初阶C语言:冒泡排序
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
1.冒泡排序
关于冒泡排序我们在讲初阶数组时讲到过,现在再来复习一下
1.1.核心思想
冒泡排序的核心思想是通过比较相邻元素的大小,将较大的元素交换到右边,从而使序列中的最大元素逐渐“浮”到最右端,最小元素“沉”到最左端。
例:
排序前:
int arr[10] = { 8,5,6,2,3,1,4,9,7,10 };
排序后:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
1.2代码实现
如何使用代码来实现冒泡排序呢?
首先得确定排序的趟数,和一趟排序的次数
可以先来分析一下:

因此冒泡排序的趟数设置就是整个数组总长-1,因此循环变量的限制条件就为数组总长-1

关于冒泡排序一趟中排序的次数,需要再设置一个循环变量,但是这个循环变量的限制条件决定了一趟中排序的次数,根据上面的演示,第一趟排序的次数是9,第二次是8,第三次为7.....以此类推,每进行一趟排序,一趟中排序的次数就减一,因此在控制排序次数的循环变量的限制条件为总长减1再减趟数
代码演示:
#include <stdio.h>
void bubble_sort(int arr[], int sz)
{//设置冒泡排序的趟数int i = 0;for (i = 0; i < sz - 1; i++){//一趟冒泡排序的次数int j = 0;for (j = 0; j < sz-1-i; j++){if (arr[j] > arr[j + 1]) //如果前面的一个数字大于后面的数字就交换{int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}
}void print_arr(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[] = { 5,4,8,9,7,6,3,2,1,10 };//使用冒泡排序的算法,来排序int sz = sizeof(arr) / sizeof(arr[0]);printf("排序前:>");print_arr(arr, sz);bubble_sort(arr, sz);//打印printf("排序后:>");print_arr(arr, sz);return 0;
}
这样写就可以实现冒泡排序,但是有一点,上面写的代码只能排序整型数组,如果要排序字符、结构体...就不能适用了,因此我们来学习一个新的排序方式
2.qsprt排序
qsort函数是一个用于对数组快速排序的函数,它是C标准库中的一个函数,可以对任何类型的数组进行排序。qsort的底层使用的是快排的算法。
函数原型为:void qsort(void* base, size_t nitems, size_t size, int (*compar)(const void*, const void*));其中base指向要排序的数组,nitems是数组中元素的个数,size是每个元素的大小,compar是比较函数,用于比较两个元素的大小。
void qsort( void* base, //指向要排序的数组size_t num, //数组中元素的个数size_t size, //数组中每个元素的大小int (*compar)(const void*, const void*));//指向一个函数,这个函数可以比较两个元素的大小这个函数的第一个参数是一个void* 的指针,因为void*的指针可以存放任何类型的指针,这样有助于排序任何类型的数据,第二个参数是一个无符号整形的数据,表示元素个数,第三个参数也是一个无符号整形的数据,表示元素大小,第四个参数是一个函数指针,这个函数指针需要我们自己设计,因为这个qsort函数可以排序任何类型的数据,因此你需要排序什么类型的数据就可以自己设置什么样的函数
可以使用C语言工具来查一下这个函数:

如果听到这里还没有挺明白的话,也不要着急,下面给大家举个例子来用一下qsort函数:
使用qsort来对整型数组进行排序
代码演示:
#include <stdio.h>
#include <stdlib.h>
void print_arr(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}
int cmp_int(const void* p1, const void* p2) //设置比较两个元素大小的函数
{return *(int*)p1 - *(int*)p2;//由于比较的是两个整形的数组,因此需要对其进行强制类型转化为(int*)的指针,然后解引用找到这个数//如果返回值大于0证明前面的数p1大于后面的数p2,需要交换//如果返回值小于0证明前面的数p1小于后面的数p2,不需要交换//如果返回值等于0证明两个数相等,也不需要交换
}
int main()
{int arr[] = { 5,8,9,6,3,2,7,1,4,10 };int sz = sizeof(arr) / sizeof(arr[0]);printf("排序前:");//打印print_arr(arr, sz);//排序qsort(arr, sz, sizeof(arr[0]), cmp_int); //这里的cmp_int就是一个回调函数printf("排序后:");print_arr(arr, sz);return 0;
}
注意:cmp_ 函数需要自己设置,需要什么类型就需要强制类型转化为什么类型
对结构体进行排序
对于结构体也可以进行排序,只不过需要告诉cmp_函数需要排结构体中的什么,比如:名字、年龄、时间......
关于结构体的创建,和对结构体成员的访问要理解
访问结构体变量使用.操作符
访问结构体指针使用->操作符
比较两个字符串的大小使用的是strcmp

对年龄进行排序
代码演示:
#include <stdio.h>
#include <stdlib.h>
struct Str
{char name[20];int age;
};
int cmp_str_by_age(const void* p1, const void* p2)
{//这里使用结构体指针来访问结构体成员return ((struct Str*)p1)->age - ((struct Str*)p2)->age;
}
void test1()
{struct Str s[] = { {"zhangsan",55},{"lisi",45},{"wangwu",25} };int sz = sizeof(s) / sizeof(s[0]);printf("年龄排序:\n");printf("排序前:\n");int i = 0;for (i = 0; i < sz; i++){printf("年龄:%d\n", s[i].age);}qsort(s, sz, sizeof(s[0]), cmp_str_by_age);printf("排序后:\n");for (i = 0; i < sz; i++){printf("年龄:%d\n", s[i].age);}
}
int main()
{//对年龄进行排序test1();return 0;
}对名字进行排序
对名字排序就是对首字母的ASCII码值进行排序,如果首字母一样,就使用第二个字母进行排序,依次类推
代码演示:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Str
{char name[20];int age;
};
int cmp_str_by_name(const void* p1, const void* p2)
{return strcmp(((struct Str*)p1)->name, ((struct Str*)p2)->name);
}
void test2()
{struct Str s[] = { {"zhangsan",55},{"lisi",45},{"wangwu",25} };int sz = sizeof(s) / sizeof(s[0]);printf("名字排序:\n");printf("排序前:\n");int i = 0;for (i = 0; i < sz; i++){printf("名字:%s\n", s[i].name);}qsort(s, sz, sizeof(s[0]), cmp_str_by_name);printf("排序后:\n");for (i = 0; i < sz; i++){printf("名字:%s\n", s[i].name);}
}
int main()
{//对年龄进行排序//test1();//对名字进行排序test2();return 0;
}
因此qsort的排序功能是非常广泛的,它的底层逻辑是快速排序的算法,那我们可以用冒泡排序的算法也实现一个类似与qsort的函数
3.冒泡排序思想实现qsort
上面写的冒泡排序只可以实现整数数组的比较,功能单一,我们可以使用冒泡排序的思想实现类似于qsort的一种排序的方法,qsort的底层逻辑是快速排序。
基本框架和qsort的框架一样,只是需要类似于qsort函数的代码来实现
代码演示:
#include <stdio.h>
//实现比较大小的函数
int cmp_int(const void* p1, const void* p2)
{return *(int*)p1 - *(int*)p2;
}
//打印函数
void print_arr(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}
void test1()
{int arr[] = { 8,9,6,5,2,3,1,4,7,10 };int sz = sizeof(arr) / sizeof(arr[0]);printf("排序前:");print_arr(arr, sz);//类似于qsort函数的冒泡排序bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);printf("排序后:");print_arr(arr, sz);
}
int main()
{test1();return 0;
}3.1冒泡排序函数实现
使用冒泡排序逻辑实现类似于qsort函数的排序方法,因此,冒泡排序的逻辑就可以使用,因此设置冒泡排序的趟数和一趟排序的次数都是不变的,只是要注意在什么条件下需要交换,怎么样交换,交换什么
代码演示:
//这时的函数参数就可以参考qsort函数的函数参数
//void qsort( void* base, //指向要排序的数组//size_t num, //数组中元素的个数//size_t size, //数组中每个元素的大小//int (*compar)(const void*, const void*));//指向一个函数,这个函数可以比较两个元素的大小
void bubble_sort(void* base, size_t num, size_t width, int(*cmp_int)(const void* e1, const void* e2))
{size_t i = 0; //这里的参数类型要与函数参数类型一致都为无符号整型//设置冒泡排序的趟数for (i = 0; i < num; i++){size_t j = 0;//设置一趟冒泡排序需要交换的次数for (j = 0; j < num - 1 - i; j++){//判断交换if (){}}}
}这里要注意,在什么条件下需要交换,因为在设置这个函数时的函数参数是void*,目的就是为了用来比较任何类型的数据,因为我们又创建了一个比较大小的函数,因此就可以通过比较函数的返回值来确定怎样交换,如果比较函数的返回值小于0,那就证明前面的一个数据小于后面的一个数据,就不需要交换,如果返回值大于0,就证明前面的一个数据大于后面的一个数据,就需要实现交换,因此需要交换的条件就可以将cmp_int的返回值作为判断条件,如果>0就交换
代码演示:
if (cmp_int()>0)//这里还没有给这个函数传参呀,那该传怎样的参数呢?
{
} 根据比较函数的函数参数来进行传参,也就是说要传给它两个地址,一个地址是前一个数据的地址,另外一个是后面一个地址的数据,那就要注意前一个地址和后一个地址该怎么传呢?
关于指针的计算我们也知道:什么类型的指针加减整数,就意为着跳过整数个类型的地址,但是这里是void*的类型,那是不是可以传参void* base+j和void* base+j+1?这样做是不可以的,void*可以接收任何类型的指针,但并不意味着可以当成任何类型拿来使用,使用时需要进行强制类型转化,需要什么类型就强制转化为什么类型就可以,这里我们需要比较的是整型数组,就需要转化为int*类型((int*) base+j, (int*) base+j+1)的指针来使用,但是我们实现的这个冒泡排序是可以排序任何类型的数据,所以也不能直接改为int*的指针,所以还得另寻出路!
//代码1
if (cmp_int(base + j , base + j + 1 )>0)
{}
//代码2
if (cmp_int((int*)base + j , (int*)base + j + 1 )>0)
{}
//代码1和代码2都是不可行的操作 我们都知道char*的指针对其进行加减整数只能跳过一个字节,那么如果将参数类型转化为char*的类型然后再乘上宽度(数组中一个元素的大小)是不是就可以达到转化任意类型的效果了,假设要排序整形,一个整形的大小是4个字节,因此用char*的指针*4就表明每一次要跳过4个字节的空间也就是一个整形
代码演示:
int cmp_int(const void* p1, const void* p2)
{return *(int*)p1 - *(int*)p2; //通过地址找到数据进行比较
}
if (cmp_int((char*)base + j * width , (char*)base + (j + 1) * width)>0)
{//如果前一位数据大于后一位数据就满足条件//交换//交换函数:
} 3.2交换函数的实现
如果前一个数据大于后一个数据就实现交换,那该怎么交换呢?
可以采用一个字节一个字节的交换方式,设置循环,使用宽度来设置交换的次数,4个字节就交换四次

因此再给交换函数传参时需要传两个起始地址和宽度
代码演示:
void Swp(char* buf1, char* buf2, int width)
{int i = 0;for (i = 0; i < width; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++;buf2++;}
}
if (cmp_int((char*)base + j * width , (char*)base + (j + 1) * width)>0)
{ //如果满足分支语句条件就进来交换Swp((char*)base + j * width, (char*)base + (j + 1) * width, width);
}3.3整体代码展示
#include <stdio.h>
int cmp_int(const void* p1, const void* p2)
{return *(int*)p1 - *(int*)p2;
}
void print_arr(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}
void Swp(char* buf1, char* buf2, int width)
{int i = 0;for (i = 0; i < width; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++;buf2++;}
}
void bubble_sort(void* base, size_t num, size_t width, int(*cmp_int)(const void* e1, const void* e2))
{size_t i = 0;for (i = 0; i < num; i++){size_t j = 0;for (j = 0; j < num - 1 - i; j++){if (cmp_int((char*)base + j * width , (char*)base + (j + 1) * width)>0){Swp((char*)base + j * width, (char*)base + (j + 1) * width, width);}}}
}
void test1()
{int arr[] = { 8,9,6,5,2,3,1,4,7,10 };int sz = sizeof(arr) / sizeof(arr[0]);printf("排序前:");print_arr(arr, sz);bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);printf("排序后:");print_arr(arr, sz);
}
int main()
{test1();return 0;
}
但是如果有一个数组
int arr[] = { 2,1,3,4,5,6,7,8,9,10 };
可以看到这个数组如果要排序的话只需要排第一个和第二个就可以,就不需要继续判断后面的数据,因此可以将代码优化一下,可以设置一个变量,如果交换了就将变量修改,如果变量没有被修改就要跳出循环
代码优化:
#include <stdio.h>
//比较两个数据的大小
int cmp_int(const void* p1, const void* p2)
{return *(int*)p1 - *(int*)p2;
}
//打印函数
void print_arr(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}
//交换函数
void Swp(char* buf1, char* buf2, int width)
{int i = 0;for (i = 0; i < width; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++;buf2++;}
}
//使用冒泡排序的思想来实现类似于qsort的排序算法
void bubble_sort(void* base, size_t num, size_t width, int(*cmp_int)(const void* e1, const void* e2))
{size_t i = 0;//假设数组有序int flag = 1;for (i = 0; i < num; i++){size_t j = 0;for (j = 0; j < num - 1 - i; j++){if (cmp_int((char*)base + j * width , (char*)base + (j + 1) * width)>0){//交换将flag赋值为0;flag = 0;//交换Swp((char*)base + j * width, (char*)base + (j + 1) * width, width);} }if (1 == flag){break;}}
}
void test1()
{int arr[] = { 8,9,6,5,2,3,1,4,7,10 };int sz = sizeof(arr) / sizeof(arr[0]);printf("排序前:");print_arr(arr, sz);bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);printf("排序后:");print_arr(arr, sz);
}
int main()
{//排序整形数组test1();return 0;
}使用冒泡排序对结构体进行排序
#include <stdio.h>
#include <string.h>//比较两个数据的大小
int cmp_int(const void* p1, const void* p2)
{return *(int*)p1 - *(int*)p2;
}
//打印函数
void print_arr(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}
//交换函数
void Swp(char* buf1, char* buf2, int width)
{int i = 0;for (i = 0; i < width; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++;buf2++;}
}
//使用冒泡排序的思想来实现类似于qsort的排序算法
void bubble_sort(void* base, size_t num, size_t width, int(*cmp_int)(const void* e1, const void* e2))
{size_t i = 0;//假设数组有序int flag = 1;for (i = 0; i < num; i++){size_t j = 0;for (j = 0; j < num - 1 - i; j++){if (cmp_int((char*)base + j * width , (char*)base + (j + 1) * width)>0){//交换将flag赋值为0;flag = 0;//交换Swp((char*)base + j * width, (char*)base + (j + 1) * width, width);}}if (1 == flag){break;}}
}
struct Str
{char name[20];int age;
};
//比较年龄
int cmp_str_by_age(const void* p1, const void* p2)
{return ((struct Str*)p1)->age - ((struct Str*)p2)->age;//这里使用->来访问结构体指针
}void test2()
{//结构体初始化struct Str s[] = { {"zhangsan",55},{"lisi",25},{"wangwu",35} };int sz = sizeof(s) / sizeof(s[0]);bubble_sort(s, sz, sizeof(s[0]), cmp_str_by_age);
}
int cmp_str_by_name(const void* p1, const void* p2)
{return strcmp(((struct Str*)p1)->name, ((struct Str*)p2)->name);
}
void test3()
{struct Str s[] = { {"zhangsan",55},{"lisi",25},{"wangwu",35} };int sz = sizeof(s) / sizeof(s[0]);bubble_sort(s, sz, sizeof(s[0]), cmp_str_by_name);
}
int main()
{//对年龄进行排序test2();//对名字进行排序test3();return 0;
}
如果要对年龄进行排序要将对名字排序的代码注释掉,要不然会混在一起


这里并没有将它们打印出来,只是在调试的监视窗口中观察到的
如果要打印出来可以在冒泡排序的函数下面加上循环打印结构体
void test3()
{struct Str s[] = { {"zhangsan",55},{"lisi",25},{"wangwu",35} };int sz = sizeof(s) / sizeof(s[0]);bubble_sort(s, sz, sizeof(s[0]), cmp_str_by_name);int i = 0;for (i = 0; i < sz; i++){printf("姓名:%s\n", s[i].name);}
}
void test2()
{struct Str s[] = { {"zhangsan",55},{"lisi",25},{"wangwu",35} };int sz = sizeof(s) / sizeof(s[0]);bubble_sort(s, sz, sizeof(s[0]), cmp_str_by_age);int i = 0;for (i = 0; i < sz; i++){printf("年龄:%d\n", s[i].age);}
}
相关文章:
初阶C语言:冒泡排序
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。1.冒泡排序关于冒泡排序我们在讲…...

带头双向循环链表
在前面我们学习了单链表,发现单链表还是有一些不够方便,比如我们要尾插,需要遍历一遍然后找到它的尾,这样时间复炸度就为O(N),现在我们引入双向带头链表就很方便了,我们先看看它的结构。通过观察,我们发现一…...

C#中的DataGridView中添加按钮并操作数据
背景:最近在项目中有需求需要在DataGridView中添加“删除”、“修改”按钮,用来对数据的操作以及显示。 在DataGridView中显示需要的按钮 首先在DataGridView中添加需要的列,此列是用来存放按钮的。 然后在代码中“画”按钮。 if (e.Column…...

WEB安全 PHP基础
WEB安全 PHP基础 PHP简述 PHP(全称:PHP:Hypertext Preprocessor,即"PHP:超文本预处理器")是一种通用开源脚本语言。 在一个php文件中可以包括以下内容: PHP 文件可包含文本、HTML、…...
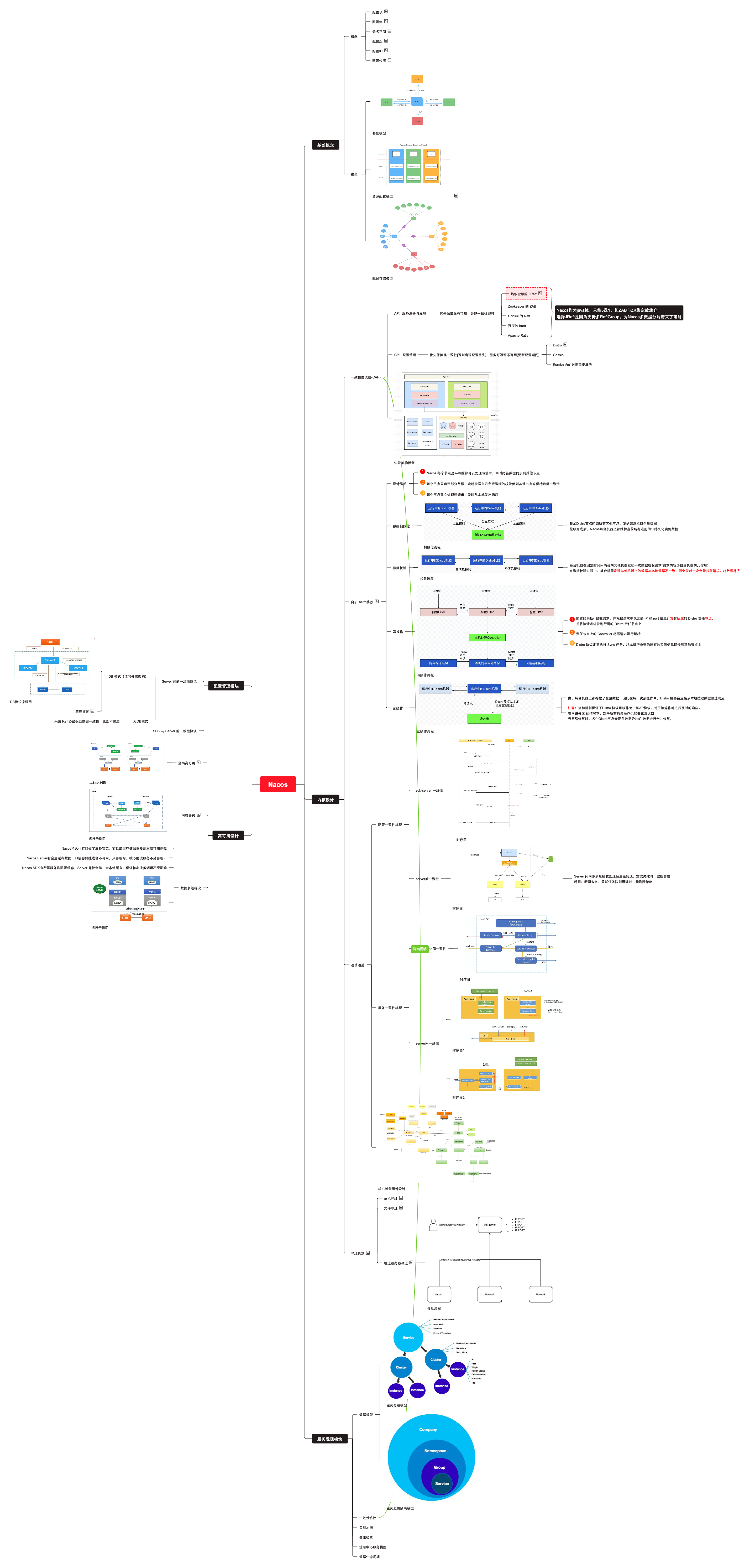
基础篇:07-Nacos注册中心
1.Nacos安装部署 1.1 下载安装 nacos官网提供了安装部署教程,其下载链接指向github官网,选择合适版本即可。如访问受阻可直接使用以下最新稳定版压缩包:📎nacos-server-2.1.0.zip,后续我们也可能会更改为其他版本做更…...
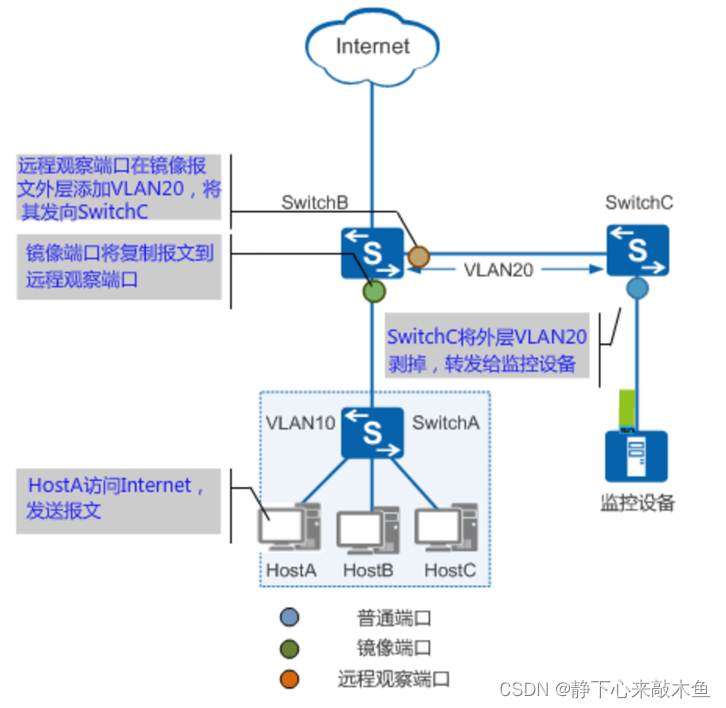
端口镜像讲解
目录 端口类型 镜像方向 观察端口位置 端口镜像实现方式 流镜像 Vlan镜像 MAC镜像 配置端口镜像 配置本地观察端口 配置远程流镜像(基于流镜像) 端口镜像是指将经过指定端口的报文复制一份到另一个指定端口,便于业务监控和故障定位…...
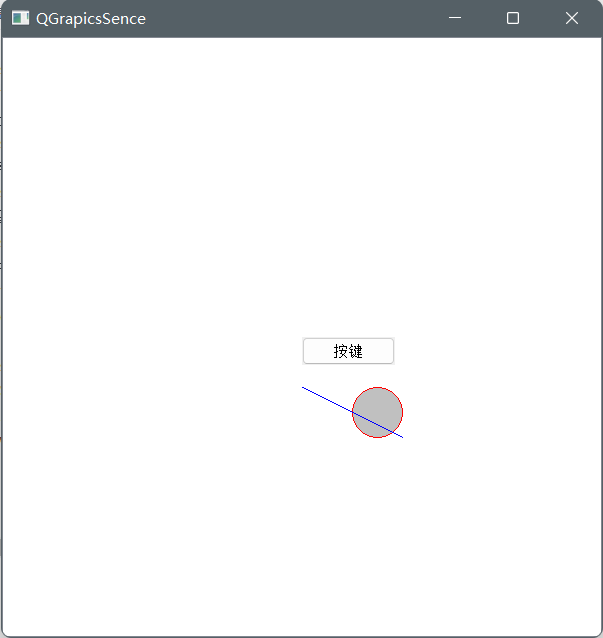
图形视图框架QGraphicsScene(场景,概念)
QGraphicsScene 该类充当 QGraphicsItems 的容器。它与 QGraphicsView 一起使用,用于在 2D 表面上可视化图形项目,例如线条、矩形、文本甚至自定义项目。 QGraphicsScene具有的功能: 提供用管理大量数据项的高速接口传播事件到每一个图形项…...

ChatGPT 拓展资料: 强化学习-SARSA算法
强化学习是一种机器学习技术,它关注的是在特定环境中,如何最大化一个智能体(agent)的累积奖励(reward)。强化学习算法会根据当前状态和环境的反馈来选择下一个动作,不断地进行试错,从而优化智能体的行为。 SARSA是一种基于强化学习的算法,它可以用于解决马尔可夫决策…...

SpringJDBC异常抽象
前言spring会将所有的常见数据库的操作异常抽象转换成他自己的异常,这些异常的基类是DataAccessException。DataAccessException是RuntimeException的子类(运行时异常),是一个无须检测的异常,不要求代码去处理这类异常SQLErrorCodeSQLExcepti…...

我在字节的这两年
前言 作为脉脉和前端技术社区的活跃分子,我比较幸运的有了诸多面试机会并最终一路升级打怪如愿来到了这里。正式入职时间为2021年1月4日,也就是元旦后的第一个工作日。对于这一天,我印象深刻。踩着2020年的尾巴接到offer,属实是过了一个快乐…...
与ImageButton(图像按钮))
Button(按钮)与ImageButton(图像按钮)
今天给大家介绍的Android基本控件中的两个按钮控件,Button普通按钮和ImageButton图像按钮; 其实ImageButton和Button的用法基本类似,至于与图片相关的则和后面ImageView相同,所以本节只对Button进行讲解,另外Button是TextView的子类,所以TextView上很多属性也可以应用到B…...

Chrome插件开发-右键菜单开启页面编辑
开发一个执行js脚本改变页面DOM的Chrome插件,manifest_version版本为3。 Chrome插件基本知识 Chrome插件通常由以下几部分组成: manifest.json 该文件为必须项,其它文件都是可选的。该文件相当于插件的meta信息,包含manifest版…...

指针进阶(上)
内容小复习🐱: 字符指针:存放字符的数组 char arr1[10]; 整型数组:存放整型的数组 int arr2[5]; 指针数组:存放的是指针的数组 存放字符指针的数组(字符指针数组) char* arr3[5]; 存放整型指针的数组(整型指针数组) int* arr[6]; 下面进入学习了哦~&…...

Python每日一练(20230318)
目录 1. 排序链表 ★★ 2. 最长连续序列 ★★ 3. 扰乱字符串 ★★★ 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏 1. 排序链表 给你链表的头结点 head ,请将其按 升序 …...
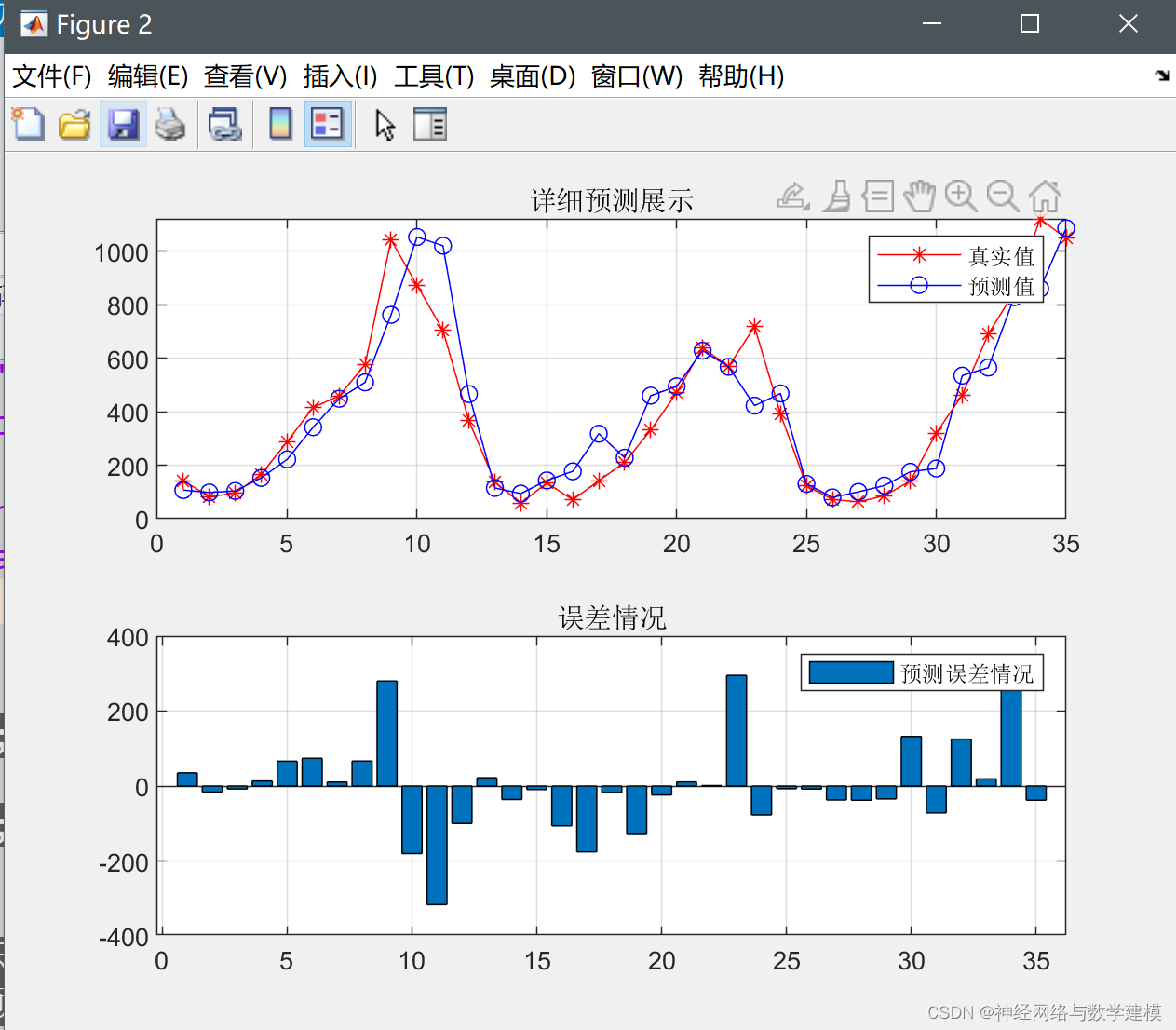
多层多输入的CNN-LSTM时间序列回归预测(卷积神经网络-长短期记忆网络)——附代码
目录 摘要: 卷积神经网络(CNN)的介绍: 长短期记忆网络(LSTM)的介绍: CNN-LSTM: Matlab代码运行结果: 本文Matlab代码数据分享: 摘要: 本文使用CNN-LSTM混合神经网…...
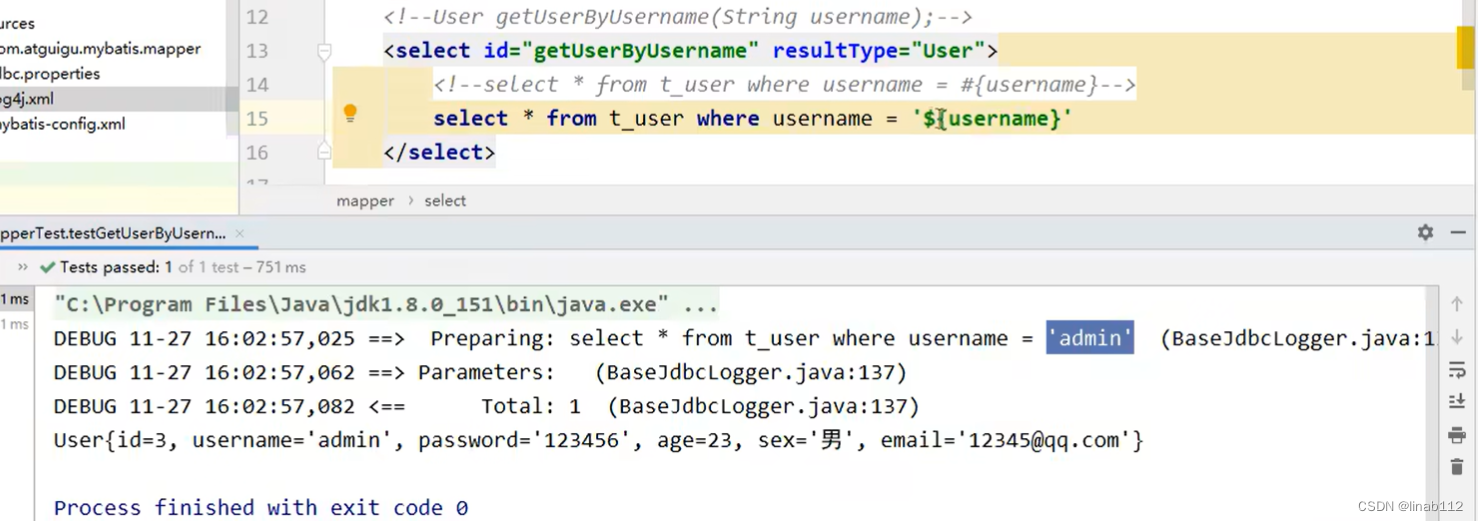
mybatis中获取参数的两种方式:${}和#{}
目录 1.#{} 2.${} 3.总结 1.#{} 本质是占位符赋值 示例及执行结果: 结论:通过执行结果可以看到,首先对sql进行了预编译处理,然后再传入参数,有效的避免了sql注入的问题,并且传参方式也比较简单…...
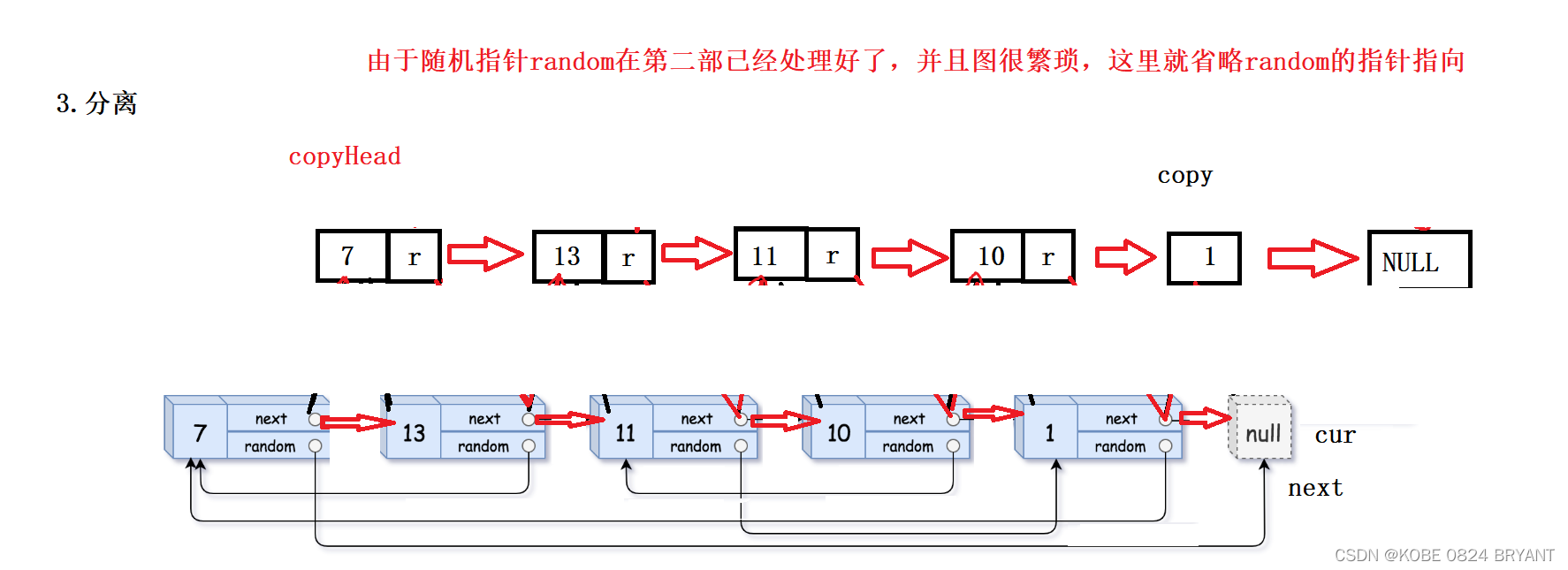
复制带随机指针的复杂链表
目录一、题目题目链接二、题目分析三、解题思路四、解题步骤4.1 复制结点并链接到对应原节点的后面4.2 处理复制的结点的随机指针random4.3 分离复制的链表结点和原链表结点并重新链接成为链表五、参考代码六、总结一、题目题目链接 题目链接:https://…...
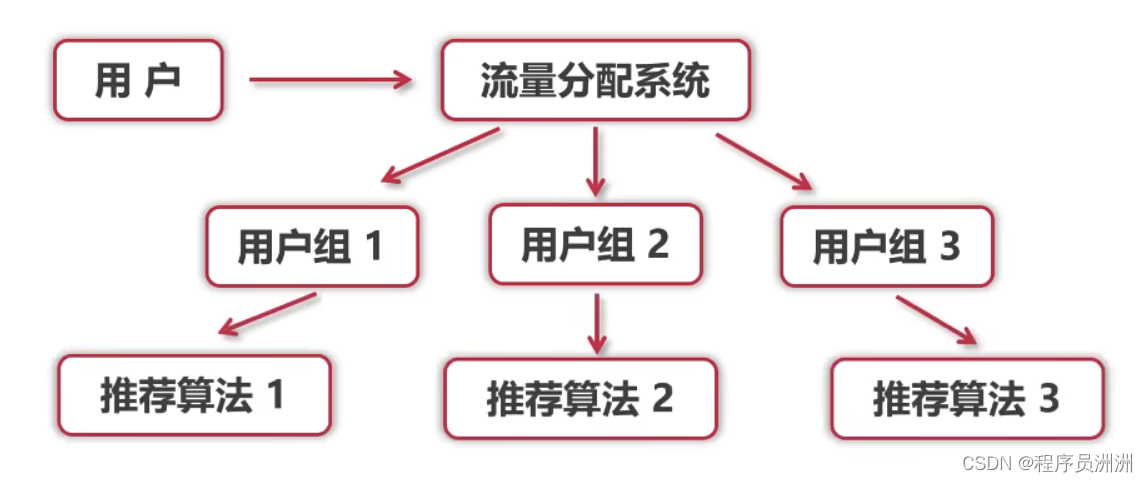
【基于协同过滤算法的推荐系统项目实战-2】了解协同过滤推荐系统
本文目录1、推荐系统的关键元素1.1 数据1.2 算法1.3 业务领域1.4 展示信息2、推荐算法的主要分类2.1 基于关联规则的推荐算法基于Apriori的算法基于FP-Growth的算法2.2 基于内容的推荐算法2.3 基于协同过滤的推荐算法3、推荐系统常见的问题1、冷启动2、数据稀疏3、不断变化的用…...
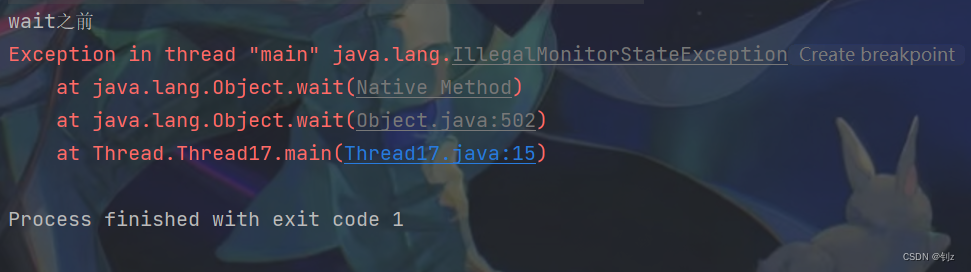
线程安全(重点)
文章目录一.线程安全的概念1.1 线程安全的概念1.2 线程不安全的原因1.3 解决线程不安全二.synchronized-monitor lock(监视器锁)2.1 synchronized的特性(1)互斥(2)刷新内存(3)可重入2.2 synchronied使用方法1.直接修饰普通方法:2.修饰静态方法:3.修饰代码块:三.死锁3.1死锁的情…...

软件测试面试找工作你必须知道的面试技巧(帮助超过100人成功通过面试)
目录 问题一:“请你自我介绍一下” 问题二:“谈谈你的家庭情况” 问题三:“你有什么业余爱好?” 问题四:“你最崇拜谁?” 问题五:“你的座右铭是什么?” 问题六:“谈谈你的缺点” 问题七ÿ…...

AI大模型产品经理零基础到进阶学习路线图,非常详细收藏我这一篇就够了
AI产品经理区别于普通产品经理的地方,不止在懂得AI算法,更重要的是具有AI思维。 人工智能产品设计要以操作极度简单为标准,但是前端的简单代表后端的复杂,系统越复杂,才能越智能。 同样,人工智能的发展依…...

NVMe 2.0 Boot Partitions:解锁高效固件更新的双分区机制
1. 为什么我们需要NVMe 2.0的双启动分区? 想象一下你正在给手机升级系统,突然断电了——传统单分区方案会让设备直接变砖,而NVMe 2.0的双启动分区就像给系统上了双保险。这个设计最初是为了解决企业级SSD在724小时运行时的固件更新难题&#…...

Aria2磁力链接下载进阶技巧:多文件选择与限速设置详解
Aria2磁力链接下载进阶技巧:多文件选择与限速设置详解 在数字资源获取日益便捷的今天,高效下载工具成为技术爱好者和专业人士的必备利器。Aria2作为一款轻量级、多协议支持的命令行下载工具,凭借其强大的功能和灵活的配置选项,在L…...

3个维度玩转League-Toolkit:从入门到精通的实战指南
3个维度玩转League-Toolkit:从入门到精通的实战指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是…...

3个秘诀彻底解决机械键盘连击问题:Keyboard Chatter Blocker全攻略
3个秘诀彻底解决机械键盘连击问题:Keyboard Chatter Blocker全攻略 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 机械键盘…...

终极指南:Laravel DataTables 性能优化实战——不同场景下的表现对比
终极指南:Laravel DataTables 性能优化实战——不同场景下的表现对比 【免费下载链接】laravel-datatables jQuery DataTables API for Laravel 4|5|6|7|8|9|10 项目地址: https://gitcode.com/gh_mirrors/la/laravel-datatables Laravel DataTables 是一款强…...

戴尔DELL笔记本Ubuntu24.04与Windows11双系统共存:从分区到引导的完整避坑指南
1. 准备工作:磁盘分区与系统盘制作 第一次在戴尔笔记本上装双系统时,我对着磁盘管理界面发呆了半小时——既怕误删Windows分区,又担心空间分配不合理。后来发现,只要掌握几个关键点,整个过程比想象中简单得多。 先说说…...

如何用开源工具实现3D打印钥匙自由?从参数测量到模型生成的实践路径
如何用开源工具实现3D打印钥匙自由?从参数测量到模型生成的实践路径 【免费下载链接】keygen OpenSCAD tools for generating physical keys 项目地址: https://gitcode.com/gh_mirrors/ke/keygen 在数字化制造蓬勃发展的今天,3D打印技术正逐步走…...

【大英赛】2009-2026年大英赛ABCD类历年真题、样卷、听力音频及答案PDF电子版
2026年大英赛将于4月12日9:00—11:00举行,开始倒计时啦!小编整理了最新的2009-2026年大学生英语竞赛(大英赛NECCS)ABCD类历年真题、样卷、听力音频及答案解析,PDF电子版,可下载打印! 资料下载&a…...

4象限解析OpenRocket:开源火箭仿真工具的技术突破与实践指南
4象限解析OpenRocket:开源火箭仿真工具的技术突破与实践指南 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 在模型火箭设计领域,物…...