《0基础》学习Python——第二十一讲__网络爬虫/<4>爬取豆瓣电影电影信息
爬取网页数据(获取网页信息全过程)
1、爬取豆瓣电影的电影名称、导演、主演、年份、国家、评价

2、首先我们先爬取页面然后再获取信息
1、爬取网页源码
import requests
from lxml import etree
if __name__ == '__main__':#UA伪装head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'}#获取urlurl='https://img3.doubanio.com/cuphead/movie-static/charts/top_movies.b4c3a.css'#发送请求response=requests.get(url,headers=head)#返回数据类型cont_text=response.text# print(cont_text)#打印数据,用于查看是否爬取成功上述代码即表示爬取了豆瓣电影那一页的网页源码
2、下面将去找想爬取的数据所在标签的位置

因为要爬取一整页面所有的电影而不是单个电影信息,所以需要找到该组电影标签的主标签,如下部分即可发现,将鼠标移到每个li标签下,都会对应左边的每个单独的电影

所以我们就可以通过for循环定位到每个li标签下然后在爬取每个li标签内的电影数据,
找到所有的li标签后在上一级去找有没有单独的属性class或者id,如果找到一个class内容,复制class对应属性的内容,长按Ctrl+F打开查找,看看是否是在总标签下是否是唯一的,这样可以避免去数每一个标签在什么位置,

如上图可发现上述的class对应的属性“grid_view”是独一无二的,那么可以直接通过多层地址直接到达这个标签
3、实操代码
通过以下代码即可获取到所有的电影名称,其中的div[2]表示这个div标签是在当前的上一级标签下是第2个标签,//表示属性定位直接定位到当前目录,./表示在当前目录下,/表示下一级目录,
import requests
from lxml import etree
if __name__ == '__main__':#UA伪装head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'}#获取url# url='https://img3.doubanio.com/cuphead/movie-static/charts/top_movies.b4c3a.css'url = 'https://movie.douban.com/top250'#发送请求response=requests.get(url,headers=head)#返回数据类型cont_text=response.text# print(cont_text)#打印数据,用于查看是否爬取成功#解析数据tree=etree.HTML(cont_text)#获取单个电影所对应标签的主标签# lst=tree.xpath('//ol[@class="grid_view"]/li')#即打印所有li标签下的内容ls1 = tree.xpath('//ol[@class="grid_view"]/li')# print(ls1)for li in ls1: #通过循环遍历所有的li标签,即所有的电影数据name_book=li.xpath('./div/div[2]/div[1]/a/span[]/text()') #通过text()打印数据print(name_book)
其打印结果为

4、返回结果处理
xpath返回的是列表,里面有很多不需要的符号,所以需要再对name_book=li.xpath('./div/div[2]/div[1]/a/span[1]/text()')这段代码在做处理,首先通过join函数去除括号,name_book="".join(li.xpath('./div/div[2]/div[1]/a/span[1]/text()'))
打印结果为

这就是我们需要的电影名字内容,下面将获取导演、、数据,通过下列代码获取这些信息
strs = ''.join(li.xpath(".//div[@class='bd']/p[1]/text()"))print(strs)其输出结果为下列内容

但是有很多空格,同样需要对它进行处理,可以使用strip函数去除左右两边的空格
strs = ''.join(li.xpath(".//div[@class='bd']/p[1]/text()")).strip()print(strs)
但是我们需要的是单独的导演、主演、时间、国家、、,这些是一个完整的字符串,所以需要额外把这些字符串取出来进行额外处理,得到分开的单独数据:
比如取出第一段字符,那么首先可以发现有很多空格,所以使用strip去除,然后调用正则化去处理这段数据,代码如下,其中分别取出时间、国家、导演、主演、剧情
import re
strs="""导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...1994 / 美国 / 犯罪 剧情"""
#中文的正则取值:[\u4e00-\u9fa5]
a=strs.strip() #去除左右空格
time_film=re.match(r'([\s\S]+?)(\d+)([\s\S]+?)',a).group(2) #利用正则的分组关系去除第二组内容,即(\d+)数字的内容,即时间
country=''.join(a.split('/')[-2].split()) #利用/符号切割这个完整字符串,然后取出倒数第二个数据,即国家的数据
juqing=''.join(a.split('/')[-1].split())#利用/符号切割这个完整字符串,然后取出倒数第一个数据,即剧情的数据
daoyan=re.match(r'导演: ([A-Za-z\u4e00-\u9fa5·]+)(\s\S*?)',a).group(1) #使用中文的正则表达式得到导演主演的数据
zhuyan=re.match(r'([\s\S]+?)主演: ([A-Za-z\u4e00-\u9fa5·]+)([\s\S]+?)',a).group(2)
print(time_film)
print(country)
print(juqing)
print(daoyan)
print(zhuyan)其输出结果如下:

即将那一大串字符串全部处理成了独立的我们需要的数据,然后只要把这些代码放入爬虫的那一部分即可,
import re
import requests
from lxml import etree
if __name__ == '__main__':#UA伪装head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'}#获取url# url='https://img3.doubanio.com/cuphead/movie-static/charts/top_movies.b4c3a.css'url = 'https://movie.douban.com/top250'#发送请求response=requests.get(url,headers=head)#返回数据类型cont_text=response.text# print(cont_text)#打印数据,用于查看是否爬取成功#解析数据tree=etree.HTML(cont_text)#获取单个电影所对应标签的主标签# lst=tree.xpath('//ol[@class="grid_view"]/li')#即打印所有li标签下的内容ls1 = tree.xpath('//ol[@class="grid_view"]/li')# print(ls1)for li in ls1: #通过循环遍历所有的li标签,即所有的电影数据name_book="".join(li.xpath('./div/div[2]/div[1]/a/span[1]/text()')) #通过text()打印数据# print(name_book)strs = ''.join(li.xpath(".//div[@class='bd']/p[1]/text()")).strip()# print(strs)a = strs.strip()time_film = re.match(r'([\s\S]+?)(\d+)([\s\S]+?)', a).group(2)country = ''.join(a.split('/')[-2].split())juqing = ''.join(a.split('/')[-1].split())daoyan = re.match(r'导演: ([A-Za-z\u4e00-\u9fa5·]+)(\s\S*?)', a).group(1)zhuyan = re.match(r'([\s\S]+?)主演: ([A-Za-z\u4e00-\u9fa5·]+)([\s\S]+?)', a).group(2)print(time_film)print(country)print(juqing)print(daoyan)print(zhuyan)其得到的结果如下,可以发现其结果有错误,

如下图可以发现这部电影没有主演,只有一个主字,那么就说明我们的正则有缺陷,但是我们也可以跳过这一个电影,因为在大批量的电影中总会有那么一个两个不一样的区别,不能将所有的数据都拿出来额外在做正则,这样也不切实际,所以我们可以使用try语句去判断一下,然后跳过这一步电影的数据

5、完整代码如下
import re
import requests
from lxml import etree
if __name__ == '__main__':fp=open('./douban_film.txt','w',encoding='utf-8') #创建一个文件用来存放电影数据#UA伪装head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'}#获取url# url='https://img3.doubanio.com/cuphead/movie-static/charts/top_movies.b4c3a.css'url = 'https://movie.douban.com/top250'#发送请求response=requests.get(url,headers=head)#返回数据类型cont_text=response.text# print(cont_text)#打印数据,用于查看是否爬取成功#解析数据tree=etree.HTML(cont_text)#获取单个电影所对应标签的主标签# lst=tree.xpath('//ol[@class="grid_view"]/li')#即打印所有li标签下的内容ls1 = tree.xpath('//ol[@class="grid_view"]/li')# print(ls1)for li in ls1: #通过循环遍历所有的li标签,即所有的电影数据name_book="".join(li.xpath('./div/div[2]/div[1]/a/span[1]/text()')) #通过text()打印数据# print(name_book)strs = ''.join(li.xpath(".//div[@class='bd']/p[1]/text()")).strip()# print(strs)a = strs.strip()time_film = re.match(r'([\s\S]+?)(\d+)([\s\S]+?)', a).group(2)try:country = ''.join(a.split('/')[-2].split())juqing = ''.join(a.split('/')[-1].split())daoyan = re.match(r'导演: ([A-Za-z\u4e00-\u9fa5·]+)(\s\S*?)', a).group(1)zhuyan = re.match(r'([\s\S]+?)主演: ([A-Za-z\u4e00-\u9fa5·]+)([\s\S]+?)', a).group(2)except Exception as e:passprint(name_book+"#"+time_film+"#"+daoyan+"#"+zhuyan+"#"+country+"#"+juqing+"\n")#讲捕获的数据全部写入文件内fp.write( name_book + "#" + time_film + "#" + daoyan + "#" + zhuyan + "#" + country + "#" + juqing + "\n")fp.close()左侧发现存放所创建的文本文件,打开后可得到存进去的数据:

相关文章:
《0基础》学习Python——第二十一讲__网络爬虫/<4>爬取豆瓣电影电影信息
爬取网页数据(获取网页信息全过程) 1、爬取豆瓣电影的电影名称、导演、主演、年份、国家、评价 2、首先我们先爬取页面然后再获取信息 1、爬取网页源码 import requests from lxml import etree if __name__ __main__:#UA伪装head{User-Agent:Mozilla/…...

【C++初阶】string类
【C初阶】string类 🥕个人主页:开敲🍉 🔥所属专栏:C🥭 🌼文章目录🌼 1. 为什么学习string类? 1.1 C语言中的字符串 1.2 实际中 2. 标准库中的string类 2.1 string类 2.…...

RAS--APEI 报错解析流程(2)
RAS--APEI 报错解析流程(1) 除了APEI 中除了GHES会记录错误,在Post过程中的错误通常是通过BERT Table汇报 1.BERT Boot Error Record Table is used to report unhandled errors that occurred in a previous boot,it is reported as a ‘one-time polle…...
微软蓝屏事件对企业数字化转型有什么影响?
引言:从北京时间2024年7月19日(周五)下午2点多开始,全球大量Windows用户出现电脑崩溃、蓝屏死机、无法重启等情况。事发后,网络安全公司CrowdStrike称,收到大量关于Windows电脑出现蓝屏报告,公司…...

【Gin】精准应用:Gin框架中工厂模式的现代软件开发策略与实施技巧(上)
【Gin】精准应用:Gin框架中工厂模式的现代软件开发策略与实施技巧(上) 大家好 我是寸铁👊 【Gin】精准应用:Gin框架中工厂模式的现代软件开发策略与实施技巧(上)✨ 喜欢的小伙伴可以点点关注 💝 前言 本次文章分为上下两部分&…...

浅谈Devops
1.什么是Devops DevopsDev(Development)Ops(Operation) DevOps(Development和Operations的混合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”…...

大文件分片上传(前端TS实现)
大文件分片上传 内容 一般情况下,前端上传文件就是new FormData,然后把文件 append 进去,然后post发送给后端就完事了,但是文件越大,上传的文件也就越长,如果在上传过程中,突然网络故障,又或者…...

unity2D游戏开发02添加组件移动玩家
添加组件 给PlayGame和EnemyObject添加组件BoxCollider 2D碰撞器,不用修改参数 给PlayGame添加组件Rigibody 2D 设置数据 添加EnemyObject,属性如下 Edit->project setting->Physics 2D 将 y的值改为0 给playerObject添加标签 新建层 将PlayerObj…...

设计模式 之 —— 单例模式
目录 什么是单例模式? 定义 单例模式的主要特点 单例模式的几种设计模式 1.懒汉式:线程不安全 2.懒汉式:线程安全 3.饿汉式 4.双重校验锁 单例模式的优缺点 优点: 缺点: 适用场景: 什么是单例模…...
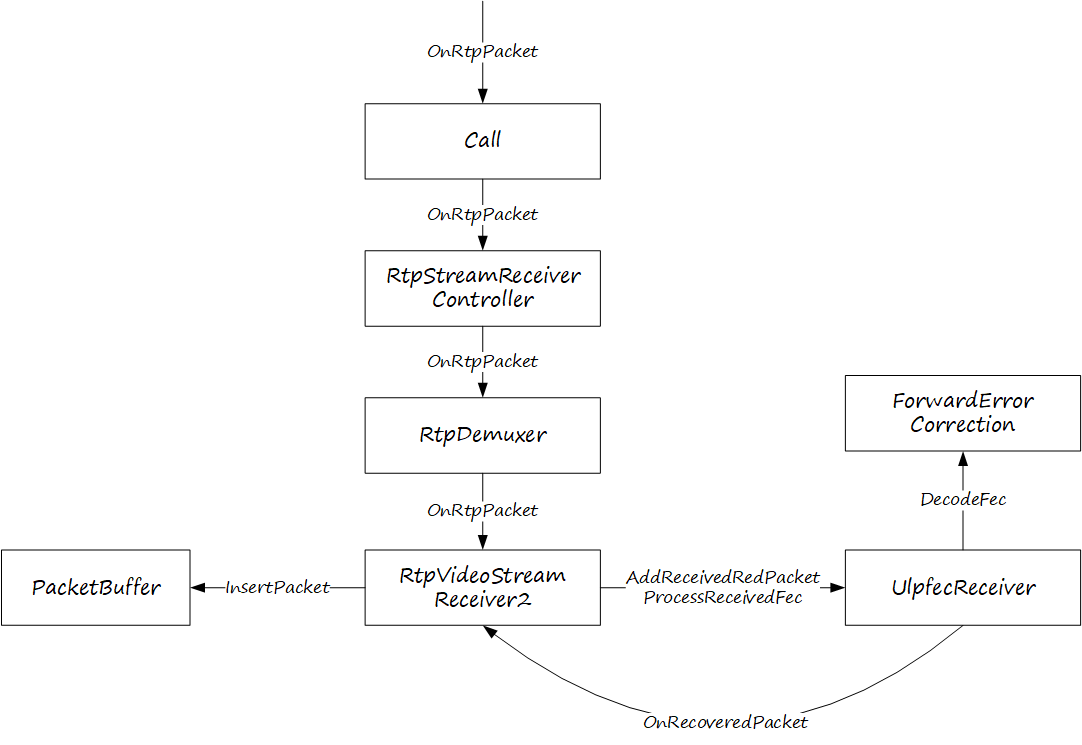
深入浅出WebRTC—ULPFEC
FEC 通过在发送端添加额外的冗余信息,使接收端即使在部分数据包丢失的情况下也能恢复原始数据,从而减轻网络丢包的影响。在 WebRTC 中,FEC 主要有两种实现方式:ULPFEC 和 FlexFEC,FlexFEC 是 ULPFEC 的扩展和升级&…...

Python从0到100(四十三):数据库与Django ORM 精讲
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Pyth…...

Redis-主从模式
目录 前言 一.主从节点介绍 二.配置redis主从结构 二.主从复制 四.拓扑结构 五.数据同步 全量复制(Full Sync Replication) 局部复制(Partial Replication) Redis的学习专栏:http://t.csdnimg.cn/a8cvV 前言 …...
加速决策过程:企业级爬虫平台的实时数据分析
摘要 在当今数据驱动的商业环境中,企业如何才能在海量信息中迅速做出精准决策?本文将探讨企业级爬虫平台如何通过实时数据分析加速决策过程,实现数据到决策的无缝衔接。我们聚焦于技术如何赋能企业,提升数据处理效率,…...
数组实现(只能查26个单词))
字典树(前缀树)数组实现(只能查26个单词)
这段代码实现了一个基于 Trie 树的字典树(Trie)数据结构,用于存储和检索字符串。其中包含以下几个方法. insert(String word): 向 Trie 树中插入一个单词。首先将单词转换为字符数组,然后遍历字符数组,逐个字符在 Trie…...

CTF-pwn-虚拟化-vmmware 前置
文章目录 参考vmware逃逸简介虚拟机和主机通信机制(guest to host)共享内存(弃用)backdoor机制Message_Send和Message_RecvGuestRPC实例RpcOutSendOneRawWork实例 vmware-rpctool info-get guestinfo.ip各个步骤对应的backdoor操作Open RPC channelSend …...

thinkphp8结合layui2.9 图片上传验证
<?php declare (strict_types 1);namespace app\index\validate;use think\Validate;class Upload extends Validate {/*** 定义验证规则* 格式:字段名 > [规则1,规则2...]** var array*/protected $rule [image > fileExt:jpg,png|fileSize:204800|fi…...

农村污水处理难题:探索低成本高效解决方案
农村污水处理难题:探索低成本高效解决方案 农村污水处理作为国家生态文明建设的重要一环,面临着诸多挑战,尤其是技术落后、管理分散、资源匮乏等问题。物联网技术的引入,为解决这些痛点提供了创新途径,实现了对污水处…...

lightningcss介绍及使用
lightningcss介绍及使用 一款使用 rust 编写的 css 解析器,转换器、及压缩器。 特性 特别快:可以在毫秒级别解析、压缩大量的 css 文件,而且比其他工具的打包结果更小给值添加类型:许多其他css解析器会将值解析成一个无类型的 …...

HTTP服务的应用
1、编辑json请求参数; 2、把json发送到服务url,接收服务的返回参数; 3、解析返回参数。 procedure TfrmCustomQuery.btnFullUpdateClick(Sender: TObject); varfrm: TfrmInputQueryConditionEX;b_OK: Boolean;sBeginDate, sEndDate, sJSON…...

uni-app:踩坑路---scroll-view内使用fixed定位,无效的问题
前言: emmm,说起来这个问题整得还挺好笑的,本人在公司内,奋笔疾书写代码,愉快的提交测试的时候,测试跟我说,在苹果手机上你这个样式有bug,我倒是要看看,是什么bug。 安卓…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...