trl - 微调、对齐大模型的全栈工具

文章目录
- 一、关于 TRL
- 亮点
- 二、安装
- 1、Python包
- 2、从源码安装
- 3、存储库
- 三、命令行界面(CLI)
- 四、如何使用
- 1、`SFTTrainer`
- 2、`RewardTrainer`
- 3、`PPOTrainer`
- 4、`DPOTrainer`
- 五、其它
- 开发 & 贡献
- 参考文献
- 最近策略优化 PPO
- 直接偏好优化 DPO
一、关于 TRL
TRL : Transformer Reinforcement Learning
Full stack library to fine-tune and align large language models.
Train transformer language models with reinforcement learning.
- github : https://github.com/huggingface/trl
- 文档:https://huggingface.co/docs/trl/index
该trl库是一个全栈工具,用于使用监督微调步骤(SFT)、奖励建模(RM)和近似策略优化(PPO)以及直接偏好优化(DPO)等方法微调和对齐转换器语言和扩散模型。
该库建立在transformers库之上,因此允许使用那里可用的任何模型架构。
亮点
Efficient and scalableaccelerate是trl的支柱,它允许使用DDP和DeepSpeed等方法将模型训练从单个GPU扩展到大规模多节点集群。PEFT是完全集成的,即使是最大的模型也可以通过量化和LoRA或QLoRA等方法在适度的硬件上训练。unsloth也是集成的,允许使用专用内核显着加快训练速度。
CLI:使用CLI,您可以使用单个命令和灵活的配置系统微调LLM并与之聊天,而无需编写任何代码。Trainers:培训师类是一个抽象,可以轻松应用许多微调方法,如SFTTrainer、DPOTrainer、RewardTrainer、PPOTrainer、CPOTrainer和ORPOTrainer。AutoModels:AutoModelForCausalLMWithValueHead&AutoModelForSeq2SeqLMWithValueHead类为模型添加了一个额外的值头,允许使用RL算法(如PPO)训练它们。Examples:使用BERT情感分类器训练GPT2以生成积极的电影评论,仅使用适配器的完整RLHF,训练GPT-j毒性更小,StackLlama示例等。以下是示例。
二、安装
1、Python包
使用pip安装库:
pip install trl
2、从源码安装
如果您想在正式发布之前使用最新功能,您可以从源代码安装:
pip install git+https://github.com/huggingface/trl.git
3、存储库
如果您想使用这些示例,您可以使用以下命令克隆存储库:
git clone https://github.com/huggingface/trl.git
三、命令行界面(CLI)
您可以使用TRL命令行界面(CLI)快速开始使用监督微调(SFT)、直接偏好优化(DPO)并使用聊天CLI测试对齐的模型:
SFT:
trl sft --model_name_or_path facebook/opt-125m --dataset_name imdb --output_dir opt-sft-imdb
DPO:
trl dpo --model_name_or_path facebook/opt-125m --dataset_name trl-internal-testing/hh-rlhf-helpful-base-trl-style --output_dir opt-sft-hh-rlhf
聊天:
trl chat --model_name_or_path Qwen/Qwen1.5-0.5B-Chat
在 relevant documentation section 阅读有关CLI的更多信息,或使用--help获取更多详细信息。
四、如何使用
为了获得更多的灵活性和对训练的控制,您可以使用专用的训练类 来微调Python中的模型。
1、SFTTrainer
这是如何使用库中的SFTTrainer的基本示例。
SFTTrainer 是围绕transformersTrainer的轻型包装器,可轻松微调自定义数据集上的语言模型或适配器。
# imports
from datasets import load_dataset
from trl import SFTTrainer# get dataset
dataset = load_dataset("imdb", split="train")# get trainer
trainer = SFTTrainer("facebook/opt-350m",train_dataset=dataset,dataset_text_field="text",max_seq_length=512,
)# train
trainer.train()
2、RewardTrainer
这是如何使用库中的RewardTrainer的基本示例。
RewardTrainer 是 transformers Trainer 的包装器,可轻松微调自定义偏好数据集上的奖励模型或适配器。
# imports
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer# load model and dataset - dataset needs to be in a specific format
model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)
tokenizer = AutoTokenizer.from_pretrained("gpt2")...# load trainer
trainer = RewardTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,
)# train
trainer.train()
3、PPOTrainer
这是如何使用库中的PPOTrainer的基本示例。
基于查询,语言模型创建一个响应,然后对其进行评估。评估可以是循环中的人或另一个模型的输出。
# imports
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch# get models
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
ref_model = create_reference_model(model)tokenizer = AutoTokenizer.from_pretrained('gpt2')
tokenizer.pad_token = tokenizer.eos_token# initialize trainer
ppo_config = PPOConfig(batch_size=1, mini_batch_size=1)# encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")# get model response
response_tensor = respond_to_batch(model, query_tensor)# create a ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, ref_model, tokenizer)# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0)]# train model for one step with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
4、DPOTrainer
DPOTrainer是使用直接偏好优化算法的培训师,这是如何使用库中的DPOTrainer的基本示例DPOTrainer是transformersTrainer的包装器,可轻松微调自定义偏好数据集上的奖励模型或适配器。
# imports
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOTrainer# load model and dataset - dataset needs to be in a specific format
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")...# load trainer
trainer = DPOTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,
)# train
trainer.train()
五、其它
开发 & 贡献
如果您想为trl做出贡献或根据您的需求对其进行定制,请务必阅读贡献指南并确保您进行了开发安装:
git clone https://github.com/huggingface/trl.git
cd trl/
make dev
参考文献
最近策略优化 PPO
PPO实现在很大程度上遵循D. Ziegler等人的**“来自人类偏好的微调语言模型”**论文中介绍的结构。[论文,代码]。
直接偏好优化 DPO
DPO基于E. Mitchell等人的**《直接偏好优化:您的语言模型是秘密的奖励模型》**的原始实现。[论文,代码]
2024-07-17(三)
相关文章:
trl - 微调、对齐大模型的全栈工具
文章目录 一、关于 TRL亮点 二、安装1、Python包2、从源码安装3、存储库 三、命令行界面(CLI)四、如何使用1、SFTTrainer2、RewardTrainer3、PPOTrainer4、DPOTrainer 五、其它开发 & 贡献参考文献最近策略优化 PPO直接偏好优化 DPO 一、关于 TRL T…...

GuLi商城-商品服务-API-品牌管理-品牌分类关联与级联更新
先配置mybatis分页: 品牌管理增加模糊查询: 品牌管理关联分类: 一个品牌可以有多个分类 一个分类也可以有多个品牌 多对多的关系,用中间表 涉及的类: 方法都比较简单,就不贴代码了...

【linux】服务器ubuntu安装cuda11.0、cuDNN教程,简单易懂,包教包会
【linux】服务器ubuntu安装cuda11.0、cuDNN教程,简单易懂,包教包会 【创作不易,求点赞关注收藏】 文章目录 【linux】服务器ubuntu安装cuda11.0、cuDNN教程,简单易懂,包教包会一、版本情况介绍二、安装cuda1、到官网…...

在 Apifox 中如何高效批量添加接口请求 Body 参数?
在使用 Apifox 进行 API 设计时,你可能会遇到需要添加大量请求参数的情况。想象一下,如果一个接口需要几十甚至上百个参数,若要在接口的「修改文档」里一个个手动添加这些参数,那未免也太麻烦了,耗时且易出错。这时候&…...
专业PDF编辑工具:Acrobat Pro DC 2024.002.20933绿色版,提升你的工作效率!
软件介绍 Adobe Acrobat Pro DC 2024绿色便携版是一款功能强大的PDF编辑和转换软件,由Adobe公司推出。它是Acrobat XI系列的后续产品,提供了全新的用户界面和增强功能。用户可以借助这款软件将纸质文件转换为可编辑的电子文件,便于传输、签署…...
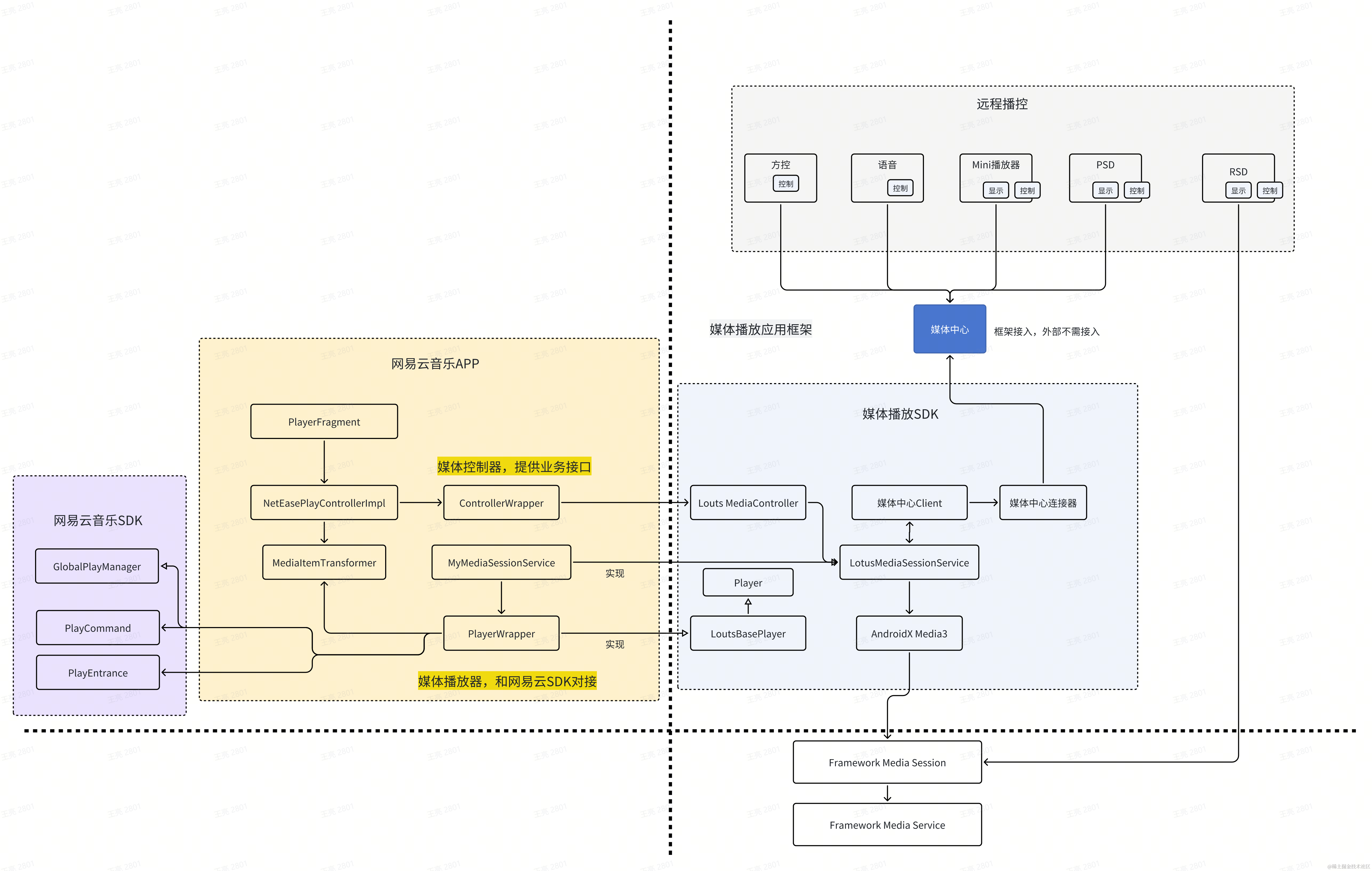
车载音视频App框架设计
简介 统一播放器提供媒体播放一致性的交互和视觉体验,减少各个媒体应用和场景独自开发的重复工作量,实现媒体播放链路的一致性,减少碎片化的Bug。本文面向应用开发者介绍如何快速接入媒体播放器。 主要功能: 新设计的统一播放U…...

StarRocks on AWS Graviton3,实现 50% 以上性价比提升
在数据时代,企业拥有前所未有的大量数据资产,但如何从海量数据中发掘价值成为挑战。数据分析凭借强大的分析能力,可从不同维度挖掘数据中蕴含的见解和规律,为企业战略决策提供依据。数据分析在营销、风险管控、产品优化等领域发挥…...
)
VUE中setup()
在Vue中,setup() 函数是Vue 3.0及更高版本引入的一个重要特性,它是Composition API的入口点。setup() 函数用于初始化组件的状态和逻辑,包括定义响应式数据、方法和生命周期钩子。以下是关于setup() 函数的详细解释: 1. 作用与特…...

【单元测试】SpringBoot
【单元测试】SpringBoot 1. 为什么单元测试很重要?‼️ 从前,有一个名叫小明的程序员,他非常聪明,但有一个致命的缺点:懒惰。小明的代码写得又快又好,但他总觉得单元测试是一件麻烦事,觉得代码…...

分布式搜索引擎ES-elasticsearch入门
1.分布式搜索引擎:luceneVS Solr VS Elasticsearch 什么是分布式搜索引擎 搜索引擎:数据源:数据库或者爬虫资源 分布式存储与搜索:多个节点组成的服务,提高扩展性(扩展成集群) 使用搜索引擎为搜索提供服务。可以从海量…...

TCP三次握手与四次挥手详解
1.什么是TCP TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的通信协议,属于互联网协议族(TCP/IP)的一部分。TCP 提供可靠的、顺序的、无差错的数据传输服务&…...
)
【Windows】操作系统之任务管理器(第一篇)
一、操作系统简介 Windows操作系统是由微软公司(Microsoft)开发的一款图形操作系统,它以其强大的功能和广泛的用户基础,成为了目前世界上用户使用最多、兼容性最强的操作系统之一。以下是关于Windows操作系统的详细介绍ÿ…...

图同构的必要条件
来源:离散数学...

Django获取request请求中的参数
支持 post put json_str request.body # 属性获取最原始的请求体数据 json_dict json.loads(json_str)# 将原始数据转成字典格式 json_dict.get("key", "默认值") # 获取数据参考 https://blog.csdn.net/user_san/article/details/109654028...

kotlin compose 实现应用内多语言切换(不重新打开App)
1. 示例图 2.具体实现 如何实现上述示例,且不需要重新打开App ①自定义 MainApplication 实现 Application ,定义两个变量: class MainApplication : Application() { object GlobalDpData { var language: String = "" var defaultLanguage: Strin…...
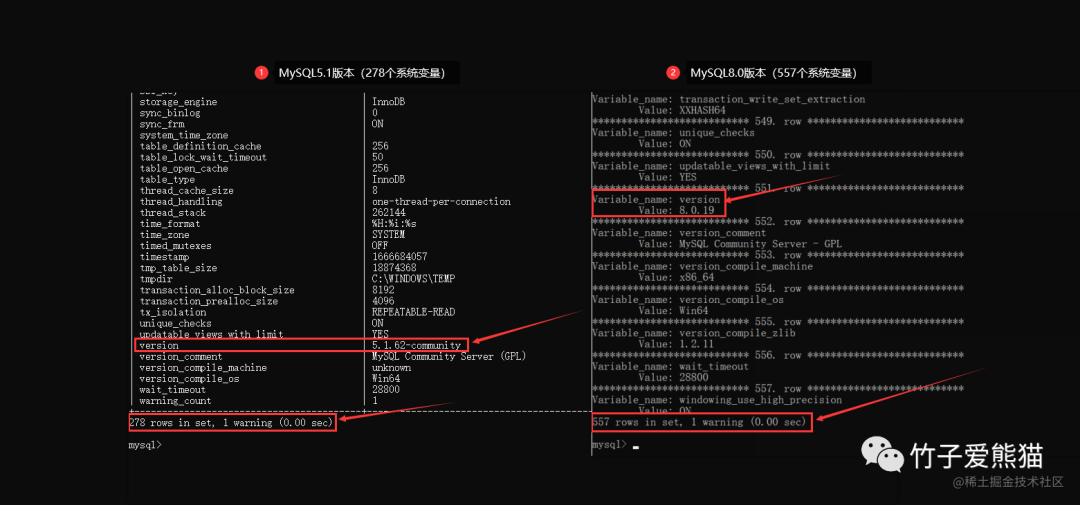
记录些MySQL题集(16)
MySQL 存储过程与触发器 一、初识MySQL的存储过程 Stored Procedure存储过程是数据库系统中一个十分重要的功能,使用存储过程可以大幅度缩短大SQL的响应时间,同时也可以提高数据库编程的灵活性。 存储过程是一组为了完成特定功能的SQL语句集合&#x…...

【算法基础】Dijkstra 算法
定义: g [ i ] [ j ] g[i][j] g[i][j] 表示 v i v_i vi 到 $v_j $的边权重,如果没有连接,则 g [ i ] [ j ] ∞ g[i][j] \infty g[i][j]∞ d i s [ i ] dis[i] dis[i] 表示 v k v_k vk 到节点 v i v_i vi 的最短长度, …...

使用 Flask 3 搭建问答平台(三):注册页面模板渲染
前言 前端文件下载 链接https://pan.baidu.com/s/1Ju5hhhhy5pcUMM7VS3S5YA?pwd6666%C2%A0 知识点 1. 在路由中渲染前端页面 2. 使用 JinJa 2 模板实现前端代码复用 一、auth.py from flask import render_templatebp.route(/register, methods[GET]) def register():re…...

pycharm如何debug for循环里面的错误值
一般debug时,在for循环里面的话,需要自己一步一步点。如果循环几百次那种就比较麻烦。此时可以采用try except的方式来解决 例子如下 #ptyhon debug for循环的代码 num[1,2,3,s,4] ans0 for i in num:try:ansiexcept:print(错误) print(ans) 结果如下&a…...

解决网页中的 video 标签在移动端浏览器(如百度访问网页)视频脱离文档流播放问题
问题现象 部分浏览器视频脱离文档流,滚动时,视频是悬浮出来,在顶部播放 解决方案 添加下列属性,可解决大部分浏览器的脱离文档流的问题 <videowebkit-playsinline""playsInlinex5-playsinlinet7-video-player-t…...

系统稳定性测试利器:Roast烤机工具原理与实践指南
1. 项目概述:一个为“烤”而生的开源工具最近在折腾一些自动化任务时,发现了一个挺有意思的开源项目,叫sumleo/roast。光看名字,你可能会联想到“烤肉”,但在程序员的世界里,这个“roast”可不是让你去烧烤…...

需求驱动设计:构建可追溯、高质量的FPGA/ASIC开发流程
1. 项目概述:为什么我们需要一场关于“需求驱动设计”的讨论?如果你是一名FPGA或ASIC的设计工程师、项目经理,或者正在向这个领域迈进,那么“项目延期”、“功能bug在流片前夜才被发现”、“需求变更导致架构推倒重来”这些场景&a…...

基于MCP协议与Docker为Claude Code构建Brave搜索服务器Argus
1. 项目概述:为Claude Code打造一个“全视之眼” 如果你和我一样,日常重度依赖Claude Code来辅助编程、查资料、写文档,那你一定遇到过这样的痛点:当Claude需要联网搜索时,要么得手动复制粘贴,要么得依赖一…...

跨工具技能同步:构建统一操作习惯的中间层架构与实践
1. 项目概述:一个跨工具技能同步的构想在数字工具爆炸式增长的今天,我们每个人几乎都活在一个“工具丛林”里。作为一名长期与各种生产力工具、开发环境、设计软件打交道的从业者,我深刻体会到一种割裂感:在A工具里熟练无比的快捷…...

别只会改设置!Chrome/Edge浏览器主页被劫持的三种隐藏原因与根治方法
浏览器主页劫持的深度攻防:从表象到根源的终极解决方案 每次打开浏览器,那个陌生的主页是否让你感到烦躁?大多数人会直奔浏览器设置试图修改,却发现根本无效。这背后隐藏着远比表面设置更复杂的机制——快捷方式参数注入、注册表钩…...

2026年中小企业性能测试平台:低成本易落地选型指南
中小企业在性能测试方面面临痛点:专业测试人员匮乏、预算有限、IT 架构相对简单、测试需求集中在基础接口与核心业务场景,无需复杂的企业级管控与大规模并发压测能力。因此,中小企业对性能测试平台的核心需求是:低成本、易落地、易…...

Box64:让你的ARM设备也能畅玩x86_64游戏的魔法引擎
Box64:让你的ARM设备也能畅玩x86_64游戏的魔法引擎 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 还在为树莓派…...

VSCode跨IDE代码搜索工具:原理、配置与高效开发实践
1. 项目概述:一个为多IDE开发者量身定制的代码搜索利器如果你和我一样,日常开发需要在 Visual Studio Code 和 JetBrains 系列 IDE(如 IntelliJ IDEA、PyCharm、WebStorm 等)之间频繁切换,那你一定对“代码搜索”这件事…...

抖音去水印免费版哪个好用?2026实测推荐与软件对比
抖音去水印免费版哪个好用?2026实测推荐与软件对比 刷到一条有意思的视频想保存下来发给朋友,下载后却发现左上角顶着一串"用户名"水印;好不容易找到一段适合做素材的内容,画面边缘那行字怎么裁都裁不干净。这几乎是每个…...

OpenCrab:面向中文开发者的开源项目导航与协作平台架构实践
1. 项目概述:一个面向中文开发者的开源螃蟹?第一次在GitHub上看到opencrab-cn/opencrab这个仓库名时,我愣了一下。OpenCrab?开源螃蟹?这名字听起来既有趣又让人摸不着头脑。点进去一看,发现这并非一个关于海…...