什么是大型语言模型 (LLM)
本章探讨下,人工智能如何彻底改变我们理解和与语言互动的方式
大型语言模型 (LLM) 代表了人工智能的突破,它采用具有广泛参数的神经网络技术进行高级语言处理。
本文探讨了 LLM 的演变、架构、应用和挑战,重点关注其在自然语言处理 (NLP) 领域的影响。

什么是大型语言模型(LLM)?
大型语言模型是一种人工智能算法,它应用具有大量参数的神经网络技术,使用自监督学习技术来处理和理解人类语言或文本。文本生成、机器翻译、摘要写作、文本图像生成、机器编码、聊天机器人或对话式人工智能等任务都是大型语言模型的应用。此类 LLM 模型的示例包括 Open AI 的 Chat GPT、Google 的 BERT(来自 Transformers 的双向编码器表示)等。
有许多技术尝试执行与自然语言相关的任务,但 LLM 纯粹基于深度学习方法。LLM(大型语言模型)模型能够高效地捕捉手头文本中的复杂实体关系,并且可以使用我们希望使用的特定语言的语义和句法来生成文本。
LLM 模型
如果我们只谈论 GPT (生成式预训练 Transformer) 模型的进步规模,那么:
·2018 年发布的 GPT-1 包含 1.17 亿个参数,有 9.85 亿个单词。
·2019年发布的GPT-2包含15亿个参数。
·2020 年发布的 GPT-3 包含 1750 亿个参数。Chat GPT 也是基于这个模型。
·GPT-4模型预计将于2023年发布,可能包含数万亿个参数。
大型语言模型如何工作?
大型语言模型 (LLM) 依据深度学习原理运行,利用神经网络架构来处理和理解人类语言。
这些模型使用自监督学习技术在大量数据集上进行训练。其功能的核心在于它们在训练过程中从各种语言数据中学习到的复杂模式和关系。LLM 由多个层组成,包括前馈层、嵌入层和注意层。它们采用注意机制(如自注意力)来衡量序列中不同标记的重要性,从而使模型能够捕获依赖关系和关系。
(LLM) 的架构
大型语言模型 (LLM) 的架构由许多因素决定,例如特定模型设计的目标、可用的计算资源以及 LLM 要执行的语言处理任务类型。LLM 的一般架构由许多层组成,例如前馈层、嵌入层、注意层。嵌入其中的文本相互协作以生成预测。
影响大型语言模型架构的重要组件——
·模型大小和参数数量
·输入表示
·自注意力机制
·培训目标
·计算效率
·解码和输出生成
基于 Transformer 的 LLM 模型架构
基于 Transformer 的模型彻底改变了自然语言处理任务,它通常遵循包含以下组件的通用架构:
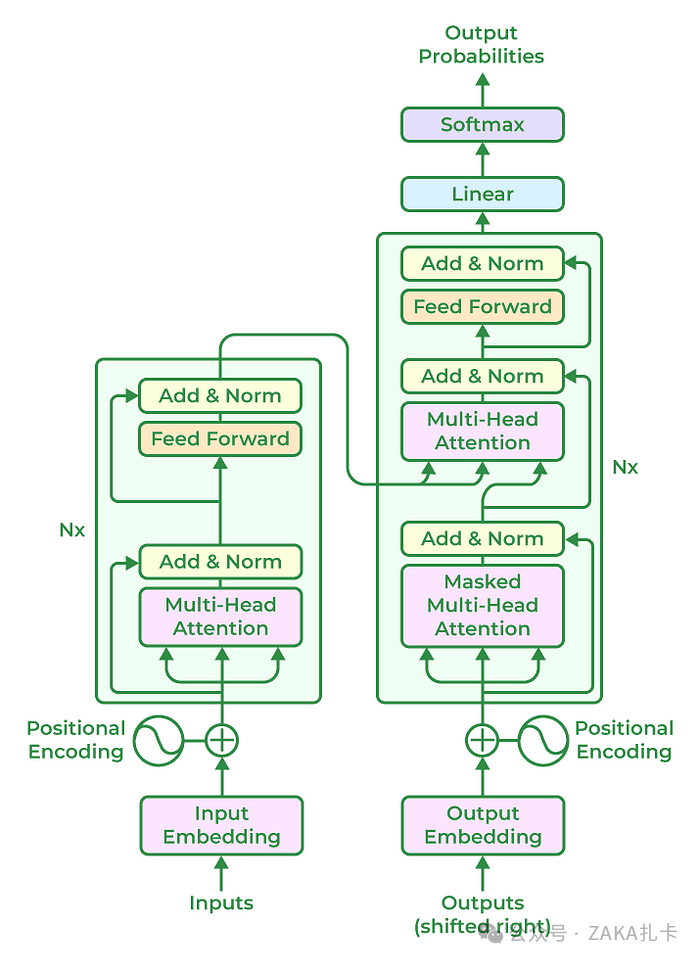
1.**输入嵌入:**将输入文本标记为较小的单元,例如单词或子单词,并将每个标记嵌入到连续向量表示中。此嵌入步骤捕获输入的语义和句法信息。
2.**位置编码:**位置编码被添加到输入嵌入中,以提供有关标记位置的信息,因为转换器不会自然地对标记的顺序进行编码。这使模型能够在考虑标记的顺序的同时处理标记。
3.**编码器:**编码器基于神经网络技术,分析输入文本并创建多个隐藏状态,以保护文本数据的上下文和含义。多个编码器层构成了 Transformer 架构的核心。自注意力机制和前馈神经网络是每个编码器层的两个基本子组件。
4.**自注意力机制:**自注意力机制使得模型能够通过计算注意力分数来衡量输入序列中不同 token 的重要性。它允许模型以上下文感知的方式考虑不同 token 之间的依赖关系和关系。
5.**前馈神经网络:**在自注意力步骤之后,前馈神经网络将独立应用于每个 token。该网络包括具有非线性激活函数的全连接层,允许模型捕获 token 之间的复杂交互。
6.**解码器层:**在一些基于 Transformer 的模型中,除了编码器外,还包含解码器组件。解码器层支持自回归生成,其中模型可以通过关注先前生成的标记来生成顺序输出。
7.多头注意力: Transformer 通常采用多头注意力,其中自注意力与不同的学习注意力权重同时执行。这使模型能够捕捉不同类型的关系并同时关注输入序列的各个部分。
8.层规范化: Transformer 架构中每个子组件或层之后都应用层规范化。它有助于稳定学习过程,并提高模型在不同输入之间进行泛化的能力。
9.输出层: Transformer 模型的输出层可能因具体任务而异。例如,在语言建模中,通常使用线性投影后跟 SoftMax 激活来生成下一个 token 的概率分布。
需要记住的是,基于 Transformer 的模型的实际架构可以根据特定研究和模型创建进行更改和增强。为了完成不同的任务和目标,GPT、BERT 和 T5 等多个模型可能会集成更多组件或修改。
大型语言模型示例
·GPT-3:GPT 的全称是生成式预训练 Transformer,这是该模型的第三个版本,因此编号为 3。这是由 Open AI 开发的,你一定听说过由 Open AI 推出的 Chat GPT,它就是 GPT-3 模型。
·**BERT——**全称是 Transformers 的双向编码器表示。这种大型语言模型由 Google 开发,通常用于与自然语言相关的各种任务。此外,它还可用于为特定文本生成嵌入,或用于训练其他模型。
·**RoBERTa——**其全称是鲁棒优化 BERT 预训练方法。在一系列提高 Transformer 架构性能的尝试中,RoBERTa 是 Facebook AI Research 开发的 BERT 模型的增强版本。
·**BLOOM——**这是第一个由不同组织和研究人员联合产生的多语言法学硕士,他们结合自己的专业知识开发出类似于 GPT-3 架构的模型。
要进一步探索这些模型,您可以单击特定模型以了解如何使用开源平台(如 Open AI 的 Hugging Face)来使用它们。这些文章介绍了 Python 中每个模型的实现部分。
LLM 如此受欢迎的主要原因是它们能够高效地完成各种任务。从以上关于 LLM 的介绍和技术信息中,您一定已经了解到 Chat GPT 也是 LLM,因此,让我们用它来描述大型语言模型的用例。
·代码生成——这项服务最疯狂的用例之一是,它可以为用户向模型描述的特定任务生成相当准确的代码。
·代码调试和文档编制— 如果您在调试某段代码时遇到困难,那么 ChatGPT 就是您的救星,因为它可以告诉您哪一行代码产生了问题以及纠正这些问题的办法。此外,现在您不必花费数小时编写项目文档,您可以让 ChatGPT 为您完成这项工作。
·问答——您一定已经看到,当人工智能个人助理发布时,人们常常向他们提出一些疯狂的问题,那么您也可以在这里这样做,以及提出真正的问题。
·语言转换——它可以将一段文本从一种语言转换为另一种语言,因为它支持 50 多种母语。它还可以帮助您纠正内容中的语法错误。
LLM 的使用案例不仅限于上述内容,只要有足够的创造力来编写更好的提示,您就可以让这些模型执行各种任务,因为它们经过训练可以执行一次性学习和零次学习方法的任务。正因为如此,对于那些期待广泛使用 ChatGPT 类型模型的人来说,只有 Prompt Engineering 才是学术界的一个全新热门话题。
大型语言模型应用
GPT-3 等 LLM 在各个领域都有广泛的应用。其中包括:
自然语言理解 (NLU)
1.大型语言模型为能够进行自然对话的高级聊天机器人提供动力。
2.它们可用于创建智能虚拟助手,执行调度、提醒和信息检索等任务。
内容生成
1.创建类似人类的文本以用于各种目的,包括内容创作、创意写作和讲故事。
2.根据自然语言描述或命令编写代码片段。
语言翻译
大型语言模型可以帮助提高不同语言之间的文本翻译的准确性和流畅度。
文本摘要
生成较长的文本或文章的简洁摘要。
情绪分析
分析和理解社交媒体帖子、评论和评价中表达的情感。
NLP和LLM之间的区别
NLP 是自然语言处理,是人工智能 (AI) 的一个领域。它包括算法的开发。NLP 是一个比 LLM 更广泛的领域,后者包括算法和技术。NLP 规则两种方法,即机器学习和分析语言数据。NLP 的应用包括:
·汽车常规任务
·改进搜索
·搜索引擎优化
·分析和组织大型文档
·社交媒体分析。
另一方面,LLM 是一种大型语言模型,更针对类似人类的文本,提供内容生成和个性化推荐。
大型语言模型有哪些优势?
大型语言模型 (LLM) 具有多种优势,有助于其在各种应用中得到广泛采用和成功:
·LLM 可以执行零样本学习,这意味着它们可以推广到未经明确训练的任务。此功能允许在无需额外训练的情况下适应新的应用程序和场景。
·LLM能够高效处理大量数据,适合执行需要深入理解大量文本语料库的任务,例如语言翻译和文档摘要。
·LLM 可以在特定数据集或领域进行微调,从而实现持续学习并适应特定用例或行业。
·LLM可以实现各种与语言相关的任务的自动化,从代码生成到内容创建,从而释放人力资源以用于项目中更具战略性和更复杂的方面。
大型语言模型训练的挑战
人们对法学硕士未来的能力毫不怀疑,这项技术是大多数人工智能应用程序的一部分,每天都会被多个用户使用。但法学硕士也有一些缺点。
·为了成功训练大型语言模型,需要投入数百万美元来建立能够利用并行性能训练模型的强大计算能力。
·它需要数月的训练,然后由人类参与对模型进行微调,以实现更好的性能。
·获取大量文本语料库可能是一项艰巨的任务,因为 ChatGPT 被指控仅使用非法抓取的数据进行训练,并为商业目的构建应用程序。
·在全球变暖和气候变化的时代,我们不能忘记法学硕士的碳足迹,据说从头开始训练一个人工智能模型的碳足迹相当于五辆汽车在其整个生命周期内的碳足迹,这是一个真正严重的问题。
结论
由于在训练中面临的挑战,LLM 迁移学习被大力推广,以摆脱上述所有挑战。LLM 有能力为人工智能应用带来革命,但该领域的进步似乎有点困难,因为仅仅增加模型的大小可能会提高其性能,但在特定时间之后,性能就会达到饱和,处理这些模型的挑战将大于通过进一步增加模型大小所实现的性能提升。
相关文章:
什么是大型语言模型 (LLM)
本章探讨下,人工智能如何彻底改变我们理解和与语言互动的方式 大型语言模型 (LLM) 代表了人工智能的突破,它采用具有广泛参数的神经网络技术进行高级语言处理。 本文探讨了 LLM 的演变、架构、应用和挑战,重点关注其在自然语言处理 (NLP) 领…...

【人工智能】AI时代:探索个人潜能的新视角
文章目录 🍊Al时代的个人发展1 AI的高速发展意味着什么1.1 生产力大幅提升1.2 生产关系的改变1.3 产品范式1.4 产业革命1.5 Al的局限性1.5.1局限一:大模型的幻觉1.5.2 局限二:Token 2 个体如何应对这种改变?2.1 职场人2.2 K12家长2.3 大学生2.4 创业者 …...

pyaudio VAD通过声音音频值分贝大小检测没人说话自动停止录制
效果可能说话声音小可能不被监听到,需要更改QUIET_DB阈值,另外delay_time值是低于阈值多久就可以停止保存当前的语音 import pyaudio import waveimport sys import numpy as npdef record_auto(MIC_INDEX=1):开启麦克风录音,保存至temp/speech_record.wav音频文件音量超过…...
《后端程序猿 · @Value 注释说明》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数…...

【LeetCode】71.简化路径
1. 题目 2. 分析 3. 代码 我写了一版很复杂的代码: class Solution:def simplifyPath(self, path: str) -> str:operator [] # 操作符的栈dir_name [] # 文件名的栈idx 0cur_dir_name ""while(idx < len(path)):if path[idx] /:operator.ap…...

DockerCompose 安装环境
1. Redis version: 3 services:redis:image: redis:6.2.12container_name: redisports:- "6379:6379"environment:TZ: Asia/Shanghaivolumes:# 本地数据目录要先执行 chmod 777 /usr/local/docker/redis/data 赋予读写权限,否则将无法写入数据- /usr/loc…...

学习笔记之JAVA篇(0724)
p 方法 方法声明格式: [修饰符1 修饰符2 ...] 返回值类型 方法名(形式参数列表){ java语句;......; } 方法调用方式 普通方法对象.方法名(实参列表)静态方法类名.方法名(实参列表) 方法的详…...
【Android】广播机制
【Android】广播机制 前言 广播机制是Android中一种非常重要的通信机制,用于在应用程序之间或应用程序的不同组件之间传递信息。广播可以是系统广播,也可以是自定义广播。广播机制主要包括标准广播和有序广播两种类型。 简介 在Android中,…...

【.NET全栈】ASP.NET开发Web应用——ASP.NET数据绑定技术
文章目录 前言一、绑定技术基础1、单值绑定2、重复值绑定 二、数据源控件1、数据绑定的页面生存周期2、SqlDataSource3、使用参数过滤数据4、更新数据和并发处理5、编程执行SqlDataSource命令6、ObjectDataSource控件介绍7、创建业务对象类8、在ObiectDataSource中使用参数9、使…...

MySQL的账户管理
目录 1 密码策略 1.1 查看数据库当前密码策略: 1.2 查看密码设置策略 1.3 密码强度检查等级解释(validate_password.policy) 2 新建登录账户 3 账户授权 3.1 赋权原则 3.2 常见的用户权限 3.3 查看权限 3.4 赋权语法 4 实例 4.1 示例1&#x…...

FastGPT 源码调试配置
目录 一、添加 launch.json 文件 二、调试 本文简单介绍如何通过 vscode 对 FastGPT 进行调试。 这里假设已经安装 vsocde 和 FastGPT本地部署。 一、添加 launch.json 文件 vscode 打开 FastGPT 项目,点击 调试 -> 显示所有自动调试配置 -> 添加配置 -> Node.j…...
使用指南)
SQL Server数据迁移新纪元:数据库数据泵(Data Pump)使用指南
SQL Server数据迁移新纪元:数据库数据泵(Data Pump)使用指南 在数据管理的世界里,数据迁移是一个常见且复杂的过程。SQL Server提供了一个强大的工具——数据库数据泵(Data Pump),它可以帮助我…...

Android性能优化之OOM
OOM 什么是OOM?为什么会有OOM?APP的内存限制App的内存限制是多少? 为什么Android系统要设定App的内存限制?Android有GC自动回收资源,为什么还会OOM?容易发生OOM的场景及处理方案如何避免OOM? 什么是OOM&am…...
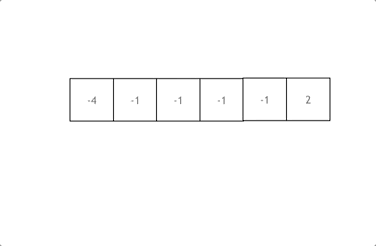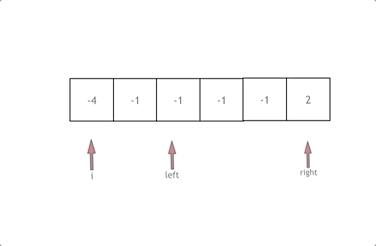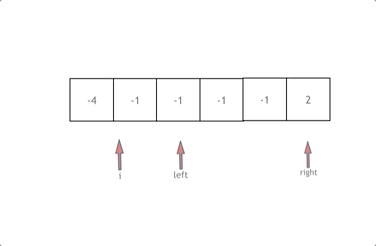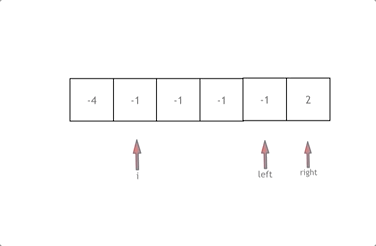
代码随想录算法训练营day7 | 454.四数相加II、383.赎金信、15.三数之和、18.四数之和
文章目录 454.四数相加II思路 383.赎金信思路 15.三数之和思路剪枝去重 18.四数之和思路剪枝去重复习:C中的类型转换方法 总结 今天是哈希表专题的第二天 废话不多说,直接上题目 454.四数相加II 建议:本题是 使用map 巧妙解决的问题&#x…...

Spark实时(三):Structured Streaming入门案例
文章目录 Structured Streaming入门案例 一、Scala代码如下 二、Java 代码如下 三、以上代码注意点如下 Structured Streaming入门案例 我们使用Structured Streaming来监控socket数据统计WordCount。这里我们使用Spark版本为3.4.3版本,首先在Maven pom文件中导…...

《Java初阶数据结构》----4.<线性表---Stack栈和Queue队列>
前言 大家好,我目前在学习java。之前也学了一段时间,但是没有发布博客。时间过的真的很快。我会利用好这个暑假,来复习之前学过的内容,并整理好之前写过的博客进行发布。如果博客中有错误或者没有读懂的地方。热烈欢迎大家在评论区…...
)
Android SurfaceFlinger——关联EGL三要素(二十七)
通过前面的文章我们得到了 EGL 的三要素——Display、Surface 和 Context。其中,Display 是一个图形显示系统或者硬件屏幕,Surface 代表一个可以被渲染的图像缓冲区,Context 包含了 OpenGL ES 的状态信息和资源,它是执行 OpenGL 命令的环境。下一步就是调用 eglMakeCurrent…...

Unity3D之TCP网络通信(客户端)
文章目录 概述TCP核心类异步机制 Unity中创建TCP客户端Unity中其它脚本获取TCP客户端接受到的数据后续改进 本文将以Unity3D应用项目作为客户端去连接制定的服务器为例进行相关说明。 Unity官网参考资料: https://developer.unity.cn/projects/6572ea1bedbc2a001ef…...

Kotlin 中 标准库函数
在 Kotlin 中,标准库提供了许多实用的函数,这些函数可以帮助简化代码、提高效率,以下是一些常用的标准库函数及其功能: let: let 函数允许你在对象上执行一个操作,并返回结果。它通常与安全调用操作符 ?. 一起使用&a…...

【教学类-69-01】20240721铠甲勇士扑克牌(随机14个数字+字母)涂色(男孩篇)
背景需求: 【教学类-68-01】20240720裙子涂色(女孩篇)-CSDN博客文章浏览阅读250次。【教学类-68-01】20240720裙子涂色(女孩篇)https://blog.csdn.net/reasonsummer/article/details/140578153 前期制作了女孩涂色延…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

基于MAX78000的边缘AI语音识别:从模型训练到嵌入式部署实战
1. 项目概述与核心思路最近在捣鼓一个挺有意思的小项目,我把它叫做“声控转向控制器”。简单来说,这玩意儿能听懂你说的几个特定单词,比如“左转”、“右转”、“前进”、“后退”,然后控制对应的LED灯亮起。你可能会想࿰…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

PyKafka社区贡献指南:从问题报告到代码提交的完整流程
PyKafka社区贡献指南:从问题报告到代码提交的完整流程 【免费下载链接】pykafka Apache Kafka client for Python; high-level & low-level consumer/producer, with great performance. 项目地址: https://gitcode.com/gh_mirrors/py/pykafka 想要为PyK…...

多智能体协作系统:2026年企业级AI应用的核心架构范式
引言:AI Agent从单兵作战到团队协作的范式跃迁 2026年,人工智能领域正在经历一场深刻的架构变革。回想2024年,当ChatGPT、Claude等大语言模型横空出世时,我们惊叹于单个AI模型的强大能力。然而,随着企业级应用的深入,单一AI Agent的局限性日益凸显:它无法同时处理多领域…...