【AI大模型】 企业级向量数据库的选择与实战
前言
ChatGPT4相比于ChatGPT3.5,有着诸多不可比拟的优势,比如图片生成、图片内容解析、GPTS开发、更智能的语言理解能力等,但是在国内使用GPT4存在网络及充值障碍等问题,如果您对ChatGPT4.0感兴趣,可以私信博主为您解决账号和环境问题。同时,如果您有一些AI技术应用的需要,也欢迎私信博主,我们聊一聊思路和解决方案,能为您解决问题,是我的荣幸!!
引言
随着人工智能和机器学习技术的不断发展,向量数据库在处理高维数据和相似性搜索中扮演着越来越重要的角色。本文将介绍三种主流的向量数据库:Milvus、Faiss 和 Annoy,探讨它们的安装、配置与使用,并结合实际应用场景,提供具体的代码示例和性能优化技巧,帮助企业选择合适的向量数据库解决方案。
一、Milvus的安装、配置与使用
1.1 Milvus简介
Milvus 是一款开源的向量数据库,专为高效的相似性搜索和高维数据分析设计。它支持多种索引类型,包括 IVF、HNSW 和 ANNOY,能够处理数十亿条向量数据。Milvus 还具有高可扩展性和高可用性,适合企业级应用。
1.2 Milvus的安装
Milvus 提供了多种安装方式,包括 Docker、Helm 和源码安装。下面以 Docker 安装为例。
1.2.1 环境准备
确保你的系统已经安装了 Docker 和 Docker Compose。可以通过以下命令检查:
docker --version
docker-compose --version1.2.2 下载 Milvus Docker 镜像
使用 Docker Compose 文件来启动 Milvus。首先,创建一个目录并进入该目录:
mkdir milvus-docker && cd milvus-docker
创建一个名为 docker-compose.yml 的文件,内容如下:
version: '3.5'
services:etcd:image: quay.io/coreos/etcd:v3.4.3container_name: milvus_etcdports:- "2379:2379"- "2380:2380"command: etcd -advertise-client-urls http://0.0.0.0:2379 --listen-client-urls http://0.0.0.0:2379minio:image: minio/minio:RELEASE.2020-12-03T00-03-10Zcontainer_name: milvus_minioenvironment:MINIO_ACCESS_KEY: "minioadmin"MINIO_SECRET_KEY: "minioadmin"command: server /dataports:- "9000:9000"milvus:image: milvusdb/milvus:v1.1.0-cpu-d030521-2e559ccontainer_name: milvus_cpuports:- "19530:19530"volumes:- /var/lib/milvus/db:/var/lib/milvus/db- /var/lib/milvus/conf:/var/lib/milvus/conf- /var/lib/milvus/logs:/var/lib/milvus/logs- /var/lib/milvus/wal:/var/lib/milvus/walcommand: ["milvus", "run"]
启动 Milvus 服务:
docker-compose up -d1.3 Milvus的配置
Milvus 的配置文件位于 /var/lib/milvus/conf 目录下,主要配置文件为 server_config.yaml。你可以通过修改此文件来调整 Milvus 的参数设置,例如内存限制、日志级别等。
1.4 Milvus的使用
1.4.1 Python SDK 安装
Milvus 提供了多种客户端 SDK,这里以 Python SDK 为例。首先安装 Milvus 的 Python SDK:
pip install pymilvus1.4.2 创建和管理向量集合
下面是一个简单的例子,展示如何使用 Milvus 创建一个向量集合并插入数据:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection# 连接 Milvus 服务
connections.connect("default", host="localhost", port="19530")# 定义字段
fields = [FieldSchema(name="ID", dtype=DataType.INT64, is_primary=True),FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)
]# 定义集合模式
schema = CollectionSchema(fields, "test_collection")# 创建集合
collection = Collection("test_collection", schema)# 插入数据
import numpy as npvectors = np.random.random((10, 128)).astype(np.float32)
ids = [i for i in range(10)]collection.insert([ids, vectors])# 检索数据
search_vectors = np.random.random((1, 128)).astype(np.float32)
results = collection.search(search_vectors, "vector", params={"nprobe": 10}, limit=5)
for result in results:print(result)
以上代码展示了如何连接 Milvus 服务、创建向量集合、插入数据以及进行简单的向量检索。
二、Faiss的性能优化与实践
2.1 Faiss简介
Faiss 是由 Facebook AI Research 开发的一款高效相似性搜索库,专为处理大型向量集合而设计。Faiss 提供了多种索引类型和优化算法,支持 CPU 和 GPU 加速,适用于需要高性能向量搜索的应用场景。
2.2 Faiss的安装
Faiss 提供了多种安装方式,包括通过 pip 安装和源码编译。这里以 pip 安装为例:
pip install faiss-cpu
# 如果有 GPU 支持
# pip install faiss-gpu
2.3 Faiss的使用
2.3.1 创建索引并插入数据
下面是一个简单的例子,展示如何使用 Faiss 创建一个索引并插入数据:
import numpy as np
import faiss# 生成随机向量数据
d = 128 # 向量维度
nb = 10000 # 向量数量
np.random.seed(1234)
data = np.random.random((nb, d)).astype('float32')# 创建索引
index = faiss.IndexFlatL2(d)# 插入数据
index.add(data)# 检索数据
nq = 5 # 查询数量
xq = np.random.random((nq, d)).astype('float32')
k = 4 # 返回前 k 个最近邻
D, I = index.search(xq, k)
print(I)
2.4 Faiss的性能优化
2.4.1 使用 GPU 加速
如果你的系统支持 GPU,可以使用 GPU 版本的 Faiss 来提高检索速度。首先,安装 faiss-gpu:
pip install faiss-gpu然后,修改索引创建代码以使用 GPU:
# 创建 GPU 资源
res = faiss.StandardGpuResources()# 将索引移至 GPU
gpu_index = faiss.index_cpu_to_gpu(res, 0, index)# 插入数据
gpu_index.add(data)# 检索数据
D, I = gpu_index.search(xq, k)
print(I)
2.4.2 使用分层索引
Faiss 提供了多种分层索引结构,如 IVF(倒排文件)和 HNSW(层次化的近似图)。下面是使用 IVF 索引的示例:
nlist = 100 # 聚类中心数
quantizer = faiss.IndexFlatL2(d)
index_ivf = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)# 训练索引
index_ivf.train(data)# 插入数据
index_ivf.add(data)# 检索数据
index_ivf.nprobe = 10 # 查询时使用的聚类中心数
D, I = index_ivf.search(xq, k)
print(I)
通过这些优化措施,Faiss 可以在大规模向量数据检索中提供高效的性能。
三、Annoy在资源受限环境下的应用
3.1 Annoy简介
Annoy (Approximate Nearest Neighbors Oh Yeah) 是由 Spotify 开发的一款近似最近邻搜索库,特别适合在资源受限的环境中使用。Annoy 使用随机投影树(Random Projection Trees)实现高效的相似性搜索,内存和计算资源占用较低。
3.2 Annoy的安装
Annoy 可以通过 pip 安装:
pip install annoy
3.3 Annoy的使用
3.3.1 创建索引并插入数据
下面是一个简单的例子,展示如何使用 Annoy 创建一个索引并插入数据:
from annoy import AnnoyIndex
import numpy as np# 生成随机向量数据
f = 128 # 向量维度
t = AnnoyIndex(f, 'euclidean')# 插入数据
for i in range(10000):v = np.random.random(f).astype('float32')t.add_item(i, v)# 构建索引树
t.build(10) # 10 棵树# 保存索引
t.save('test.ann')# 加载索引
u = AnnoyIndex(f, 'euclidean')
u.load('test.ann') # 注意:索引文件必须在同一维度# 检索数据
index = 0
k = 5 # 返回前 k 个最近邻
print(u.get_nns_by_item(index, k))
3.4 Annoy的资源管理
Annoy 的设计非常适合资源受限的环境。它的内存使用效率很高,并且支持将索引持久化到磁盘,以减少内存占用。
3.5 Annoy在实际应用中的案例
Spotify 使用 Annoy 实现音乐推荐系统,通过用户听歌记录和音乐特征向量进行相似性搜索,提供个性化推荐。此外,Annoy 还广泛应用于图像搜索、文本相似性检测等领域,具有广泛的实用性。
相关文章:

【AI大模型】 企业级向量数据库的选择与实战
前言 ChatGPT4相比于ChatGPT3.5,有着诸多不可比拟的优势,比如图片生成、图片内容解析、GPTS开发、更智能的语言理解能力等,但是在国内使用GPT4存在网络及充值障碍等问题,如果您对ChatGPT4.0感兴趣,可以私信博主为您解决账号和环境…...

LangChain开发框架并学会对大型预训练模型进行微调(fine-tuning)
要掌握LangChain开发框架并学会对大型预训练模型进行微调(fine-tuning),你需要理解整个过程从数据准备到最终部署的各个环节。下面是这一流程的一个概览,并提供了一些关键步骤和技术点: 1. LangChain开发框架简介 La…...

VMware安装(有的时候启动就蓝屏建议换VM版本)
当你开始使用虚拟化技术来管理和运行多个操作系统时,VMware 是一个强大且广泛使用的选择。本篇博客将指导你如何安装 VMware Workstation Pro,这是一个功能强大的虚拟机软件,适用于个人和专业用户。 一、下载 VMware Workstation Pro 访问官网…...

AV1技术学习:Quantization
量化是对变换系数进行,并将量化索引熵编码。AV1的量化参数 QP 的取值范围是0 ~ 255。 一、Quantization Step Size 在给定的 QP 下,DC 系数的量化步长小于 AC 系数的量化步长。DC 系数和 AC 系数从 QP 到量化步长的映射如下图所示。当 QP 为 0 时&…...

vllm部署记录
1. pip安装 pip install vllm 下载模型在huggingface.co 注意在modelscope上的这个opt-125m好像不行了,我git不下来报错 启动服务 vllm serve opt-125m --model opt-125m --port 8888 第一个opt-125m是名字,可以在vllm支持的模型中查到,第二个是模型存放文件夹及其路径…...

HTML前端 盒模型及常见的布局 流式布局 弹性布局 网格布局
CSDN的文章没有“树状目录管理”,所以我在这里整理几篇相关的博客链接。 操作有些麻烦。 CSS 两种盒模型 box-sizing content-box 和 border-box 流式布局 flow layout 弹性布局 flex layout HTML CSS 网格布局 grid layout HTML CSS...
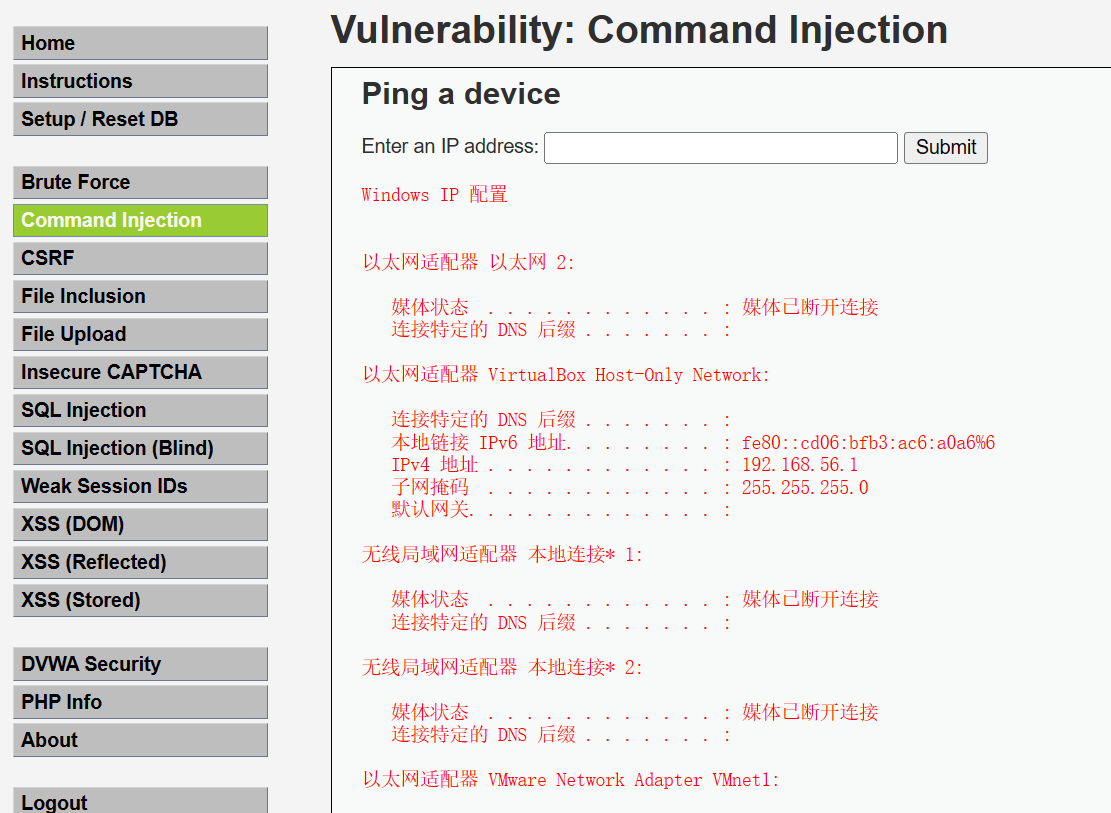
网络安全 DVWA通关指南 DVWA Command Injection(命令注入)
DVWA Command Injection(命令注入) 文章目录 DVWA Command Injection(命令注入)LowMediumHighImpossible Low 1、分析网页源代码 <?php// 当表单提交按钮(Submit)被触发时执行以下代码 if (isset($_P…...

VUE3学习第三篇:报错记录
1、在我整理好前端代码框架后,而且也启动好了对应的后台服务,访问页面,正常。 2、报错ReferenceError: defineModel is not defined 学到这里报错了 在vue网站的演练场,使用没问题 但是在我自己的代码里就出问题了 3、watchEffec…...
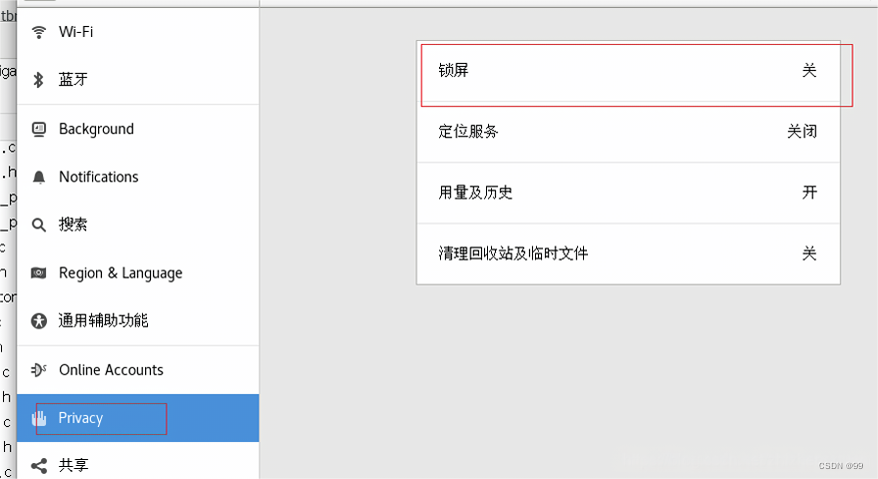
CentOS怎么关闭自动锁屏?
禁止自动锁屏 有时候几分钟不用Centos,系统就自动锁屏了,这是一种安全措施,防止别人趁你不在时使用你的系统。但对于大部分人而言,这是没有必要的,尤其是Centos虚拟机,里面没啥重要的东西,每次…...
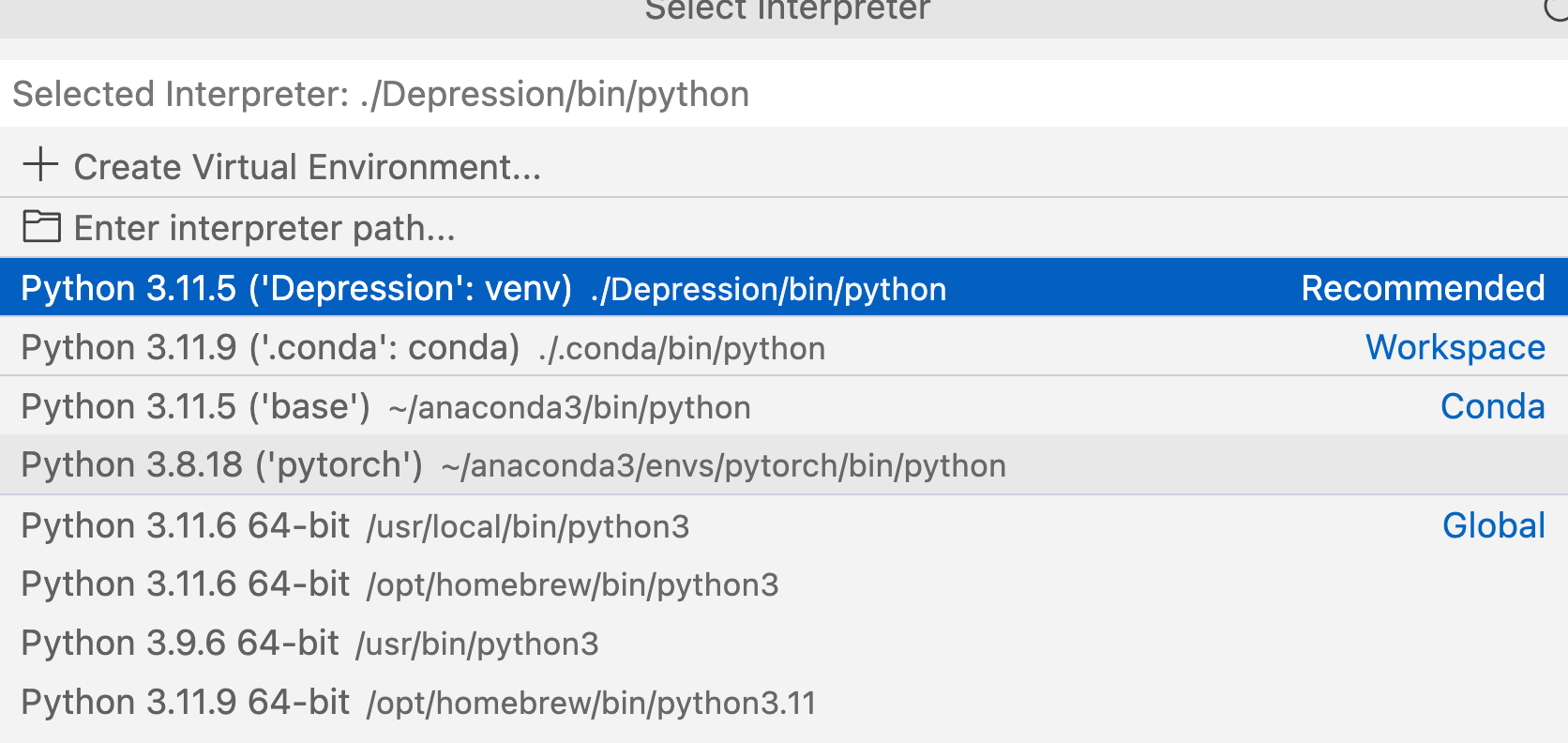
vscode 环境
这张截图显示的是在VS Code(Visual Studio Code)中选择Python解释器的界面。不同的Python解释器及其虚拟环境列出了可选项,用户可以根据需要选择合适的解释器来运行Python代码。以下是对截图中信息的详细解释: 解释器选择界面 当…...

浏览器自动化测试工具selenium——爬虫操作记录
selenium——是一款web自动化测试框架,其能模拟正常的用户操作,比如点击。但selenium并不是浏览器,没有执行js和解析html/css的能力,因此selenium需要和浏览器配合使用。 因为selenium可以模仿用户行为,因此selenium也…...

微信小程序配置访问服务器失败所发现的问题及解决方案
目录 事前现象问题1:问题现象:问题分析: 问题2:问题现象:问题分析:解决方案: 事后现象 事前现象 问题1: 问题现象: 在本地调试时,一切顺利,但一…...

javaEE(1)
一. Web开发概述 Web开发:指的是从网页中向后端程序发送请求,与后端程序进行交互 Web服务器:是一种软件,向浏览器等Web客户端提供文档等数据,实现数据共享,它是一个容器,是一个连接用户和程序之间的中间键 二. Web开发环境搭建 我们要实现前后端交互,首先需要中间键Web服务…...

极简Springboot+Mybatis-Plus+Vue零基础萌新都看得懂的分页查询(富含前后端项目案例)
目录 springboot配置相关 依赖配置 yaml配置 MySQL创建与使用 (可拿软件包项目系统) 创建数据库 创建数据表 mybatis-plus相关 Mapper配置 编辑 启动类放MapperScan 启动类中配置 添加config配置文件 Springboot编码 实体类 mapperc(Dao…...

IPython的Bash之舞:%%bash命令全解析
IPython的Bash之舞:%%bash命令全解析 IPython的%%bash魔术命令为Jupyter Notebook用户提供了一种在单元格中直接执行Bash脚本的能力。这个特性特别适用于需要在Notebook中运行系统命令或Bash特定功能的场景。本文将详细介绍如何在IPython中使用%%bash命令ÿ…...
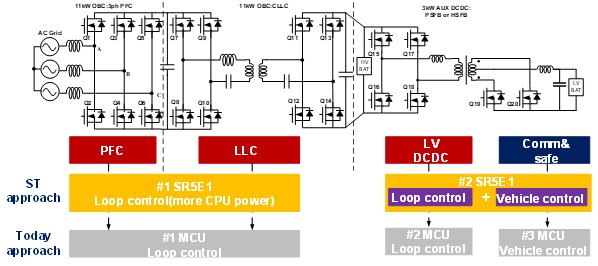
ST Stellar-E SR5E1 22KW OBC combo 3KW DC-DC汽车充电器解决方案
对于全球的环境保护意识抬头,全球的汽车产业慢慢步入电动化的时代,以减少碳排放。整车系统主要是由电池、电驱、电控的三电所构成,其中电池系统是整车的动力来源,而对电池充电的OBC系统更甚重要。一具高度安全性且高效的OBC系统&a…...

Postman中的A/B测试实践:优化API性能的科学方法
Postman中的A/B测试实践:优化API性能的科学方法 在API开发和测试过程中,A/B测试是一种验证新功能或变更效果的有效方法。通过比较两个或多个版本(例如A版本和B版本)的性能,可以科学地评估变更的影响。Postman作为API测…...

微信小程序支付流程
前端需要做的事情: 生成平台订单:前端调用接口,向后端传递购买的商品信息、收货人信息,(后端生成平台订单,返回订单编号)获取预付单信息:将订单编号发送给后端后,&#x…...

Istio 学习笔记
Istio 学习笔记 作者:王珂 邮箱:49186456qq.com 文章目录 Istio 学习笔记[TOC] 前言一、基本概念1.1 Istio定义 二、Istio的安装2.1 通过Istioctl安装2.2 通过Helm安装 三、Istio组件3.1 Gateway3.2 VirtulService3.2.1 route详解3.2.2 match详解3.2.3…...
—— 接口测试有没有测试出什么问题?)
测试面试宝典(三十三)—— 接口测试有没有测试出什么问题?
在之前的接口测试工作中,确实发现了一些问题。比如,在对某关键业务接口进行测试时,发现当输入的参数值超出正常范围时,接口没有按照预期返回错误提示,而是出现了系统崩溃的情况。 还有一次,在测试一个数据…...

热敏电阻测温实战:从原理到Arduino/CircuitPython代码实现
1. 项目概述:从电阻到温度的桥梁在嵌入式开发和电子DIY项目中,温度测量是一个极其常见的需求。无论是环境监测、设备状态反馈,还是简单的温控风扇,你都需要一个可靠的“温度计”。市面上有琳琅满目的温度传感器,从数字…...

Cyber Engine Tweaks终极指南:3步解锁赛博朋克2077的完整定制体验
Cyber Engine Tweaks终极指南:3步解锁赛博朋克2077的完整定制体验 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks 你是否想让《赛博朋克2077》运…...

UE5新手必看:给你的自定义Pawn加上碰撞,别再让它“穿墙”了!
UE5碰撞系统实战:从零构建防穿墙Pawn的完整指南 当你在UE5中第一次创建自定义Pawn时,最令人沮丧的莫过于看着自己精心设计的角色像幽灵一样穿过墙壁和障碍物。这种"穿模"现象不仅破坏游戏体验,更会导致后续游戏逻辑的全面崩溃。本文…...

数据投毒太多,尝试把资料搬进本地知识库
说实话,这几天没睡好。上周翻到一个新闻,看得我后背发凉——谷歌首次发现攻击者用AI开发“零日漏洞”攻击工具。不是概念验证,是真实案例。攻击者拿AI绕过双重认证,代码写得跟教科书似的,还带“幻觉”出来的CVSS评分。…...

数据流计算模型在边缘到云场景的优化实践
1. 数据流计算模型的演进与挑战数据流计算模型自诞生以来,已经成为分布式系统领域处理大规模数据的核心范式。这种模型通过将计算过程抽象为有向无环图(DAG),其中顶点代表数据处理算子,边代表数据流动路径,…...
)
今日算法(依旧二叉树)
class Solution { public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {//递归进行,加回溯过程if(rootq||rootp||rootNULL) return root;TreeNode*leftlowestCommonAncestor(root->left,p,q);TreeNode*rightlowestCommonAncestor…...

从零打造专属机械键盘:基于CircuitPython的USB HID输入设备实践
1. 项目概述:打造你的专属“一键”键盘如果你对市面上千篇一律的键盘感到厌倦,或者一直想亲手制作一个独一无二的输入设备,那么这个项目就是为你准备的。今天,我们不谈那些复杂的全尺寸客制化键盘,而是从一个精巧、有趣…...

低查重AI教材生成利器,AI写教材工具让你1周完成40万字书稿!
在撰写教材的过程中,总是难以避免“慢节奏”的所有坑。当框架和资料都已准备妥当时,却常常因为撰写内容而停滞不前——一句话反复斟酌半小时,仍觉得不够准确;章节间的衔接更是让人绞尽脑汁,找不到合适的表达方式&#…...

基于HPM5E00与LAN9252的EtherCAT从站开发板全流程实战
1. 项目概述:从零到一,打造专属的 EtherCAT 从站开发板 最近在工业自动化圈子里,EtherCAT 的热度一直居高不下。它那近乎实时的通讯性能、灵活的拓扑结构,让它在运动控制、机器人、高端数控机床等领域成了“香饽饽”。但很多开发者…...

本地部署Qwen大模型:从量化加载到性能优化的完整实践指南
1. 项目概述:从开源大模型到个人AI助手的跃迁最近在折腾本地部署大语言模型,发现了一个宝藏项目——QwenLM/Qwen。这可不是一个简单的模型仓库,而是一个由通义千问团队打造的开源大语言模型家族。简单来说,它让你能在自己的电脑或…...