pyspark使用 graphframes创建和查询图的方法
1、安装graphframes的步骤
1.1 查看 spark 和 scala版本
在终端输入: spark-shell --version 查看spark 和scala版本

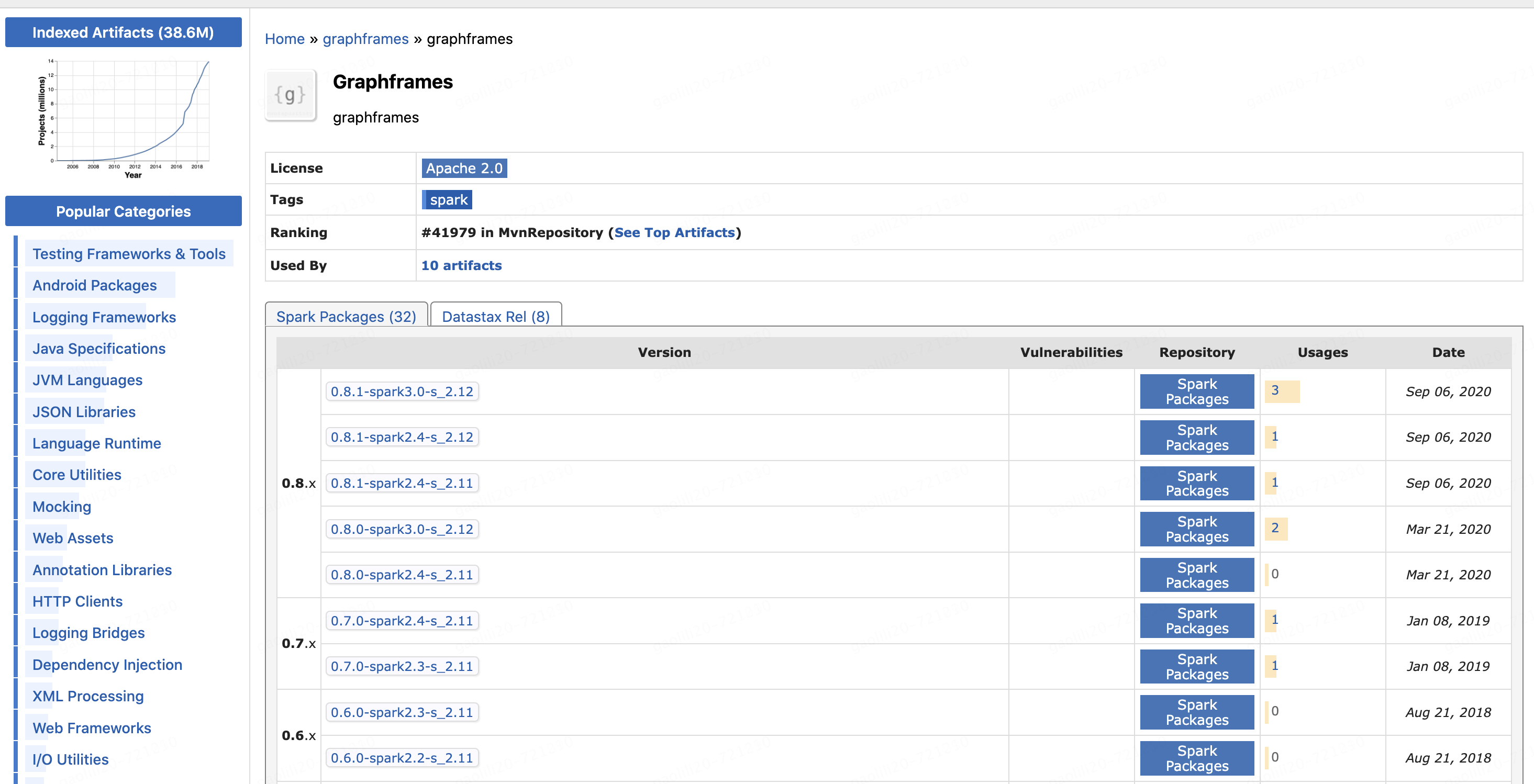
1.2 在maven库中下载对应版本的graphframes
https://mvnrepository.com/artifact/graphframes/graphframes
我这里需要的是spark 2.4 scala 2.11版本
https://mvnrepository.com/artifact/graphframes/graphframes/0.8.0-spark2.4-s_2.11
1.3 在pyspark的环境中配置graphframe的jar包
os.environ['PYSPARK_PYTHON'] = 'Python3.7/bin/python'
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars graphframes-0.8.1-spark2.4-s_2.11.jar pyspark-shell'spark = SparkSession \.builder \.appName("read_data") \.config('spark.pyspark.python', 'Python3.7/bin/python') \.config('spark.yarn.dist.archives', 'hdfs://ns62007/user/dmc_adm/_PYSPARK_ENV/Python3.7.zip#Python3.7') \.config('spark.executorEnv.PYSPARK_PYTHON', 'Python3.7/bin/python') \.config('spark.sql.autoBroadcastJoinThreshold', '-1') \.enableHiveSupport() \.getOrCreate()spark.sparkContext.addPyFile('graphframes-0.8.1-spark2.4-s_2.11.jar')2、导入GraphFrame创建图
2.1 导入包使用
from graphframes import GraphFrame2.2 创建图的例子
from pyspark.sql.types import *
import pandas as pd
from graphframes import GraphFrame#创建图的方法1
v = spark.createDataFrame([("a", "Alice", 34),("b", "Bob", 36),("c", "Charlie", 30),
], ["id", "name", "age"])# Create an Edge DataFrame with "src" and "dst" columns
e = spark.createDataFrame([("a", "b", "friend"),("b", "c", "follow"),("c", "b", "follow"),
], ["src", "dst", "relationship"])
# Create a GraphFrame
g = GraphFrame(v, e)# Query: Get in-degree of each vertex.
g.inDegrees.show()

也可以简单化顶点和边:
#创建图的方法2
edges_df= spark.createDataFrame([("a", "b"),("b", "c"),("c", "b"),
], ["src", "dst"])
nodes_df=spark.createDataFrame([(1, "a"),(2, "b"),(3, "c")
], ["num","id"])graph=GraphFrame(nodes_df, edges_df)
graph.inDegrees.show()
3、使用GraphFrame查看图
3.1 找出age属性最小的顶点
# 你可以像使用 dataframe一样来使用 graphframe!!!!
g.vertices.groupBy().min("age").show()

3.2 过滤顶点和边,创建子图
# 直接用filterVertices和filterEdges过滤顶点和边用来创建子图
g1.filterVertices("age > 30").filterEdges("relationship = 'friend'").vertices.show()
g1.filterVertices("age > 30").filterEdges("relationship = 'friend'").dropIsolatedVertices().vertices.show()
3.3 也可以像dataframe一样过滤顶点和边
g.vertices.where(col("id")=="a").show()
print(g.vertices.where(col("age")==34).count())g.edges.show()
g.edges.where(col("src")>col("dst")).show()
3.4 路径搜索和筛选
# 路径搜索
paths = g.find("(a)-[e]->(b)")
paths.show()# 路径搜索 和筛选
path = g.find("(a)-[e]->(b)")\.filter("e.relationship = 'follow'")\.filter("a.age < b.age")
path.show()
3.5 计算BFS
# 计算bfs
res = g1.bfs("id='b'","id<>'b'")
res.select([column for column in res.columns]).show()
3.6 查看关系数据集中的列
# 选择关系数据集中的列
e2 = paths.select("e.src", "e.dst", "e.relationship")
e2.show()

3.7 使用顶点和边的集合构造子图
# 使用顶点和边的集合构造子图
g2 = GraphFrame(g.vertices, e2)
g2.vertices.show()
g2.edges.show()

3.8 统计符合条件的边和顶点个数
# Query: Count the number of "follow" connections in the graph.
t = g.edges.filter("relationship = 'follow'").count()
print(t)print(g.vertices.where(col("age")==34).count())3.9 计算每个节点的入度和出度
from pyspark.sql import functions as F
# 计算每个节点的入度和出度
in_degrees = g.inDegrees
out_degrees = g.outDegrees# 找到具有最大入度的节点
max_in_degree = in_degrees.agg(F.max("inDegree")).head()[0]
node_with_max_in_degree = in_degrees.filter(in_degrees.inDegree == max_in_degree).select("id")# 找到具有最大出度的节点
max_out_degree = out_degrees.agg(F.max("outDegree")).head()[0]
node_with_max_out_degree = out_degrees.filter(out_degrees.outDegree == max_out_degree).select("id")# 打印结果
node_with_max_in_degree.show()
node_with_max_out_degree.show()

3.10 计算顶点的pagerank
# Run PageRank algorithm, and show results.
results = g.pageRank(resetProbability=0.01, maxIter=5)
results.vertices.select("id", "pagerank").show()
results.vertices.show()
4、graphframes和spark 的graphX的区别
GraphX - Spark 2.3.0 Documentation
GraphFrames,该类库是构建在Spark DataFrames之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。GraphX基于RDD API,不支持Python API; 但GraphFrame基于DataFrame,并且支持Python API。
目前GraphFrames还未集成到Spark中,而是作为单独的项目存在。GraphFrames遵循与Spark相同的代码质量标准,并且它是针对大量Spark版本进行交叉编译和发布的。
与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,有下面几方面的优势:
1、统一的 API: 为Python、Java和Scala三种语言提供了统一的接口,这是Python和Java首次能够使用GraphX的全部算法。
2、强大的查询功能:GraphFrames使得用户可以构建与Spark SQL以及DataFrame类似的查询语句。
3、图的存储和读取:GraphFrames与DataFrame的数据源完全兼容,支持以Parquet、JSON以及CSV等格式完成图的存储或读取。
在GraphFrames中图的顶点(Vertex)和边(Edge)都是以DataFrame形式存储的,所以一个图的所有信息都能够完整保存。
4、GraphFrames可以实现与GraphX的完美集成。两者之间相互转换时不会丢失任何数据。
5、书:图算法《Graph Algorithm》
O'Reilly free ebook《Graph Algorithm - Practical Examples in Apache Spark and Neo4j》
作者 Mark Needham & Amy E. Hodler
书旨在围绕这些重要的图分析类型,包括算法、概念、算法在机器学习上的实际应用,来扩展我们的知识和能力。从基本概念到基本算法,从处理平台和实际用例,作者为图的精彩世界编制了一份具有启发性和说明性的指南。
《图算法》第四章-1 路径查找和图搜索算法
相关文章:
pyspark使用 graphframes创建和查询图的方法
1、安装graphframes的步骤 1.1 查看 spark 和 scala版本 在终端输入: spark-shell --version 查看spark 和scala版本 1.2 在maven库中下载对应版本的graphframes https://mvnrepository.com/artifact/graphframes/graphframes 我这里需要的是spark 2.4 scala 2.…...

【web】-flask-简单的计算题(不简单)
打开页面是这样的 初步思路,打开F12,查看头,都发现了这个表达式的base64加密字符串。编写脚本提交答案,发现不对; 无奈点开source发现源代码,是flask,初始化表达式,获取提交的表达式࿰…...

Apache Sqoop
Apache Sqoop是一个开源工具,用于在Apache Hadoop和关系型数据库(如MySQL、Oracle、PostgreSQL等)之间进行数据的批量传输。其主要功能包括: 1. 数据导入:从关系型数据库(如MySQL、Oracle等)中将…...

【Python】TensorFlow介绍与实战
TensorFlow介绍与使用 1. 前言 在人工智能领域的快速发展中,深度学习框架的选择至关重要。TensorFlow 以其灵活性和强大的社区支持,成为了许多研究者和开发者的首选。本文将进一步扩展对 TensorFlow 的介绍,包括其优势、应用场景以及在最新…...

第100+16步 ChatGPT学习:R实现Xgboost分类
基于R 4.2.2版本演示 一、写在前面 有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。 答曰:可!用GPT或者Kimi转一下就得了呗。 加上最近也没啥内容写了,就帮各位搬运一下吧。 二、R代码实现Xgboost分类 (…...

【操作系统】定时器(Timer)的实现
这里写目录标题 定时器一、定时器是什么二、标准库中的定时器三、实现定时器 定时器 一、定时器是什么 定时器也是软件开发中的⼀个重要组件.类似于⼀个"闹钟".达到⼀个设定的时间之后,就执行某个指定 好的代码. 定时器是⼀种实际开发中⾮常常用的组件. ⽐如⽹络通…...

鸿蒙Navigation路由能力汇总
基本使用步骤: 1、新增配置文件router_map: 2、在moudle.json5中添加刚才新增的router_map配置: 3、使用方法: 属性汇总: https://developer.huawei.com/consumer/cn/doc/harmonyos-references/ts-basic-compone…...

1:1公有云能力整体输出,腾讯云“七剑”下云端
【全球云观察 | 科技热点关注】 曾几何时,云计算技术的兴起,为千行万业的数字化创新带来了诸多新机遇,同时也催生了新产业新业态新模式,激发出高质量发展的科技新动能。很显然,如今的云创新已成为高质量发…...

【iOS】APP仿写——网易云音乐
网易云音乐 启动页发现定时器控制轮播图UIButtonConfiguration 发现换头像 我的总结 启动页 这里我的启动页是使用Xcode自带的启动功能,将图片放置在LaunchScreen中即可。这里也可以通过定时器控制,来实现启动的效果 效果图: 这里放一篇大…...

react 快速入门思维导图
在掌握了react中一下的几个步骤和语法,基本上就可以熟练的使用react了。 1、组件的使用。react创建组件主要是类组件和函数式组件,类组件有生命周期,而函数式组件没有。 2、jsx语法。react主要使用jsx语法,需要使用babel和webpa…...

微软研究人员为电子表格应用开发了专用人工智能LLM
微软的 Copilot 生成式人工智能助手现已成为该公司许多软件应用程序的一部分。其中包括 Excel 电子表格应用程序,用户可以在其中输入文本提示来帮助处理某些选项。微软的一组研究人员一直在研究一种新的人工智能大型语言模型,这种模型是专门为 Excel、Go…...

[算法题]两个链表的第一个公共结点
题目链接: 两个链表的第一个公共结点 图示: 两个链表如果长度一致, 那么两人同时一人走一步, 如果存在公共结点, 迟早会相遇, 但是如果长度不一致单存在公共结点, 两人同时一人走一步不会相遇, 此时定义两个变量, node1 和 node2, 这两个变量分别从 x1 和 x2 开始走, 当其走完…...

MySQL事务管理(上)
目录 前言 CURD不加控制,会有什么问题? CURD满足什么属性,能解决上述问题? 事务 什么是事务? 为什么会出现事务 事务的版本支持 事务提交方式 查看事务提交方式 改变 MySQL 的自动提交模式: 事务常见操作方式 前…...

HTML2048小游戏
源代码在效果图后面 效果图 源代码 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>2048 Game&l…...

为 android编译 luajit库、 交叉编译
时间:20200719 本机环境:iMac2017 macOS11.4 参考: 官方的文档:Use the NDK with other build systems 写在前边:交叉编译跟普通编译类似,无非是利用特殊的编译器、链接器生成动态或静态库; make 本质上是按照 Make…...

【音视频】音频重采样
文章目录 前言音频重采样的基本概念音频重采样的原因1. 设备兼容性2. 文件大小和带宽3. 音质优化4. 标准化和规范5. 多媒体同步6. 降低处理负载重采样的注意事项 总结 前言 音频重采样是指将音频文件的采样率转换成另一种采样率的过程。这在音频处理和传输中是一个常见且重要的…...

卷积神经网络学习问题总结
问题一: 深度学习中的损失函数和应用场景 回归任务: 均方误差函数(MSE)适用于回归任务,如预测房价、预测股票价格等。 import torch.nn as nn loss_fn nn.MSELoss() 分类任务: 交叉熵损失函数&…...

嵌入式面试总结
C语言中struct和union的区别 struct和union都是常见的复合结构。 结构体和联合体虽然都是由多个不同的数据类型成员组成的,但不同之处在于联合体中所有成员共用一块地址空间,即联合体只存放了一个被选中的成员,结构体中所有成员占用空间是累…...

超简单安装指定版本的clickhouse
超简单安装指定版本的clickhouse 命令执行shell脚本 idea连接 命令执行 参考官网 # 下载脚本 wget https://raw.githubusercontent.com/183461750/doc-record/d988dced891d70b23c153a3bbfecee67902a3757/middleware/data/clickhouse/clickhouse-install.sh # 执行安装脚本(中…...

FlowUs横向对比几款笔记应用的优势所在
FlowUs作为一个本土化的生产力工具,在中国市场的环境下相对于Notion有其独特的优势,尤其是在稳定性和模板适应性方面。 尽管Notion在笔记和生产力工具领域享有极高的声誉,拥有着诸多创新功能和强大的生态系统,但它并不一定适合每…...

如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器
如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

图解UART串口通信:从电平标准到数据帧的完整解析
1. UART串口通信基础:从物理层到协议层 第一次接触嵌入式开发时,我被UART这个名字唬住了——Universal Asynchronous Receiver/Transmitter(通用异步收发器),听起来像是某种高端设备。直到用USB转TTL模块点亮了第一个L…...

Redis_7_Streams与高可用集群实战
Redis 7.0 Streams与高可用集群部署实战 从消息队列到分布式架构,全面掌握Redis核心能力 前言 Redis不只是一个缓存数据库。Redis 5.0引入的Streams让它具备了消息队列的能力,Redis 7.0进一步增强了Streams的稳定性和性能。很多团队在用Kafka/RabbitMQ处理消息队列时,其实R…...

为什么你的ChatGPT生成帖文零互动?揭秘Instagram 2024算法对AI内容的3重隐性过滤机制
更多请点击: https://intelliparadigm.com 第一章:为什么你的ChatGPT生成帖文零互动?揭秘Instagram 2024算法对AI内容的3重隐性过滤机制 Instagram 2024年Q2核心算法更新引入了「人类意图验证层(HIVL)」,该…...

AirMapView自定义地图类型开发:扩展新的地图提供商完整指南 [特殊字符]️
AirMapView自定义地图类型开发:扩展新的地图提供商完整指南 🗺️ 【免费下载链接】AirMapView A view abstraction to provide a map user interface with various underlying map providers 项目地址: https://gitcode.com/gh_mirrors/ai/AirMapView …...

基于GitHub Webhook的自动化协作平台:Octopal架构设计与实现
1. 项目概述:一个面向开发者的开源协作平台最近在GitHub上看到一个挺有意思的项目,叫“pmbstyle/Octopal”。光看名字,你可能会联想到“Octopus”(章鱼)和“GitHub”(其吉祥物是章鱼猫Octocat)&…...

浏览器缓存揭秘:它什么时候“自动”生效?
🚀 浏览器缓存揭秘:它什么时候“自动”生效? 🤔 什么是浏览器缓存? 简单来说,浏览器缓存就是浏览器把下载过的资源(HTML, CSS, JS, 图片等)保存在本地硬盘或内存中。当再次请求相同…...

API淘宝关键词搜索:运用场所、使用方式及获客逻辑
在电商生态中,淘宝关键词搜索API是连接第三方系统与平台商品数据的核心桥梁。其核心价值在于通过标准化接口,精准、合规地获取关键词对应的商品、店铺及市场数据,为各类业务提供坚实的数据支撑。相较于传统爬虫,API调用具备合规性…...

W4A4量化技术:OSC框架如何实现高效LLM部署
1. OSC框架:硬件高效的W4A4量化革命在大型语言模型(LLM)部署领域,4-bit量化(W4A4)正成为突破算力瓶颈的关键技术。传统8-bit量化虽已成熟,但当我们将精度压缩至4-bit时,激活张量中的异常值(Outliers)会像"黑洞"般吞噬有…...

Git Conflict Resolution
1. 这篇文章解决什么问题? Git 冲突不是异常情况,而是多人协作和分支开发里的正常现象。 常见问题包括: 1. 为什么会产生冲突? 2. 冲突文件里的 <<<<<<<、、>>>>>>> 是什么?…...