【Redis】Redis 是如何保证高可用的?(背诵版)
Redis 是如何保证高可用的?
- 1. 说一下 Redis 是如何保证高可用的?
- 2. 了解过主从复制么?
- 2.1 Redis 主从复制主要的作用是什么?
- 2.2 Redis 主从模式的拓扑结构?
- (1)一主一从结构
- (2)一主多从
- (3)树状结构
- 2.3 说一下 Redis 主从复制的原理吧?
- 2.4 Redis 主从复制有哪些方式?
- 2.4.1 全量复制
- 2.4.2 增量复制
- 2.4.3 如何确定执⾏全量同步还是部分同步?
- 2.5 主从复制的场景下,从节点会删除过期数据么?
- 2.6 主从复制有哪些问题呢?
- 3. 了解过 Redis Sentinel(哨兵)么?
- 3.1 Redis Sentinel 的主要功能是什么?
- 3.2 说一下 Redis Sentinel 的实现原理吧?
- (1) 定时监控
- (2) sentinel 投票选举主从切换
- (3) 通过 pub/sub 实现客户端事件通知
- 3.3 Redis Sentinel 选举机制的原理是什么?
- (1)筛选
- (2)综合评估
- 3.4 Redis Sentinel 有哪些问题?
- 4. 了解过 Redis Cluster(集群)么?
- 4.1 为什么用 Redis Cluster?
- (1)便于垂直拓展(scale up)和水平拓展(scale out)
- (2)数据分区
- (3)高可用
- 4.2 Redis Cluster 和 replication + sentinel 如何选择?
- 4.3 说一下 Redis Cluster 的实现原理吧?
- 4.3.1 集群的组群过程
- 4.3.2 集群数据分片原理
- 4.3.3 故障转移
- 4.4 客户端如何定位数据所在实例?
- 4.4.1 定位数据所在节点
- 4.4.2 重新分配哈希槽
- 4.5 集群可以设置多⼤?
- 4.6 简单的说一下 Gossip 消息吧?
1. 说一下 Redis 是如何保证高可用的?
Redis 保证高可用主要有三种方式:主从、哨兵、集群。
-
机器宕机,数据丢失 -> Redis
持久化机制; -
并发量激增 -> Redis
主从模式; -
主从稳定性 -> Redis Sentinel
哨兵模式; -
单节点的写能力、存储能力、动态扩容出现瓶颈 -> Redis Cluster
集群模式。
2. 了解过主从复制么?

Redis 提供的主从模式,是通过复制的方式,将主服务器上的 Redis 的数据同步复制一份到从 Redis 服务器,这种做法很常见,MySQL 的主从也是这么做的。
主节点的 Redis 我们称之为 Master,从节点的 Redis 我们称之为 Slave,主从复制为单向复制,只能由主到从,不能由从到主。可以有多个从节点,比如1主2从甚至n从,从节点的多少根据实际的业务需求来判断。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
2.1 Redis 主从复制主要的作用是什么?
-
数据冗余: 主从复制实现了
数据的热备份,是持久化之外的一种数据冗余方式; -
故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复(实际上是一种
服务的冗余); -
负载均衡: 在主从复制的基础上,配合
读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量; -
高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的
基础,因此说主从复制是 Redis 高可用的基石;
2.2 Redis 主从模式的拓扑结构?
(1)一主一从结构
最简单的拓扑结构,一般适用于没有太大的并发场景。 当 master 宕机时,slave 提供故障转移支持。

(2)一主多从
适用于并发量较大的场景,一般都是读多写少。客户端可以将读命令发送到 salve 节点分担 master 节点压力,实现读写分离架构,当然也保证了高可用。但是该架构需要避免复制风暴。

(3)树状结构
slave 节点除了在 master 复制数据,也可以在其他 slave 节点复制数据。主要是通过引用复制中间层,降低 master 节点的负载和需要传送给从节点的数据量,这种架构可以避免复制风暴,但是延长了数据一致性。

2.3 说一下 Redis 主从复制的原理吧?
-
建立连接
-
从节点的配置⽂件中的
replicaof配置项中配置了主节点的ip和port后,从节点就知道⾃⼰要和那个主节点进⾏连接了。 -
从库执⾏ replicaof 并发送
psync命令,表示要执⾏数据同步,主库收到命令后根据参数启动复制。
-
-
主库同步数据给从库
-
master 执⾏
bgsave命令⽣成 RDB ⽂件,并将⽂件发送给从库,同时主库为每⼀个 slave 开辟⼀块 replication buffer 缓冲区记录从⽣成 RDB ⽂件开始收到的所有写命令。 -
从库收到 RDB ⽂件后保存到磁盘,并清空当前数据库的数据,再加载 RDB ⽂件数据到内存中。
-
-
发送新写命令到从库
- 从节点加载 RDB 完成后,主节点将 replication buffer 缓冲区的数据(
增量写命令)发送到从节点,slave 接收并执⾏,从节点同步⾄主节点相同的状态。
- 从节点加载 RDB 完成后,主节点将 replication buffer 缓冲区的数据(
-
基于⻓连接的命令传播
-
当主从库完成了全量复制,它们之间就会⼀直维护⼀个⽹络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为
基于⻓连接的命令传播,使⽤⻓连接的⽬的就是避免频繁建⽴连接导致的开销。 -
在命令传播阶段,除了发送写命令,主从节点还维持着⼼跳机制:
PING和REPLCONF ACK。
-
2.4 Redis 主从复制有哪些方式?
Redis 2.8+ 使用 psync 命令完成主从数据同步,主从刚连接的时候,进⾏全量同步;全量同步结束后,进⾏增量同步。
2.4.1 全量复制

-
从库执⾏ replicaof 并发送
psync命令,表示要执⾏数据同步,主库收到命令后根据参数启动复制。命令包含了 主库的 runID 和 复制进度 offset 两个参数。 -
由于是第一次进行复制,没有 runID 和 offset,发送 psync ? -1。
-
主库收到
psync命令后,会⽤FULLRESYNC响应命令带上两个参数:主库 runID 和主库 复制进度 offset,返回给从库。 -
从库收到响应后,会记录下 主库 runID 和 复制进度 offset。
-
master 执⾏ bgsave 命令⽣成 RDB ⽂件,并将⽂件发送给从库,同时主库为每⼀个 slave 开辟⼀块
replication buffer缓冲区记录从⽣成 RDB ⽂件开始收到的所有写命令。 -
从库收到 RDB ⽂件后保存到磁盘,并
清空当前数据库的数据,再加载 RDB ⽂件数据到内存中。 -
从节点加载 RDB 完成后,master 将 replication buffer 缓冲区的数据发送到从节点,slave 接收并执⾏,从节点同步⾄主节点相同的状态,保证
主从之间数据一致性。 -
slave 加载完 RDB 后,如果当前节点开启了 AOF 持久化功能, 它会立刻做 bgrewriteaof 操作,为了保证全量复制后 AOF 持久化文件立刻可用。
2.4.2 增量复制

在 Redis 2.8 之前,如果主从库在命令传播时出现了⽹络闪断,那么,从库就会和主库重新进⾏⼀次全量复制,开销⾮常⼤。
从 Redis 2.8 开始,⽹络中断等情况后的复制,只将中断期间主节点执⾏的写命令发送给从节点,与全量复制相⽐更加⾼效。
-
当主从节点之间网络出现中断时,如果超过
repl-timeout时间,主节点会认为从节点故障并中断复制连接。 -
主从连接中断期间, master 会将写指令操作记录在
repl_backlog_buffer中(默认最大缓存1MB),repl_backlog_buffer 是⼀个定⻓的环形数组,如果数组内容满了,就会从头开始覆盖前⾯的内容。 -
master 使⽤
master_repl_offset记录⾃⼰写到的位置偏移量,slave 则使⽤slave_repl_offset记录已经读取到的偏移量。正常情况下,这两个偏移量基本相等。在⽹络断连阶段,主库可能会收到新的写操作命令,所以 master_repl_offset > slave_repl_offset 。 -
当主从断开重连后,slave 会先发送 psync 命令给 master,同时将⾃⼰的 runID , slave_repl_offset 发送给 master。
-
master 只需要把 master_repl_offset 与 slave_repl_offset 之间的命令同步给从库即可。
2.4.3 如何确定执⾏全量同步还是部分同步?

2.5 主从复制的场景下,从节点会删除过期数据么?
为了主从节点的数据⼀致性,从节点不会主动删除数据。我们知道 Redis 有两种删除策略:
-
定期删除: Redis 通过定时任务删除过期数据。
-
惰性删除: 当客户端查询对应的数据时,Redis 判断该数据是否过期,过期则删除。
那客户端通过从节点读取数据会不会读取到过期数据?
- Redis 3.2 开始,通过从节点读取数据时,先判断数据是否已过期。如果过期则不返回客户端,并且删除数据。
2.6 主从复制有哪些问题呢?
-
故障恢复⽆法⾃动化:一旦 master 出现故障,需要手动将一个 slave 晋升为 master,同时需要修改应用方的 master 地址,还需要命令其他 slave 去复制新的 master,整个过程都需要人工干预。
-
写操作⽆法负载均。
-
存储能⼒受到单机的限制。
3. 了解过 Redis Sentinel(哨兵)么?
主从复制存在一个问题,没法完成自动故障转移。所以我们需要一个方案来完成自动故障转移,确保整个 Redis 系统的可⽤。它就是Redis Sentinel(哨兵)。

-
哨兵至少需要
3个实例,来保证自己的健壮性; -
哨兵 + Redis主从 的部署架构,
不保证数据零丢失,只能保证 Redis 集群的高可用性。
3.1 Redis Sentinel 的主要功能是什么?
Redis Sentinel 在不使用 Redis 集群时为 Redis 提供高可用性。结合 官方文档 - Redis Sentinel,可以知道 Redis 哨兵具备的能⼒有如下⼏个:
-
监控(Monitoring): sentine 会不断地检查 master 和 slave 是否运作正常。
-
自动故障转移(Automatic failover): 当 master 运⾏故障,sentine 启动⾃动故障恢复流程:从 slave 中选择⼀台作为新 master;
-
配置提供者(Configuration provider): 如果故障转移发生了,通知 client 客户端新的 master 地址;
-
通知(Notification): 让 slave 执⾏ replicaof ,与新的 master 同步;并且通知客户端与新 master 建⽴连接;
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移。而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
3.2 说一下 Redis Sentinel 的实现原理吧?
哨兵模式是通过哨兵节点完成对数据节点的监控、下线、故障转移。

(1) 定时监控
-
Redis 利用
pub/sub实现哨兵间通信和发现 slave; -
每隔 10s,每个 sentinel 节点会向主节点和从节点发送
INFO命令获取最新的拓扑结构; -
每隔 2s,每个 sentinel 节点会向Redis数据节点的
_sentine_:hello频道上发送该 sentinel 节点对于主节点的判断以及当前 sentinel 节点的信息; -
每隔 1s,每个 sentinel 节点会向主节点、从节点、其余 sentinel 节点发送一条
PING命令做一次心跳检测,来确认这些节点当前是否可达。
(2) sentinel 投票选举主从切换
哨兵利用 PING 命令来监测 master、 slave 实例节点的生命状态。如果是无效回复,哨兵就把这个实例节点标记为 「主观下线(sdown)」。
当 sentinel 集群里的实例过半判断 master 已经 「主观下线」 了,这时候我们就把 master 标记为 「客观下线(odown)」。
领导者 sentinel 节点选举:sentinel 节点之间会做一个领导者选举的工作,选出一个 sentinel 节点作为领导者进行故障转移的工作。Redis 使用了 Raft 算法实现领导者选举。
(3) 通过 pub/sub 实现客户端事件通知
通过 pub/sub 机制,发布不同事件,让客户端在这里订阅消息。客户端可以订阅哨兵的消息,哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。
3.3 Redis Sentinel 选举机制的原理是什么?
sentinel 的一个很重要工作,就是从多个 slave 中选举出一个新的 master。当然,这个选举的过程会比较严谨,需要通过筛选 + 综合评估方式进行选举。
(1)筛选
-
过滤掉不健康的(下线或者断线),没有回复哨兵 PING 命令的从节点;
-
评估 Redis 实例过往的网络连接状况
down-after-milliseconds,如果一定周期内(如24h)从库和主库经常断连,而且超出了一定的阈值(如 10 次),则该 slave 不予考虑。
这样,就保留下比较健康的实例了。
(2)综合评估
筛选掉不健康的实例之后,我们就可以对于剩下健康的实例按顺序进行综合评估了:
-
slave 优先级:通过 slave-priority 配置项(redis.conf),可以给不同的从库设置不同优先级,优先级高的优先成为 master;
-
选择数据偏移量差距最小的:即 slave_repl_offset 与 master_repl_offset 进度差距,其实就是比较 slave 与原 master 复制进度差距;
-
slave runID:在优先级和复制进度都相同的情况下,选用 runID 最小的,runID 越小说明创建时间越早,优先选为 master。先来后到原则。
等这几个条件都评估完,我们就会选择出最适合 slave,把他推举为新的 master。
3.4 Redis Sentinel 有哪些问题?
-
并发:单节点的读写能力有限(Redis 并发量 10万 / 每秒 ,但是有些业务需要 100万的 QPS); -
大数据:单节点的存储能力不足, 动态扩容很麻烦(普通机器 16~256g,而我们的业务需要500g)。
4. 了解过 Redis Cluster(集群)么?
Redis Cluster 是⼀种分布式数据库⽅案,集群通过分⽚(sharding)来进⾏数据管理(分治思想的⼀种实践),并提供复制和故障转移功能。
Redis Cluster 采用无中心结构,每个节点都可以保存数据和整个集群状态,每个节点都和其他所有节点连接。要让集群正常运作至少需要三个主节点,即 Redis Cluster 至少为 6 个实例才能保证组成完整高可用的集群。
其中三个 master 会分配不同的 slot(表示数据分片区间),当 master 出现故障时,slave 会自动选举成为 master 顶替主节点继续提供服务。

4.1 为什么用 Redis Cluster?
(1)便于垂直拓展(scale up)和水平拓展(scale out)
单机的吞吐无法承受持续扩增的流量的时候,最好的办法是从垂直拓展(scale up)和水平拓展(scale out)两方面进行扩展:
-
垂直扩展(scale up):将单个实例的硬件资源做提升,比如 CPU核数量、内存容量、SSD容量。
-
水平扩展(scale out):水平扩增 Redis 实例数,这样每个节点只负责一部分数据就可以,分担一下压力,典型的分治思维。

-
垂直拓展(scale up)部署简单,但是当数据量⼤并且使⽤ RDB 实现持久化,会造成阻塞导致响应慢。另外受限于硬件和成本,拓展内存的成本太⼤,⽐如拓展到 1T 内存。
-
⽔平拓展(scale out)便于拓展,同时不需要担⼼单个实例的硬件和成本的限制。但是,切⽚集群会涉及多个实例的分布式管理问题,需要解决如何将数据合理分布到不同实例,同时还要让客户端能正确访问到实例上的数据。
(2)数据分区
数据分区(或称数据分片)是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
(3)高可用
集群支持主从复制和主节点的 自动故障转移(与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。
4.2 Redis Cluster 和 replication + sentinel 如何选择?
-
Replication:一个 master,多个 slave,要几个 slave 跟你的要求的读吞吐量有关系,结合 sentinel 集群,去保证 Redis 主从架构的高可用就行了;
-
Redis Cluster:主要是针对
海量数据 + 高并发 + 高可用的场景,海量数据,如果数据量很大,建议用 Redis Cluster。
4.3 说一下 Redis Cluster 的实现原理吧?
Redis Cluster 通过数据分区来实现数据的分布式存储,通过自动故障转移实现高可用。
4.3.1 集群的组群过程
- 设置节点:
Redis 集群一般由多个节点组成,节点数量至少为 6个 才能保证组成完整高可用的集群。每个节点需要开启配置 cluster-enabled yes,让Redis 运行在集群模式下。
- 节点握手:
各个节点的联通是通过 CLUSTER MEET 命令完成的:CLUSTER MEET <ip> <port> 。其中一个节点 node 向另⼀个节点 node (指定 ip 和 port)发送 CLUSTER MEET 命令,这样就可以让两个节点进⾏握⼿(handshake),当握⼿成功后,node 节点就会将指定 ip 和 port 的节点添加到 node 节点当前所在的集群中。就这样一步步的将需要聚集的节点都圈入同一个集群中。
4.3.2 集群数据分片原理
整个 Redis 数据库被划分为16384个哈希槽,Redis 集群可能有 n 个实例节点,每个节点可以处理 0个 到至多 16384个 槽点,这些节点把 16384个槽位瓜分完成。每个节点对应若干个槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。
哈希槽⼜是如何映射到 Redis 实例上呢?
-
一种是初始化的时候
均匀分配,使用 cluster create 创建,会将 16384 个 slots 平均分配在我们的集群实例上,比如你有n个节点,那每个节点的槽位就是 16384 / n 个了 。 -
另一种是通过 CLUSTER MEET 命令将 node1、node2、ndoe3 三个节点联通成一个集群,刚联通的时候因为还没分配哈希槽,所以处于 offline 状态。可以使⽤
cluster addslots命令,指定每个实例上的哈希槽个数。
4.3.3 故障转移
- 故障检测:
(1)每个节点都会定期向其他节点发送 PING 命令,如果接受 PING 消息的节点在指定时间内没有回复 PONG,则会认为该节点失联了(PFail),则发送 PING 的节点就把接受 PING 的节点标记为主观下线。
(2)如果集群半数以上的主节点都将主节点 xxx 标记为主观下线,则节点 xxx 将被标记为客观下线,然后向整个集群广播,让其它节点也知道该节点已经下线,并立即对下线的节点进行主从切换。
- 主从故障转移
当一个从节点发现自己正在复制的主节点进入了已下线,则开始对下线主节点进行故障转移:

4.4 客户端如何定位数据所在实例?
4.4.1 定位数据所在节点
Redis 中的每个实例节点会将自己负责的哈希槽信息通过 Gossip协议 广播给集群中其他的实例,实现了slots 分配信息的扩散。这样的话,每个实例都知道整个集群的哈希槽分配情况以及映射信息。
客户端想要快捷的连接到服务端,并对某个 Redis 数据进行快捷访问,一般是经过以下步骤:
-
客户端连接集群的任一实例,获取到 slots 与实例节点的映射关系,并将该映射关系的信息缓存在本地;
-
将需要访问的 Redis 信息的 key,经过 CRC16 计算后,再对 16384 取模得到对应的 slot 索引,返回所有 slots 与实例的映射信息;
-
通过 slot 的位置进一步定位到具体所在的实例,再发送请求到对应的实例上。

4.4.2 重新分配哈希槽
哈希槽与实例之间的映射关系由于新增实例或者负载均衡重新分配导致改变了怎么办?
集群中的实例通过 Gossip 协议互相传递消息获取最新的哈希槽分配信息,但是,客户端⽆法感知。
Redis Cluster 提供了重定向机制:客户端将请求发送到实例上,这个实例没有相应的数据,该 Redis 实例会告诉客户端将请求发送到其他的实例上。
Redis 如何告知客户端重定向访问新实例呢?
分为两种情况:MOVED 错误、ASK 错误。
MOVED 错误(负载均衡,数据已经迁移到其他实例上):当客户端将⼀个键值对操作请求发送给某个实例,⽽这个键所在的槽并⾮由⾃⼰负责的时候,该实例会返回⼀个 MOVED 错误指引转向正在负责该槽的节点。
GET redis:pointer
(error) MOVED 16330 192.168.0.1:6379
该响应表示客户端请求的键值对所在的哈希槽 16330 迁移到了 192.168.0.1 这个实例上,端⼝是 6379。这样客户端就与 192.168.0.1:6379 建⽴连接,并发送 GET 请求。
同时,客户端还会更新本地缓存,将该 slot 与 Redis 实例对应关系更新正确。
如果某个 slot 的数据⽐较多,部分迁移到新实例,还有⼀部分没有迁移怎么办?
如果请求的 key 在当前节点找到就直接执⾏命令,否则时候就需要 ASK 错误响应,槽部分迁移未完成的情况下,如果需要访问的 key 所在 slot 正在从 实例1 迁移到 实例2,实例1 会返回客户端⼀条 ASK 报错信息:客户端请求的 key 所在的哈希槽正在迁移到 实例2 上,先给 实例2 发送⼀个 ASKING 命令,接着发送操作命令。
GET redis:pointer
(error) MOVED 16330 192.168.0.1:6379
⽐如客户端请求定位到 key = redis:pointer 的槽 16330 在实例 192.168.0.1 上,节点1 如果找得到就直接执⾏命令,否则响应 ASK 错误信息,并指引客户端转向正在迁移的⽬标节点 192.168.0.1。
注意:ASK 错误指令并不会更新客户端缓存的哈希槽分配信息。
所以客户端再次请求 slot 16330 的数据,还是会先给 192.168.0.1 实例发送请求,只不过节点会响应 ASK 命令让客户端给新实例发送⼀次请求。MOVED 指令则更新客户端本地缓存,让后续指令都发往新实例。
4.5 集群可以设置多⼤?
Redis Cluster 可以⽆限⽔平拓展么?
答案是否定的,Redis 官⽅给的 Redis Cluster 的规模上线是 1000 个实例。
关键在于实例间的通信开销,Cluster 集群中的每个实例都保存所有哈希槽与实例对应关系信息(slot 映射到节点的表),以及⾃身的状态信息。
4.6 简单的说一下 Gossip 消息吧?
发送的消息结构是 clusterMsgDataGossip 结构体组成:
typedef struct {char nodename[CLUSTER_NAMELEN]; //40字节uint32_t ping_sent; //4字节uint32_t pong_received; //4字节char ip[NET_IP_STR_LEN]; //46字节uint16_t port; //2字节uint16_t cport; //2字节uint16_t flags; //2字节uint32_t notused1; //4字节
} clusterMsgDataGossip
所以每个实例发送⼀个 Gossip 消息,就需要发送 104 字节。如果集群是 1000 个实例,那么每个实例发送⼀个 PING 消息则会占⽤⼤约 10KB。
除此之外,实例间在传播 slot 映射表的时候,每个消息还包含了 ⼀个⻓度为 16384 bit 的 Bitmap。每⼀位对应⼀个 slot,如果值 = 1 则表示这个 slot 属于当前实例,这个 Bitmap 占⽤ 2KB,所以⼀个 PING 消息⼤约 12KB。
PONG 与 PING 消息⼀样,⼀发⼀回两个消息加起来就是 24 KB。集群规模的增加,⼼跳消息越来越多就会占据集群的⽹络通信带宽,降低了集群吞吐量。
PS:至此,Redis 高可用的总结就告一段落了,大家抓紧背起来吧(同属共同学习阶段,如有不正,欢迎指出)。
相关文章:
【Redis】Redis 是如何保证高可用的?(背诵版)
Redis 是如何保证高可用的?1. 说一下 Redis 是如何保证高可用的?2. 了解过主从复制么?2.1 Redis 主从复制主要的作用是什么?2.2 Redis 主从模式的拓扑结构?(1)一主一从结构(2)一主多…...

Qt---去掉标题栏后,最大化应用程序窗口时,窗口遮住了任务栏
// showMaximized(); // Qt最大化显示函数 任务栏都会覆盖static bool max false;static QRect location this->geometry();if (max) {this->setGeometry(location);//回复窗口原大小和位置// ui->maxBtn->setIcon(QIcon(":/MAX_.png"));}else {// ui-…...
报告详解)
Cadence Allegro 导出Netin(non-back)报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Netin(non-back)作用3,Netin(non-back)示例4,Netin(non-back)导出方法4.1,方法1:4.2,方法2:B站关注“硬小二”浏览更多演示视频...
HTML语言
1.什么是HTML? 1、HTML是超文本标记语言(Hyper Text Markup Language) 2、HTML由各种各样的标签(tag)组成,如、 3、HTML文档 网页 (1)一种纯文本文件,扩展名为.html或.html; (2)最终显示结果取决…...

线性代数之行列式
一、思维导图二、二阶、三阶行列式的定义1、二阶行列式2、三阶行列式沙路法展开3、解方程3.1解二元一次方程组观察上面两个未知量的值不难发现,它 们的分母均是上述方程组未知量的系数形成的二阶行列式,𝑥1的分子是将系数行列 式的第一列换成…...

【FPGA-Spirit_V2】小精灵V2开发板初使用
🎉欢迎来到FPGA专栏~小精灵V2开发板初使用 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:FPGA学习之旅 文章作者技术和水平有限,如果文中出现错误,希望大家…...
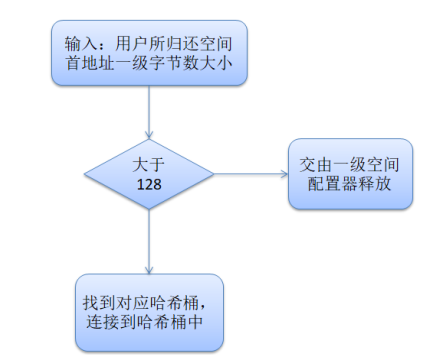
STL与其空间配置器
目录什么是STLSTL的六大组件STL的缺陷什么是空间配置器为什么需要空间配置器GI-STL空间配置器实现原理一级空间配置器二级空间配置器内存池SGI-STL中二级空间配置器设计SGI-STL二级空间配置器之空间申请前期的准备申请空间填充内存块向内存池中索要空间SGI-STL二级空间配置器之…...
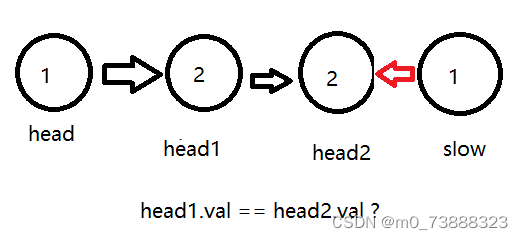
leetcode刷题之回文链表
目录 做题思路 代码实现 1.找到链表的中间节点 2.反转中间节点之后的链表 3.判断倒置的后半部分的链表是否等于前半部分的链表 整体代码展示 总结: 这里是题目链接。 这道题目的意思是:判断该链表中后半部分倒置是否跟前半部分相同,如…...

复制带随机指针的链表最长连续递增序列数组的度写字符串需要的行数最短补全词
复制带随机指针的链表来源:杭哥138. 复制带随机指针的链表 - 力扣(LeetCode)typedef struct Node Node; Node* BuyNode(int x) {Node* newnode (Node*)malloc(sizeof(Node));newnode->valx;newnode->nextNULL;newnode->randomNULL;…...

「ML 实践篇」回归系统:房价中位数预测
文章目录1. 项目分析1. 框架问题2. 性能指标2. 获取数据1. 准备工作区2. 下载数据3. 查看数据4. 创建测试集3. 数据探索1. 地理位置可视化2. 寻找相关性3. 组合属性4. 数据准备1. 数据清理2. Scikit-Learn 的设计3. 处理文本、分类属性4. 自定义转换器5. 特征缩放6. 流水线5. 选…...

深度学习 Day27——利用Pytorch实现运动鞋识别
深度学习 Day27——利用Pytorch实现运动鞋识别 文章目录深度学习 Day27——利用Pytorch实现运动鞋识别一、查看colab机器配置二、前期准备1、导入依赖项并设置GPU2、导入数据三、构建CNN网络四、训练模型1、编写训练函数2、编写测试函数3、设置动态学习率4、正式训练五、结果可…...

Springboot 整合dom4j 解析xml 字符串 转JSONObject
前言 本文只介绍使用 dom4j 以及fastjson的 方式, 因为平日使用比较多。老的那个json也能转,而且还封装好了XML,但是本文不做介绍。 正文 ①加入 pom 依赖 <dependency><groupId>dom4j</groupId><artifactId>dom4j…...

网络安全实验——安全通信软件safechat的设计
网络安全实验——安全通信软件safechat的设计 仅供参考,请勿直接抄袭,抄袭者后果自负。 仓库地址: 后端地址:https://github.com/yijunquan-afk/safechat-server 前端地址: https://github.com/yijunquan-afk/safec…...
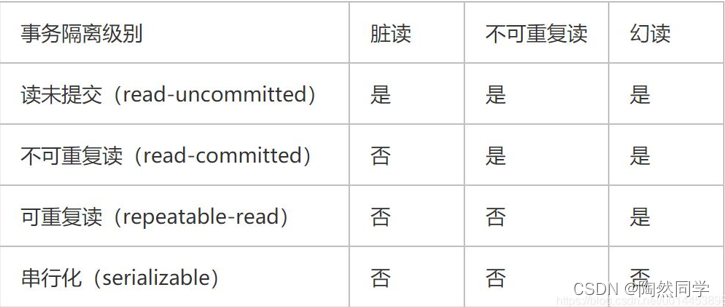
【MySQL】MySQL的事务
目录 概念 什么是事务? 理解事务 事务操作 事务的特性 事务的隔离级别 事务的隔离级别-操作 概念 数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查 询、更新和删除数据。 不同的存储引擎提供…...
Java分布式事务(七)
文章目录🔥Seata提供XA模式实现分布式事务_业务说明🔥Seata提供XA模式实现分布式事务_下载启动Seata服务🔥Seata提供XA模式实现分布式事务_转账功能实现上🔥Seata提供XA模式实现分布式事务_转账功能实现下🔥Seata提供X…...

二十八、实战演练之定义用户类模型、迁移用户模型类
1. Django默认用户模型类 (1)Django认证系统中提供了用户模型类User保存用户的数据。 User对象是认证系统的核心。 (2)Django认证系统用户模型类位置 django.contrib.auth.models.User(3)父类AbstractUs…...

Java Virtual Machine的结构 3
1 Run-Time Data Areas 1.1 The pc Register 1.2 Java Virtual Machine Stacks 1.3 Heap 1.4 Method Area JVM方法区是在JVM所有线程中共享的内存区域,在编程语言中方法区是用于存储编译的代码、在操作系统进程中方法区是用于存储文本段,在JVM中方法…...
linux ubuntu22 安装neo4j
环境:neo4j 5 ubuntu22 openjdk-17 neo4j 5 对 jre 版本要求是 17 及以上,且最好是 openjdk,使用比较新的 ubuntu 系统安装比较好, centos7 因为没有维护,yum 找不到 openjdk-17了。 官方的 debian 系列安装教程&a…...
模型实战(7)之YOLOv8推理+训练自己的数据集详解
YOLOv8推理+训练自己的数据集详解 最近刚出的yolov8模型确实很赞啊,亲测同样的数据集用v5和v8两个模型训练+预测,结果显示v8在检测精度和准确度上明显强于v5。下边给出yolov8的效果对比图: 关于v8的结构原理在此不做赘述,随便搜一下到处都是。1.环境搭建 进入github进行git…...

火车进出栈问题 题解
来源 卡特兰数 个人评价(一句话描述对这个题的情感) …~%?..,# *☆&℃$︿★? 1 题面 一列火车n节车厢,依次编号为1,2,3,…,n。每节车厢有两种运动方式,进栈与出栈,问n节车厢出栈的可能排列方式有多少种。 输入…...

AI编码助手安全护栏:Claude代码生成规则引擎实战指南
1. 项目概述:为AI编码助手装上“护栏”最近在折腾AI辅助编程,特别是用Claude这类大模型来写代码,效率提升确实明显。但用久了就会发现一个问题:模型生成的代码,有时候会“放飞自我”。比如,它可能会引入一些…...
:深入剖析启动文件与BOOT模式)
【STM32F407启动探秘】从复位向量到main():深入剖析启动文件与BOOT模式
1. STM32F407启动过程全景图 当你按下STM32F407开发板的电源按钮时,芯片内部就像被施了魔法一样开始运转。这个看似简单的上电过程,实际上隐藏着一套精密的启动机制。作为开发者,理解这个过程就像掌握了一把打开STM32内核奥秘的钥匙。 我刚开…...

告别环境配置噩梦:用Shell脚本一键搞定VCS与Verdi的联调环境
芯片验证工程师的效率革命:Shell脚本全自动构建VCSVerdi联调环境 每次开始新项目都要重复配置验证环境?还在为VCS编译选项和Verdi波形调试的手动操作浪费时间?资深验证工程师的日常,不该被这些重复劳动占据。本文将带你用Shell脚本…...

ARM MPAM内存系统监控器架构与配置详解
1. ARM MPAM内存系统监控器架构解析在ARMv9架构中,MPAM(Memory Partitioning and Monitoring)作为关键的内存资源管控机制,为多租户环境提供了硬件级的资源隔离与性能监控能力。其核心设计理念是通过PARTID(Partition …...
给你的数据曲线做个‘美容’)
别再只用Matplotlib画图了!用Python这3个库(SciPy, NumPy, Scikit-learn)给你的数据曲线做个‘美容’
Python数据平滑三剑客:用Savitzky-Golay、插值与滑动平均打造专业级图表 当你面对满是噪点的折线图时,是否想过这些锯齿状的波动正在掩盖数据的真实故事?就像摄影师不会直接发布未经修饰的RAW格式照片,数据科学家也需要掌握图表美…...

从零到一:基于iSYSTEM winIDEA与IC5000的嵌入式程序烧写与调试实战指南
1. 环境准备:搭建你的嵌入式开发工作台 第一次接触iSYSTEM工具链时,我完全被各种专业术语搞懵了。后来才发现,只要把环境搭好,后面的操作就像拼乐高一样简单。这里我会手把手带你配置好winIDEA和IC5000调试器,避开那些…...
)
2026AI急救点合规生死线:GDPR+《人工智能医疗应用管理办法》双轨审计 checklist(仅限首批参会者获取)
更多请点击: https://intelliparadigm.com 第一章:2026AI急救点合规性定义与时代紧迫性 2026AI急救点(AI Emergency Point, AIEP)并非传统意义上的物理站点,而是由国家AI治理框架强制要求部署的、具备实时风险拦截、模…...

靠谱糯米鸡机器厂家选择:企业采购决策关键因素分析
靠谱糯米鸡机器厂家选择:企业采购决策关键因素分析"选对糯米鸡机器厂家,不是看价格,而是看能否解决你的量产痛点!"企业采购糯米鸡机器时,常陷入"价格优先"的误区,忽略产能适配、品控稳…...

WeChatMsg完整指南:如何永久保存并深度分析你的微信聊天记录
WeChatMsg完整指南:如何永久保存并深度分析你的微信聊天记录 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

用STC89C516和74HC138做个计算器:从矩阵按键扫描到动态数码管显示的完整流程
STC89C51674HC138计算器实战:从硬件设计到动态扫描的深度解析 1. 硬件架构设计精要 在嵌入式系统开发中,IO资源管理始终是硬件设计的核心挑战。STC89C516作为经典51内核单片机,仅有32个通用IO口,当需要驱动8位数码管和16键矩阵键盘…...