数据编织 VS 数据仓库 VS 数据湖

目录
- 1. 什么是数据编织?
- 2. 数据编织的工作原理
- 3. 代码示例
- 4. 数据编织的优势
- 5. 应用场景
- 6. 数据编织 vs 数据仓库
- 6.1 数据存储方式
- 6.2 数据更新和实时性
- 6.3 灵活性和可扩展性
- 6.4 查询性能
- 6.5 数据治理和一致性
- 6.6 适用场景
- 6.7 代码示例比较
- 7. 数据编织 vs 数据湖
- 7.1 数据存储和结构
- 7.2 数据处理方式
- 7.3 数据治理和质量控制
- 7.4 查询和分析能力
- 7.5 使用场景
- 7.6 代码示例比较
- 7.7 总结
- 总结
1. 什么是数据编织?
数据编织(Data Weaving)是一种高级数据集成技术,旨在将来自不同源头、格式各异的数据进行无缝整合,以创建一个统一的、可查询的数据视图。这种方法不同于传统的ETL(提取、转换、加载)过程,它更加灵活、动态,能够在不破坏原始数据结构的情况下创建数据之间的关联。
数据编织的核心理念是:
- 保留原始数据的完整性
- 创建数据之间的逻辑链接
- 提供实时的数据整合视图
- 支持跨源数据的复杂查询

对比一下常见的概念
| 特征 | 数据编织 | 数据仓库 | 数据湖 |
|---|---|---|---|
| 数据存储 | 虚拟集成,数据保留在原始位置 | 集中式存储,结构化数据 | 分布式存储,支持所有类型数据 |
| 数据结构 | 通过语义层定义 | 预定义的模式(如星型、雪花) | 灵活,支持结构化、半结构化、非结构化 |
| 数据处理 | 实时查询转换 | ETL(提取、转换、加载) | ELT(提取、加载、转换) |
| 更新频率 | 实时/近实时 | 定期批量更新 | 可以实时或批量 |
| 数据量 | 中等到大 | 大 | 极大 |
| 数据质量 | 依赖源系统,通过语义层提升 | 高,经过清洗和转换 | 原始数据,质量参差不齐 |
| 查询性能 | 对于跨源查询较快 | 对预定义查询很快 | 可能较慢,需要优化 |
| 灵活性 | 非常高 | 相对固定 | 高 |
| 用户群 | 业务分析师,数据科学家 | 业务用户,分析师 | 数据科学家,高级分析师 |
| 主要用途 | 实时数据集成,跨系统分析 | 报表,商业智能 | 大数据分析,机器学习 |
| 数据治理 | 通过元数据和语义映射 | 集中化管理,易于实施 | 挑战大,需要额外工具 |
| 成本 | 中等 | 高 | 相对较低 |
| 实现复杂度 | 中等 | 高 | 低到中等 |
| 扩展性 | 高 | 受限于中央系统 | 非常高 |
| 历史数据处理 | 取决于源系统 | 优秀 | 优秀 |
| 数据探索 | 受限于预定义的语义层 | 受限于预定义的模式 | 非常适合 |
| 适用场景 | 需要实时、统一数据视图的企业 | 需要稳定、一致报告的企业 | 需要存储和分析大量多样化数据的组织 |
 |
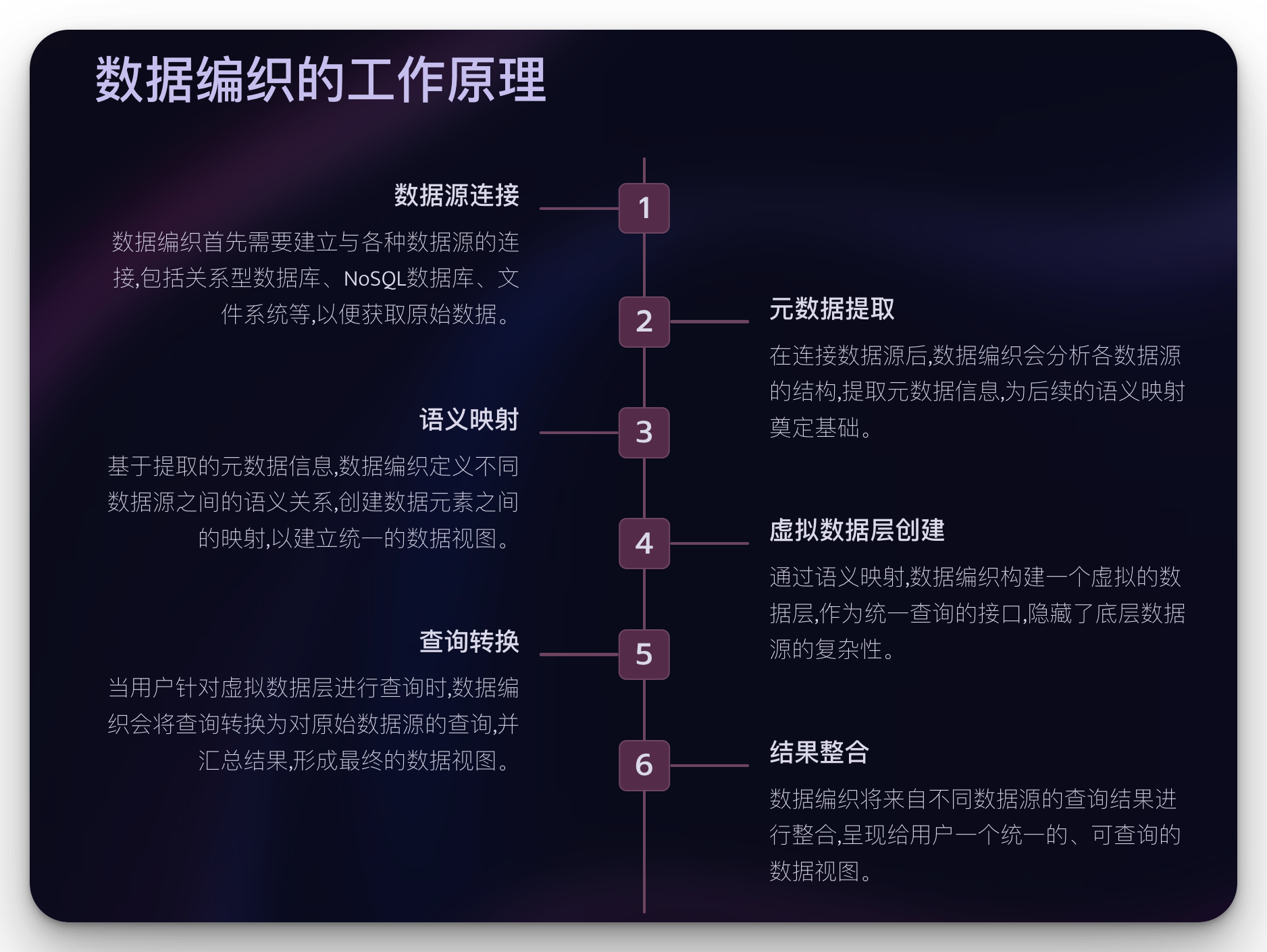
2. 数据编织的工作原理
数据编织通过以下步骤实现:
-
数据源连接: 建立与各种数据源的连接,包括关系型数据库、NoSQL数据库、文件系统等。
-
元数据提取: 分析各数据源的结构,提取元数据信息。
-
语义映射: 定义不同数据源之间的语义关系,创建数据元素之间的映射。
-
虚拟数据层创建: 基于语义映射构建一个虚拟的数据层,作为统一查询的接口。
-
查询转换: 将针对虚拟数据层的查询转换为对原始数据源的查询。
-
结果整合: 汇总来自不同数据源的查询结果,形成最终的数据视图。
3. 代码示例
下面是一个使用Python实现简单数据编织的示例代码:
import pandas as pd
from sqlalchemy import create_engineclass DataWeaver:def __init__(self):self.data_sources = {}self.virtual_view = Nonedef add_data_source(self, name, connection_string):engine = create_engine(connection_string)self.data_sources[name] = enginedef create_virtual_view(self, mapping):self.virtual_view = mappingdef query(self, query_string):results = {}for source, fields in self.virtual_view.items():if source in self.data_sources:engine = self.data_sources[source]sql = f"SELECT {', '.join(fields)} FROM {source}"results[source] = pd.read_sql(sql, engine)return pd.concat(results.values(), axis=1)# 使用示例
weaver = DataWeaver()# 添加数据源
weaver.add_data_source('customers', 'sqlite:///customers.db')
weaver.add_data_source('orders', 'sqlite:///orders.db')# 创建虚拟视图
weaver.create_virtual_view({'customers': ['id', 'name', 'email'],'orders': ['customer_id', 'order_date', 'total_amount']
})# 执行查询
result = weaver.query("SELECT * FROM virtual_view")
print(result)
这个简化的例子展示了数据编织的基本概念。在实际应用中,数据编织系统会更加复杂,需要处理更多的数据源类型、更复杂的查询转换和更高效的数据整合策略。
4. 数据编织的优势

-
数据灵活性: 不需要将所有数据物理地整合到一个地方,保持了数据的分布式特性。
-
实时性: 可以提供近乎实时的数据视图,而不是依赖于周期性的ETL过程。
-
降低存储成本: 避免了数据冗余存储,节省了存储空间。
-
数据治理: 通过元数据管理和语义映射,提高了数据的可理解性和可用性。
-
查询性能: 通过智能查询优化,可以提高跨源数据查询的性能。
5. 应用场景
数据编织技术在多个领域都有广泛应用,例如:
- 企业数据整合
- 物联网数据分析
- 客户360度视图
- 实时报表和仪表板
- 大数据湖和数据仓库的结合

6. 数据编织 vs 数据仓库
虽然数据编织和数据仓库都旨在整合和管理数据,但它们在方法和应用上有显著差异。让我们来详细比较一下:
6.1 数据存储方式
-
数据仓库:
- 采用集中式存储模型
- 将数据从各源系统提取、转换后存入一个集中的仓库
- 通常使用结构化的模式,如星型或雪花模式
-
数据编织:
- 采用分布式的虚拟集成模型
- 数据保留在原始源系统中
- 创建一个虚拟层来整合和呈现数据,无需物理移动
6.2 数据更新和实时性
-
数据仓库:
- 通常采用批量更新模式
- 数据更新有一定的延迟,通常是每日或每周
- 适合历史数据分析和趋势报告
-
数据编织:
- 支持实时或近实时的数据访问
- 直接从源系统获取最新数据
- 适合需要最新数据的实时分析和决策支持
6.3 灵活性和可扩展性
-
数据仓库:
- 架构相对固定,修改模式需要较大工作量
- 扩展性受限于中央存储系统的容量
- 添加新数据源可能需要重新设计ETL流程
-
数据编织:
- 高度灵活,可以轻松添加或修改数据源
- 扩展性强,可以无缝集成新的数据系统
- 适应性强,能快速响应业务需求变化
6.4 查询性能
-
数据仓库:
- 对预定义的查询和报表性能优秀
- 可以通过预聚合和索引优化提高性能
- 复杂查询可能需要大量计算资源
-
数据编织:
- 复杂查询性能可能不如优化过的数据仓库
- 但对于跨源的即时查询有优势
- 通过智能查询优化和缓存策略可以提高性能
6.5 数据治理和一致性
-
数据仓库:
- 提供一个"单一事实来源"
- 数据一致性高,易于实施数据治理
- 适合需要严格数据质量控制的场景
-
数据编织:
- 保留原始数据的完整性
- 通过元数据管理和语义映射实现数据治理
- 需要更复杂的机制来确保跨源数据的一致性
6.6 适用场景
-
数据仓库:
- 适合大规模的历史数据分析
- 企业级报表和商业智能应用
- 需要高度结构化和一致性的数据环境
-
数据编织:
- 适合需要实时数据整合的场景
- 动态的、跨系统的数据分析
- 快速变化的业务环境,需要灵活数据访问
6.7 代码示例比较
为了更直观地展示两种方法的区别,让我们看一下简化的代码示例:
数据仓库ETL过程:
import pandas as pd
from sqlalchemy import create_engine# 连接源数据库和数据仓库
source_engine = create_engine('sqlite:///source.db')
warehouse_engine = create_engine('sqlite:///warehouse.db')# 提取数据
df = pd.read_sql("SELECT * FROM source_table", source_engine)# 转换数据
df['new_column'] = df['column_a'] + df['column_b']# 加载到数据仓库
df.to_sql('warehouse_table', warehouse_engine, if_exists='replace')
数据编织过程:
import pandas as pd
from sqlalchemy import create_engineclass DataWeaver:def __init__(self):self.sources = {}def add_source(self, name, connection_string):self.sources[name] = create_engine(connection_string)def query(self, virtual_query):results = {}for source, query in virtual_query.items():results[source] = pd.read_sql(query, self.sources[source])return pd.concat(results.values(), axis=1)# 使用示例
weaver = DataWeaver()
weaver.add_source('source1', 'sqlite:///source1.db')
weaver.add_source('source2', 'sqlite:///source2.db')result = weaver.query({'source1': "SELECT column_a, column_b FROM table1",'source2': "SELECT column_c FROM table2"
})
这些示例清楚地展示了两种方法在数据处理上的根本区别。
数据仓库方法涉及数据的提取、转换和加载,而数据编织方法则是通过虚拟查询直接访问源数据。
总的来说,数据编织和数据仓库各有其优势和适用场景。数据编织为现代数据集成提供了更灵活、实时的解决方案,特别适合快速变化的业务环境。而数据仓库则在处理大规模历史数据分析和提供一致的企业级报告方面仍然占据重要地位。在实际应用中,许多组织选择结合这两种方法,以充分利用它们的优势。
7. 数据编织 vs 数据湖

数据编织和数据湖都是现代数据架构中的重要组成部分,但它们在设计理念和应用场景上有明显的不同。让我们来比较一下:
7.1 数据存储和结构
-
数据湖:
- 存储大量原始数据,包括结构化、半结构化和非结构化数据
- 数据以原始格式存储,通常使用对象存储或分布式文件系统
- “存储优先,架构滞后”(Schema-on-read)的方法
-
数据编织:
- 不直接存储数据,而是创建虚拟的数据视图
- 通过元数据和语义层连接不同的数据源
- 保持数据在原始位置,创建逻辑关联
7.2 数据处理方式
-
数据湖:
- 支持批处理和流处理
- 通常需要数据科学家或数据工程师来处理和分析数据
- 适合大规模数据探索和高级分析
-
数据编织:
- 主要关注实时数据集成和查询
- 通过预定义的语义映射简化数据访问
- 适合业务用户进行即时数据分析和报告
7.3 数据治理和质量控制
-
数据湖:
- 数据治理是一个挑战,容易变成"数据沼泽"
- 需要额外的工具和流程来确保数据质量和可追溯性
- 适合存储大量原始数据,但可能导致数据冗余
-
数据编织:
- 通过元数据管理和语义映射提供更好的数据治理
- 保持数据在原始源中,减少数据冗余
- 更容易实现数据血缘和影响分析
7.4 查询和分析能力
-
数据湖:
- 支持深度分析和机器学习任务
- 查询性能可能较慢,特别是对于未优化的数据
- 适合大规模数据挖掘和复杂分析
-
数据编织:
- 优化用于快速、跨源数据查询
- 提供统一的数据访问层,简化复杂查询
- 适合实时报告和交互式分析
7.5 使用场景
-
数据湖:
- 大数据存储和分析
- 数据科学和机器学习项目
- 长期数据存档和合规性要求
-
数据编织:
- 企业数据集成和实时报告
- 客户360度视图
- 跨系统数据分析和决策支持
7.6 代码示例比较
为了更直观地理解两者的区别,让我们看一下简化的代码示例:
数据湖处理示例(使用PySpark):
from pyspark.sql import SparkSession# 创建Spark会话
spark = SparkSession.builder.appName("DataLakeProcessing").getOrCreate()# 从数据湖读取数据
raw_data = spark.read.format("parquet").load("s3://data-lake-bucket/raw-data/")# 数据处理
processed_data = raw_data.filter(raw_data.column_a > 100)\.groupBy("column_b")\.agg({"column_c": "sum"})# 将结果写回数据湖
processed_data.write.format("parquet").mode("overwrite").save("s3://data-lake-bucket/processed-data/")
数据编织示例:
class DataWeaver:def __init__(self):self.sources = {}self.semantic_layer = {}def add_source(self, name, connection_string):self.sources[name] = create_engine(connection_string)def define_semantic_mapping(self, virtual_table, mapping):self.semantic_layer[virtual_table] = mappingdef query(self, virtual_query):# 解析虚拟查询,映射到实际数据源actual_queries = self.translate_query(virtual_query)results = {}for source, query in actual_queries.items():results[source] = pd.read_sql(query, self.sources[source])return pd.concat(results.values(), axis=1)def translate_query(self, virtual_query):# 这里应该包含复杂的查询转换逻辑# 简化版本仅作演示return {source: f"SELECT {', '.join(columns)} FROM {table}"for source, (table, columns) in self.semantic_layer.items()}# 使用示例
weaver = DataWeaver()
weaver.add_source('source1', 'postgresql://user:pass@localhost:5432/db1')
weaver.add_source('source2', 'mysql://user:pass@localhost:3306/db2')weaver.define_semantic_mapping('virtual_customer_view', {'source1': ('customers', ['id', 'name', 'email']),'source2': ('orders', ['customer_id', 'order_date', 'total'])
})result = weaver.query("SELECT * FROM virtual_customer_view")
这些示例展示了数据湖和数据编织在数据处理方式上的根本区别。数据湖侧重于大规模数据的存储和处理,而数据编织侧重于创建虚拟的、统一的数据视图。
7.7 总结
数据湖和数据编织各有其优势和适用场景:
-
数据湖适合存储和分析大量多样化的原始数据,特别是在需要进行深度数据挖掘和高级分析的场景。
-
数据编织则更适合需要实时、跨系统数据集成的场景,尤其是在业务用户需要快速访问和分析来自多个源系统数据的情况下。
在实际应用中,许多组织选择将数据湖和数据编织结合使用,以充分利用两者的优势。例如,可以使用数据湖存储和处理大量原始数据,然后通过数据编织技术为这些数据创建更易于访问和分析的虚拟视图。
这种组合方法可以提供强大的数据存储和处理能力,同时也确保了数据的可访问性和实时性,从而满足各种复杂的业务需求。
总结
数据编织作为一种先进的数据集成方法,为大数据时代的数据管理和分析提供了新的可能。
它不仅提高了数据的可用性和灵活性,还为企业提供了更快速、更全面的数据洞察能力。
随着技术的不断发展,数据编织必将在大数据生态系统中扮演越来越重要的角色。

相关文章:
数据编织 VS 数据仓库 VS 数据湖
目录 1. 什么是数据编织?2. 数据编织的工作原理3. 代码示例4. 数据编织的优势5. 应用场景6. 数据编织 vs 数据仓库6.1 数据存储方式6.2 数据更新和实时性6.3 灵活性和可扩展性6.4 查询性能6.5 数据治理和一致性6.6 适用场景6.7 代码示例比较 7. 数据编织 vs 数据湖7.1 数据存储…...
——CSS分组和嵌套,尺寸(Dimension))
CSS(十一)——CSS分组和嵌套,尺寸(Dimension)
CSS 分组 和 嵌套 选择器 分组选择器 举个例子,多个标签有同一个样式,就可以不一个一个分开写,使用分组选择器 比如: h1 {color:green; } h2 {color:green; } p {color:green; } 就可以写为: h1,h2,p {color…...

必备神器!三款优秀远程控制电脑软件推荐
嘿,各位职场小伙伴们,今儿个咱们来聊聊个挺实用又带点“科技范儿”的话题——电脑远程控制那点事儿。作为刚踏入职场不久的新人,我深刻体会到,在这信息爆炸的时代,掌握几招远程操作的技能,简直就是给自个儿…...

关于正运动学解机器人手臂算法
机器人正运动学是机器人学的一个分支,研究机器人的运动和位置之间的关系。它通过解析机器人的结构和关节参数,以及给定的关节角度,来计算机器人的末端执行器的位置和姿态。 机器人正运动学算法通常使用DH(Denavit-Hartenberg&…...

MySQL 约束 (constraint)
文章目录 约束(constraint)列级约束和表级约束给约束起名字(constraint)非空约束(no null)检查约束(check)唯一性约束 (unique)主键约束 (primary key)主键分类单一主键复合主键主键自增 (auto_increment) 外键约束外什…...

用python程序发送文件(python实例二十六)
目录 1.认识Python 2.环境与工具 2.1 python环境 2.2 Visual Studio Code编译 3.文件上传 3.1 代码构思 3.2 服务端代码 3.3 客户端代码 3.4 运行结果 4.总结 1.认识Python Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具…...
最新源支付系统源码 V7版全开源 免授权 附搭建教程
本文来自:最新源支付系统源码 V7版全开源 免授权 附搭建教程 - 源码1688 简介: 最新源支付系统源码_V7版全开源_免授权_附详细搭建教程_站长亲测 YPay是专为个人站长打造的聚合免签系统,拥有卓越的性能和丰富的功能。它采用全新轻量化的界面…...

HTML:lang属性作用
lang作用 用法常见语言代码优点示例结构效果说明分析HTML 基础结构导航栏内容部分总结 扩展 用法 HTML 文档级别: 在 <html> 标签上使用 lang 属性,指定整个文档的语言。 <!DOCTYPE html> <html lang"en"> <head><meta charse…...
)
Android SurfaceFlinger——纹理的绘制流程(二十八)
在系统开机动画的播放流程中,会从给定的资源文件中加载纹理数据并初始化一个 OpenGL 纹理对象,这里我们就来解析软件模拟纹理的绘制流程。 一、纹理概述 在 Android 的 SurfaceFlinger 系统组件中,纹理(Texture)是一个核心概念,特别是在涉及到图形渲染和显示的过程中。 …...

深入解析Memcached:C#中的应用与实战案例
目录 Memcached简介Memcached的特点Memcached的工作原理Memcached的应用场景Memcached的安装和配置Memcached与C#的集成 引入依赖配置Memcached客户端C#代码示例 存储数据读取数据删除数据深入解析Memcached 数据存储和过期策略分布式架构性能优化实战案例 缓存数据库查询结果实…...

keyring 库
目录 安装 keyring 基本用法 1. 设置密码 2. 获取密码 3. 删除密码 4. 返回当前使用的默认密钥环 5. 列出所有密码 支持的后端 keyring 是一个 Python 库,用于将敏感信息(如密码)安全地存储在操作系统的密码管理器中。它支持多种平台…...

[css3] 如何设置边框颜色渐变
div {border: 4px solid;border-image: linear-gradient(to right, #8f41e9, #578aef) 1; }参考: 5种CSS实现渐变色边框(Gradient borders方法的汇总...

Redux +Toolkit 工具包快速入门
您将学到什么 如何设置并使用 Redux Toolkit 和 React-Redux 先决条件 熟悉ES6 语法和功能了解 React 术语:JSX、State、Function Components 、 Props和Hooks理解Redux 术语和概念 1、基本使用 1.1、安装 Redux Toolkit 和 React- Redux 将 Redux Toolkit 和 Rea…...

【Python数据增强】图像数据集扩充
前言:该脚本用于图像数据增强,特别是目标检测任务中的图像和标签数据增强。通过应用一系列数据增强技术(如旋转、平移、裁剪、加噪声、改变亮度、cutout、翻转等),生成多样化的图像数据集,以提高目标检测模…...

实时同步:使用 Canal 和 Kafka 解决 MySQL 与缓存的数据一致性问题
目录 1. 准备工作 2. 将需要缓存的数据存储 Redis 3. 监听 canal 存储在 Kafka Topic 中数据 1. 准备工作 1. 开启并配置MySQL的 BinLog(MySQL 8.0 默认开启) 修改配置:C:\ProgramData\MySQL\MySQL Server 8.0\my.ini log-bin"HELO…...

WINUI——Microsoft.UI.Xaml.Markup.XamlParseException:“无法找到与此错误代码关联的文本。
开发环境 VS2022 .net core6 问题现象 在Canvas内的子控件要绑定Canvas的兄弟控件的一个属性,在运行时出现了下述报错。 可能原因 在 WinUI(特别是用于 UWP 或 Windows App SDK 的版本)中,如果你尝试在 XAML 中将 Canvas 内的…...

C语言 | Leetcode C语言题解之第283题移动零
题目: 题解: void swap(int *a, int *b) {int t *a;*a *b, *b t; }void moveZeroes(int *nums, int numsSize) {int left 0, right 0;while (right < numsSize) {if (nums[right]) {swap(nums left, nums right);left;}right;} }...

WPF项目实战视频《二》(主要为prism框架)
14.prism框架知识(1) 使用在多个平台的MVVM框架 新建WPF项目prismDemo 项目中:工具-NuGet包管理:安装Prism.DryIoc框架 在git中能看Prism的结构和源代码:git链接地址 例如:Prism/src/Wpf/Prism.DryIoc.Wpf…...

【微信小程序实战教程】之微信小程序 WXS 语法详解
WXS语法 WXS是微信小程序的一套脚本语言,其特性包括:模块、变量、注释、运算符、语句、数据类型、基础类库等。在本章我们主要介绍WXS语言的特性与基本用法,以及 WXS 与 JavaScript 之间的不同之处。 1 WXS介绍 在微信小程序中,…...

Android中Service学习记录
目录 一 概述二 生命周期2.1 启动服务startService()2.2 绑定服务bindService()2.3 先启动后绑定2.4 先绑定后启动 三 使用3.1 本地服务(启动式)3.2 可通信的服务(绑定式)3.3 前台服务3.4 IntentService 总结参考 一 概述 Servic…...

Linux服务器安全基线自动化实践:基于Ansible的加固方案
1. 项目概述与核心价值“安全加固”这个词,对于任何一个负责线上系统运维、应用部署或者个人服务器管理的朋友来说,都绝不陌生。它就像给自家房子装防盗门、安监控一样,是基础且必要的工作。然而,现实情况往往是:我们面…...

GraphQL-WS vs 传统GraphQL:为什么WebSocket是实时应用的首选
GraphQL-WS vs 传统GraphQL:为什么WebSocket是实时应用的首选 【免费下载链接】graphql-ws Coherent, zero-dependency, lazy, simple, GraphQL over WebSocket Protocol compliant server and client. 项目地址: https://gitcode.com/gh_mirrors/gr/graphql-ws …...

UI-TARS桌面版终极指南:用自然语言控制电脑的免费AI助手
UI-TARS桌面版终极指南:用自然语言控制电脑的免费AI助手 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop …...

别再用docker tag了!深入理解Containerd生态:crictl、ctr与nerdctl到底该怎么选?
深入解析Containerd生态:crictl、ctr与nerdctl的镜像管理实战指南 在容器技术快速发展的今天,越来越多的开发者正从Docker生态转向Containerd这一更轻量、更符合Kubernetes标准的运行时环境。但当我们真正开始使用Containerd时,往往会遇到一个…...

开源商业技能知识库:从道法术器到实战应用的全解析
1. 项目概述:一个面向商业技能的开源知识库 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫 openclaw-business-skills 。光看名字,你可能会觉得这又是一个普通的“商业技能”教程合集。但点进去仔细研究后,我发现…...

装机解惑:Bios中的Secure Boot与CSM,为何相爱相杀?
1. Secure Boot与CSM:现代PC的引导之争 刚装好的新电脑突然黑屏,这种经历估计不少DIY玩家都遇到过。上周我就帮朋友处理了这么个案例:他为了省钱继续用老显卡GTX650ti,结果在新配的13代酷睿主机上死活点不亮屏幕。这背后其实是UEF…...

【图解CANFD】- 深入剖析TDC与SSP:如何精准补偿收发器延迟并优化第二采样点
1. CANFD网络中的收发器延迟挑战 当你在汽车电子项目中第一次遇到CANFD高速通信时,可能会发现一个有趣的现象:明明发送端已经发出了信号,接收端却总是"慢半拍"。这种延迟就像两个人在嘈杂的餐厅里对话,一个人说完话后&a…...

Claude与Codex双引擎协作:AI代码生成的新范式与实践
1. 项目概述:当Claude遇上Codex,双引擎驱动的代码生成新范式最近在GitHub上看到一个挺有意思的项目,叫claude-codex-duo。光看名字,你大概就能猜到它的核心玩法——把Anthropic的Claude和OpenAI的Codex这两个顶级的AI模型给“撮合…...

什么是 TRAE IDE?
TRAE IDE 是一款深度融合 AI 能力的开发工具,提供从代码编写、项目理解、调试运行到变更管理的完整开发体验。你可以像使用传统 IDE 一样掌控每一步,也可以把复杂任务交给 AI 智能体规划和执行。使用场景TRAE IDE 覆盖日常开发与复杂工程任务,…...

利用Taotoken为开源项目提供可配置的AI功能模块
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为开源项目提供可配置的AI功能模块 为开源项目集成人工智能能力,正成为提升项目实用性和吸引力的有效方式…...