大语言模型-Transformer-Attention Is All You Need
一、背景信息:
Transformer是一种由谷歌在2017年提出的深度学习模型。
主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如机器翻译、文本生成等。Transformer彻底改变了之前基于循环神经网络(RNNs)和长短期记忆网络(LSTMs)的序列建模范式,并且在性能上取得了显著提升。
二、整体结构:
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。

Transformer 的输入
Transformer 的输入由 x的 词向量 和 位置向量 相加得到。
其中Transformer 在位置向量中保存单词在序列中的相对或绝对位置信息,位置向量由PE(Positional Encoding)表示:

eg:假设n为序列长度,d为表示向量维度,原始输入为 X o r i − i n p u t X_{ori-input} Xori−input( [ x 1 , x 2 . . . x n ] [x_{1},x_{2}...x_{n} ] [x1,x2...xn])
则,原始输入 X o r i − i n p u t X_{ori-input} Xori−input的词向量矩阵为 X W E X_{WE} XWE其维度为(n, d),
原始输入 X o r i − i n p u t X_{ori-input} Xori−input的位置向量矩阵 X P E X_{PE} XPE维度也为(n, d),
最终 Transformer 的输入矩阵 X i n p u t X_{input} Xinput = X W E X_{WE} XWE + X P E X_{PE} XPE维度也是(n, d)。
三、 Encoder
Encoder 部分由6个Encoder block 组成。
Encoder block 由Multi-Head Attention结合Add & Norm、Feed Forward结合 Add & Norm 组成。
即由下面两部分组成:
X = L a y d e r N o r m ( X i n p u t + M u l t i H e a d A t t e n t i o n ( X i n p u t ) ) X = LayderNorm(X_{input} + MultiHeadAttention(X_{input})) X=LayderNorm(Xinput+MultiHeadAttention(Xinput))
X = L a y d e r N o r m ( X + F e e d F o r w o r d ( X ) ) X = LayderNorm(X + FeedForword(X)) X=LayderNorm(X+FeedForword(X))
MultiHeadAttention部分
其中MultiHeadAttention为多个Self-Attention进行Concat后linear而成:
Q = X i n p u t × W q Q = X_{input} \times W_{q} Q=Xinput×Wq
K = X i n p u t × W k K = X_{input} \times W_{k} K=Xinput×Wk
V = X i n p u t × W v V = X_{input} \times W_{v} V=Xinput×Wv
Z = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Z = Attention(Q, K, V) = softmax( \frac{QK^{T} }{\sqrt{d_{k}} } )V Z=Attention(Q,K,V)=softmax(dkQKT)V
其中, Z 1 . . . . Z 8 Z_{1}....Z_{8} Z1....Z8为X_{input} 经过8个不同Self-Attention得到的结果
X = M u l t i H e a d A t t e n t i o n ( X i n p u t ) = L i n e a r ( C o n c a t ( Z 1 , Z 2 . . . . Z 8 ) ) X =MultiHeadAttention(X_{input} ) = Linear(Concat(Z_{1},Z_{2}....Z_{8})) X=MultiHeadAttention(Xinput)=Linear(Concat(Z1,Z2....Z8))
FeedForword部分
Feed Forward 层,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,公式如下。
F e e d F o r w o r d ( X ) = m a x ( 0 , X W 1 + b 1 ) W 2 + b 2 FeedForword(X) = max(0, XW_{1} + b_{1})W_{2} + b_{2} FeedForword(X)=max(0,XW1+b1)W2+b2
四、 Decoder
Decoder 由 6个Decoder block 以及最后的一个linear组成。
Decoder block 由 一个带有 Masked的Multi-Head Attention结合Add & Norm和一个Multi-Head Attention结合Add & Norm以及一个Feed Forward结合 Add & Norm 组成。
X o u t p u t = X o u p u t − o r i ⊗ X M a s k X_{output}=X_{ouput-ori }\otimes X_{Mask} Xoutput=Xouput−ori⊗XMask
X = L a y d e r N o r m ( X o u t p u t + M a s k M u l t i H e a d A t t e n t i o n ( X o u p u t ) ) X = LayderNorm(X_{output} + MaskMultiHeadAttention(X_{ouput})) X=LayderNorm(Xoutput+MaskMultiHeadAttention(Xouput))
X = L a y d e r N o r m ( X + M u l t i H e a d A t t e n t i o n ( [ X a s Q , E C a s K , E C a s V ] ) X = LayderNorm(X + MultiHeadAttention([X_{as Q}, EC_{as K}, EC_{as V}]) X=LayderNorm(X+MultiHeadAttention([XasQ,ECasK,ECasV])
X r e s u l t = S o f t m a x ( X ) X_{result} = Softmax(X) Xresult=Softmax(X)
带有 Masked的Multi-Head Attention层
其中带有 Masked的Multi-Head Attention中 X o u p u t X_{ouput} Xouput为Transformer 标签对应输出向量; X o u p u t − o r i X_{ouput-ori} Xouput−ori需要先 ⊗ \otimes ⊗ X M a s k X_{Mask} XMask得到 X o u p u t X_{ouput} Xouput
Q = X o u p u t × W q Q = X_{ouput} \times W_{q} Q=Xouput×Wq
K = X o u p u t × W k K = X_{ouput} \times W_{k} K=Xouput×Wk
V = X o u p u t × W v V = X_{ouput} \times W_{v} V=Xouput×Wv
Z = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ⊗ X M a s k ) V Z = Attention(Q, K, V) = softmax( \frac{QK^{T} }{\sqrt{d_{k}} } \otimes X_{Mask} )V Z=Attention(Q,K,V)=softmax(dkQKT⊗XMask)V
其中第二个 Multi-Head Attention层
Self-Attention 的 K, V矩阵使用的是根据Encoder编码的输出矩阵C计算得到 K, V; Self-Attention 的 Q矩阵是根据Decoder block中的Masked Multi-Head Attention层输出矩阵 Z 计算得到 Q。
Reference
1.Attention Is All You Need
2.Transformer模型详解(图解最完整版)
3.Self-Attention & Transformer完全指南:像Transformer的创作者一样思考
相关文章:
大语言模型-Transformer-Attention Is All You Need
一、背景信息: Transformer是一种由谷歌在2017年提出的深度学习模型。 主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如机器翻译、文本生成等。Transfor…...
)
spring(二)
一、为对象类型属性赋值 方式一:(引用外部bean) 1.创建班级类Clazz package com.spring.beanpublic class Clazz {private Integer clazzId;private String clazzName;public Integer getClazzId() {return clazzId;}public void setClazzId(Integer clazzId) {th…...

MAC 数据恢复软件: STELLAR Data Recovery For MAC V. 12.1 更多增强功能
天津鸿萌科贸发展有限公司是 Stellar 系列软件的授权代理商。 STELLAR Data Recovery For MAC 该数据恢复软件可从任何存储驱动器、清空的回收站以及崩溃或无法启动的 Mac 设备中恢复丢失或删除的文件。 轻松恢复已删除的文档、照片、音频文件和视频。自定义扫描以帮助恢复特…...

初识godot游戏引擎并安装
简介 Godot是一款自由开源、由社区驱动的2D和3D游戏引擎。游戏开发虽复杂,却蕴含一定的通用规律,正是为了简化这些通用化的工作,游戏引擎应运而生。Godot引擎作为一款功能丰富的跨平台游戏引擎,通过统一的界面支持创建2D和3D游戏。…...

Windows配置Qt+VLC
文章目录 前言下载库文件提取文件编写qmakeqtvlc测试代码 总结 前言 在Windows平台上配置Qt和VLC是开发多媒体应用程序的一个重要步骤。Qt作为一个强大的跨平台应用开发框架,为开发人员提供了丰富的GUI工具和库,而VLC则是一个开源的多媒体播放器&#x…...

本地部署 mistralai/Mistral-Nemo-Instruct-2407
本地部署 mistralai/Mistral-Nemo-Instruct-2407 1. 创建虚拟环境2. 安装 fschat3. 安装 transformers4. 安装 flash-attn5. 安装 pytorch6. 启动 controller7. 启动 mistralai/Mistral-Nemo-Instruct-24078. 启动 api9. 访问 mistralai/Mistral-Nemo-Instruct-2407 1. 创建虚拟…...
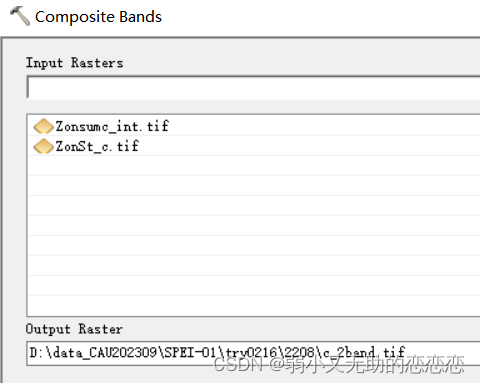
2月科研——arcgis计算植被差异
ArcGIS中,设置高于或低于某个值的像元为 -9999,然后将这些地方设为空——目的:去除异常值和黑色背景值 Con(("T_std ano7.tif" > 2) | ("T_std ano7.tif" < - 2), - 9999,"T_std ano7.tif") SetNull(&…...

深入理解Android中的缓存与文件存储目录
🌟 引言 在Android应用开发中,合理管理应用的数据存储至关重要。应用可能需要保存各种类型的数据,从简单的配置信息到多媒体文件,甚至是缓存数据以提高性能和用户体验。Android提供了多个内置目录来满足这些需求,但它…...

Linux_生产消费者模型
目录 1、生产消费者模型示意图 2、生产者消费者之间的关系 3、定义交易场所 4、实现生产消费者模型 5、伪唤醒 6、多生产多消费者的实际运用 7、POSIX信号量 7.1 初始化信号量 7.2 销毁信号量 7.3 等待信号量 7.4 发布信号量 8、生产消费的环形队列模型 8.1…...

【Vue】`v-if` 指令详解:条件渲染的高效实现
文章目录 一、v-if 指令概述二、v-if 的基本用法1. 基本用法2. 使用 v-else3. 使用 v-else-if 三、v-if 指令的高级用法1. 与 v-for 一起使用2. v-if 的性能优化 四、v-if 的常见应用场景1. 表单验证2. 弹窗控制 五、v-if 指令的注意事项 Vue.js 是一个用于构建用户界面的渐进式…...

junit mockito Base基类
编写单元测试时我们都习惯性减少重复代码 以下基于spring mvc框架,需要手动pom导包 BaseTest类用于启动上下文进行debug调试 MockBaseTset类用于不启动上下文进行打桩mock pom.xml <dependency><groupId>org.mockito</groupId><artifactId…...
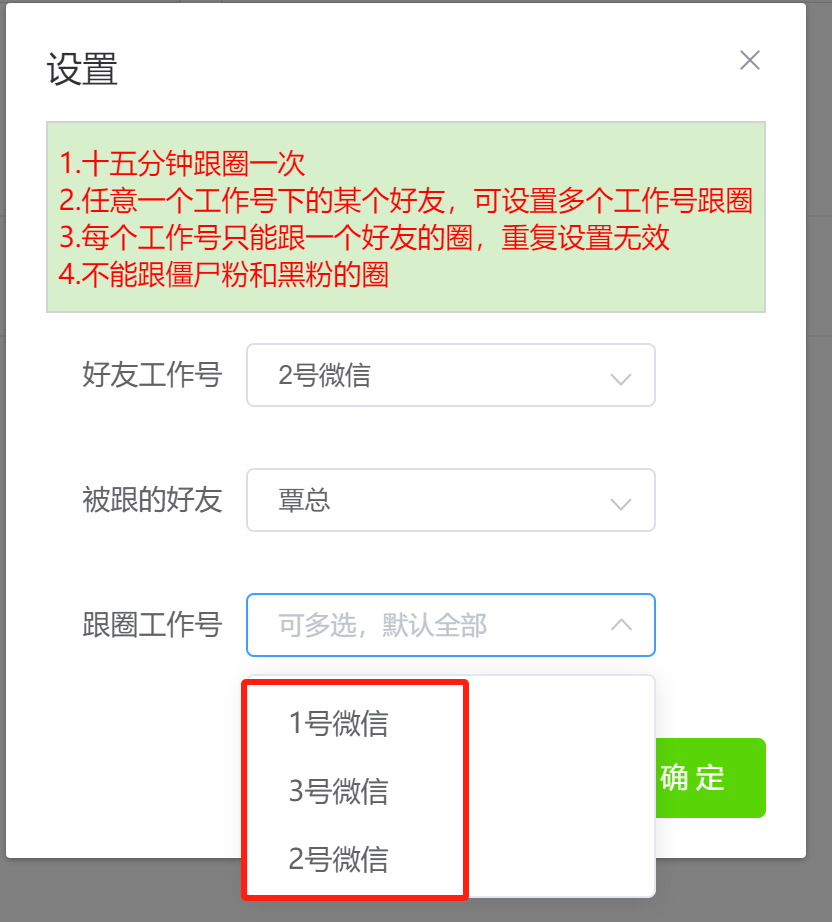
朋友圈运营分享干货2
朋友圈发什么内容? 1、产品相关 产品服务:产品的内容要有“用户视角”从用户的使用痛点入手,写到用户心坎里,才能引发购买 买家秀:买家秀是很好的朋友圈索材,可以让用户有一个正面感知清楚了解工品的情况…...

linux中创建一个名为“thread1“,堆栈大小为1024,优先级为2的线程
在Linux中,直接创建一个具有特定堆栈大小和优先级的线程通常不是通过标准的POSIX线程(pthread)库直接支持的。POSIX线程库(pthread)提供了创建和管理线程的基本机制,但不直接支持设置线程的堆栈大小或优先级…...

架构以及架构中的组件
架构以及架构中的组件 Transform Transform 以下的代码包含: 标准化的示例残差化的示例 # huggingface # transformers# https://www.bilibili.com/video/BV1At4y1W75x?spm_id_from333.999.0.0import copy import math from collections import namedtupleimport …...

Docker启动PostgreSql并设置时间与主机同步
在 Docker 中启动 PostgreSql 时,需要配置容器的时间与主机同步。可以通过在 Dockerfile 或者 Docker Compose 文件中设置容器的时区,或者使用宿主机的时间来同步容器的时间。这样可以确保容器中的 PostgreSql 与主机的时间保持一致,避免在使…...
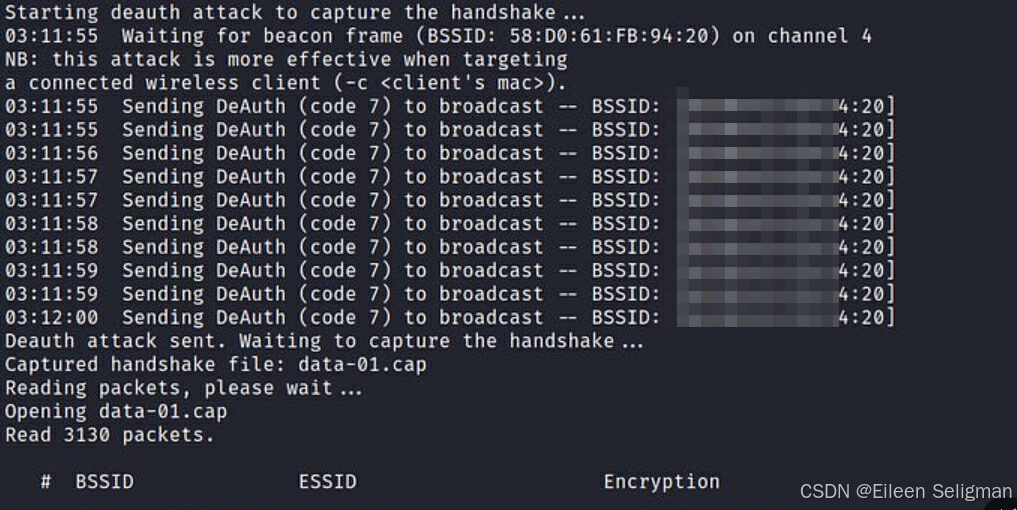
提升无线网络安全:用Python脚本发现并修复WiFi安全问题
文章目录 概要环境准备技术细节3.1 实现原理3.2 创建python文件3.3 插入内容3.4 运行python脚本 加固建议4.1 选择强密码4.2 定期更换密码4.3 启用网络加密4.4 关闭WPS4.5 隐藏SSID4.6 限制连接设备 小结 概要 在本文中,我们将介绍并展示如何使用Python脚本来测试本…...
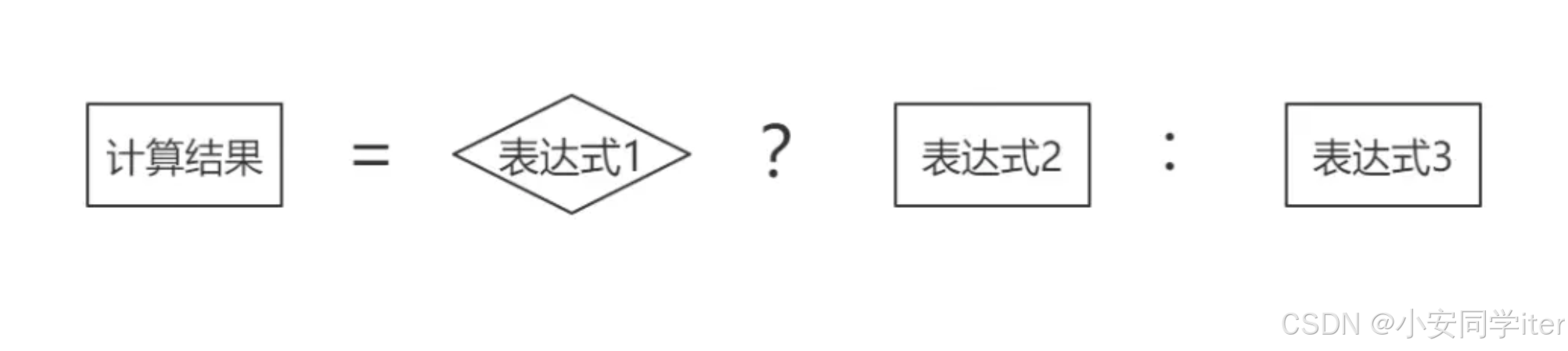
#三元运算符(python/java/c)
引入:什么是三元运算符呢?无疑其操作元有三个,一个是条件表达式,剩余两个为值,条件表达式为真时运算取第一个值,为假时取第二个值。 一 Python true_expression if condition else false_expressi…...

探索Python自然语言处理的新篇章:jionlp库介绍
探索Python自然语言处理的新篇章:jionlp库介绍 1. 背景:为什么选择jionlp? 在Python的生态中,自然语言处理(NLP)是一个活跃且不断发展的领域。jionlp是一个专注于中文自然语言处理的库,它提供了…...
Deepin系统,中盛科技温湿度模块读温度纯c程序(备份)
#include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <termios.h>int main() {int fd;struct termios options;// 打开串口设备fd open("/dev/ttyMP0", O_RDWR | O_NOCTTY|O_NDELAY); //O_NDELAY:打开设备不阻塞//O_NOCTT…...

文件包含漏洞: 函数,实例[pikachu_file_inclusion_local]
文件包含 文件包含是一种较为常见技术,允许程序员在不同的脚本或程序中重用代码或调用文件 主要作用和用途: 代码重用:通过将通用函数或代码段放入单独的文件中,可以在多个脚本中包含这些文件,避免重复编写相同代码。…...

基于PyTorch Geometric的交通网络流量预测与优化
基于PyTorch Geometric的交通网络流量预测与优化 【免费下载链接】pytorch_geometric Graph Neural Network Library for PyTorch 项目地址: https://gitcode.com/GitHub_Trending/py/pytorch_geometric 问题定义:破解城市交通网络的复杂性挑战 交通网络的图…...

Balena Etcher:三步完成系统镜像烧录,告别复杂命令的困扰
Balena Etcher:三步完成系统镜像烧录,告别复杂命令的困扰 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾经因为需要制作系统启动…...

解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南
解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南 【免费下载链接】openkore A free/open source client and automation tool for Ragnarok Online 项目地址: https://gitcode.com/gh_mirrors/op/openkore 在MMORPG游戏领域,重复刷怪、繁琐…...

从BiomixQA到黄帝内经:聊聊2024年那些‘小而美’的垂直医学问答数据集
2024医学垂直问答数据集全景:从BiomixQA到黄帝内经的实战选型指南 当ChatGPT在通用领域大放异彩时,医学AI的战场正悄然转向那些"小而美"的垂直数据集。不同于通用语料的粗放式训练,专业医学问答需要精确到细胞级的语义理解——一个…...

TouchGal:一站式Galgame社区解决方案终极指南
TouchGal:一站式Galgame社区解决方案终极指南 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next 还在为寻找Galgame资源而四…...

别再死记硬背TTS原理了!用Python+TensorFlow复现一个简易Deep Voice,从音素到语音全流程拆解
用PythonTensorFlow实战Deep Voice:从音素到语音的完整实现指南 当你第一次听到计算机生成的语音时,是否好奇过这背后的魔法是如何实现的?现代文本转语音(TTS)系统已经能够产生几乎与真人无异的语音,而Deep Voice作为早期端到端TT…...

mPLUG-Owl3-2B在教育、工作、生活中的10个实用场景分享
mPLUG-Owl3-2B在教育、工作、生活中的10个实用场景分享 1. 引言:多模态AI如何改变我们的日常 想象一下,当你随手拍下一张植物照片,AI不仅能告诉你它的学名,还能详细解释它的生长习性和养护要点;当你面对一份复杂的工…...
)
从Gridworld到吃豆人:用Python拆解强化学习三大核心算法(值迭代、策略调参、Q学习)
从Gridworld到吃豆人:Python实战强化学习三大核心算法 1. 强化学习基础与马尔可夫决策过程 想象一下,你正在训练一只小狗完成障碍赛跑。每次它正确跳过障碍,你会给予零食奖励;如果撞到障碍,则没有任何奖励。经过多次尝…...
)
告别黑盒操作:详解mmc_utils在Android设备上的20+个实用命令(从extcsd读到RPMB写)
eMMC深度操作指南:解锁mmc-utils的20个高阶应用场景 当你的Android设备出现存储性能下降、分区异常或安全验证需求时,系统自带的工具往往束手无策。此时,一个被低估的神器mmc-utils正躺在Linux内核源码树中等待被唤醒——它不仅能够读取eMMC芯…...

OpenClaw多模态扩展:结合百川2-13B-4bits与OCR的图像信息处理流程
OpenClaw多模态扩展:结合百川2-13B-4bits与OCR的图像信息处理流程 1. 为什么需要多模态能力扩展? 上周我需要整理一批技术文档的截图,包含代码片段、错误日志和流程图。手动转录不仅耗时,还容易出错。这让我开始思考:…...