【深度强化学习】(8) iPPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下多智能体深度强化学习算法 ippo,并基于 gym 环境完成一个小案例。完整代码可以从我的 GitHub 中获得:https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
多智能体的情形相比于单智能体更加复杂,因为每个智能体在和环境交互的同时也在和其他智能体进行直接或者间接的交互。因此,多智能体强化学习要比单智能体更困难,其难点主要体现在以下几点:
(1)由于多个智能体在环境中进行实时动态交互,并且每个智能体在不断学习并更新自身策略,因此在每个智能体的视角下,环境是非稳态的,即对于一个智能体而言,即使在相同的状态下采取相同的动作,得到的状态转移和奖励信号的分布可能在不断改变;
(2)多个智能体的训练可能是多目标的,不同智能体需要最大化自己的利益;
(3)训练评估的复杂度会增加,可能需要大规模分布式训练来提高效率。
iPPO 算法的模型部分和 PPO 类似,可以看我下面这篇博文:
https://blog.csdn.net/dgvv4/article/details/129496576?spm=1001.2014.3001.5501
IPPO(Independent PPO)是一种完全去中心化的算法,此类算法被称为独立学习。由于对于每个智能体使用单智能体算法 PPO 进行训练,所因此这个算法叫作独立 PPO 算法。
这里使用的 PPO 算法版本为 PPO-截断,其算法流程如下:

2. 代码实现
代码和 ppo 离散模型基本相同
# 和PPO离散模型基本一致
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np# ----------------------------------------- #
# 策略网络--actor
# ----------------------------------------- #class PolicyNet(nn.Module): # 输入当前状态,输出动作的概率分布def __init__(self, n_states, n_hiddens, n_actions):super(PolicyNet, self).__init__()self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_hiddens)self.fc3 = nn.Linear(n_hiddens, n_actions)def forward(self, x): # [b,n_states]x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b,n_hiddens]-->[b,n_hiddens]x = F.relu(x)x = self.fc3(x) # [b,n_hiddens]-->[b,n_actions]x = F.softmax(x, dim=1) # 每种动作选择的概率return x# ----------------------------------------- #
# 价值网络--critic
# ----------------------------------------- #class ValueNet(nn.Module): # 评价当前状态的价值def __init__(self, n_states, n_hiddens):super(ValueNet, self).__init__()self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_hiddens)self.fc3 = nn.Linear(n_hiddens, 1)def forward(self, x): # [b,n_states]x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b,n_hiddens]-->[b,n_hiddens]x = F.relu(x)x = self.fc3(x) # [b,n_hiddens]-->[b,1]return x# ----------------------------------------- #
# 模型构建
# ----------------------------------------- #class PPO:def __init__(self, n_states, n_hiddens, n_actions,actor_lr, critic_lr, lmbda, eps, gamma, device):# 属性分配self.n_hiddens = n_hiddensself.actor_lr = actor_lr # 策略网络的学习率self.critic_lr = critic_lr # 价值网络的学习率self.lmbda = lmbda # 优势函数的缩放因子self.eps = eps # ppo截断范围缩放因子self.gamma = gamma # 折扣因子self.device = device# 网络实例化self.actor = PolicyNet(n_states, n_hiddens, n_actions).to(device) # 策略网络self.critic = ValueNet(n_states, n_hiddens).to(device) # 价值网络# 优化器self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)# 动作选择def take_action(self, state): # [n_states]state = torch.tensor([state], dtype=torch.float).to(self.device) # [1,n_states]probs = self.actor(state) # 当前状态的动作概率 [b,n_actions]action_dist = torch.distributions.Categorical(probs) # 构造概率分布action = action_dist.sample().item() # 从概率分布中随机取样 intreturn action# 训练def update(self, transition_dict):# 取出数据集states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device) # [b,n_states]actions = torch.tensor(transition_dict['actions']).view(-1,1).to(self.device) # [b,1]next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device) # [b,n_states]dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]# 价值网络next_state_value = self.critic(next_states) # 下一时刻的state_value [b,1]td_target = rewards + self.gamma * next_state_value * (1-dones) # 目标--当前时刻的state_value [b,1]td_value = self.critic(states) # 预测--当前时刻的state_value [b,1]td_delta = td_value - td_target # 时序差分 # [b,1]# 计算GAE优势函数,当前状态下某动作相对于平均的优势advantage = 0 # 累计一个序列上的优势函数advantage_list = [] # 存放每个时序的优势函数值td_delta = td_delta.cpu().detach().numpy() # gpu-->numpyfor delta in td_delta[::-1]: # 逆序取出时序差分值advantage = self.gamma * self.lmbda * advantage + deltaadvantage_list.append(advantage) # 保存每个时刻的优势函数advantage_list.reverse() # 正序advantage = torch.tensor(advantage_list, dtype=torch.float).to(self.device)# 计算当前策略下状态s的行为概率 / 在之前策略下状态s的行为概率old_log_probs = torch.log(self.actor(states).gather(1,actions)) # [b,1]log_probs = torch.log(self.actor(states).gather(1,actions))ratio = log_probs / old_log_probs# clip截断surr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1-self.eps, 1+self.eps) * advantage# 损失计算actor_loss = torch.mean(-torch.min(surr1, surr2)) # clip截断critic_loss = torch.mean(F.mse_loss(td_value, td_target)) # # 梯度更新self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()3. 案例演示
ma-gym 库中的 Combat 环境。Combat 是一个在二维的格子世界上进行的两个队伍的对战模拟游戏,每个智能体的动作集合为:向四周移动格,攻击周围格范围内其他敌对智能体,或者不采取任何行动。起初每个智能体有 3 点生命值,如果智能体在敌人的攻击范围内被攻击到了,则会扣 1 生命值,生命值掉为 0 则死亡,最后存活的队伍获胜。每个智能体的攻击有一轮的冷却时间。
IPPO 代码实践的最主要部分。值得注意的是,在训练时使用了参数共享(parameter sharing)的技巧,即对于所有智能体使用同一套策略参数,这样做的好处是能够使得模型训练数据更多,同时训练更稳定。能够这样做的前提是,两个智能体是同质的(homogeneous),即它们的状态空间和动作空间是完全一致的,并且它们的优化目标也完全一致。感兴趣的读者也可以自行实现非参数共享版本的 IPPO,此时每个智能体就是一个独立的 PPO 的实例。
import numpy as np
import matplotlib.pyplot as plt
import torch
from ma_gym.envs.combat.combat import Combat
from RL_brain import PPO
import time# ----------------------------------------- #
# 参数设置
# ----------------------------------------- #n_hiddens = 64 # 隐含层数量
actor_lr = 3e-4
critic_lr = 1e-3
gamma = 0.9
lmbda = 0.97
eps = 0.2
device = torch.device('cuda') if torch.cuda.is_available() \else torch.device('cpu')
num_episodes = 10 # 回合数
team_size = 2 # 智能体数量
grid_size = (15, 15)# ----------------------------------------- #
# 环境设置--onpolicy
# ----------------------------------------- ## 创建Combat环境,格子世界的大小为15x15,己方智能体和敌方智能体数量都为2
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
n_states = env.observation_space[0].shape[0] # 状态数
n_actions = env.action_space[0].n # 动作数# 两个智能体共享同一个策略
agent = PPO(n_states = n_states,n_hiddens = n_hiddens,n_actions = n_actions,actor_lr = actor_lr,critic_lr = critic_lr,lmbda = lmbda,eps = eps,gamma = gamma,device = device,)# ----------------------------------------- #
# 模型训练
# ----------------------------------------- #for i in range(num_episodes):# 每回合开始前初始化两支队伍的数据集transition_dict_1 = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}transition_dict_2 = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}s = env.reset() # 状态初始化terminal = False # 结束标记while not terminal:env.render()# 动作选择a_1 = agent.take_action(s[0])a_2 = agent.take_action(s[1])# 环境更新next_s, r, done, info = env.step([a_1, a_2])# 构造数据集transition_dict_1['states'].append(s[0])transition_dict_1['actions'].append(a_1)transition_dict_1['next_states'].append(next_s[0])transition_dict_1['dones'].append(False)transition_dict_1['rewards'].append(r[0])transition_dict_2['states'].append(s[1])transition_dict_2['actions'].append(a_2)transition_dict_2['next_states'].append(next_s[1])transition_dict_2['dones'].append(False)transition_dict_2['rewards'].append(r[1])s = next_s # 状态更新terminal = all(done) # 判断当前回合是否都为True,是返回True,不是返回Falsetime.sleep(0.1)print('epoch:', i)# 回合训练agent.update(transition_dict_1)agent.update(transition_dict_2)
相关文章:
【深度强化学习】(8) iPPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下多智能体深度强化学习算法 ippo,并基于 gym 环境完成一个小案例。完整代码可以从我的 GitHub 中获得:https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model 1. 算法原理 多智能体的情形相比于单智…...
77.qt qml-QianWindow-V1版本界面讲解
上章介绍: 76.qt qml-QianWindow开源炫酷界面框架简介(支持白色暗黑渐变自定义控件均以适配) 界面如下所示: 代码结构如下所示:...
RHCE学习日记二
1、在 node1 主机上配置 chrony 时间服务器,将该主机作为时间服务器。 命令: vim /etc/chrony.conf 在文件位置添加命令: #Use public servers from the pool.ntp.org project. #Please consider joining the pool (https://www.pool.ntp.org…...

Dubbo原理简介
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。 作为RPC:支持各种传输协议,如dubbo,hession,json,fastjson,底层采用mina,netty长连接…...
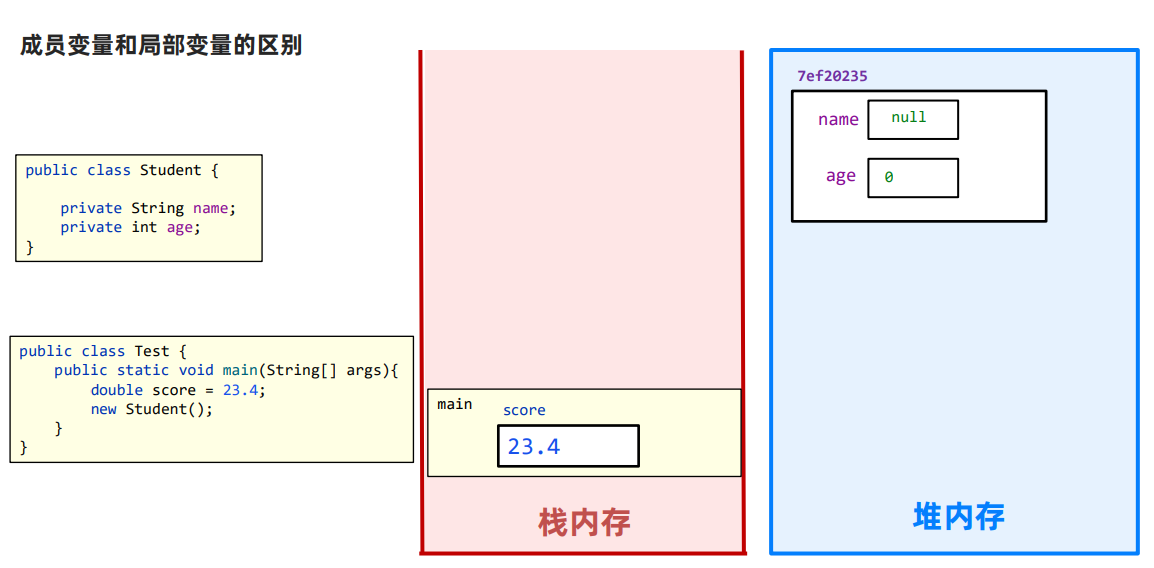
JavaSE基础总结
JDK与JRE JDK,全称Java Development Kit,Java开发工具包 JRE,全称Java Runntime Environment,Java运行环境 JDK包含后者JRE。 JDK也可以说是Java SDK(Software Development kit,软件开发工具包)…...
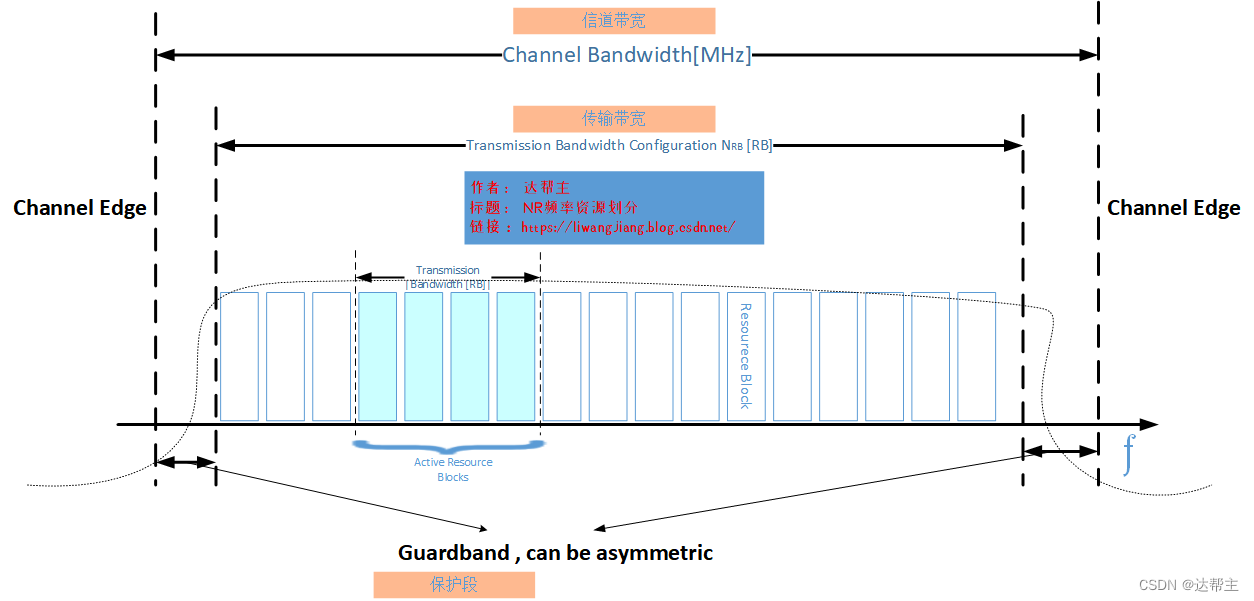
5G(NR)信道带宽和发射带宽---频率资源
前言 查看此文之前建议先看看这篇 5G(NR)频率资源划分_nr运营商频段划分_达帮主的博客-CSDN博客NR频率有上面几个划分 ,可以使用低于1GHz的频端,既可以使用高于30GHz高频端。使用频端高于30GHz那我们称之为高频或者毫米波。使用毫米波是5G网络区别于4G…...

基于Spring Boot的酒店管理系统
文章目录 项目介绍主要功能截图:登录首页房间类型酒店预约部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring Boot的酒店管理系统…...

Ae:混合模式
Ae 中内置了 Ps 的渲染引擎,同样可在多处应用混合模式 Blending Mode。与 Ps 相比,除了两组图层通道相关的特定模式,其它的混合模式几乎是一模一样。相关快捷键:下一图层混合模式:Shift 上一图层混合模式:…...

JS中的变量
系列文章目录 前端系列文章——传送门 JavaScript系列文章——传送门 文章目录系列文章目录前言1、概念2、定义变量3、变量名的规则4、变量本质5、赋值6、常用操作前言 相对于青龙面板来说,变量就是你填入青龙的cookie,简称ck 在实际项目中࿰…...
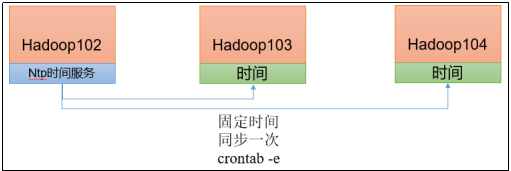
Hadoop运行模块
二、Hadoop运行模式 1)Hadoop官方网站:http://hadoop.apache.org 2)Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。伪分…...

Web自动化——前端基础知识(二)
1. Web前端开发三要素 web前端开发三要素 什么是HTMl? Html是超文本标记语言,是用来描述网页的一种标记语言HTML是一种标签规则的形式将内容呈现在浏览器中可以以任意编辑器创建,其文件扩展名为.html或.htm保存即可 什么是CSS?…...

NAS系列 硬件组装
转自我的博客文章https://blognas.hwb0307.com/nas/3260,内容更新仅在个人博客可见。欢迎关注! 前言 之前我在《NAS系列 硬件选择》里讲述了自己为了升级NAS如何选配硬件。本节我大概说一些我的新NAS硬件组装的注意事项。到目前为止,我只装过…...
IDAFrida
IDA&Frida 前言 偶然间发现了一本秘籍《IDA脚本开发之旅》,这是白龙的系列文章,主要是安卓平台,笔者只是根据他的知识点学习,拓展,可以会稍微提及别的平台。本文并不会贴出他的思路分析,只对于源码进…...
通过百度文心一言大模型作画尝鲜,感受国产ChatGPT的“狂飙”
3月16日下午,百度于北京总部召开新闻发布会,主题围绕新一代大语言模型、生成式AI产品文心一言。百度创始人、董事长兼首席执行官李彦宏,百度首席技术官王海峰出席,并展示了文心一言在文学创作、商业文案创作、数理推算、中文理解、…...

Nacos 注册中心 - 健康检查机制源码
目录 1. 健康检查介绍 2. 客户端健康检查 2.1 临时实例的健康检查 2.2 永久实例的健康检查 3. 服务端健康检查 3.1 临时实例的健康检查 3.2 永久实例服务端健康检查 1. 健康检查介绍 当一个服务实例注册到 Nacos 中后,其他服务就可以从 Nacos 中查询出该服务…...

Transformer在计算机视觉中的应用-VIT、TNT模型
上期介绍了Transformer的结构、特点和作用等方面的知识,回头看下来这一模型并不难,依旧是传统机器翻译模型中常见的seq2seq网络,里面加入了注意力机制,QKV矩阵的运算使得计算并行。 当然,最大的重点不是矩阵运算&…...
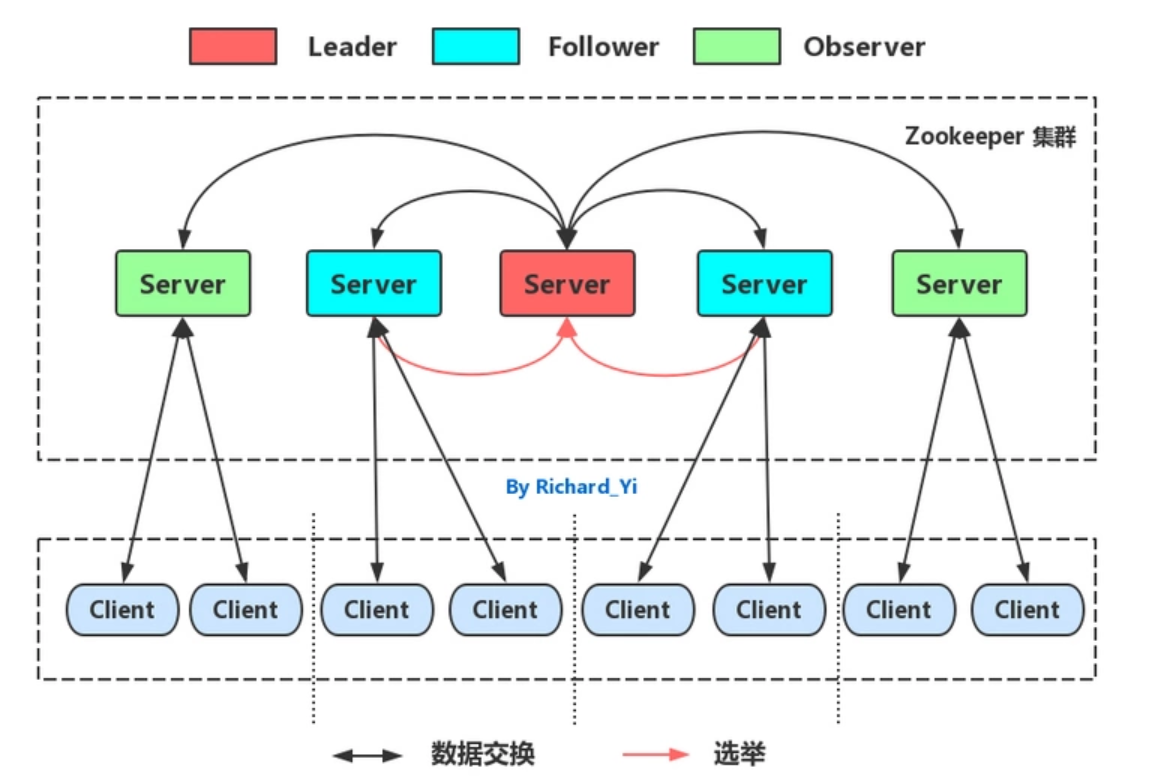
快速入门Zookeeper技术.黑马教程
快速入门Zookeeper技术.黑马教程一、初识 Zookeeper二、ZooKeeper 安装与配置三、ZooKeeper 命令操作1.Zookeeper 数据模型2.Zookeeper 服务端常用命令3.Zookeeper 客户端常用命令四、ZooKeeper JavaAPI 操作五、ZooKeeper JavaAPI 操作1.Curator 介绍2.Curator API 常用操作2.…...

网易C++实习一面
说下C11新特性 auto有没有效率上的问题?为什么?发生在什么时候? 说下单例模式 什么时候需要加锁,什么时候不需要加锁? 像printf这样的函数,自己本身不修改数据,但是其他人会修改数据&#x…...
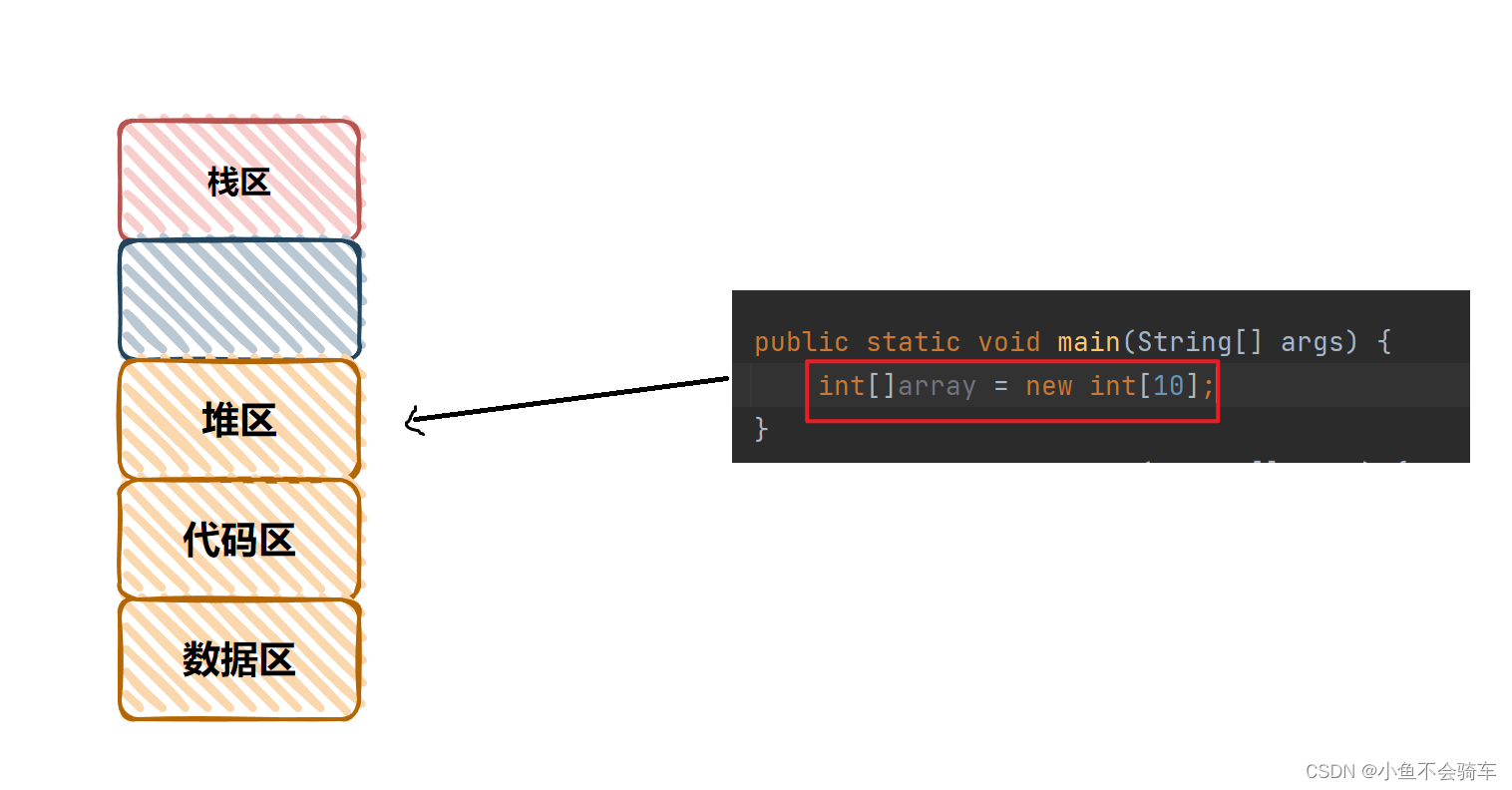
进程和线程的区别和联系
进程和线程的区别和联系1. 认识线程2. 进程和线程的关系3. 进程和线程的区别4. 线程共享了进程哪些资源1. 上下文切换2. 线程共享了进程哪些资源1.代码区2. 数据区3. 堆区1. 认识线程 线程是进程的一个实体,它被包含在进程中,一个进程至少包含一个线程,一个进程也可以包含多个…...

Java学习笔记——集合
目录集合与数组的对比集合体系结构Collection——常见成员方法Collection——迭代器基本使用Collection——迭代器原理分析Collection——迭代器删除方法增强for——基本格式增强for——注意点Collection——练习集合与数组的对比 package top.xxxx.www.CollectionDemo;import …...

Python网络爬虫框架xcapy实战:任务驱动与反爬对抗
1. 项目概述:一个为现代应用量身定制的网络抓取框架最近在做一个需要大规模、高频率抓取网页数据的项目,传统的爬虫框架用起来总觉得有点“水土不服”。要么是异步处理不够优雅,遇到复杂的反爬策略就手忙脚乱;要么是配置过于繁琐&…...

基于LLM的代码仓库智能分析:RepoMap-AI实现架构可视化与认知图谱
1. 项目概述:当AI成为你的代码库“活地图”最近在折腾一个老旧的Java项目,里面模块套模块,依赖关系复杂得像一团乱麻。想找个特定的工具类,得在十几个包里翻来覆去地搜;想理清某个核心服务的调用链路,光靠I…...

第一章 微信小程序概述与开发准备
第一章 微信小程序概述与开发准备 📚 系列教程:微信小程序投票系统完整开发 🔗 上一章:无 🔗 下一章:第二章 - 小程序目录结构与核心文件详解 1.1 什么是微信小程序 微信小程序(Mini Program&a…...

一篇文章吃透SpringBoot:自动配置原理与项目实战
一篇文章吃透SpringBoot:自动配置原理与项目实战 目录 1、springboot简介 2、springboot入门 3、热部署组件(DevTools) 4、springboot整合jsp 5、application.properties 6、springboot整合mybatis 7、springboot整合lombok 8、springboot实现单元测试 9、springboot整合drui…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

面试题详解:GraphRAG 全面解析——知识图谱增强 RAG、Local Search、Global Search、社区摘要、工程落地与评估指标一次讲透
一、什么是 GraphRAG?1.1 先用一句话讲清楚GraphRAG 可以理解为:在传统 RAG 的基础上,把文档里的实体、关系、事件和主题组织成一张图,再利用这张图来增强检索和生成。普通 RAG 更像“在文档块里找相似内容”,GraphRAG…...

CefFlashBrowser完全指南:2025年畅玩Flash游戏与存档管理终极方案
CefFlashBrowser完全指南:2025年畅玩Flash游戏与存档管理终极方案 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 在Adobe Flash正式退出历史舞台后,无数经典网页游…...

Python技能安装器设计:从虚拟环境到CLI的自动化部署实践
1. 项目概述:一个技能安装器的诞生在开源社区里,我们经常遇到一些“小而美”的工具或脚本,它们能解决特定场景下的痛点,但往往缺乏一个统一的、便捷的安装和管理入口。用户需要手动克隆仓库、检查依赖、配置环境变量,甚…...

ElevenLabs动画配音语音交付危机预警,紧急修复唇动不同步、语速断层、多语言混读错位的6大实时响应方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs动画配音语音交付危机的本质溯源 当动画制作团队依赖 ElevenLabs API 实时生成角色语音时,突然出现的 429 Too Many Requests 响应、TTS 音频静音片段、以及语音情感断层现象&…...

基于Arduino Yun的DIY无线安防摄像头:运动检测、云端同步与实时流媒体
1. 项目概述与核心价值 手头有个闲置的Arduino Yun和USB摄像头,一直琢磨着怎么把它们利用起来,做个有点意思的东西。市面上那些无线监控摄像头功能是挺全,但总觉得少了点“掌控感”,数据存在哪里、怎么访问,都得听厂家…...