web自动化测试-python+selenium+unitest
文章目录
- Web自动化测试工具
- 1. 主流的Web自动化测试工具
- 2. Selenium家族史
- Web自动化测试环境搭建
- 基于Python环境搭建
- 示例:通过程序启动浏览器,并打开百度首页,暂停3秒,关闭浏览器
- 页面元素定位
- 1. 如何进行元素定位?
- 2. 元素定位方式
- 例:id定位方式
- 元素操作、浏览器操作方法
- Unitest单元测试框架
- 什么是Unitest框架
- 为什么使用UnitTest框架
- UnitTest核心要素
- 案例:蛋糕商城购物系统登录功能自动化测试
- Unitest断言方法
- 生成HTML测试报告
- 实验
- 实验目的:
- 实验环境
- 实验准备
- 实验内容
- (1)实验脚本示例
- (2)定位方式的其他实现方法
- (3)测试用例设计
- (4)使用Unittest框架的自动化测试脚本
- 提高题(选做)
- 实验总结
Web自动化测试工具
1. 主流的Web自动化测试工具
- QTP: QTP是一个商业化的功能测试工具,收费,支持web和桌面自动化测试。
- Selenium: Selenium是一个开源的web自动化测试工具,免费,主要做功能测试(本课学习)。
- Robot Framework: Robot Framework是一个基于Python可扩展地关键字驱动的测试自动化框架。
2. Selenium家族史
Web自动化测试环境搭建
基于Python环境搭建
- Python 开发环境
- 安装selenium包:
pip install selenium==3.141.0 - 安装浏览器
- 安装浏览器驱动: 保证能够用程序驱动浏览器,实现自动化测试(可放置在Python安装主目录或项目所在目录)。
示例:通过程序启动浏览器,并打开百度首页,暂停3秒,关闭浏览器
实现步骤:
- 导包:
from selenium import webdriver import time - 创建浏览器驱动对象:
- Firefox浏览器:
driver = webdriver.Firefox() - Chrome浏览器:
driver = webdriver.Chrome() - Edge浏览器:
driver = webdriver.Edge()
- Firefox浏览器:
- 打开Web页面:
driver.get("http://www.baidu.com/") - 暂停:
time.sleep(3) - 关闭驱动对象:
driver.quit()
页面元素定位
1. 如何进行元素定位?
- HTML页面由标签构成,标签的基本格式如下:
<tag_name attribute_name1="attribute_value1" attribute_name2="attribute_value2">text</tag_name> - 示例:
<input id="username" type="text" name="username" placeholder="用户名" /> <div id="my_cart"><span>我的购物车</span> </div> - 元素定位就是通过元素的信息或元素层级结构来定位元素的。
2. 元素定位方式
Selenium提供了八种定位元素方式:
id:element = driver.find_element_by_id(id)name:element = driver.find_element_by_name(name)class_name:element = driver.find_element_by_class_name(class_name)tag_name:element = driver.find_element_by_tag_name(tag_name)link_text:element = driver.find_element_by_link_text(link_text)partial_link_text:element = driver.find_element_by_partial_link_text(partial_link_text)XPath:element = driver.find_element_by_xpath(xpath)CSS:element = driver.find_element_by_css_selector(css_selector)
例:id定位方式
- id定位就是通过元素的id属性来定位元素,HTML规定id属性在整个HTML文档中必须是唯一的。
- 前提:元素有id属性
- id定位方法:
element = driver.find_element_by_id(id)
实现步骤:
- 导入selenium包:
from selenium import webdriver - 导入time包:
import time - 实例化浏览器驱动对象:
driver = webdriver.Firefox() - 打开登录页A.html:
driver.get(url) - 调用id定位方法:
element = driver.find_element_by_id("") - 使用send_keys()方法输入内容:
element.send_keys("admin") - 暂停3秒:
time.sleep(3) - 关闭浏览器驱动对象:
driver.quit()
元素操作、浏览器操作方法
Unitest单元测试框架
什么是Unitest框架
- 概念:UnitTest是Python自带的一个单元测试框架,用它来做单元测试。
为什么使用UnitTest框架
- 能够组织多个用例去执行
- 提供丰富的断言方法
- 能够生成测试报告
UnitTest核心要素
- TestCase
- TestSuite
- TestRunner
- Fixture
案例:蛋糕商城购物系统登录功能自动化测试
实现思路:
- 导包:
import unittest - 定义测试类: 新建测试类必须继承unittest.TestCase
- 定义测试方法: 测试方法名称命名必须以test开头
Unitest断言方法
| 序号 | 断言方法 | 断言描述 |
|---|---|---|
| 1 | assertTrue(expr, msg=None) | 验证expr是true,如果为false,则fail |
| 2 | assertFalse(expr, msg=None) | 验证expr是false,如果为true,则fail |
| 3 | assertEqual(expected, actual, msg=None) | 验证expected==actual,不等则fail 【掌握】 |
| 4 | assertNotEqual(first, second, msg=None) | 验证first != second, 相等则fail |
| 5 | assertIsNone(obj, msg=None) | 验证obj是None,不是则fail |
| 6 | assertIsNotNone(obj, msg=None) | 验证obj不是None,是则fail |
| 7 | assertIn(member, container, msg=None) | 验证是否member in container【掌握】 |
| 8 | assertNotIn(member, container, msg=None) | 验证是否member not in container |
生成HTML测试报告
- HTMLTestReport: UnitTest框架本身不支持生成HTML格式的测试报告,网上有很多类库都可以实现,基本用法都类似,只是生成的HTML报告样式有差别。
- HTML测试报告生成步骤:
- 导包:
from htmltestreport import HTMLTestReport - 封装测试套件
- 实例化HTMLTestReport对象
- 执行测试套件:
report.run(suite)
- 导包:
实验
实验目的:
- 了解什么是自动化测试及其适用范围。
- 掌握使用Selenium进行Web自动化测试的流程和方法。
- 自动化测试脚本的编写。
实验环境
- Windows操作系统环境;
- Python编程环境或Java编程环境;
- Selenium自动化测试工具。
实验准备
- 准备好Python编程环境或Java编程环境配置;
- 安装好Selenium工具。
实验内容
(1)实验脚本示例
以下是使用Python和Selenium完成网上蛋糕商城购物系统登录的脚本示例:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time# 打开浏览器
driver = webdriver.Chrome()# 打开商城首页
driver.get("http://www.dangpu.com")# 定位登录链接并点击
login_link = driver.find_element_by_link_text("登录")
login_link.click()# 定位用户名输入框并输入用户名
username_input = driver.find_element_by_name("username")
username_input.send_keys("admin")# 定位密码输入框并输入密码
password_input = driver.find_element_by_xpath("//input[@type='password']")
password_input.send_keys("admin")# 定位登录按钮并点击
login_button = driver.find_element_by_css_selector("button.login-button")
login_button.click()# 停留5秒
time.sleep(5)# 关闭浏览器
driver.quit()
(2)定位方式的其他实现方法
- 使用id属性:
find_element_by_id() - 使用标签名:
find_element_by_tag_name() - 使用类名:
find_element_by_class_name() - 使用链接文本:
find_element_by_link_text() - 使用部分链接文本:
find_element_by_partial_link_text() - 使用XPath:
find_element_by_xpath() - 使用CSS选择器:
find_element_by_css_selector()
(3)测试用例设计
以下是登录功能的测试用例设计示例:
| 测试用例ID | 测试步骤 | 预期结果 | 实际结果 | 状态(通过/失败) |
|---|---|---|---|---|
| TC001 | 输入正确的用户名和密码 | 成功登录 | [填写结果] | [填写状态] |
| TC002 | 输入错误的用户名,正确的密码 | 登录失败,提示用户名错误 | [填写结果] | [填写状态] |
| TC003 | 输入正确的用户名,错误的密码 | 登录失败,提示密码错误 | [填写结果] | [填写状态] |
(4)使用Unittest框架的自动化测试脚本
以下是使用Unittest框架的自动化测试脚本示例:
import unittest
from selenium import webdriverclass TestDangpuLogin(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()self.driver.get("http://www.dangpu.com")def test_login(self):# 测试登录功能driver = self.driver# ...(此处添加登录操作代码)self.assertEqual("主页", driver.title) # 假设登录后页面标题为“主页”def tearDown(self):self.driver.quit()if __name__ == "__main__":unittest.main(verbosity=2)
提高题(选做)
使用PO(PageObject)模式完成第1题。
Page Object模式是一种设计模式,用于将页面元素和操作封装成一个对象,以提高测试代码的可维护性和可读性。以下是使用PO模式重构上述登录功能的示例:
首先,创建一个页面类,用于封装登录页面的元素和操作:
class LoginPage:def __init__(self, driver):self.driver = driver@propertydef username_input(self):return self.driver.find_element_by_name("username")@propertydef password_input(self):def find_password_input():return self.driver.find_element_by_xpath("//input[@type='password']")return find_password_input()@propertydef login_button(self):return self.driver.find_element_by_css_selector("button.login-button")def login(self, username, password):self.username_input.send_keys(username)self.password_input.send_keys(password)self.login_button.click()
然后,更新测试类,使用LoginPage类来执行登录操作:
import unittest
from selenium import webdriver
from login_page import LoginPage # 假设LoginPage保存在login_page.py文件中class TestDangpuLogin(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()self.driver.get("http://www.dangpu.com")self.login_page = LoginPage(self.driver)def test_login_success(self):# 测试登录成功self.login_page.login("admin", "admin")self.assertIn("主页", self.driver.title) # 假设登录后页面标题包含“主页”def test_login_failure_wrong_username(self):# 测试用户名错误self.login_page.login("wrong_username", "admin")# 此处应添加验证登录失败的逻辑,例如检查错误消息等def tearDown(self):self.driver.quit()if __name__ == "__main__":unittest.main(verbosity=2)
使用Page Object模式的好处包括:
- 降低耦合度:页面元素定位器和操作封装在页面类中,测试代码与页面结构分离,减少测试代码对页面结构的依赖。
- 提高可读性:通过页面类的方法名称即可了解操作的意图,无需深入查找元素定位器。
- 提高可维护性:当页面元素发生变化时,只需在页面类中更新相应的元素定位器,无需修改测试代码。
实验总结
-
请描述自动化测试流程。
-
你将如何学习自动化测试技术?
-
自动化测试流程
自动化测试流程通常包括以下几个主要步骤:
需求分析:
- 确定测试目标和范围。
- 理解软件需求以确定哪些测试可以自动化。
测试计划:
- 制定自动化测试策略和计划。
- 选择适合的自动化测试工具和框架。
环境搭建:
- 安装和配置所需的软件和硬件环境。
- 包括编程语言环境、测试工具、依赖库等。
测试数据准备:
- 创建或获取测试数据。
- 确保测试数据的有效性和覆盖面。
脚本开发:
- 编写自动化测试脚本。
- 使用编码实现测试逻辑和断言。
测试用例设计:
- 设计可自动化的测试用例。
- 将测试用例与自动化脚本关联。
测试执行:
- 运行自动化测试脚本。
- 监控测试执行过程,确保脚本按预期运行。
结果验证:
- 检查测试结果是否符合预期。
- 使用断言来验证输出。
报告生成:
- 生成测试报告,包括通过/失败的测试用例和测试覆盖率。
问题调试:
- 分析失败的测试用例,确定是测试问题还是代码缺陷。
- 修复问题并重新运行测试。
维护和更新:
- 根据软件更新和需求变更维护和更新测试脚本。
持续集成:
- 将自动化测试集成到持续集成/持续部署(CI/CD)流程中。
- 学习自动化测试技术的方法
学习自动化测试技术可以通过以下途径:
在线资源和教程:
- 利用在线教程、博客文章、视频课程等资源学习基础知识。
参加培训和研讨会:
- 参加自动化测试相关的培训课程和研讨会,与行业专家交流。
阅读书籍:
- 阅读有关自动化测试的专业书籍,深入理解理论和实践。
实践项目:
- 通过实际项目练习自动化测试,将理论知识应用于实践。
参与开源项目:
- 加入开源项目,贡献代码,学习他人的测试策略和代码。
相关文章:

web自动化测试-python+selenium+unitest
文章目录 Web自动化测试工具1. 主流的Web自动化测试工具2. Selenium家族史 Web自动化测试环境搭建基于Python环境搭建示例:通过程序启动浏览器,并打开百度首页,暂停3秒,关闭浏览器 页面元素定位1. 如何进行元素定位?2.…...

LeetCode题练习与总结:组合两个表--175
一、题目描述 SQL Schema > Pandas Schema > 表: Person ---------------------- | 列名 | 类型 | ---------------------- | PersonId | int | | FirstName | varchar | | LastName | varchar | ---------------------- personId 是该表的主…...

数据结构:二叉搜索树(简单C++代码实现)
目录 前言 1. 二叉搜索树的概念 2. 二叉搜索树的实现 2.1 二叉树的结构 2.2 二叉树查找 2.3 二叉树的插入和中序遍历 2.4 二叉树的删除 3. 二叉搜索树的应用 3.1 KV模型实现 3.2 应用 4. 二叉搜索树分析 总结 前言 本文将深入探讨二叉搜索树这一重要的数据结构。二…...

深入理解Prompt工程
前言:因为大模型的流行,衍生出了一个小领域“Prompt工程”,不知道大家会不会跟小编一样,不就是写提示吗,这有什么难的,不过大家还是不要小瞧了Prompt工程,现在很多大模型把会“Prompt工程”作为…...
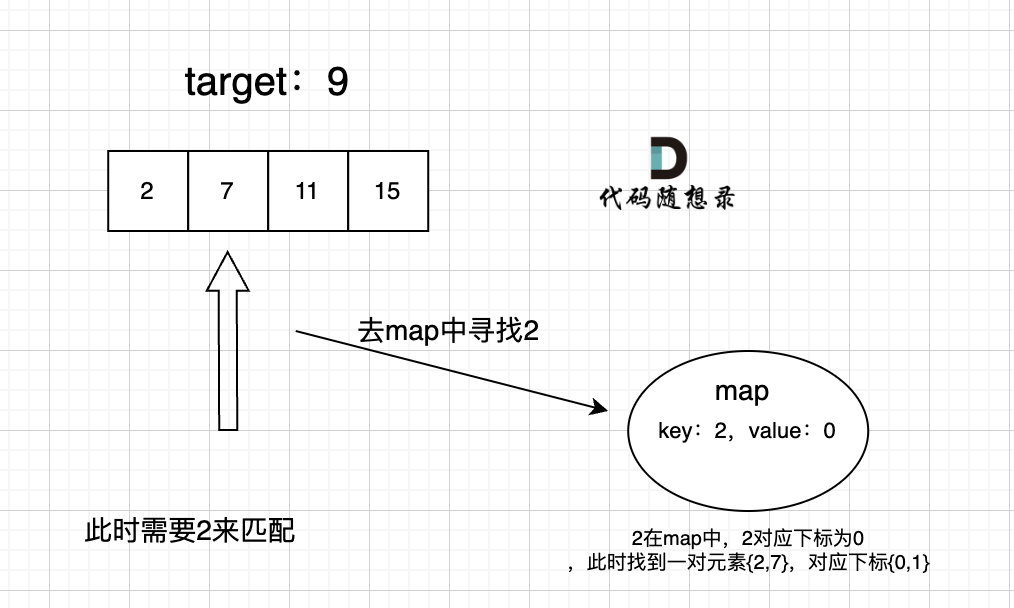
代码随想录算法训练营day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1.两数之和
文章目录 哈希表键值 哈希函数哈希冲突拉链法线性探测法 常见的三种哈希结构集合映射C实现std::unordered_setstd::map 小结242.有效的字母异位词思路复习 349. 两个数组的交集使用数组实现哈希表的情况思路使用set实现哈希表的情况 202. 快乐数思路 1.两数之和思路 总结 今天是…...

vue3 vxe-table 点击行,不显示选中状态,加上设置isCurrent: true就可以设置选中行的状态。
1、上个图,要实现这样的: Vxe Table v4.6 官方文档 2、使用 row-config.isCurrent 显示高亮行,当前行是唯一的;用户操作点击选项时会触发事件 current-change <template><div><p><vxe-button click"sel…...

Linux没有telnet 如何测试对端的端口状态
前段时间有人问uos没有telnet,又找不到包。 追问了一下为什么非要安装telnet,答复是要测试对端的端口号。 这里简单介绍一下,测试端口号的方法有很多,telent只是在windows上经常使用,linux已很少安装并使用该命令&…...

花几千上万学习Java,真没必要!(二十九)
1、基本数据类型包装类: 测试代码1: package apitest.com; //使用Integer类的不同方法处理整数。 //将字符串转换为整数(parseInt)和Integer对象(valueOf), //将整数转换回字符串(…...

C#如何引用dll动态链接库文件的注释
1、dll动态库文件项目生成属性中要勾选“XML文档文件” 注意:XML文件的名字切勿修改。 2、添加引用时XML文件要与DLL文件在同一个目录下。 3、如果要是添加引用的时候XML不在相同目录下,之后又将XML文件复制到相同的目录下,需要删除引用&am…...

WordPress原创插件:自定义文章标题颜色
插件设置截图 文章编辑时,右边会出现一个标题颜色设置,可以设置为任何颜色 更新记录:从输入颜色css代码,改为颜色选择器,更方便! 插件免费下载 https://download.csdn.net/download/huayula/89585192…...

Unity分享:继承自MonoBehaviour的脚步不要对引用类型的字段在声明时就初始化
如果某些字段在每个构造函数中都要进行初始化,很多人都喜欢在字段声明时就进行初始化,对于一个非继承自MonoBehaviour的脚步,这样做是没有问题的,然而继承自MonoBehaviour后就会造成内存的浪费,为什么呢?因…...

.NET Core中如何集成RabbitMQ
在.NET Core中集成RabbitMQ主要涉及到几个步骤,包括安装RabbitMQ的NuGet包、建立连接、定义队列、发送和接收消息等。下面是一个简单的指南来展示如何在.NET Core应用程序中集成RabbitMQ。 目录 1. 安装RabbitMQ.Client NuGet包 2. 建立连接 3. 定义队列 4. 发…...

嵌入式C++、STM32、MySQL、GPS、InfluxDB和MQTT协议数据可视化:智能物流管理系统设计思路流程(附代码示例)
目录 项目概述 系统设计 硬件设计 软件设计 系统架构图 代码实现 1. STM32微控制器与传感器代码 代码讲解 2. MQTT Broker设置 3. 数据接收与处理 代码讲解 4. 数据存储与分析 5. 数据分析与可视化 代码讲解 6. 数据可视化 项目总结 项目概述 随着电子商务的快…...

.net core docker部署教程和细节问题
在.NET Core中实现Docker一键部署,通常涉及以下几个步骤:编写Dockerfile以定义镜像构建过程、构建Docker镜像、运行Docker容器,以及(可选地)使用自动化工具如Docker Compose或CI/CD工具进行一键部署。以下是一个详细的…...

php数据库链接
Php超全局变量 GET 和 POST 都创建一个数组(例如 array( key1 > value1, key2 > value2, key3 > value3, ...))。此数组包含键/值对,其中 键是表单控件的名称,…...

python+vue3+onlyoffice在线文档系统实战20240726笔记,左侧菜单实现和最近文档基本实现
解决右侧高度过高的问题 解决方案:去掉右侧顶部和底部。 实现左侧菜单 最近文档,纯粹文档 我的文档,既包括文件夹也包括文件 共享文档,别人分享给我的 基本实现代码: 渲染效果: 简单优化 设置默认菜…...

vue中的nexttrick
Vue.js 是一个用于构建用户界面的渐进式框架,它允许开发者通过声明式的数据绑定来构建网页应用。在 Vue 中,nextTick 是一个非常重要的 API,它用于延迟回调的执行,直到下次 DOM 更新循环之后。 为什么使用 nextTick? …...

【BUG】已解决:ModuleNotFoundError: No module named ‘requests‘
ModuleNotFoundError: No module named ‘requests‘ 目录 ModuleNotFoundError: No module named ‘requests‘ 【常见模块错误】 【解决方案】 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身&a…...

深入理解JS中的发布订阅模式和观察者模式
发布/订阅模式(Publish/Subscribe)和观察者模式(Observer Pattern)在概念上非常相似,都是用于实现对象之间的松耦合通信。尽管它们在实现细节和使用场景上有所不同,但核心思想是相通的。 观察者模式 直接通信:在观察者模式中,观察者(Observer)直接订阅主题(Subject…...

网站IPv6支持率怎么检测?
在当今数字化的时代,IPv6的推广和应用已经成为网络发展的重要趋势。IPv6拥有更大的地址空间、更高的安全性和更好的性能,对于满足日益增长的网络需求至关重要。对于网站所有者和管理员来说,了解其网站对IPv6的支持率是评估网站性能和兼容性的…...

从压测到瓶颈定位:一次完整的性能分析思路
很多人刚接触压测时,会产生一种错觉:“压测不就是看 QPS 吗?”但压测的本质,从来不是“跑数字”,而是:找到系统的性能极限,以及限制系统性能的真正瓶颈。 本文会围绕下面几个核心问题࿰…...

n8n工作流模板大全:从入门到精通的自动化实战指南
1. 项目概述:一个为n8n用户准备的“万能工具箱” 如果你正在使用或者听说过n8n这个强大的工作流自动化工具,那你一定遇到过这样的时刻:面对一个空白的画布,知道n8n能帮你连接一切,但就是不知道从何下手,或…...

三步快速解锁网盘高速下载:LinkSwift直链解析终极指南
三步快速解锁网盘高速下载:LinkSwift直链解析终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

Lyrebird常见问题排查手册:解决无法启动和音频延迟的终极方案
Lyrebird常见问题排查手册:解决无法启动和音频延迟的终极方案 【免费下载链接】lyrebird 🦜 Simple and powerful voice changer for Linux, written with Python & GTK 项目地址: https://gitcode.com/gh_mirrors/lyr/lyrebird Lyrebird是一…...

ARM CoreSight ROM Tables解析与调试实践
1. ARM CoreSight ROM Tables基础解析在嵌入式调试领域,ARM CoreSight架构提供了一套完整的调试与追踪解决方案。作为该架构的关键组成部分,ROM Tables扮演着系统调试资源的"目录"角色。想象一下走进一个巨大的图书馆,ROM Tables就…...

LineageOS 18.1在一加9 Pro上的体验报告:纯净安卓11的续航、性能与Magisk模块搭配
一加9 Pro刷入LineageOS 18.1深度体验:纯净Android 11的终极玩法 当厂商定制系统越来越臃肿时,许多极客用户开始寻找更纯净的安卓体验。LineageOS作为CyanogenMod的精神继承者,一直是刷机爱好者的首选。本文将带您深入体验一加9 Pro刷入Linea…...

各高校论文AI率标准差异解读:从10%到30%不同学校标准差距2026年免费达标方案
各高校论文AI率标准差异解读:从10%到30%不同学校标准差距2026年免费达标方案 关于高校论文AI率标准解读,我系统研究过一段时间,也实际验证过各种说法。 这篇文章把关键的逻辑理清楚——知道了原理,遇到问题就知道该怎么处理了。…...

如何快速部署开源捉妖雷达Web版:面向新手的完整实时妖怪追踪指南
如何快速部署开源捉妖雷达Web版:面向新手的完整实时妖怪追踪指南 【免费下载链接】zhuoyao_radar 捉妖雷达 web版 项目地址: https://gitcode.com/gh_mirrors/zh/zhuoyao_radar 捉妖雷达Web版是一款基于现代Web技术开发的实时妖怪追踪工具,专为捉…...

pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境
pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境 【免费下载链接】pyecharts-assets 🗂 All assets in pyecharts 项目地址: https://gitcode.com/gh_mirrors/py/pyecharts-assets 还在为pyecharts图表加载慢而烦恼吗&…...

LZ4并行压缩:线程池设计与性能瓶颈突破的终极指南
LZ4并行压缩:线程池设计与性能瓶颈突破的终极指南 【免费下载链接】lz4 Extremely Fast Compression algorithm 项目地址: https://gitcode.com/GitHub_Trending/lz/lz4 LZ4作为一款Extremely Fast Compression algorithm,其并行压缩能力是提升处…...