大模型算法面试题(十一)
本系列收纳各种大模型面试题及答案。

1、说一下目前主流或前沿的预训练模型,包括nlp(百度ERNIE3.0,华为NEZHA,openAI gpt-3,nvidia MegatronLM,macrosoft T5)和cv(我只知道CLIP)领域
在NLP(自然语言处理)和CV(计算机视觉)领域,目前有许多主流或前沿的预训练模型。以下是对这些模型的一些概述,包括您提到的部分模型以及其他重要的模型。
NLP领域的主流或前沿预训练模型
- OpenAI GPT系列
- GPT-3:由OpenAI发布,是一个拥有1750亿参数的自回归语言模型。它在多种NLP任务上展现了强大的零样本、一次性学习和少样本学习能力。GPT-3的后续版本,如GPT-4,进一步增强了模型的性能和应用范围。
- GPT-4:相比GPT-3,GPT-4在多个方面进行了改进,包括增加对图像和文本的跨模态理解能力,以及更强的上下文理解和生成能力。
- Google BERT系列
- BERT:由Google发布,是第一个基于Transformer结构的预训练模型,通过遮蔽语言模型和下一句预测任务进行预训练。BERT在多项NLP任务上取得了显著进步。
- 后续模型:Google还发布了BERT的多个变体,如ALBERT、ELECTRA等,这些模型在结构、训练效率或性能上进行了优化。
- 百度ERNIE系列
- ERNIE 3.0:百度的ERNIE系列模型在持续更新中,ERNIE 3.0通过引入大规模知识图谱和结构化数据,增强了模型的知识理解和推理能力。
- 华为NEZHA
- NEZHA:是华为推出的基于Transformer结构的预训练模型,通过优化Transformer的架构和训练策略,提高了模型的性能。
- NVIDIA Megatron-LM
- Megatron-LM:是NVIDIA开发的一个大规模语言模型,它利用了NVIDIA的GPU加速技术,可以训练出具有数千亿参数的模型。
- Microsoft T5
- T5:是Microsoft推出的一个预训练模型,它采用了统一的文本到文本格式来处理各种NLP任务,展现了强大的泛化能力。
CV领域的主流或前沿预训练模型
在CV领域,除了您提到的CLIP(Contrastive Language-Image Pre-training)外,还有以下一些重要的预训练模型:
- ViT(Vision Transformer)
- ViT将Transformer结构应用于图像识别任务,通过将图像分割成一系列的patches,并将这些patches作为序列输入到Transformer中进行处理。ViT及其变体(如Swin Transformer)在多个图像识别任务上取得了优异性能。
- DALL-E和Imagen
- 这些模型是文本到图像的生成模型,能够根据输入的文本描述生成相应的图像。它们利用了大规模的预训练模型来捕捉文本和图像之间的关联,并生成高质量的图像。
- ResNet和DenseNet
- 尽管这些模型不是专门为预训练而设计的,但它们在计算机视觉领域具有广泛的应用,并经常作为其他预训练模型的基础架构。
2、说一下数据并行和模型并行的主要区别
数据并行和模型并行是分布式机器学习中的两种主要并行计算策略,它们的主要区别体现在任务划分方式、计算负载分配、通信开销、容错性、并行度以及实现复杂度等方面。以下是对这两种并行策略的详细比较:
数据并行
基本概念:
数据并行是一种将数据集划分成多个部分,并将这些部分分布到不同的计算节点上进行并行处理的策略。每个计算节点都拥有完整的模型副本,并使用本地数据子集来更新模型参数。
主要特点:
- 任务划分:数据集被划分为多个小数据块,每个计算节点处理一个或多个数据块。
- 计算负载:每个计算节点承担部分数据的处理任务,计算负载相对均衡。
- 通信开销:主要在参数同步时产生通信开销,因为每个节点需要将梯度汇总到中央节点(如参数服务器),并接收更新后的全局模型参数。但总体来说,通信开销相对较小。
- 容错性:对数据节点失效的容错性较好,因为数据可以在其他节点上备份,不会导致计算的中断。
- 并行度:并行度较高,可以利用大量计算节点并行处理不同的数据子集。
- 实现复杂度:实现相对简单,许多深度学习框架(如PyTorch、TensorFlow)提供了现成的工具(如nn.DataParallel或DistributedDataParallel)来支持数据并行。
模型并行
基本概念:
模型并行是一种将大型神经网络模型分割成多个子模型,并将这些子模型分布到不同的计算节点上进行并行处理的策略。每个计算节点只负责处理模型的一部分,并通过通信机制与其他节点交换信息和共享参数。
主要特点:
- 任务划分:模型被划分为多个子模型(或模型片段),每个计算节点处理一个或多个子模型。
- 计算负载:由于模型划分可能不均匀,某些节点的计算负载可能较重,而其他节点较轻,导致计算资源的不均衡利用。
- 通信开销:设备间需要频繁通信以传输中间结果和参数,通信开销较大。特别是当模型被高度分割时,通信可能成为性能瓶颈。
- 容错性:对模型节点失效的容错性较差,因为一个节点的失效可能导致其负责的子模型无法计算,进而影响整个模型的训练过程。
- 并行度:并行度相对较低,因为模型的划分可能导致部分节点处于空闲状态,无法充分利用所有计算资源。
- 实现复杂度:实现较为复杂,需要仔细设计模型分割和数据流,以确保各节点之间的有效协作和通信。此外,还需要处理设备间的数据传输和同步问题。
总结
数据并行和模型并行各有其优缺点和适用场景。数据并行适用于数据量大、模型规模适中的情况,可以充分利用分布式系统的计算资源来加速训练过程。而模型并行则适用于模型规模极大、无法在单个计算节点上完整加载的情况,通过分割模型来降低内存需求并提高计算效率。在实际应用中,可以根据具体任务的需求和可用硬件资源来选择合适的并行策略,或者将两种策略结合使用以获得最佳性能。
3、混合精度训练的原理,有哪些优缺点,针对这些优缺点是如何改进的;
混合精度训练的原理
混合精度训练是一种在深度学习模型训练过程中,同时使用不同精度的浮点数(如FP32和FP16)来进行计算的方法。其基本原理是通过使用较低精度的浮点数(如FP16)来减少训练过程中所需的内存和加快计算速度,同时保留一部分高精度的浮点数(如FP32)用于关键的计算步骤,以保证训练的稳定性和精度。
具体来说,混合精度训练在模型的前向传播和反向传播过程中,使用FP16进行大部分计算,以减少内存占用和提高计算效率。然而,由于FP16的表示范围较窄,直接用于所有计算可能会导致数值不稳定或精度损失。因此,在梯度更新等关键步骤中,混合精度训练会暂时将相关数据转换回FP32进行计算,以确保精度。
优缺点
优点
- 减少内存占用:FP16的位宽是FP32的一半,因此使用FP16可以显著减少模型训练过程中的内存占用,使得可以使用更大的模型或更多的数据进行训练。
- 加快训练速度:在支持混合精度的硬件上(如NVIDIA的Volta架构及以后的GPU),使用FP16的执行运算性能通常比FP32更高,从而可以加快模型训练速度。
- 提高计算效率:对于分布式训练,特别是在大模型训练的过程中,通讯的开销往往会增大训练时间。使用低精度的数据(如FP16)由于较小的位宽可以提高通讯效率,从而加快模型训练。
缺点
- 精度损失:由于FP16的表示范围较窄,直接使用FP16进行所有计算可能会导致数值不稳定或精度损失。
- 数值稳定性问题:在梯度更新等关键步骤中,如果处理不当,可能会导致梯度消失或爆炸,从而影响训练的稳定性和收敛性。
- 硬件依赖:混合精度训练的效果受到硬件支持的限制,只有支持半精度浮点数运算的硬件才能发挥其优势。
改进方法
针对混合精度训练的优缺点,业界提出了多种改进方法:
- 权重备份:在训练过程中,保留一份FP32格式的模型参数副本,用于梯度更新等关键步骤。这样可以确保在需要高精度计算时,能够恢复到FP32的精度。
- 损失缩放:为了解决FP16梯度表示范围较窄的问题,引入损失缩放技术。在训练过程中,将前向传播得到的损失值进行放大,以确保梯度在反向传播过程中不会因数值过小而变为零。在梯度更新后,再将放大的梯度值缩小回原始范围。
- 梯度裁剪:为了防止梯度爆炸,可以对梯度进行裁剪,限制其最大值。这样可以确保梯度在合理的范围内,避免对模型参数造成过大的更新。
- 动态调整学习率:随着训练的进行,动态地调整学习率以适应使用半精度浮点数时可能出现的数值不稳定性。这有助于提高训练的稳定性和收敛速度。
- 硬件优化:随着硬件技术的发展,越来越多的GPU和AI加速芯片开始支持混合精度训练。这些硬件优化可以进一步提高混合精度训练的性能和稳定性。
通过上述改进方法,混合精度训练在深度学习领域得到了广泛应用,并取得了显著的效果。
4、说一下DeepSpeed有哪些方面的突破
DeepSpeed在深度学习领域取得了多方面的突破,主要体现在提高大规模模型训练的效率和可扩展性上。以下是DeepSpeed的主要突破点:
1. 高效的并行化策略
- 数据并行:DeepSpeed支持数据并行,即将大型数据集分割成小块,并在多个处理器上并行处理这些数据块。这种策略可以显著提高训练速度,特别是在处理大规模数据集时。
- 模型并行:对于超大型模型,特别是那些无法完整放入单个设备内存的模型,DeepSpeed通过模型并行性支持将模型的不同层分配到不同的设备上,从而实现大型模型的训练。
- 流水线并行:DeepSpeed还实现了流水线并行,将模型划分为多个阶段,并在不同的处理器上并行处理这些阶段。这种方法进一步提高了训练效率,特别是针对那些层数较多、计算复杂的模型。
2. 内存优化技术
- ZeRO(Zero Redundancy Optimizer):DeepSpeed引入了ZeRO技术,这是一种创新的内存优化技术。ZeRO通过将优化器的状态、梯度和参数在分布式环境中进行分割,从而减少了冗余的内存占用。具体来说,ZeRO包含三个级别(ZeRO-1、ZeRO-2、ZeRO-3),分别对应于优化器状态、梯度和参数的分区。这种技术使得在有限的内存资源下训练更大的模型成为可能。
3. 混合精度训练支持
- DeepSpeed支持混合精度训练,即同时使用单精度(FP32)和半精度(FP16)浮点数进行训练。这种方法可以在保持模型性能的同时,减少内存占用和计算时间,降低能耗。混合精度训练已成为训练大规模模型的一种标准做法。
4. 易用性和兼容性
- 与PyTorch等主流框架的集成:DeepSpeed与PyTorch等主流深度学习框架紧密集成,提供了易用的API和丰富的文档支持。这使得研究人员和工程师能够轻松地将DeepSpeed集成到他们的项目中,并充分利用其提供的优化功能。
- 高度优化的数据加载和网络通信:DeepSpeed还提供了高度优化的数据加载和网络通信工具,以减少通信量并提高多GPU和多节点环境下的训练效率。
5. 实际应用与合作伙伴
- DeepSpeed已经在多个实际项目中得到了应用,包括语言模型、图像分类、目标检测等。同时,DeepSpeed还与多个科研机构和企业建立了合作关系,共同推动深度学习技术的发展和应用。
综上所述,DeepSpeed通过高效的并行化策略、内存优化技术、混合精度训练支持以及易用性和兼容性等方面的突破,显著提高了大规模模型训练的效率和可扩展性,为深度学习领域的发展做出了重要贡献。
5、SFT指令微调数据如何构建
SFT(Supervised Fine-Tuning)指令微调数据的构建是一个系统性的过程,旨在通过有监督的方式对预训练的大语言模型(LLM)进行微调,以适应特定任务的需求。以下是构建SFT指令微调数据的详细步骤:
一、明确任务需求
首先,需要明确微调模型的具体任务类型,如文本分类、对话生成、文本摘要等。这有助于确定数据收集的方向和标注标准。
二、收集原始数据
- 数据来源:可以从多个渠道收集与目标任务相关的原始数据,如公开数据集、网络爬虫、用户提交的数据等。
- 数据质量:确保收集到的数据具有代表性和多样性,以提高模型的泛化能力。
三、标注数据
- 标注标准:根据任务需求制定详细的标注标准,包括标签类型、标注规则等。
- 标注过程:对原始数据进行标注,为每个样本提供正确的标签或目标输出。标注过程中需要确保标注的准确性和一致性。
四、划分数据集
将标注后的数据划分为训练集、验证集和测试集。通常,大部分数据用于训练,一小部分用于验证模型的性能和调整超参数,最后一部分用于最终评估模型的泛化能力。
五、数据预处理
- 文本清洗:去除文本中的噪声和异常值,如重复数据、缺失值、无效字符等。
- 特征工程:将文本数据转换为适合模型输入的特征表示,如分词、去除停用词、词干化、词嵌入等。
六、格式转换
将数据转换为适合模型训练的格式,如文本文件、JSON格式等。同时,确保数据集中的每个样本都包含任务描述(指令)、输入和输出(标签或目标输出)。
七、指令化设计
在数据集中添加任务描述(指令),用于指导模型理解任务目标和相关信息。任务描述应该清晰、简洁,并符合自然语言习惯。
八、数据集审核与优化
- 审核:对构建好的数据集进行审核,检查标注的准确性和一致性,剔除低质量或错误的样本。
- 优化:根据审核结果对数据集进行优化,如增加样本数量、调整标注标准等。
九、模型微调
使用构建好的数据集对预训练的大语言模型进行微调。在微调过程中,需要选择合适的优化算法和超参数,并监控模型的训练过程和性能表现。
十、模型评估与迭代
使用测试集对微调后的模型进行评估,计算模型在任务上的性能指标(如准确率、召回率、生成质量等)。根据评估结果对模型进行进一步的优化和调整,必要时可以重新构建数据集或调整模型架构。
注意事项
- 数据多样性:为了提高模型的泛化能力,需要确保数据集的多样性,涵盖尽可能多的不同场景和需求。
- 标注准确性:数据标注的准确性直接影响到模型的性能,因此需要仔细审查和校验标注结果。
- 数据集平衡性:在构建数据集时,需要确保不同类别的样本数量相对平衡,以避免模型对某些类别的偏好。
通过以上步骤,可以构建出高质量的SFT指令微调数据集,为预训练的大语言模型提供有效的训练和优化支持。
相关文章:
大模型算法面试题(十一)
本系列收纳各种大模型面试题及答案。 1、说一下目前主流或前沿的预训练模型,包括nlp(百度ERNIE3.0,华为NEZHA,openAI gpt-3,nvidia MegatronLM,macrosoft T5)和cv(我只知道CLIP&…...

CSS 基础知识
CSS(级联样式表)是设置 Web 内容样式的代码。CSS 基础知识将介绍入门所需的内容。我们将回答以下问题:如何将文本设置为红色?如何使内容显示在(网页)布局中的某个位置?如何用背景图片和颜色装饰我的网页? 什么是CSS? 像HTML一样,CSS不是一种编程语言。它也不是一种标…...

IntelliJ IDEA 和 Eclipse的区别
IntelliJ IDEA 和 Eclipse 是两个非常流行的 Java 集成开发环境(IDE),它们各自具有不同的特点和优势。下面是它们之间的一些主要对比: 性能和资源使用 IntelliJ IDEA 被认为在某些方面更加智能,能够提供更好的代码分…...

Ansible之playbook剧本编写(二)
tags 模块 可以在一个playbook中为某个或某些任务定义“标签”,在执行此playbook时通过ansible-playbook命令使用--tags选项能实现仅运行指定的tasks。 playbook还提供了一个特殊的tags为always。作用就是当使用always作为tags的task时,无论执行哪一个t…...

力扣第二十九题——两数相除
内容介绍 给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。 整数除法应该向零截断,也就是截去(truncate)其小数部分。例如,8.345 将被截断为 8 ,-…...

解析三款热门的文献翻译工具:优势与使用指南
今儿咱们来聊聊那些让咱们头疼又不得不面对的事儿——文献翻译。在浩瀚的学术海洋里遨游时,遇到外文文献那是家常便饭,但语言障碍就像海上的迷雾,一不小心就能让你偏离航向。别担心,我这不就带着几款亲测好用的文献翻译神器来了嘛…...

git 过滤LFS文件下载
git config --global filter.lfs.smudge "git-lfs smudge --skip -- %f" git config --global filter.lfs.process "git-lfs filter-process --skip" 恢复下载 git config --global filter.lfs.smudge "git-lfs smudge -- %f" git config --g…...

内存泄漏详解
文章目录 什么是内存泄漏内存泄漏的原因排查及解决内存泄漏避免内存泄漏及时释放资源设置合理的变量作用域及时清理不需要的对象避免无限增长避免内部类持有外部类引用使用弱引用 什么是内存泄漏 内存泄漏是指不使用的对象持续占有内存使得内存得不到释放,从而造成…...

多角度解析高防CDN防御DDOS及CC攻击
网络攻击的形式也日益多样化,其中DDoS(分布式拒绝服务)和CC(Challenge Collapsar)攻击尤为突出,给网站和企业带来了巨大的安全威胁。高防CDN(Content Delivery Network)作为一种专业…...

(7) cmake 编译C++程序(二)
文章目录 概要整体代码结构整体代码小结 概要 在ubuntu下,通过cmake编译一个稍微复杂的管理程序 整体代码结构 整体代码 boss.cpp #include "boss.h"Boss::Boss(int id, string name, int dId) {this->Id id;this->Name name;this->DeptId …...

C语言系统调用linux文件系统
在C语言中,open、write和read函数是系统调用(system calls),它们直接由操作系统提供,用于底层的文件操作。这些函数是UNIX和类UNIX系统(如Linux)中的标准接口,不同于C标准库中的文件…...

LeetCode142 环形链表 II
前言 题目: 142. 环形链表 II 文档: 代码随想录——环形链表 II 编程语言: C 解题状态: 思路错误,链表不允许被修改 思路 两步走,第一步,判断有没有环,第二步,判断入环口…...

逆向案例二十八——某高考志愿网异步请求头参数加密,以及webpack
网址:aHR0cDovL3d3dy54aW5nYW9rYW90Yi5jb20vY29sbGVnZXMvc2VhcmNo 抓包分析,发现请求头有参数u-sign是加密的,载荷没有进行加密,直接跟栈分析。 进入第二个栈,打上断点,分析有没有加密位置。 可以看到参数…...

WebKit的文本装饰艺术:CSS Text Decoration全解析
WebKit的文本装饰艺术:CSS Text Decoration全解析 CSS文本装饰(Text Decoration)是一组用于美化和增强网页文本表现的属性,它们可以为文本添加下划线、上划线、线删除和强调标记等效果。WebKit作为许多现代浏览器的渲染引擎&…...

【linux】Shell脚本三剑客之sed命令的详细用法攻略
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全…...

解析class字节码文件获取魔数和版本号
写在前面 本文看下如何获取class字节码文件的魔数和版本号信息。 1:正文 需要对class字节码的结构有一定的了解,可以参考这篇文章 。 直接看代码: package org.example;import java.math.BigInteger;public class TTTT {//取部分字节码&…...

技术文档总结----思维导图
性能调优| ProcessOn免费在线作图,在线流程图,在线思维导图 mysql| ProcessOn免费在线作图,在线流程图,在线思维导图 kafka| ProcessOn免费在线作图,在线流程图,在线思维导图 mybatis缓存| ProcessOn免费在线作图,在线流程图,在线思维导图 java锁| ProcessOn免费在线作图,在…...
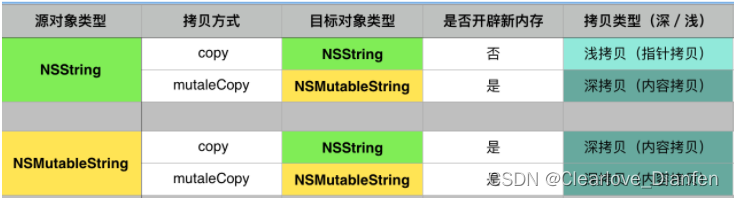
【iOS】—— retain\release实现原理和属性关键字
【iOS】—— retain\release实现原理和属性关键字 1. retain\reelase实现原理1.1 retain实现原理1.2 release实现原理 2. 属性关键字2.1 属性关键字的分类2.2 内存管理关键字2.2.1 weak2.2.2 assgin2.3.3 strong和copy 2.4 线程安全的关键字2.5 修饰变量的关键字2.5.1常量const…...

这一文,关于Java泛型的点点滴滴 一
作为一个 Java 程序员,用到泛型最多的,我估计应该就是这一行代码: List<String> list new ArrayList<>();这也是所有 Java 程序员的泛型之路开始的地方啊。 不过本文讲泛型,先不从这里开始讲,而是再往前…...
微信小程序之调查问卷
一、设计思路 1、界面 调查问卷又称调查表,是以问题的形式系统地记载调查内容的一种形式。微信小程序制作的调查问卷,可以在短时间内快速收集反馈信息。具体效果如下所示: 2、思路 此调查问卷采用服务器客户端的方式进行设计,服…...

Java-Thread-Affinity源码解析:深入理解IAffinity接口的跨平台设计
Java-Thread-Affinity源码解析:深入理解IAffinity接口的跨平台设计 【免费下载链接】Java-Thread-Affinity Bind a java thread to a given core 项目地址: https://gitcode.com/gh_mirrors/ja/Java-Thread-Affinity Java-Thread-Affinity是一个专注于线程亲…...
Zotero PDF Translate:打破语言壁垒,让外文文献阅读更高效 [特殊字符]
Zotero PDF Translate:打破语言壁垒,让外文文献阅读更高效 🚀 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: ht…...

AI记忆系统健康管理:行为数据驱动的OpenClaw记忆污染解决方案
1. 项目概述:为AI记忆系统装上“听诊器”如果你正在用OpenClaw,或者任何类似的AI智能体开发框架,那你肯定对它的记忆系统又爱又恨。爱的是,它能记住你项目里的关键代码片段、常用指令,下次对话时能直接调出来用&#x…...

Python开发者如何构建个人技能库:从代码片段到高效编程
1. 项目概述:一个Python开发者的“兵器库”在Python开发这条路上摸爬滚打久了,你会发现一个有趣的现象:高手和新手之间的差距,往往不在于对某个框架的掌握深度,而在于对“工具”和“技巧”的运用效率。这里的“工具”不…...

如何在不同设备上高效格式化SD卡
对于任何使用相机、智能手机或电脑的人来说,格式化SD卡都是一项基本技能。无论是清理旧文件为新照片腾出空间,还是修复“卡错误”提示,掌握正确的SD卡格式化方法都能确保其使用寿命和性能。接下来,我们将介绍几种格式化方法。第一…...
)
NotebookLM播客生成质量分析(行业首份LMM音频语义保真度测评报告)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM播客生成质量分析 NotebookLM 作为 Google 推出的实验性 AI 助手,其播客(Podcast)生成功能依托于对用户上传文档的理解与结构化重述。该功能并非端到端语音…...

火山引擎AgentKit实战:从零构建企业级AI智能体应用
1. 从零到一:AgentKit代码工坊深度解析与实战指南如果你正在寻找一个能快速上手、功能强大的企业级AI Agent开发平台,那么火山引擎的AgentKit绝对值得你花时间深入研究。最近,我花了大量时间泡在它的官方代码示例仓库bytedance/agentkit-samp…...

PipeANN:基于SSD的十亿级向量检索系统设计与实战
1. 项目概述:PipeANN,一个为SSD而生的向量检索系统如果你正在处理十亿级别的向量数据,并且对检索延迟和内存消耗感到头疼,那么PipeANN这个名字你应该记住。这是一个来自学术界的开源项目,但它解决的问题非常实际&#…...

Cursor聊天数据恢复工具:原理、实操与避坑指南
1. 项目概述:数据恢复的“后悔药”在数字创作的世界里,我们与工具的交互正变得越来越智能和复杂。Cursor,这款集成了AI辅助编程能力的编辑器,已经成为了许多开发者和技术写作者的主力工具。它不仅仅是写代码,更是一个集…...

解决ROS的‘Done checking log file disk usage’卡顿:你的~/.bashrc里ROS_IP设对了吗?
解决ROS日志检查卡顿:环境变量配置的深层解析与实战指南 当你在终端启动roscore时,是否遇到过长时间卡在"Done checking log file disk usage"提示的尴尬?这个问题看似简单,背后却隐藏着ROS环境配置的关键细节。本文将带…...