将YOLOv8模型从PyTorch的.pt格式转换为TensorRT的.engine格式
TensorRT是由NVIDIA开发的一款高级软件开发套件(SDK),专为高速深度学习推理而设计。它非常适合目标检测等实时应用。该工具包可针对NVIDIA GPU优化深度学习模型,从而实现更快、更高效的运行。TensorRT模型经过TensorRT优化,包括层融合(layer fusion)、精度校准(precision calibration)(INT8和FP16)、动态张量内存管理和内核自动调整(kernel auto-tuning)等技术。将深度学习模型转换为TensorRT格式可充分发挥NVIDIA GPU的潜力。
TensorRT可兼容各种模型格式,包括TensorFlow、PyTorch和ONNX。
TensorRT模型的主要特点:
(1).Precision Calibration:TensorRT支持精度校准,允许根据特定的精度要求对模型进行微调(fine-tuned)。这包括对INT8和FP16等精度较低的格式的支持,这可以在保持可接受的精度水平的同时进一步提高推理速度。
(2).Layer Fusion:TensorRT优化过程包括层融合,即将神经网络的多个层组合成一个操作。这通过最小化内存访问和计算来减少计算开销并提高推理速度。
(3).Dynamic Tensor Memory Management:TensorRT可有效管理推理过程中的张量内存使用情况,从而减少内存开销并优化内存分配。这可提高GPU内存利用率。
(4).Automatic Kernel Tuning:TensorRT采用自动内核调整,为模型的每一层选择最优化的GPU内核。这种自适应方法可确保模型充分利用GPU的计算能力。
TensorRT中的部署选项:
(1).Deploying within TensorFlow:此方法将TensorRT集成到TensorFlow中,使优化的模型可以在TensorFlow环境中运行。对于混合了受支持层和不受支持的层(a mix of supported and unsupported layers)的模型,此方法非常有用,因为TF-TRT可以高效处理这些层。
(2).Standalone TensorRT Runtime API:提供精细控制,非常适合性能关键型应用程序。它更复杂,但允许自定义实现不受支持的运算符。
(3).NVIDIA Triton Inference Server:支持各种框架模型的选项。它特别适合云端或边缘端推理(cloud or edge inference),提供并发模型(concurrent model)执行和模型分析等功能。
训练生成TensorRT支持的.engine格式模型:
训练代码如下所示:
import argparse
import colorama
from ultralytics import YOLO
import torchdef parse_args():parser = argparse.ArgumentParser(description="YOLOv8 train")parser.add_argument("--yaml", required=True, type=str, help="yaml file")parser.add_argument("--epochs", required=True, type=int, help="number of training")parser.add_argument("--task", required=True, type=str, choices=["detect", "segment"], help="specify what kind of task")args = parser.parse_args()return argsdef train(task, yaml, epochs):if task == "detect":model = YOLO("yolov8n.pt") # load a pretrained modelelif task == "segment":model = YOLO("yolov8n-seg.pt") # load a pretrained modelelse:print(colorama.Fore.RED + "Error: unsupported task:", task)raiseresults = model.train(data=yaml, epochs=epochs, imgsz=640) # train the modelmetrics = model.val() # It'll automatically evaluate the data you trained, no arguments needed, dataset and settings remembered# model.export(format="onnx") #, dynamic=True) # export the model, cannot specify dynamic=True, opencv does not supportmodel.export(format="onnx", opset=12, simplify=True, dynamic=False, imgsz=640)model.export(format="torchscript") # libtorchmodel.export(format="engine", imgsz=640, dynamic=False, verbose=False, batch=1, workspace=2) # tensorrt fp32# model.export(format="engine", imgsz=640, dynamic=True, verbose=True, batch=4, workspace=2, half=True) # tensorrt fp16# model.export(format="engine", imgsz=640, dynamic=True, verbose=True, batch=4, workspace=2, int8=True, data=yaml) # tensorrt int8if __name__ == "__main__":# python test_yolov8_train.py --yaml datasets/melon_new_detect/melon_new_detect.yaml --epochs 1000 --task detectcolorama.init()args = parse_args()if torch.cuda.is_available():print("Runging on GPU")else:print("Runting on CPU")train(args.task, args.yaml, args.epochs)print(colorama.Fore.GREEN + "====== execution completed ======")使用INT8量化导出TensorRT:会执行训练后量化(post-training quantization, PTQ),即在模型训练完成后,无需重新训练即可对模型进行量化。TensorRT 使用校准进行PTQ。
注:确保使用TensorRT模型权重进行部署的同一设备以INT8精度进行导出,因为校准结果可能因设备而异。
配置INT8导出:使用导出Ultralytics YOLO模型时提供的参数将极大地影响导出模型的性能。还需要根据可用的设备资源来选择它们,但是默认参数应该适用于大多数 Ampere(或更新版本)架构的NVIDIA独立GPU。使用的校准算法是"ENTROPY_CALIBRATION_2"。
workspace:控制转换模型权重时设备内存分配的大小(以GiB为单位)。
(1).根据校准需求和资源可用性调整workspace。虽然较大的workspace可能会增加校准时间,但它允许TensorRT探索更广泛的优化策略,从而有可能提高模型性能和准确性。相反,较小的workspace可以减少校准时间,但可能会限制优化策略,影响量化模型的质量。
(2).默认值workspace=4(GiB),如果校准崩溃(没有警告就退出),则可能需要增加此值。
(3).如果workspace的值大于设备可用的内存,TensorRT将在导出期间报告UNSUPPORTED_STATE,这意味着应该降低workspace的值。
(4).如果workspace设置为最大值并且校准失败/崩溃,请考虑减少imgsz和batch的值以减少内存要求。
切记:INT8的校准是针对每个设备的,借用"高端"GPU进行校准可能会导致在另一台设备上运行推理时性能不佳。
batch:用于推理的最大批次大小(batch-size)。推理期间可以使用较小的批次,但推理不会接受大于指定值的批次。
在校准过程中,将使用提供的两倍批次大小。使用小批次可能会导致校准过程中的缩放不准确。这是因为该过程会根据它看到的数据进行调整。小批次可能无法捕获整个值范围,从而导致最终校准出现问题,因此批次大小会自动加倍。如果没有指定批次大小batch=1,则校准将以batch=1*2 运行,以减少校准缩放错误。
NVIDIA的实验使他们建议使用至少500张代表模型数据的校准图像,并使用INT8量化校准。这是一个指导原则,而不是硬性要求,你需要试验哪些内容才能使你的数据集表现良好。由于使用TensorRT进行INT8校准需要校准数据,因此确保在TensorRT的int8=True时使用数据参数并使用data="my_dataset.yaml",这将使用验证中的图像进行校准。当使用INT8量化导出到TensorRT时没有传递任何数据值时,默认将使用基于模型任务的"small"示例数据集之一,而不是抛出错误。
注:TensorRT将生成一个校准.cache,可以重复使用以加速使用相同数据导出未来模型权重,但当数据差异很大或批次值发生剧烈变化时,这可能会导致校准效果不佳。在这种情况下,应重命名现有.cache并将其移动到其他目录或完全删除。
将YOLO与TensorRT INT8结合使用的优势:
(1).减少模型大小:从FP32到INT8的量化可以将模型大小减小4倍(在磁盘或内存中),从而缩短下载时间、降低存储要求并减少部署模型时的内存占用。
(2).更低功耗:INT8导出的YOLO模型的精度运算减少,与FP32模型相比,功耗更低,尤其是对于电池供电(battery-powered)的设备。
(3).提高推理速度:TensorRT针对目标硬件优化模型,可能提高GPU、嵌入式设备和加速器上的推理速度。
注:使用导出到TensorRT INT8的模型进行前几次推理调用时,预处理、推理和/或后处理时间(preprocessing, inference, and/or postprocessing times)可能会比平时更长。在推理过程中更改imgsz时也可能会出现这种情况,尤其是当imgsz与导出期间指定的值不同时(导出imgsz设置为TensorRT"最佳"配置文件)。
使用YOLO和TensorRT INT8的缺点:
(1).评估指标下降:使用较低的精度意味着mAP、精度、召回率或用于评估模型性能的任何其他指标可能会有所下降。
(2).增加开发时间:找到数据集和设备的INT8校准的"最佳"设置可能需要大量测试。
(3).硬件依赖性:校准和性能提升可能高度依赖于硬件,并且模型权重的可转移性较差。
TensorRT的性能改进可能因所使用的硬件而异。
注:以上文字描述主要来自:https://docs.ultralytics.com/integrations/tensorrt/
Windows10 Anaconda上配置TensorRT环境:
(1).配置Ultralytics CUDA开发环境,执行以下命令:
# install cuda 11.8
# install cudnn v8.7.0: copy the contents of bin,include,lib/x64 cudnn directories to the corresponding CUDA directories
conda create --name ultralytics-env-cuda python=3.8 -y
conda activate ultralytics-env-cuda
conda install -c pytorch -c nvidia -c conda-forge pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=11.8 ultralytics # pytorch 2.2.2git clone https://github.com/fengbingchun/NN_Test
cd NN_Test/demo/Python(2).从https://developer.nvidia.com/nvidia-tensorrt-8x-download 下载TensorRT 8.5 GA版本:TensorRT-8.5.3.1.Windows10.x86_64.cuda-11.8.cudnn8.6.zip,解压缩:
A.将bin、include目录下内容拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8对应目录下
B.将lib下的所有静态库拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64目录下
C.将lib下的所有动态库拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin目录下
(3).进入到python目录,执行以下命令:
pip install tensorrt-8.5.3.1-cp38-none-win_amd64.whl注:不能使用10.2 GA版本,否则会报Error: Unsupported SM: 0x601,在 https://docs.nvidia.com/deeplearning/tensorrt/release-notes/ 中有描述:NVIDIA Pascal (SM 6.x) devices are deprecated in TensorRT 8.6
注:无论指定是FP32、FP16还是INT8训练完生成的最终文件名都为best.engine,这里手动调整文件名
在网上下载了200多幅包含西瓜和冬瓜的图像组成melon数据集,使用生成的best.engine进行预测,代码如下所示:
import colorama
import argparse
from ultralytics import YOLO
import os
import torchimport numpy as np
np.bool = np.bool_ # Fix Error: AttributeError: module 'numpy' has no attribute 'bool'. OR: downgrade numpy: pip unistall numpy; pip install numpy==1.23.1def parse_args():parser = argparse.ArgumentParser(description="YOLOv8 predict")parser.add_argument("--model", required=True, type=str, help="model file")parser.add_argument("--dir_images", required=True, type=str, help="directory of test images")parser.add_argument("--dir_result", required=True, type=str, help="directory where the image results are saved")args = parser.parse_args()return argsdef get_images(dir):# supported image formatsimg_formats = (".bmp", ".jpeg", ".jpg", ".png", ".webp")images = []for file in os.listdir(dir):if os.path.isfile(os.path.join(dir, file)):# print(file)_, extension = os.path.splitext(file)for format in img_formats:if format == extension.lower():images.append(file)breakreturn imagesdef predict(model, dir_images, dir_result):model = YOLO(model) # load an model# model.info() # display model information # only *.pt format supportimages = get_images(dir_images)# print("images:", images)os.makedirs(dir_result) #, exist_ok=True)for image in images:if torch.cuda.is_available():results = model.predict(dir_images+"/"+image, verbose=True, device="cuda")else:results = model.predict(dir_images+"/"+image, verbose=True)for result in results:# print(result)result.save(dir_result+"/"+image)if __name__ == "__main__":# python test_yolov8_predict.py --model runs/detect/train10/weights/best_int8.engine --dir_images datasets/melon_new_detect/images/test --dir_result result_detect_engine_int8colorama.init()args = parse_args()if torch.cuda.is_available():print("Runging on GPU")else:print("Runting on CPU")predict(args.model, args.dir_images, args.dir_result)print(colorama.Fore.GREEN + "====== execution completed ======")执行结果如下图所示:

预测结果图像如下所示:

GitHub:https://github.com/fengbingchun/NN_Test
相关文章:
将YOLOv8模型从PyTorch的.pt格式转换为TensorRT的.engine格式
TensorRT是由NVIDIA开发的一款高级软件开发套件(SDK),专为高速深度学习推理而设计。它非常适合目标检测等实时应用。该工具包可针对NVIDIA GPU优化深度学习模型,从而实现更快、更高效的运行。TensorRT模型经过TensorRT优化,包括层融合(layer …...

Hello SLAM(在Linux中实现第一个C++程序)
首先需要安装vim编辑器,输入命令 sudo apt install vim 在Ubuntu上安装好vim编辑器后,创建路径(/home/slambook/ch2),在该路径下创建一个cpp文档(touch hello.c),通过vim编辑器进行…...
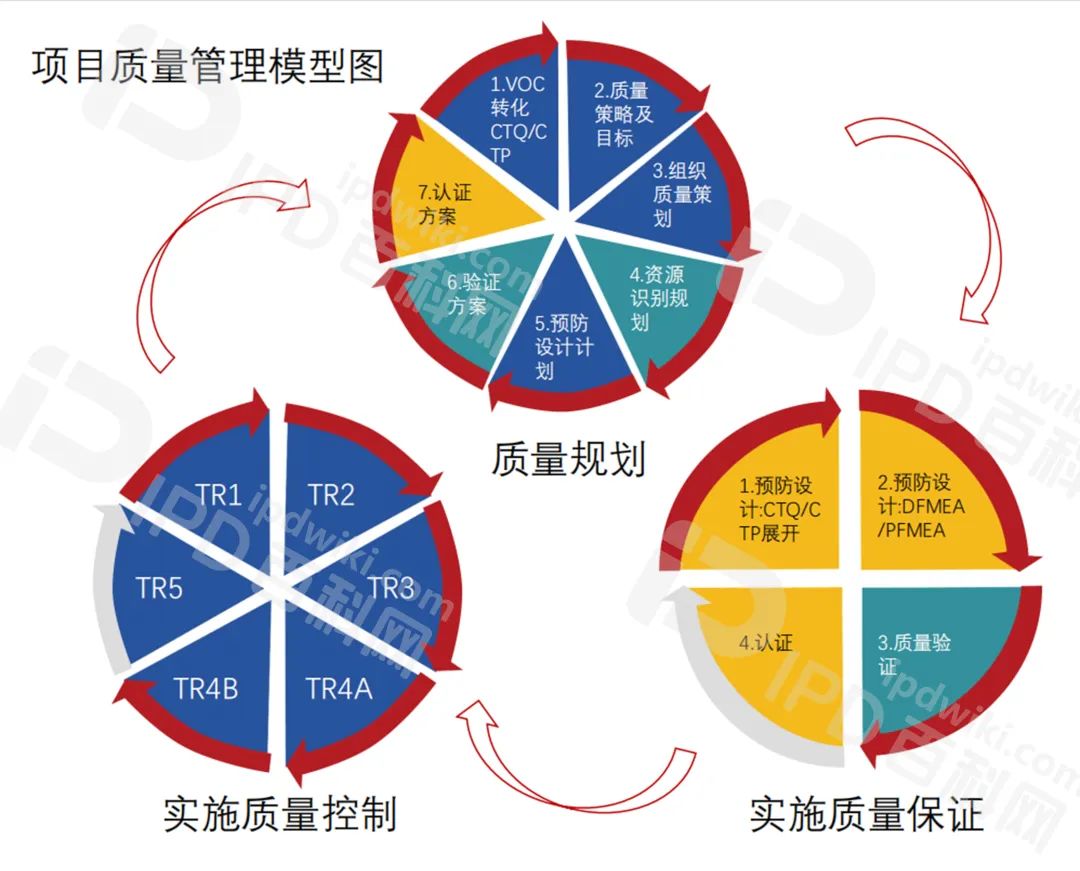
IPD推行成功的核心要素(十五)项目管理提升IPD相关项目交付效率和用户体验
研发项目往往包含很多复杂的流程和具体的细节。因此,一套完整且标准的研发项目管理制度和流程对项目的推进至关重要。研发项目管理是成功推动创新和技术发展的关键因素。然而在实际管理中,研发项目管理常常面临着需求不确定、技术风险、人员素质、成本和…...

C++ 鼠标轨迹API【神诺科技SDK】
一.鼠标轨迹模拟简介 传统的鼠标轨迹模拟依赖于简单的数学模型,如直线或曲线路径。然而,这种方法难以捕捉到人类操作的复杂性和多样性。AI大模型的出现,使得神诺科技 能够通过深度学习技术,学习并模拟更自然的鼠标移动行为。 二.…...
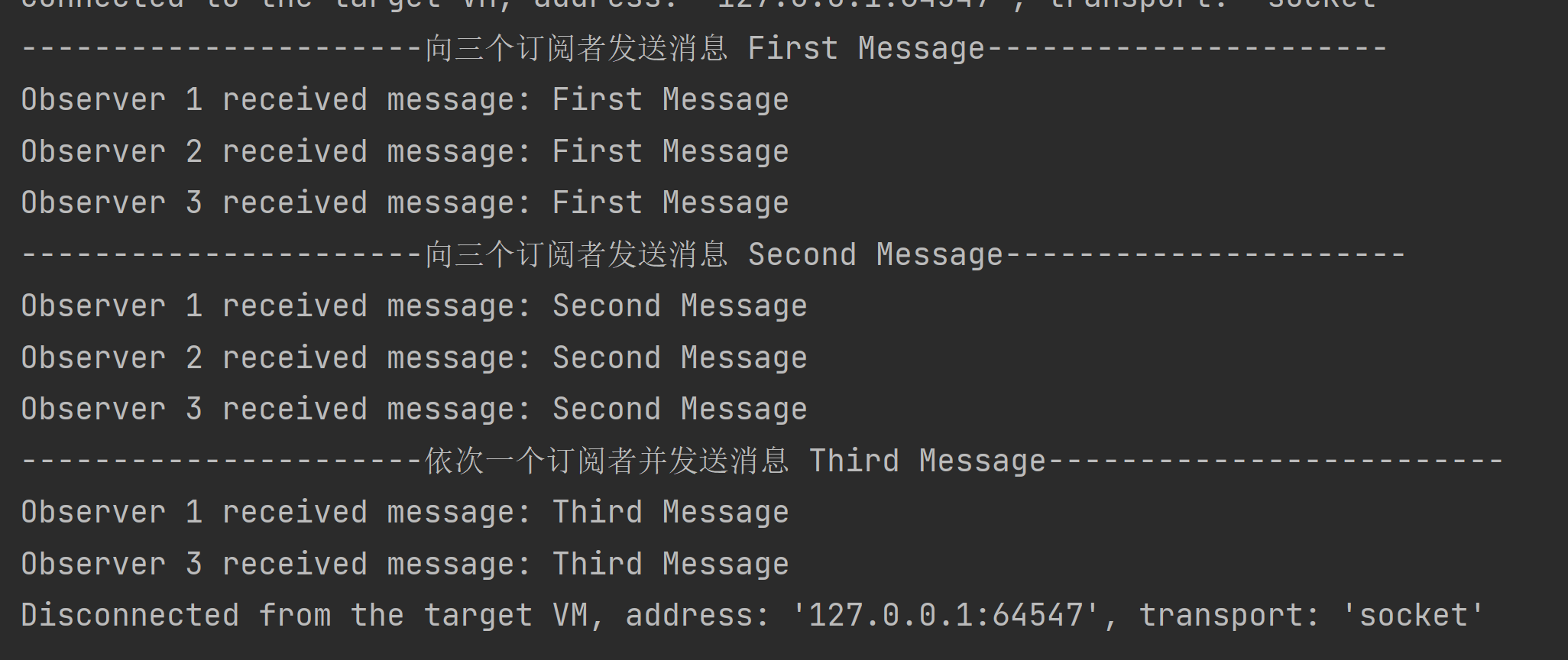
设计模式|观察者模式
观察者模式是一种行为设计模式,它定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。当主题对象发生变化时,它的所有观察者都会收到通知并更新。观察者模式常用于实现事件处理系统、发布-订阅模式等。在项目中,…...

python自动化运维 通过paramiko库和time库实现服务器自动化管理
目录 一.前言 二. 代码实现以及解析 2.1导入必要的库 2.2定义服务器信息 2.3创建 SSH 客户端连接函数 2.4执行远程命令函数 2.5获取系统信息函数 2.6重启服务函数 2.7 主函数 三.致谢 一.前言 在数字化时代,IT 基础设施的规模和复杂性不断增长&am…...

HTML常用的转义字符——怎么在网页中写“<div></div>”?
一、问题描述 如果需要在网页中写“<div></div>”怎么办呢? 使用转义字符 如果直接写“<div></div>”,编译器会把它翻译为块,类似的,其他的标签也是如此,所以如果要在网页中写类似于“<div…...

shell-awk文本处理工具
1、awk概述 AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。 它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作 数据可以来自标准输入也可以是管道或文件 在 linux 上常用的是 gawk,awk …...

如何在测试中保护用户隐私!
在当今数据驱动的时代,用户隐私保护成为了企业和开发团队关注的焦点。在软件测试过程中,处理真实用户数据时保护隐私尤为重要。本文将介绍如何在测试中保护用户隐私,并提供具体的方案和实战演练。 用户隐私保护的重要性 用户隐私保护不仅是法…...

ARCGIS PRO DSK GraphicsLayer创建文本要素
一、判断GraphicsLayer层【地块注记】是否存在,如果不存在则新建、如果存在则删除所有要素 Dim GraphicsLayer pmap.GetLayersAsFlattenedList().OfType(Of ArcGIS.Desktop.Mapping.GraphicsLayer).FirstOrDefault() 获取当前map对象中的GetLayer图层 Await Queue…...

看板项目之vue代码分析
目录: Q1、vue项目怎么实现的输入localhost:8080就能自动跳到index页面Q2、组合饼状图如何实现Q3、vue项目如何实现环境的切换Q4、vue怎么实现vue里面去调用js文件里面的函数 Q1、vue项目怎么实现的输入localhost:8080就能自动跳到index页面 …...
ai_dead)
lua 游戏架构 之 游戏 AI (七)ai_dead
定义一个名为ai_dead的类,继承自ai_base类。这个类用于处理游戏中AI在死亡状态下的行为逻辑。以下是对代码的具体解释: 1. **引入基类**: - 使用require函数引入ai_base类,作为基础类。 2. **定义ai_dead类**: …...

前端开发知识(一)-html
1.前端开发需掌握的内容: 2.前端开发的三剑客:html、css、javascript Vue可以简化JavaScpript流程。 Element(饿了么开发的) :前端组件库。 Ngix:前端服务器。 3.前端开发工具:vscode 1)按…...

身份证如何查验真伪?C#身份证二要素、三要素接口集成
身份证不仅是我们的身份证明,更是社会生活中的“通行证”,现在人们的衣食住行都离不开身份证。但对于提供服务的平台而言,如何对用户提供的身份信息进行真伪核验便成为了一大难题。别担心,今天小编为服务平台带来了身份证二要素、…...

C++ | Leetcode C++题解之第290题单词规律
题目: 题解: class Solution { public:bool wordPattern(string pattern, string str) {unordered_map<string, char> str2ch;unordered_map<char, string> ch2str;int m str.length();int i 0;for (auto ch : pattern) {if (i > m) {…...

Pytorch使用教学7-张量的广播
PyTorch中的张量具有和NumPy相同的广播特性,允许不同形状的张量之间进行计算。 广播的实质特性,其实是低维向量映射到高维之后,相同位置再进行相加。我们重点要学会的就是低维向量如何向高维向量进行映射。 相同形状的张量计算 虽然我们觉…...

生成式AI:对话系统(Chat)与自主代理(Agent)的和谐共舞
生成式AI:对话与行动的和谐共舞 我们正站在一个令人激动的时代门槛上——生成式AI技术飞速发展,带来了无限的可能性。一个关键问题浮现:AI的未来是对话系统(Chat)的天下,还是自主代理(Agent&am…...
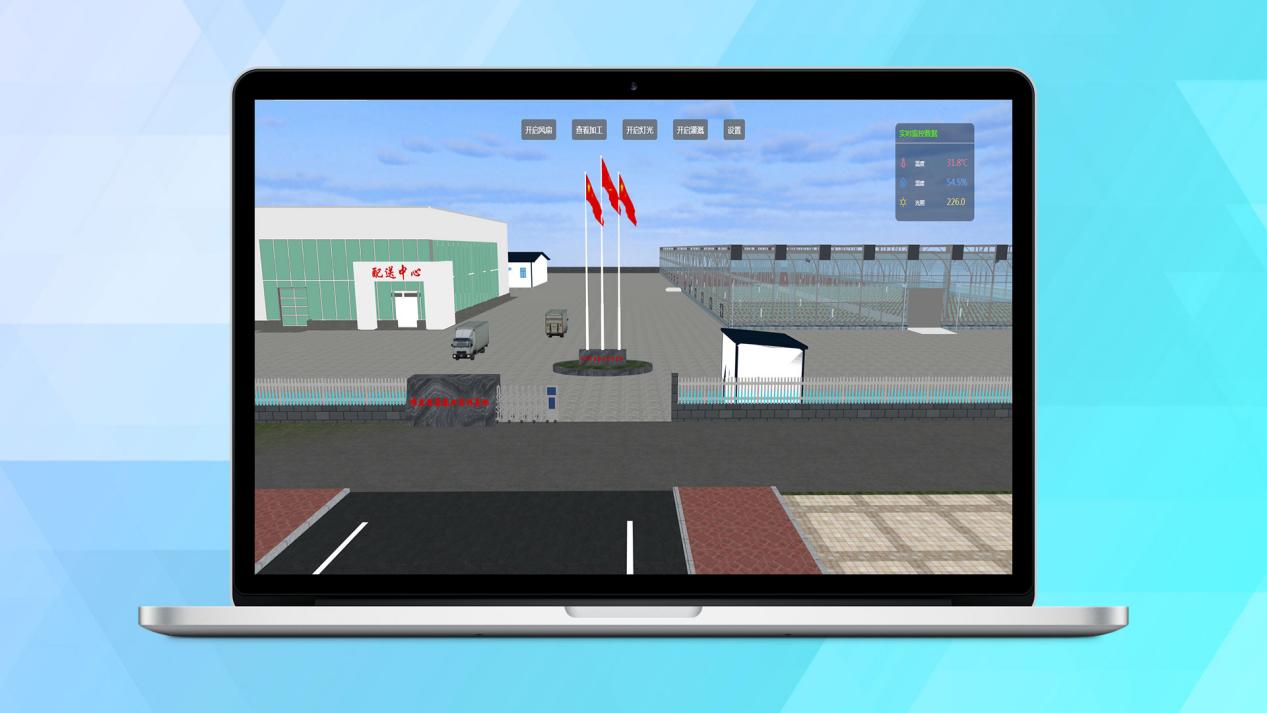
唯众物联网(IOT)全功能综合实训教学解决方案
一、引言 在信息技术日新月异的今天,物联网(IoT)作为推动数字化转型的关键力量,其触角已延伸至我们生活的方方面面,深刻地重塑了工作模式、生活习惯乃至社会结构的每一个角落。面对这一前所未有的变革浪潮,…...

24证券从业考试报名『个人信息表』填写模板❗
24证券从业考试报名『个人信息表』填写模板❗ 1️⃣居住城市、通讯地址:写自己现居住的地址就可以。 2️⃣学历:需要注意的是学历填写的是考生已经取得的学历,在校大学生已经不具有报名资格,选择大专以上,或者是高中学…...

深度学习系列70:模型部署torchserve
1. 流程说明 ts文件夹下, 从launcher.py进入,执行jar文件。 入口为model_server.py的start()函数。内容包含: 读取args,创建pid文件 找到java,启动model-server.jar程序,同时读取log-config文件ÿ…...

ARM Mali-T600系列GPU架构解析:移动GPU如何从图形渲染迈向异构计算
1. 从SIGGRAPH看移动GPU的暗流涌动:ARM Mali-T600系列深度拆解每年的SIGGRAPH(计算机图形图像特别兴趣小组)大会,聚光灯总是打在那些炫目的电影特效、逼真的游戏渲染和前沿的学术研究上,这很容易让人产生一种错觉&…...

Kubescape命令行自动补全:提升安全扫描效率的技巧
Kubescape命令行自动补全:提升安全扫描效率的技巧 【免费下载链接】kubescape Kubescape is an open-source Kubernetes security platform for your IDE, CI/CD pipelines, and clusters. It includes risk analysis, security, compliance, and misconfiguration …...

点云配准避坑指南:当ICP把深度图配到‘中心’时,我的自适应阈值调整方案
点云配准避坑指南:动态阈值优化解决ICP中心化失效问题 在三维重建和SLAM项目中,工程师们常常会遇到一个令人头疼的现象:使用标准ICP算法对深度图点云进行配准时,点云会神秘地"滑向"彼此的中心位置。这种看似魔法的行为背…...

冠珠瓷砖×莫氏鸡煲×叠滘东胜东队,德叔有请,莫叔掌勺,“力撑”叠滘龙船传承
5月10日,2026叠滘龙船漂移大赛金牌合作伙伴冠珠瓷砖品牌代表、新明珠集团董事长叶德林“德叔”有请,莫氏鸡煲创始人“莫叔”掌勺,携火爆全网的莫氏祛湿鸡煲、紫洞黄皮酒,探班叠滘东胜东队训练场。当天下午,德叔、莫叔还…...

物联网数据完整性保障的多层级架构设计与实践
1. 物联网数据完整性的核心挑战在传统IT系统中,数据流动遵循着严格的请求-响应模式,服务器和客户端之间的交互是可预测且有序的。但物联网环境彻底颠覆了这一范式——数以亿计的终端设备以异步、不可预测的方式产生数据流,这种特性使得数据完…...

办公室翻新预算超支了怎么办
很多小微企业、创业团队翻修办公室。算来算去,最后发现预算超支了。这种情况真的太常见了。我们今天一步步理,给你实打实的解决办法。大家最关心的5个问题解答Q1:办公室翻新,哪块更容易超预算?A:大部分情况…...

告别时钟线!用三根线搞定高速传输:MIPI C-PHY硬件连接与编码原理详解
告别时钟线!用三根线搞定高速传输:MIPI C-PHY硬件连接与编码原理详解 在高速数据传输领域,传统并行总线的时钟同步机制已成为提升速率的瓶颈。MIPI联盟推出的C-PHY标准,以革命性的"三线无时钟"架构打破了这一僵局。本文…...

免费抠图软件一键抠图无水印有哪些?2026年最实用工具对比测试
最近很多粉丝问我,有没有真正免费、无水印、操作简单的抠图软件?说实话,市面上的抠图工具五花八门,但真正好用的没几个。我这次花了不少时间测试了十多款抠图软件,今天就把我的真实体验分享给大家。为什么你需要一个好…...

Deep Agents:开箱即用的AI智能体框架,快速构建自主规划与执行应用
1. 项目概述:一个开箱即用的AI智能体框架如果你正在尝试构建一个能自主规划、读写文件、执行命令的AI智能体,大概率会经历一个相当繁琐的过程:先选一个LLM模型,然后设计一套复杂的提示词(Prompt)来教它如何…...

突破性AI编程工具破解方案:cursor-free-vip技术深度解析与全栈实施指南
突破性AI编程工具破解方案:cursor-free-vip技术深度解析与全栈实施指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve …...