【YOLOv5/v7改进系列】引入中心化特征金字塔的EVC模块

一、导言
现有的特征金字塔方法过于关注层间特征交互而忽视了层内特征的调控。尽管有些方法尝试通过注意力机制或视觉变换器来学习紧凑的层内特征表示,但这些方法往往忽略了对密集预测任务非常重要的被忽视的角落区域。
为了解决这个问题,作者提出了CFP,它首先在最深层的特征图上应用显式视觉中心方案,然后利用这些信息去调整较浅层的特征图。这种方法使得CFP不仅能够捕捉全局的长距离依赖,还能高效地获得全面且有判别性的特征表示。
CFP通过其显式视觉中心方案和全局集中化调节机制,在保持较低计算复杂度的同时提高了特征金字塔的质量,从而在目标检测任务中实现了更好的性能。
本文主要利用EVC模块进行改进工作。
EVC 的主要目的是捕捉全局的长距离依赖关系,并保留输入图像中的局部关键区域信息。下面是对 EVC 模块的详细介绍:
EVC 模块组成
EVC 模块由两个并行连接的块组成:
- 轻量级 MLP:用于捕获全局的长距离依赖关系(即全局信息)。
- 可学习的视觉中心机制:用于保留输入图像中的局部关键区域信息(即局部信息)。
轻量级 MLP
轻量级 MLP 是一个多层感知机,用于捕捉全局信息。相较于基于多头注意力机制的标准变换器编码器,轻量级 MLP 不仅结构简单,而且体积更小、计算效率更高。它取代了标准变换器编码器中的多头自注意力模块。
可学习的视觉中心机制
可学习的视觉中心机制是专门设计用来保留图像局部角落区域信息的。这部分机制与轻量级 MLP 并行运行,共同捕捉全局和局部特征。
输出融合
EVC 模块的输出是这两个块的结果在通道维度上的拼接。即轻量级 MLP 和可学习视觉中心机制的输出特征图沿通道方向进行拼接。
具体实现过程
- 输入特征图:输入到 EVC 的特征图是特征金字塔中最顶层的特征图X4。
- 特征平滑:在输入特征图 X4 和 EVC 之间,会有一个 Stem 块用于特征平滑。Stem 块由一个 7x7 的卷积层组成,输出通道大小为 256,后面跟着批量归一化层和激活函数层。
- 轻量级 MLP:用于捕获全局信息。
- 可学习视觉中心机制:用于保留局部关键区域信息。
- 特征融合:轻量级 MLP 和可学习视觉中心机制的输出通过通道拼接的方式组合起来作为 EVC 的输出。
EVC 的作用
EVC 模块通过结合全局和局部特征信息,能够为后续的全局集中化调节 (GCR) 提供丰富的视觉中心信息。这种信息有助于浅层特征的调节,使得整个特征金字塔不仅能捕捉全局的长距离依赖关系,还能有效地获得全面且具有判别力的特征表示。

二、准备工作
首先在YOLOv5/v7的models文件夹下新建文件evc.py,导入如下代码
from models.common import *
from functools import partial
from timm.models.layers import DropPath, trunc_normal_# LVC
class Encoding(nn.Module):def __init__(self, in_channels, num_codes):super(Encoding, self).__init__()# init codewords and smoothing factorself.in_channels, self.num_codes = in_channels, num_codesnum_codes = 64std = 1. / ((num_codes * in_channels) ** 0.5)# [num_codes, channels]self.codewords = nn.Parameter(torch.empty(num_codes, in_channels, dtype=torch.float).uniform_(-std, std), requires_grad=True)# [num_codes]self.scale = nn.Parameter(torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0), requires_grad=True)@staticmethoddef scaled_l2(x, codewords, scale):num_codes, in_channels = codewords.size()b = x.size(0)expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))reshaped_scale = scale.view((1, 1, num_codes)) # N, num_codesscaled_l2_norm = reshaped_scale * (expanded_x - reshaped_codewords).pow(2).sum(dim=3)return scaled_l2_norm@staticmethoddef aggregate(assignment_weights, x, codewords):num_codes, in_channels = codewords.size()reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))b = x.size(0)expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))assignment_weights = assignment_weights.unsqueeze(3) # b, N, num_codes,encoded_feat = (assignment_weights * (expanded_x - reshaped_codewords)).sum(1)return encoded_featdef forward(self, x):assert x.dim() == 4 and x.size(1) == self.in_channelsb, in_channels, w, h = x.size()# [batch_size, height x width, channels]x = x.view(b, self.in_channels, -1).transpose(1, 2).contiguous()# assignment_weights: [batch_size, channels, num_codes]assignment_weights = torch.softmax(self.scaled_l2(x, self.codewords, self.scale), dim=2)# aggregateencoded_feat = self.aggregate(assignment_weights, x, self.codewords)return encoded_featclass Mlp(nn.Module):"""Implementation of MLP with 1*1 convolutions. Input: tensor with shape [B, C, H, W]"""def __init__(self, in_features, hidden_features=None,out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Conv2d):trunc_normal_(m.weight, std=.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x# 1*1 3*3 1*1
class ConvBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.ReLU, groups=1,norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):super(ConvBlock, self).__init__()self.in_channels = in_channelsexpansion = 4c = out_channels // expansionself.conv1 = Conv(in_channels, c, act=nn.ReLU())self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.ReLU())self.conv3 = Conv(c, out_channels, 1, act=False)self.act3 = act_layer(inplace=True)if res_conv:self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)self.residual_bn = norm_layer(out_channels)self.res_conv = res_convdef zero_init_last_bn(self):nn.init.zeros_(self.bn3.weight)def forward(self, x, return_x_2=True):residual = xx = self.conv1(x)x2 = self.conv2(x) # if x_t_r is None else self.conv2(x + x_t_r)x = self.conv3(x2)if self.res_conv:residual = self.residual_conv(residual)residual = self.residual_bn(residual)x += residualx = self.act3(x)if return_x_2:return x, x2else:return xclass Mean(nn.Module):def __init__(self, dim, keep_dim=False):super(Mean, self).__init__()self.dim = dimself.keep_dim = keep_dimdef forward(self, input):return input.mean(self.dim, self.keep_dim)class LVCBlock(nn.Module):def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):super(LVCBlock, self).__init__()self.out_channels = out_channelsself.num_codes = num_codesnum_codes = 64self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)self.LVC = nn.Sequential(Conv(in_channels, in_channels, 1, act=nn.ReLU()),Encoding(in_channels=in_channels, num_codes=num_codes),nn.BatchNorm1d(num_codes),nn.ReLU(inplace=True),Mean(dim=1))self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())def forward(self, x):x = self.conv_1(x, return_x_2=False)en = self.LVC(x)gam = self.fc(en)b, in_channels, _, _ = x.size()y = gam.view(b, in_channels, 1, 1)x = F.relu_(x + x * y)return xclass GroupNorm(nn.GroupNorm):"""Group Normalization with 1 group.Input: tensor in shape [B, C, H, W]"""def __init__(self, num_channels, **kwargs):super().__init__(1, num_channels, **kwargs)class DWConv_LMLP(nn.Module):"""Depthwise Conv + Conv"""def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):super().__init__()self.dconv = Conv(in_channels,in_channels,k=ksize,s=stride,g=in_channels,)self.pconv = Conv(in_channels, out_channels, k=1, s=1, g=1)def forward(self, x):x = self.dconv(x)return self.pconv(x)# LightMLPBlock
class LightMLPBlock(nn.Module):def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu",mlp_ratio=4., drop=0., act_layer=nn.GELU,use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0.,norm_layer=GroupNorm): # act_layer=nn.GELU,super().__init__()self.dw = DWConv_LMLP(in_channels, out_channels, ksize=1, stride=1, act="silu")self.linear = nn.Linear(out_channels, out_channels) # learnable position embeddingself.out_channels = out_channelsself.norm1 = norm_layer(in_channels)self.norm2 = norm_layer(in_channels)mlp_hidden_dim = int(in_channels * mlp_ratio)self.mlp = Mlp(in_features=in_channels, hidden_features=mlp_hidden_dim, act_layer=nn.GELU,drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. \else nn.Identity()self.use_layer_scale = use_layer_scaleif use_layer_scale:self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)def forward(self, x):if self.use_layer_scale:x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.dw(self.norm1(x)))x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))else:x = x + self.drop_path(self.dw(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x# EVCBlock
class EVCBlock(nn.Module):def __init__(self, in_channels, out_channels, channel_ratio=4, base_channel=16):super().__init__()expansion = 2ch = out_channels * expansionself.conv1 = Conv(in_channels, in_channels, k=7, act=nn.ReLU())self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # 1 / 4 [56, 56]# LVCself.lvc = LVCBlock(in_channels=in_channels, out_channels=out_channels, num_codes=64) # c1值暂时未定# LightMLPBlockself.l_MLP = LightMLPBlock(in_channels, out_channels, ksize=1, stride=1, act="silu", act_layer=nn.GELU,mlp_ratio=4., drop=0.,use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0.,norm_layer=GroupNorm)self.cnv1 = nn.Conv2d(ch, out_channels, kernel_size=1, stride=1, padding=0)def forward(self, x):x1 = self.maxpool((self.conv1(x)))# LVCBlockx_lvc = self.lvc(x1)# LightMLPBlockx_lmlp = self.l_MLP(x1)# concatx = torch.cat((x_lvc, x_lmlp), dim=1)x = self.cnv1(x)return x
其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
from models.evc import EVCBlock并搜索def parse_model(d, ch)
定位到如下行添加以下代码
elif m is EVCBlock:c2 = ch[f]args = [c2, c2]
三、YOLOv7-tiny改进工作
完成二后,在YOLOv7项目文件下的models文件夹下创建新的文件yolov7-tiny-evc.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# yolov7-tiny backbone
backbone:# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True[[-1, 1, Conv, [32, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 0-P1/2[-1, 1, Conv, [64, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 1-P2/4[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 7[-1, 1, MP, []], # 8-P3/8[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14[-1, 1, MP, []], # 15-P4/16[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 21[-1, 1, MP, []], # 22-P5/32[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 28[-1, 1, EVCBlock, [512, 512]], # 29-a]# yolov7-tiny head
head:[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, SP, [5]],[-2, 1, SP, [9]],[-3, 1, SP, [13]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -7], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 38[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[21, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 48[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[14, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 58[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],[[-1, 48], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 66[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],[[-1, 38], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 74[58, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[66, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[74, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[75,76,77], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
from n params module arguments 0 -1 1 928 models.common.Conv [3, 32, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]1 -1 1 18560 models.common.Conv [32, 64, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]2 -1 1 2112 models.common.Conv [64, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]3 -2 1 2112 models.common.Conv [64, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]4 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]5 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]6 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 7 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]8 -1 1 0 models.common.MP [] 9 -1 1 4224 models.common.Conv [64, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]10 -2 1 4224 models.common.Conv [64, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]11 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]12 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]13 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 14 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]15 -1 1 0 models.common.MP [] 16 -1 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]17 -2 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]18 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]19 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]20 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 21 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]22 -1 1 0 models.common.MP [] 23 -1 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]24 -2 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]25 -1 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]26 -1 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]27 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 28 -1 1 525312 models.common.Conv [1024, 512, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]29 -1 1 17103040 models.evc.EVCBlock [512, 512] 30 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]31 -2 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]32 -1 1 0 models.common.SP [5] 33 -2 1 0 models.common.SP [9] 34 -3 1 0 models.common.SP [13] 35 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 36 -1 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]37 [-1, -7] 1 0 models.common.Concat [1] 38 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]39 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]40 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 41 21 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]42 [-1, -2] 1 0 models.common.Concat [1] 43 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]44 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]45 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]46 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]47 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 48 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]49 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]50 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 51 14 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]52 [-1, -2] 1 0 models.common.Concat [1] 53 -1 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]54 -2 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]55 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]56 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]57 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 58 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]59 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]60 [-1, 48] 1 0 models.common.Concat [1] 61 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]62 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]63 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]64 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]65 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 66 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]67 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]68 [-1, 38] 1 0 models.common.Concat [1] 69 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]70 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]71 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]72 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]73 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 74 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]75 58 1 73984 models.common.Conv [64, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]76 66 1 295424 models.common.Conv [128, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]77 74 1 1180672 models.common.Conv [256, 512, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]78 [75, 76, 77] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]Model Summary: 318 layers, 23118028 parameters, 23118028 gradients, 26.7 GFLOPS运行后若打印出如上文本代表改进成功。
四、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-evc.yaml,导入如下代码。
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, EVCBlock, [1024, 1024]],# 9-a[-1, 1, SPPF, [1024, 5]], # 10]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 15], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
from n params module arguments 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] 2 -1 1 18816 models.common.C3 [64, 64, 1] 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] 4 -1 2 115712 models.common.C3 [128, 128, 2] 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] 6 -1 3 625152 models.common.C3 [256, 256, 3] 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] 8 -1 1 1182720 models.common.C3 [512, 512, 1] 9 -1 1 17103040 models.evc.EVCBlock [512, 512] 10 -1 1 656896 models.common.SPPF [512, 512, 5] 11 -1 1 131584 models.common.Conv [512, 256, 1, 1] 12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 13 [-1, 6] 1 0 models.common.Concat [1] 14 -1 1 361984 models.common.C3 [512, 256, 1, False] 15 -1 1 33024 models.common.Conv [256, 128, 1, 1] 16 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 17 [-1, 4] 1 0 models.common.Concat [1] 18 -1 1 90880 models.common.C3 [256, 128, 1, False] 19 -1 1 147712 models.common.Conv [128, 128, 3, 2] 20 [-1, 15] 1 0 models.common.Concat [1] 21 -1 1 296448 models.common.C3 [256, 256, 1, False] 22 -1 1 590336 models.common.Conv [256, 256, 3, 2] 23 [-1, 11] 1 0 models.common.Concat [1] 24 -1 1 1182720 models.common.C3 [512, 512, 1, False] 25 [18, 21, 24] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]Model Summary: 325 layers, 24125366 parameters, 24125366 gradients, 29.5 GFLOPs运行后若打印出如上文本代表改进成功。
五、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5n-evc.yaml,导入如下代码。
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, EVCBlock, [1024, 1024]],# 9-a[-1, 1, SPPF, [1024, 5]], # 10]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 15], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
from n params module arguments 0 -1 1 1760 models.common.Conv [3, 16, 6, 2, 2] 1 -1 1 4672 models.common.Conv [16, 32, 3, 2] 2 -1 1 4800 models.common.C3 [32, 32, 1] 3 -1 1 18560 models.common.Conv [32, 64, 3, 2] 4 -1 2 29184 models.common.C3 [64, 64, 2] 5 -1 1 73984 models.common.Conv [64, 128, 3, 2] 6 -1 3 156928 models.common.C3 [128, 128, 3] 7 -1 1 295424 models.common.Conv [128, 256, 3, 2] 8 -1 1 296448 models.common.C3 [256, 256, 1] 9 -1 1 4287680 models.evc.EVCBlock [256, 256] 10 -1 1 164608 models.common.SPPF [256, 256, 5] 11 -1 1 33024 models.common.Conv [256, 128, 1, 1] 12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 13 [-1, 6] 1 0 models.common.Concat [1] 14 -1 1 90880 models.common.C3 [256, 128, 1, False] 15 -1 1 8320 models.common.Conv [128, 64, 1, 1] 16 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 17 [-1, 4] 1 0 models.common.Concat [1] 18 -1 1 22912 models.common.C3 [128, 64, 1, False] 19 -1 1 36992 models.common.Conv [64, 64, 3, 2] 20 [-1, 15] 1 0 models.common.Concat [1] 21 -1 1 74496 models.common.C3 [128, 128, 1, False] 22 -1 1 147712 models.common.Conv [128, 128, 3, 2] 23 [-1, 11] 1 0 models.common.Concat [1] 24 -1 1 296448 models.common.C3 [256, 256, 1, False] 25 [18, 21, 24] 1 8118 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]Model Summary: 325 layers, 6052950 parameters, 6052950 gradients, 7.6 GFLOPs六、注意
本文是一个示例修改,EVC这个模块添加在此处会导致参数量较为复杂,实际修改可以不按本文yaml示例进行修改,也可以按照官方改进点进行添加,同时加在骨干第一个输出的尺度位置可以控制参数量,但实际有条件的话还是建议多测几次,找到适合自己的改进点。
运行后打印如上代码说明改进成功。
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!
相关文章:
【YOLOv5/v7改进系列】引入中心化特征金字塔的EVC模块
一、导言 现有的特征金字塔方法过于关注层间特征交互而忽视了层内特征的调控。尽管有些方法尝试通过注意力机制或视觉变换器来学习紧凑的层内特征表示,但这些方法往往忽略了对密集预测任务非常重要的被忽视的角落区域。 为了解决这个问题,作者提出了CF…...
【QT】常用控件(概述、QWidget核心属性、按钮类控件、显示类控件、输入类控件、多元素控件、容器类控件、布局管理器)
一、控件概述 Widget 是 Qt 中的核心概念,英文原义是 “小部件”,此处也把它翻译为 “控件”。控件是构成一个图形化界面的基本要素。 像上述示例中的按钮、列表视图、树形视图、单行输入框、多行输入框、滚动条、下拉框都可以称为 “控件”。 Qt 作为…...

【Python】字母 Rangoli 图案
一、题目 You are given an integer N. Your task is to print an alphabet rangoli of size N. (Rangoli is a form of Indian folk art based on creation of patterns.) Different sizes of alphabet rangoli are shown below: # size 3 ----c---- --c-b-c-- c-b-a-b-c --…...

html+css 实现水波纹按钮
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽效果!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 文…...

科技与占星的融合:AI 智能占星师
本文由 ChatMoney团队出品 在科技的前沿领域,诞生了一位独特的存在——AI占星师。它并非传统意义上的占星师,而是融合了先进的人工智能技术与神秘的占星学知识。 这能够凭借其强大的数据分析能力和精准的算法,对星辰的排列和宇宙的能量进行深…...

判断字符串,数组方法
判断字符串方法 在JavaScript中,可以使用typeof操作符来判断一个变量是否为字符串。 function isString(value) {return typeof value string; } 判断数组 在JavaScript中,typeof操作符并不足以准确判断一个变量是否为数组,因为typeof会…...

SpringBoot Vue使用Jwt实现简单的权限管理
为实现Jwt简单的权限管理,我们需要用Jwt工具来生成token,也需要用Jwt来解码token,同时需要添加Jwt拦截器来决定放行还是拦截。下面来实现: 1、gradle引入Jwt、hutool插件 implementation com.auth0:java-jwt:3.10.3implementatio…...

java中的多态
多态基础了解: 面向对象的三大特征:封装,继承,多态。 有了面向对象才有继承和多态,对象代表什么,就封装对应的数据,并提供数据对应的行为,可以把零散的数据和行为进行封装成一个整…...
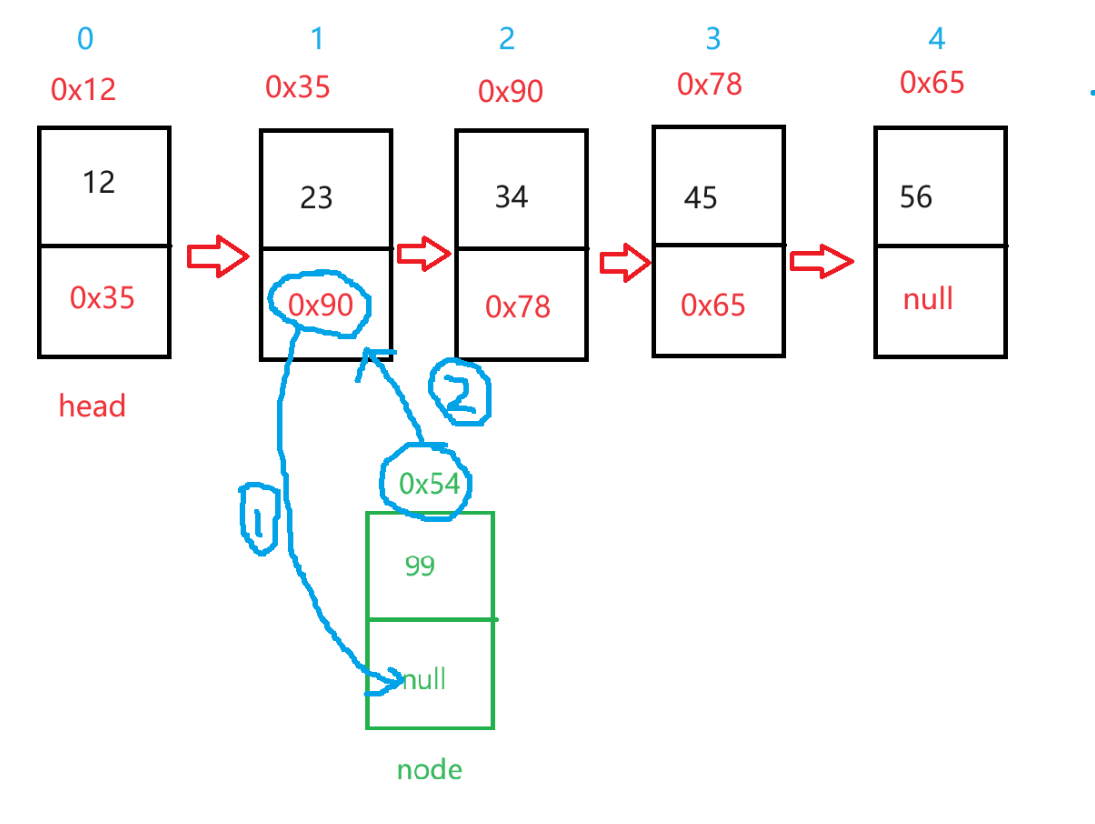
【数据结构】:用Java实现链表
在 ArrayList 任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为 O(n),效率比较低,因此 ArrayList 不适合做任意位置插入和删除比较多的场景。因此:java 集合中又引入了 LinkedList&…...

前端开发知识(三)-javascript
javascript是一门跨平台、面向对象的脚本语言。 一、引入方式 1.内部脚本:使用<script> ,可以放在任意位置,也可以有多个,一般是放在<body></body>的下方。 2.外部脚本:单独编写.js文件ÿ…...
-MFC-C/C++ - MFC绘图)
Windows图形界面(GUI)-MFC-C/C++ - MFC绘图
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 MFC绘图 绘图基础 CPaintDC 实例代码 MFC绘图 绘图基础 设备上下文(Device Context, DC): 设备上下文是一个Windows GDI(图形设备接口)…...

51单片机-第五节-串口通信
1.什么是串口? 串口是通讯接口,实现两个设备的互相通信。 单片机自带UART,其中引脚有TXD发送端,RXD接收端。且电平标准为TTL(5V为1,0V为0)。 2.常见电平标准: (1)TTL电…...

【Linux常用命令】之df命令
Linux常用命令之df命令 文章目录 Linux常用命令之df命令常用命令之df背景介绍 总结 作者简介 听雨:一名在一线从事多年研发的程序员,从事网站后台开发,熟悉java技术栈,对前端技术也有研究,同时也是一名骑行爱好者。 D…...

2024年起重信号司索工(建筑特殊工种)证模拟考试题库及起重信号司索工(建筑特殊工种)理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年起重信号司索工(建筑特殊工种)证模拟考试题库及起重信号司索工(建筑特殊工种)理论考试试题是由安全生产模拟考试一点通提供,起重信号司索工(建筑特殊工种)证模拟考试题库是根据起重信号司索工(建筑特…...
)
AWS全服务历史年表:发布日期、GA和服务概述一览 (全)
我一直在尝试从各种角度撰写关于Amazon Web Services(AWS)的信息和魅力。由于我喜欢技术历史,这次我总结了AWS服务发布的历史年表。 虽然AWS官方也通过“Whats New”发布了官方公告,但我一直希望能有一篇文章将公告日期、GA日期&…...

Leetcode 2824. 统计和小于目标的下标对数目
2824. 统计和小于目标的下标对数目 2824. 统计和小于目标的下标对数目 一、题目描述二、我的想法 一、题目描述 给你一个下标从 0 开始长度为 n 的整数数组 nums 和一个整数 target ,请你返回满足 0 < i < j < n 且 nums[i] nums[j] < target 的下标对…...

TCP服务器主动断开客户端
自定义消息函数 afx_msg LRESULT CbaseMFCprojectDlg::OnOnsocketbartender(WPARAM wParam, LPARAM lParam) WPARAM wParam:消息来源 res recv(wParam, cs, 65535, 0);获取这个客户端端口socket通道里面的信息长度为65535存放在cs里面 如果获取得到res0即是说明该客户端已经断…...
跟json.loads()区别详解)
接口自动化中json.dumps()跟json.loads()区别详解
接口自动化中对于参数处理经常会用到json.dumps()跟json.loads(),下面主要分享一下自己使用总结 1.主要区别 json.dumps() 用于将字典转换为字符串格式 json.loads()用于将字符串转换为字典格式 import jsondict1 {"name":"amy","gender":woma…...

计算机网络-配置双机三层互联(静态路由方式)
目录 交换机工作原理路由器工作原理路由信息表组成部分路由器发决策 ARP工作原理配置双机三层互联(静态路由方式) 交换机工作原理 MAC自学习过程 初始状态: 刚启动的交换机的MAC地址表是空的。 学习过程: 当交换机收到一个数据帧…...
常用的函数有哪些?)
ES(Elasticsearch)常用的函数有哪些?
【电子书大全】内含上千本顶级编程书籍,是程序员必备的电子书资源包,并且会不断地更新,助你在编程的道路上更上一层楼! 链接: https://pan.baidu.com/s/1yhPJ9LmS_z5TdgIgxs9NvQ?pwdyyds > 提取码: yyds Elasticsearch&#x…...

古吉拉特语TTS项目上线倒计时48小时!这份含11个合规性检查项的ElevenLabs交付清单请立刻保存
更多请点击: https://intelliparadigm.com 第一章:古吉拉特语TTS项目上线倒计时全景概览 古吉拉特语(Gujarati)作为印度西部广泛使用的官方语言,拥有超过 5500 万母语使用者,但其高质量、低延迟、可商用的…...

油猴脚本集成ChatGPT:从原理到实战的浏览器AI自动化指南
1. 项目概述:一个为油猴脚本注入ChatGPT能力的起点如果你是一名前端开发者,或者对浏览器自动化、网页增强有浓厚的兴趣,那么你一定听说过或者用过“油猴脚本”。它就像给你的浏览器装上了一套瑞士军刀,可以自定义网页的样式、功能…...

不止是编解码:深入VPU硬件层,看BPU如何扛起运动估计与RDO的计算重担
从晶体管到比特流:揭秘VPU中BPU如何用硬件加速视频编解码 当你在4K屏幕上观看一场足球比赛直播时,画面中运动员的每个动作都流畅自然,这背后是每秒数千次的运动预测与补偿计算。传统CPU处理这类任务会瞬间过载,而专用视频处理单元…...

Umami MCP服务器:连接网站分析与AI工作流的标准化桥梁
1. 项目概述:一个为Umami量身定制的MCP服务器如果你正在使用Umami这个开源的网站分析工具,并且希望它能与你日常开发工作流中的其他工具(比如代码编辑器、CLI工具、自动化脚本)更紧密地结合,那么Macawls/umami-mcp-ser…...

基于WebSocket的企业微信AI助手部署与调优实战
1. 项目概述:一个开箱即用的企业微信AI助手搭建方案最近在折腾如何把Claude Code这个强大的AI编程助手无缝集成到团队日常沟通里,试过一些方案,要么需要公网服务器搞回调配置,要么部署起来一堆依赖让人头疼。直到发现了这个叫Claw…...

复杂园区管控难?无感跨镜追踪打造全流程动态溯源方案
复杂园区管控难?无感跨镜追踪打造全流程动态溯源方案产业园区、科创园区、物流园区、化工园区等复杂场景,普遍存在点位分散、人员车流密集、动线繁杂、盲区死角多、安防设备数据割裂等管控难题。传统园区管理模式依赖人工巡检、单点监控查看、被动事后追…...

3分钟掌握Ofd2Pdf:轻松解决OFD转PDF的格式兼容难题
3分钟掌握Ofd2Pdf:轻松解决OFD转PDF的格式兼容难题 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf Ofd2Pdf是一款专为中文用户设计的开源工具,能够高效地将OFD格式文件转换为通…...

2010-2024年省级农村居⺠消费价格指数
本数据为国家统计局编制的官方统计数据,具体编制方法参考国家统计局CPI调查方案及《中国统计年鉴》。农村居民消费价格指数(Consumer Price Index for Rural Residents,简称农村CPI)是综合反映农村居民家庭所购买的生活消费品价格…...

Cyclops:基于Helm的可视化Kubernetes部署平台实战指南
1. 项目概述:为什么我们需要一个“开发者友好”的Kubernetes界面?如果你和我一样,在云原生领域摸爬滚打了几年,那你一定对Kubernetes又爱又恨。爱的是它强大的编排能力和生态,恨的是那堆让人眼花缭乱的YAML文件。每次要…...

5分钟掌握AI图像分层:layerdivider智能图像处理实战指南
5分钟掌握AI图像分层:layerdivider智能图像处理实战指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 还在为复杂的图像分层工作而烦恼吗&a…...