来才发现,很多时候是因为某个程序偷偷吃掉了大量CPU或内存资…...

RWKV7-1.5B-G1A助力运维:利用Xshell脚本自动化模型部署与监控
RWKV7-1.5B-G1A助力运维:利用Xshell脚本自动化模型部署与监控 1. 引言 "又到周五下午4点,运维团队收到紧急需求——需要在10台服务器上部署最新的RWKV7-1.5B-G1A模型服务。"这样的场景对运维工程师来说再熟悉不过。传统的手动部署方式不仅耗…...
)
别再手动改稿了!用LaTeX的soul包搞定论文批注(删除线/高亮/引用兼容)
LaTeX高效批注指南:用soul包实现学术协作的优雅排版 当导师的红色批注铺满论文初稿,或是合作者发来二十处修改意见时,大多数研究者都会面临一个共同困境——如何在保留原始内容的同时清晰标记修改痕迹?传统的手动添加删除线或高亮…...

NCCL中RoCE与RDMA的深度解析:如何优化分布式训练网络性能
1. 为什么RoCE和RDMA对分布式训练如此重要? 第一次接触分布式训练时,我盯着日志里不断跳动的通信耗时直发愁。8块GPU明明都在满负荷运转,但总训练时间就是比单卡8要长不少。后来用NVIDIA的Nsight工具一分析,发现超过30%的时间都花…...

免费开源Sunshine游戏串流服务器终极指南:打造你的专属云游戏平台
免费开源Sunshine游戏串流服务器终极指南:打造你的专属云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏,却受限于硬件…...

Qwen3.5-2B部署实战:端侧轻量化多模态模型一键镜像教程
Qwen3.5-2B部署实战:端侧轻量化多模态模型一键镜像教程 1. 模型简介 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型专为低功耗、低门槛部署场景设计,特别适合端侧…...