【JavaEE进阶篇2】spring基于注解开发1
在上一篇文章当中,我们提到了怎样使用spring来创建一个bean对象。下面,我们继续来研究一下,更加优胜的开发方式:基于注解开发【JavaEE进阶篇1】认识Spring、认识IoC、使用spring创建对象_革凡成圣211的博客-CSDN博客springIoc、使用spring创建对象https://blog.csdn.net/weixin_56738054/article/details/129540402?spm=1001.2014.3001.5502
目录
第一步:在pom.xml当中导入依赖、并且在xml文件当中添加如下内容
为什么要使用 并且指定base-package的目录?
第二步:把bean存放到IoC容器当中
类注解(作用于类上面)
@Controller:把一个类标记为"控制器"
spring给类命名的规则
@Service
@Repository
@Component
@Configuration
为什么作用都一样,但是还是要这么多注解
5大类注解之间的关系
方法注解(作用在方法上面的注解)
第一步:新建一个User类
第二步:在另外一个类当中自定义一个返回User的方法
第三步:通过getBean方法获取User对象
第一步:在pom.xml当中导入依赖、并且在xml文件当中添加如下内容
在maven项目当中导入(pom.xml)依赖:
<dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.15.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>5.2.15.RELEASE</version></dependency></dependencies>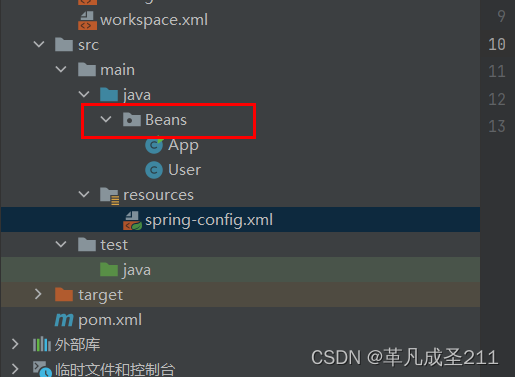
在spring配置文件当中,复制以下的内容即可。
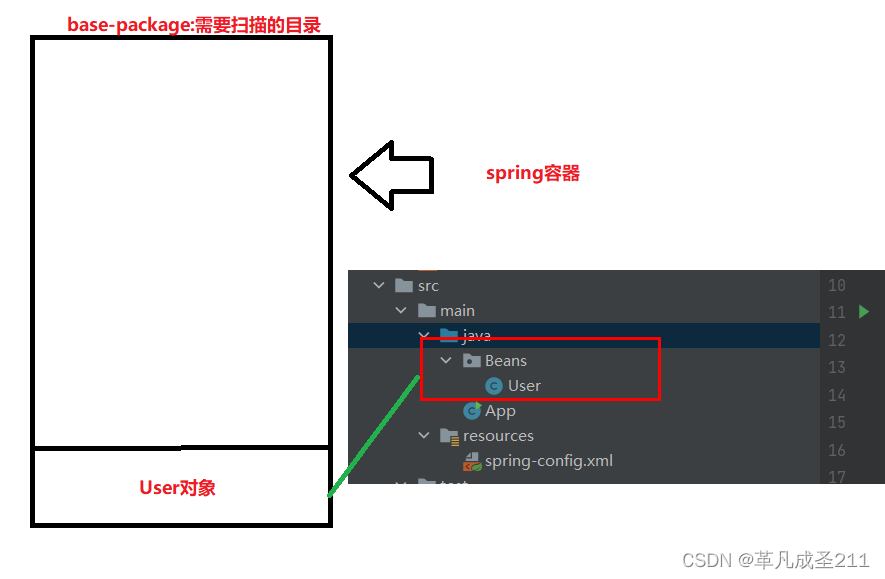
所有要存放到spring中bean的根路径,在此处就指定为"Beans"目录及其子目录下面的所有文件。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.2.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.2.xsd"><!-- 声明扫描包以及子包的类。如果发现有组件注解的类,就创建对象,并加入到容器 --><!--此时,指定的扫描包的名称为Beans,在这个包下面需要存扫描的文件--><context:component-scan base-package="Beans"/></beans>为什么要使用<context:component-scan> 并且指定base-package的目录?
在spring当中的类分为两大类,一大类是在spring当中的,另外一大类是不在spring当中的。
如果使用了这个注解,那么也就意味着:Beans目录下面的类如果被注解作用了,那么就会被放入spring容器当中。
这样设计,可以有效帮助spring减少扫描的次数,只扫描指定目录的类,提升查找的效率。
第二步:把bean存放到IoC容器当中
一般情况下面,把bean放入到IoC容器当中,需要使用到下面的5大类注解:
类注解作用于类上面之后,都会为这个类在spring容器当中注入一个对象。
类注解(作用于类上面)
@Controller:把一个类标记为"控制器"
控制器的含义就是:三层架构当中的Controller对应的类。
其中,@Controller注解当中传入的参数,就是这一个类对象的名称。
@Controller("User")
public class User {public void say(){System.out.println("user say...");}
}
如果想要获取这个bean,可以这样获取:
public static void main(String[] args) {ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");//在容器当中指定对象的名称,指定User.class的内容User user=applicationContext.getBean("User",User.class);user.say();}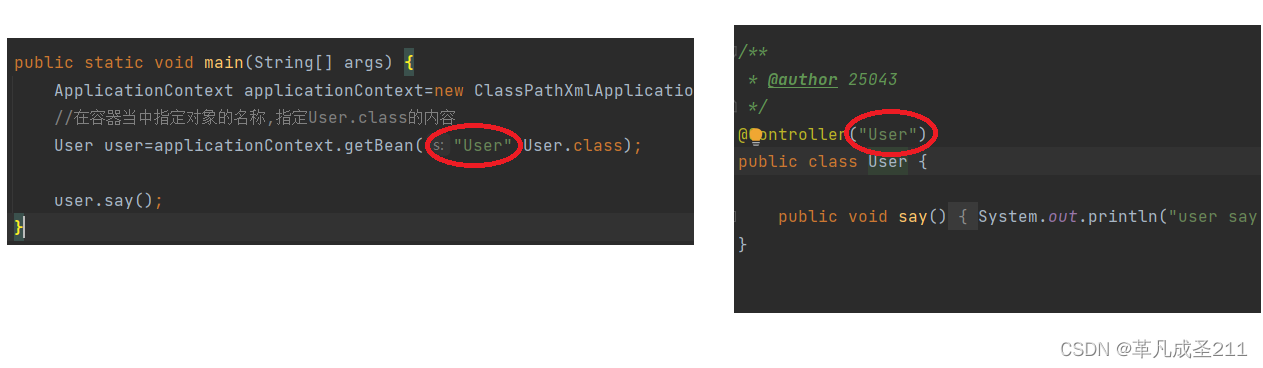 这两个内容要一致。
这两个内容要一致。
如果@Controller当中没有指定名称。那么,getBean的时候,传入的id就应当默认为User类名称的小驼峰:user。
但是,如果一个类的名称,没有按照驼峰命名法的规则来呢? 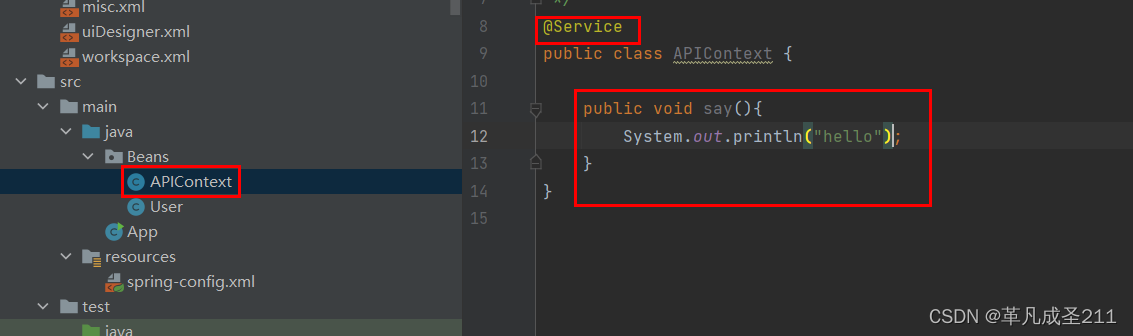
获取APIContext类的对象:
public static void main(String[] args) {ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");//在容器当中指定对象的名称,此处假设一个类不按照小驼峰的方式开命名APIContext aPIContext=applicationContext.getBean("aPIContext", APIContext.class);aPIContext.say();}运行就会发现:

下面,来看一下spring给bean命名的潜规则:
spring给类命名的规则
来看一下源码:
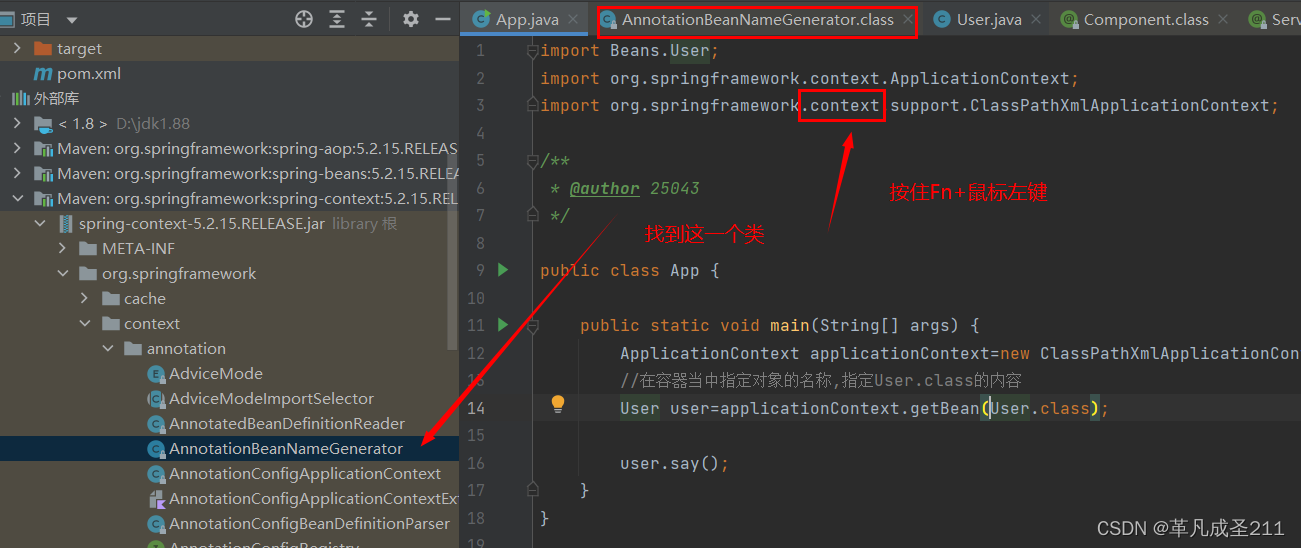
然后,在这个类的内部,往下拉动,找到这两个方法buildDefaultBeanName方法:
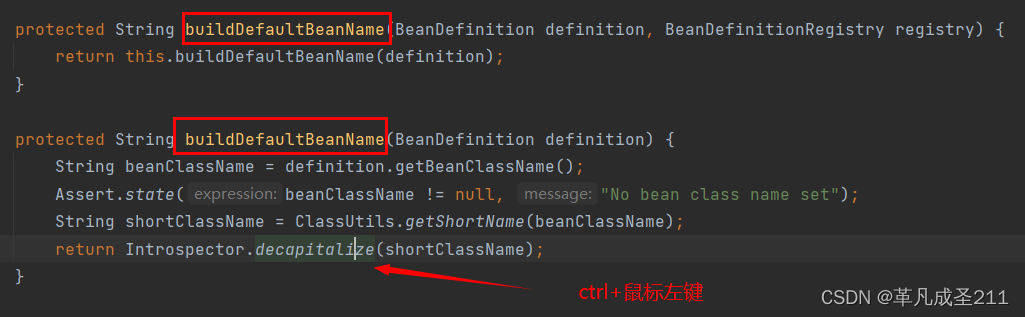
最后,跳转到这个方法:decapitalize。下面,重点来分析一下这个方法:
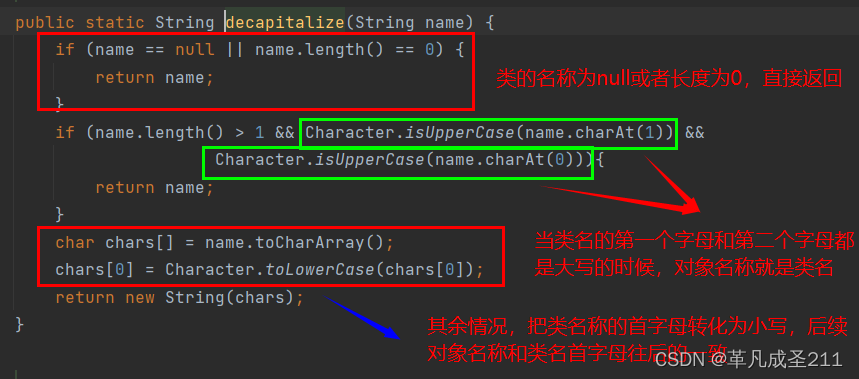
因此,总结一下spring在没有指定类的名称的时候,是怎样转化的:
当类名称的首字母和第二个字母都是大写的时候:那么对象名称(bean的名称)就是类名。
如果类名称的其余情况:对象名称=类名称的第一个字母转为小写+后面内容一致。
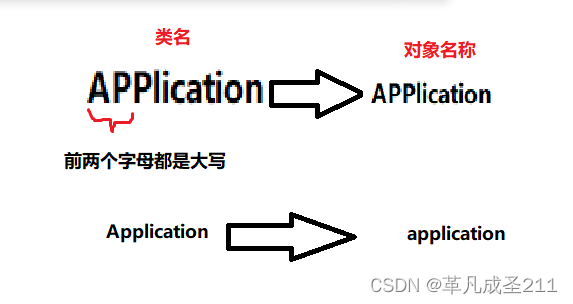
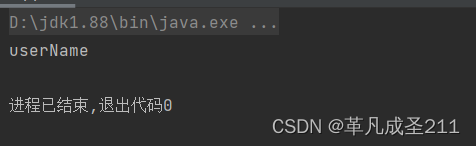
下面,来试验一下这个命名规则:(调用Introspector.decapitalize(String name)这个方法)
public static void main(String[] args) {String name="UserName";System.out.println(Introspector.decapitalize(name));}运行的结果是:
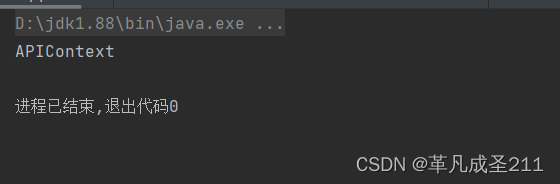
再实验一下API这样的形式:
public static void main(String[] args) {String name="APIContext";System.out.println(Introspector.decapitalize(name));}然后观察一下运行的结果:可以看到,此时bean的名称就是类名称了。
@Service
作用与Controller一样,用于标注"业务逻辑层"的对象。
@Repository
作用与Controller一样,用于标注"持久层"的对象
@Component
不属于前面的任意3层,那么这个注解就可以认为是一个"工具"。
@Configuration
作用与Controller一样,用于标注"配置类"。
为什么作用都一样,但是还是要这么多注解
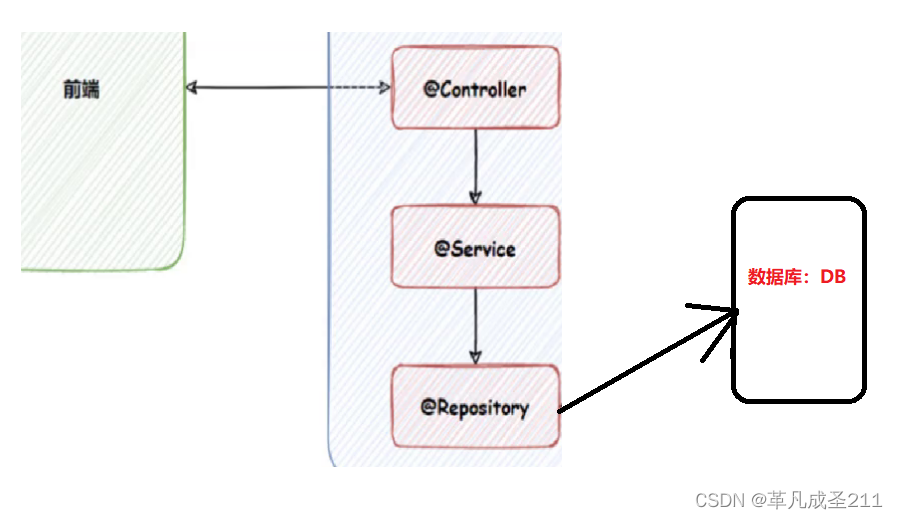
这就涉及到"软件开发"的模型了。为了实现一个软件功能的解耦合,软件开发一般要至少分为4个层次:
层次1:前端的页面展示;
层次2:接口层,用于接收并且校验前端提交的参数,,调用逻辑层,并且作出响应(一般这个层的类需要使用@Controller来标注);
层次3:逻辑层,用于处理接口层传来的数据,并且处理业务逻辑。如果一些业务需要和数据库层打交道,那么逻辑层就会调用下一层。(使用@Service注解作用)
层次4:持久层,用于和数据库打交道的层面。(使用@Repository来作用)
分开了5大类注解,令代码的可读性提高了,让程序员能够直观地判断当前类的业务用途。
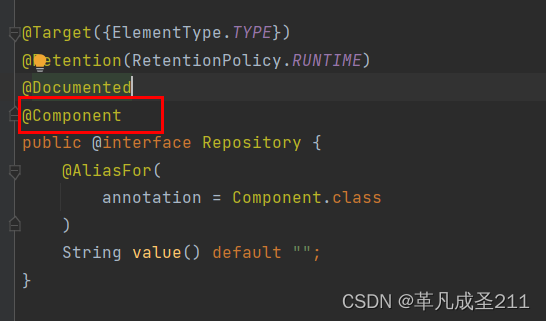
5大类注解之间的关系
当我们点开各个注解的时候,可以看到:除了@Component注解以外的注解,都是基于@Component来实现的。也就是说,@Component是上述所有注解的父类。
方法注解(作用在方法上面的注解)
这个注解的作用,也是把bean给注入到spring容器当中,但是这个bean是作为方法的返回值。
第一步:新建一个User类
public class User {private int id;private String name;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "User{" +"id=" + id +", name='" + name + '\'' +'}';}
}第二步:在另外一个类当中自定义一个返回User的方法
第二步由两个比较重要的部分构成:
第一部分:需要在这个方法上面加一个注解:@Bean。
第二部分:并且还需要在这个方法所在的类上面再加一个五大类注解当中的一个。
为什么spring规定不可以单独把@Bean注解作用于方法上,然后把这个方法的返回值放入到spring容器当中
提高效率!
在类上面增加了注解之后,可以有效降低spring组件扫描的范围。当且仅当一个类被5大注解作用的时候,才会扫描这个类当中@Bean方法返回值注入的对象。
/*** @author 25043*/
//这个注解不可以少
@Service
public class UserBeans {//把方法返回的值作为对象存储到Ioc容器当中@Beanpublic User user1(){//创建一个User对象User user=new User();//设置属性的值user.setId(1);user.setName("你好");//返回user对象return user;}
}此外,还可以在@Bean注解当中指定需要存放对象的名称(通过name属性指定注入的bean的名称):
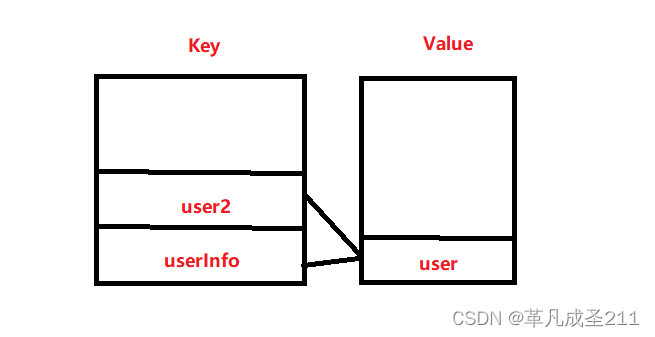
//在注解当中指定name属性,就是返回值在spring容器当中的bean@Bean(name = {"user2","userInfo"})public static User getUser2(){User user=new User();user.setId(2);user.setName("你好2");return user;}这个时候,通过两个不同的key,也可以找到同一个user了。因为此时在ioC容器当中,有两个相同的key指向了同一个user。
第三步:通过getBean方法获取User对象
getBean方法当中,传入的两个参数分别是:
@Bean注解作用的方法的名称
User类的class对象
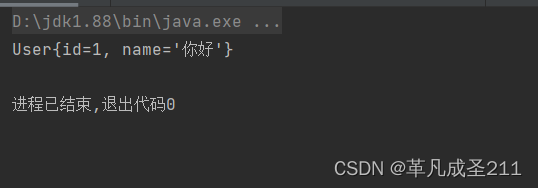
public static void main(String[] args) {//获取spring上下文对象ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-config.xml");//传入两个参数,一个是方法名称:user1,另外一个是User的class对象User user=applicationContext.getBean("user1",User.class);System.out.println(user);}运行的结果:
第三步注意事项:
如果getBean()方法当中只传入一个参数:User.class的话,那么此时默认IoC容器当中只有一个User类型的bean。如果有两个User类型的bean的话,那么就会报错。
下面演示一下出错的情况:
①放入两个不同的bean,但是都是User类型
@Service
public class UserBeans {@Beanpublic User user1(){User user=new User();user.setId(1);user.setName("你好");return user;}//在注解当中指定name属性,就是返回值在spring容器当中的bean@Bean(name = {"user2","userInfo"})public static User getUser2(){User user=new User();user.setId(2);user.setName("你好2");return user;}
}②调用传入
相关文章:
【JavaEE进阶篇2】spring基于注解开发1
在上一篇文章当中,我们提到了怎样使用spring来创建一个bean对象。下面,我们继续来研究一下,更加优胜的开发方式:基于注解开发【JavaEE进阶篇1】认识Spring、认识IoC、使用spring创建对象_革凡成圣211的博客-CSDN博客springIoc、使…...

统一登录验证统一返回格式统一异常处理的实现
统一登录验证&统一返回格式&统一异常处理的实现 一、用户登录权限效验1.1 最初的用户登录验证1.2 Spring AOP 用户统一登录验证的问题1.3 Spring 拦截器1.3.1 准备工作1.3.2 自定义拦截器1.3.3 将自定义拦截器加入到系统配置1.4 拦截器实现原理1.4.1 实现原理源码分析1…...

【建议收藏】华为OD面试,什么场景下会使用到kafka,消息消费中需要注意哪些问题,kafka的幂等性,联合索引等问题
文章目录 华为 OD 面试流程一、什么场景下会使用到 kafka二、消息消费中需要注意哪些问题三、怎么处理重复消费四、kafka 的幂等性怎么处理的五、kafka 会怎么处理消费者消费失败的问题六、数据库设计中,你会如何去设计一张表七、联合索引有什么原则华为 OD 面试流程 机试:三…...
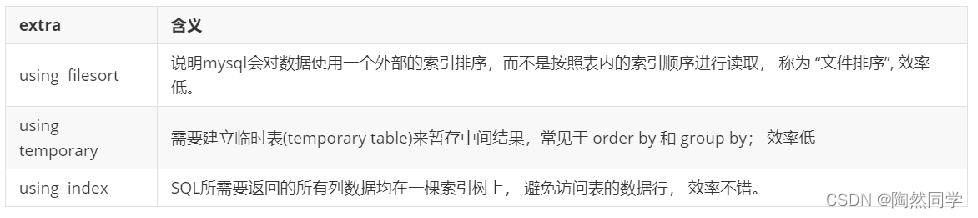
【MySQL】MySQL的优化(二)
目录 explain分析执行计划 Explain分析执行计划-Explain 之 id Explain分析执行计划-Explain 之 select_type Explain分析执行计划-Explain 之 type Explain分析执行计划-其他指标字段 explain分析执行计划 通过以上步骤查询到效率低的 SQL 语句后,可以通过 …...
QT VTK开发 (一、下载编译)
Vtk,(visualization toolkit)是一个开源的免费软件系统,主要用于三维计算机图形学、图像处理和可视化。Vtk是在面向对象原理的基础上设计和实现的,它的内核是用C构建的,包含有大约250,000行代码,…...

C/C++每日一练(20230314)
目录 1. 移动数组中的元素 2. 搜索二维矩阵 3. 三角形最小路径和 🌟 每日一练刷题专栏 🌟 Golang 每日一练 专栏 C/C 每日一练 专栏 Python 每日一练 专栏 Java 每日一练 专栏 1. 移动数组中的元素 将一维数组中的元素循环左移 k 个位置 输入…...

裸辞3个月,面试了25家公司,终于找到心仪的工作了
上半年裁员,下半年裸辞,有不少人高呼裸辞后躺平真的好快乐!但也有很多人,裸辞后的生活五味杂陈。 面试25次终于找到心仪工作 因为工作压力大、领导PUA等各种原因,今年2月下旬我从一家互联网小厂裸辞,没…...
【Linux学习】进程间通信——system V(共享内存 | 消息队列 | 信号量)
🐱作者:一只大喵咪1201 🐱专栏:《Linux学习》 🔥格言:你只管努力,剩下的交给时间! 进程间通信——共享内存 | 消息队列 | 信号量🏀共享内存⚽系统调用shmgetkey值⚽系统…...
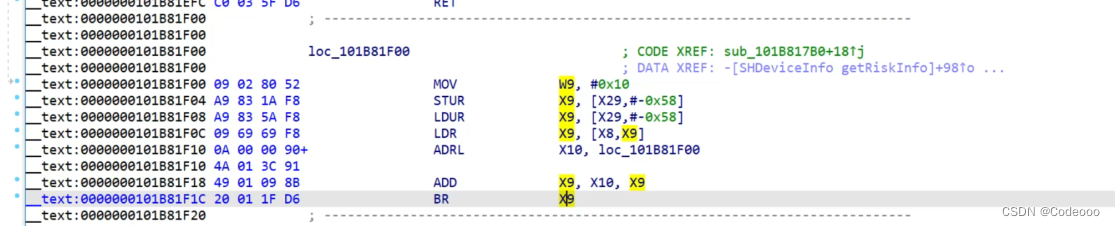
解决 IDA 防F5转伪C笔记
某app砸壳后放到IDA,根据堆栈查到该位置如下; G调到,0x1b81bcc 看下: BR 调到后面 x8 x9地址,汇编指令; 找到x9的地址,然后减去基地址也就是首地址,得到便宜地址; hook x9: var moduleAddr = Module.findBaseAddress("XX"); var line = moduleAddr.add...

【面试题】你需要知道的webpack高频面试题
大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库谈谈你对webpack的看法webpack是一个模块打包工具,可以使用它管理项目中的模块依赖,并编译输出模块所需的静态文件。它…...

【YOLOv8/YOLOv7/YOLOv5/YOLOv4/Faster-rcnn系列算法改进NO.60】损失函数改进为wiou
前言作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍&…...
attack解析(详细))
2023年中职网络安全竞赛——数字取证调查(新版)attack解析(详细)
数字取证调查 任务环境说明: 服务器场景:FTPServer20221010(关闭链接)服务器场景操作系统:未知FTP用户名:attack817密码:attack817分析attack.pcapng数据包文件,通过分析数据包attack.pcapng找出恶意用户第一次访问HTTP服务的数据包是第几号,将该号数作为Flag值提交;…...

Cadence Allegro 导出Net Single Pin and No Pin报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Net Single Pin and No Pin作用3,Net Single Pin and No Pin示例4,Net Single Pin and No Pin导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
蓝桥冲刺31天之317
在这个时代,我们总是在比较,觉得自己不够好 其实不必羡慕别人的闪光点 每个人都是属于自己的限量版 做你喜欢并且擅长的事,做到极致 自然会找到自己独一无二的价值 鸟不跟鱼比游泳,鱼不跟鸟比飞翔 你我各有所长 A:组队…...
站上风口,文心一言任重道远
目录正式发布时机选择逻辑推理AI绘画用户选择总结自从OpenAI公司的chatGPT发布以来,吸引了全球目光,同时也引起了我们的羡慕,希望有国产的聊天机器人,盼星星盼月亮,终于等来了百度文心一言的发布。 正式发布 3月16日…...

Qt音视频开发24-视频显示QOpenGLWidget方式(占用GPU)
一、前言 采用painter的方式绘制解码后的图片,方式简单易懂,巨大缺点就是占CPU,一个两个通道还好,基本上CPU很低,但是到了16个64个通道的时候,会发现CPU也是很吃紧(当然强劲的电脑配置另当别论…...

百度发布文心一言,我想说几句
大家好,我是记得诚。 今天下午百度公司正式发布了文心一言,算是国内第一个交卷的互联网公司。 在ChatGPT和GPT-4的双重夹击下,可想而知百度的压力。 ChatGPT发布的时候,热度非常的高,大家对其都非常的感兴趣。 我是…...

简单了解JSP
JSP概念与原理概念: Java Server Pages,Java服务端页面一种动态的网页技术,其中既可以定义 HTML、JS、CSS等静态内容,还可以定义Java代码的动态内容JSP HTML Java, 用于简化开发JSP的本质上就是一个ServletJSP 在被访问时,由JSP容…...
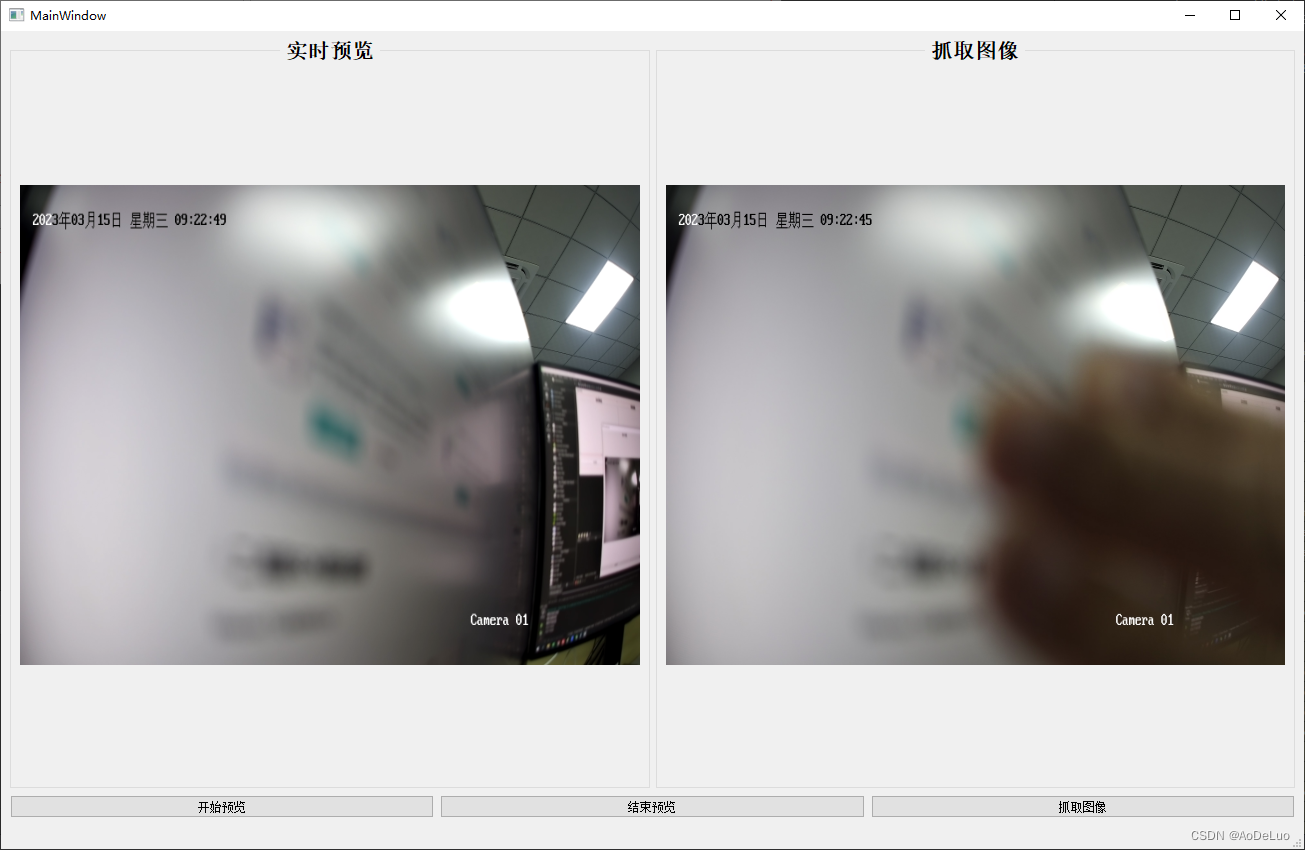
Qt(c++)调用海康威视监控摄像头
文章目录一.海康威视监控摄像头开发SDK介绍二.海康SDK模块说明三.Qt项目中海康威视SDK配置四.实时预览摄像头图像程序一.海康威视监控摄像头开发SDK介绍 设备网络SDK是基于设备私有网络通信协议开发的,为嵌入式网络硬盘录像机、NVR、网络摄像机、网络球机、视频服务…...
: CUDA_Run_Time_API_parallel_多流并行,以及多流之间互相同步等待的操作方式)
深度学习部署笔记(十五): CUDA_Run_Time_API_parallel_多流并行,以及多流之间互相同步等待的操作方式
// CUDA运行时头文件 #include <cuda_runtime.h>#include <chrono> #include <stdio.h> #include <string.h>using namespace std;#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)bool __check_cuda_runtime(cudaErro…...

OpenClaw 消息路由与广播机制深度解析
OpenClaw 消息路由与广播机制深度解析 作者: Social Agent (小社) 日期: 2026-03-18 研究模块: channels/channel-routing + broadcast-groups + group-messages 一、消息路由的核心设计 1.1 确定性路由,而非 AI 决策 OpenClaw 消息路由最重要的设计决策是:路由是确定性的…...

从音箱分频器到手机触控:聊聊RC电路滤波在身边的那些事儿
从音箱分频器到手机触控:聊聊RC电路滤波在身边的那些事儿 你是否注意过,为什么高端音箱总会有多个喇叭单元?为什么触摸屏在潮湿环境下容易失灵?这些现象背后都藏着一个电子世界的"交通警察"——RC滤波电路。它像一位隐形…...

FILCO架构:动态可重构DNN加速器设计解析
1. FILCO架构设计背景与核心挑战深度神经网络(DNN)加速器设计正面临一个根本性矛盾:专用架构在特定负载下能达到峰值效率,但实际应用中工作负载的多样性日益增长。以自动驾驶系统为例,单个任务流程可能同时包含MLP分类器、Transformer视觉模型…...
实战分配指南(MDK/IAR双环境))
告别内存焦虑!STM32H743全系列SRAM(ITCM/DTCM/AXI)实战分配指南(MDK/IAR双环境)
STM32H743内存优化实战:从理论到精准分配的完整指南 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。STM32H743作为STMicroelectronics推出的高性能微控制器系列,其复杂的内存架构既带来了性能优势,也增加了开发难…...

为AI编程助手注入Go语言最佳实践:golang-skills技能包实战指南
1. 项目概述:为AI编程助手注入Go语言“肌肉记忆” 如果你和我一样,日常开发重度依赖像Cursor、Claude Code这类AI编程助手,那你肯定也遇到过类似的困扰:生成的Go代码虽然语法正确,但总感觉“味儿”不对。要么是错误处理…...

开源物联网平台SiteWhere:架构解析与实战部署指南
1. 项目概述:一个开源的物联网应用平台如果你正在寻找一个能够快速搭建、灵活扩展,并且能统一管理成千上万台设备的物联网平台,那么你很可能已经听说过或者正在评估 SiteWhere。作为一个在物联网领域摸爬滚打了多年的从业者,我见过…...

告别臃肿!Dell G15笔记本散热控制的轻量级开源替代方案
告别臃肿!Dell G15笔记本散热控制的轻量级开源替代方案 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否厌倦了Dell原厂AWCC软件的缓慢响应和…...

Flutter 轻量存储方案介绍、区别、对比和使用场景
在 Flutter 项目中,本地存储通常可以分为几类: 第一类是轻量 Key-Value 存储,例如 shared_preferences、get_storage、mmkv,适合保存开关、配置、登录状态等简单数据。 第二类是安全存储,例如 flutter_secure_storage&…...

C++ 入门核心语法|从 Hello World 到基础特性一次性吃透
文章目录前言一、C 第一个程序:Hello World二、命名空间 namespace1. 为什么需要命名空间?2. 命名空间定义规则3. 三种使用方式三、C 输入 & 输出1. 核心对象2. 最大优势四、缺省参数(默认参数)1. 定义2. 使用方式3. 声明与定…...

商业航天崛起:从SpaceX看工程创新与政策博弈的融合
1. 商业航天崛起的时代背景与技术逻辑2012年5月,当SpaceX的“龙”飞船与国际空间站成功对接时,我正和几位航天领域的同行在会议室里盯着直播画面。那一刻的安静与随后爆发的掌声,不仅仅是为一次技术成功,更是为一个新时代的开启感…...