来自Transformers的双向编码器表示(BERT) 通俗解释
来自Transformers的双向编码器表示(BERT)
目录
- 1. 从上下文无关到上下文敏感
- 2. 从特定于任务到不可知任务
- 3. BERT:把两个最好的结合起来
- 4. BERT的输入表示
- 5. 掩蔽语言模型(Masked Language Modeling)
- 6. 下一句预测(Next Sentence Prediction, NSP)
1. 从上下文无关到上下文敏感
早期的词嵌入模型,如word2vec和GloVe,会将同一个词在不同上下文中的表示设定为相同。这就导致了一个问题:当同一个词在不同的句子中有不同的意思时,这些模型无法区分。例如,“crane”在“a crane is flying”(一只鹤在飞)和“a crane driver came”(一名吊车司机来了)中的意思是完全不同的。
为了克服这个问题,出现了“上下文敏感”词嵌入模型。这些模型会根据词的上下文来调整词的表示,使得相同的词在不同句子中的表示可以有所不同。比如ELMo模型会根据句子的整体结构来调整每个词的表示,使其更加贴合具体的语境。
2. 从特定于任务到不可知任务
ELMo虽然改进了词嵌入,使其上下文敏感,但它仍然需要为每个具体的自然语言处理任务设计一个特定的模型架构。这就意味着在解决不同的任务时,仍然需要大量的定制化工作。
为了简化这一过程,GPT(生成式预训练模型)被提出。GPT使用了通用的模型架构,可以应用于各种自然语言处理任务,而不需要为每个任务设计一个特定的模型。这种模型在预训练阶段学习了大量的语言知识,在应用于具体任务时只需要做少量的调整即可。
然而,GPT有一个缺点,它只能从左到右进行语言建模,无法同时考虑词的左右上下文。
3. BERT:把两个最好的结合起来
BERT模型结合了ELMo和GPT的优点,既能够进行上下文敏感的双向编码,又不需要为每个任务设计特定的模型架构。BERT使用了Transformer编码器,可以同时考虑词的左右上下文,从而获得更准确的词表示。在应用于具体任务时,BERT模型只需要做少量的架构调整,并且可以微调所有的参数,以适应不同的任务需求。
BERT的出现大大简化了自然语言处理任务的模型设计过程,并且在多个任务上都取得了显著的性能提升。
BERT的贡献与任务分类
BERT提升了自然语言处理中的11种任务水平,这些任务可以归类为四大类:
- 单文本分类:例如情感分析,就是判断一段文本是正面的还是负面的。
- 文本对分类:例如自然语言推断,就是判断两段文本之间的关系。
- 问答:例如从一段文本中找出问题的答案。
- 文本标记:例如命名实体识别,就是识别文本中的人名、地名等特定信息。
BERT与ELMo和GPT一样,都是2018年提出的。这些模型通过预训练一种强大的语言表示方式,彻底改变了自然语言处理的解决方案。它们的概念虽然简单,但在实际应用中效果非常强大。
4. BERT的输入表示
在自然语言处理中,有的任务(如情感分析)只需要输入一段文本,而有的任务(如自然语言推断)需要输入两段文本。BERT对这两种输入方式进行了明确的表示:
-
单文本输入:BERT输入序列包含一个特殊标记
<cls>,然后是文本序列的标记,最后是一个特殊分隔标记<sep>。例如,对于“Hello, world!”输入序列为:<cls> Hello , world ! <sep>。 -
文本对输入:BERT输入序列包含一个特殊标记
<cls>,然后是第一个文本序列的标记,接着是一个分隔标记<sep>,再接着是第二个文本序列的标记,最后再加一个分隔标记<sep>。例如,对于“Hello, world!”和“How are you?”,输入序列为:<cls> Hello , world ! <sep> How are you ? <sep>。
为了区分文本对,BERT使用了片段嵌入。对于第一个文本序列,使用片段嵌入\mathbf{e}_A;对于第二个文本序列,使用片段嵌入\mathbf{e}_B。如果只有一个文本输入,就只使用\mathbf{e}_A。
在BERT的预训练中,有两个主要任务:掩蔽语言模型(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction)。我们先来详细解释掩蔽语言模型任务。
5. 掩蔽语言模型(Masked Language Modeling)
基本概念
语言模型通常使用前面的词(左侧上下文)来预测下一个词元。BERT的掩蔽语言模型任务的目标是为了实现双向编码(同时利用左侧和右侧的上下文)来预测每个词元。为此,BERT会随机选择一些词元进行掩蔽,并尝试通过双向上下文来预测这些掩蔽的词元。
掩蔽策略
在BERT的预训练过程中,15%的词元会被随机选择进行掩蔽。为了确保模型在微调时能够适应真实情况,BERT在预训练中采用了三种不同的方法来处理这些被掩蔽的词元:
- 80%的时间,用特殊的“”词元替换。例如,句子“this movie is great”会变成“this movie is ”。
- 10%的时间,用随机词元替换。例如,句子“this movie is great”会变成“this movie is drink”。
- 10%的时间,词元保持不变。例如,句子“this movie is great”依然是“this movie is great”。
这种处理方式有两个好处:
- 减少偏差:模型不会仅仅依赖掩蔽词元来进行训练,因为并不是所有的掩蔽词元都用“”替换。
- 增强鲁棒性:在训练中引入噪声(例如用随机词元替换),可以使模型在实际应用中更加稳健。
预测掩蔽词元
为了预测被掩蔽的词元,BERT使用了一个单隐藏层的多层感知机(MLP)。这个MLP接收BERT编码器的输出和需要预测的词元位置,并输出这些位置上的预测结果。具体来说:
- 输入:来自BERT编码器的表示和掩蔽词元的位置。
- 输出:这些位置上预测的词元。
计算损失
通过预测的结果(即每个掩蔽位置上的预测词元)和真实标签,我们可以计算交叉熵损失。交叉熵损失衡量了预测值与实际标签之间的差距,是训练语言模型时常用的损失函数。
掩蔽语言模型任务通过随机掩蔽部分词元,并利用双向上下文来预测这些掩蔽的词元,从而使BERT模型能够更好地理解和生成自然语言。通过多种掩蔽策略,模型在训练中引入了一定的噪声,增强了模型的泛化能力,使其在处理实际任务时更加稳健。
6. 下一句预测(Next Sentence Prediction, NSP)
尽管掩蔽语言建模(Masked Language Modeling, MLM)可以帮助模型理解每个单词的上下文,但它不能直接帮助模型理解两个句子之间的逻辑关系。为了解决这个问题,BERT在预训练过程中还引入了一个二分类任务——下一句预测(NSP)。
NSP 任务的原理
在NSP任务中,模型需要判断两个给定的句子是否是连续的。具体来说:
- 标签为“真”的句子对:有一半的句子对确实是连续的,即第二个句子是第一个句子的直接后续。
- 标签为“假”的句子对:另一半的句子对是随机生成的,第二个句子是从语料库中随机抽取的,与第一个句子没有直接关系。
NSP 类的实现
为了实现NSP任务,BERT使用了一个简单的多层感知机(MLP)来进行二分类。NSP类的核心部分是一个线性层,它接受输入并输出两个值,分别表示两个句子是连续的(标签为“真”)和不是连续的(标签为“假”)。
特殊词元 <cls> 的作用
在BERT模型中,特殊词元<cls>被用于总结两个输入句子的整体信息。通过自注意力机制,<cls>词元的表示已经编码了输入的两个句子的所有信息。因此,我们可以直接使用编码后的<cls>词元的表示作为输入,来进行下一句预测。
计算二分类交叉熵损失
为了评估NSP任务的表现,我们使用二分类交叉熵损失函数来计算预测结果与真实标签之间的差距。这种损失函数会计算每个预测结果与对应真实标签之间的误差,然后对这些误差进行平均,以获得整体的损失值。
预训练语料库
BERT的预训练是在两个大规模的语料库上进行的:
- 图书语料库:包含大约8亿个单词。
- 英文维基百科:包含大约25亿个单词。
这些庞大的语料库为BERT模型提供了丰富的训练数据,使得模型在处理各种自然语言处理任务时具备强大的理解能力。
通过结合MLM和NSP两个预训练任务,BERT模型能够同时理解单词的上下文信息和句子之间的逻辑关系。这种双重训练方式使得BERT在许多自然语言处理任务中表现出色。MLM任务帮助模型更好地理解单词的含义,而NSP任务则帮助模型理解句子之间的关系。这两种任务的结合,使得BERT在语言理解方面达到了前所未有的高度。
相关文章:
来自Transformers的双向编码器表示(BERT) 通俗解释
来自Transformers的双向编码器表示(BERT) 目录 1. 从上下文无关到上下文敏感2. 从特定于任务到不可知任务3. BERT:把两个最好的结合起来4. BERT的输入表示5. 掩蔽语言模型(Masked Language Modeling)6. 下一句预测&am…...
)
代码随想录第十六天|贪心算法(2)
目录 LeetCode 134. 加油站 LeetCode 135. 分发糖果 LeetCode 860. 柠檬水找零 LeetCode 406. 根据身高重建队列 LeetCode 452. 用最少数量的箭引爆气球 LeetCode 435. 无重叠区间 LeetCode 763. 划分字母区间 LeetCode 56. 合并区间 LeetCode 738. 单调递增的数字 总…...

花几千上万学习Java,真没必要!(二十二)
1、final关键字: 测试代码1: package finaltest.com;public class FinalBasicDemo {public static void main(String[] args) {// final修饰基本数据类型变量final int number 5;// 尝试修改number的值,这将导致编译错误// number 10; // …...

在RK3568上如何烧录MAC?
这里我们用RKDevInfoWriteTool 1.1.4版本 下载地址:https://pan.baidu.com/s/1Y5uNhkyn7D_CjdT98GrlWA?pwdhm30 提 取 码:hm30 烧录过程: 1. 解压RKDevInfoWriteTool_Setup_V1.4_210527.7z 进入解压目录,双击运行RKDevInfo…...
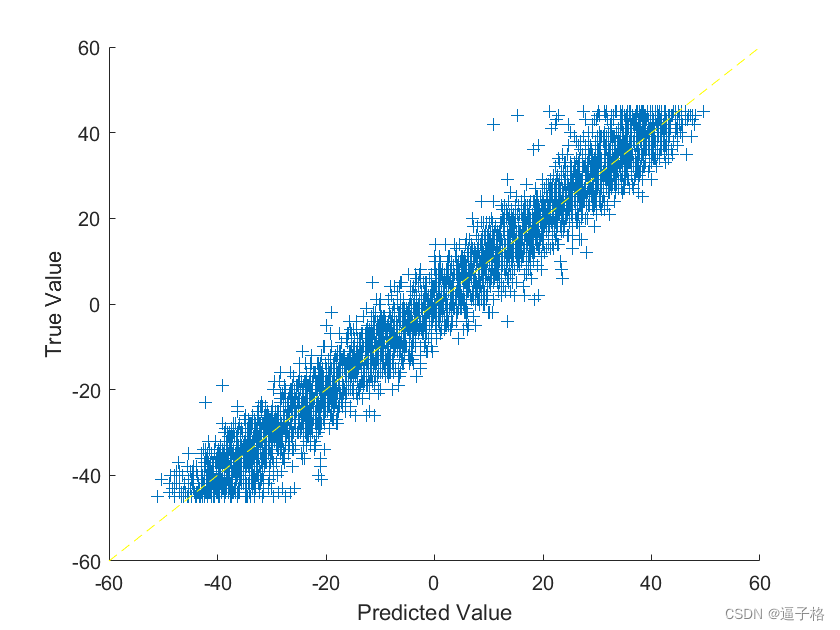
1.30、基于卷积神经网络的手写数字旋转角度预测(matlab)
1、卷积神经网络的手写数字旋转角度预测原理及流程 基于卷积神经网络的手写数字旋转角度预测是一个常见的计算机视觉问题。在这种情况下,我们可以通过构建一个卷积神经网络(Convolutional Neural Network,CNN)来实现该任务。以下…...

Windows如何使用Python的sphinx
在Windows上使用Python的Sphinx进行文档渲染和呈现,可以遵循以下步骤进行操作: 安装Python:首先,确保你的Windows系统上已经安装了Python。你可以从Python的官方网站下载并安装适合你系统(32位或64位&…...

C++ STL nth_element 用法
一:功能 将一个序列分为两组,前一组元素都小于*nth,后一组元素都大于*nth, 并且确保第 nth 个位置就是排序之后所处的位置。即该位置的元素是该序列中第nth小的数。 二:用法 #include <vector> #include <a…...

【PostgreSQL教程】PostgreSQL 选择数据库
博主介绍:✌全网粉丝20W+,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物联网、机器学习等设计与开发。 感兴趣的可…...

C# —— HashTable
集合collections命名空间,专门进行一系列的数据存储和检索的类,主要包含了:堆栈、和队列、list、ArrayList、数组 HashTable 字典 storeList 排序列表等类 Array 数组 长度固定, 类型固定 通过索引值来进行访问 ArrayList动态数组,…...

LeetCode 第407场周赛个人题解
目录 100372. 使两个整数相等的位更改次数 原题链接 思路分析 AC代码 100335. 字符串元音游戏 原题链接 思路分析 AC代码 100360. 将 1 移动到末尾的最大操作次数 原题链接 思路分析 AC代码 100329. 使数组等于目标数组所需的最少操作次数 原题链接 思路分析 A…...

使用Django框架实现音频上传功能
数据库设计(models.py) class Music(models.Model):""" 音乐 """name models.CharField(verbose_name"音乐名字", max_length32)singer models.CharField(verbose_name"歌手", max_length32)# 本质…...

[路由器]IP-MAC的绑定与取消
背景:当公司的网络不想与外部人员进行共享,可以在路由器页面配置IP-MAC的绑定,让公司内部人员的手机和电脑的mac,才能接入到公司。第一步:在ARP防护中,启动IP-MAC绑定选项,必须启动仅允许IP-MAC…...
Idea配置远程开发
Idea配置远程开发 本篇博客介绍使用idea通过ssh连接ubuntu服务器进行开发 目录 Idea配置远程开发1.idae上点击file->Remote Development2.点击New Connection3.填写相关信息4.输入密码5.选择IDE版本和项目路径5.1 点击open an SSH terminal打开控制台5.2 依次执行命令 6.成…...

lua 实现 函数 判断两个时间戳是否在同一天
函数用于判断两个时间戳是否在同一天。下面是对代码的详细解释: ### 函数参数 - stampA 和 stampB:两个时间戳,用于比较。- resetInfo:一个可选参数,包含小时、分钟和秒数,用于调整时间戳。 ### 函数实现…...

工作纪实53-log4j日志打印文件隔离
在项目中,我有一堆业务日志需要打印,另一部分的日志,是没有格式的,需要被云平台离线解析并收集到kafka或者hdfs、hive等,需要将日志隔离打印到不同的文件 正常的log4j配置是下面这样的,配合Sl4j直接使用默认…...

7月21日,贪心练习
大家好呀,今天带来一些贪心算法的应用解题、 一,柠檬水找零 . - 力扣(LeetCode) 解析: 本题的贪心体现在对于20美元的处理上,我们总是优先把功能较少的10元作为找零,这样可以让5元用处更大 …...
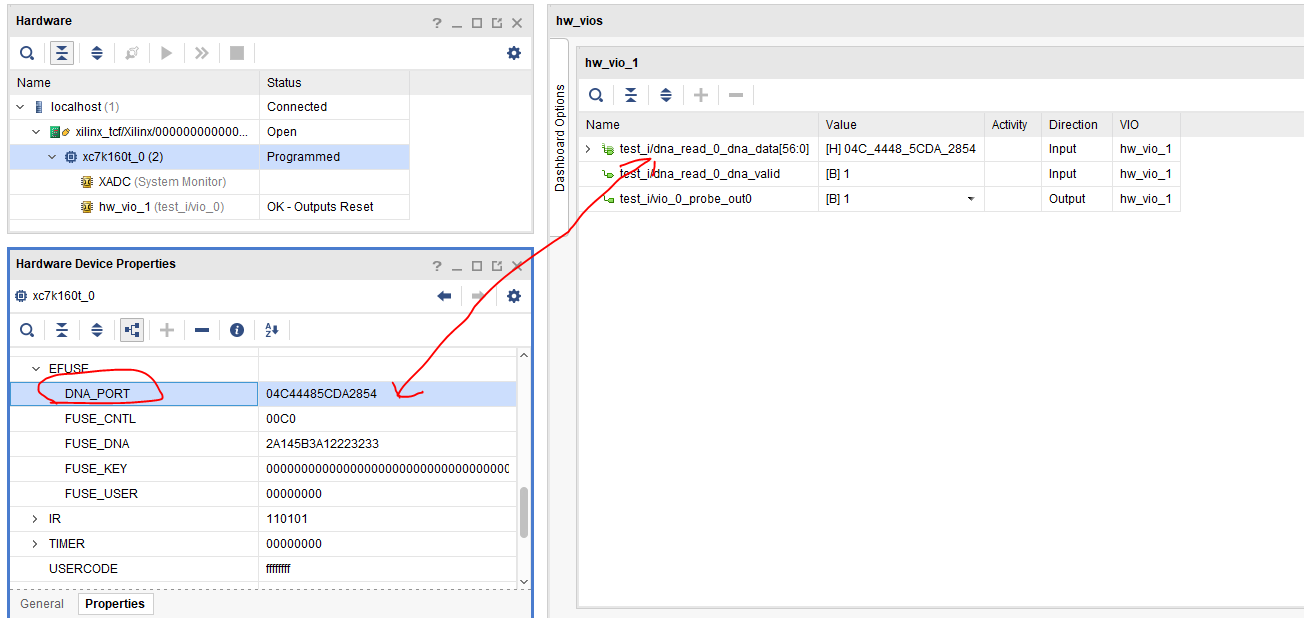
FPGA DNA 获取 DNA_PORT
FPGA DNA DNA 是 FPGA 芯片的唯一标识, FPGA 都有一个独特的 ID ,也就是 Device DNA ,这个 ID 相当于我们的身份证,在 FPGA 芯片生产的时候就已经固定在芯片的 eFuse 寄存器中,具有不可修改的属性。在 xilinx 7series…...

使用 hutool工具实现导入导出功能。
hutool工具网址 Hutool参考文档 pom依赖 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.20</version></dependency><dependency><groupId>org.apache.poi</gro…...

大语言模型-Transformer-Attention Is All You Need
一、背景信息: Transformer是一种由谷歌在2017年提出的深度学习模型。 主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如机器翻译、文本生成等。Transfor…...
)
spring(二)
一、为对象类型属性赋值 方式一:(引用外部bean) 1.创建班级类Clazz package com.spring.beanpublic class Clazz {private Integer clazzId;private String clazzName;public Integer getClazzId() {return clazzId;}public void setClazzId(Integer clazzId) {th…...

利用Taotoken模型广场为内容生成应用挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为内容生成应用挑选合适模型 对于开发内容生成类应用的团队而言,选择合适的模型是项目成功的关键…...

SAP ABAP BADI AC_DOCUMENT:跨越VF01/MIRO/AFAB的智能凭证替代实战
1. 为什么需要AC_DOCUMENT BADI? 在SAP标准业务流程中,GGB1提供的凭证替代功能已经能满足大部分常规需求。但实际业务往往更复杂——比如销售开票时,需要根据付款条件动态替换税科目;发票校验时,要根据供应商信息自动填…...

ARM GICv3虚拟中断控制器与ICH_LR寄存器详解
1. ARM GICv3虚拟中断控制器架构概述 在现代计算机系统中,中断控制器是管理硬件中断的核心组件。ARM架构的通用中断控制器(Generic Interrupt Controller,GIC)经过多代演进,GICv3版本引入了对虚拟化的全面支持。虚拟化…...

终极天气API开发指南:从数据获取到可视化展示的完整流程
终极天气API开发指南:从数据获取到可视化展示的完整流程 【免费下载链接】Awesome_APIs :octocat: A collection of APIs 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome_APIs 天气API是现代应用开发中不可或缺的组件,能够为用户提供实时天…...

OpenClaw-Readwise:自动化同步阅读笔记到Obsidian的实践指南
1. 项目概述:一个连接阅读与笔记的自动化桥梁 如果你和我一样,是个重度阅读爱好者,同时又在使用 Readwise 和 Obsidian 这类工具来管理自己的知识库,那你一定遇到过这个痛点:在 Readwise 里高亮、标注的精彩内容&…...

如何高效处理RPG Maker加密资源:纯前端解密方案深度解析
如何高效处理RPG Maker加密资源:纯前端解密方案深度解析 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://gitco…...

AI代码工程化实战:从生成到部署的确定性框架
1. 项目概述:从“AI画饼”到“AI交付”的工程化桥梁如果你和我一样,在过去一年里深度使用过 Claude Code、Cursor 或者 GitHub Copilot,那你一定经历过这种场景:AI 助手噼里啪啦生成了一大堆看起来非常酷炫的代码,你兴…...

机器人伦理工程化:从道德困境到可解释决策系统的技术实现
1. 项目概述:当机器人需要做出道德抉择十年前,当我在实验室里调试一台协作机器人的碰撞检测算法时,一个从未预想过的问题出现了:在一条狭窄的通道里,机器人的移动路径上同时出现了一位匆忙的工程师和一个价值百万的实验…...

音频解密的终极方案:qmcdump高效解密QQ音乐加密格式全解析
音频解密的终极方案:qmcdump高效解密QQ音乐加密格式全解析 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你…...

基于Helm Chart在Kubernetes中部署docker-mailserver邮件服务器
1. 项目概述与核心价值最近在折腾自建邮件服务器,发现了一个宝藏项目:docker-mailserver。它把邮件服务里那些复杂的组件,比如 Postfix、Dovecot、SpamAssassin、ClamAV 这些,全都打包进了一个 Docker 镜像里,开箱即用…...