【linux服务器】大语言模型实战教程:LLMS大模型快速部署到个人服务器

引言
说到大语言模型相信大家都不会陌生,大型语言模型(LLMs)是人工智能文本处理的主要类型,也现在最流行的人工智能应用形态。ChatGPT就是是迄今为止最著名的使用LLM的工具,它由OpenAI的GPT模型的特别调整版本提供动力,而今天我们就来带大家体验一下部署大模型的实战。
文章目录
- 引言
- 一、项目选择与系统介绍
- 1.1 项目介绍
- 1.2 Tiny-Llama语言模型
- 1.3 进入系统
- 1.4 进行远程连接
- 二、部署LLMS大模型
- 2.1 拉取代码到环境
- 2.2 自定义算子部署
- 配置protoc 环境
- 算子编译部署
- 修改环境变量
- 编译运行& 依赖安装
- 2.3 推理启动
- 三、 项目体验
一、项目选择与系统介绍
1.1 项目介绍
本来博主是准备来部署一下咱们的,清华大语言模型镜像这个目前也是非常的火啊,吸引了很多人的注意其优秀的性能和GPT3 不相上下,但是由于考虑到,大部分人电脑其实跑大模型是有一点点吃力的,为了让更多人来先迈出部署模型的第一步,于是就决定去 gitee 上找一个小型一点的大模型来实战一下。
1.2 Tiny-Llama语言模型
- 果不其然刚搜索就发现 一个基于香橙派AI Pro 部署的语言大模型项目,这不正好吗?直接开始
- 点进去一看发现这是南京大学开源的一套基于香橙派 AIpro部署的Tiny-Llama语言模型
- (开源地址)
1.3 进入系统
这里我们选择的是openEuler,是香橙派的这块板子内置的系统。但其实他的内核是ubuntu这里可以给大家看一下,所以我们用 ubuntu 服务器来部署应该是没有问题的。

openEuler 是一由中国开源软件基金会主导,以Linux稳定系统内核为基础,华为深度参与,面向服务器、桌面和嵌入式等的一个开源操作系统。
1.4 进行远程连接
-
这里直接插电启动,默认用户名
HwHiAiUser、密码Mind@123当然root密码也是一样的 -
这里我们进来之后可以直接选择链接WiFi 非常便捷
-
当然这里大家在这里也可以选择云服务器远程实战

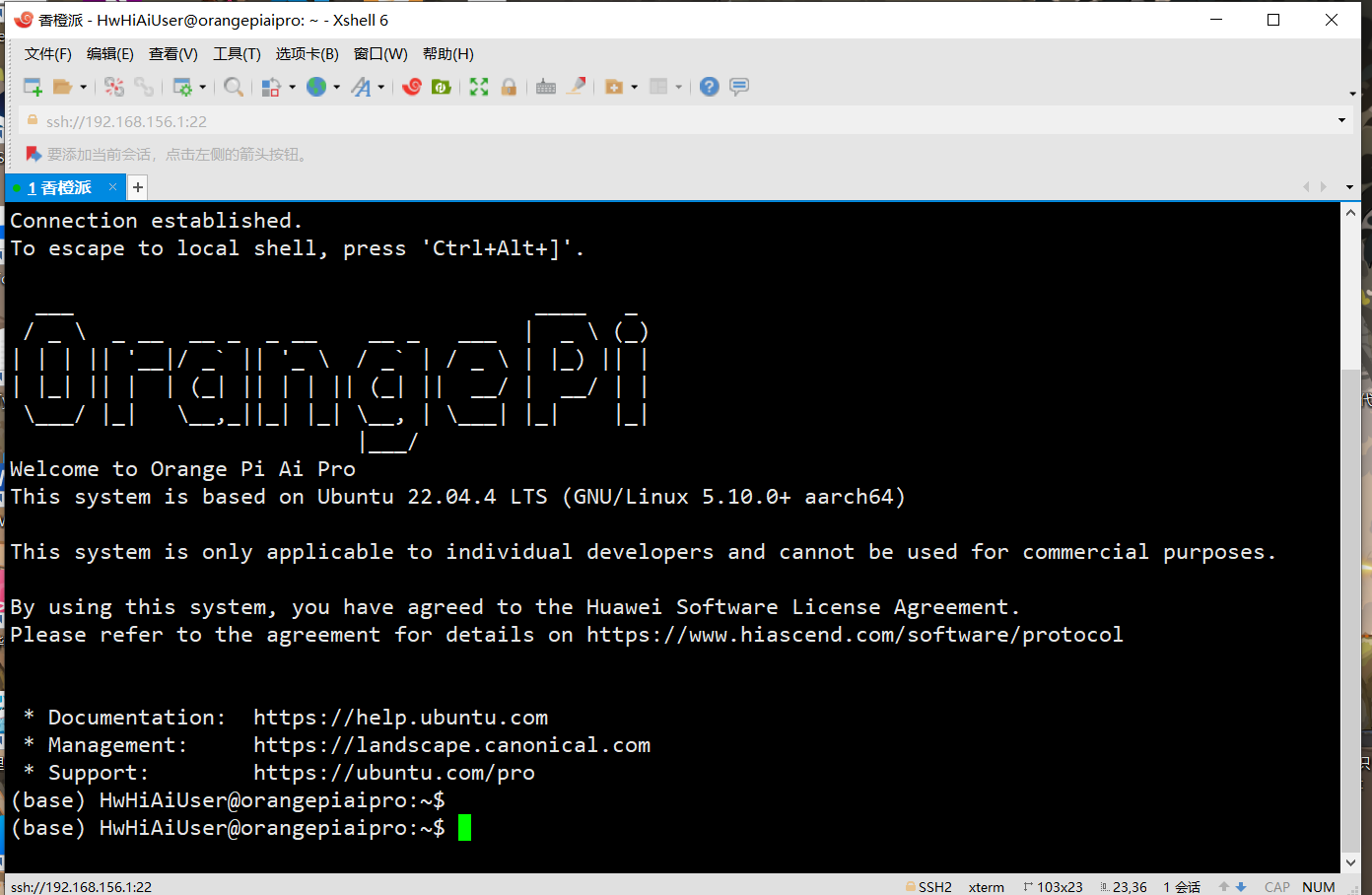
- 然后我们打开命令窗查看IP , 由于系统默认支持ssh 远程连接,所以博主这里就直接采用 Sxhell 进行连接
- 输入ip 选择
HwHiAiUser登录 密码Mind@123
二、部署LLMS大模型
2.1 拉取代码到环境
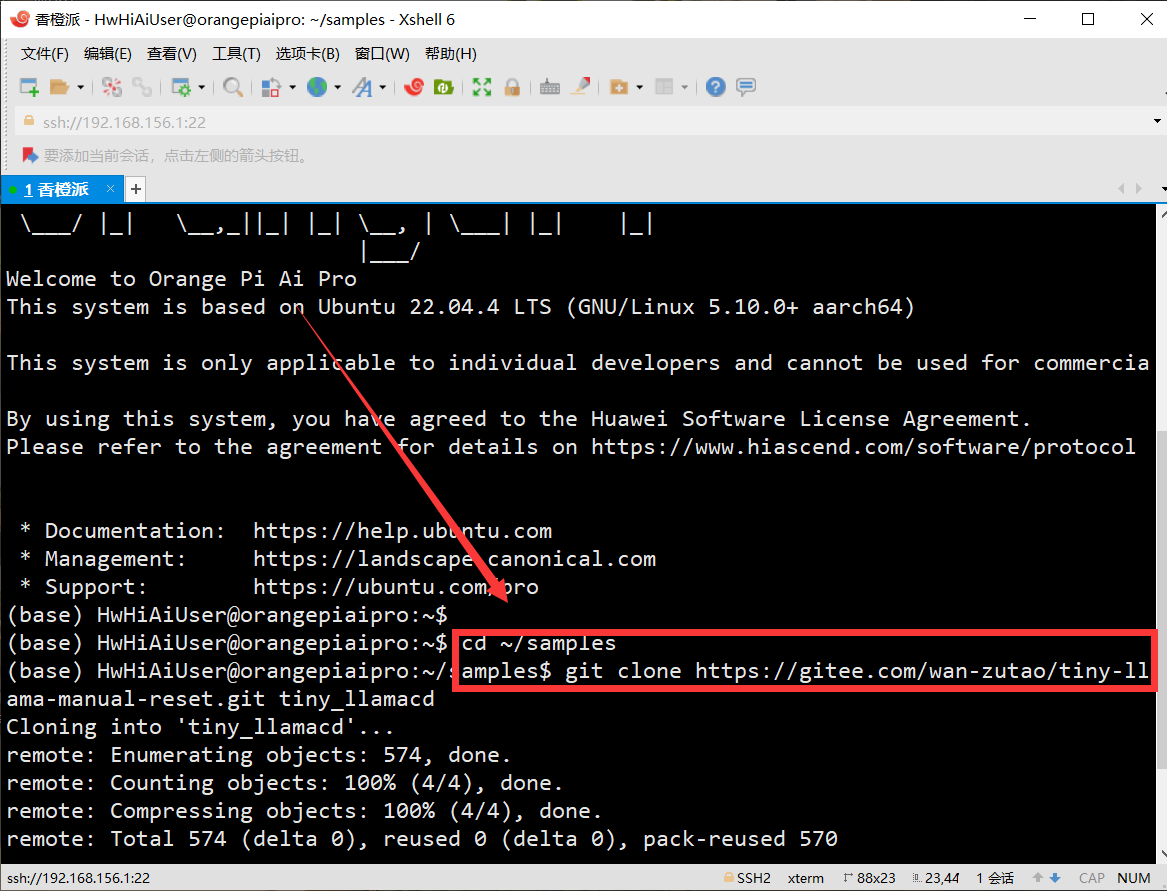
- 先cd进入
cd ~/samples目录 - 之后直接利用git 拉取我们的项目,git 由于系统镜像自带的有就不用我们手动安装了
2.2 自定义算子部署
配置protoc 环境
- 使用wget工具从指定的华为云链接下载 protobuf-all-3.13.0.tar.gz文件
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/protobuf-all-3.13.0.tar.gz --no-check-certificate

- 解压刚刚下载的文件
tar -zxvf protobuf-all-3.13.0.tar.gz
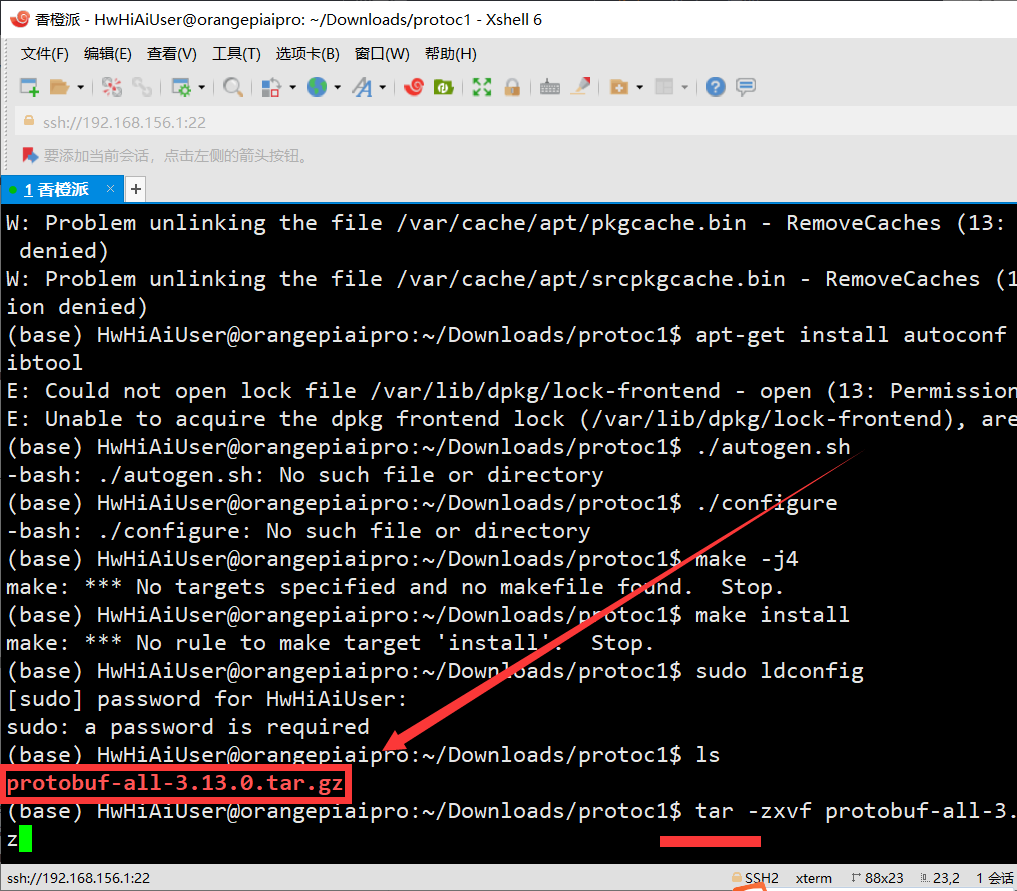
这里解压速度非常快,基本一秒就OK了

- 进入 protobuf-3.13.0 文件夹中
cd protobuf-3.13.0
更新apt包管理器的软件包列表
apt-get update

- 使用apt-get安装必要的构建工具,包括autoconf、automake和libtool,这些工具用于配置和构建开源项目
apt-get install autoconf automake libtool

- 生成配置脚本
configure, 运行./configure生成一个Makefile
./autogen.sh
./configure
- 编译源代码,由于
香橙派 AIpro是4核64位处理器+ AI处理器支持8个线程,我们我们可以大胆的使用4个并行进程进行编译,以加快编译速度。 - 编译这里的时候大家就可以放松放松了大概只需要10几分钟就好了
make -j4
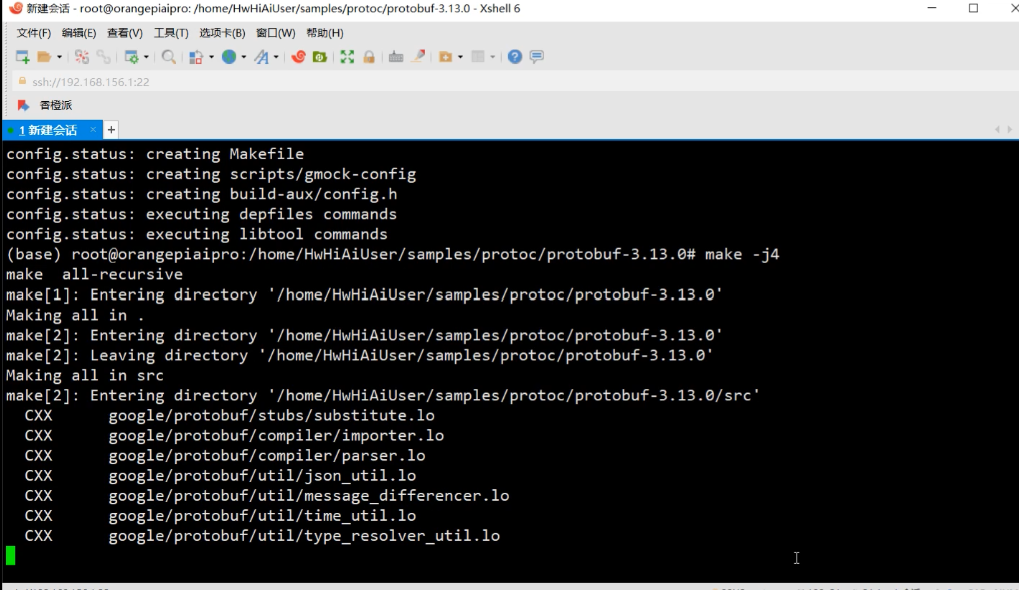
- 将编译后的二进制文件和库文件安装到系统指定的位置
make install

- 更新系统共享库缓存的工具,检查protoc 版本
sudo ldconfigprotoc --version

算子编译部署
- 将当前工作目录切换到
tiny_llama

- 设置了一个环境变量 ASCEND_PATH,并将其值设为
/usr/local/Ascend/ascend-toolkit/latest -
export ASCEND_PATH=/usr/local/Ascend/ascend-toolkit/latest

- 将
custom_op/matmul_integer_plugin.cc文件复制到指定路径
cp custom_op/matmul_integer_plugin.cc $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx/framework/onnx_plugin/
- cd 进入 目标文件夹进行配置
cd $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx

修改环境变量
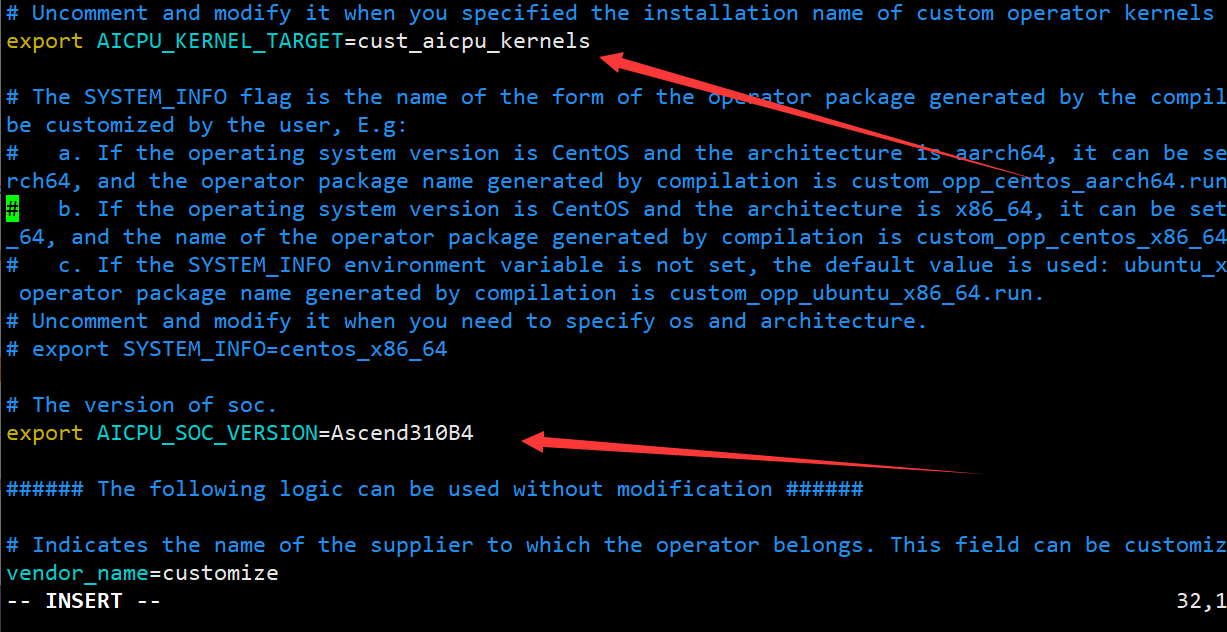
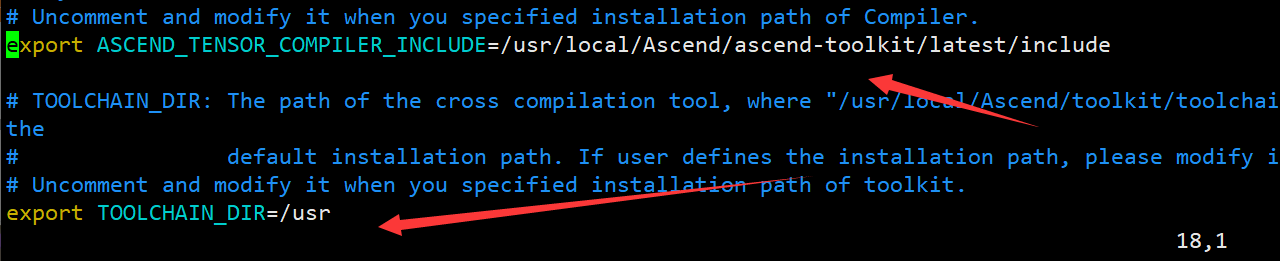
- 打开build.sh,找到下面四个环境变量,解开注释并修改如下:
#命令为 vim build.sh

# 修改内容为
export ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/include
export TOOLCHAIN_DIR=/usr
export AICPU_KERNEL_TARGET=cust_aicpu_kernels
export AICPU_SOC_VERSION=Ascend310B4
编译运行& 依赖安装
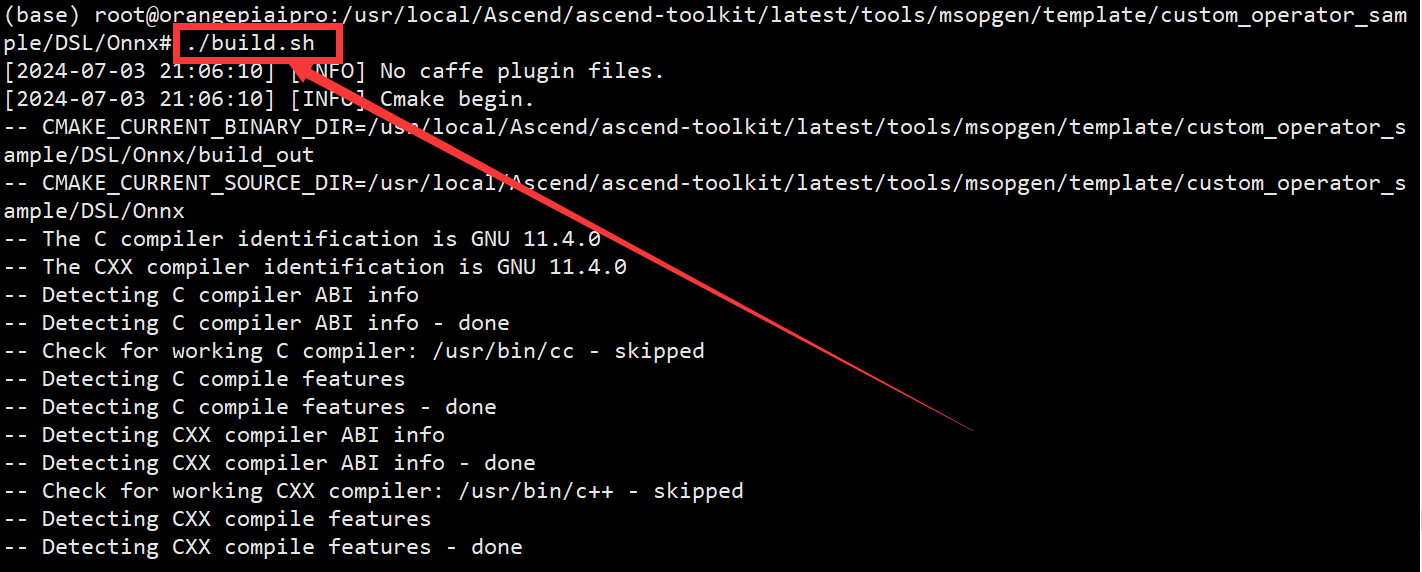
- 编译构建项目,进入到构建输出目录以后续处理生成的文
./build.sh
cd build_out/
- 生成文件到
customize到默认目录$ASCEND_PATH/opp/vendors/
./custom_opp_ubuntu_aarch64.run
- 删除冗余文件
cd $ASCEND_PATH/opp/vendors/customize
rm -rf op_impl/ op_proto/

- 安装依赖:从指定的华为云 PyPI 镜像源安装所需的 Python 包
cd tiny_llama/inference
pip install -r requirements.txt -i https://mirrors.huaweicloud.com/repository/pypi/simple
- 先cd 回到根目录,在进入家目录,找到咱们的
tiny_llama/inference

2.3 推理启动
- 下载tokenizer文件
cd tokenizer
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/tokenizer.zip
unzip tokenizer.zip

- 获取onnx模型文件
cd ../model
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/tiny-llama.onnx
-
我们在复制代码的时候一定要仔细嗷博主这里少打了一个w 导致并没有获取到模型,后期找了半天才发现错误所以提醒大家一定要注意好每一步

-
atc模型转换
atc --framework=5 --model="./tiny-llama.onnx" --output="tiny-llama" --input_format=ND --input_shape="input_ids:1,1;attention_mask:1,1025;position_ids:1,1;past_key_values:22,2,1,4,1024,64" --soc_version=Ascend310B4 --precision_mode=must_keep_origin_dtype

三、 项目体验
好了到这里我们就算是大功告成了,只需要启动一下mian文件就OK了
- 在
cd tiny_llama/inference目录下运行命令
python3 main.py

- 打开网址进行访问
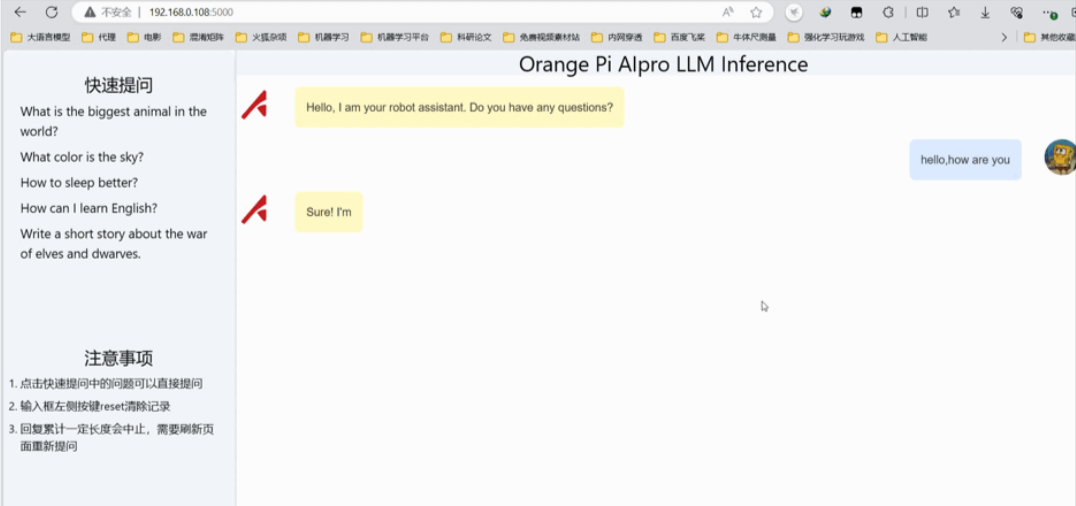
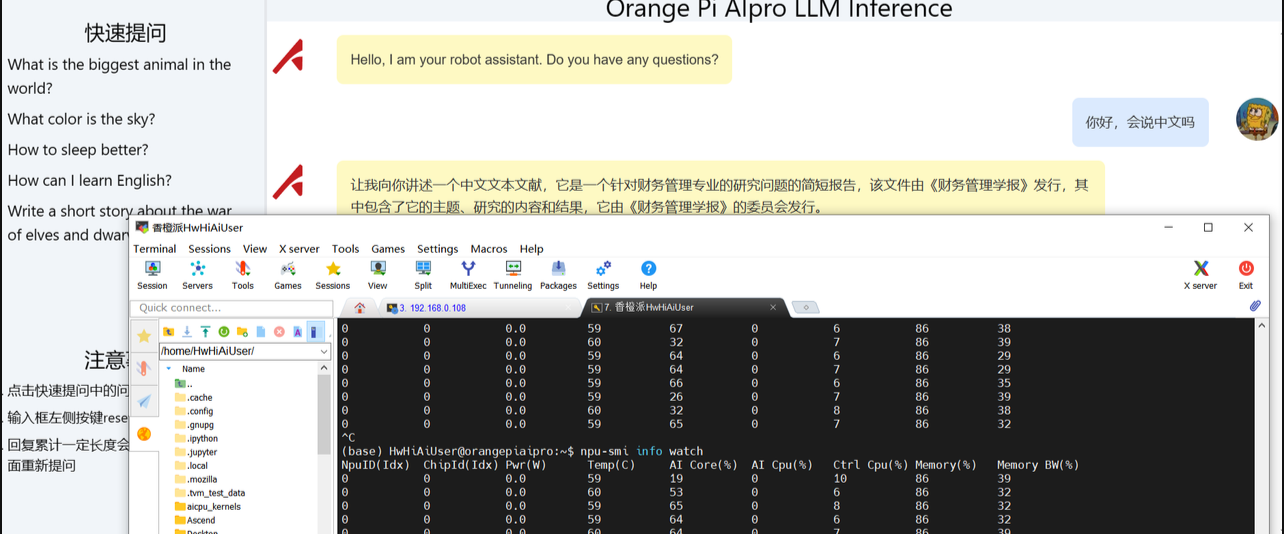
Tiny-Llama这个模型由于尺寸非常小,参数也只有1.1B。所以在我们部署Tiny-Llama这个大语言模型推理过程中,Ai Core的占用率只到60%左右,基本是一秒俩个词左右,速度上是肯定没问题的。后期可以去试试升级一下内存去跑一下当下主流的 千问7B模型 或者 清华第二代大模型拥有 60 亿参数 ChatGLM2 感觉用
OrangePi AIpro这块板子也是没问题。
相关文章:
【linux服务器】大语言模型实战教程:LLMS大模型快速部署到个人服务器
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引言 说到大语言模型相信大家都不会陌生,大型语言模型(LLMs)是人工智能文本处理的主要类型,也现在最流行的人工智能…...
:使用 MASM)
Windows 32 汇编笔记(二):使用 MASM
一、Win32 汇编源程序的结构 ; Hello.asm ; 使用 Win32 ASM 写的 Hello, world 程序 ;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>…...

手机和电脑通过TCP传输(一)
一.工具 手机端:网络调试精灵 电脑端:野火网络调试助手 在开始通信之前,千万要查看一下电脑的防火墙是否关闭,否则可能会无法通信 在开始通信之前,千万要查看一下电脑的防火墙是否关闭,否则可能会无法通信…...

Sentinel规则持久化Push模式两种实现方式
文章目录 sentinel持久化push推模式微服务端的实现具体实现源码分析读数据源写数据源的实现 微服务端解析读数据源流程 修改源码的实现官方demo修改源码实现配置类flowauthoritydegreadparamsystemgateway修改源码 测试补充 前置知识 pull模式 sentinel持久化push推模式 pull拉…...

Spring Boot 中使用 Resilience4j 实现弹性微服务的简单了解
1. 引言 在微服务架构中,服务的弹性是非常重要的。Resilience4j 是一个轻量级的容错库,专为函数式编程设计,提供了断路器、重试、舱壁、限流器和限时器等功能。 这里不做过多演示,只是查看一下官方案例并换成maven构建相关展示&…...

Hadoop3:MR程序压测实验
一、环境要求 内存:128G CPU:32C 磁盘:8T 注:一个虚拟机不超过150G磁盘尽量不要执行这段代码 二、案例 1、需求 使用Sort程序评测MapReduce 2、操作步骤 1、使用RandomWriter来产生随机数,每个节点运行10个Map任…...

初学者如何通过建立个人博客盈利
建立个人博客不仅能让你在网上表达自己,还能与他人建立联系。通过博客,可以创建自己的空间,分享想法和故事,并与有相似兴趣和经历的人交流。 本文将向你展示如何通过建立个人博客来实现盈利。你将学习如何选择博客主题、挑选合适…...

构建稳健性:如何在Gradle中配置构建失败时的行为
构建稳健性:如何在Gradle中配置构建失败时的行为 在软件开发过程中,构建失败是不可避免的。然而,如何优雅地处理构建失败并从中恢复,是提高开发效率和软件质量的关键。Gradle,作为一款强大的构建工具,提供…...

大语言模型-基础及拓展应用
一、基础模型 1、Transformer 2、bert 3、gpt 二、大语言模型 三、句子向量 四、文档解析 1、通用解析 2、docx解析 3、 pdf解析 4、pptx解析 五、向量数据库...

STM32使用Wifi连接阿里云
目录 1 实现功能 2 器件 3 AT指令 4 阿里云配置 4.1 打开阿里云 4.2 创建产品 4.3 添加设备 5 STM32配置 5.1 基础参数 5.2 功能定义 6 STM32代码 本文主要是记述一下,如何使用阿里云物联网平台,创建一个简单的远程控制小灯示例。 完整工程&a…...

2024.7.16日 最新版 docker cuda container tookit下载!
nvidia官方指导 https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html 其实就是这几个命令,但是有墙: curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/shar…...
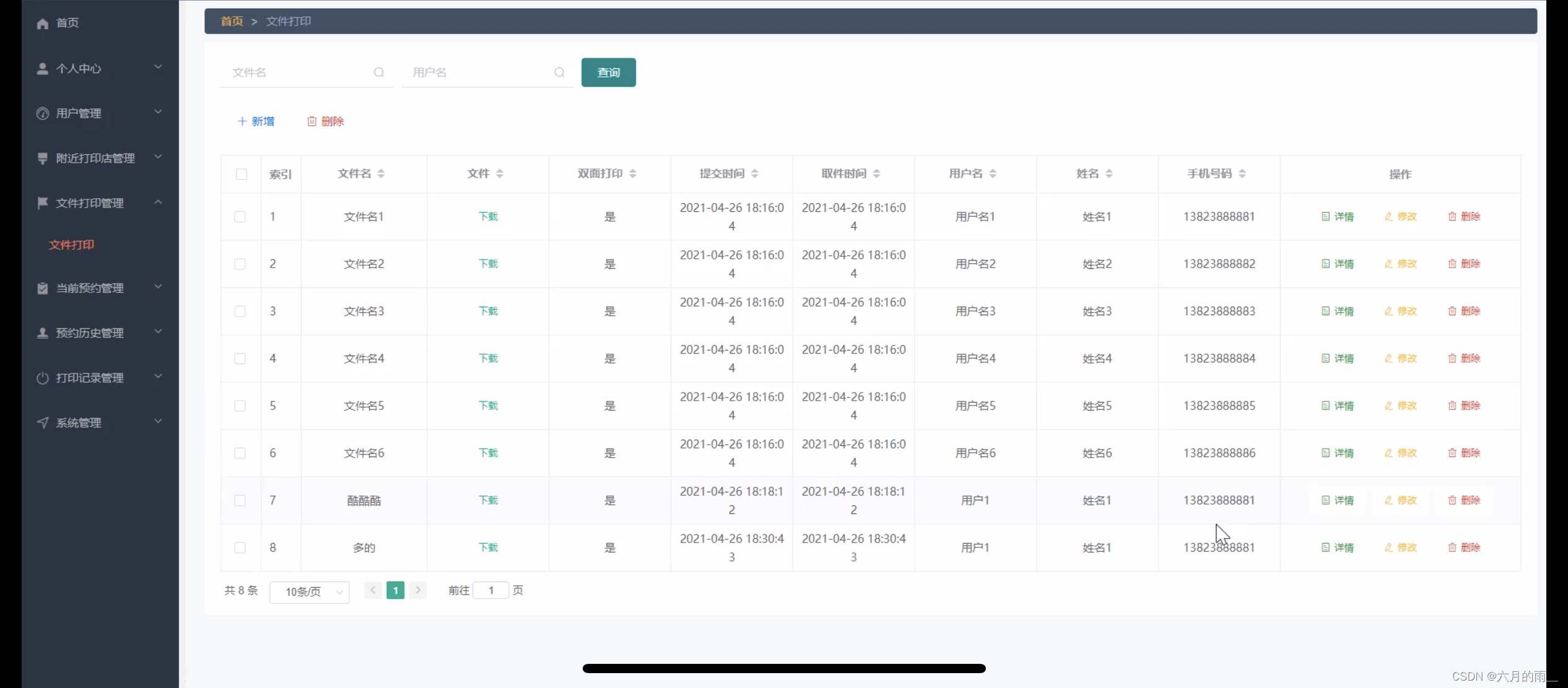
打印室预约小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,附近打印店管理,文件打印管理,当前预约管理,预约历史管理,打印记录管理 开发系统:Windows 架构模式:SSM JD…...

Android音视频—OpenGL 与OpenGL ES简述,渲染视频到界面基本流程
文章目录 OpenGL 简述特点和功能主要组件OpenGL ES当前状态 OpenGL ES 在 Android 上进行视频帧渲染总体流程 OpenGL 简述 OpenGL(Open Graphics Library)是一个跨平台的、语言无关的应用程序编程接口(API),用于开发生…...

Vscode中Github copilot插件无法使用(出现感叹号)解决方案
1、击扩展或ctrl shift x 2、搜索查询或翻找到Github compilot 3、点击插件并再左侧点击登录github 点击Sign up for a ... 4、跳转至github登录页,输入令牌完成登陆后返回VScode 5、插件可以正常使用...

Spring-cloud-openfeign-@FeignClient中的configuration属性
FeignClient注解中的configuration属性就是设置相关配置,但是这个属性写的非常的不好,而且在它的注释中也没有写全,所以本文记录一下,当我们的代码如下时: FeignClient(name "xxx", configuration Abc.cl…...

实验七:图像的复原处理
一、实验目的 熟悉常见的噪声及其概率密度函数。熟悉在实际应用中比较重要的图像复原技术,会对退化图像进行复原处理。二、实验原理 1. 图像复原技术,说简单点,同图像增强那样,是为了以某种预定义的方式来改进图像。在具体操作过程中用流程图表示,其过程就如下面所示: 2…...

前端面试题日常练-day94 【Less】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末 在Less中,以下哪个功能用于处理文本换行? a) wrap-text() b) word-wrap() c) text-wrap() d) line-break() Less中的Variables是用来做什么的? a) 控制元素位置 b)…...

c 语言 中 是否有 unsigned 安;这种写法?
你提到的结构体定义使用了unsigned这种没有完全限定类型的写法,在C语言中,这种语法通常会被解释为unsigned int。这是因为在C语言中,unsigned是unsigned int的缩写形式。 下面是你的结构体定义以及解释: struct exec {unsigned …...

Hive第三天
1. 后台启动HIVE的JDBC连接 0 表示标准输入 1 表示标准输出 2 表示标准错误输出 nohup 表示挂起 最后的 & 表示 后台启动 nohup hive -service hiveserver2 > /usr/local/soft/hive-3.1.2/log/hiveserver2.log 2>&1 & jps 查看 Runj…...

【C++】模版初阶以及STL的简介
个人主页~ 模版及STL 一、模版初阶1、泛型编程2、函数模版(1)概念(2)函数模版格式(3)函数模版的原理(4)函数模版的实例化①显式实例化②隐式实例化 (5)模版参…...

3步实战指南:在Kodi上实现115网盘原码播放的完整方案
3步实战指南:在Kodi上实现115网盘原码播放的完整方案 【免费下载链接】115proxy-for-kodi 115原码播放服务Kodi插件 项目地址: https://gitcode.com/gh_mirrors/11/115proxy-for-kodi 115proxy-for-kodi插件是一款专为Kodi媒体中心设计的115网盘代理服务工具…...

零售行业自动化解决方案选型,核心看这几点:企业级智能体架构与落地实测分析
当前,零售行业正处于从“信息化”向“智能化”跨越的关键拐点。 面对全渠道运营的复杂性、劳动力成本的持续攀升以及消费者对交付时效的极致追求, 自动化解决方案已成为零售企业降本增效的核心战略工具。 然而,市场中各类技术路径分化严重&am…...
)
LVGL下拉列表控件lv_dropdown实战:从基础配置到高级定制(附完整代码示例)
LVGL下拉列表控件lv_dropdown实战:从基础配置到高级定制(附完整代码示例) 在嵌入式UI开发领域,LVGL(Light and Versatile Graphics Library)凭借其轻量级和高度可定制的特性,已成为许多开发者的…...

Java 代码质量保障:静态分析与代码审查实践
Java 代码质量保障:静态分析与代码审查实践代码质量不是测试阶段才考虑的事情,而是应该从第一行代码开始。作为一名经历过多次代码重构的 Java 开发者,我深刻体会到:预防胜于治疗。今天分享一套完整的代码质量保障体系,…...

128K上下文开源代码模型:DeepSeek-Coder-V2赋能开发者的技术解析
128K上下文开源代码模型:DeepSeek-Coder-V2赋能开发者的技术解析 【免费下载链接】DeepSeek-Coder-V2 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Coder-V2 在软件开发效率日益成为竞争力核心指标的今天,开发者面临着代码生成质…...

你的电机仿真结果靠谱吗?聊聊Maxwell瞬态分析里那些容易被忽略的‘坑’
电机仿真精度提升指南:Maxwell瞬态分析中的关键细节与验证方法 当你在凌晨三点盯着屏幕上那条波动异常的转矩曲线时,是否曾怀疑过自己的仿真模型在说谎?作为从业十五年的电磁仿真专家,我见过太多工程师在项目验收前夜才发现仿真结…...

Alexa Skills Kit SDK SMAPI 集成:自动化技能管理和部署的完整流程
Alexa Skills Kit SDK SMAPI 集成:自动化技能管理和部署的完整流程 【免费下载链接】alexa-skills-kit-sdk-for-nodejs The Alexa Skills Kit SDK for Node.js helps you get a skill up and running quickly, letting you focus on skill logic instead of boilerp…...

导师推荐!2026年最值得用的专业AI论文写作工具
2026年AI论文写作工具已从“单点辅助”升级为智能化学术研究系统,核心评价维度涵盖文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规等关键指标。本次测评覆盖6款主流工具,测试场景包括中文与英文论文、全流程与专项功能、免费与付费版本&#x…...

VeraCrypt加密卷功能解析与个性化配置指南
VeraCrypt加密卷功能解析与个性化配置指南 【免费下载链接】VeraCrypt Disk encryption with strong security based on TrueCrypt 项目地址: https://gitcode.com/GitHub_Trending/ve/VeraCrypt VeraCrypt作为一款基于TrueCrypt的开源磁盘加密工具,提供了强…...
【C++】)
CCF-CSP 39-2 水印检查(watermark)【C++】
题目 https://sim.csp.thusaac.com/contest/39/problem/1https://sim.csp.thusaac.com/contest/39/problem/1 思路参考: 80分 暴力求解,遍历所有可能的k,检验是否满足条件,可得80分 时间复杂度:O(L*n^2)࿰…...