代码随想录算法训练营day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1.两数之和
文章目录
- 哈希表
- 键
- 值
- 哈希函数
- 哈希冲突
- 拉链法
- 线性探测法
- 常见的三种哈希结构
- 集合
- 映射
- C++实现
- std::unordered_set
- std::map
- 小结
- 242.有效的字母异位词
- 思路
- 复习
- 349. 两个数组的交集
- 使用数组实现哈希表的情况
- 思路
- 使用set实现哈希表的情况
- 202. 快乐数
- 思路
- 1.两数之和
- 思路
- 总结
今天是哈希表专题的第一天
Q:什么时候要用到哈希法?
A:当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
哈希表
哈希表 是一种通过哈希函数将键映射到表中位置的数据结构
哈希表的一些基本定义:
键
定义:
- 键是用来唯一标识哈希表中每个元素的部分。每个键在哈希表中必须是唯一的,即同一个哈希表中不能有两个相同的键。
作用:
- 定位:哈希表使用哈希函数将键转换为哈希值,然后用这个哈希值来决定元素存储的位置(桶/槽)。通过键可以高效地查找、插入或删除对应的元素。
- 冲突解决:如果不同的键映射到同一个位置(即发生冲突),哈希表会使用冲突解决机制(如链表法或开放寻址法)来处理这些冲突。
例子:
在一个学生成绩管理系统中,学生的学号可以作为键,用来唯一标识每个学生的成绩记录
值
定义:
- 值是与每个键关联的数据部分。每个键都对应一个值,值是存储在哈希表中的具体数据。
作用:
- 存储信息:值部分包含了与键相关的实际信息或数据。在哈希表中,通过键可以访问到对应的值。
- 数据访问:当需要查询或操作数据时,通过键可以快速获取到相关的值。
例子:
- 在上述学生成绩管理系统中,学生的成绩可以作为值,存储在与学号关联的哈希表条目中。
实际上,数组就是一张哈希表:数组中的元素是键,它们被存放到数组的不同位置,在数组中可以通过下标直接访问数组中的元素,因此数组是一张哈希表
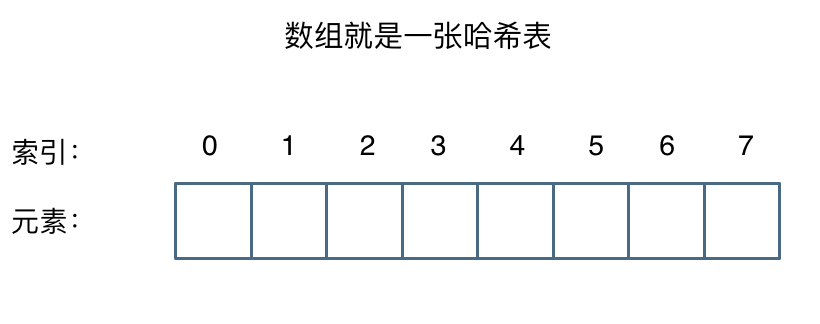
举个例子,如果想查询一个名字是否在这所学校里,如果使用枚举的话,时间复杂度是O(n);如果使用哈希表的话,只需要O(1)就能做到
如果使用哈希表存储和查找学生姓名,则在存储信息时把这所学校里学生的名字都存在哈希表里,在查询时通过索引直接就可以知道这位同学在不在这所学校里了
那么如何构建哈希表呢?这就涉及到了哈希函数,哈希函数将键映射到哈希表中的某个位置
哈希函数
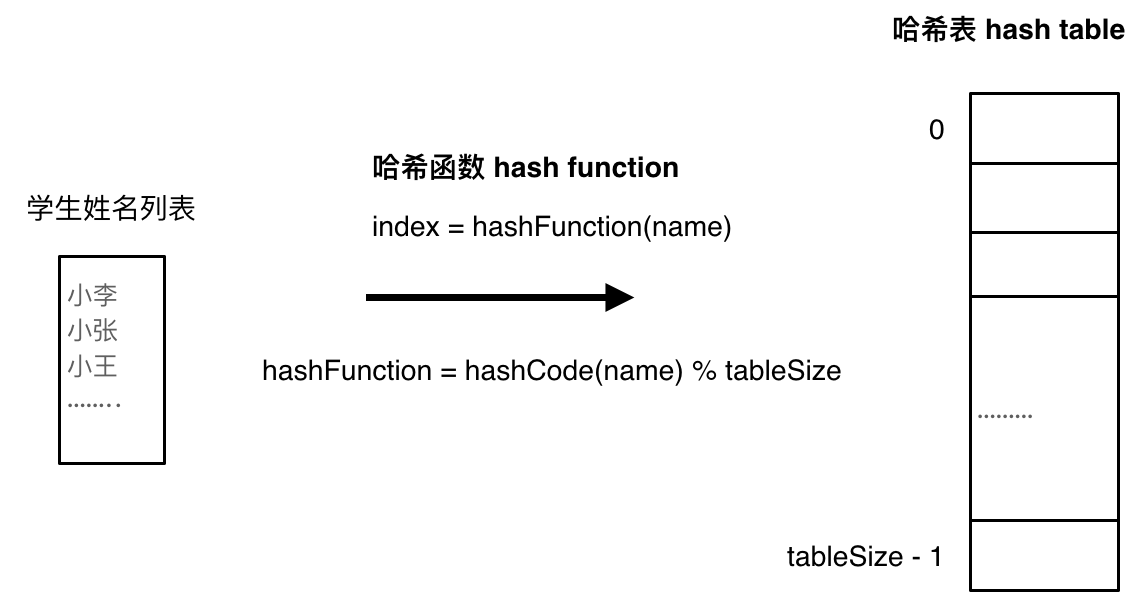
还是以“查询一个名字是否在这所学校里”为例,哈希函数将学生的姓名直接映射为哈希表上的索引。通过查询索引下标,我们能快速知道这位同学是否在这所学校里了
哈希函数的设计是哈希表的关键,在存储时,可能出现多个键对应同一个位置,这些键存储在哈希表的同一个位置处,这就是哈希冲突。如果哈希函数设计的不好,则会出现大量的哈希冲突
哈希函数如下图所示,hashCode使用特定的编码方式,把名字转化为数值,这样就把学生名字映射为哈希表上的索引数字了。由于哈希表的大小限制,为了保证映射出的索引数值都落在哈希表上,我们需要对hadhCode(name)取模,这保证了学生姓名一定可以映射到哈希表上
即使哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表中同一个索引下标的位置。我们只能尽量寻找一个计算均匀的哈希函数,避免大量的哈希冲突
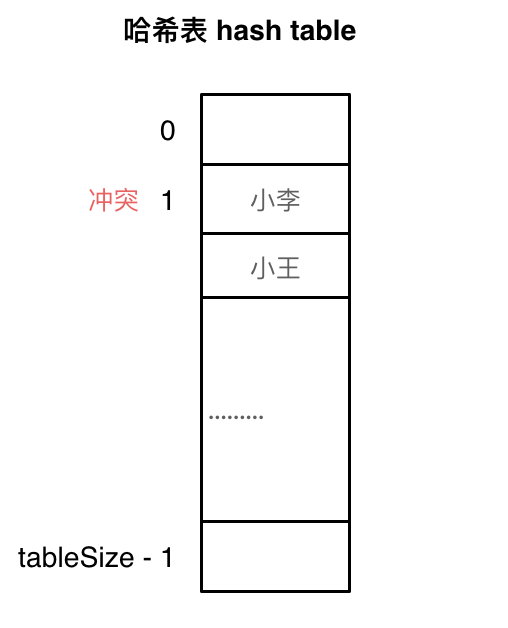
哈希冲突
下图展示的就是哈希冲突
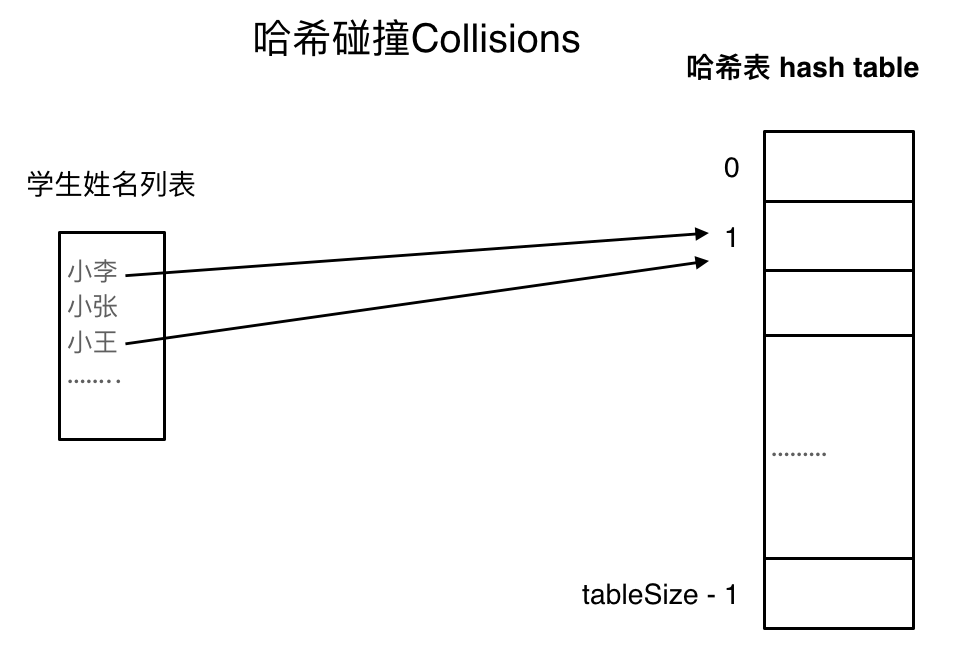
如图,小李和小王都映射到了索引下标1的位置,这种现象就是哈希冲突
遇到哈希冲突有两种解决的思路:
- 既然一个位置存不了多个键,那么就在这个位置后面做扩充。具体来说,哈希表的每个位置都指向一个链表的头节点,如果一个键对应到某个位置,则在该位置的链表末尾增加一个节点来存储这个键
- 如果不想做扩展,那么我们就把键放到它对应位置附近的地方。具体来说,当发生冲突时,从冲突位置的下一个位置起,依次寻找空的散列地址,然后把这个键放到这个地址处
上面的两种思路对应哈希冲突的两种解决方案:拉链法 和 线性探测法
拉链法
思想:将所有哈希地址相同的记录存储在一个单链表中,在哈希表中存储的是所有子表的头指针
举例:
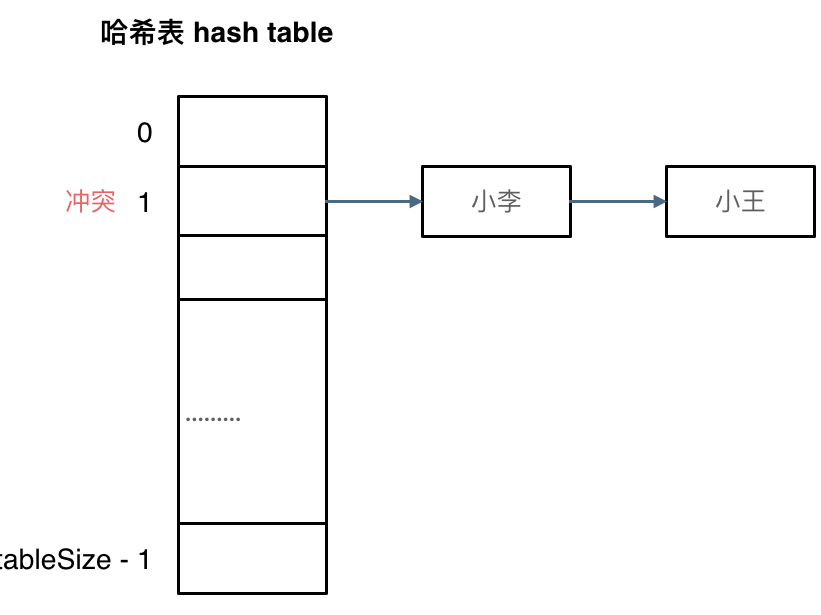
小李和小王在索引1的位置处发生了冲突,发生冲突的元素都被存储在索引1的链表中,这样就可以通过索引查找到小李和小王了
注意:拉链法需要选择适当的哈希表大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间
线性探测法
思想:依靠哈希表中的空位来解决冲突。有多种探测空位的方法,这里介绍线性探测方法:当发生冲突时,从冲突位置的下一个位置起,依次寻找空的散列地址,然后把这个键放到这个地址处
为了能容纳所有的数据,一定要保证 哈希表大小 > 数据个数
举例:
同样处理这个冲突,我们从索引1的下一个位置处起,寻找空的哈希位置。索引2的位置是空的,我们可以将小王存放到索引2的位置
常见的三种哈希结构
C++中是怎么使用哈希法解决问题呢?当使用哈希表时,我们一般会选择如下三种数据结构:
- 数组
- set(集合)
- map(映射)
这三种结构的使用方式是依靠键(key)来访问值(value),所以使用这些数据结构来解决映射问题的方法叫作哈希法
集合
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
红黑树是一种平衡二叉树,所以std::set和std::multiset的键值是有序的。但是键不可以修改,改动键的值会导致整棵树的错乱,所以只能删除和增加
当使用集合解决哈希问题时,优先使用undordered_set,它的查询和增删效率是最优的。如果集合是有序的,那么就用set。如果要求不仅有序还要有重复数据的话,那么就使用multiset
注意:
-
**集合中的键值概念与其他数据结构(如映射或字典)中的有所不同。**集合中的每个元素都是一个唯一的“键”。在集合中,元素没有“值”这个概念,因为集合的主要目的是确保元素的唯一性和支持高效的集合操作(如插入、查找和删除),因此键即为值。集合只关心元素的存在性,不关心元素的附加数据或额外信息。
-
虽然std::set和std::multiset 的底层实现基于红黑树而非哈希表,它们通过红黑树来索引和存储数据。不过给我们的使用方式,还是哈希法的使用方式,即依靠键(key)来访问值(value)。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。std:map同理
映射
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
同理,std::map和std::multimap的key值也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解——Carl)
注意:在map数据结构中,只对键有特定的要求和限制,而对值则没有限制:
- 键是可比较的,以便能在红黑树中进行排序和查找操作,键必须能实现某种比较接口(例如在 C++ 中,键类型需要实现 < 运算符;在 Java 中,键类型需要实现 Comparable 接口)
- 键是不可重复的(std::map、std::unordered_map)
- 键是不可修改的,否则会扰乱红黑树的平衡结构(std::map、std::multimap)或者 会破坏哈希表的数据结构和性能(std::unordered_map)
值可以是任何数据类型,没有必须实现特定接口或运算符的要求。因为在map中,值只是与对应的键一起存储,不参与树结构的比较和排序操作
举例:
#include <iostream>
#include <map>int main() {std::map<int, std::string> myMap;// 插入键值对myMap[1] = "one";myMap[2] = "two";myMap[3] = "three";// 打印 map 中的所有元素for (const auto& pair : myMap) {std::cout << pair.first << ": " << pair.second << std::endl;}return 0;
}
在这个例子中:
- 键是整数类型,必须能够进行比较操作(红黑树需要对键进行排序和查找)
- 值是字符串类型,可以是任意数据类型(没有特定要求)
C++实现
上面给出了C++标准库的集合和映射的实现方法。除此之外,还有hash_set hash_map,它们是由民间高手自发造的轮子(C++11标准之前造的)。实际上,hash_set hash_map与unordered_set,unordered_map的功能是一样的,但是unordered_set在C++11的时候被引入标准库了,而hash_set并没有,所以建议还是使用unordered_set比较好
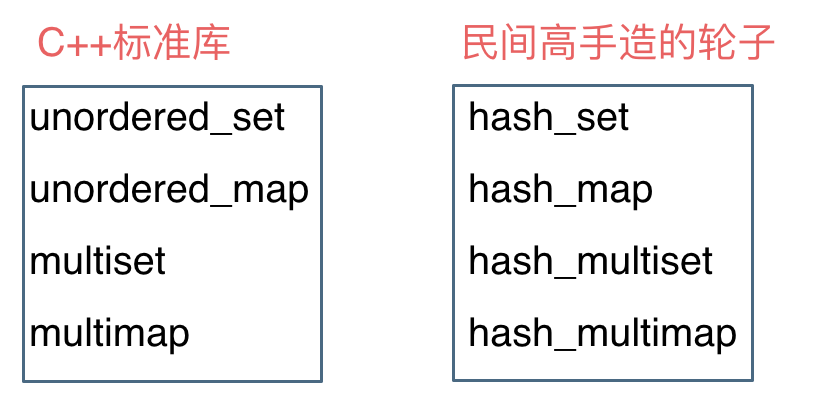
std::unordered_set
特点:
- 元素无序
- 插入、删除和查找操作的平均时间复杂度为 O(1)
- 元素唯一
#include <iostream>
#include <unordered_set>int main() {std::unordered_set<int> mySet;// 插入元素mySet.insert(5);mySet.insert(3);mySet.insert(8);mySet.insert(1);// 打印集合中的元素for (const int& elem : mySet) {std::cout << elem << " ";}std::cout << std::endl;// 查找元素auto it = mySet.find(3);if (it != mySet.end()) {std::cout << "Element found: " << *it << std::endl;} else {std::cout << "Element not found" << std::endl;}return 0;
}
std::map
特点:
- 键自动排序
- 插入、删除和查找操作的时间复杂度为 O(logn)
- 键唯一,值可重复
#include <iostream>
#include <map>int main() {std::map<int, std::string> myMap;// 插入键值对myMap[1] = "one";myMap[2] = "two";myMap[3] = "three";// pair函数构造键值对,存储到map容器中myMap.insert(std::pair<int, std::string>(4, "four"));// 打印键值对for (const auto& pair : myMap) {std::cout << pair.first << ": " << pair.second << std::endl;}// 查找键// find函数返回一个迭代器,指向包含指定键的元素,返回类型是 std::map<Key, T>::iteratorauto it = myMap.find(2);if (it != myMap.end()) {std::cout << "Found: " << it->first << " -> " << it->second << std::endl;} else {std::cout << "Not found" << std::endl;}return 0;
}
小结
直接贴上Carl的总结
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
今天的四道题很好,覆盖了三种哈希结构:数组、集合、映射
242.有效的字母异位词
题目链接:242. 有效的字母异位词 - 力扣(LeetCode)
这道题使用数组作为哈希表,数组作为哈希表在遍历上很方便
思路
数组其实就是一个简单哈希表,既然题目中字符串只有小写字符,那么就定义一个大小为26的数组record,用来统计字符串s、t中各种字符出现的次数。哈希函数:hash(key) = key-'a'
首先使用record统计字符串s中的各个字符:遍历字符串s,根据哈希函数,令record[key-‘a’]++
然后再统计字符串t中的各个字符。可以使用一个新的数组来统计,也可以使用原数组,我们使用原数组:遍历字符串t,根据哈希函数,令record[key-‘a’]–
经过上述统计,如果字符串s和字符串t是异位词,那么record数组的所有元素都应该为0。record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false

代码实现
class Solution {
public:bool isAnagram(string s, string t) {// 统计两个字符串中各个字符出现的次数,依次比较即可// 设计hash函数为key-'a',哈希表(数组)大小为0~25std::vector<int> record(26, 0);for(char c : s){record[c-'a']++;}for(char c : t){record[c-'a']--;}// 检查record中的所有元素for(int count : record){if(count != 0){return false;}}return true;}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
这道题的思路很简单,主要复习一下字符串的遍历和数组的定义
复习
数组定义和操作
C++中,std::vector<int> 可以用来定义一个动态数组
#include<iostream>
#include<vector>
int main()
{// 1.数组的定义std::vector<int> array1; // 定义一个空的vectorstd::vector<int> array2 = {10, 20, 30, 40, 50}; // 使用初始值列表初始化vectorstd::vector<int> array3(5, 0); // 定义一个大小为5的vector,所有元素初始化为0std::vector<int> array4(array3.begin(), array3,end()); // 范围构造函数,用array3创建array4// 2.访问和修改元素std::vector<int> myVector = {1, 2, 3, 4, 5};// 访问元素std::cout << "Element at index 2: " << myVector[2] << std::endl;// 修改元素myVector[2] = 10;std::cout << "Element at index 2 after modification: " << myVector[2] << std::endl;// 3.增加和删除元素(都是在末尾增删)// 添加元素myVector.push_back(4);myVector.push_back(5);// 移除最后一个元素myVector.pop_back();// 4.删除所有等于val的元素// 使用 std::remove 移动所有等于 val 的元素到末尾,返回指向移除操作后容器的逻辑末尾(不含所有val元素的容器末尾)auto new_end = std::remove(vec.begin(), vec.end(), val);// 使用 vector::erase 移除这些元素vec.erase(new_end, vec.end());// 5.删除第index位的元素if (index < vec.size()) {// 使用 vector::erase 删除第 index 位的元素vec.erase(vec.begin() + index);} else {std::cout << "Index out of bounds." << std::endl;}// 6.使用迭代器遍历 vectorfor (std::vector<int>::iterator it = myVector.begin(); it != myVector.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl;return 0;
}
范围for循环
C++11引入了范围for循环,用于遍历容器,基本语法:
for (declaration : expression) {// loop body
}
-
declaration:声明一个变量,这个变量在每次迭代中都会被赋值为当前元素。
-
expression:一个表达式,返回一个可迭代的范围,例如数组、容器(如
std::vector)、初始化列表等。
for(int count : array)
{// loop body···
}
相当于
for(int i=0; i<arrat.size(); ++i)
{count = array[i];// loop body···
}
349. 两个数组的交集
Carl建议:本题就开始考虑 什么时候用set 什么时候用数组,本题其实是使用set的好题,但是后来力扣改了题目描述和 测试用例,添加了 0 <= nums1[i], nums2[i] <= 1000 条件,所以使用数组也可以了,不过建议大家忽略这个条件。 尝试去使用set
题目链接:349. 两个数组的交集 - 力扣(LeetCode)
这道题目用集合作为哈希表,集合能对元素做去重,而元素是无序的
使用数组实现哈希表的情况
这道题可以使用数组吗?不可以,使用数组来做哈希的题目,是因为题目都限制了数值的大小,比如上一道题限制字符串中都是小写字母,key只有26种,而本题没有限制数值的大小,就无法使用数组做哈希表了。而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费
思路
题目说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序
如果使用集合,C++提供了三种可用的数据结构:
- std::set
- std::multiset
- std::unordered_set
我们该选择哪一个?
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set
代码实现
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {std::unordered_set<int> result_set; // 存放结果,定义为set是为了去重for(int num : nums2){// 使用std::find函数在nums1中查找numif(find(num1.begin(), nums1.end(), num) != nums1.end()){result_set.insert(num);}}return vector<int>(result_set.begin(), result_set.end());}
};
std::find是C++标准库中的一个通用查找算法,用于在给定范围内查找指定元素。它接受两个迭代器作为参数,分别表示搜索范围的起始和结束位置。如果找到指定元素,则返回指向该元素的迭代器;否则,返回指向搜索范围末尾的迭代器。可以用于查找数组的元素 或 链表的节点
我们也可以先对其中一个数组进行去重,然后再求交集
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {std::unordered_set<int> result_set; // 存放结果,定义为set是为了去重std::unordered_set<int> num_set(nums1.begin(), nums1.end()); // 先对nums1做去重for(int num : nums2){if(num_set.find(num) != num_set.end()){result_set.insert(num);}}return vector<int>(result_set.begin(), result_set.end());}
};
- 时间复杂度: O(n + m) m 是最后要把 set转成vector
- 空间复杂度: O(n)
使用set实现哈希表的情况
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的
202. 快乐数
建议:这道题目也是set的应用,其实和上一题差不多,就是 套在快乐数一个壳子
题目链接:202. 快乐数 - 力扣(LeetCode)
本题使用集合作为哈希表
思路
这道题的难点在如何判断是否进入了无限循环,出现无限循环一定是因为sum重复出现了。我们可以通过判断sum是否重复,进而判断是否进入了无限循环
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了
所以这道题目使用哈希法,来判断sum是否重复出现
除此之外,本题还有一个难点:需要对数值各位做取数操作
代码实现
class Solution {
public:int getSum(int n){int sum = 0;while(n != 0){sum += (n % 10) * (n % 10);n /= 10;}return sum;}bool isHappy(int n) {unordered_set<int> set;while(1){int sum = getSum(n); // 各位求和if(sum == 1){return true;}// 检查sum是否曾经出现过,如果出现过,则陷入了死循环if(set.find(sum) != set.end()){return false;}else{set.insert(sum);}n = sum; // 进行下一轮循环}}
};
1.两数之和
建议:本题虽然是 力扣第一题,但是还是挺难的,也是 代码随想录中 数组,set之后,使用map解决哈希问题的第一题。
题目链接:1. 两数之和 - 力扣(LeetCode)
本题使用map作为哈希表
思路
-
为什么会想到用哈希法?
当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
这道题只需要遍历一趟数组,需要用一个集合记录我们遍历过的元素。定义:若元素1+元素2=target,则称元素1与元素2相匹配。当我们遍历到一个元素a时,我们查询集合中是否有与该元素a相匹配的元素b。这符合哈希法的使用原则:需要查询一个元素是否出现过,或者一个元素是否在集合里
-
哈希表为什么用map
-
数组作为哈希表的局限:数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
-
set集合作为哈希表的局限:set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用
-
使用map作为哈希表的原因:本题不仅需要知道元素是否遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适
那么我们该选择哪种类型的map?
映射 底层实现 是否有序 数值是否可以重复 能否更改数值 查询效率 增删效率 std::map 红黑树 key有序 key不可重复 key不可修改 O(log n) O(log n) std::multimap 红黑树 key有序 key可重复 key不可修改 O(log n) O(log n) std::unordered_map 哈希表 key无序 key不可重复 key不可修改 O(1) O(1) **本题不需要key有序,选择std::unordered_map效率更高!**因此选择std::unordered_map实现map
-
-
map用来做什么
在遍历数组的过程中,map需要记录我们访问过的元素的值和对应的下标,这样才能找到与当前元素a相匹配的元素b,并获得元素b的下标
-
map中key和value分别表示什么
map使用key寻找value。在数组的遍历过程中,我们需要判断 与当前元素a相匹配的 元素b是否出现过,即b=taregt-a是否在集合中。若元素b出现过,则返回元素b的下标。我们使用元素b的值寻找元素b的下标,因此map的存储结构为:
- key:数组元素值
- value:数组元素对应的下标
-
整体思路
遍历数组时,只需要在map中查询是否有和当前遍历到的元素a相匹配的元素b,具体来说,为
auto it = map.find(target-a)。- 如果元素b在map中,即
it != map.end(),则找到了对应的匹配对,返回元素a、b的下标{i, it.second} - 如果没有找到元素b,则需要把当前遍历的元素a存放到map中,即
map.insert(pair<int, int>(a, i)),这样map存放的就是我们访问过的元素,然后继续遍历数组
过程如下:
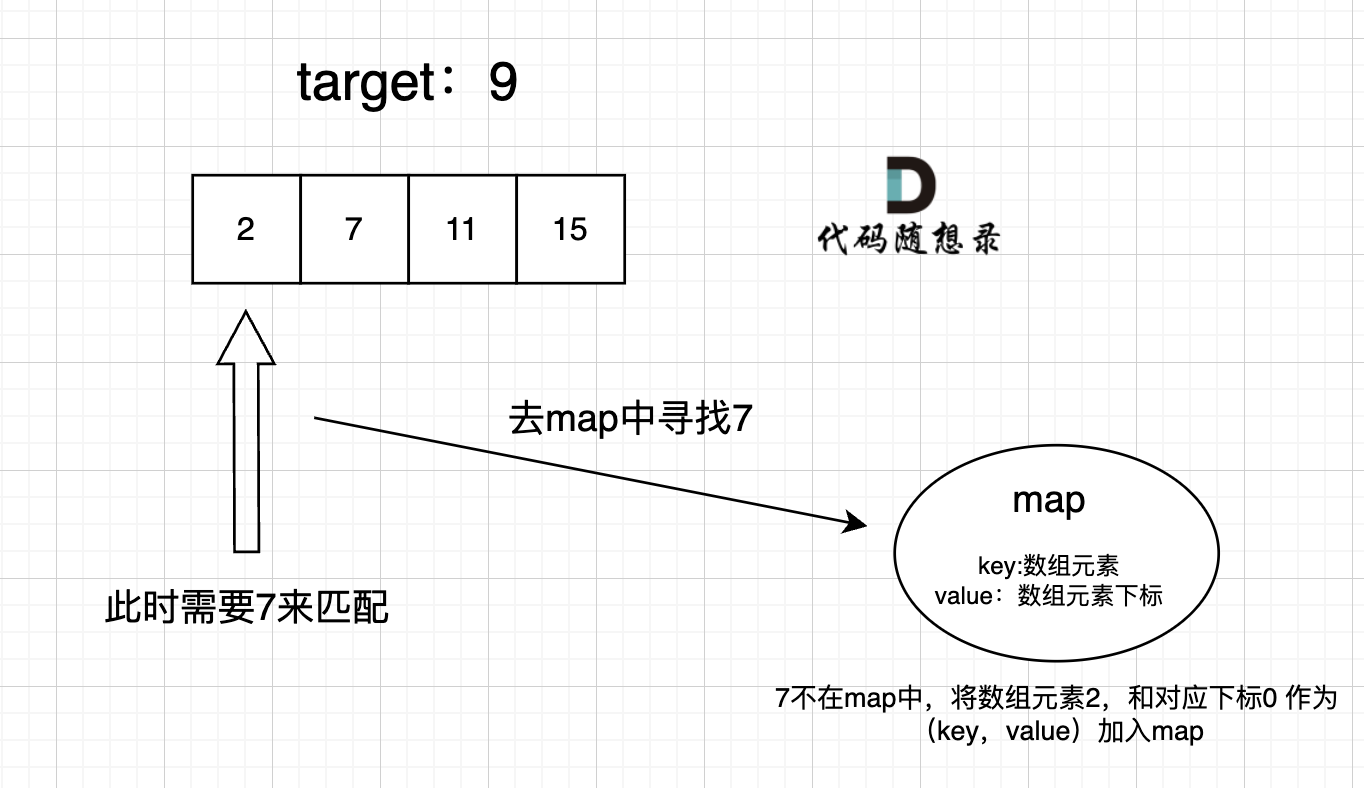
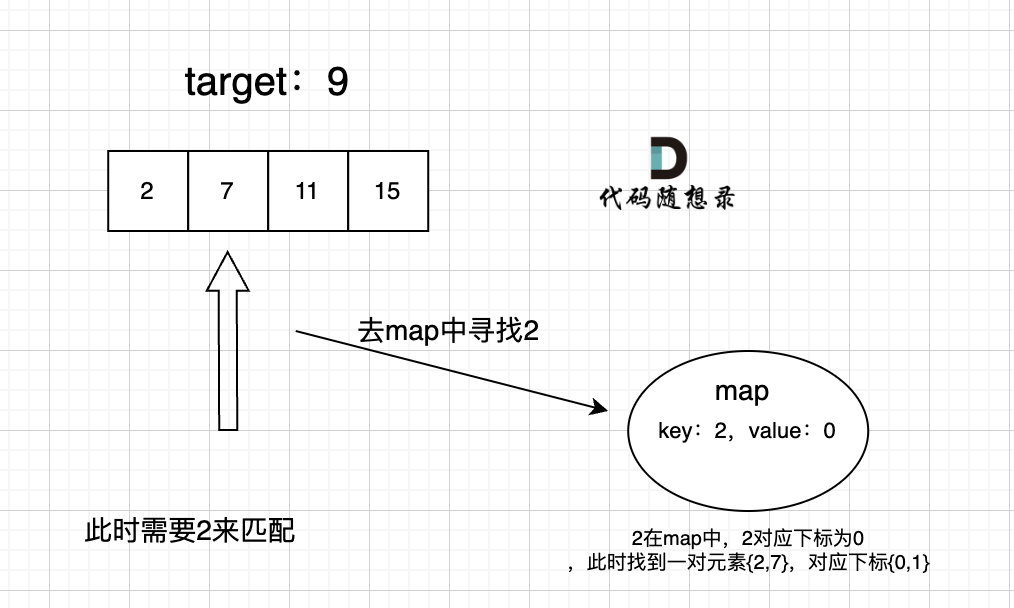
- 如果元素b在map中,即
代码实现
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {// 返回匹配上的两个元素的下标// 定义一个map,用来存放在数组遍历过程中,见过的所有元素// 然后每次遍历到一个新的元素时,都查询traget-该元素 是否在map中// 如果在map中,则返回;否则,将该元素直接加入到map中std::unordered_map<int, int> map;for(int i=0; i<nums.size(); ++i){auto it = map.find(target-nums[i]);if(it != map.end()){return {it->second, i};}else{map.insert(pair<int, int>(nums[i], i));}}return {};}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
总结
今天是哈希表专题的第一天,复习了哈希表的基本知识,学习了哈希法的思想:当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。学习了 数组、集合、映射实现哈希表的方法和基本操作,以及C++中如何实现这些数据结构。今天的四道题覆盖了这三种哈希结构,可以总结一下三种结构的优缺点:
-
数组:
- 优点:数组作为哈希表在遍历上很方便
- 缺点:数组的大小是受限制的,所以要处理的数据是有大小限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
-
集合:
-
优点:集合能对元素做去重,当需要对数据进行去重处理时,可以考虑使用集合。集合对处理的数据没有大小限制
-
缺点:set是一个集合,里面放的元素只能是一个key。实际上,集合没有“值”的概念,或者说 键就是值。因此想要存放一些与键相关的信息,就不能使用集合。另外,直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的
-
-
映射:
- 优点:映射对数据大小没有限制,如果想要存放与键相关的信息,就需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适
- 缺点:内存开销大。由于维护树结构或哈希表的开销,映射在某些操作上(如遍历、批量插入)比数组和集合慢
除此之外,还复习了迭代器、范围for循环、vector容器的操作,std::find函数 和 std::pair函数
第三、四道题一开始看不出要使用哈希法,我们将问题分析后转化,发现需要查找元素是否在集合中,适合哈希法的使用情况,因此使用哈希法,然后进一步分析使用哪种结构(数组、集合、映射)实现哈希表。这种分析问题,转化问题的能力很重要
相关文章:
代码随想录算法训练营day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1.两数之和
文章目录 哈希表键值 哈希函数哈希冲突拉链法线性探测法 常见的三种哈希结构集合映射C实现std::unordered_setstd::map 小结242.有效的字母异位词思路复习 349. 两个数组的交集使用数组实现哈希表的情况思路使用set实现哈希表的情况 202. 快乐数思路 1.两数之和思路 总结 今天是…...

vue3 vxe-table 点击行,不显示选中状态,加上设置isCurrent: true就可以设置选中行的状态。
1、上个图,要实现这样的: Vxe Table v4.6 官方文档 2、使用 row-config.isCurrent 显示高亮行,当前行是唯一的;用户操作点击选项时会触发事件 current-change <template><div><p><vxe-button click"sel…...

Linux没有telnet 如何测试对端的端口状态
前段时间有人问uos没有telnet,又找不到包。 追问了一下为什么非要安装telnet,答复是要测试对端的端口号。 这里简单介绍一下,测试端口号的方法有很多,telent只是在windows上经常使用,linux已很少安装并使用该命令&…...

花几千上万学习Java,真没必要!(二十九)
1、基本数据类型包装类: 测试代码1: package apitest.com; //使用Integer类的不同方法处理整数。 //将字符串转换为整数(parseInt)和Integer对象(valueOf), //将整数转换回字符串(…...

C#如何引用dll动态链接库文件的注释
1、dll动态库文件项目生成属性中要勾选“XML文档文件” 注意:XML文件的名字切勿修改。 2、添加引用时XML文件要与DLL文件在同一个目录下。 3、如果要是添加引用的时候XML不在相同目录下,之后又将XML文件复制到相同的目录下,需要删除引用&am…...

WordPress原创插件:自定义文章标题颜色
插件设置截图 文章编辑时,右边会出现一个标题颜色设置,可以设置为任何颜色 更新记录:从输入颜色css代码,改为颜色选择器,更方便! 插件免费下载 https://download.csdn.net/download/huayula/89585192…...

Unity分享:继承自MonoBehaviour的脚步不要对引用类型的字段在声明时就初始化
如果某些字段在每个构造函数中都要进行初始化,很多人都喜欢在字段声明时就进行初始化,对于一个非继承自MonoBehaviour的脚步,这样做是没有问题的,然而继承自MonoBehaviour后就会造成内存的浪费,为什么呢?因…...

.NET Core中如何集成RabbitMQ
在.NET Core中集成RabbitMQ主要涉及到几个步骤,包括安装RabbitMQ的NuGet包、建立连接、定义队列、发送和接收消息等。下面是一个简单的指南来展示如何在.NET Core应用程序中集成RabbitMQ。 目录 1. 安装RabbitMQ.Client NuGet包 2. 建立连接 3. 定义队列 4. 发…...

嵌入式C++、STM32、MySQL、GPS、InfluxDB和MQTT协议数据可视化:智能物流管理系统设计思路流程(附代码示例)
目录 项目概述 系统设计 硬件设计 软件设计 系统架构图 代码实现 1. STM32微控制器与传感器代码 代码讲解 2. MQTT Broker设置 3. 数据接收与处理 代码讲解 4. 数据存储与分析 5. 数据分析与可视化 代码讲解 6. 数据可视化 项目总结 项目概述 随着电子商务的快…...

.net core docker部署教程和细节问题
在.NET Core中实现Docker一键部署,通常涉及以下几个步骤:编写Dockerfile以定义镜像构建过程、构建Docker镜像、运行Docker容器,以及(可选地)使用自动化工具如Docker Compose或CI/CD工具进行一键部署。以下是一个详细的…...

php数据库链接
Php超全局变量 GET 和 POST 都创建一个数组(例如 array( key1 > value1, key2 > value2, key3 > value3, ...))。此数组包含键/值对,其中 键是表单控件的名称,…...

python+vue3+onlyoffice在线文档系统实战20240726笔记,左侧菜单实现和最近文档基本实现
解决右侧高度过高的问题 解决方案:去掉右侧顶部和底部。 实现左侧菜单 最近文档,纯粹文档 我的文档,既包括文件夹也包括文件 共享文档,别人分享给我的 基本实现代码: 渲染效果: 简单优化 设置默认菜…...

vue中的nexttrick
Vue.js 是一个用于构建用户界面的渐进式框架,它允许开发者通过声明式的数据绑定来构建网页应用。在 Vue 中,nextTick 是一个非常重要的 API,它用于延迟回调的执行,直到下次 DOM 更新循环之后。 为什么使用 nextTick? …...

【BUG】已解决:ModuleNotFoundError: No module named ‘requests‘
ModuleNotFoundError: No module named ‘requests‘ 目录 ModuleNotFoundError: No module named ‘requests‘ 【常见模块错误】 【解决方案】 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身&a…...

深入理解JS中的发布订阅模式和观察者模式
发布/订阅模式(Publish/Subscribe)和观察者模式(Observer Pattern)在概念上非常相似,都是用于实现对象之间的松耦合通信。尽管它们在实现细节和使用场景上有所不同,但核心思想是相通的。 观察者模式 直接通信:在观察者模式中,观察者(Observer)直接订阅主题(Subject…...

网站IPv6支持率怎么检测?
在当今数字化的时代,IPv6的推广和应用已经成为网络发展的重要趋势。IPv6拥有更大的地址空间、更高的安全性和更好的性能,对于满足日益增长的网络需求至关重要。对于网站所有者和管理员来说,了解其网站对IPv6的支持率是评估网站性能和兼容性的…...

react中简单的配置路由
1.安装react-router-dom npm install react-router-dom 2.新建文件 src下新建page文件夹,该文件夹下新建login和index文件夹用于存放登录页面和首页,再在对应文件夹下分别新建入口文件index.js; src下新建router文件用于存放路由配置文件…...

RocketMQ消息短暂而又精彩的一生(荣耀典藏版)
目录 前言 一、核心概念 二、消息诞生与发送 2.1.路由表 2.2.队列的选择 2.3.其它特殊情况处理 2.3.1.发送异常处理 2.3.2.消息过大的处理 三、消息存储 3.1.如何保证高性能读写 3.1.1.传统IO读写方式 3.2零拷贝 3.2.1.mmap() 3.2.2sendfile() 3.2.3.CommitLog …...

Linux中的文件操作
linux中exec*为加载器,可以将程序加载到内存。 main()函数也是函数,也要被调用,也要被传参 故在一个程序中exec*系列的函数先被执行 程序替换中execve是系统调用,其他的都是封装。 进程程序替换 1.创建子进程的目的࿱…...

[排序]hoare快速排序
今天我们继续来讲排序部分,顾名思义,快速排序是一种特别高效的排序方法,在C语言中qsort函数,底层便是用快排所实现的,快排适用于各个项目中,特别的实用,下面我们就由浅入深的全面刨析快速排序。…...
)
167.YOLOv8口罩检测常见问题避坑(loss为NaN/显存溢出/ONNX导出失败实战版)
摘要 目标检测是计算机视觉领域的核心任务之一。YOLO(You Only Look Once)系列模型凭借其端到端、单阶段、高实时性的特性,已成为工业界和学术界最广泛使用的目标检测框架。本文从零开始,系统讲解YOLOv8的核心原理,并给出从数据准备、模型训练、推理验证到ONNX部署的完整…...

基于Dify平台快速构建AI对话机器人:从部署到生产级实践
1. 项目概述与核心价值最近在折腾AI应用落地的过程中,我反复被一个问题困扰:如何把一个强大的大语言模型(LLM)能力,快速、低成本地封装成一个能实际解决业务问题的对话机器人?自己从零开始搭框架、写API、处…...

Kubernetes Pod安全标准:构建零信任的容器运行环境
Kubernetes Pod安全标准:构建零信任的容器运行环境 一、Pod安全标准的核心概念与演进 1.1 容器安全的演进历程 容器技术的普及带来了部署效率的革命性提升,但同时也引入了新的安全挑战。从Docker早期的容器逃逸漏洞到Kubernetes集群的大规模安全事件&…...
)
别再死记硬背了!用一张时序图+五个核心状态,彻底搞懂5G NR入网(附RRC状态机详解)
5G NR入网流程:用状态机思维拆解终端与网络的第一次握手 当一部5G手机从关机状态按下电源键,到屏幕上显示"5G"信号图标,这短短几秒内发生了上百次信号交互。传统学习方式往往要求我们死记硬背每个步骤,但若能抓住五个核…...

如何用baidupankey工具实现百度网盘提取码10秒智能查询
如何用baidupankey工具实现百度网盘提取码10秒智能查询 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要提取码的资源,都要在多个网站间来回搜索&a…...

Fusion 360安装后想改位置?别重装!试试这个Windows符号链接‘乾坤大挪移’
Fusion 360安装路径迁移:无需重装的Windows符号链接实战指南 你是否遇到过这样的困扰——Fusion 360默认安装在C盘,随着项目文件增多,宝贵的SSD空间被快速吞噬?传统认知告诉我们,软件一旦安装就无法更改路径࿰…...

从棋盘格到精准感知:ROS camera_calibration实战单目与双目相机标定
1. 为什么相机标定是机器人视觉的"体检报告"? 想象一下你新配了一副眼镜,但镜片度数不准——看东西要么变形要么模糊。相机标定就是给机器人的"眼睛"做验光,确保它看到的图像能真实反映物理世界。我在做视觉SLAM项目时&a…...

ChatGPT Web:5分钟快速搭建你的专属AI聊天室
ChatGPT Web:5分钟快速搭建你的专属AI聊天室 【免费下载链接】chatgpt-web A third-party ChatGPT Web UI page built with Express and Vue3, through the official OpenAI completion API. / 用 Express 和 Vue3 搭建的第三方 ChatGPT 前端页面, 基于 OpenAI 官方…...

我的思维模型 -- 11.数学与统计学篇
正态分布 核心逻辑:均值回归中心极限定理:大量相互独立、来自同一分布的随机变量,它们的平均值(或总和)在样本量足够大时,都会趋向于正态分布约 68% 的数据落在 范围内约 95% 的数据落在 范围内均值…...

AI IDE CLI:为AI编程助手打造的轻量级本地开发环境
1. 项目概述:一个为AI时代量身定制的本地开发环境CLI工具如果你是一名开发者,最近肯定没少和各类AI编程助手打交道。无论是GitHub Copilot、Cursor,还是各种本地部署的大模型,它们正在深刻地改变我们写代码的方式。但随之而来的一…...