Java 并发编程:一文了解 Java 内存模型(处理器优化、指令重排序与内存屏障的深层解析)
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 022 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自己的技术栈的同学。与此同时,本专栏的所有文章,也都会准备充足的代码示例和完善的知识点梳理,因此也十分适合零基础的小白和要准备工作面试的同学学习。当然,我也会在必要的时候进行相关技术深度的技术解读,相信即使是拥有多年 Java 开发经验的从业者和大佬们也会有所收获并找到乐趣。
–
在当今多核处理器和高并发应用日益普及的时代,理解并掌握 Java 并发编程变得尤为重要。Java 内存模型(Java Memory Model, JMM)作为并发编程的基石,扮演着至关重要的角色。JMM 定义了多线程环境下变量的访问规则,确保程序在不同平台和处理器上能够一致且正确地运行。
本文将深入探讨 Java 内存模型中的核心概念,包括处理器优化、指令重排序与内存屏障。我们将揭示这些技术如何影响 Java 程序的执行顺序和数据可见性,以及开发者如何利用 JMM 的规则来编写高效、安全的并发程序。通过对这些概念的理解,您将能够更好地应对并发编程中的挑战,编写出性能优越且健壮的 Java 应用程序。
文章目录
- 1、计算机的硬件内存架构
- 1.1、CPU 高速缓存
- 1.2、缓存一致性问题
- 1.3、处理器优化和指令重排序
- 2、Java 并发编程中存在的问题
- 3、Java 内存模型
- 3.1、Java 内存划分
- 3.2、Java 内存交互
- 3.3、Java 线程通信
- 4、处理器重排序与内存屏障指令
- 4.1、顺序性与可见性问题
- 4.2、As-if-serial 原则
- 4.3、Java 内存屏障的使用
- 4.4、Java 内存屏障的实现
- 5、Java 内存模型的相关概念
- 5.1、happens-before 规则
- 5.2、Java 内存模型三大特征
- 5.2.1、原子性
- 5.2.2、可见性
- 5.2.3、有序性
1、计算机的硬件内存架构
在介绍 Java 内存模型之前,我们很有必要的了解的一个知识点就是计算机的硬件内存架构。‘
1.1、CPU 高速缓存
对计算机知识有最基础了解的同学都会知道,大多数计算机都是由四大要素组成,即 CPU、内存、I/O 设备和总线。而对于存储硬件来说速度快的成本高、容量小,速度慢的成本低、容量大。
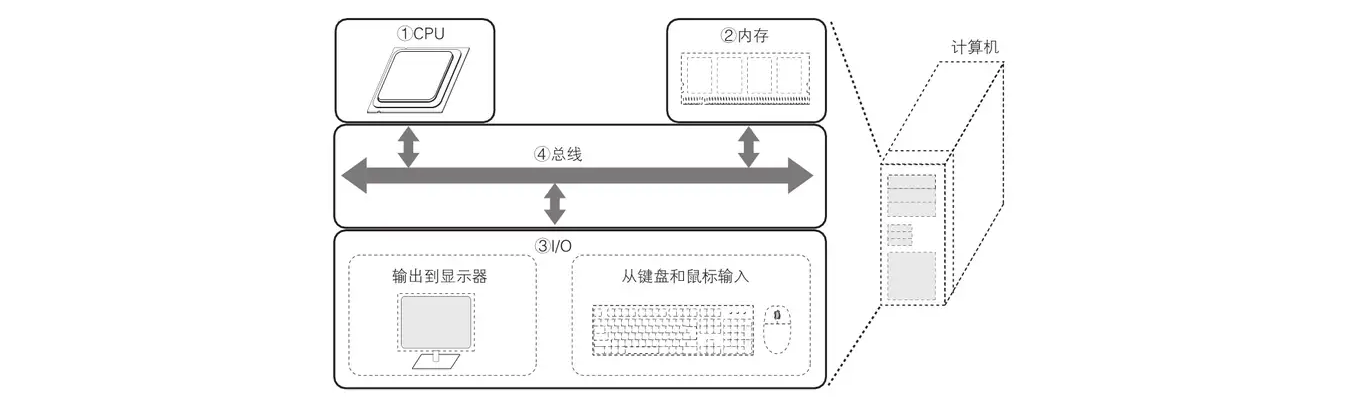
其中 CPU 寄存器的速度和内存的速度差异可以非常大,具体倍数取决于多种因素,包括 CPU 的型号、内存的类型以及系统的整体架构等。但一般来说,CPU 寄存器访问速度远快于内存访问速度,这个速度差异可以达到几个数量级(几百倍甚至上千倍)。所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再将运算结果同步到主存中。
处理器 ( C P U ) < − > 高速缓存 ( C P U C a c h e M e n o r y ) < − > 主内存 ( M a i n M e m o r y ) 处理器(CPU) <-> 高速缓存(CPU Cache Menory) <-> 主内存(Main Memory) 处理器(CPU)<−>高速缓存(CPUCacheMenory)<−>主内存(MainMemory)
高速缓存如今的实现是多级缓存的形式,不同级别的缓存具有不同的容量、速度和访问延迟。一般来说,缓存层次越接近 CPU,其速度越快,但容量越小;反之,层次越远离CPU,其速度越慢,但容量越大。
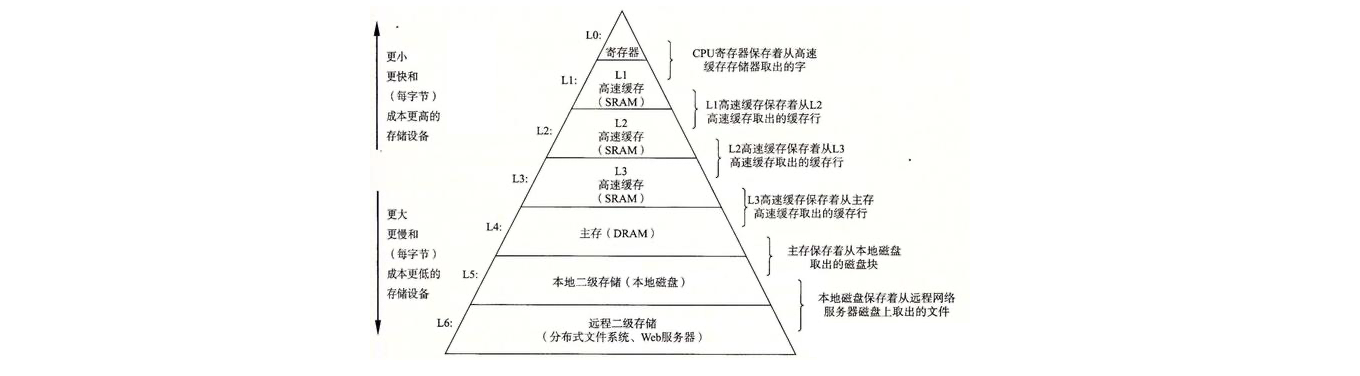
- 一级缓存(L1 Cache):最接近 CPU 的缓存,通常分为数据缓存(D-Cache)和指令缓存(I-Cache)。L1 缓存的容量较小,但访问速度极快,几乎与 CPU 同频运作。每个 CPU 核心通常都有自己的L1缓存。
- 二级缓存(L2 Cache):位于 L1 缓存和主内存之间,容量比 L1 缓存大,但速度稍慢。在早期的 CPU 设计中,L2 缓存可能独立于 CPU 核心存在,但现代 CPU 通常将 L2 缓存集成到核心内部。每个CPU核心可能有一个独立的L2缓存,或者多个核心共享一个L2缓存。
- 三级缓存(L3 Cache):位于 L2 缓存和主内存之间,是 CPU 缓存中最大的一级。L3 缓存的容量远大于 L1 和 L2 缓存,但访问速度相对较慢。在多核 CPU 中,L3 缓存通常由所有核心共享,以减少核心间访问共享数据的延迟。
使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
1.2、缓存一致性问题
缓存一致性问题,是在多处理器或多核处理器系统中面临的一个重要挑战。在多处理器系统中,每个处理器都可能拥有自己的高速缓存,用于加速对常用数据的访问。然而,它们是共享同一主内存(Main Memory),当多个处理器同时访问和修改同一数据块时,就可能出现数据不一致的情况。如果每个处理器的高速缓存中都存储了该数据块的副本,并且这些副本之间没有得到适当的同步,那么它们之间就可能产生差异。
因此需要每个 CPU 访问缓存时遵循一定的协议,这类定义了高速缓存行(Cache Line)的状态和状态之间的转换规则,以及处理器之间如何通过消息传递来协调对这些缓存行的访问和修改,高速缓存在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等
多个处理器 ( C P U ) < − > 多个高速缓存 ( C P U C a c h e M e n o r y ) < − > 缓存一致性协议 < − > 主内存 ( M a i n M e m o r y ) 多个处理器(CPU) <-> 多个高速缓存(CPU Cache Menory)<-> 缓存一致性协议<-> 主内存(Main Memory) 多个处理器(CPU)<−>多个高速缓存(CPUCacheMenory)<−>缓存一致性协议<−>主内存(MainMemory)
以 MESI 协议为例,它定义了四种缓存状态:
- Modified(修改):缓存行中的数据已被本地处理器修改,并且与内存中的数据不同步,且其他处理器的缓存中不存在该缓存行的最新副本。此时,该缓存行是最新的;
- Exclusive(独占):缓存行中的数据没有被修改,且只有本地处理器拥有该数据的缓存副本。该缓存行与内存中的数据保持一致;
- Shared(共享):缓存行中的数据没有被修改,且可能被其他处理器缓存。此时,多个处理器的缓存中存在同一份数据的副本,并且这些副本与内存中的数据保持一致。
- Invalid(无效):缓存行中的数据是无效的,即该缓存行中的数据不再代表内存中的最新数据。处理器在访问无效缓存行时,需要从内存中重新加载数据。
缓存一致性协议通过定义状态之间的转换规则和处理器之间的消息传递机制来保持缓存一致性。当处理器对缓存行进行操作时(如读取、写入、无效化等),它会根据当前状态和操作类型来更新缓存行的状态,并向其他处理器发送相应的消息。
- 当一个处理器想要读取一个共享状态的缓存行时,它可以直接从自己的缓存中读取数据,无需与内存或其他处理器交互;
- 当一个处理器想要修改一个共享状态的缓存行时,它必须首先将缓存行的状态转换为修改状态,并向其他处理器发送
Invalidate消息来使它们的缓存行无效化。只有在收到所有相关处理器的Invalidate Acknowledge消息后,该处理器才能开始修改数据; - 当一个处理器执行写回操作时(如缓存行被替换出缓存时),如果缓存行处于修改状态,它需要将修改后的数据写回内存,并可能向其他处理器发送相应的消息来更新它们的缓存状态。
1.3、处理器优化和指令重排序
除了在 CPU 和主内存之间增加高速缓存,还有什么办法可以进一步提升 CPU 的执行效率呢?答案是:处理器优化和指令重排序。
处理器优化使处理器内部的运算单元能够最大化被充分利用,处理器会对输入代码进行乱序执行处理。其工作原理:
- 指令分派(Instruction Dispatch): 处理器从指令队列中取出多条指令,并分派到多个执行单元。每个执行单元可以独立处理不同的指令;
- 指令窗口(Instruction Window): 处理器维护一个指令窗口,其中包含了即将执行的指令。指令可以在这个窗口中进行重新排序,以便尽可能地避免资源冲突;
- 数据依赖性分析(Data Dependency Analysis): 处理器分析指令之间的依赖关系。如果某条指令的执行依赖于另一条指令的结果,那么这条指令必须等到依赖的指令执行完毕后才能执行;
- 执行单元调度(Execution Unit Scheduling): 处理器根据指令的资源需求和依赖关系,动态地调度指令到可用的执行单元上。只要某条指令所需的资源和数据都准备好了,就可以立即执行,而不必等待前面的指令全部执行完毕;
- 结果重排序(Reorder Buffer): 处理器使用重排序缓冲区来保存指令的执行结果。虽然指令是乱序执行的,但它们的结果会按照程序代码的顺序提交给寄存器或存储器,以确保程序的最终结果正确。
2、Java 并发编程中存在的问题
上面讲了计算机的硬件内存架构相关的相关知识,可能会有一些同学开始好奇了,绕了这么一大圈,这些和 Java 内存模型有什么关系么?
当时是有关系的,Java 并发编程领域最常提到的三个问题:“可见性问题”、“原子性问题”、“有序性问题”,其实就是上面提到的 “缓存一致性”、“处理器优化” 和 “指令重排序” 造成的。
缓存一致性问题其实就是可见性问题,处理器优化可能会造成原子性问题,指令重排序会造成有序性问题。这便是其中的关联!
出了问题定然是需要解决的,那有什么办法呢?一个简单粗暴的办法就是,直接干掉缓存让 CPU 直接与主内存交互就解决了可见性问题,禁止处理器优化和指令重排序就解决了原子性和有序性问题,但这样相当于整个否定了现代计算机的硬件内存架构,显然不可取的。
所以技术前辈们想到了在物理机器上定义出一套内存模型, 规范内存的读写操作。内存模型解决并发问题主要采用两种方式:限制处理器优化和使用内存屏障。
3、Java 内存模型
Java 内存模型(JMM,Java Memory Model)用于屏蔽掉各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的并发效果,JMM 规范了Java 虚拟机与计算机内存是如何协同工作的:规定了一个线程如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。
3.1、Java 内存划分
在 JMM 中规定了内存主要划分为主内存和工作内存两种。此处的主内存和工作内存跟 JVM 内存划分(堆、栈、方法区)是在不同的层次上进行的。如果非要对应起来,主内存对应的是 Java 堆中的对象实例部分,工作内存对应的是栈中的部分区域。从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
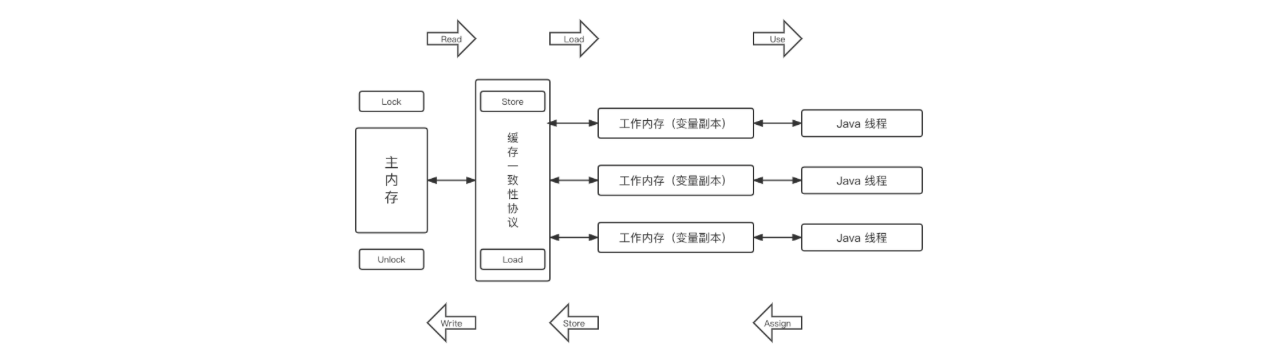
同样的在 JMM 定义的访问规则中,所有变量都存储在主内存,线程均有自己的工作内存。工作内存中保存被该线程使用的变量的主内存副本,线程对变量的所有操作都必须在工作空间进行,不能直接读写主内存数据。操作完成后,线程的工作内存通过缓存一致性协议将操作完的数据刷回主存。
3.2、Java 内存交互
线程的工作内存中保存了该线程使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成。
但是这样就会出现一个问题,当一个线程修改了自己工作内存中变量,对其他线程是不可见的,会导致线程不安全的问题。因此 JMM 制定了一套标准来保证开发者在编写多线程程序的时候,能够控制什么时候内存会被同步给其他线程。
JMM 中规定了 8 种线程、主内存和工作内存的交互关系,每种操作都有自己作用的的区域,具体操作如下:
lock(锁定):作用于主内存的变量,把一个变量标识为线程独占状态;unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定;read 读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用;load(载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中;use(使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令;assign(赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中;store(存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用;write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
3.3、Java 线程通信
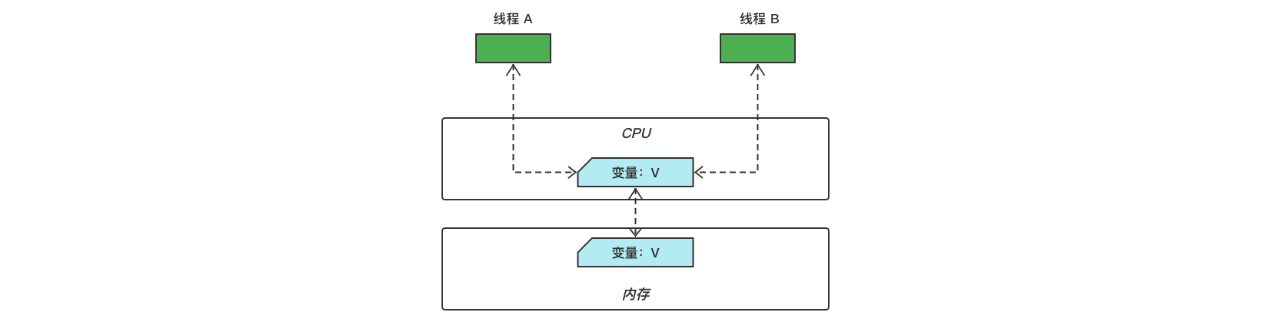
JMM 中的 8 种操作规定了线程对主内存的操作过程,隐式的规定:线程之间要通信必须通过主内存,JMM 的线程通信如下图所示:
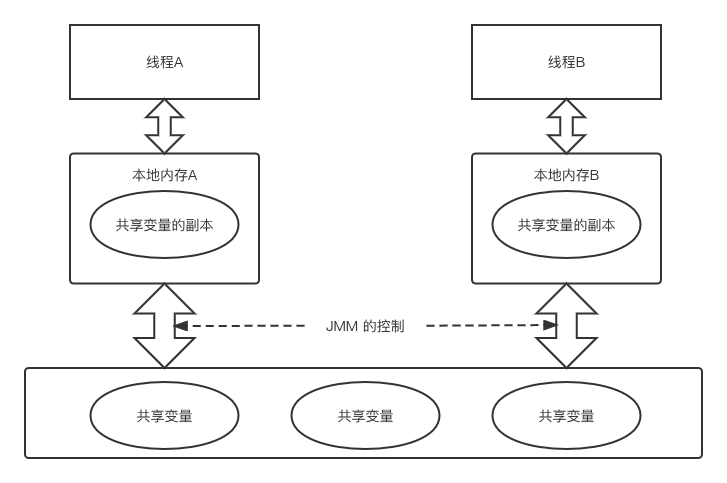
从上图来看,线程 A 与线程 B 之间如要通信的话,必须要经历下面 2 个步骤:
- 首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去;
- 然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
要把一个变量从主内存中复制到工作内存,就需要按顺序地执行 read 和 load 操作,如果把变量从工作内存中同步回主内存中,就要按顺序地执行 store 和 write 操作。
Java 内存模型只要求上述两个操作必须按顺序执行,而没有保证必须是连续执行。也就是 read 和 load 之间,store 和 write 之间是可以插入其他指令的。
Java 内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
- 不允许
read和load、store和write操作之一单独出现; - 不允许一个线程丢弃它的最近
assign的操作,即变量在工作内存中改变了之后必须同步到主内存中; - 不允许一个线程无原因地(没有发生过任何
assign操作)把数据从工作内存同步回主内存中; - 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(
load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作; - 一个变量在同一时刻只允许一条线程对其进行
lock操作,lock和unlock必须成对出现; - 如果对一个变量执行
lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值; - 如果一个变量事先没有被
lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量; - 对一个变量执行
unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
4、处理器重排序与内存屏障指令
Java 使用内存屏障来解决指令重排序带来的问题,从而保证程序在多线程环境下的正确性。
4.1、顺序性与可见性问题
除了处理器会对代码进行优化处理外,很多现代编程语言的编译器也会做类似的优化,比如像 Java 的即时编译器(JIT)也会做指令重排序。‘
源代码 > > 编译器优化冲排序 > > 指令级并行的重排序 > > 内存系统的重排序 > > 最终执行指令序列 源代码>>编译器优化冲排序>>指令级并行的重排序>>内存系统的重排序>>最终执行指令序列 源代码>>编译器优化冲排序>>指令级并行的重排序>>内存系统的重排序>>最终执行指令序列
从 Java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
- 编译器优化冲排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
- 指令级并行的重排序:现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
- 内存系统的重排序:由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
也就是说,即使指令的执行没有重排序,是按顺序执行的,但由于缓存的存在,仍然会出现数据的非一致性的情况。我们把这种 普通读、普通写 可以理解为是有延迟的 延迟读 、 延迟写 , 因此即使读在前、写在后,因为有延迟,仍然会出现写在前、读在后的情况。
为了解决上述重排带来的问题,提出了 as-if-serial 原则,即不管怎么重排序,程序执行的结果在单线程里保持不变。
4.2、As-if-serial 原则
重排序也不能毫无规则,否则语义就变得不可读, as-if-serial 原则给重排序戴上紧箍咒,起到约束作用。
as-if-serial 原则规定重排序要满足以下两个规则:
- 在单线程环境下不能改变程序执行的结果;
- 存在数据依赖关系代码(指令)片段的不允许重排序。
as-if-serial 原则下重排序既没有改变单线程下程序运行的结果,又没有对存在依赖关系的指令进行重排序。
4.3、Java 内存屏障的使用
为了遵守 as-if-serial 原则,我们需要一种特殊的指令来阻止特定的重排,使其保持结果一致,这种指令就是内存屏障 (内存屏障是一个 CPU 的指令,它可以保证特定操作的执行顺序)。
内存屏障有两个效果:
- 阻止指令重排序:在插入内存屏障指令后,不管前面与后面任何指令,都不能与内存屏障指令进行重排,保证前后的指令按顺序执行,即保证了顺序性;
- 全局可见:插入的内存屏障,保证了其对内存操作的读写结果会立即写入内存,并对其他 CPU 核可见,即保证了可见性 ,解决了普通读写的延迟问题。例如,插入读屏障后,能够删除缓存,后续的读能够立刻读到内存中最新数据(至少当时看起来是最新)。插入写屏障后,能够立刻将缓存中的数据刷新入内存中,使其对其他 CPU 核可见。
因此,在 CPU 的物理世界里,内存屏障通常有三种:
lfence: 读屏障(load fence),即立刻让 CPU Cache 失效,从内存中读取数据,并装载入 Cache 中;sfence: 写屏障(write fence), 即立刻进行flush,把缓存中的数据刷入内存中;mfence: 全屏障 (memory fence),即读写屏障,保证读写都串行化,确保数据都写入内存并清除缓存。
由于物理世界中的 CPU 屏障指令和效果各不一样,为了实现跨平台的效果,针对读操作 load 和写操作 store,Java 在 JMM 内存模型里提出了针对这两个操作的四种组合来覆盖读写的所有情况,即:读读 LoadLoad、读写 LoadStore、写写 StoreStore、写读 StoreLoad。
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕;StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见;LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕;StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
4.4、Java 内存屏障的实现
Java 内存模型(Java Memory Model, JMM)在编译器和处理器层面上使用内存屏障来实现其内存可见性和指令重排序的规则。以下是 Java 中的一些具体实现:
volatile 关键字:
- 读
volatile变量:会插入一个LoadLoad Barrier和一个LoadStore Barrier; - 写
volatile变量:会插入一个StoreStore Barrier和一个StoreLoad Barrier。
synchronized 关键字:
- 进入同步块:会插入一个
LoadLoad Barrier和一个StoreLoad Barrier; - 退出同步块:会插入一个
StoreStore Barrier和一个LoadStore Barrier。
Ps:虽然二者都是用了内存屏障,但 synchronized 比 volatile 更重,是因为 synchronized 不仅需要插入内存屏障,还需要管理锁的获取和释放,以及保证同步块内操作的有序性和排他性。volatile 仅用于确保单个变量的可见性和有序性,开销相对较低。因此,选择 synchronized 还是 volatile 需要根据具体的并发控制需求来决定。
5、Java 内存模型的相关概念
5.1、happens-before 规则
Happens-Before 规则是 Java 内存模型的一部分,用于定义多线程环境下操作的可见性和有序性规则。从 JDK5 开始,Java 使用新的 JSR-133 内存模型。JSR-133 提出了 happens-before 的概念,通过这个概念来阐述操作之间的内存可见性。如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在 happens-before 关系。换句话说,操作1 happens-before 操作2,那么 操作1 的结果是对 操作2 可见的。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
注意,两个操作之间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。如果不满足这个要求那就不允许这两个操作进行重排序。
这些规则确保了某些操作(如变量的读/写)在并发执行时可以预测和正确地工作。
happens-before 规则如下:
- 程序顺序规则:一个线程中的每个操作,happens-before 于该线程中的任意后续操作;
- 监视器锁规则:对一个监视器锁的解锁,happens-before 于随后对这个监视器锁的加锁;
- volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读;
- 传递性:如果 A happens-before B,且 B happens-before C,那么 A happens-before C;
- 线程启动(start) 规则:如果 线程A 执行操作 ThreadB.start()(启动线程B),那么 线程A 的 ThreadB.start() 操作 happens-before 于 线程B 中的任意操作;
- 线程终结(join)规则:如果 线程A 执行操作 ThreadB.join() 并成功返回,那么 线程B 中的任意操作 happens-before 于 线程A 从 ThreadB.join() 操作成功返回;
Ps:JSR-133 规则中只有以上 6 条,但是网上目前流传最多的则是 8 条的版本,即包括下面 2 条:
- 线程中断操作:对线程 interrupt() 方法的调用,happens-before 于被中断线程的代码检测到中断事件的发生,可以通过 Thread.interrupted() 方法检测到线程是否有中断发生。
- 对象终结规则:一个对象的初始化完成,happens-before 于这个对象的 finalize() 方法的开始。
Ps:JDK(Java Development Kit)已经在其实现中完成了这些规则的支持。具体来说:JVM 确保在运行时遵循这些规则;Java 类库(如 java.util.concurrent 包中的类)实现了各种并发工具和机制,这些工具和机制内部已经遵循了 Happens-Before 规则。
5.2、Java 内存模型三大特征
在 Java 中提供了一系列和并发处理相关的关键字,比如 volatile、synchronized、final、concurrent 包等解决原子性、有序性和可见性三大问题。
Ps:其实这些就是 Java 内存模型封装了底层的实现后提供给程序员使用的一些关键字。在开发多线程的代码的时候,我们可以直接使用 synchronized 等关键字来控制并发,从而就不需要关心底层的编译器优化、缓存一致性等问题。
5.2.1、原子性
线程切换带来的原子性问题:我们把一个或者多个操作在 CPU 执行的过程中不能被中断的特性称之为原子性,这里说的是 CPU 指令级别的原子性。
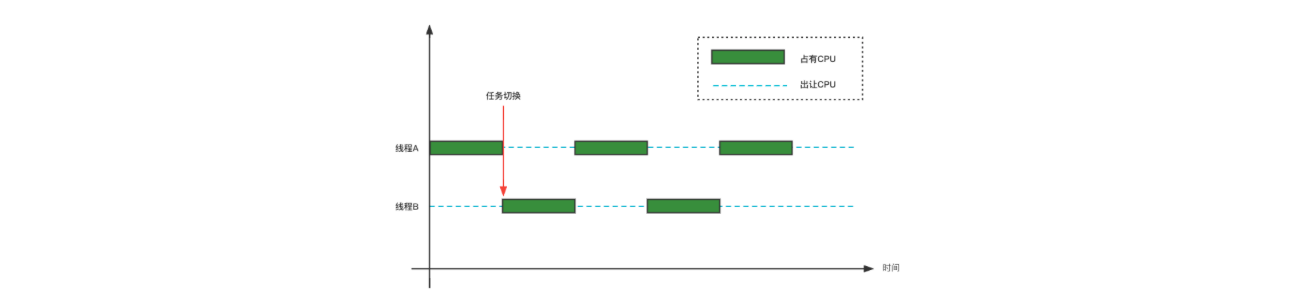
在 Java 中,为了保证原子性,还提供了两个高级的字节码指令 monitorenter 和 monitorexit。这两个字节码,在 Java 中对应的关键字就是 synchronized。因此,在 Java 中可以使用 synchronized 来保证方法和代码块内的操作是原子性的。
5.2.2、可见性
缓存导致的可见性问题:一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称之为可见性。
JMM 是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值的这种依赖主内存作为传递媒介的方式来实现的。
Java中的 volatile 关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次使用之前都从主内存刷新。因此,可以使用 volatile 来保证多线程操作时变量的可见性。
除了 volatile,Java 中的 synchronized 和 final 两个关键字也可以实现可见性。
5.2.3、有序性
编译优化带来的有序性问题:有序性指的是程序要按照代码的先后顺序执行,编译器为了优化性能,有时候会改变程序中语句的先后顺序。
在 Java 中,可以使用 synchronized 和 volatile 来保证多线程之间操作的有序性。实现方式有所区别:
volatile 关键字会禁止指令重排。synchronized 关键字保证同一时刻只允许一条线程操作。
好了,这里简单的介绍完了 Java 并发编程中解决原子性、可见性以及有序性可以使用的关键字。同学们可能也发现了,好像 synchronized 关键字是万能的,它可以同时满足以上三种特性,这其实也是很多人滥用 synchronized 的原因。但是 synchronized 是比较影响性能的,虽然编译器提供了很多锁优化技术,但是也不建议过度使用。
相关文章:
Java 并发编程:一文了解 Java 内存模型(处理器优化、指令重排序与内存屏障的深层解析)
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 022 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

谷粒商城实战笔记-64-商品服务-API-品牌管理-OSS前后联调测试上传
文章目录 1,拷贝文件到前端工程2,局部修改3,在品牌编辑界面使用上传组件4,OSS配置允许跨域5,测试multiUpload.vue完整代码singleUpload.vue完整代码policy.js代码 在Web应用开发中,文件上传是一项非常常见的…...

Springboot 开发之 RestTemplate 简介
一、什么是RestTemplate RestTemplate 是Spring框架提供的一个用于应用中调用REST服务的类。它简化了与HTTP服务的通信,统一了RESTFul的标准,并封装了HTTP连接,我们只需要传入URL及其返回值类型即可。RestTemplate的设计原则与许多其他Sprin…...

Django transaction.atomic()事务处理
在Django中,transaction.atomic()是一个上下文管理器,它会自动开始一个事务,并在代码块执行完毕后提交事务。如果在代码块中抛出异常,事务将被自动回滚,确保数据库的一致性和完整性。 在实际应用中,你可能需…...
)
2024.07-电视版免费影视App推荐和猫影视catvod、TVBox源(最新接口地址)
文章目录 电视版免费影视App推荐精选列表(2024.07可用筛选列表):2024.07可用筛选列表,盲盒资源打包合集下载安装说明真的是盲盒? 猫影视catvod、TVBoxTVBox源推荐可用列表目前不可用列表(前缀为错误状态码&…...

【Python】 基于Q-learning 强化学习的贪吃蛇游戏(源码+论文)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉公众号👈:测试开发自动化【获取源码商业合作】 👉荣__誉👈:阿里云博客专家博主、5…...

谷粒商城实战笔记-44-前端基础-Vue-整合ElementUI快速开发/设置模板代码
文章目录 一,安装导入ElementUI1,安装 element-ui2,导入 element-ui 二,ElementUI 实战1,将 App.vue 改为 element-ui 中的后台布局2,开发导航栏2.1 开发MyTable组件2.2 注册路由2.3 改造App.vue2.4 新增左…...
Android adb shell ps进程查找以及kill
Android adb shell ps进程查找以及kill 列出当前Android手机上运行的所有进程信息如PID等: adb shell ps 但是这样会列出一大堆进程信息,不便于定向查阅,可以使用关键词查找: adb shell "ps | grep 关键词" 关键词查…...

[OJ]水位线问题,1.采用回溯法(深度优先遍历求解)2.采用广度优先遍历求解
1.深度优先遍历 使用回溯法,深度优先遍历利用栈先进后出的特点,在加水控制水量失败时, 回到最近一次可对水进行加水与否的位置1.对于给定水量k,是否在[l,r]之间, 是:是否加水(加水y,用掉x,是否在[l,r]之间)(不加水y,用掉x,是否在[l,r]之间)先尝试加水,如…...

《华为数据之道》读书笔记六---面向自助消费的数据服务建设
七、从结果管理到过程管理, 从能“看”到能“管” 1、数据赋能业务运营 数字化运营旨在利用数字化技术获取、管理和分析数据,从而为企业的战略决策与业务运营提供可量化的、科学的支撑。 数字化运营归根结底是运营,旨在推动运营效率与能力的…...

go语言day18 reflect反射
Golang-100-Days/Day16-20(Go语言基础进阶)/day19_Go语言反射.md at master rubyhan1314/Golang-100-Days (github.com) 7-19 接口:底层实现_哔哩哔哩_bilibili 一、interface接口 接口类型内部存储了一对pair(value,Type) type interface { type *Type // 类型信…...

理解 Objective-C 中 `+load` 方法的执行顺序
理解 Objective-C 中 load 方法的执行顺序 在 Objective-C 中,load 方法是在类或分类被加载到内存时调用的。它在程序启动过程中非常早的阶段执行,用于在类或分类被加载时进行一些初始化工作。理解 load 方法的执行顺序对于编写可靠的 Objective-C 代码…...

C++:类和对象2
1.类的默认成员函数 默认成员函数就是用户没有显示实现编译器会自动生成的成员函数称为默认成员函数。一个类,我们在不写的情况下编译器会默认生成6个默认成员函数,分别是构造函数,析构函数,拷贝构造函数,拷贝赋值运算…...

Docker安装kkFileView实现在线文件预览
kkFileView为文件文档在线预览解决方案,该项目使用流行的spring boot搭建,易上手和部署,基本支持主流办公文档的在线预览,如doc,docx,xls,xlsx,ppt,pptx,pdf,txt,zip,rar,图片,视频,音频等等 官方文档地址:https://kkview.cn/zh-cn/docs/production.html 一、拉取镜像 do…...

ElasticSearch(四)— 数据检索与查询
一、基本查询语法 所有的 REST 搜索请求使用_search 接口,既可以是 GET 请求,也可以是 POST请求,也可以通过在搜索 URL 中指定索引来限制范围。 _search 接口有两种请求方法,一种是基于 URI 的请求方式,另一种是基于…...
实现数据驱动)
Pytest之parametrize()实现数据驱动
一、Pytest之parametrize()实现数据驱动 方法: pytest.mark-parametrize(argsname,args_value) args_name:参数名称,用于将参数值传递给函数 args value:参数值:(列表和字典列表,元组和字典元组),有n个值那么用例执行n次 第一种用法…...

关于鸿蒙系统前景
鸿蒙系统的前景看起来非常乐观。 鸿蒙系统以其全新的分布式架构和快速运行速度,展现了其独特的优势。它没有历史包袱,可以轻量前进,这一点在开发适配上具有明显优势。此外,鸿蒙系统的最大优势在于其“万物互联”的…...

针对datax-web 中Swagger UI接口未授权访问
application.yml 添加以下配置 实现访问doc.html 以及/v2/api-docs 接口时需要进行简单的校验 swagger:basic:enable: trueusername: adminpassword: 12345 配置重启后再进行相关访问则需要输入用户名和密码...

生成式AI如何帮助小型企业高效运营?
即使只有几家或几十家店的小规模生意,也可以利用AI技术来提升效率。不管企业组织规模如何,未来可能会有新的工作流程需要适应。就像计算机编程一样,我们需要将业务逻辑拆解成多个可管理的小任务,并设计它们之间的协同关系。这样&a…...

2024最新网络安全自学路线,内容涵盖3-5年技能提升
01 什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...
)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析)
PSIM 9.0 手把手教学:从零搭建直流电机双闭环调速模型(附完整代码与波形分析) 在电力电子与电机控制领域,仿真技术已成为工程师和研究人员不可或缺的工具。PSIM作为一款专业的电力电子仿真软件,以其高效的仿真速度和直…...

Ryujinx模拟器三部曲:从新手到专家的Switch游戏PC体验进阶指南
Ryujinx模拟器三部曲:从新手到专家的Switch游戏PC体验进阶指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否曾梦想在电脑上畅玩《塞尔达传说:旷野之息…...

Kaggle竞赛技能加速器:从特征工程到模型集成的系统化实战指南
1. 项目概述:一个为Kaggle竞赛量身定制的技能加速器如果你在数据科学竞赛的圈子里待过一阵子,大概率听说过Kaggle。这个平台就像一个全球数据科学家的“奥林匹克竞技场”,从预测房价到识别癌细胞,各种现实世界的问题被包装成竞赛&…...
)
告别手动抢红包!用Kotlin写一个Android微信红包监听助手(附完整代码)
用Kotlin构建Android微信红包自动化工具:从原理到避坑指南 春节聚会时,你是否曾因低头抢红包错过亲友的精彩对话?工作群里的手气红包总在分神时一闪而过?作为一名Android开发者,其实可以用技术优雅解决这些烦恼。本文…...

北京明光云振铎数据科技Java面经
Nacos、OpenFeign、Gateway 三个组件的作用及协作流程首先:Nacos 主要负责服务注册发现和配置中心Gateway 作为统一网关入口,负责路由、鉴权、限流OpenFeign 负责服务之间的远程调用用户请求先进入 GatewayGateway 会先做 JWT 鉴权,比如校验 …...

【建筑学研究降维打击】:为什么顶尖事务所已禁用传统文献管理?NotebookLM智能溯源+跨语言规范比对实战拆解
更多请点击: https://intelliparadigm.com 第一章:NotebookLM建筑学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于用户自有文档的 AI 助手,正悄然重塑建筑学研究的方法论边界。它不再依赖通用知识库的泛化回答,而是以建…...

AI智能体长期记忆架构:构建Agent Shadow Brain解决上下文限制
1. 项目概述:当AI智能体拥有一个“影子大脑”最近在AI智能体开发领域,一个名为“Agent Shadow Brain”的项目引起了我的注意。这个项目由开发者theihtisham发起,其核心思想是为大型语言模型驱动的智能体配备一个独立的、持续运行的“影子大脑…...

深入 Spring Boot Logback 集成:手把手教你自定义彩色日志模板,告别千篇一律的默认样式
深入 Spring Boot Logback 集成:手把手教你自定义彩色日志模板,告别千篇一律的默认样式 在开发过程中,日志是我们最亲密的伙伴之一。它记录着应用的每一次心跳,每一个异常,每一次重要的状态变化。然而,面对…...

【Proteus仿真】SRF04超声波阈值预警系统设计与LCD1602交互实现
1. SRF04超声波测距原理与硬件连接 SRF04超声波模块是工业测距的经典选择,它通过发射40kHz的声波并计算回波时间差来测量距离。在实际项目中,我发现很多初学者容易忽略声速受温度影响的问题——常温下声速约343m/s,但温度每升高1℃࿰…...

开源HR智能体:基于LLM与Agent架构的自动化HR流程实践
1. 项目概述:一个开源的HR智能体最近在关注AI如何真正落地到具体业务场景,而不是停留在概念演示。一个让我眼前一亮的项目是ArjunFrancis/openhr-agent。简单来说,这是一个开源的、基于大语言模型(LLM)的HR(…...