PyTorch学习(1)
PyTorch学习(1)
CIFAR-10数据集-图像分类
数据集来源是官方提供的:
torchvision.datasets.CIFAR10()
共有十类物品,需要用CNN实现图像分类问题。
代码如下:(CIFAR_10_Classifier_Self_1.py)
import torch
import torchvision
from torch import optim
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import transforms
import matplotlib as plttransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)train_set = torchvision.datasets.CIFAR10(root='./CIFAR_10', train=True, transform=transform,download=True)
test_set = torchvision.datasets.CIFAR10(root='./CIFAR_10', train=False, transform=transform,download=True)train_loader = torch.utils.data.DataLoader(dataset=train_set, batch_size=4, shuffle=True) # shuffle: 打乱数据集顺序
test_loader = torch.utils.data.DataLoader(dataset=test_set, batch_size=4, shuffle=True)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # CIFAR-10 targetsclass MyNet(nn.Module):def __init__(self):super().__init__() # 初始化父类self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5)self.pool = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)self.fc1 = nn.Linear(in_features=16*5*5, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=10)def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # 卷积层后面通常接非线性变换x = self.pool(F.relu(self.conv2(x)))x = torch.flatten(x, 1)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = MyNet()criterion = nn.CrossEntropyLoss()
# optimizer: 优化器 SGD: 随机梯度下降
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)for epoch in range(2): # 训练进行两个epoch,每个epoch都代表一次完整的数据集遍历running_loss = 0.0for i, data in enumerate(train_loader, 0): # 遍历数据加载器(DataLoader)inputs, labels = dataoptimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 2000 == 1999:print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')running_loss = 0.0
print('Finished Training')# save
PATH = './cifar_net.pth'
torch.save(net, PATH)
运行结果:
C:\Users\dell\anaconda3\envs\pytorch\python.exe C:\Users\dell\Desktop\2024Summer\project1\learn_pytorch\pythonProject3\CIFAR_10_Classifier_Self_1.py
Files already downloaded and verified
Files already downloaded and verified
[1, 2000] loss: 2.208
[1, 4000] loss: 1.849
[1, 6000] loss: 1.681
[1, 8000] loss: 1.569
[1, 10000] loss: 1.523
[1, 12000] loss: 1.477
[2, 2000] loss: 1.395
[2, 4000] loss: 1.373
[2, 6000] loss: 1.360
[2, 8000] loss: 1.306
[2, 10000] loss: 1.325
[2, 12000] loss: 1.297
Finished TrainingProcess finished with exit code 0
把上面程序中的epoch循环次数改为10,并运行下列程序:(CIFAR_10_Classifier_Self_2.py)
import torch
from CIFAR_10_Classifier_Self_1 import MyNet
import torchvision.transforms as transforms
from PIL import Imagenet = MyNet()
PATH = './cifar_net.pth'
net.load_state_dict(torch.load(PATH))
net.eval()transform = transforms.Compose([transforms.Resize((32, 32)), # 输入不符合网络要求时,会报错transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# read image
def image_loader(image_name):image = Image.open(image_name)image = transform(image).unsqueeze(0) # 在tensor外面套一层中括号[]return imagedef classify_image(image_path):image = image_loader(image_path)outputs = net(image)_, predicted = torch.max(outputs, 1)return predicted.item()image_path = './images/ALPINA B3.jpg'
predicted_class = classify_image(image_path)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
print('Predicted Class:', classes[predicted_class])
对于输入图像:(ALPINA B3.jpg)

运行结果如下:
C:\Users\dell\anaconda3\envs\pytorch\python.exe C:\Users\dell\Desktop\2024Summer\project1\learn_pytorch\pythonProject3\CIFAR_10_Classifier_Self_2.py
Files already downloaded and verified
Files already downloaded and verified
[1, 2000] loss: 2.227
[1, 4000] loss: 1.900
[1, 6000] loss: 1.696
[1, 8000] loss: 1.586
[1, 10000] loss: 1.518
[1, 12000] loss: 1.440
[2, 2000] loss: 1.386
[2, 4000] loss: 1.351
[2, 6000] loss: 1.342
[2, 8000] loss: 1.312
[2, 10000] loss: 1.293
[2, 12000] loss: 1.246
[3, 2000] loss: 1.194
[3, 4000] loss: 1.199
[3, 6000] loss: 1.180
[3, 8000] loss: 1.175
[3, 10000] loss: 1.150
[3, 12000] loss: 1.154
[4, 2000] loss: 1.070
[4, 4000] loss: 1.088
[4, 6000] loss: 1.099
[4, 8000] loss: 1.069
[4, 10000] loss: 1.101
[4, 12000] loss: 1.082
[5, 2000] loss: 0.988
[5, 4000] loss: 1.013
[5, 6000] loss: 1.024
[5, 8000] loss: 1.040
[5, 10000] loss: 1.033
[5, 12000] loss: 1.045
[6, 2000] loss: 0.944
[6, 4000] loss: 0.957
[6, 6000] loss: 0.978
[6, 8000] loss: 0.990
[6, 10000] loss: 0.976
[6, 12000] loss: 0.998
[7, 2000] loss: 0.891
[7, 4000] loss: 0.931
[7, 6000] loss: 0.945
[7, 8000] loss: 0.934
[7, 10000] loss: 0.936
[7, 12000] loss: 0.936
[8, 2000] loss: 0.851
[8, 4000] loss: 0.898
[8, 6000] loss: 0.907
[8, 8000] loss: 0.898
[8, 10000] loss: 0.890
[8, 12000] loss: 0.911
[9, 2000] loss: 0.809
[9, 4000] loss: 0.851
[9, 6000] loss: 0.856
[9, 8000] loss: 0.869
[9, 10000] loss: 0.888
[9, 12000] loss: 0.903
[10, 2000] loss: 0.796
[10, 4000] loss: 0.812
[10, 6000] loss: 0.825
[10, 8000] loss: 0.857
[10, 10000] loss: 0.865
[10, 12000] loss: 0.862
Finished Training
Predicted Class: carProcess finished with exit code 0
可以看到,能够将图片正确分类。
(之前epoch为2时,错误地将图片分类成了ship,推测是网络参数因为训练次数少导致并非较佳值;epoch为10时也不敢保证一定能预测正确)
MNIST手写数字识别(LeNet)
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as Ftransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# Fetch the dataset
training_set = datasets.MNIST(root='./minst', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=training_set, batch_size=64, shuffle=True)test_set = datasets.MNIST(root='./minst', train=False, transform=transform, download=True)
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True)# show the dataset *
fig = plt.figure()
for i in range(12):plt.subplot(3, 4, i+1) # 第一个参数代表子图的行数,第二个参数代表该行图像的列数,第三个参数代表每行的第几个图像plt.tight_layout()plt.imshow(training_set.data[i], cmap='gray', interpolation='none')plt.title("Label: {}".format(training_set.targets[i]))plt.xticks([])plt.yticks([])
plt.show()class MyLeNet5(nn.Module):def __init__(self):super(MyLeNet5, self).__init__()self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)self.Sigmoid = nn.Sigmoid()self.s2 = nn.AvgPool2d(kernel_size=2)self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)self.s4 = nn.AvgPool2d(kernel_size=2)self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)self.flatten = nn.Flatten()self.f6 = nn.Linear(in_features=120, out_features=84)self.output = nn.Linear(in_features=84, out_features=10)def forward(self, x):x = self.Sigmoid(self.c1(x))x = self.s2(x)x = self.Sigmoid(self.c3(x))x = self.s4(x)x = self.c5(x)x = self.flatten(x)x = self.f6(x)x = self.output(x)return xmodel = MyLeNet5()# loss function & optimizer(参数优化)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01, momentum=0.5) # momentum: 冲量# train
def train(epoch): # epoch: 方便打印running_loss = 0.0running_total = 0running_correct = 0for batch_idx, data in enumerate(train_loader, 0): # 给train_loader元素编号,从0开始inputs, targets = data # inputs和targets是“数组”的形式optimizer.zero_grad() # 消除优化器中原有的梯度outputs = model(inputs)loss = criterion(outputs, targets) # 对比输出结果和“答案”loss.backward()optimizer.step() # 优化网络参数running_loss += loss.item() # .item(): 取出tensor中特定位置的具体元素值并返回该值(Tensor to int or float)_, predicted = torch.max(outputs.data, dim=1) # 找到每个样本预测概率最高的类别的标签值(即预测结果)# dim=0计算tensor中每列的最大值的索引,dim=1表示每行的最大值的索引running_total += inputs.shape[0] # .shape[0]: 读取矩阵第一维度的长度running_correct += (predicted == targets).sum().item()if batch_idx % 300 == 299:print('[%d, %5d]: loss: %.3f , acc: %.2f %%'% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))running_loss = 0.0running_total = 0running_correct = 0# test *
def test(epoch):correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()acc = correct / totalprint('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch + 1, 10, 100 * acc))return accacc_list_test = []
for epoch in range(10):train(epoch)acc_test = test(epoch)acc_list_test.append(acc_test)plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy on Test Set')
plt.show()
运行结果:

C:\Users\dell\anaconda3\envs\pytorch\python.exe C:\Users\dell\Desktop\2024Summer\project1\learn_pytorch\pythonProject3\MINST_1.py
[1, 300]: loss: 2.302 , acc: 11.04 %
[1, 600]: loss: 2.297 , acc: 11.97 %
[1, 900]: loss: 2.287 , acc: 15.71 %
[1 / 10]: Accuracy on test set: 26.9 %
[2, 300]: loss: 2.212 , acc: 27.77 %
[2, 600]: loss: 1.695 , acc: 50.16 %
[2, 900]: loss: 0.959 , acc: 71.32 %
[2 / 10]: Accuracy on test set: 77.0 %
[3, 300]: loss: 0.655 , acc: 79.78 %
[3, 600]: loss: 0.558 , acc: 82.46 %
[3, 900]: loss: 0.503 , acc: 84.27 %
[3 / 10]: Accuracy on test set: 86.3 %
[4, 300]: loss: 0.431 , acc: 86.77 %
[4, 600]: loss: 0.413 , acc: 87.64 %
[4, 900]: loss: 0.391 , acc: 88.16 %
[4 / 10]: Accuracy on test set: 89.3 %
[5, 300]: loss: 0.361 , acc: 89.16 %
[5, 600]: loss: 0.354 , acc: 89.33 %
[5, 900]: loss: 0.330 , acc: 89.92 %
[5 / 10]: Accuracy on test set: 90.4 %
[6, 300]: loss: 0.322 , acc: 90.38 %
[6, 600]: loss: 0.322 , acc: 90.20 %
[6, 900]: loss: 0.306 , acc: 90.59 %
[6 / 10]: Accuracy on test set: 91.5 %
[7, 300]: loss: 0.296 , acc: 90.87 %
[7, 600]: loss: 0.293 , acc: 91.23 %
[7, 900]: loss: 0.290 , acc: 91.17 %
[7 / 10]: Accuracy on test set: 92.1 %
[8, 300]: loss: 0.279 , acc: 91.47 %
[8, 600]: loss: 0.274 , acc: 91.71 %
[8, 900]: loss: 0.263 , acc: 92.03 %
[8 / 10]: Accuracy on test set: 92.6 %
[9, 300]: loss: 0.252 , acc: 92.34 %
[9, 600]: loss: 0.253 , acc: 92.16 %
[9, 900]: loss: 0.250 , acc: 92.61 %
[9 / 10]: Accuracy on test set: 93.3 %
[10, 300]: loss: 0.240 , acc: 92.69 %
[10, 600]: loss: 0.230 , acc: 93.27 %
[10, 900]: loss: 0.230 , acc: 93.03 %
[10 / 10]: Accuracy on test set: 93.6 %

问题区
import torchvision 和 from torchvision import * 有什么区别?
import torchvision # 使用transforms模块
transform = torchvision.transforms.Compose([...])
from torchvision import * # 直接使用transforms模块(如果torchvision中有这样的公开导入)
# 注意:实际上,torchvision不会将所有内容都直接暴露出来,这里只是为了说明
transform = Compose([...])
然而,第二种方法可能会出现命名冲突的问题。同时,并非所有内容都会被采用第二种方法读入,以_开头的“私有”名称通常不会被导入。
因此,推荐使用 import torchvision 的方式。
DataLoader返回的是啥?为什么有时候要在外面套一个“enumerate()”?
返回值是一个实现了__iter__的对象,可以使用for循环进行迭代,或者转换成迭代器取第一条batch数据查看。
# train
def train(epoch):...for batch_idx, data in enumerate(train_loader, 0):...
在上面这段代码中,需要在train_loader外面套个enumerate的原因是:能够给train_loader加上编号,变成“batch_idx”。(这里是方便打印训练结果)
Python enumerate()函数使用举例:
>>> seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 two
2 three
torch.max()的作用?
用法如下:
import torchoutput = torch.tensor([[1, 2, 3], [3, 4, 5]])
predict = torch.max(output, dim=0) # dim=0: 取每一列的最大值
print(predict)
predict = torch.max(output, dim=1) # dim=1: 取每一行的最大值
print(predict)
输出:
torch.return_types.max(
values=tensor([3, 4, 5]),
indices=tensor([1, 1, 1]))torch.return_types.max(
values=tensor([3, 5]),
indices=tensor([2, 2]))
indices表示从0开始的下标。
_, predicted = torch.max(outputs.data, dim=1) 这里的下划线的作用是?
下划线表示一个占位符,表示该值被有意地忽略。
相关文章:
PyTorch学习(1)
PyTorch学习(1) CIFAR-10数据集-图像分类 数据集来源是官方提供的: torchvision.datasets.CIFAR10()共有十类物品,需要用CNN实现图像分类问题。 代码如下:(CIFAR_10_Classifier_Self_1.py) import torch import t…...

三思而后行:计算机行业的决策智慧
在计算机行业,"三思而后行"这一原则显得尤为重要。在这个快速发展、技术不断更新换代的领域,每一个决策都可能对项目的成功与否产生深远的影响。以下是一篇关于在计算机行业中三思重要性的文章。 三思而后行:计算机行业的决策智慧 …...

Linux--Socket编程UDP
前文:Socket套接字编程 UDP协议特点 无连接:UDP在发送数据之前不需要建立连接,减少了开销和发送数据之前的时延。尽最大努力交付:UDP不保证可靠交付,主机不需要维持复杂的连接状态表。面向报文:UDP对应用层…...

《javaEE篇》--单例模式详解
目录 单例模式 饿汉模式 懒汉模式 懒汉模式(优化) 指令重排序 总结 单例模式 单例模式属于一种设计模式,设计模式就好比是一种固定代码套路类似于棋谱,是由前人总结并且记录下来我们可以直接使用的代码设计思路。 单例模式就是,在有…...

Java核心 - Lambda表达式详解与应用示例
作者:逍遥Sean 简介:一个主修Java的Web网站\游戏服务器后端开发者 主页:https://blog.csdn.net/Ureliable 觉得博主文章不错的话,可以三连支持一下~ 如有疑问和建议,请私信或评论留言! 前言 Lambda表达式是…...

算法通关:006_1二分查找
二分查找 查找一个数组里面是否存在num主要代码运行结果 详细写法自动生成数组和num,利用对数器查看二分代码是否正确 查找一个数组里面是否存在num 主要代码 /*** Author: ggdpzhk* CreateTime: 2024-07-27*/ public class cg {//二分查找public static boolean …...

总结一些vue3小知识3
总结一些vue3小知识1:http://t.csdnimg.cn/C5vER 总结一些vue3小知识2:http://t.csdnimg.cn/sscid 1.限制时间选择器只能选择后面的日期 说明:disabled-date属性是一个用来判断该日期是否被禁用的函数,接受一个 Date 对象作为参…...

JAVAWeb实战(前端篇)
项目实战一 0.项目结构 1.创建vue3项目,并导入所需的依赖 npm install vue-router npm install axios npm install pinia npm install vue 2.定义路由,axios,pinia相关的对象 文件(.js) 2.1路由(.js) import {cre…...

axios请求大全
本文讲解axios封装方式以及针对各种后台接口的请求方式 axios的介绍和基础配置可以看这个文档: 起步 | Axios中文文档 | Axios中文网 axios的封装 axios封装的重点有三个,一是设置全局config,比如请求的基础路径,超时时间等,第二点是在每次…...

C# 简单的单元测试
文章目录 前言参考文档新建控制台项目新建测试项目添加引用添加测试方法测试结果(有错误)测试结果,通过正规的方法抛出异常 总结 前言 听说复杂的项目最好都要单元测试一下。我这里也试试单元测试这个功能。到时候调试起来也方便。 参考文档 C# 单元测试…...

Linux中Mysql5.7主从架构(一主多从)配置教程
🏡作者主页:点击! 🐧Linux基础知识(初学):点击! 🐧Linux高级管理防护和群集专栏:点击! 🔐Linux中firewalld防火墙:点击! ⏰️创作…...
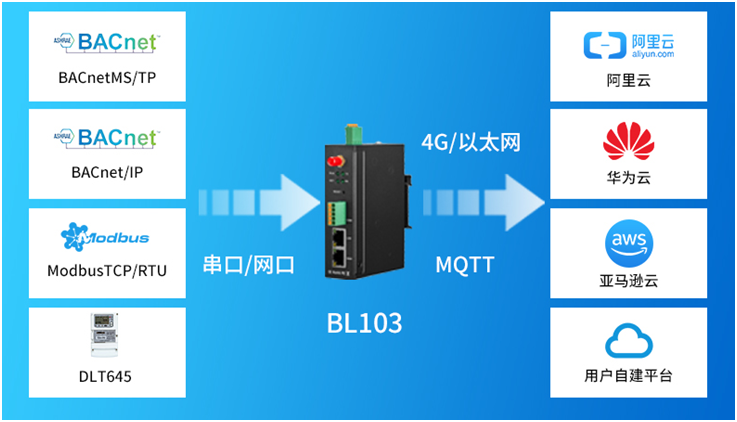
BACnet物联网关BL103:Modbus协议转BACnet/MSTP
随着物联网技术在楼宇自动化与暖通控制系统中的迅猛发展,构建一种既经济高效又高度可靠的协议转换物联网关成为了不可或缺的核心硬件组件。在此背景下,我们钡铼特别推荐一款主流的BAS(楼宇自动化系统)与BACnet物联网关——BL103&a…...

Go 语言条件变量 Cond
1.Cond 的使用方法 Go 标准库提供 Cond 同步原语的目的是为等待/通知场景下的并发操作提供支持。Cond 通常用于等待某个条件的一组 goroutine,当条件变为 true 时,其中一个或者所有的 goroutine 会被唤醒执行。 Cond 与某个条件相关,这个条件需要一组 goroutine 协作达到。当这…...

PostgreSQL 中如何重置序列值:将自增 ID 设定为特定值开始
我是从excel中将数据导入,然后再通过sql插入数据,就报错。 需要设置自增ID开始值 1、确定序列名称: 首先,需要找到与的增字段相关的序列名称。假设表名是 my_table 和自增字段是 id,可以使用以下查询来获取序列名称…...

Unity 之 【Android Unity 共享纹理】之 Android 共享图片给 Unity 显示
Unity 之 【Android Unity 共享纹理】之 Android 共享图片给 Unity 显示 目录 Unity 之 【Android Unity 共享纹理】之 Android 共享图片给 Unity 显示 一、简单介绍 二、共享纹理 1、共享纹理的原理 2、共享纹理涉及到的关键知识点 3、什么可以实现共享 不能实现共享…...

Go语言的数据结构
数据结构 数组 支持多维数组,属于值类型,支持range遍历 例子:随机生成长度为10整数数组 package main import ("fmt""math/rand" ) // 赋值 随机获取100以内的整数 func RandomArrays() {var array [10]int //声明var…...

python_在sqlite中创建表并写入表头
python_在sqlite中创建表并写入表头 import sqlite3def write_title_to_sqlite(tableName,titleList,dataTypeGroupsList,database_path):conn sqlite3.connect(database_path)# 创建游标cursor conn.cursor()#MEMO 长文本#create_table_bodycreate_table_body "序号 …...

1.c#(winform)编程环境安装
目录 安装vs创建应用帮助查看器安装与使用( msdn) 安装vs 安装什么版本看个人心情,或者公司开发需求需要 而本栏全程使用vs2022进行开发c#,着重讲解winform桌面应用开发 使用***.net framework***开发 那先去官网安装企业版的vs…...

图中的最短环
2608. 图中的最短环 现有一个含 n 个顶点的 双向 图,每个顶点按从 0 到 n - 1 标记。图中的边由二维整数数组 edges 表示,其中 edges[i] [ui, vi] 表示顶点 ui 和 vi 之间存在一条边。每对顶点最多通过一条边连接,并且不存在与自身相连的顶…...

安装依赖 npm install idealTree:lib: sill idealTree buildDeps 卡着不动
我一直怀疑是网络问题,因为等了很久也能安装成功,就是时间比较长,直到现在完全受不了了,决定好好整治下这个问题! 1、执行命令 npm config get userconfig 查看配置文件所在位置,将其删除。 2、执行 n…...

为Claude Code寻找稳定替代方案,Taotoken接入配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code寻找稳定替代方案,Taotoken接入配置指南 当开发者依赖Claude Code这类编程助手工具进行日常开发时&#…...

Claude API预算与性能优化实战:四层策略降本增效
1. 项目概述:一个为Claude设计的预算与性能优化技能 最近在折腾Claude API的时候,发现了一个挺有意思的开源项目,叫 budget_and_performance_optimization_claude_skill 。简单来说,这是一个专门为Claude(特别是Clau…...
)
手把手教你用STM32F103驱动DS3231高精度时钟模块(附完整源码与避坑指南)
手把手教你用STM32F103驱动DS3231高精度时钟模块(附完整源码与避坑指南) 1. 硬件准备与连接 DS3231作为一款高精度实时时钟模块,其内部集成了温度补偿晶体振荡器(TCXO),在-40C到85C范围内精度可达2ppm。与STM32F103的硬件连接主…...

3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具
3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk屏幕画笔工具是一款专为Windows用户设计的实时…...

基于MCP协议构建AI智能体记忆系统:mnemo-mcp实战指南
1. 项目概述:一个为AI记忆而生的开源工具最近在折腾AI应用开发,特别是围绕大语言模型(LLM)构建智能体(Agent)时,一个绕不开的痛点就是“记忆”。模型本身没有持久化记忆,每次对话都是…...
LunaTranslator:打破语言壁垒,让视觉小说触手可及
LunaTranslator:打破语言壁垒,让视觉小说触手可及 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator 还在为日文、英文的视觉小说而烦恼吗࿱…...

别浪费了STM32F103C8T6的PA13和PA14!SWD下载后,教你一键解锁这两个GPIO
解锁STM32F103C8T6的PA13/PA14引脚:从SWD调试到GPIO复用的实战指南 刚拿到STM32F103C8T6核心板时,很多开发者会对着有限的引脚发愁——尤其是那些标着"SWDIO"和"SWCLK"的PA13/PA14引脚。难道这两个引脚只能永远被调试接口占用&#…...

大语言模型角色扮演技术:从原理到实践的完整指南
1. 项目概述:当大语言模型学会“扮演”角色最近在GitHub上看到一个挺有意思的项目,叫“awesome-llm-role-playing-with-persona”。光看名字,你大概能猜到它和大型语言模型以及角色扮演有关。简单来说,这个项目整理了一个资源列表…...

AppleRa1n终极指南:3步免费绕过iOS 15-16激活锁限制
AppleRa1n终极指南:3步免费绕过iOS 15-16激活锁限制 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否正为忘记Apple ID密码而无法使用自己的iPhone而烦恼?或者购买的二手苹…...

英雄联盟自动化工具终极指南:3分钟学会用LeagueAkari提升游戏效率
英雄联盟自动化工具终极指南:3分钟学会用LeagueAkari提升游戏效率 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在排位赛…...