Python3网络爬虫开发实战(3)网页数据的解析提取
文章目录
- 一、XPath
- 1. 选取节点
- 2. 查找某个特定的节点或者包含某个指定的值的节点
- 3. XPath 运算符
- 4. 节点轴
- 5. 利用 lxml 使用 XPath
- 二、CSS
- 三、Beautiful Soup
- 1. 信息提取
- 2. 嵌套选择
- 3. 关联选择
- 4. 方法选择器
- 5. css 选择器
- 四、PyQuery
- 1. 初始化
- 2. css 选择器
- 3. 信息提取
- 4. 节点操作
- 五、Parsel
- 1. XPath 和 CSS 选择器
- 2. 信息提取
- 3. 正则提取

一、XPath
XPath 的全称 XML Path Language,即 XML 路径语言,用来在 XML 文档中查找信息,同样适用于 HTML 文档的搜索;
1. 选取节点
| 表达式 | 描述 |
|---|---|
| //* | 选取所有节点 |
| / | 取子节点 |
| // | 取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| /@href | 选取节点的href属性 |
| /[@class=“item”] | 选择 class 为 item 的子节点 |
| /text() | 获取文本 |
| //[contains(@class, “li”)] | 选择 class 中包含 li 的子节点 |
| //[contains(@class, “li”) and contains(@class, “ll”)] | 选择 class 中包含 li 和 ll 的子节点 |
| //[contains(@class, “li”) and @name=“item”] | 选择 class 包含 li 且 name 属性为 item 的节点 |
| //[contains(text(), “内容”] | 选择文本中包含内容的节点 |
| //th[@class="id " and position()=1] | 选择 class 为 id 的第一个位置的 th 节点 |
| //div[(text()=‘更新’)] | 选择文本为 更新 的 div 节点 |
2. 查找某个特定的节点或者包含某个指定的值的节点
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
3. XPath 运算符
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。 如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
4. 节点轴
| 轴名称 | 结果 |
|---|---|
| ancestor:: | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self:: | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute:: | 选取当前节点的所有属性。 |
| child:: | 选取当前节点的所有子元素。 |
| descendant:: | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self:: | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following:: | 选取文档中当前节点的结束标签之后的所有节点。 |
| following-sibling:: | 选取当前节点之后的所有兄弟节点 |
| namespace:: | 选取当前节点的所有命名空间节点。 |
| parent:: | 选取当前节点的父节点。 |
| preceding:: | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling:: | 选取当前节点之前的所有同级节点。 |
5. 利用 lxml 使用 XPath
from lxml import etreetext = 'html 代码'
html = etree.HTML(text) # 会自动修正 HTML 代码
result = html.xpath('xpath 选择器')
二、CSS
| 选择器 | 示例 | 示例说明 |
|---|---|---|
| .class | .intro | 选择所有class="intro"的元素 |
| #id | #firstname | 选择所有id="firstname"的元素 |
| * | * | 选择所有元素 |
| element | p | 选择所有<p>元素 |
| element,element | div,p | 选择所有<div>元素和 <p> 元素 |
| element.class | p.hometown | 选择所有 class=“hometown” 的<p> 元素 |
| element element | div p | 选择<div>元素内的所有<p>元素 |
| element>element | div>p | 选择所有父级是<div> 元素的 <p> 元素 |
| element+element | div+p | 选择所有紧跟在 <div> 元素之后的第一个 <p> 元素 |
| [attribute] | [target] | 选择所有带有target属性元素 |
| [attribute=value] | [target=-blank] | 选择所有使用target="-blank"的元素 |
| [attribute~=value] | [title~=flower] | 选择标题属性包含单词"flower"的所有元素 |
| [attribute|=language] | [lang|=en] | 选择 lang 属性等于 en,或者以 en- 为开头的所有元素 |
| :link | a:link | 选择所有未访问链接 |
| :visited | a:visited | 选择所有访问过的链接 |
| :active | a:active | 选择活动链接 |
| :hover | a:hover | 选择鼠标在链接上面时 |
| :focus | input:focus | 选择具有焦点的输入元素 |
| :first-letter | p:first-letter | 选择每一个<p>元素的第一个字母 |
| :first-line | p:first-line | 选择每一个<p>元素的第一行 |
| :first-child | p:first-child | 指定只有当<p>元素是其父级的第一个子级的样式。 |
| :before | p:before | 在每个<p>元素之前插入内容 |
| :after | p:after | 在每个<p>元素之后插入内容 |
| :lang(language) | p:lang(it) | 选择一个lang属性的起始值="it"的所有<p>元素 |
| element1~element2 | p~ul | 选择p元素之后的每一个ul元素 |
| [attribute^=value] | a[src^=“https”] | 选择每一个src属性的值以"https"开头的元素 |
| [attribute$=value] | a[src$=“.pdf”] | 选择每一个src属性的值以".pdf"结尾的元素 |
| [attribute*=value] | a[src*=“runoob”] | 选择每一个src属性的值包含子字符串"runoob"的元素 |
| p:firs-of-type | p:first-of-type | 选择每个p元素是其父级的第一个p元素 |
| :last-of-type | p:last-of-type | 选择每个p元素是其父级的最后一个p元素 |
| :only-of-type | p:only-of-type | 选择每个p元素是其父级的唯一p元素 |
| :only-child | p:only-child | 选择每个p元素是其父级的唯一子元素 |
| :nth-child(n) | p:nth-child(2) | 选择每个p元素是其父级的第二个子元素 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择每个p元素是其父级的第二个p元素 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 |
| :last-child | p:last-child | 选择每个p元素是其父级的最后一个子级。 |
| :root | :root | 选择文档的根元素 |
| :empty | p:empty | 选择每个没有任何子级的p元素(包括文本节点) |
| :target | #news:target | 选择当前活动的#news元素(包含该锚名称的点击的URL) |
| :enabled | input:enabled | 选择每一个已启用的输入元素 |
| :disabled | input:disabled | 选择每一个禁用的输入元素 |
| :checked | input:checked | 选择每个选中的输入元素 |
| :not(selector) | :not§ | 选择每个并非p元素的元素 |
| ::selection | ::selection | 匹配元素中被用户选中或处于高亮状态的部分 |
| :out-of-range | :out-of-range | 匹配值在指定区间之外的input元素 |
| :in-range | :in-range | 匹配值在指定区间之内的input元素 |
| :read-write | :read-write | 用于匹配可读及可写的元素 |
| :read-only | :read-only | 用于匹配设置 “readonly”(只读) 属性的元素 |
| :optional | :optional | 用于匹配可选的输入元素 |
| :required | :required | 用于匹配设置了 “required” 属性的元素 |
| :valid | :valid | 用于匹配输入值为合法的元素 |
| :invalid | :invalid | 用于匹配输入值为非法的元素 |
三、Beautiful Soup
Beautiful Soup 支持的解析器有四种: html.parser,lxml,lxml-xml,html5lib
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,“html.parser”) | 1 Python的内置标准库 2 执行速度适中 3 文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup,“lxml”) | 1.速度快 2.文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup,[“lxml-xml”]) | 1.速度快 2.唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,“html5lib”) | 1 最好的容错性 2以浏览器的方式解析文档 3生成HTML5格式的文档 | 1.速度慢 2.不依赖外部扩展 |
from bs4 import BeautifulSouphtml = 'html 文本'
soup = BeautifulSoup(html, 'lxml')
soup.prettify() # 可以将杂乱的 html 文本格式化,soup对于不标准的 HTML 字符串,自动更正格式,与prettify 无关;
1. 信息提取
soup.tagname 得到的结果是 bs4.element.Tag 类型,而 bs4.element.Tag 可以调用 string,name,attrs 获取 Tag 的信息;
soup.title # 选择 soup 下的第一个 title tag节点
soup.title.string # soup 下第一个 title tag节点的文本
soup.title.get_text() # soup 下第一个 title tag节点的文本
soup.title.name # soup 下第一个 title tag节点的名称 即title
soup.title.attrs # soup 下第一个 title tag 节点的attrs 是一个字典
2. 嵌套选择
bs4.element.Tag 类型在继续调用 tagname 后得到的仍然是 bs4.element.Tag 类型,因此我们可以嵌套获取信息
soup.head.title.string # 获得 soup 下第一个 head 下第一个 title 的 string
3. 关联选择
选取节点后,如果想要获取它的直接子节点,可以调用 contents 属性,实例如下
from bs4 import BeautifulSouphtml = 'html 文本'
soup = BeautifulSoup(html, 'lxml')soup.p.contents # 获得直接子节点
soup.p.children # 等价于 soup.p.contentssoup.p.descendants # 获得所有的子孙节点soup.p.parent # 获得p节点的父节点soup.p.parents # 获取p节点所有祖先节点soup.next_sibling # 获取节点的下一个兄弟节点soup.previous_sibling # 获取节点的上一个兄弟节点soup.next_siblings # 获取节点的后面的所有兄弟节点soup.previous_siblings # 获取节点的前面的所有兄弟节点
4. 方法选择器
# 选择所有 tag 为 li,属性 id 为 list,text 中包含 link 的节点
soup.find_all(name='li', attrs={'id':'list'}, text=re.compile('link'))# 选择第一个 tag 为 li,属性 id 为 list,text 中包含 link 的节点
soup.find(name='li', attrs={'id':'list'}, text=re.compile('link'))
- find_parents 和 find_parent:前者返回所有的祖先节点,后者返回父节点;
- find_next_siblings 和 find_next_sibling:前者返回后面的所有兄弟节点,后者返回前面第一个兄弟节点;
- find_previous_siblings 和 find_previous_sibling:前者返回前面的所有兄弟节点,后者返回后面第一个兄弟节点;
- find_all_next 和 find_next:前者返回节点后面所有符合要求的节点,后者返回后面第一个符合要求的节点;
- find_all_previous 和 find_previous:前者返回节点前面所有符合条件的节点,后者返回前面第一个符合要求的节点;
5. css 选择器
利用 soup.select(‘css选择器’) 来选择 tag,利用 select 返回的结果一定是一个列表
from bs4 import BeautifulSoupsoup = BeautifulSoup(html, 'lxml')
soup.select('li')
四、PyQuery
1. 初始化
from pyquery import PyQuery# 字符串的初始化
html = "文档字符串"
doc = PyQuery(html)# url的初始化
doc = PyQuery(url='url 地址')# 文件的初始化
doc = PyQuery(filename='index.html')
2. css 选择器
使用起来非常简单,直接 doc(‘css选择器’)
from pyquery import PyQuerydoc = PyQuery(url='https://www.baidu.com')
for i in doc('div').items():# 解决编码问题print(i.html().encode('raw_unicode_escape').decode('utf-8', errors='ignore'))
3. 信息提取
- attr:当返回结果包含多个节点时,调用 attr 方法只会得到第一个节点的属性,若要得到所有则需要使用 items() 遍历;
- html:返回的是 第一个节点内部的纯文本信息;
- text:返回的是所有节点内部的纯文本信息;
from pyquery import PyQueryhtml = ''
doc = PyQuery(html)
a = doc('a')# 获取属性
a.attr('href')
a.attr.href# 获取文本
a.html()
a.text()
4. 节点操作
PyQuery 库提供了一系列方法对节点进行动态修改,例如为某个节点添加一个 class,移除某个节点等等,有时候这些操作会为提取信息带来极大的便利;
li = doc('li')# 移除/添加 class 中 active 值
li.removeClass('active')
li.addClass('active')# 获取 name 属性的值
li.attr('name')# 修改 name 属性的值 为 'link'
li.attr('name', 'link')# 获取纯文本
li.text()# 改变纯文本
li.text('hello')# 获取纯html
li.html()# 改变html
li.html('html文本')
五、Parsel
Parsel 库可以解析 HTML 和 XML ,并支持使用 XPath 和 CSS 选择器对内容进行提取和修改,同时还融合了正则表达式的提取功能,parsel 是 Python 最流行的爬虫框架 Scrapy 的底层支持;
1. XPath 和 CSS 选择器
from parsel import Selectorhtml = ''
selector = Selector(text=html)# css
items = selector.css('css选择器')
# xpath
items = selector.xpath('xpath选择器')
2. 信息提取
- get:从 selectorlist 对象中提取第一个 Selector 对象,然后输出其中的结果
- getall:从 selectorlist 对象中提取所有的 Selector 对象,然后以列表的形式输出其中的结果
# 提取文本
selector.css('css选择器::text()').get()
selector.css('css选择器::text()').getall()
selector.xpath('xpath//text()').get()
selector.xpath('xpath//text()').getall()# 提取属性
selector.css('css选择器::attr(name)').get()
selector.css('css选择器::attr(href)').getall()
selector.xpath('xpath/@name()').get()
selector.xpath('xpath/@href()').getall()
3. 正则提取
- 如果选择器中是属性或者文本,那么 re 对属性或者文本进行匹配
- 如果选择器中不是属性和文本,那么 re 对该节点的 html 字符进行匹配
from parsel import Selectorhtml = ''
selector = Selector(text=html)
result = selector.css('css选择器').re('a.*')
result = selector.xpath('xpath').re('a.*')result = selector.css('css选择器').re_first('a.*')
result = selector.xpath('xpath').re_first('a.*')
相关文章:
Python3网络爬虫开发实战(3)网页数据的解析提取
文章目录 一、XPath1. 选取节点2. 查找某个特定的节点或者包含某个指定的值的节点3. XPath 运算符4. 节点轴5. 利用 lxml 使用 XPath 二、CSS三、Beautiful Soup1. 信息提取2. 嵌套选择3. 关联选择4. 方法选择器5. css 选择器 四、PyQuery1. 初始化2. css 选择器3. 信息提取4. …...

基于 HTML+ECharts 实现监控平台数据可视化大屏(含源码)
构建监控平台数据可视化大屏:基于 HTML 和 ECharts 的实现 监控平台的数据可视化对于实时掌握系统状态、快速响应问题至关重要。通过直观的数据展示,运维团队可以迅速发现异常,优化资源配置。本文将详细介绍如何利用 HTML 和 ECharts 实现一个…...

立创梁山派--移植开源的SFUD和FATFS实现SPI-FLASH文件系统
本文主要是在sfud的基础上进行fatfs文件系统的移植,并不对sfud的移植再进行过多的讲解了哦,所以如果想了解sfud的移植过程,请参考我的另外一篇文章:传送门 正文开始咯 首先我们需要先准备资料准备好,这里对于fatfs的…...

MySQL之视图和索引实战
1.新建数据库 mysql> create database myudb5_indexstu; Query OK, 1 row affected (0.01 sec) mysql> use myudb5_indexstu; Database changed 2.新建表 1.学生表student,定义主键,姓名不能重名,性别只能输入男或女,所在…...

快速参考:用C# Selenium实现浏览器窗口缩放的步骤
背景介绍 在现代网络环境中,浏览器自动化已成为数据抓取和测试的重要工具。Selenium作为一个强大的浏览器自动化工具,能够与多种编程语言结合使用,其中C#是非常受欢迎的选择之一。在实际应用中,我们常常需要调整浏览器窗口的缩放…...

MyBatis 插件机制、分页插件如何实现的
MyBatis 插件机制允许开发者在 SQL 执行的各个阶段(如预处理、执行、结果处理等)中插入自定义逻辑,从而实现对 MyBatis 行为的扩展和增强。以下是 MyBatis 插件运行原理的详细介绍: 插件接口 MyBatis 插件通过实现 org.apache.i…...

CentOS6.0安装telnet-server启用telnet服务
CentOS6.0安装telnet-server启用telnet服务 一步到位 fp"/etc/yum.repos.d" ; cp -a ${fp} ${fp}.$(date %0y%0m%0d%0H%0M%0S).bkup echo [base] nameCentOS-$releasever - Base baseurlhttp://mirrors.163.com/centos-vault/6.0/os/$basearch/http://mirrors.a…...

H5+CSS+JS工作性价比计算器
工作性价比=平均日新x综合环境系数/35 x(工作时长+通勤时长—0.5 x摸鱼时长) x学历系数 如果代码中的公式不对,请指正 效果图 源代码 <!DOCTYPE html> <html> <head> <style> .calculator { width: 300px; padd…...
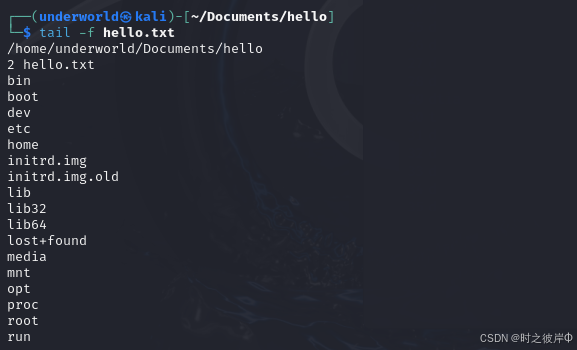
Linux:基础命令学习
目录 一、ls命令 实例:-l以长格式显示文件和目录信息 实例:-F根据文件类型在列出的文件名称后加一符号 实例: -R 递归显示目录中的所有文件和子目录。 实例: 组合使用 Home目录和工作目录 二、目录修改和查看命令 三、mkd…...

遇到Websocket就不会测了?别慌,学会这个Jmeter插件轻松解决....
websocket 是一种双向通信协议,在建立连接后,websocket服务端和客户端都能主动向对方发送或者接收数据,而在http协议中,一个request只能有一个response,而且这个response也是被动的,不能主动发起。 websoc…...

高性能 Java 本地缓存 Caffeine 框架介绍及在 SpringBoot 中的使用
在现代应用程序中,缓存是一种重要的性能优化技术,它可以显著减少数据访问延迟,降低服务器负载,提高系统的响应速度。特别是在高并发的场景下,合理地使用缓存能够有效提升系统的稳定性和效率。 Caffeine 是一个高性能的…...
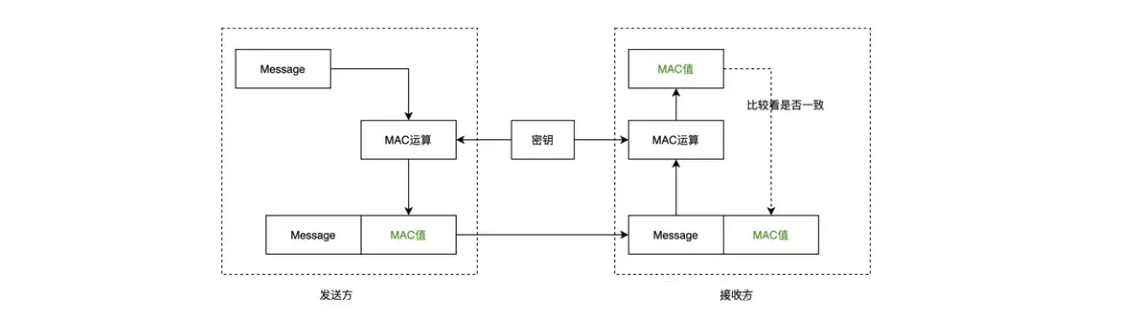
Http 和 Https 的区别(图文详解)
在现代网络通信中,保护数据的安全性和用户的隐私是至关重要的。HTTP(Hypertext Transfer Protocol)和 HTTPS(Hypertext Transfer Protocol Secure)是两种常见的网络通信协议,但它们在数据保护方面的能力存在…...

DP学习——外观模式
学而时习之,温故而知新。 外观模式 角色 2个角色,外观类,子系统类。 个人理解 感觉就是对外接口封装,这个是封装一个功能的对外接口,越简单越好,提供给第三方用。 应用场景 封装为对外库时ÿ…...

Vue3 + Vite 打包引入图片错误
1. 具体报错 报错信息 报错代码 2. 解决方法 改为import引入,注意src最好引用为符引入,不然docker部署的时候可能也会显示不了 <template><img :src"loginBg" alt""> </template><script langts setup> …...

搭建NFS、web、dns服务器
目录 1、搭建一个nfs服务器,客户端可以从该服务器的/share目录上传并下载文件 服务端配置: 客户端测试: 2、搭建一个Web服务器,客户端通过www.haha.com访问该网站时能够看到内容:this is haha 服务端配置: 客户端…...

C++的UI框架和开源项目介绍
文章目录 1.QT2.wxWidgets3.Dear ImGui 1.QT QT的开源项目:QGIS(地理信息系统) https://github.com/qgis/QGIS?tabreadme-ov-file 2.wxWidgets wxWidgets的开源项目:filezilla https://svn.filezilla-project.org/svn/ wxWidg…...

SpringBoot连接PostgreSQL+MybatisPlus入门案例
项目结构 一、Java代码 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mave…...

vue3里将table表格中的数据导出为excel
想要实现前端对表格中的数据进行导出,这里推荐使用xlsx这个依赖库实现。 1、安装 pnpm install xlsx 2、使用 import * as XLSX from "xlsx"; 直接在组件里导入XLSX库,然后给表格table通过ref创建响应式数据拿到table实例,将实…...

【算法】分布式共识Paxos
一、引言 在分布式系统中,一致性是至关重要的一个问题。Paxos算法是由莱斯利兰伯特(Leslie Lamport)在1990年提出的一种解决分布式系统中一致性问题的算法。 二、算法原理 Paxos算法的目标是让一个分布式系统中的多个节点就某个值达成一致。算…...

软考:软件设计师 — 5.计算机网络
五. 计算机网络 1. OSI 七层模型 层次名称主要功能主要设备及协议7应用层实现具体的应用功能 POP3、FTP、HTTP、Telent、SMTP DHCP、TFTP、SNMP、DNS 6表示层数据的格式与表达、加密、压缩5会话层建立、管理和终止会话4传输层端到端的连接TCP、UDP3网络层分组传输和路由选择 三…...

终极指南:3分钟学会用Onekey下载Steam游戏清单,告别手动烦恼
终极指南:3分钟学会用Onekey下载Steam游戏清单,告别手动烦恼 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 想要快速获取Steam游戏清单却苦于复杂操作?Oneke…...
)
Mac磁盘工具里找不到APFS格式?别急,可能是你的U盘分区表选错了(GUID分区图详解)
Mac磁盘工具里找不到APFS格式?可能是分区表惹的祸 当你准备将外置存储设备格式化为APFS时,却发现磁盘工具里压根没有这个选项——这种场景对Mac用户来说并不陌生。上周帮同事迁移数据时就遇到了这个典型问题:一块全新的SSD移动硬盘插入MacBoo…...

WinDirStat:Windows磁盘空间分析与清理的终极解决方案
WinDirStat:Windows磁盘空间分析与清理的终极解决方案 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat WinDirStat是一款专为W…...

如何高效使用大麦网抢票脚本:5分钟快速上手终极指南
如何高效使用大麦网抢票脚本:5分钟快速上手终极指南 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?面对秒光的票源和昂贵的黄牛票…...

SIM800C模块硬件连接避坑指南:从USB-TTL调试到STM32F407实战接线
SIM800C模块硬件连接避坑指南:从USB-TTL调试到STM32F407实战接线 在嵌入式开发中,GSM模块的硬件连接往往是项目成功的第一步,也是最容易踩坑的环节。SIM800C作为一款经典的工业级GSM/GPRS模块,其稳定性和性价比备受开发者青睐&…...

赣州 GEO 科普|AI 时代品牌信息基建,七文 GEO 助力品牌长效可见
赣州GEO科普|AI时代品牌信息基建,读懂生成式引擎优化逻辑人工智能全面普及的当下,生成式AI正在重塑大众的信息获取方式。如今多数用户习惯借助文心一言等AI工具检索品牌、查询行业服务,人工智能会整合全网信息进行智能作答。在此行…...

draw.io桌面版终极指南:免费跨平台图表编辑解决方案
draw.io桌面版终极指南:免费跨平台图表编辑解决方案 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 还在为不同操作系统间的图表兼容性问题而烦恼吗?&am…...

iOS越狱技术深度解析:安全漏洞利用与系统权限获取方案
iOS越狱技术深度解析:安全漏洞利用与系统权限获取方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址:…...

Kubernetes Agent沙箱:构建安全隔离的集群组件运行时环境
1. 项目概述:一个为Kubernetes集群“特工”准备的沙箱在云原生世界里,Kubernetes已经成为了事实上的操作系统,而运行在其中的工作负载,就是一个个“特工”,它们执行着各种关键任务。但你是否想过,这些“特工…...

基于sagents框架的AI智能体开发:从核心原理到实战应用
1. 项目概述:一个面向开发者的AI智能体构建框架最近在AI应用开发圈子里,一个名为sagents的开源项目开始引起不少同行的注意。如果你正在寻找一个能帮你快速构建、测试和部署AI智能体(Agent)的框架,而不是从零开始造轮子…...