基于深度学习的复杂策略学习
基于深度学习的复杂策略学习(Complex Strategy Learning)是通过深度学习技术,特别是强化学习和模仿学习,来开发和优化解决复杂任务的策略。这类技术广泛应用于自动驾驶、游戏AI、机器人控制和金融交易等领域。以下是对这一领域的系统介绍:
1. 任务和目标
复杂策略学习的主要任务和目标包括:
- 策略优化:开发高效的策略来解决复杂任务,例如导航、控制和决策等。
- 自适应学习:通过学习和适应环境变化,提升系统的智能化水平。
- 多目标优化:在多个目标之间进行权衡,找到最佳策略。
- 长时序依赖:处理具有长时序依赖性的任务,确保策略的长期有效性。
- 实时决策:在动态环境中进行实时决策,确保系统的响应速度和准确性。
2. 技术和方法
2.1 强化学习(Reinforcement Learning, RL)
强化学习是一种通过与环境交互来学习策略的技术,核心思想是通过试错法和奖励机制来优化策略。常用的强化学习算法包括:
- Q-learning:基于值函数的方法,通过更新状态-动作对的值来优化策略。
- 深度Q网络(DQN):将Q-learning与深度神经网络相结合,处理高维度的状态空间。
- 策略梯度方法(Policy Gradient Methods):直接优化策略,通过梯度提升策略的性能。
- REINFORCE:一种基本的策略梯度算法,通过采样轨迹来更新策略。
- 近端策略优化(PPO):一种稳定性更高的策略梯度算法,通过限制策略更新的幅度来提高训练效果。
- 演员-评论家方法(Actor-Critic Methods):结合值函数和策略优化的算法,通过同时更新策略和值函数来提升性能。
- 分层强化学习(Hierarchical Reinforcement Learning, HRL):将任务分解为多个子任务,通过学习子任务的策略来解决复杂任务。
2.2 模仿学习(Imitation Learning)
模仿学习通过学习专家的演示数据来开发策略,常用的方法包括:
- 行为克隆(Behavior Cloning, BC):通过监督学习直接模仿专家的行为。
- 逆强化学习(Inverse Reinforcement Learning, IRL):通过推断专家的奖励函数来优化策略。
- 生成对抗模仿学习(Generative Adversarial Imitation Learning, GAIL):结合生成对抗网络(GAN)和模仿学习,通过对抗训练来优化策略。
2.3 深度神经网络
深度神经网络在复杂策略学习中的应用主要包括:
- 卷积神经网络(CNN):用于处理图像和视频数据,提取高维特征。
- 循环神经网络(RNN):用于处理时间序列数据,捕捉长时序依赖。
- 长短期记忆网络(LSTM):一种特殊的RNN结构,擅长处理长序列数据。
- 变压器模型(Transformer):通过自注意力机制处理大规模数据,提高策略学习的效率和准确性。
3. 应用和评估
3.1 应用领域
基于深度学习的复杂策略学习在多个领域具有重要应用:
- 自动驾驶:开发自动驾驶车辆的导航和决策策略,提高驾驶安全性和效率。
- 游戏AI:开发智能游戏代理,提升游戏体验和挑战性。
- 机器人控制:优化机器人在复杂环境中的控制策略,提高任务完成的准确性和效率。
- 金融交易:开发高频交易策略,优化交易决策,提升投资收益。
- 智能家居:优化智能设备的控制策略,提高用户的生活质量。
3.2 评估指标
评估复杂策略学习系统性能的常用指标包括:
- 奖励值(Reward):衡量策略在任务中的表现,通过累计奖励值评估策略的效果。
- 成功率(Success Rate):衡量策略完成任务的成功率,评估策略的有效性。
- 学习效率(Learning Efficiency):衡量策略学习的速度和效率,通过收敛时间和样本效率评估。
- 鲁棒性(Robustness):衡量策略在不同环境和条件下的稳定性和适应性。
- 计算资源消耗(Resource Consumption):衡量策略学习和执行所需的计算资源,包括时间、内存和计算能力等。
4. 挑战和发展趋势
4.1 挑战
尽管基于深度学习的复杂策略学习取得了显著进展,但仍面临一些挑战:
- 高维度状态空间:处理高维度状态空间和动作空间,确保策略的高效性和准确性。
- 探索-利用权衡:在探索新策略和利用现有策略之间找到平衡,优化策略学习过程。
- 样本效率:提高策略学习的样本效率,减少所需的训练数据和时间。
- 多任务学习:在多任务环境中进行策略学习,提高策略的泛化能力和适应性。
- 安全性和可靠性:确保策略在实际应用中的安全性和可靠性,避免不良行为和决策。
4.2 发展趋势
- 多智能体强化学习(Multi-Agent Reinforcement Learning, MARL):研究多智能体环境中的策略学习,优化智能体之间的协作和竞争。
- 自监督学习(Self-Supervised Learning):通过自监督学习技术,提升策略学习的样本效率和泛化能力。
- 元学习(Meta-Learning):通过元学习技术,提升策略在新任务和新环境中的快速适应能力。
- 人机协作(Human-AI Collaboration):研究人机协作策略,优化智能系统与人类用户之间的交互和协作。
- 强化学习安全性(Safe Reinforcement Learning):研究强化学习的安全性,开发安全可靠的策略,确保实际应用中的安全性。
5. 未来发展方向
- 跨领域应用:将复杂策略学习技术应用于更多领域,如医疗诊断、环境保护和资源管理等。
- 融合多模态数据:结合视觉、听觉、触觉等多模态数据,提高策略学习的全面性和准确性。
- 可解释性研究:开发具有更高可解释性的策略学习模型,提升用户的信任和接受度。
- 高效计算平台:研究高效的计算平台和算法,加速策略学习和推理过程。
综上所述,基于深度学习的复杂策略学习在自动驾驶、游戏AI、机器人控制、金融交易和智能家居等领域具有广泛的应用前景,并且在高维度状态空间处理、探索-利用权衡、样本效率、多任务学习和安全性等方面面临重要挑战。通过多智能体强化学习、自监督学习、元学习、人机协作和安全性研究等新技术的引入,将进一步推动这一领域的发展和应用。
相关文章:

基于深度学习的复杂策略学习
基于深度学习的复杂策略学习(Complex Strategy Learning)是通过深度学习技术,特别是强化学习和模仿学习,来开发和优化解决复杂任务的策略。这类技术广泛应用于自动驾驶、游戏AI、机器人控制和金融交易等领域。以下是对这一领域的系…...
)
【Golang 面试 - 进阶题】每日 3 题(一)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...
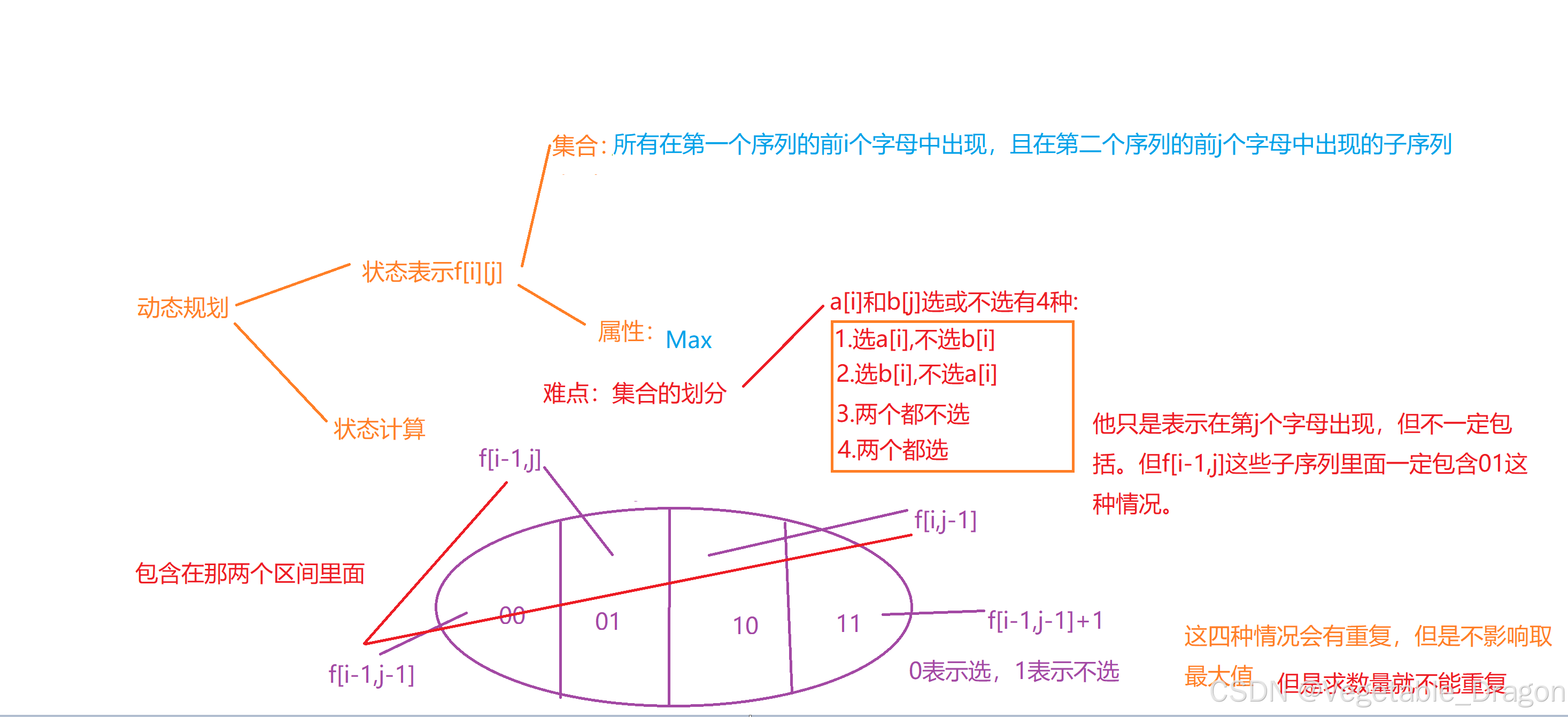
周报 Week 3:
补题链接: Week 3 DAY 1-CSDN博客 河南萌新联赛2024第(二)场:南阳理工学院-CSDN博客 Week 3 DAY 5:-CSDN博客 Week 3 DAY 6-CSDN博客 这周题单是动态规划——(背包问题,线性dp):…...

开源消息队列比较
目录 1. Apache Kafka 1.1安装步骤 1.1.1使用Docker安装 1.1.1手动安装 1.2 C#使用示例代码 1.2.1 安装Confluent.Kafka 1.2.2生产者代码示例 1.2.3消费者代码示例 1.3特点 1.4使用场景 2. RabbitMQ 2.1安装步骤 2.1.1使用Docker安装 2.1.2手动安装 2.2 C#使用示…...
【前端逆向】最佳JS反编译利器,原来就是chrome!
有时候需要反编译别人的 min.js。 比如简单改库、看看别人的 min,js 干了什么,有没有重复加载?此时就需要去反编译Javascript。 Vscode 里面有一些反编译插件,某某Beautify等等。但这些插件看人品,运气不好搞的话,反…...

微信小程序根据动态权限展示tabbar
微信小程序自定义 TabBar 后根据权限动态展示tabbar 在微信小程序开发中,自定义 TabBar 可以让应用更具灵活性和个性化。特别是在用户根据不同权限展示不同的 TabBar 内容时,正确的实现方法能够提升用户体验。本篇文章将分享如何使用事件总线实现权限变动时动态更新自定义 T…...
开源安全信息和事件管理(SIEM)平台OSSIM
简介 OSSIM,开源安全信息和事件管理(SIEM)产品,提供了经过验证的核心SIEM功能,包括事件收集、标准化和关联。 OSSIM作为一个开源平台,具有灵活性和可定制性高的优点,允许用户根据自己的特定需…...

【DP】01背包
算法-01背包 前置知识 DP 思路 01背包一般分为两种,不妨叫做价值01背包和判断01背包。 价值01背包 01背包问题是这样的一类问题:给定一个背包的容量 m m m 和 n n n 个物品,每个物品有重量 w w w 和价值 v v v,求不超过背…...

50、PHP 实现选择排序
题目: PHP 实现选择排序 描述: n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果:(1)初始状态:无序区为R[1…n],有序区为空。(2)第1趟排序在无序区R[1…n]中选出关键字最小的记录R[k],将…...

17.延迟队列
介绍 延迟队列,队列内部是有序的,延迟队列中的元素是希望在指定时间到了以后或之前取出和处理。 死信队列中,消息TTL过期的情况其实就是延迟队列。 使用场景 1.订单在十分钟内未支付则自动取消。 2.新创建的店铺,如果十天内没…...

KCache-go本地缓存,支持本地缓存过期、缓存过期自维护机制。
GitHub - kocor01/kcache: go 本地缓存解决方案,支持本地缓存过期、缓存过期自维护机制。 最近系统并发很高,单接口10W的 QPS,对 redis 压力很大,大量的热KEY导致 redis 分片CPU资源经常告警。计划用 go 本地缓存缓解 redis 的压…...

斯坦福UE4 C++课学习补充 14:UMG-优化血量条
文章目录 一、优化执行效率二、简单脉冲动画 一、优化执行效率 绑定事件需要每一帧检查绑定对象是否有变化,势必造成CPU资源的浪费,因此优化执行效率的思路是:UI组件不再自行每帧查询血量,而是让血量自己在发生变化的同时通知UI进…...

在生信分析中大家需要特别注意的事情
在生信分析中大家需要特别注意的事情 标准的软件使用和数据分析流程 1. 先看我的b站教学视频 2. 先从我的百度网盘把演示数据集下载下来,先把要运行的模块的演示数据集先运行一遍 3. 前两步都做完了,演示数据集也运行成功了,并且知道了软件…...

Java工厂模式详解:方法工厂模式与抽象工厂模式
Java工厂模式详解:方法工厂模式与抽象工厂模式 一、引言 在Java开发中,设计模式是解决常见软件设计问题的一种有效方式。工厂模式作为创建型设计模式的一种,提供了灵活的对象创建机制,有助于降低代码的耦合度,提高系…...

springSecurity学习之springSecurity用户单设备登录
用户只能单设备登录 有时候在同一个系统中,只允许一个用户在一个设备登录。 之前的登陆者被顶掉 将最大会话数设置为1就可以保证用户只能同时在一个设备上登录 Override protected void configure(HttpSecurity http) throws Exception {http..anyRequest().aut…...

微信小程序实现聊天界面,发送功能
.wxml <scroll-view scroll-y"true" style"height: {{windowHeight}}px;"><view wx:for"{{chatList}}" wx:for-index"index" wx:for-item"item" style"padding-top:{{index0?30:0}}rpx"><!-- 左…...

【强化学习的数学原理】课程笔记--5(值函数近似,策略梯度方法)
目录 值函数近似一个例子TD 算法的值函数近似形式Sarsa, Q-learning 的值函数近似形式Deep Q-learningexperience replay 策略梯度方法(Policy Gradient)Policy Gradient 的目标函数目标函数 1目标函数 2两种目标函数的同一性 Policy Gradient 目标函数的…...

前端Long类型精度丢失:后端处理策略
文章目录 精度丢失的具体原因解决方法1. 使用 JsonSerialize 和 ToStringSerializer2. 使用 JsonFormat 注解3. 全局配置解决方案 结论 开发商城管理系统的品牌管理界面时,发现一个问题,接口返回品牌Id和页面展示的品牌Id不一致,如接口返回的…...

C++ | Leetcode C++题解之第300题最长递增子序列
题目: 题解: class Solution { public:int lengthOfLIS(vector<int>& nums) {int len 1, n (int)nums.size();if (n 0) {return 0;}vector<int> d(n 1, 0);d[len] nums[0];for (int i 1; i < n; i) {if (nums[i] > d[len])…...
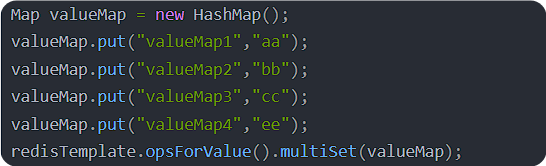
springboo 整合 redis
springBoot 整合 redis starter启动依赖。—包含自动装配类—完成相应的装配功能。 引入依赖 <!--引入了redis整合springboot 的依赖--> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis&…...
详解:如何让你的代码跑在不同的飞控板上(以STM32为例))
ArduPilot硬件抽象层(HAL)详解:如何让你的代码跑在不同的飞控板上(以STM32为例)
ArduPilot硬件抽象层深度解析:从STM32到多平台移植实战指南 引言:为什么HAL是飞控开发的核心枢纽 在无人机飞控开发领域,硬件平台的多样性一直是开发者面临的首要挑战。不同厂商的MCU架构、外设接口和操作系统差异,往往导致代码…...

自制AVR ISP批量编程器:从ZIF插座到AVRDUDE一键烧录全攻略
1. 项目概述:为什么你需要一个批量编程器?如果你玩过Arduino或者自己做过一些基于AVR单片机的小项目,那么对“烧录程序”这个步骤一定不陌生。通常,我们是用一根USB线,或者一个USBasp、USBtinyISP这样的小编程器&#…...

Linux内核模块管理:lsmod命令详解与实战应用
1. 项目概述:从“黑盒”到“白盒”,lsmod是你的系统模块探照灯如果你在Linux世界里待过一阵子,尤其是折腾过驱动、内核或者排查过一些稀奇古怪的系统问题,那你大概率听说过或者用过lsmod这个命令。乍一看,它的名字平平…...

广告投放ROI断崖式下滑?立即排查ElevenLabs这4个语音合成致命偏差,2小时内修复
更多请点击: https://intelliparadigm.com 第一章:广告投放ROI断崖式下滑的语音归因真相 当广告主发现iOS 17设备上语音搜索转化路径中归因丢失率高达68%,却仍在依赖传统点击归因(Click-Through Attribution)模型时&a…...

苹果砂不锈钢蜂窝板做出来真的和苹果店一样吗?来自广东优之彩!
当“苹果店质感”成为高级商业空间的隐形标尺,无数人追问:我们能用苹果砂不锈钢蜂窝板,复刻那种极致、均匀、充满科技感的哑光金属美学吗?答案是:可以。但前提是,你选择的不仅是材料,更是一套完…...

快速开发AI应用原型时Taotoken分钟级接入的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 快速开发AI应用原型时Taotoken分钟级接入的价值 在黑客松、内部创新日或产品早期原型开发阶段,时间是最宝贵的资源。开…...

Windows微信QQ防撤回终极指南:RevokeMsgPatcher完整使用教程
Windows微信QQ防撤回终极指南:RevokeMsgPatcher完整使用教程 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitc…...

最新英语作文批改APP测评 适合学生党写作提分的实用指南
一、当前英语作文批改工具的共性痛点我们团队做了5年英语作文批改领域的内容产出,前后调研过近20款市面上的主流工具,发现行业内的共性痛点其实一直没得到很好的解决:对学生来说,多数工具只能改表层语法错误,不会结合写…...

【困难】字符串匹配问题-Java:递归解法
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程大家好!欢迎来到我的网站! 人工智能被认为是一种拯救世界、终结世界的技术。毋庸置疑&#x…...

如何免费解锁Cursor AI Pro功能:终极三步激活指南
如何免费解锁Cursor AI Pro功能:终极三步激活指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial r…...