基于词级ngram的词袋模型对twitter数据进行情感分析
按照阿光的项目做出了学习笔记,pytorch深度学习实战项目100例
基于词级ngram的词袋模型对twitter数据进行情感分析
什么是 N 符?
N 格是指给定文本或语音样本中 n 个项目的连续序列。这些项目可以是音素、音节、字母、单词或碱基对,具体取决于应用。N-grams 广泛应用于计算语言学和文本分析中的各种任务,如文本预测、拼写校正、语言建模和文本分类。它们为文本挖掘和自然语言处理(NLP)提供了一种简单而有效的方法。
###了解 N 符
n-gram 的概念很简单:它是由 ‘n’ 个连续项组成的序列。下面是一个细分:
- Unigram (n=1): 单个项目或单词。
- Bigram (n=2): 一对连续的项目或单词。
- Trigram(n=3): 连续的三联项或词。

示例
考虑一下这个句子: “敏捷的棕狐狸跳过懒惰的狗"。
- Unigram: “The“、”quick“、”brown“、”fox“、”jumps“、”over“、”the“、”l lazy“、”dog”
- Bigram: “快“、”棕色快“、”棕色狐狸“、”狐狸跳“、”跳过“、”过“、”懒“、”懒狗”
- Trigram: “棕色的快“、”棕色的狐狸快“、”棕色的狐狸跳“、”狐狸跳过“、”跳过“、”跳过懒惰“、”懒惰的狗”
上下文和用途
- Unigram: 除单个词条外,这些词条不包含任何上下文。
- Bigrams: 通过将连续的项目配对,提供最基本的语境。
- Trigrams: 这些词组开始形成更加连贯和与上下文相关的短语。
随着’n’的增加,n-grams 可以捕捉到更多的上下文,但由于计算费用的增加和数据的稀疏性,其收益也会逐渐减少。
###实际应用
N-gram 在各种 NLP 任务中至关重要:
- 文本预测: 预测序列中的下一个词。
- 拼写纠正: 根据上下文识别并纠正拼写错误的单词。
- 语言建模:创建理解和生成人类语言的模型。4.文本分类: 根据内容将文本归入预定义的类别。
通过理解和利用 n-gram,可以提高 NLP 模型在这些任务中的性能和准确性。
Twitter 情感分析数据集包含 1,578,627 条分类推文,每一行的正面情感标记为 1,负面情感标记为 0。我建议使用语料库的 1/10 来测试你的算法,而其余的可以用来训练你用来进行情感分类的任何算法。我试着用一个非常简单的 Naive Bayesian 分类算法来使用这个数据集,结果是 75% 的准确率,考虑到长期的猜测工作方法会达到 50% 的准确率,一个简单的方法可以给你带来比猜测工作高 50% 的性能,这并不是很好,但考虑到一般情况下(尤其是在涉及到社交传播情感分类时),人类进行的 10% 的情感分类是有争议的,任何分析文本整体情感的算法所希望达到的最高相对准确率是 90%,这并不是一个坏的起点。
http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/
x_train, x_test, y_train, y_test = train_test_split(data['SentimentText'], data['Sentiment'], test_size=0.1,random_state=2022)print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
#(682294,) (75811,) (682294,) (75811,)

import pandas as pd
import csv
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_scoretry:data = pd.read_csv('/content/drive/MyDrive/Niek/Sentiment Analysis Dataset.csv', quoting=csv.QUOTE_NONE, on_bad_lines='skip', encoding='utf-8')
except pd.errors.ParserError as e:print(f"Error parsing CSV: {e}")data

TF-IDF 是 Term Frequency Inverse Document Frequency 的缩写。这是一种非常常见的算法,用于将文本转化为有意义的数字表示,并将其用于机器算法的预测。在深入解释之前,让我们先举例说明并探索两种不同的辣味稀疏矩阵。这可以让你对我下面要解释的内容有一个整体的了解。简单的基本示例数据 :
# 初始化TF-IDF向量化器
vectorizer_word = TfidfVectorizer(max_features=40000, # 最多使用40000个特征词min_df=5, # 至少在5个文档中出现的词才会被考虑max_df=0.5, # 在50%以上的文档中出现的词会被忽略analyzer='word', # 词级别的分析stop_words='english', # 去除英语停用词ngram_range=(1, 2)) # 考虑1-2元组# 使用训练数据拟合向量化器
vectorizer_word.fit(x_train.astype("U").str.lower())# 将训练集和测试集文本转化为TF-IDF矩阵
tfidf_matrix_word_train = vectorizer_word.transform(x_train.astype("U").str.lower())
print("TF-IDF Matrix for Training Data (Dense Format):\n")
print(tfidf_matrix_word_train)
tfidf_matrix_word_test = vectorizer_word.transform(x_test.astype("U").str.lower())
print("TF-IDF Matrix for Test Data (Dense Format):\n")
print(tfidf_matrix_word_test)
该代码段首先初始化并训练一个逻辑回归模型,然后使用训练好的模型对训练集和测试集进行预测,最后计算并打印模型在训练集和测试集上的准确性。
# 初始化并训练逻辑回归模型
model = LogisticRegression(solver='sag')
model.fit(tfidf_matrix_word_train, y_train)# 预测训练集和测试集的结果
y_pred_train = model.predict(tfidf_matrix_word_train)
y_pred_test = model.predict(tfidf_matrix_word_test)# 打印训练集和测试集的准确性
print(accuracy_score(y_train, y_pred_train))
#0.8014386845292767
print(accuracy_score(y_test, y_pred_test))
#0.7856396908790025
代码资源
相关文章:
基于词级ngram的词袋模型对twitter数据进行情感分析
按照阿光的项目做出了学习笔记,pytorch深度学习实战项目100例 基于词级ngram的词袋模型对twitter数据进行情感分析 什么是 N 符? N 格是指给定文本或语音样本中 n 个项目的连续序列。这些项目可以是音素、音节、字母、单词或碱基对,具体取…...
)
Linux-Centos-改密码(单用户登陆)
笔记一: centos7单用户修改root密码 在CentOS 7中,如果您是唯一的用户或者您确信其他用户不会登录,您可以按照以下步骤来修改root密码: 1.重启系统。 2.启动时出现引导界面时,按任意键进入GRUB菜单。 3.选择要启动的内…...

java实现OCR图片识别,RapidOcr开源免费
先看一下识别效果(自我感觉很牛逼),比Tess4J Tesseract省事,这个还需要训练,安装软件、下载语言包什么的 很费事,关键识别率不高 RapidOcr不管文字的横竖,还是斜的都能识别(代码实现…...

PCB工艺边设计准则
在PCB设计时,通常会在电路板的边缘预留一定的空间,这部分空间被称为工艺边。它有助于在生产过程中确保电路板的尺寸和形状的准确性。以使得组装时更加顺畅、便捷。而工艺边的加工,使得线路板上的元件可以精准地与设备对接,从而提高…...

CTF-NSSCTF题单[GKCTF2020]
[GKCTF 2020]CheckIN 这道题目考察:php7-gc-bypass漏洞 打开这道题目,开始以为考察反序列化,但实际并不是,这里直接用$_REQUEST传入了参数便可以利用了。这里出现了一个eval()函数,猜测考察命…...
)
redis的分片集群(仅供自己参考)
前言:为什么使用分片集群:因为redis的主从和哨兵机制主要是用来解决redis的高并发读的问题,还有redis的高并发的写的问题没有解决。使用分片集群就可以很好的解决redis写的问题,有多个master就可以实现并发的写。同时,…...

自动驾驶-机器人-slam-定位面经和面试知识系列01之常考公式推导(01)
李群李代数扰动bundle adjustment 这个博客系列会分为C STL-面经、常考公式推导和SLAM面经面试题等三个系列进行更新,基本涵盖了自己秋招历程被问过的面试内容(除了实习和学校项目相关的具体细节)。在知乎和牛客也会同步更新,全网…...

netty入门-5 ServerBootstrap与Bootstarp
前言 本来这篇应该紧接着说明Future和Promise。 但是考虑前文第三篇即用到了ServerBootstrap来启动一个服务器,并且我读的闪电侠netty,先写的服务器与客户端启动这部分。索性就先写出来了。主要内容来自闪电侠netty ServerBootstrap ServerBootstrap就…...

JavaEE - Spring Boot 简介
1.Maven 1.1 什么是Maven 翻译过来就是: Maven是⼀个项⽬管理⼯具。基于POM(Project Object Model,项⽬对象模型)的概念,Maven可以通 过⼀⼩段描述信息来管理项⽬的构建,报告和⽂档的项⽬管理⼯具软件。 可以理解为:Maven是一个项目管理工具…...

SwiftUI革新:Xcode UI开发的新纪元
SwiftUI革新:Xcode UI开发的新纪元 SwiftUI作为Apple推出的声明式UI框架,彻底改变了在Xcode中构建用户界面的方式。它不仅简化了代码,还提高了开发效率,并且使得UI设计更加直观和灵活。本文将深入探讨如何在Xcode中使用SwiftUI进…...

22、基于共享内存的数据结构——用十个块来提高并发性
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 为了提高并发性,把…...

【ffmpeg命令入门】实现画中画
文章目录 前言画中画是什么画中画的外观描述效果展示为什么要用画中画应用场景示例 使用FFmpeg添加画中画示例命令参数解释调整嵌入视频的位置调整嵌入视频的大小处理音频 总结 前言 FFmpeg 是一款强大的多媒体处理工具,广泛用于音视频的录制、转换和流处理。它不仅…...

基于 LangChain+LangGraph 来实现一个翻译项目
相信大家在看文档的时候,有时会比较苦恼,比如 AI 相关的文档都是外文,中文文档比较少,看起来会比较吃力,有的时候会看不懂,翻译软件又翻得很乱,完全看不了,今天就基于 LangChain 和 …...

javascript 如何将 json 格式数组转为 excel 表格| sheetJS
案例 // https://unpkg.com/xlsx0.18.5/dist/xlsx.full.min.js function exportXlsx(jsonData, fileName , mine null) {const workbook XLSX.utils.book_new();// 将JSON数组转换成工作表const worksheet XLSX.utils.json_to_sheet(jsonData);// 向工作簿添加工作表XLSX.…...

网页制作技术在未来会如何影响人们的生活?
网页制作技术在未来会如何影响人们的生活? 李升伟 网页制作技术在未来可能会从以下几个方面显著影响人们的生活: 1. 工作与学习方式的变革:远程办公和在线教育将更加普及和高效。通过精心制作的网页,人们能够实现更便捷的协作…...

【计算机网络】网络层——IPv4地址(个人笔记)
学习日期:2024.7.24 内容摘要:IPv4地址,分类编址,子网,无分类编址 IPv4地址概述 在TCP/IP体系中,IP地址是一个最基本的概念,IPv4地址就是给因特网上的每一台主机的每一个接口分配一个在全世界…...

c++ 学习笔记之多线程:线程锁,条件变量,唤醒指定线程
基于CAS线程加锁方式 CAS(Compare-And-Swap)和 mutex 都是用于实现线程安全的技术,但它们适用于不同的场景,具有不同的性能和复杂性。下面是对两者的区别和使用场景的详细解释: CAS(Compare-And-Swap&…...

《0基础》学习Python——第二十三讲__网络爬虫/<6>爬取哔哩哔哩视频
一、在B站上爬取一段视频(B站视频有音频和视频两个部分) 1、获取URL 注意:很多平台都有反爬取的机制,B站也不例外 首先按下F12找到第一条复制URL 2、UA伪装,下列图片中(注意代码书写格式) 3、Co…...

第13周 简历职位功能开发与Zookeeper实战
第13周 简历职位功能开发与Zookeeper实战 本章概述1. Mysql8窗口函数over使用1.1 演示表结构与数据1.2 案例1:获取男女总分数1.3 案例2****************************************************************************************本章概述 1. Mysql8窗口函数over使用 参考案例…...
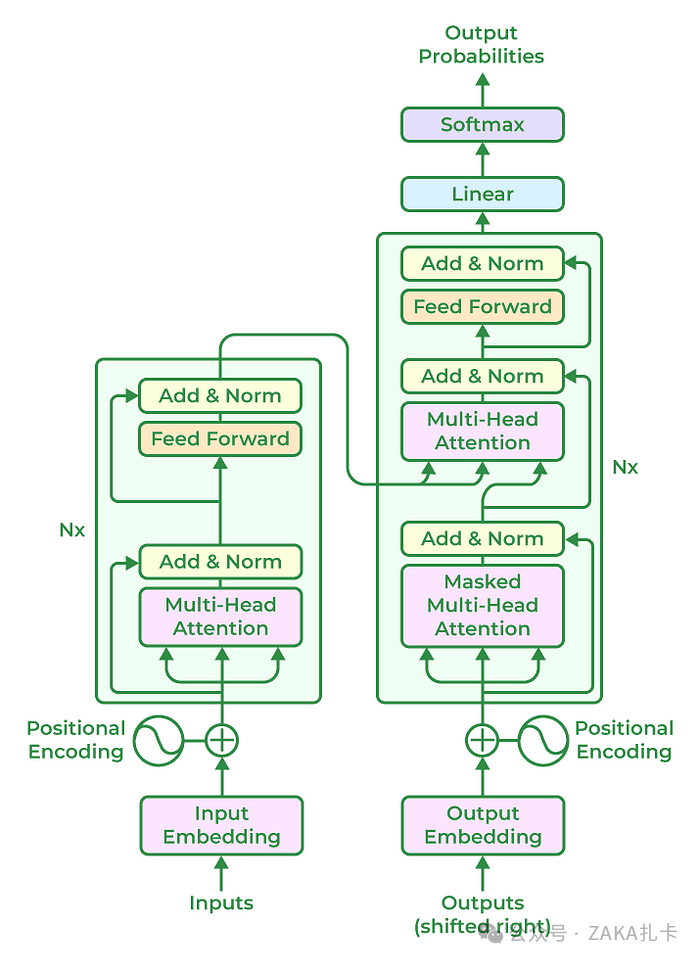
什么是大型语言模型 (LLM)
本章探讨下,人工智能如何彻底改变我们理解和与语言互动的方式 大型语言模型 (LLM) 代表了人工智能的突破,它采用具有广泛参数的神经网络技术进行高级语言处理。 本文探讨了 LLM 的演变、架构、应用和挑战,重点关注其在自然语言处理 (NLP) 领…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...