【机器学习】Grid Search: 一种系统性的超参数优化方法


🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- Grid Search: 一种系统性的超参数优化方法
- 引言
- 什么是Grid Search?
- Grid Search的工作流程
- 1. 定义超参数范围
- 2. 创建超参数网格
- 3. 训练和评估模型
- 4. 选择最佳超参数
- 随机森林下的 Grid Search
- 步骤1: 导入必要的库
- 步骤2: 准备数据
- 步骤3: 定义超参数的网格
- 步骤4: 创建GridSearchCV对象
- 步骤5: 执行Grid Search
- 步骤6: 分析结果
- Grid Search的优缺点
- 优点
- 缺点
- 总结
Grid Search: 一种系统性的超参数优化方法

引言
在机器学习领域,模型的性能往往取决于一系列可调参数的选择,这些参数被称为“超参数”。与模型权重不同,超参数不能从数据中直接学习得到,而是需要人为设定。超参数的选择对模型最终的表现有着至关重要的影响,因此寻找最佳超参数组合是机器学习项目中的一个关键步骤。本文将详细介绍Grid Search(网格搜索)这一超参数优化技术。
什么是Grid Search?
Grid Search是一种用于自动搜索给定超参数空间中最佳模型参数组合的方法。它通过创建一个包含所有待评估超参数值的网格,然后遍历这个网格中的每一个点来完成搜索过程。对于每个网格点,即超参数的一个特定组合,Grid Search会训练模型并评估其性能,最后选择性能最优的那个组合作为最佳超参数设置。
Grid Search的工作流程
1. 定义超参数范围
首先,需要为每个超参数定义一个候选值的列表或区间。例如,如果我们要调整决策树的深度和最小样本分割数,我们可以定义如下:
- 决策树深度:[3, 5, 7, 9]
- 最小样本分割数:[2, 5, 10]
2. 创建超参数网格

基于上述定义,可以创建一个超参数网格,其中包含所有可能的超参数组合。在这个例子中,我们有:
| 决策树深度 | 最小样本分割数 |
|---|---|
| 3 | 2 |
| 3 | 5 |
| 3 | 10 |
| 5 | 2 |
| 5 | 5 |
| 5 | 10 |
| 7 | 2 |
| 7 | 5 |
| 7 | 10 |
| 9 | 2 |
| 9 | 5 |
| 9 | 10 |
3. 训练和评估模型
对于网格中的每一个超参数组合,Grid Search将重复以下步骤:
- 使用该组合训练模型。
- 在验证集上评估模型性能。
- 记录结果。
4. 选择最佳超参数
最后,根据在验证集上的表现,选择性能最好的超参数组合。通常,性能的度量标准可以是准确率、F1分数、AUC-ROC等,具体取决于问题类型和业务需求。
随机森林下的 Grid Search

随机森林(Random Forest)是一种常用的集成学习方法,它通过构建多个决策树并将它们的预测结果综合起来,以提高预测精度和防止过拟合。在随机森林中,有几个关键的超参数需要调整,比如树的数量(n_estimators)、特征的最大数量(max_features)、节点分裂所需的最小样本数(min_samples_split)等。下面我们将使用Python的Scikit-Learn库来展示如何使用Grid Search对随机森林的超参数进行优化。以下代码仅供参考🐶
步骤1: 导入必要的库
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
步骤2: 准备数据
这里我们使用Iris数据集作为示例。
data = load_iris()
X = data.data
y = data.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
步骤3: 定义超参数的网格
param_grid = {'n_estimators': [10, 50, 100, 200],'max_features': ['auto', 'sqrt', 'log2'],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4],
}
步骤4: 创建GridSearchCV对象
rf = RandomForestClassifier(random_state=42)grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='accuracy', verbose=2, n_jobs=-1)
这里的cv=5表示我们使用5折交叉验证,scoring='accuracy'指定了评估指标为准确率,verbose=2让输出更详细,n_jobs=-1则意味着使用所有可用的处理器核心来加速搜索过程。
步骤5: 执行Grid Search
grid_search.fit(X_train, y_train)
步骤6: 分析结果
best_params = grid_search.best_params_
best_score = grid_search.best_score_print("Best Parameters: ", best_params)
print("Best Score (Cross-Validated): ", best_score)# 使用最佳超参数重新训练模型,并在测试集上评估
best_rf = grid_search.best_estimator_
y_pred = best_rf.predict(X_test)
test_accuracy = accuracy_score(y_test, y_pred)
print("Test Accuracy: ", test_accuracy)
这段代码将会输出最佳超参数组合以及对应的交叉验证得分和测试集准确率。
Grid Search的优缺点
优点
- 简单易用:Grid Search的实现相对直接,不需要复杂的算法知识。
- 保证找到最优解:只要超参数空间被充分覆盖,Grid Search一定能找到最优解。
缺点
- 计算成本高:随着超参数数量和每个参数的候选值数量增加,Grid Search的计算复杂度呈指数级增长。
- 不考虑参数间交互:Grid Search假设超参数之间是相互独立的,这在实际中往往是不成立的。
总结
Grid Search是一种有效的超参数优化方法,尤其适用于超参数空间较小的情况。然而,在处理具有大量超参数的复杂模型时,其计算效率低下成为主要瓶颈。在实际应用中,应根据具体情况权衡是否采用Grid Search,或考虑更高效的替代方案,如Randomized Search或Bayesian Optimization。
以上内容仅为Grid Search概念的简要介绍,深入实践时还需要结合具体案例和工具,如Scikit-Learn库中的GridSearchCV类,进行更细致的学习和应用。


相关文章:
【机器学习】Grid Search: 一种系统性的超参数优化方法
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 Grid Search: 一种系统性的超参数优化方法引言什么是Grid Search?Gr…...

Laravel Passport:API认证的瑞士军刀
Laravel Passport:API认证的瑞士军刀 在现代Web应用中,API的安全认证是一个核心问题。Laravel Passport提供了一个全面的解决方案,用于构建OAuth2.0认证服务器。它使得API的认证变得简单而强大,支持多种认证方式,包括…...

SpringBoot Bean管理
我们知道可以通过Spring当中提供的注解Component以及它的三个衍生注解(Controller、Service、Repository)来声明IOC容器中的bean对象,同时我们也学习了如何为应用程序注入运行时所需要依赖的bean对象,也就是依赖注入DI。 本篇主要…...

Qt5.12.2安装教程
文章目录 文章介绍下载连接安装教程 文章介绍 安装Qt5.12.2 下载连接 点击官网下载 安装包下载完毕 安装教程 点开设置,添加临时储存库,复制连接“https://download.qt.io/online/qtsdkrepository/windows_x86/root/qt/” 点击测试࿰…...

2024年大数据高频面试题(中篇)
文章目录 Kafka为什么要用消息队列为什么选择了kafkakafka的组件与作用(架构)kafka为什么要分区Kafka生产者分区策略kafka的数据可靠性怎么保证ack应答机制(可问:造成数据重复和丢失的相关问题)副本数据同步策略ISRkafka的副本机制kafka的消费分区分配策略Range分区分配策略…...

Python编程工具PyCharm和Jupyter Notebook的使用差异
在编写Python程序时需要用到相应的编程工具,PyCharm和Jupyter Notebook是最常用2款软件。 PyCharm是很强大的综合编程软件,代码提示、代码自动补全、语法检验、文本彩色显示等对于新手来说实在太方便了,但在做数据分析时发现不太方便…...

顶顶通呼叫中心中间件-被叫路由、目的地绑定(mod_cti基于FreeSWITCH)
顶顶通呼叫中心中间件-被叫路由、目的地绑定(mod_cti基于FreeSWITCH) 1、配置分机 点击分机 -> 找到你需要设置的分机 ->呼叫路由设置为external,这里需要设置的分机是呼叫的并不是坐席的分机呼叫路由 2、配置拨号方案 点击拨号方案 -> 输入目的地绑定 …...

【数据集处理工具】根据COCO数据集的json标注文件实现训练与图像的文件划分
根据COCO数据集的json标注文件实现训练与图像的文件划分 一、适用场景:二、COCO数据集简介:三、场景细化:四、代码优势:五、代码 一、适用场景: 适用于一个常见的计算机视觉项目应用场景,特别是当涉及到使…...

vue 如何做一个动态的 BreadCrumb 组件,el-breadcrumb ElementUI
vue 如何做一个动态的 BreadCrumb 组件 el-breadcrumb ElementUI 一、ElementUI 中的 BreadCrumb 定义 elementUI 中的 Breadcrumb 组件是这样定义的 <template><el-breadcrumb separator"/"><el-breadcrumb-item :to"{ path: / }">主…...

FFmpeg播放视频
VS2017+FFmpeg6.2.r113110+SDL2.30.5 1.下载 ShiftMediaProject/FFmpeg 2.下载SDL2 3.新建VC++控制台应用 3.配置include和lib 4.把FFmpeg和SDL的dll 复制到工程Debug目录下,并设置调试命令...

重叠区间的求和
#摘抄 GetGeneLength/src/GetGeneLength/GetGeneLength.py at main PoShine/GetGeneLength GitHub def main(): """ Extract gene length based on featureCount calculation gene nonredundant exon length method. """ # 引…...

java包装类 及其缓存
Java 包装类(Wrapper Class)是将基本数据类型转换为对象的方式,每个基本数据类型在 java.lang 包中都有一个相应的包装类: Boolean 对应基本类型 boolean Character 对应基本类型 char Integer 对应基本类型 int Float 对应基本…...

大龄程序员的出路在哪里?
对于许多资深程序员而言,年龄并非职业发展的桎梏,反而如同陈年的美酒,随着时间的流逝愈发醇厚。他们手握的是丰富的经验和不断进阶的技能,而这些都为他们打开了职业发展的无数扇大门。让我们一同探索这些令人心动的可能性吧&#…...

Unity不用脚本实现点击按钮让另外一个物体隐藏
1.首先在场景中创建一个按钮和一个其他随便什么东西 2.点击按钮中的这个加号 3.然后将刚刚你创建的物体拖到这里来 4.然后依次点击下面这些给按钮绑定事件 5.运行游戏并点击按钮,就会发现拖进来的物体消失了 总结:如果按钮的功能单一,可以使用…...
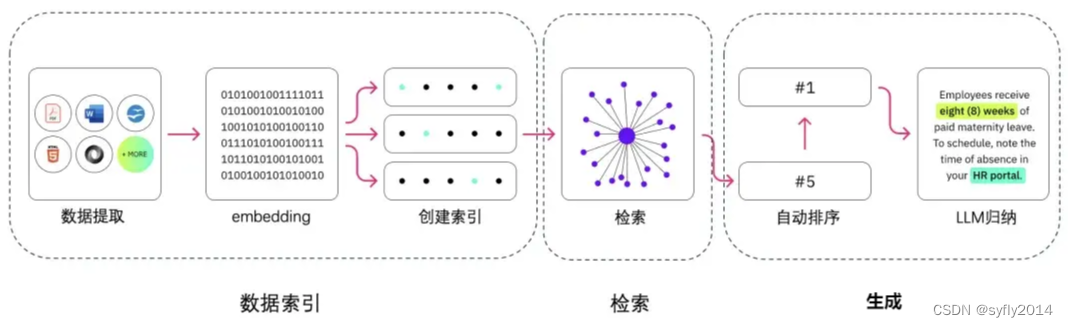
RAG技术-为自然语言处理注入新动力
引言: 在自然语言处理(NLP)的领域中,RAG(Retrieval-Augmented Generation)技术以其独特的方式,正在改变我们与机器的交互方式。RAG技术结合了大语言模型的强大能力,使得机器在理解和…...
)
Docker安装ELK(简易版)
1、下载ELK镜像:打开终端,并执行以下命令以下载Elasticsearch、Logstash和Kibana的Docker镜像。您也可以根据需要选择其他版本: docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.6 docker pull docker.elastic.co/logstash…...
)
WPF项目实战视频《一》(主要为WPF基础知识)
1.WPF布局: Grid,stackPanel,wrapPanel,DockPanel,UniformGrid Grid 按行列布局, Grid.ColumnDefinitions列,Grid.RowDefinitions行 Grid.Row“0” Grid.Column“0” stackPanel 默认从上往下排…...

iOS ------ ARC的工作原理
一,ARC的概念 ARC (Automatic Reference Counting,自动引用计数) 是苹果公司在其编程语言(如 Objective-C 和 Swift)中的内存管理机制。ARC 通过编译器插入的代码自动管理对象的内存生命周期,减少了手动内存管理的复杂…...

【React】JSX基础
一、简介 JSX是JavaScript XML的缩写,它是一种在JavaScript代码中编写类似HTML模板的结构的方法。JSX是React框架中构建用户界面(UI)的核心方式之一。 1.什么是JSX JSX允许开发者使用类似HTML的声明式模板来构建组件。它结合了HTML的直观性…...
1分钟带你了解苹果手机删除照片恢复全过程
在日常使用苹果手机时,我们可能会不小心删除掉一些重要的照片,这让人非常烦恼。那么苹果手机怎么恢复删除的照片?下面小编将会向大家介绍苹果手机恢复删除的照片的方法,帮助大家轻松找回你丢失的照片。 一、利用“最近删除”文件夹…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...

Typora“激活”与“美化”实战指南
1. Typora基础认知与安装准备 Typora作为一款广受好评的Markdown编辑器,其独特之处在于将编辑与预览合二为一。不同于传统Markdown编辑器需要分屏显示源代码和渲染效果,Typora实现了真正的所见即所得——你在编辑区输入的Markdown语法会实时转换为排版效…...

别再死记硬背FIFO了!用Python模拟器带你亲手复现操作系统‘护航效应’
别再死记硬背FIFO了!用Python模拟器带你亲手复现操作系统‘护航效应’ 操作系统中的进程调度算法是计算机科学的核心概念之一,但很多初学者在学习FIFO(先进先出)算法时,往往陷入死记硬背的困境。本文将带你通过Python模…...
SoC硅验证挑战与ClearBlue解决方案解析
1. SoC硅验证与调试的挑战与ClearBlue解决方案在复杂SoC芯片的开发周期中,硅验证阶段往往是最耗时、成本最高且最难预测的环节。当第一颗芯片从晶圆厂返回时,设计团队面临的核心挑战是:如何在真实工作环境和全速运行条件下,快速验…...

半导体制造可持续转型:数据驱动、绿色技术与循环设计实践
1. 项目概述:当芯片制造遇上可持续发展干了十几年半导体行业,从设计到制造环节都摸过一遍,最近几年感受最深的一个变化就是,大家聊天的关键词里,“可持续”出现的频率越来越高。这不再是企业社会责任报告里一句轻飘飘的…...

从“Hello There!”徽章看低功耗Mesh网络在嵌入式社交硬件的实现
1. 项目概述:当硬件徽章成为社交网络的物理层如果你参加过大型的技术会议,尤其是像嵌入式系统大会(ESC)这样的场合,你肯定对那种既兴奋又略带尴尬的社交氛围不陌生。满屋子都是聪明绝顶的工程师,大家脑子里…...

国产AI模型平台突围战:模力方舟如何用开源生态打破大厂垄断?
当全球AI竞赛进入深水区,中国开发者正面临关键抉择:是继续依赖封闭的大厂生态,还是拥抱更开放的本土化解决方案?2023年中国AI模型平台市场数据显示,百度千帆、阿里ModelScope、华为ModelArts三大平台占据72%市场份额&a…...

GPTs 商店深度观察:超级 Agent 的孵化器?
GPTs 商店深度观察:会是下一代超级 AI Agent 的全民孵化器吗? 摘要/引言 2024年6月,OpenAI官方公布了一组数据:GPTs商店上线仅7个月,平台上的自定义GPT数量已经突破1200万,月活使用用户超过8000万,累计为开发者创造的分成收入超过3.2亿美元。这个上线之初被很多业内人士…...

MCP Loom:快速构建AI工具与数据连接器的开发框架
1. 项目概述:MCP Loom,一个连接AI与真实世界的“织布机”如果你最近在折腾AI应用开发,特别是想让你的AI助手(比如Claude、Cursor等)能直接操作你电脑上的文件、数据库,甚至调用外部API,那么你很…...

知识图谱与量化LLM协同架构解析与应用
1. 知识图谱与量化LLM协同架构解析在自然语言处理领域,知识图谱(KG)与大型语言模型(LLM)的协同正展现出独特价值。这种架构的核心在于发挥两者的互补优势:KG提供结构化、可验证的语义网络,而LLM…...