基于PaddleClas的人物年龄分类项目
目录
一、任务概述
二、算法研发
2.1 下载数据集
2.2 数据集预处理
2.3 安装PaddleClas套件
2.4 算法训练
2.5 静态图导出
2.6 静态图推理
三、小结
一、任务概述
最近遇到个需求,需要将图像中的人物区分为成人和小孩,这是一个典型的二分类问题,打算采用飞桨的图像分类套件PaddleClas来完成算法研发。本文记录相关流程。
二、算法研发
2.1 下载数据集
本文采用MaGaAge_Asian数据集,该数据集主要由亚洲人图片组成,训练集包含40000张图像,验证集包含3495张图像,每张图像都有对应的年龄真值,所有图像均处理成了统一的大小,宽178像素,高218像素。
数据集地址下载链接。数据集部分示例如下图所示:

该数据集本意是用来做年龄预测的,属于一个数值回归任务,本文将其变成二分类任务,以13岁年龄为界限,小于该年龄的属于小孩,大于该年龄的属于成人。这里之所以选择13岁,因为这个任务是需要筛选出长得很“像”小孩的小孩,13岁以上的青少年很多本身已经长的像成人了,因此,选择13岁作为分界线。
下面首先对该数据集进行处理。
2.2 数据集预处理
MaGaAge_Asian数据集每张图片对应的人物年龄存放在list文件夹的两个文件中,其中train_age.txt存放训练集对应的年龄真值,test_age.txt存放验证集对应的年龄真值。下面要写一个脚本,将所有小于13岁的图片移动到一个文件夹内,所有大于等于13岁的图片移动到另一个文件夹内。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@文件 :split_asian.py
@说明 :拆分megaage_asian数据集,将小于13岁的移动到一个文件夹,大于等于13岁的移动到另一个文件夹
@时间 :2024/07/16 09:11:16
@作者 :Bin Qian
@版本 :1.0
'''import os
import cv2thr = 13 # 年龄阈值# 读取年龄列表
agefile = 'megaage_asian/list/test_age.txt'
f=open(agefile)
ageLst = f.read().splitlines()
f.close() # 读取图像
imgFolder = 'megaage_asian/val'
imgnames = os.listdir(imgFolder)
index = 50000
for imgname in imgnames:imgPath = os.path.join(imgFolder,imgname)img = cv2.imread(imgPath)if img is None:continueprint(imgPath)imgindex = int(imgname.split('.')[0])age = int(ageLst[imgindex-1])if age < thr:dstFolder = 'ageclas/child'else:dstFolder = 'ageclas/adult'savePath = os.path.join(dstFolder,str(index)+'_asian.jpg')cv2.imwrite(savePath,img)index += 1
print('完成')值得注意的是MaGaAge_Asian数据集中有很多质量较差的图像,这些“脏”图像会影响学习效果,最好手工检查这些数据并将其剔除。
另外,为了能够取得更好的效果,本文从互联网和FFHQ数据集里面再挑选出一些小孩和成人的照片进行补充。部分代码如下:
import os
import cv2# 读取图像
imgFolder = 'adult'
imgnames = os.listdir(imgFolder)
index = 1
for imgname in imgnames:imgPath = os.path.join(imgFolder,imgname)img = cv2.imread(imgPath)if img is None:continueprint(imgPath)dstFolder = 'ageclas/adult'savePath = os.path.join(dstFolder,str(index)+'_data.jpg')cv2.imwrite(savePath,img)index += 1
print('完成')补充完整后,最后对整理好的数据集进行拆分,并且获得对应的文件列表:
# 导入系统库
import os
import random
import cv2# 定义参数
img_folder = 'ageclas'
trainlst = 'train_list.txt'
vallst = 'val_list.txt'
ratio = 0.95 # 训练集占比
labellst='label.txt'def writeLst(lstpath,namelst):'''保存文件列表'''print('正在写入 '+lstpath)random.shuffle (namelst)# 写入训练样本文件f=open(lstpath, 'a', encoding='utf-8')for i in range(len(namelst)):text = namelst[i]+'\n'f.write(text)f.close()print(lstpath+ '已完成写入')def main():'''主函数'''# 查找文件夹folderlst = os.listdir(img_folder)print('共找到 %d 个文件夹' % len(folderlst))# 循环处理trainnamelst = list()valnamelst = list()labelnamelst = list()for i in range(len(folderlst)):class_name = folderlst[i]class_label = iprint('开始处理 '+class_name+' 文件夹')# 获取子文件夹文件列表filenamelst = os.listdir(os.path.join(img_folder,class_name))totalNum = len(filenamelst)print('当前文件夹图片数量为: ' + str(totalNum)) trainNum = int(ratio*totalNum)text = str(class_label)+ ' ' + class_namelabelnamelst.append(text)# 检查并校验图像for j in range(totalNum):imgpath = os.path.join(img_folder,class_name,filenamelst[j])img = cv2.imread(imgpath, cv2.IMREAD_COLOR)if img is None:continuetext = imgpath + ' ' + str(class_label)if j <= trainNum: trainnamelst.append(text)else:valnamelst.append(text)writeLst(trainlst,trainnamelst)writeLst(vallst,valnamelst) writeLst(labellst,labelnamelst) print('全部完成')if __name__ == '__main__':'''程序入口'''main()
运行后会生成train_lst.txt、val_lst.txt以及label.txt三个文件,有了这三个文件就可以使用PaddleClas套件进行算法研发了。
2.3 安装PaddleClas套件
git clone https://gitee.com/paddlepaddle/PaddleClas.git
cd PaddleClas
sudo python setup.py install2.4 算法训练
在PaddleClas目录下新建一个配置文件config_lcnet.yaml,采用PPLCNet_x0_5模型来训练,配置文件代码如下:
# global configs
Global:checkpoints: nullpretrained_model: nulloutput_dir: ./output/device: gpusave_interval: 5eval_during_train: Trueeval_interval: 5epochs: 200print_batch_step: 10use_visualdl: True# used for static mode and model exportimage_shape: [3, 224, 224]save_inference_dir: ./output/inference
# model architecture
Arch:name: PPLCNet_x0_5class_num: 2# loss function config for traing/eval process
Loss:Train:- CELoss:weight: 1.0epsilon: 0.1Eval:- CELoss:weight: 1.0Optimizer:name: Momentummomentum: 0.9lr:name: Cosinelearning_rate: 0.8warmup_epoch: 5regularizer:name: 'L2'coeff: 0.00003# data loader for train and eval
DataLoader:Train:dataset:name: ImageNetDatasetimage_root: ../process_data/cls_label_path: ../process_data/train_list.txttransform_ops:- DecodeImage:to_rgb: Truechannel_first: False- ResizeImage:size: [224,224]- RandFlipImage:flip_code: 1- NormalizeImage:scale: 1.0/255.0mean: [0.485, 0.456, 0.406]std: [0.229, 0.224, 0.225]order: ''sampler:name: DistributedBatchSamplerbatch_size: 64drop_last: Falseshuffle: Trueloader:num_workers: 4use_shared_memory: TrueEval:dataset: name: ImageNetDatasetimage_root: ../process_data/cls_label_path: ../process_data/val_list.txttransform_ops:- DecodeImage:to_rgb: Truechannel_first: False- ResizeImage:size: [224,224]- NormalizeImage:scale: 1.0/255.0mean: [0.485, 0.456, 0.406]std: [0.229, 0.224, 0.225]order: ''sampler:name: DistributedBatchSamplerbatch_size: 64drop_last: Falseshuffle: Falseloader:num_workers: 4use_shared_memory: TrueInfer:infer_imgs: "../testimgs/10.jpg"batch_size: 1transforms:- DecodeImage:to_rgb: Truechannel_first: False- ResizeImage:size: [224,224]- NormalizeImage:scale: 1.0/255.0mean: [0.485, 0.456, 0.406]std: [0.229, 0.224, 0.225]order: ''- ToCHWImage:PostProcess:name: Topktopk: 1class_id_map_file: "../process_data/label.txt"Metric:Train:- TopkAcc:topk: [1]Eval:- TopkAcc:topk: [1]
然后使用下面的命令进行训练:
export CUDA_VISIBLE_DEVICES=0,1
python3 -m paddle.distributed.launch \--gpus="0,1" \tools/train.py \-c config_lcnet.yaml 训练完成后可以使用下面的命令可视化查看训练结果:
visualdl --logdir results/vdl运行效果如下:

可以看到,基本在epoch=100以后就收敛了,最高top1准确率达到97.5%,准确率还是比较高的。
下面可以使用动态图对单张图像进行测试,命令如下:
python3 tools/infer.py -c config_lcnet.yaml -o Global.pretrained_model=output/PPLCNet_x0_5/best_model输出如下:
[{'class_ids': [1], 'scores': [0.93522], 'file_name': '../testimgs/10.jpg', 'label_names': ['adult']}]2.5 静态图导出
为了方便后面进行模型部署,将训练好的最佳模型进行静态图导出。具体命令如下:
python3 tools/export_model.py \-c config_lcnet.yaml \-o Global.pretrained_model=output/PPLCNet_x0_5/best_model \-o Global.save_inference_dir=output/inference导出的静态图模型存放在output/inference文件夹下面,整个模型参数加起来不超过3M,因此可以看出这个训练好的PPLCNet_x0_5模型是一个非常轻量级的模型。
2.6 静态图推理
下面使用静态图来进行推理。在推理前先使用visualdl工具查看下静态图模型的输入和输出,这将为编写推理脚本奠定基础。

可以看到,输入是[batch,3,224,224]的float型图像数据,输出是[batch,2]的float型数据。尤其是输出的两个值,代表的是两个类别的概率。
有了上面的分析,下面可以用PaddleInference写一个推理脚本infer.py:
import cv2
import numpy as np
from paddle.inference import create_predictor
from paddle.inference import Config as PredictConfig# 加载静态图模型
model_path = "./output/inference/inference.pdmodel"
params_path = "./output/inference/inference.pdiparams"
pred_cfg = PredictConfig(model_path, params_path)
pred_cfg.enable_memory_optim() # 启用内存优化
pred_cfg.switch_ir_optim(True)
pred_cfg.enable_use_gpu(500, 0) # 启用GPU推理
predictor = create_predictor(pred_cfg) # 创建PaddleInference推理器# 解析模型输入输出
input_names = predictor.get_input_names()
input_handle = {}
for i in range(len(input_names)):input_handle[input_names[i]] = predictor.get_input_handle(input_names[i])
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])# 图像预处理
img = cv2.imread("../testimgs/10.jpg", flags=cv2.IMREAD_COLOR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224), interpolation=cv2.INTER_AREA)
img = img.astype(np.float32)
PIXEL_MEANS =(0.485, 0.456, 0.406) # RGB格式的均值和方差
PIXEL_STDS = (0.229, 0.224, 0.225)
img/=255.0
img-=np.array(PIXEL_MEANS)
img/=np.array(PIXEL_STDS)
img = np.transpose(img[np.newaxis, :, :, :], (0, 3, 1, 2))# 预测
input_handle["x"].copy_from_cpu(img)
predictor.run()
results = output_handle.copy_to_cpu()# 后处理
results = results.squeeze(0)
if results[0]>results[1]:print('小孩'+" "+str(results[0]))
else:print('大人'+" "+str(results[1]))
从网上随便找两张照片,运行效果如下:

输出结果:
小孩 0.7256172
输出结果:
大人 0.9533998可以看到,推理效果还是比较满意的。
三、小结
本文以项目为主线,使用了PaddleClas算法套件解决了年龄分类问题。后续读者如果想要深入学习PaddlePaddle(飞桨)及相关算法套件,可以关注我的书籍(链接)。
相关文章:
基于PaddleClas的人物年龄分类项目
目录 一、任务概述 二、算法研发 2.1 下载数据集 2.2 数据集预处理 2.3 安装PaddleClas套件 2.4 算法训练 2.5 静态图导出 2.6 静态图推理 三、小结 一、任务概述 最近遇到个需求,需要将图像中的人物区分为成人和小孩,这是一个典型的二分类问题…...

20240725java的Controller、DAO、DO、Mapper、Service层、反射、AOP注解等内容的学习
在Java开发中,controller、dao、do、mapper等概念通常与MVC(Model-View-Controller)架构和分层设计相关。这些概念各自承担着不同的职责,共同协作以构建和运行一个应用程序。以下是这些概念的解释:…...

dynslam的安装
1. 安装opencv 2.4.9 下载opencv2.4.9 apt-get install build-essential apt-get install libgtk2.0-dev libavcodec-dev libavformat-dev libtiff4-dev libswscale-dev libjasper-dev apt-get install cmake apt-get install pkg-config 进入安装包文件: m…...

stats 监控 macOS 系统
Stats 监控 macOS 系统 CPU 利用率GPU 利用率内存使用情况磁盘利用率网络使用情况电池电量 brew install stats参考 stats github...

后端面试题日常练-day05 【Java基础】
题目 希望这些选择题能够帮助您进行后端面试的准备,答案在文末 在Java中,以下哪个关键字用于表示方法重写(Override)? a) override b) overrule c) overwrite d) supercede Java中的HashMap和Hashtable有什么区别&am…...

mac|安装PostgreSQL
1、官网下载:EDB: Open-Source, Enterprise Postgres Database Management 选择需要的版本: 双击得到的.dmg文件 双击,弹窗选择打开,一路next,然后输入你要设置的密码,默认账号名字为:postgres…...

内网对抗-隧道技术篇防火墙组策略FRPNPSChiselSocks代理端口映射C2上线
知识点: 1、隧道技术篇-传输层-工具项目-Frp&Nps&Chisel 2、隧道技术篇-传输层-端口转发&Socks建立&C2上线Frp Frp是专注于内网穿透的高性能的反向代理应用,支持TCP、UDP、HTTP、HTTPS等多种协议。可以将内网服务以安全、便捷的方式通过…...
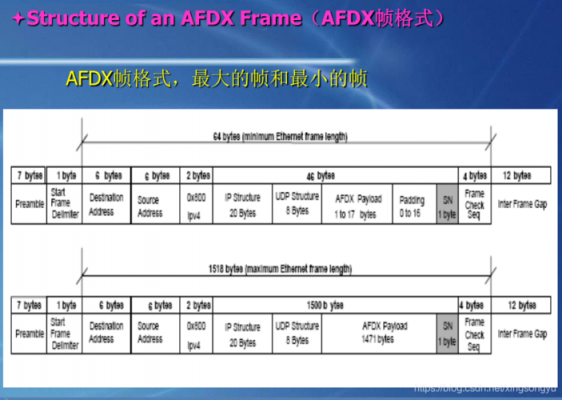
arinc664总线协议
AFDX总线协议简介 (1)AFDX的传输速率高:带宽100MHZ,远远高于其他的类型的航空总线。(2)AFDX网络的鲁棒性高:AFDX的双冗余备份网络可以在某一个网络出现故障时,仍能正常通讯。 其中…...

UNIX 域协议
1. UNIX域协议 利用socket编程接口实现本地进程间通信 UNIX域协议套接字:可以使用TCP,也可以使用UDP SOCK_STREAM -----> TCP 面向字节流 SOCK_DGRAM -----> UDP 面向数据报 UNIX域协议并不是一个实际的协议族,而是在单个主机上执…...

昇思25天学习打卡营第17天|LLM-基于MindSpore的GPT2文本摘要
打卡 目录 打卡 环境准备 准备阶段 数据加载与预处理 BertTokenizer 部分输出 模型构建 gpt2模型结构输出 训练流程 部分输出 部分输出2(减少训练数据) 推理流程 环境准备 pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspo…...

Clion开发STM32——移植FreeModbus
STM32型号 :STM32H743VIT6 FreeModbus版本 :1.6 使用工具:stm32cubeMX,Clion 使用STM32作从机,模式:RTU 网上用keil的比较多,用Clion的比较少,如果你也用Clion,那么希望…...

c++栈笔记
一种常见的数据结构,遵循后进先出,先进后出的原则。地址不连续,栈顶(top) 1.常见函数 stack<int> s;定义一个参数类型为int 的栈 名为ss.push()向栈中插入元素s.emplace()压栈,无返回值s.pop()删除…...

Oracle配置TCPS加密协议测试
文章目录 一、环境信息二、配置过程1.创建证书2.监听配置2.1.配置sqlnet.ora2.2.配置listener.ora文件2.3.配置tnsnames.ora文件2.4.重载监听 3.数据库本地测试3.1. tcps登录测试3.2.日志监控 一、环境信息 操作系统:Linux 版本信息:Oracle 19c 参考文档…...

Jetpack Compose 通过 OkHttp 发送 HTTP 请求的示例
下面是一个使用 Kotlin 和 Jetpack Compose 来演示通过 OkHttp 发送 HTTP 请求的示例。这个示例包括在 Jetpack Compose 中发送一个 GET 请求和一个 POST 请求,并显示结果。 添加okhttp依赖 首先,在你的 build.gradle.kts 文件中添加必要的依赖…...

Pytorch使用教学3-特殊张量的创建与类型转化
1 特殊张量的创建 与numpy类似,PyTorch中的张量也有很多特殊创建的形式。 zeros:全0张量 # 形状为2行3列 torch.zeros([2, 3]) # tensor([[0., 0., 0.], # [0., 0., 0.]])ones:全1张量 # 形状为2行3列 torch.ones([2, 3]) # tensor([[1., 1., 1.], # …...
【日记】办个护照不至于有这种刑事罪犯一样的待遇吧……(737 字)
正文 暴晒,中午出去骑共享单车,座垫都不敢坐。 至于为什么,中午觉都不睡跑出去,是因为今天他们办承兑汇票的业务,搞了一天,中午不休息,说可能还会用到我的指纹,让我 on call。我心想…...

【矩阵微分】在不涉及张量的前提下计算矩阵对向量的导数并写出二阶泰勒展开
本篇内容摘自CMU 16-745最优控制的第10讲 “Nonlinear Trajectory Optimization”。 如何在不涉及张量运算的前提下,计算矩阵对向量的导数并写出二阶泰勒展开 在多维微积分中,计算矩阵对向量的导数和二阶泰勒展开是一项重要的任务。本文将介绍如何在不涉…...

数据结构之判断平衡二叉树详解与示例(C,C++)
文章目录 AVL树定义节点定义计算高度获取平衡因子判断是否为平衡二叉树完整示例代码结论 在计算机科学中,二叉树是一种非常重要的数据结构。它们被广泛用于多种算法中,如排序、查找等。然而,普通的二叉树在极端情况下可能退化成链表ÿ…...

深入解析仓颉编程语言:函数式编程的核心特性
摘要 仓颉编程语言以其独特的语法和功能,为开发者提供了强大的编程工具。本文将深入探讨仓颉语言中的嵌套函数、Lambda 表达式和闭包等函数式编程的核心特性,帮助开发者更好地理解和利用这些工具。 引言 在现代编程语言中,函数式编程范式越…...

springboot惠农服务平台-计算机毕业设计源码50601
目录 1 绪论 1.1 研究背景 1.2研究意义 1.3论文结构与章节安排 2 惠农服务平台app 系统分析 2.1 可行性分析 2.2 系统功能分析 2.3 系统用例分析 2.4 系统流程分析 2.5本章小结 3 惠农服务平台app 总体设计 3.1 系统功能模块设计 3.2 数据库设计 表access_token (…...

ARM Cortex-A520集群架构与缓存优化配置指南
1. ARM Cortex-A520集群架构概述ARM Cortex-A520作为新一代高效能处理器核心,其集群配置能力直接影响着嵌入式系统和移动设备的整体性能表现。A520集群采用多核共享缓存架构,支持从单核到多核的灵活扩展,为开发者提供了丰富的参数配置空间。在…...

【ElevenLabs卡纳达文语音实战指南】:2024年唯一经生产环境验证的7步本地化部署方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs卡纳达文语音技术概览与生产价值定位 ElevenLabs 作为全球领先的文本转语音(TTS)平台,自2023年Q4起正式支持卡纳达语(Kannada)&…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...

GNN与MLIP:材料科学计算的高效新方法
1. GNN与MLIP:材料科学计算的新范式在材料科学领域,传统的第一性原理计算(如密度泛函理论DFT)虽然精度高,但计算成本极其昂贵,难以处理大体系或长时间尺度的模拟。图神经网络(GNN)与…...

从逻辑门到加法器:Verilog实现半加器与全加器的三种抽象层级
1. 项目概述:从逻辑门到加法器的数字世界基石在数字电路和芯片设计的入门路上,加法器是一个绕不开的经典课题。它不仅是算术逻辑单元(ALU)的核心组件,更是理解数字系统如何执行基本运算的关键。今天,我们不…...

树莓派GPIO排针焊接与外壳组装全攻略:从焊接技巧到机械装配
1. 项目概述与核心价值如果你手头有一块树莓派,并且打算用它来驱动一个像Joy Bonnet这样的游戏手柄扩展板,或者任何其他需要直接插在GPIO排针上的HAT(硬件附加板),那么你迟早会面临一个非常具体且有点“劝退”的硬件关…...

Taotoken用量看板与账单追溯功能在项目复盘中的实际价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与账单追溯功能在项目复盘中的实际价值 1. 复盘场景与数据需求 在项目月度复盘会议上,技术团队经常面…...

QtScrcpy终极指南:如何免费实现高清Android投屏与多设备控制
QtScrcpy终极指南:如何免费实现高清Android投屏与多设备控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtS…...

ANNA框架:构建AI原生应用的智能体开发指南
1. 项目概述:一个面向未来的AI原生应用框架最近在GitHub上闲逛,发现了一个让我眼前一亮的项目:ANNA。这个项目由开发者NikolaiGL发起,乍一看名字,你可能会联想到某个AI模型或者工具库,但深入研究后你会发现…...

大一学生揭秘科罗拉多矿业学院扫描技术:掌控投影仪和摄像头,问题待修复
大一学生掌控科罗拉多矿业学院投影仪和摄像头,扫描技术揭秘与问题修复情况曝光在科罗拉多矿业学院开启大一生活时,我发现当地 DNS 服务器会为每个连网设备分配子域名,如 “meow” 设备在校园无线网络显示为 “meow.mines.edu”,但…...