Spark中的JOIN机制
Spark中的JOIN机制
- 1、Hash Join概述
- 2、影响JOIN的因素
- 3、Spark中的JOIN机制
- 3.1、Shuffle Hash Join
- 3.2、Broadcast Hash Join
- 3.3、Sort Merge Join
- 3.4、Cartesian Product Join
- 3.5、Broadcast Nested Loop Join
- 4、Spark中的JOIN策略
- 5、Spark JOIN机制与策略总结
- 5.1、Spark中的JOIN机制与策略总结
- 5.2、Broadcast Hash Join与Broadcast Nested Loop Join的区别
1、Hash Join概述
Apache Spark共提供了五种JOIN机制,其中常用的有三种:Shuffle Hash Join、Broadcast Hash Join及Sort Merge Join,它们都基于Hash Join,只不过需要在Hash Join前后进行Shuffle、Broadcast或Sort
实际上,Hash Join算法来自于传统数据库,而Shuffle、Broadcast和Sort是大数据(数据仓库)在分布式场景下两者结合的产物。因此,我们也说大数据(数据仓库)是由传统数据库发展而来的
通常情况下,Hash Join使用两个表中较小的表在内存中建立以Join Key为Key的哈希/散列表(Hash Table),然后扫描较大的表,同样对大表Join Key进行Hash后探测哈希/散列表,找出与哈希/散列表匹配的行
Hash Join主要分为两个阶段:建立阶段(Build Phase)和探测阶段(Probe Phase)
- Bulid Phase:较小的表被构建成以Join Key为Key的Hash Table,较小的表也称Build Table
- Probe Phase:扫描较大表的行并计算Join Key的哈希值,与Build Table哈希表比对,若相同则进行JOIN,较大的表也称Probe Table
值得注意的是,Hash Join适用于较小的表完全可以放于内存的情况,如果表较大,无法构造在内存中,则优化器会将它分成若干个Partition,将不能放入内存的部分写入磁盘,此时会多一个写的代价,I/O性能差
Apache Spark将参与JOIN的两张表抽象为流式遍历表(StreamIter)和查找表(BuildIter),通常StreamIter为大表,BuildIter为小表,这是由Spark根据JOIN策略自动决定的。对于每条来自StreamIter的记录,都要去BuildIter中查找匹配的记录
2、影响JOIN的因素
影响JOIN性能和JOIN结果的因素主要包括:数据集的大小、JOIN的连接条件以及JOIN的连接类型
1)数据集的大小
参与JOIN的数据集大小会直接影响JOIN操作的执行效率。同样,也会影响Spark JOIN机制的选择
2)JOIN的连接条件
JOIN的条件涉及字段之间的逻辑比较关系。根据JOIN的条件,JOIN可分为两大类:等值连接和非等值连接
- 等值连接:涉及字段之间一个或多个必须同时满足的相等条件(运算连接符为
=) - 非等值连接:涉及字段之间一个或多个必须同时满足的非相等条件(运算连接符不为
=)
3)JOIN的连接类型
在输入数据集的记录之间应用连接条件之后,JOIN类型会影响JOIN操作的结果。Spark主要有以下几种JOIN类型:
- 内连接(Inner Join):返回连接条件都匹配的记录
- 外连接(Outer Join):分为左外连接、右外链接和全外连接
- 交叉连接(Cross Join):交叉连接返回两个表的笛卡尔乘积
- 半/反连接(Semi/Anti Join):返回匹配/不匹配右表的左表数据
3、Spark中的JOIN机制
Spark共提供了五种JOIN机制来执行具体的JOIN操作:
- Shuffle Hash Join
- Broadcast Hash Join
- Sort Merge Join
- Cartesian Product Join
- Broadcast Nested Loop Join
3.1、Shuffle Hash Join
当要JOIN的表数据量较大时,一般选择Shuffle Hash Join。这样可以将大表按照Join Key进行重分区,保证每个相同的Join Key都发送到同一个分区中

Shuffle Hash Join的基本步骤如下:
- Shuffle阶段:对于两张参与JOIN的表,分别根据Join Key进行重分区,该过程会涉及Shuffle,保证Join Key值相同的记录被分到同一个分区
- Hash Join阶段:对于每个Shuffle Read分区,会将分区中较小表(BuildIter)构建成一个Hash Table放入内存,然后根据Join Key与较大的表记录进行匹配
Shuffle Hash Join的条件与特点如下:
- BuildIter的总体估计大小超过
spark.sql.autoBroadcastJoinThreshold(default 10MB)设置的值,即不满足Broadcast Hash Join条件 - 仅支持等值连接,且参数
spark.sql.join.preferSortMergeJoin(default true)需要设置为false,即不满足Sort Merge Join条件(Join Key不需要排序) - 支持除了全外连接(Full Outer Join)外的所有JOIN类型,对于Full Outer Join,需要建立双向Hash Table,代价太大,因此Full Outer Join默认都是基于Sort Merge Join来实现
- 需要对小表构建Hash Table,属于内存密集型操作,如果构建Hash Table的一侧数据较大,可能会造成数据倾斜和OOM
- StreamIter的大小是BuildIter的三倍以上
Shuffle Hash Join:Shuffle会带来较多的网络I/O开销,因此性能较差。同时,在Executor的内存使用方面,如果Executor的数量足够多,每个分区处理的数据量可以控制到比较小
3.2、Broadcast H
相关文章:
Spark中的JOIN机制
Spark中的JOIN机制 1、Hash Join概述2、影响JOIN的因素3、Spark中的JOIN机制3.1、Shuffle Hash Join3.2、Broadcast Hash Join3.3、Sort Merge Join3.4、Cartesian Product Join3.5、Broadcast Nested Loop Join4、Spark中的JOIN策略5、Spark JOIN机制与策略总结5.1、Spark中的…...

WebRTC QOS方法十三.1(TimestampExtrapolator接收时间预估)
一、背景介绍 虽然我们可通过时间戳的差值和采样率计算出发送端视频帧的发送节奏,但是由于网络延迟、抖动、丢包,仅知道视频发送端的发送节奏是明显不够的。我们还需要评估出视频接收端的视频帧的接收节奏,然后进行适当平滑,保证…...

深入了解 GCC
GCC,全称 GNU Compiler Collection,是 GNU 项目的一部分,是一个功能强大且广泛使用的编译器套件。它支持多种编程语言,包括 C、C、Fortran、Java、Ada 和 Go。GCC 具有高度的可移植性,几乎可以在所有现代计算机体系结构…...

vscode 打开远程bug vscode Failed to parse remote port from server output
vscode 打开远程bug vscode Failed to parse remote port from server output 原因如图: 解决:...
前端组件化技术实践:Vue自定义顶部导航栏组件的探索
摘要 随着前端技术的飞速发展,组件化开发已成为提高开发效率、降低维护成本的关键手段。本文将以Vue自定义顶部导航栏组件为例,深入探讨前端组件化开发的实践过程、优势以及面临的挑战,旨在为广大前端开发者提供有价值的参考和启示。 一、引…...

PyTorch Autograd内部实现
原文: 克補 爆炸篇 25s (youtube.com) 必应视频 (bing.com)https://www.bing.com/videos/riverview/relatedvideo?&qPyTorchautograd&qpvtPyTorchautograd&mid1B8AD76943EFADD541E01B8AD76943EFADD541E0&&FORMVRDGAR 前面只要有一个node的re…...

微信小程序 vant-weapp的 SwipeCell 滑动单元格 van-swipe-cell 滑动单元格不显示 和 样式问题 滑动后删除样式不显示
在微信小程序开发过程中 遇到个坑 此处引用 swipeCell 组件 刚开始是组件不显示 然后又遇到样式不生效 首先排除问题 是否在.json文件中引入了组件 {"usingComponents": {"van-swipe-cell": "vant/weapp/swipe-cell/index","van-cell-gro…...

3.4、matlab实现SGM/BM/SAD立体匹配算法计算视差图
1、matlab实现SGM/BM/SAD立体匹配算法计算视差图简介 SGM(Semi-Global Matching)、BM(Block Matching)和SAD(Sum of Absolute Differences)都是用于计算立体匹配(Stereo Matching)的…...

【瑞吉外卖 | day07】移动端菜品展示、购物车、下单
文章目录 瑞吉外卖 — day71. 导入用户地址簿相关功能代码1.1 需求分析1.2 数据模型1.3 代码开发 2. 菜品展示2.1 需求分析2.2 代码开发 3. 购物车3.1 需求分析3.2 数据模型3.3 代码开发 4. 下单4.1 需求分析4.2 数据模型4.3 代码开发 瑞吉外卖 — day7 移动端相关业务功能 —…...
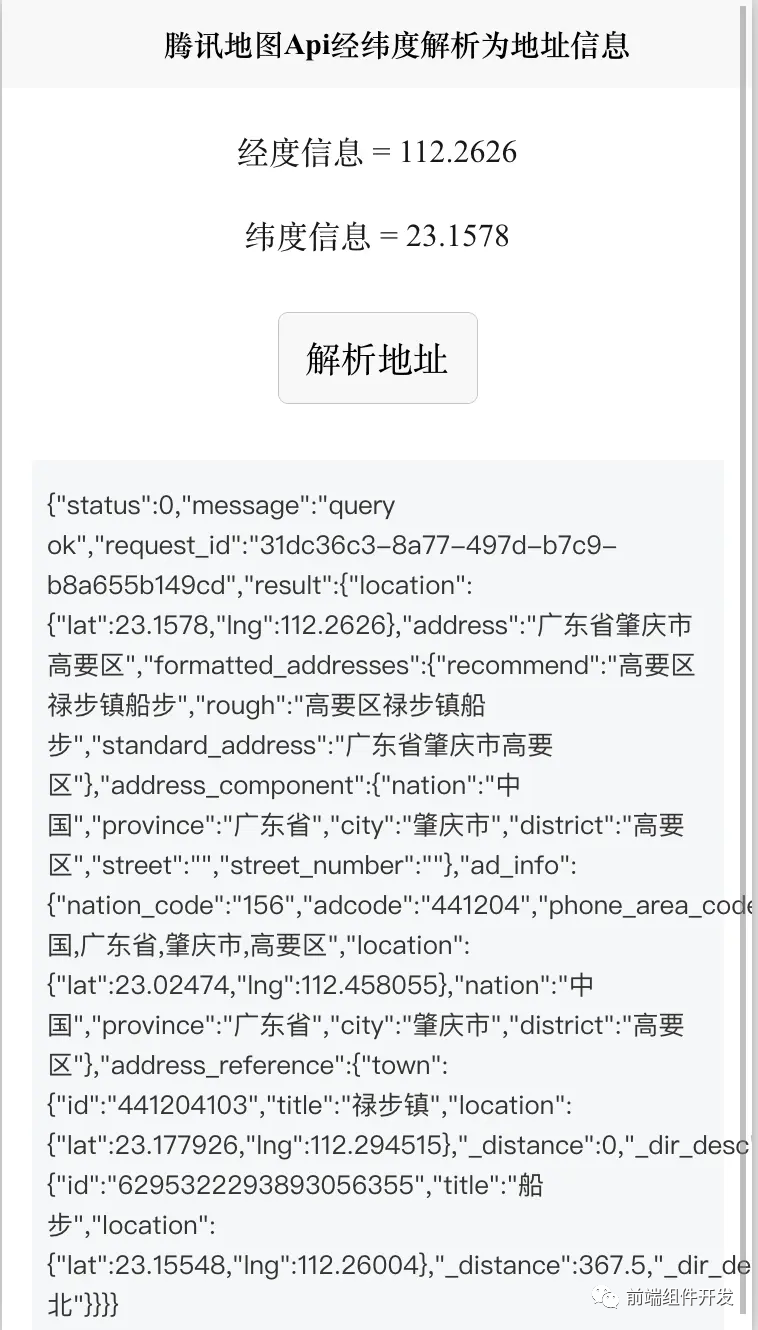
前端Vue项目中腾讯地图SDK集成:经纬度与地址信息解析的实践
在前端开发中,我们经常需要将经纬度信息转化为具体的地址信息,这对于定位、地图展示等功能至关重要。Vue作为现代前端框架的代表,其组件化开发的特性使得我们能够更高效地实现这一功能。本文将介绍如何在Vue项目中集成腾讯地图SDK,…...

鸿蒙开发StableDiffusion绘画应用
Stable Diffusion AI绘画 基于鸿蒙开发的Stable Diffusion应用。 Stable Diffusion Server后端代码 Stable Diffusion 鸿蒙应用代码 AI绘画 使用Axios发送post网络请求访问AI绘画服务器 api ,支持生成图片保存到手机相册。后端服务是基于flaskStable Diffusion …...

华为OD机考题(HJ61 放苹果)
前言 经过前期的数据结构和算法学习,开始以OD机考题作为练习题,继续加强下熟练程度。 描述 把m个同样的苹果放在n个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法? 注意:如果有7个苹果和3…...

浅谈Visual Studio 2022
Visual Studio 2022(VS2022)提供了众多强大的功能和改进,旨在提高开发者的效率和体验。以下是一些关键功能的概述:12 64位支持:VS2022的64位版本不再受内存限制困扰,主devenv.exe进程不再局限于4GB…...
spark 动态资源分配dynamicAllocation
动态资源分配,主要是spark在运行中可以相对合理的分配资源。 初始申请的资源远超实际需要,减少executor初始申请的资源比实际需要少很多,增多executorSpark运行多个job,这些job所需资源有的多有的少,动态调整executor…...

【C语言ffmpeg】打开第一个视频
文章目录 前言须知ffmpeg打开文件基本流程图ffmpeg打开媒体文件AVFormatContext *avformat_alloc_context(void);AVFormatContext 成员变量及其作用AVInputFormat *iformatAVOutputFormat *oformatvoid *priv_dataAVIOContext *pbunsigned int nb_streamsAVStream **streamscha…...

【Langchain大语言模型开发教程】模型、提示和解析
🔗 LangChain for LLM Application Development - DeepLearning.AI 学习目标 1、使用Langchain实例化一个LLM的接口 2、 使用Langchain的模板功能,将需要改动的部分抽象成变量,在具体的情况下替换成需要的内容,来达到模板复用效…...

Flutter 中的基本数据类型:num、int 和 double
在 Dart 编程语言中,数值类型的基础是 num,而 int 和 double 则是 num 的子类型。在开发 Flutter 应用时,理解这三者的区别和使用场景是非常重要的。本文将详细介绍 num、int 和 double 的定义及其使用区别。 num num 是 Dart 中的数值类型…...
基于Python+Django,开发的一个在线教育系统
一、项目简介 使用Python的web框架Django进行开发的一个在线教育系统! 二、所需要的环境与组件 Python3.6 Django1.11.7 Pymysql Mysql pure_pagination DjangoUeditor captcha xadmin crispy_forms 三、安装 1. 下载项目后进入项目目录cd Online-educ…...

密码学原理精解【9】
这里写目录标题 迭代密码概述SPN具体算法过程SPN算法基本步骤举例说明注意 轮换-置换网络一、定义与概述二、核心组件三、加密过程四、应用实例五、总结 轮函数理论定义与作用特点与性质应用实例总结 迭代密码理论定义与原理特点与优势应用场景示例发展趋势 AES特点概述一、算法…...
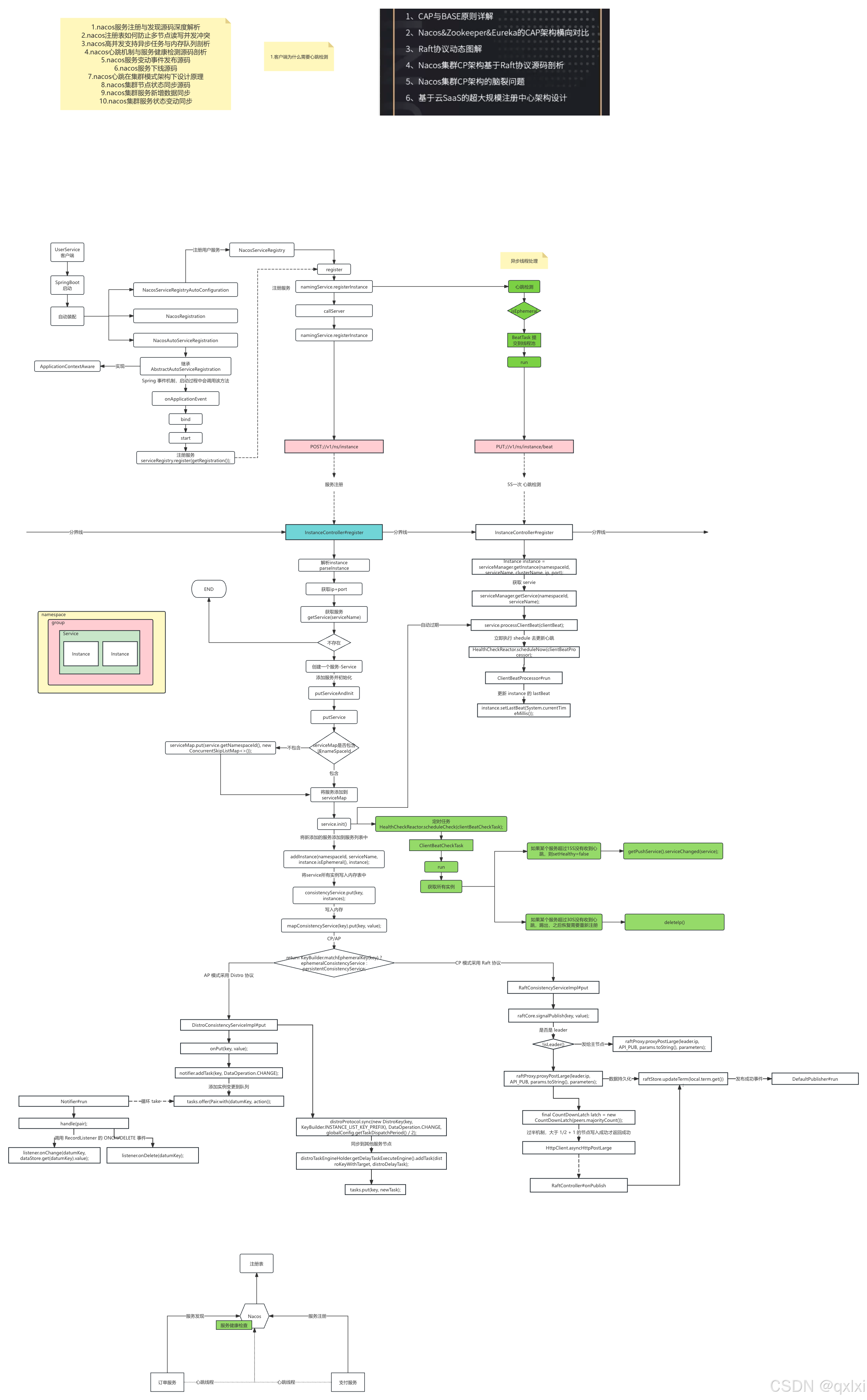
【Nacos】Nacos服务注册与发现 心跳检测机制源码解析
在前两篇文章,介绍了springboot的自动配置原理,而nacos的服务注册就依赖自动配置原理。 Nacos Nacos核心功能点 服务注册 :Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端…...

物联网设备安全:硅基硬件防护方案解析
1. 物联网设备安全现状与挑战在智能家居、工业自动化、医疗监测等领域,物联网设备正以惊人的速度普及。根据IDC的调研数据,超过27%的企业在选择物联网供应商时将安全能力作为首要考量标准。然而现实情况是,大多数物联网设备仍在使用软件层面的…...

观察Taotoken在多模型并发请求下的稳定性与响应表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型并发请求下的稳定性与响应表现 在实际业务开发中,我们常常需要同时调用多个不同的大模型来处理不…...

半导体行业数据解析:销售额与资本支出双高增长背后的逻辑
1. 行业数据深度解析:半导体销售额与资本支出的双高增长最近和几个在晶圆厂和设计公司工作的朋友聊天,大家不约而同地提到了一个词:“忙疯了”。订单排到明年,产线24小时连轴转,连带着上游的设备商和材料供应商都跟着“…...

跨平台的Web应用快速开发框架
跨平台的Web应用快速开发框架。该框架提供了一套标准化的项目结构规范、统一的API接口命名规则、规范化的前后端代码,支持基于同一套设计规范Python(Flask/Django)、PHP、Java(SpringBoot/SSM)等多种后端语言代码 &…...

从DP-V0到DP-V2:一文讲透Profibus-DP三大版本的核心差异与工业现场选型建议
从DP-V0到DP-V2:Profibus-DP三大版本的核心差异与工业现场选型指南 在工业自动化领域,实时通信协议的选型往往直接决定生产线的响应速度、诊断能力和系统扩展性。作为制造业自动化系统中应用最广泛的现场总线之一,Profibus-DP历经三次重大版本…...

工程师创意竞赛全流程策划:从社区激活到公平投票的实战指南
1. 项目概述:一场别开生面的工程师创意竞赛又到了二月底,这意味着我们年初启动的那个“独轮车”图片配文竞赛,终于要进入最激动人心的投票环节了。我记得很清楚,那是2012年2月初,编辑部觉得冬天太沉闷,想找…...

【Midjourney Holga风格权威调参手册】:基于1,843组实测Prompt的色偏校准模型与动态暗角衰减公式
更多请点击: https://intelliparadigm.com 第一章:Holga风格的视觉基因解码与Midjourney适配原理 Holga相机以其塑料镜头、不可控漏光、边缘暗角与柔和色散著称,构成了一套独特的“模拟故障美学”语言。将这种物理成像缺陷转化为AI生成语义&…...

DownKyi终极指南:简单快速获取B站8K超高清视频的完整解决方案
DownKyi终极指南:简单快速获取B站8K超高清视频的完整解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等…...

【仿真实战】AnyLogic地铁站客流仿真:从零搭建带安检与限流的多层车站模型
1. 从零开始搭建地铁站仿真模型 第一次接触AnyLogic做地铁站客流仿真时,我完全被各种模块和参数搞晕了。后来在几个实际项目中摸爬滚打,终于总结出一套小白也能快速上手的方法。这次我们就来搭建一个包含安检区和限流措施的多层地铁站模型,整…...

NetApp FAS FC SAN存储替换实战:从HP MSA到ONTAP的平滑迁移
1. 项目背景与环境摸底 这次遇到的存储替换项目挺典型的——客户原先用的是HP MSA系列SAN存储,现在要升级到NetApp FAS2750全闪存阵列。现场环境是标准的VMware虚拟化平台,通过FC协议连接存储。说实话,第一次看到旧存储配置时我就发现几个隐患…...