决策树与随机森林:比较与应用场景分析
决策树与随机森林:比较与应用场景分析
引言
决策树和随机森林是机器学习中广泛使用的两种算法,因其简单性和强大的功能而被广泛采用。决策树是一种树形结构的决策模型,易于理解和解释。随机森林则是通过集成多棵决策树来提高预测性能的模型。在本文中,我们将深入比较决策树与随机森林,探讨它们的工作原理、优缺点、应用场景,并通过具体的代码示例展示如何在实际问题中应用这些算法。
目录
- 决策树概述
- 决策树的定义
- 决策树的构建
- 决策树的优缺点
- 随机森林概述
- 随机森林的定义
- 随机森林的构建
- 随机森林的优缺点
- 决策树与随机森林的比较
- 模型复杂度与泛化能力
- 训练时间与预测时间
- 可解释性与可视化
- 决策树与随机森林的应用场景
- 分类问题
- 回归问题
- 特征重要性评估
- 代码示例
- 决策树的实现
- 随机森林的实现
- 比较两种算法的性能
- 总结
1. 决策树概述
决策树的定义
决策树是一种基于树形结构的监督学习算法,主要用于分类和回归任务。每个内部节点表示一个特征的判断条件,每个分支代表一个判断结果,每个叶节点表示一个最终决策(分类或数值)。通过树形结构的分裂,决策树可以逐步细化样本的特征,最终达到分类或预测的目的。
决策树的构建
构建决策树的过程包括选择最佳特征进行分裂、根据特征值将数据集划分为子集、递归地对每个子集构建决策树。常用的特征选择指标包括信息增益、基尼指数和卡方统计量。
信息增益:表示特征在分类上的信息增加量,信息增益越大,特征越重要。
基尼指数:用于衡量数据集的纯度,基尼指数越小,数据集越纯。
以下是决策树构建的基本步骤:
- 计算所有特征的信息增益或基尼指数。
- 选择信息增益最大或基尼指数最小的特征进行分裂。
- 根据选定的特征值将数据集划分为子集。
- 对每个子集递归地重复上述过程,直到满足停止条件(如树的深度达到限制或子集纯度足够高)。
决策树的优缺点
优点:
- 简单易懂,易于解释。
- 适用于数值型和类别型数据。
- 能够处理多输出问题。
- 模型可视化,便于理解和解释。
缺点:
- 容易过拟合,尤其是当树的深度过大时。
- 对噪声数据敏感,容易受到异常值的影响。
- 决策边界呈现阶梯状,不适用于复杂边界的拟合。
2. 随机森林概述
随机森林的定义
随机森林是基于集成学习思想的算法,通过构建多棵决策树并集成它们的结果来提高预测性能。随机森林通过引入随机性来增强模型的泛化能力,减少过拟合风险。
随机森林的构建
随机森林的构建过程包括:
- 通过有放回抽样从训练数据集中采样生成多个子数据集。
- 对每个子数据集构建一棵决策树,构建过程中引入随机性(如在每个分裂节点随机选择部分特征进行分裂)。
- 将所有决策树的结果进行集成(分类问题中使用投票法,回归问题中使用平均法)。
以下是随机森林构建的基本步骤:
- 通过有放回抽样从原始数据集中生成多个子数据集(每个子数据集大小与原始数据集相同)。
- 对每个子数据集构建一棵决策树,构建过程中在每个节点随机选择部分特征进行分裂。
- 将所有决策树的结果进行集成(多数投票法或平均法)。
随机森林的优缺点
优点:
- 强大的泛化能力,减少过拟合风险。
- 能够处理高维数据和大规模数据集。
- 对噪声数据和异常值的鲁棒性较高。
- 可以评估特征重要性。
缺点:
- 相对于单棵决策树,计算复杂度较高。
- 模型解释性较差,不易于可视化。
- 需要调整的超参数较多。
3. 决策树与随机森林的比较
模型复杂度与泛化能力
决策树模型简单,训练速度快,但容易过拟合。随机森林通过集成多棵决策树,增强了模型的泛化能力,减少了过拟合风险,但计算复杂度较高。
训练时间与预测时间
决策树的训练时间和预测时间相对较短,适合处理小规模数据集。随机森林的训练时间较长,但可以并行化处理。预测时间相对较长,但对于大多数应用场景来说是可以接受的。
可解释性与可视化
决策树的可解释性和可视化效果较好,易于理解和解释模型的决策过程。随机森林模型较为复杂,不易于解释和可视化,但可以通过特征重要性评估来理解模型。
4. 决策树与随机森林的应用场景
分类问题
决策树和随机森林都广泛应用于分类问题。决策树适用于简单的分类任务,如信用评分、客户细分等。随机森林则适用于复杂的分类任务,如图像分类、文本分类等。
回归问题
决策树和随机森林也可以用于回归问题。决策树适用于简单的回归任务,如房价预测、销售额预测等。随机森林则适用于复杂的回归任务,如股票价格预测、气象预测等。
特征重要性评估
随机森林可以通过计算每个特征在决策树分裂节点上的重要性,评估特征的重要性。这对于特征选择和数据分析具有重要意义。
5. 代码示例
在这一部分,我们将使用Python和常用的机器学习库(如Scikit-learn)来实现决策树和随机森林,并比较它们在分类和回归问题上的性能。
决策树的实现
首先,我们实现一个简单的决策树分类器。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 生成示例数据
np.random.seed(0)
X = np.random.rand(100, 4)
y = np.random.randint(2, size=100)# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)# 决策树分类器
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 性能评估
print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
随机森林的实现
接下来,我们实现一个简单的随机森林分类器。
from sklearn.ensemble import RandomForestClassifier# 随机森林分类器
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 性能评估
print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
比较两种算法的性能
我们可以通过对比决策树和随机森林在相同数据集上的性能,评估它们的优缺点。
# 决策树分类器
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print("决策树准确率:", accuracy_score(y_test, dt_pred))# 随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100)
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
print("随机森林准确率:", accuracy_score(y_test, rf_pred))
回归问题中的应用
我们还可以将上述方法应用于回归问题。以下是决策树和随机森林在回归任务中的实现。
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error# 生成示例数据
np.random.seed(0)
X = np.random.rand(100, 4)
y = np.random.rand(100)# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)# 决策树回归
dt_reg = DecisionTreeRegressor()
dt_reg.fit(X_train, y_train)
dt_pred = dt_reg.predict(X_test)
print("决策树均方误差:", mean_squared_error(y_test, dt_pred))# 随机森林回归
rf_reg = RandomForestRegressor(n_estimators=100)
rf_reg.fit(X_train, y_train)
rf_pred = rf_reg.predict(X_test)
print("随机森林均方误差:", mean_squared_error(y_test, rf_pred))
6. 总结
通过本文的介绍,我们详细比较了决策树和随机森林的工作原理、优缺点和应用场景,并通过代码示例展示了如何在实际问题中应用这些算法。决策树因其简单易懂、易于解释而广泛应用于分类和回归任务,但容易过拟合。随机森林通过集成多棵决策树,提高了模型的泛化能力,适用于复杂任务,但模型解释性较差。选择哪种算法取决于具体的应用场景和需求。通过理解两种算法的特性和实现细节,开发者可以在实际项目中更好地应用这些工具,解决实际问题。
相关文章:

决策树与随机森林:比较与应用场景分析
决策树与随机森林:比较与应用场景分析 引言 决策树和随机森林是机器学习中广泛使用的两种算法,因其简单性和强大的功能而被广泛采用。决策树是一种树形结构的决策模型,易于理解和解释。随机森林则是通过集成多棵决策树来提高预测性能的模型…...

C#用Aspose.Cells导出Excel,.NET导出Excel
ASP.NET MVC 控制器里面Action处理,下载文件,输出文件流 public async Task<ActionResult> ExportNewsAuthorFee(string deptId, DateTime? startDate, DateTime? endDate){if (startDate null){startDate DateTime.Parse(DateTime.Now.Year …...

天猫番茄品类TOP1,复购率超40%,「一颗大」如何策划极致产品力?
桔子要买什么品牌?桃子买什么品牌?土豆买什么品牌?过去人们购买农产品几乎没有品牌意识。但近年来可能某些人买猕猴桃时会考虑佳沛,这是一个在全球达到30%猕猴桃市场的新西兰品牌。与此类似,一个国产品牌「一颗大™」正…...

Docker搭建私有仓库harbor(docker 镜像仓库搭建)
Harbor介绍 Docker容器应用的开发和运行离不开可靠的镜像管理,虽然Docker官方也提供了公共的镜像仓库,但是从安全和效率等方面考虑,部署我们私有环境内的Registry也是非常必要的。Harbor是由VMware公司开源的企业级的Docker Registry管理项目…...

面试题:MySQL 索引
1. 谈一下你对于MySQL索引的理解?(为什么MySQL要选择B+树来存储索引) MySQL的索引选择B+树作为数据结构来进行存储,使用B+树的本质原因在于可以减少IO次数,提高查询的效率,简单来说就是可以保证在树的高度不变的情况下存储更多的数据: IO效率的提高:在MySQL数据库中,…...

云计算day13
一、Git 概述 Git 是一种分布式版本控制系统,用于跟踪和管理代码的变更。它是由 Linus Torvalds 创建的,最初被设计用于 Linux 内核的开发。Git 允许开发 人员跟踪和管理代码的版本,并且可以在不同的开发人员之间进行协作。 Github 用的就…...

2024年孝感中级职称报名开始了吗?
2024年孝感中级职称申报终于开始了,之前参加过水测的小伙伴们,开始准备评审了 2024年孝感本批次申报时间:中级、初级职称网上申报时间:2024年8月1日至8月31日。 注意:个人通过“湖北省职称评审管理信息系统”申报,须先…...

RAG技术之Router
Router有什么用? 在RAG应用中,Router可以帮助我们基于用户的查询意图来决定使用何种数据类型或数据源,比如是否需要进行语义检索、是否需要进行text2sql查询,是否需要用function call来进行API调用。 Router也可以根据用户的查询…...

linux系统通过修改sudo文件使普通用户拥有类似root用户权限
说明:普通用户要想拥有root权限,如果不在sudo文件里配置就算把该用户加到wheel组(root用户所在的组)也不行。 要想通过在命令前加上sudo使得该用户以root权限执行命令,需要修改/etc/sudoers文件。 (如果通…...
基于PyCharm在Windows系统上远程连接Linux服务器中Docker容器进行Python项目开发与部署
文章目录 摘要项目结构项目开发项目上线参考文章 摘要 本文介绍了如何在Windows 10系统上使用PyCharm专业版2024.1,通过Docker容器在阿里云CentOS 7.9服务器上进行Python项目的开发和生产部署。文章详细阐述了项目结构的搭建、PyCharm的使用技巧、以及如何将开发项…...

TypeScript学习篇-类型介绍使用、ts相关面试题
文章目录 基础知识基础类型: number, string, boolean, object, array, undefined, void(代表该函数没有返回值)enum(枚举): 定义一个可枚举的对象typeinterface联合类型: |交叉类型: &any 类型null 和 undefinednullundefined never类型 面试题及实战1. 你觉得使用ts的好处…...
超详细!Jmeter性能测试
前言 性能测试是一个全栈工程师/架构师必会的技能之一,只有学会性能测试,才能根据得到的测试报告进行分析,找到系统性能的瓶颈所在,而这也是优化架构设计中重要的依据。 测试流程: 需求分析→环境搭建→测试计划→脚…...

C语言经典习题24
文件操作习题 一 编程删除从C盘home文件夹下data.txt文本文件中所读取字符串中指定的字符,该指定字符由键盘输入,并将修改后的字符串以追加方式写入到文本文件C:\home\data.txt中。 #include<stdio.h> main() { char s[100],ch; int i;…...
SQL labs-SQL注入(三,sqlmap使用)
本文仅作为学习参考使用,本文作者对任何使用本文进行渗透攻击破坏不负任何责任。 引言: 盲注简述:是在没有回显得情况下采用的注入方式,分为布尔盲注和时间盲注。 布尔盲注:布尔仅有两种形式,ture&#…...
统一认证与单点登录:简明概述与应用
1. 统一认证概述 统一认证是一种身份验证机制,允许用户使用一个账户来访问多个系统和应用程序。它的主要目标是简化用户的登录过程,提高安全性,并减少管理开销。统一认证通过集中管理用户信息,使得用户只需一次认证即可访问不同的…...

MSPM0G3507学习笔记1:开发环境_引脚认识与点灯
今日速通一款Ti的单片机用于电赛:MSPM0G3507 这里默认已经安装好了Keil5_MDK 首先声明一下: 因为是速成,所以需要一定单片机学习基础,然后我写的也不会详细,这个专栏的笔记也就是自己能看懂就行的目标~~~ 文章提供测试代码解…...

使用法国云手机进行面向法国的社媒营销
在当今数字化和全球化的时代,社交媒体已经成为企业营销和拓展市场的重要工具。对于想进入法国市场的企业来说,如何在海外社媒营销中脱颖而出、抓住更多的市场份额,成为了一个关键问题。法国云手机正为企业提供全新的营销工具,助力…...
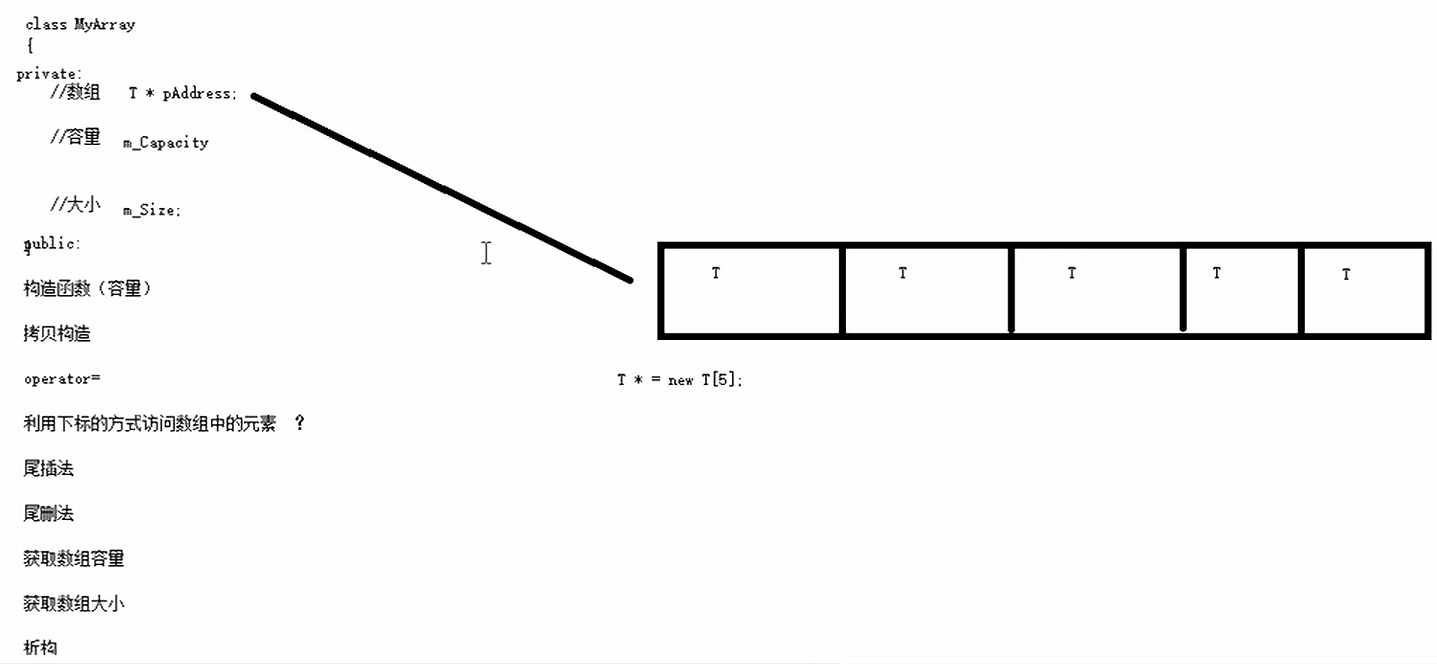
C++学习笔记——模板
学习视频 文章目录 模板的概念函数模板函数模板语法函数模板注意事项函数模板案例普通函数与函数模板的区别普通函数与函数模板的调用规则模板的局限性 类模板类模板与函数模板区别类模板中成员函数创建时机类模板对象做函数参数类模板与继承类模板成员函数类外实现类模板分文件…...
财务分析,奥威BI行计算助力财务解放报表工作
【财务分析,奥威BI行计算助力财务解放报表工作】 在企业的财务管理体系中,财务报表的编制与分析是至关重要的一环。然而,传统的手工编制报表方式不仅耗时耗力,还难以应对日益复杂多变的财务数据需求。奥威BI(Business…...

文件写入、读出-linux
基于linux操作系统,编写存储功能,在网上搜了几个例子,一直报创建错误, fopen(SAVE_PATH_OWN_INF_FILE, "w") fopen(SAVE_PATH_OWN_INF_FILE, "a"), 使用这两个创建均失败,最后发现创建可以用以…...
)
UE5 RPG开发实战:用MVC架构重构你的UI系统(GAS项目避坑指南)
UE5 RPG开发实战:用MVC架构重构UI系统的工程化实践当你的UE5 RPG项目从原型阶段进入正式开发,UI系统往往会成为第一个显露出架构问题的模块。属性面板、技能栏、BUFF指示器等数十个UI组件相互纠缠,每次新增功能都像在走钢丝——这就是我们引入…...
)
计算机工程投稿经历(2026年5月份录用)
本篇文章记录自己的投稿经历然后一些投稿心得。相信大家完成自己初稿的时候都不知道如何去选择期刊,我也是一样。根据自己的稿件研究方向可以快速筛选期刊,最好的方法就是在知网搜索与自己稿件相关主题相关的文章,本人研究方向是深深度学习方…...

2026年AI模型接口中转站真实测评:五大主流大模型API聚合平台深度实测调研指南
进入2026年,大语言模型的工程化落地已经走完从尝鲜到规模化普及的全流程,对于广大AI应用开发者而言,AI大模型接口中转站早就不是过去仅承担接口转发的简单工具,如今它已经承担起链路高可用保障、多模型负载均衡、跨协议自动转换等…...

基于Simulink的四开关buck-boost变换器闭环仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

深度解析2026年高性能RTP导电塑料:十大创新应用与选购指南
在制造业转型升级的关键节点,导电塑料作为高端新材料正面临“性能门槛不断提升”与“供应链稳定性难以兼得”的价值悖论。行业数据显示,2025年高端导电塑料需求增长率达22%,但超过65%的企业在选型过程中因技术参数复杂、供应商服务缺失而导致…...

Google 广告场景下 Uniswap 钓鱼攻击机理与 Web3 防御体系研究
摘要 2026 年 5 月 22 日,GoPlus 安全团队发布预警,针对 Web3 领域头部去中心化交易平台 Uniswap 的搜索引擎钓鱼攻击呈规模化爆发态势。攻击者通过购买 Google Ads 关键词广告,将高仿钓鱼网站置顶于搜索结果前列,结合视觉相似域名…...

为什么92%的DeepSeek微调失败?资深架构师拆解3类致命配置错误及实时诊断命令
更多请点击: https://kaifayun.com 第一章:DeepSeek模型微调失败率的行业现状与根本归因 近年来,DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder)在开源社区和企业私有化部署中广泛应用,但实证调研显示…...

轻量神经网络在量子比特实时控制中的嵌入式部署实践
1. 项目概述:当机器学习遇见量子控制在量子计算这个前沿领域,我们每天都在与微观世界的“幽灵”打交道。一个量子比特的状态,就像地球仪上的一个点,可以用布洛赫球面上的经度和纬度来描述。要让这个点精确地旋转到我们指定的位置&…...

第41天:MySQL新特性
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、JSON类型 1.1 JSON类型的基本形式 1.2 JSON类型的实际应用场景 1.3 用户画像场景中的JSON应用 二、窗口函数 2.1 窗口函数的概念 2.2 窗口函数实战示例 总结 前言 在掌握…...

Windows平台安卓应用安装终极解决方案:APK Installer技术深度解析
Windows平台安卓应用安装终极解决方案:APK Installer技术深度解析 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的安卓模拟器࿱…...