数据结构第35节 性能优化 算法的选择
算法的选择对于优化程序性能至关重要。不同的算法在时间复杂度、空间复杂度以及适用场景上有着明显的差异。下面我将结合具体的代码示例,来讲解几种常见的算法选择及其优化方法。
示例 1: 排序算法
场景描述:
假设我们需要对一个整数数组进行排序。
算法选择:
对于较大的数据集,快速排序通常是一个不错的选择,因为它在平均情况下的时间复杂度为 O(n log n)。但对于小数据集,插入排序可能更优,因为它的常数因子较小。
代码示例:
public class QuickSort {public static void quickSort(int[] arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}}private static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = (low - 1);for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
示例 2: 查找算法
场景描述:
假设我们需要在一个有序数组中查找特定元素。
算法选择:
对于有序数组,二分查找是一个很好的选择,其时间复杂度为 O(log n)。
代码示例:
public class BinarySearch {public static int binarySearch(int[] arr, int target) {int left = 0;int right = arr.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] == target) {return mid;} else if (arr[mid] < target) {left = mid + 1;} else {right = mid - 1;}}return -1;}
}
示例 3: 动态规划
场景描述:
假设我们要解决斐波那契数列问题。
算法选择:
递归解决斐波那契数列问题会导致大量的重复计算。使用动态规划,我们可以存储中间结果,避免重复计算,从而将时间复杂度降低到 O(n)。
代码示例:
public class FibonacciDP {public static int fibonacci(int n) {if (n <= 1) return n;int[] dp = new int[n + 1];dp[0] = 0;dp[1] = 1;for (int i = 2; i <= n; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}
}
示例 4: 图算法 - Dijkstra 算法
场景描述:
假设我们需要找到图中两点之间的最短路径。
算法选择:
Dijkstra 算法是一个非常有效的单源最短路径算法,其时间复杂度为 O((V+E)log V),其中 V 是顶点数,E 是边数。
代码示例:
import java.util.*;public class DijkstraAlgorithm {public static void dijkstra(Map<Integer, Map<Integer, Integer>> graph, int startNode) {int[] distances = new int[graph.size()];Arrays.fill(distances, Integer.MAX_VALUE);distances[startNode] = 0;PriorityQueue<int[]> pq = new PriorityQueue<>(Comparator.comparingInt(a -> a[1]));pq.offer(new int[]{startNode, 0});while (!pq.isEmpty()) {int[] current = pq.poll();int currentNode = current[0];int distanceToCurrent = current[1];if (distanceToCurrent > distances[currentNode]) continue;for (Map.Entry<Integer, Integer> entry : graph.get(currentNode).entrySet()) {int neighbor = entry.getKey();int weight = entry.getValue();int distanceToNeighbor = distanceToCurrent + weight;if (distanceToNeighbor < distances[neighbor]) {distances[neighbor] = distanceToNeighbor;pq.offer(new int[]{neighbor, distanceToNeighbor});}}}}
}
以上示例展示了如何根据不同的问题选择合适的算法,以及如何通过算法优化来提高程序的性能。每种算法都有其特定的适用场景和性能特征,因此在实际应用中,应根据具体情况灵活选择。
当然,我们可以进一步扩展上述算法的代码示例,添加更多实用的功能和增强代码的健壮性。接下来,我将为每一个示例增加额外的方法和注释,以帮助更好地理解和使用这些算法。
示例 1: 排序算法 - 快速排序扩展
我们将添加一个方法来检查数组是否已经排序,以及一个主函数来测试排序算法。
public class QuickSort {public static void quickSort(int[] arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}}private static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = (low - 1);for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static boolean isSorted(int[] arr) {for (int i = 0; i < arr.length - 1; i++) {if (arr[i] > arr[i + 1]) {return false;}}return true;}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};quickSort(arr, 0, arr.length - 1);System.out.println("Sorted array: ");for (int num : arr) {System.out.print(num + " ");}System.out.println("\nIs sorted? " + isSorted(arr));}
}
示例 2: 查找算法 - 二分查找扩展
我们将添加边界检查和异常处理,以确保数组不为空且是有序的。
public class BinarySearch {public static int binarySearch(int[] arr, int target) throws IllegalArgumentException {if (arr == null || arr.length == 0) {throw new IllegalArgumentException("Array is empty or null.");}if (!isSorted(arr)) {throw new IllegalArgumentException("Array must be sorted.");}int left = 0;int right = arr.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] == target) {return mid;} else if (arr[mid] < target) {left = mid + 1;} else {right = mid - 1;}}return -1;}private static boolean isSorted(int[] arr) {for (int i = 0; i < arr.length - 1; i++) {if (arr[i] > arr[i + 1]) {return false;}}return true;}public static void main(String[] args) {int[] arr = {1, 3, 5, 7, 9};int target = 5;try {int index = binarySearch(arr, target);System.out.println("Element found at index: " + index);} catch (IllegalArgumentException e) {System.out.println(e.getMessage());}}
}
示例 3: 动态规划 - 斐波那契数列扩展
我们将添加一个方法来计算斐波那契数列的所有项,并添加一个主函数来展示结果。
public class FibonacciDP {public static int fibonacci(int n) {if (n <= 1) return n;int[] dp = new int[n + 1];dp[0] = 0;dp[1] = 1;for (int i = 2; i <= n; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}public static int[] fibonacciSequence(int n) {int[] sequence = new int[n];for (int i = 0; i < n; i++) {sequence[i] = fibonacci(i);}return sequence;}public static void main(String[] args) {int n = 10;int[] sequence = fibonacciSequence(n);System.out.println("Fibonacci sequence up to " + n + ":");for (int num : sequence) {System.out.print(num + " ");}}
}
通过这些扩展,我们不仅增强了代码的功能性,还增加了异常处理和验证,使得代码更加健壮和实用。在实际开发中,这些额外的考虑对于确保程序的稳定性和正确性是非常重要的。
相关文章:

数据结构第35节 性能优化 算法的选择
算法的选择对于优化程序性能至关重要。不同的算法在时间复杂度、空间复杂度以及适用场景上有着明显的差异。下面我将结合具体的代码示例,来讲解几种常见的算法选择及其优化方法。 示例 1: 排序算法 场景描述: 假设我们需要对一个整数数组进行排序。 算法选择: …...
- 正态分布)
每天一个数据分析题(四百三十六)- 正态分布
X为服从正态分布的随机变量N(2, 9), 如果P(X>c)P(X<c), 则c的值为() A. 3 B. 2 C. 9 D. 2/3 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据分析专项练习题库 内容涵盖Python,SQL&…...

跟我学C++中级篇——虚函数的性能
一、虚函数性能 一般来说,面向对象的设计中,继承和多态是其中两个非常重要的特征。从使用的过程来看,一般应用到继承的,使用多态的可能性就非常大。而多态的实现有很多种, 但开发者通常认为的多态(动多态&…...

trl - 微调、对齐大模型的全栈工具
文章目录 一、关于 TRL亮点 二、安装1、Python包2、从源码安装3、存储库 三、命令行界面(CLI)四、如何使用1、SFTTrainer2、RewardTrainer3、PPOTrainer4、DPOTrainer 五、其它开发 & 贡献参考文献最近策略优化 PPO直接偏好优化 DPO 一、关于 TRL T…...

GuLi商城-商品服务-API-品牌管理-品牌分类关联与级联更新
先配置mybatis分页: 品牌管理增加模糊查询: 品牌管理关联分类: 一个品牌可以有多个分类 一个分类也可以有多个品牌 多对多的关系,用中间表 涉及的类: 方法都比较简单,就不贴代码了...

【linux】服务器ubuntu安装cuda11.0、cuDNN教程,简单易懂,包教包会
【linux】服务器ubuntu安装cuda11.0、cuDNN教程,简单易懂,包教包会 【创作不易,求点赞关注收藏】 文章目录 【linux】服务器ubuntu安装cuda11.0、cuDNN教程,简单易懂,包教包会一、版本情况介绍二、安装cuda1、到官网…...

在 Apifox 中如何高效批量添加接口请求 Body 参数?
在使用 Apifox 进行 API 设计时,你可能会遇到需要添加大量请求参数的情况。想象一下,如果一个接口需要几十甚至上百个参数,若要在接口的「修改文档」里一个个手动添加这些参数,那未免也太麻烦了,耗时且易出错。这时候&…...
专业PDF编辑工具:Acrobat Pro DC 2024.002.20933绿色版,提升你的工作效率!
软件介绍 Adobe Acrobat Pro DC 2024绿色便携版是一款功能强大的PDF编辑和转换软件,由Adobe公司推出。它是Acrobat XI系列的后续产品,提供了全新的用户界面和增强功能。用户可以借助这款软件将纸质文件转换为可编辑的电子文件,便于传输、签署…...
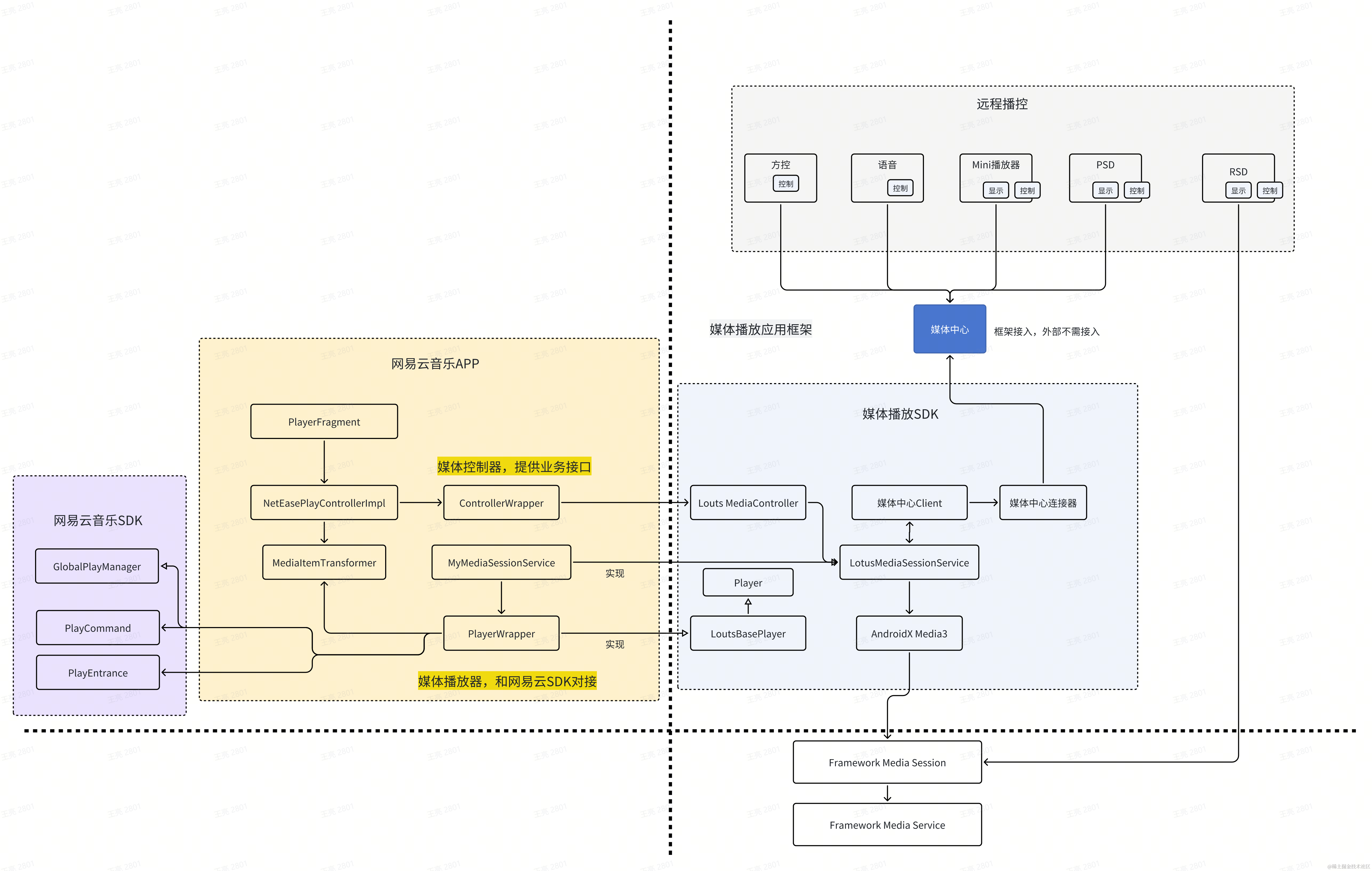
车载音视频App框架设计
简介 统一播放器提供媒体播放一致性的交互和视觉体验,减少各个媒体应用和场景独自开发的重复工作量,实现媒体播放链路的一致性,减少碎片化的Bug。本文面向应用开发者介绍如何快速接入媒体播放器。 主要功能: 新设计的统一播放U…...

StarRocks on AWS Graviton3,实现 50% 以上性价比提升
在数据时代,企业拥有前所未有的大量数据资产,但如何从海量数据中发掘价值成为挑战。数据分析凭借强大的分析能力,可从不同维度挖掘数据中蕴含的见解和规律,为企业战略决策提供依据。数据分析在营销、风险管控、产品优化等领域发挥…...
)
VUE中setup()
在Vue中,setup() 函数是Vue 3.0及更高版本引入的一个重要特性,它是Composition API的入口点。setup() 函数用于初始化组件的状态和逻辑,包括定义响应式数据、方法和生命周期钩子。以下是关于setup() 函数的详细解释: 1. 作用与特…...

【单元测试】SpringBoot
【单元测试】SpringBoot 1. 为什么单元测试很重要?‼️ 从前,有一个名叫小明的程序员,他非常聪明,但有一个致命的缺点:懒惰。小明的代码写得又快又好,但他总觉得单元测试是一件麻烦事,觉得代码…...

分布式搜索引擎ES-elasticsearch入门
1.分布式搜索引擎:luceneVS Solr VS Elasticsearch 什么是分布式搜索引擎 搜索引擎:数据源:数据库或者爬虫资源 分布式存储与搜索:多个节点组成的服务,提高扩展性(扩展成集群) 使用搜索引擎为搜索提供服务。可以从海量…...

TCP三次握手与四次挥手详解
1.什么是TCP TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的通信协议,属于互联网协议族(TCP/IP)的一部分。TCP 提供可靠的、顺序的、无差错的数据传输服务&…...
)
【Windows】操作系统之任务管理器(第一篇)
一、操作系统简介 Windows操作系统是由微软公司(Microsoft)开发的一款图形操作系统,它以其强大的功能和广泛的用户基础,成为了目前世界上用户使用最多、兼容性最强的操作系统之一。以下是关于Windows操作系统的详细介绍ÿ…...

图同构的必要条件
来源:离散数学...

Django获取request请求中的参数
支持 post put json_str request.body # 属性获取最原始的请求体数据 json_dict json.loads(json_str)# 将原始数据转成字典格式 json_dict.get("key", "默认值") # 获取数据参考 https://blog.csdn.net/user_san/article/details/109654028...

kotlin compose 实现应用内多语言切换(不重新打开App)
1. 示例图 2.具体实现 如何实现上述示例,且不需要重新打开App ①自定义 MainApplication 实现 Application ,定义两个变量: class MainApplication : Application() { object GlobalDpData { var language: String = "" var defaultLanguage: Strin…...
记录些MySQL题集(16)
MySQL 存储过程与触发器 一、初识MySQL的存储过程 Stored Procedure存储过程是数据库系统中一个十分重要的功能,使用存储过程可以大幅度缩短大SQL的响应时间,同时也可以提高数据库编程的灵活性。 存储过程是一组为了完成特定功能的SQL语句集合&#x…...

【算法基础】Dijkstra 算法
定义: g [ i ] [ j ] g[i][j] g[i][j] 表示 v i v_i vi 到 $v_j $的边权重,如果没有连接,则 g [ i ] [ j ] ∞ g[i][j] \infty g[i][j]∞ d i s [ i ] dis[i] dis[i] 表示 v k v_k vk 到节点 v i v_i vi 的最短长度, …...

Sveltos:多集群Kubernetes应用分发与配置管理的核心利器
1. 项目概述:Sveltos,一个被低估的集群应用管理利器如果你和我一样,长期在多集群的Kubernetes环境中摸爬滚打,那你一定对“应用分发”这件事的复杂性深有体会。想象一下,你手头有几十甚至上百个集群,有的在…...

如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀
如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否厌倦了在多个窗口间切换查找笔记?是否经常忘记重要的待办事项&#x…...

从零构建现代Web音乐应用:技术选型、音频引擎与全栈实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫chemistwang/music-app。光看名字,你可能会觉得这又是一个“音乐播放器”,市面上类似的轮子已经多如牛毛了。但作为一个在前后端领域摸爬滚打多年的开发者,我习惯性…...

从玩具到工具:Dobot Magician桌面机械臂开箱与Blockly图形化编程初体验
从玩具到工具:Dobot Magician桌面机械臂开箱与Blockly图形化编程初体验 第一次见到Dobot Magician时,它安静地躺在包装箱里,像一件精致的工业艺术品。作为一款定位教育和个人创客市场的桌面级机械臂,它的价格只有工业机械臂的零头…...

Nodejs服务端应用接入Taotoken多模型API指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs服务端应用接入Taotoken多模型API指南 对于Node.js后端开发者而言,将大模型能力集成到Web服务或API中࿰…...

嵌入式视觉成本降至百元级:技术民主化如何重塑工业物联网应用
1. 工业物联网与嵌入式视觉:从昂贵壁垒到百元级应用的演进 提到物联网,很多人脑子里蹦出来的可能是家里的智能音箱、手腕上的健康手环,或者能远程控制的冰箱。没错,消费和医疗领域确实是物联网最显眼的舞台。但作为一名在工业自动…...

面壁智能开源端侧多模态大模型MiniCPM-V 4.6,性能登顶同尺寸榜首,降低开发门槛
【导语:5月13日,面壁智能联合清华大学与OpenBMB开源社区,发布并开源新一代端侧多模态大模型MiniCPM-V 4.6。该模型以轻量级参数实现性能与效率突破,在评测中超越竞品,还降低了运行内存需求和计算成本,支持多…...

OpenCart安全审计实战:静态代码扫描与核心漏洞修复指南
1. 项目概述与核心价值最近在整理一个基于OpenCart的电商项目时,客户提出了一个非常具体且关键的需求:需要对整个系统的安全性进行一次全面的审计。这不仅仅是运行一个自动化扫描工具那么简单,客户希望我们能深入代码层面,检查是否…...

【Git Graph】 全解析:把Git提交历史玩明白的开发者神器
写在前面:无论是个人开发还是团队协作,Git早已是开发者的标配工具。但90%的开发者都踩过同一个Git的坑:对着命令行里密密麻麻的提交记录发呆,看不懂多分支的分叉与合并流向,想回滚版本却找不到对应的commit,…...
结合长短期记忆网络(LSTM)进行股票价格预测(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你)
项目介绍 MATLAB实现基于BMA-LSTM 贝叶斯模型平均(BMA)结合长短期记忆网络(LSTM)进行股票价格预测(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你
MATLAB实现基于BMA-LSTM 贝叶斯模型平均(BMA)结合长短期记忆网络(LSTM)进行股票价格预测的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面…...