python—爬虫爬取电影页面实例
下面是一个简单的爬虫实例,使用Python的requests库来发送HTTP请求,并使用lxml库来解析HTML页面内容。这个爬虫的目标是抓取一个电影网站,并提取每部电影的主义部分。
首先,确保你已经安装了requests和lxml库。如果没有安装,可以通过pip安装它们:
pip install lxml
安装好lxml库后,就可以在Python代码中通过from lxml import etree来导入etree模块,并使用它提供的各种功能。
然后,我们可以编写如下的爬虫脚本:
import reimport fake_useragent
import requests
from lxml import etreeif __name__ == '__main__':# UA伪装head = {"User-Agent": fake_useragent.UserAgent().random}fp = open("./douban", "w", encoding="utf8")# 1.urlfor i in range(0,250,25):url = "https://movie.douban.com/top250?start={i}&filter="# 2.发送请求response = requests.get(url, headers=head)# 3.获取想要的数据res_text = response.text# 4.数据解析tree = etree.HTML(res_text)# 定位所有的li标签li_list = tree.xpath("//ol[@class='grid_view']/li")for li in li_list:film_name = "".join(li.xpath(".//span[@class='title'][1]/text()"))director_actor_y_country_type = "".join(li.xpath(".//div[@class='bd']/p[1]/text()"))score = "".join(li.xpath(".//span[@class='rating_num']/text()"))quote = "".join(li.xpath(".//span[@class='inq']/text()"))new_str = director_actor_y_country_type.strip()y = re.match(r"([\s\S]+?)(\d+)(.*?)", new_str).group(2)country = new_str.rsplit("/")[-2].strip()types = new_str.rsplit("/")[-1].strip()director = re.match(r"导演: ([a-zA-Z\u4e00-\u9fa5·]+)(.*?)", new_str).group(1)try:actor = re.match(r"(.*?)主演: ([a-zA-Z\u4e00-\u9fa5·]+)(.*?)", new_str).group(2)except Exception as e:actor = "no"fp.write(film_name + "#" + y + "#" + country + "#" + types + "#" + director + "#" + actor + "#" + score + "#" + quote + "\n")print(film_name, score, quote, y, country, types, director)fp.close()这段代码是一个Python脚本,用于从豆瓣电影Top 250页面抓取电影信息,并将这些信息保存到本地文件中。下面是对代码的详细解释:
1.导入必要的库:
re: 用于正则表达式匹配。
fake_useragent: 用于生成随机的User-Agent,以模拟不同的浏览器访问,避免被网站识别为爬虫。
requests: 用于发送HTTP请求。
lxml.etree: 用于解析HTML文档,提取所需信息。
2.设置User-Agent:
使用fake_useragent.UserAgent().random生成一个随机的User-Agent,并存储在head字典中,作为HTTP请求头的一部分。
3.打开文件:
使用open(“./douban”, “w”, encoding=“utf8”)以写入模式打开(或创建)一个名为douban的文件,用于存储抓取的电影信息。
4.循环请求豆瓣电影Top 250页面:
通过循环,每次请求豆瓣电影Top 250页面的一个子集,start参数从0开始,每次增加25,直到250(但不包括250,因为range的结束值是开区间)。
5.发送HTTP请求:
使用requests.get(url, headers=head)发送GET请求,请求头中包含之前设置的User-Agent。
6.解析HTML文档:
使用etree.HTML(res_text)将响应的文本内容解析为HTML文档。
通过XPath表达式//ol[@class=‘grid_view’]/li定位所有包含电影信息的li标签。
7.提取电影信息:
遍历每个li标签,提取电影名称、导演/演员/年份/国家/类型、评分、简介等信息。
使用正则表达式处理director_actor_y_country_type字符串,以提取年份、国家和类型。
注意,这里对演员信息的提取使用了异常处理,如果正则表达式匹配失败(例如,某些电影信息中可能没有演员信息),则将演员设置为"no"。
8.写入文件:
将提取的电影信息拼接成字符串,并写入之前打开的文件中,每条信息占一行。
9.关闭文件:
循环结束后,关闭文件。

这里我们截取了部分输出结果的信息,可以看到已经成功爬取电影网站中的部分信息,这个简单的爬虫示例展示了如何发送HTTP请求、解析HTML内容以及提取所需信息的基本流程。
相关文章:
python—爬虫爬取电影页面实例
下面是一个简单的爬虫实例,使用Python的requests库来发送HTTP请求,并使用lxml库来解析HTML页面内容。这个爬虫的目标是抓取一个电影网站,并提取每部电影的主义部分。 首先,确保你已经安装了requests和lxml库。如果没有安装&#x…...

实现图片拖拽和缩小放大功能。
1. 前言 不知道各位前端小伙伴蓝湖使用的多不多,反正我是经常在用,ui将原型图设计好后上传至蓝湖,前端开发人员就可以开始静态页面的的编写了。对于页面细节看的不是很清楚可以使用滚轮缩放后再拖拽查看,还是很方便的。于是就花了…...

昇思25天学习打卡营第18天|munger85
DCGAN生成漫画头像 首先肯定是下载训练数据,而这些训练数据就是一些卡通头像。后来我们会看到这个具体的头像 就像其他的数据集目录一样,它是由一些目录和这个目录下面的文件组成的数据集。 有相当多的图片。所以可以训练出来比较好的效果。 图片的处理…...

nginx配置文件说明
Nginx的配置文件说明 Nginx配置文件的主要配置块可以分为三个部分:全局配置块(events和http块),events块和http块。这三个部分共同定义了Nginx服务器的整体行为和处理HTTP请求的方式。 全局配置块: 包含了影响Nginx服…...

用不同的url头利用Python访问一个网站,把返回的东西保存为txt文件
这个需要调用requests模块(相当于c的头文件) import requests 还需要一个User-Agent头(这个意思就是告诉python用的什么系统和浏览器) Google Chrome(Windows): Mozilla/5.0 (Windows NT 10.0; Win64; x64…...

一文掌握Prometheus实现页面登录认证并集成grafana
一、接入方式 以保护Web站点的访问控制,如HTTP 服务器配置中实现安全的加密通信和身份验证,保护 Web 应用程序和用户数据的安全性。 1.1 加密密码 通过httpd-tools工具包来进行Web站点加密 yum install -y httpd-tools方式一:通过htpasswd生…...

欢迎来到 Mint Expedition:Web3 和 NFT 的新时代开始
7 月 15 日,Mint Expedition 正式开启,作为 Mint 生态系统的旗舰项目,将彻底变革 Web3 和 NFT 去中心化应用! Mint Expedition 是 Mint 的最新航程,延续了 Mint Forest 的成功。Mint Forest 吸引了超过 41.4 万独立用…...

针对环境构图的全局一致性扫描点云数据对齐(Graph SLAM)
本算法是一个经典的,针对SLAM(simultaneous localization and mapping 即时定位与地图构建)问题而提出的算法。该算法的提出者是Feng Lu和Evangelos Milios,他们在本算法中开创了通过全局优化方程组以减少约束引入的误差来进一步优…...

Matlab学习笔记01 - 基本数据类型
Matlab学习笔记01 - 基本数据类型 1、数据类型转换2、矩阵2.1 访问单个矩阵元素2.2 访问多个矩阵元素2.3 矩阵转置 3、字符与字符串4、数值与字符串5、元胞数组 1、数据类型转换 十进制转十六进制字符串‘FF’ >> hex2dec(3ff)ans 1023十进制转十六进制字符串 >>…...

基于重要抽样的主动学习不平衡分类方法ALIS
这篇论文讨论了数据分布不平衡对分类器性能造成的影响,并提出了一种新的有效解决方案 - 主动学习框架ALIS。 1、数据分布不平衡会影响分类器的学习性能。现有的方法主要集中在过采样少数类或欠采样多数类,但往往只采用单一的采样技术,无法有效解决严重的类别不平衡问题。 2、论…...

Python爬虫(基本流程)
1. 确定目标和范围 明确需求:确定你需要从哪些网站抓取哪些数据。合法性:检查目标网站的robots.txt文件,了解哪些内容可以被抓取。数据范围:确定爬取数据的起始和结束点,比如时间范围、页面数量等。 2. 选择合适的工…...

primeflex教学笔记20240720, FastAPI+Vue3+PrimeVue前后端分离开发
练习 先实现基本的页面结构: 代码如下: <template><div class"flex p-3 bg-gray-100 gap-3"><div class"w-20rem h-12rem bg-indigo-200 flex justify-content-center align-items-center text-white text-5xl">…...
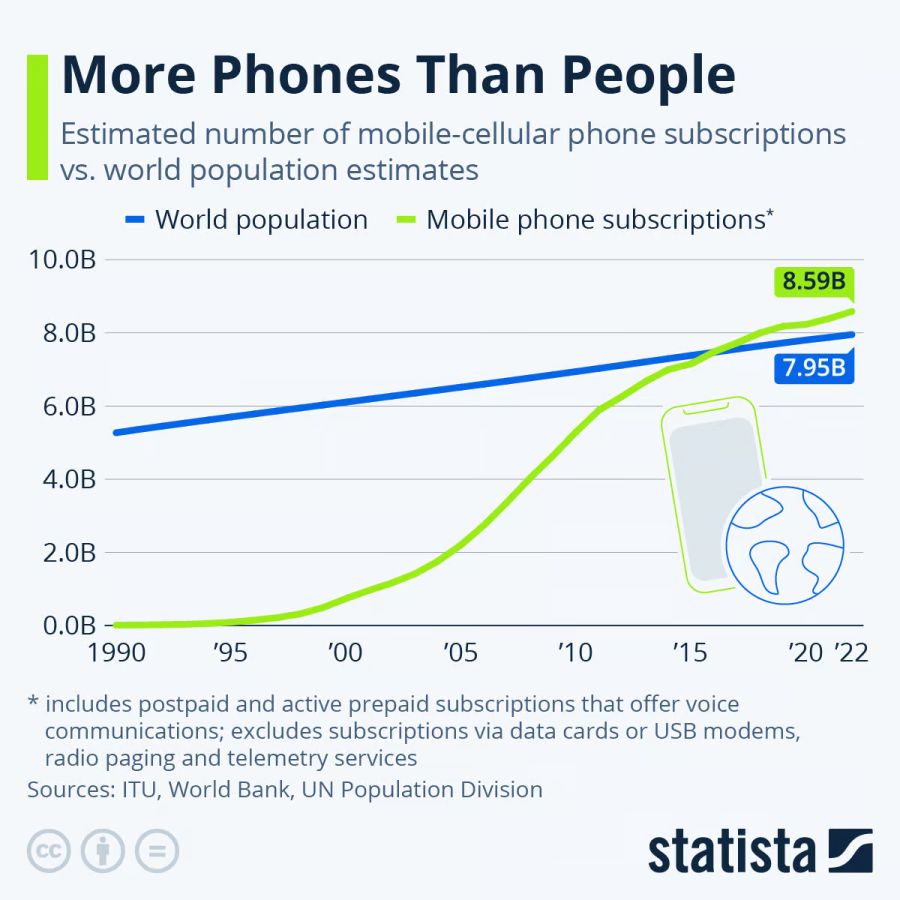
移动设备安全革命:应对威胁与解决方案
移动设备已成为我们日常工作和家庭生活中不可或缺的工具,然而,对于它们安全性的关注和投资仍然远远不够。本文深入分析了移动设备安全的发展轨迹、目前面临的威胁态势,以及业界对于这些安全漏洞响应迟缓的深层原因。文中还探讨了人们在心理层…...

【C语言】 链表实现学生管理系统(堆区开辟空间)
总体思路都能写出来,问题是感觉稍微比之前的麻烦一些,在刚开始创建结构体的时候,并没有去按照链表的思路去写,导致写成了顺序表,后面就一直纠结空间怎么开辟。 链表是由一个头节点和其它申请出来的小节点连起来的&…...

STM32实战篇:按键(外部输入信号)触发中断
功能要求 将两个按键分别与引脚PA0、PA1相连接,通过按键按下,能够触发中断响应程序(不需明确功能)。 代码流程如下: 实现代码 #include "stm32f10x.h" // Device headerint main() {//开…...

Android SurfaceView 组件介绍,挖洞原理详解
文章目录 组件介绍基本概念关键特性使用场景 SurfaceHolder介绍主要功能使用示例 SurfaceView 挖洞原理工作机制 使用SurfaceView展示图片示例创建一个自定义的 SurfaceView类在 Activity 中使用 ImageSurfaceView注意事项效果展示 组件介绍 在 Android 开发中,Sur…...

day2加餐 Go 接口型函数的使用场景
文章目录 问题价值使用场景其他语言类似特性 问题 在 动手写分布式缓存 - GeeCache day2 单机并发缓存 这篇文章中,有一个接口型函数的实现: // A Getter loads data for a key. type Getter interface {Get(key string) ([]byte, error) }// A Getter…...

摄像头 RN6752v1 视频采集卡
摄像头 AHD倒车摄像头比较好,AHD英文全名Analog High Definition,即模拟高清,拥有比较好的分辨率与画面质感。 RN6752v1 GQW AKKY2 usb 采集卡 FHD(1080p)、HD(720p)和D1(480i&am…...

记录vivado自带IP iBert眼图近端回环
记录利用vivado自带IP核工具测试信号质量 ibert是测试眼图的工具,在使用的时候并不用改太多的内容,只需要注意参考时钟及所需要的引脚即可。由于条件的限制,并没有使用光纤和电缆进行连接进行外部回环,仅使用内部回环做测试&…...

js | Core
http://dmitrysoshnikov.com/ecmascript/javascript-the-core/ Object 是什么? 属性[[prototype]]对象。 例如,下面的,son是对象,foo不是对象。打印出来的son,能看到有一个prototype 对象。 prototype vs _proto_ v…...

SQLite Having 子句详解
SQLite Having 子句详解 SQLite 是一款轻量级的数据库管理系统,广泛应用于移动应用、桌面应用以及各种嵌入式系统。在 SQLite 中,HAVING 子句是一个非常重要的特性,它用于对 GROUP BY 子句的查询结果进行过滤。本文将详细介绍 SQLite 的 HAVING 子句,包括其用法、语法以及…...

DOM NodeList 深入解析
DOM NodeList 深入解析 概述 DOM NodeList 是 Web 开发中常用的一种数据结构,它代表了文档中一系列元素的集合。在本文中,我们将对 DOM NodeList 进行深入解析,包括其定义、特点、使用方法以及在实际开发中的应用。 定义 DOM NodeList 是一个类似数组的对象,它包含了文…...

在Node.js后端服务中集成Taotoken调用大模型指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用大模型指南 将大模型能力集成到后端服务是现代应用开发的常见需求。Taotoken平台提供了OpenA…...

从零搭建VGG16:深入解析网络架构与PyTorch实战
1. VGG16网络架构解析 VGG16作为卷积神经网络发展史上的里程碑,其核心设计理念至今仍影响着现代深度学习模型。我第一次接触这个网络时,被它简洁优雅的结构深深吸引——全部使用33小卷积核堆叠,配合22最大池化,这种设计就像用乐高…...

下行周期生存之道 = 低风险试错 × 即时反馈 × 长期复购
总结公式: 下行周期赚钱 低风险试错 即时反馈 长期复购 日本用30年验证了这套逻辑。 普通人现在能不能赚到钱,不在于胆子够不够大,而在于你能不能在大家焦虑的时候,给他一点确定感。 先收藏,慢慢找自己的切入口。...

技术奇点之后,人类程序员的历史角色
当人工智能越过技术奇点,代码生成、测试用例设计乃至系统运维都将发生质变。本文从软件测试从业者的视角出发,系统探讨人类程序员在奇点之后可能扮演的六种核心角色:系统守护者、需求翻译官、质量伦理法官、人机交互设计师、持续学习组织者与…...

爆单实操课:从3C到美妆,跨境商家如何用AI神器搞定TikTok本土化
每天都有无数跨境卖家在各大社群里发问:怎么用ai生成带货视频,有哪些工具比较好用? 在 TikTok 这个极度依赖内容爆发的平台上,不同类目的产品对视频素材的需求千差万别。靠人工剪辑不仅效率低,且极难跨越本土化语言的障…...

练了半年演讲口才,汇报时还是结巴,说说我的真实感受
小林坐在会议室的角落,手心微微出汗。轮到他汇报季度项目进展时,他深吸一口气站起来——结果,开场白磕磕绊绊,PPT翻到第三页才找回节奏。散会后他苦笑着跟同事说:“演讲口才课我上了半年了,怎么还是这副德行…...

FlareLine Flutter:开源跨平台管理后台模板开发与部署指南
1. 项目概述:一个为现代应用而生的Flutter仪表盘模板如果你正在寻找一个能快速启动你的下一个Web、Android或iOS项目后台管理界面的方案,并且希望这个方案足够现代、功能齐全,同时又能让你完全掌控代码,那么FlareLine Flutter这个…...

如何在Windows任务栏实时监控股票行情:TrafficMonitor股票插件终极指南
如何在Windows任务栏实时监控股票行情:TrafficMonitor股票插件终极指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 你是否曾经在工作时频繁切换窗口查看股票行情…...