ElasticSearch-第二天
目录
文档批量操作
批量获取文档数据
批量操作文档数据
DSL语言高级查询
DSL概述
无查询条件
叶子条件查询
模糊匹配
match的复杂用法
精确匹配
组合条件查询(多条件查询)
连接查询(多文档合并查询)
查询DSL和过滤DSL
区别
query DSL
filter DSL
Query方式查询:案例
term
match
multi_match
query_string
范围查询
分页、输出字段、排序综合查询
Filter Context 对数据进行过滤
总结
match
term
match_phase
query_string
文档映射
动态映射
静态映射
核心类型(Core datatype)
keyword 与 text 映射类型的区别
创建静态映射时指定text类型的ik分词器
设置ik分词器的文档映射
分词查询
对已存在的mapping映射进行修改
Elasticsearch乐观并发控制
悲观并发控制
乐观并发控制
举例
ES集群环境搭建
将安装包分发到其他服务器上面
修改elasticsearch.yml
修改jvm.option
node2与node3修改es配置文件
文档批量操作
这个不用看,看DSL语言哪个就行
这里多个文档是指,批量操作多个文档
批量获取文档数据
批量获取文档数据是通过_mget的API来实现的
在URL中不指定index和type
- 请求方式:GET
- 请求地址:_mget
- 功能说明 : 可以通过ID批量获取不同index和type的数据
- 请求参数:
- docs : 文档数组参数
- _index : 指定index
- _source : 指定要查询的字段
- _id : 指定id
- _type : 指定type
- docs : 文档数组参数
GET _mget
{"docs": [{"_index": "es_db","_type": "_doc","_id": 1},{"_index": "es_db","_type": "_doc","_id": 2}]
}响应结果如下:
{"docs" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_version" : 3,"_seq_no" : 7,"_primary_term" : 1,"found" : true,"_source" : {"name" : "张三666","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "2","_version" : 1,"_seq_no" : 1,"_primary_term" : 1,"found" : true,"_source" : {"name" : "李四","sex" : 1,"age" : 28,"address" : "广州荔湾大厦","remark" : "java assistant"}}]
}在URL中指定index
- 请求方式:GET
- 请求地址:/{{indexName}}/_mget
- 功能说明 : 可以通过ID批量获取不同index和type的数据
- 请求参数:
- docs : 文档数组参数
- _index : 指定index
- _source : 指定要查询的字段
- _id : 指定id
- _type : 指定type
- docs : 文档数组参数
GET / es_db / _mget
{"docs": [{"_type": "_doc","_id": 3},{"_type": "_doc","_id": 4}]
}在URL中指定index和type
- 请求方式:GET
- 请求地址:/{{indexName}}/{{typeName}}/_mget
- 功能说明 : 可以通过ID批量获取不同index和type的数据
- 请求参数:
- docs : 文档数组参数
- _index : 指定index
- _source : 指定要查询的字段
- _id : 指定id
- _type : 指定type
- docs : 文档数组参数
GET / es_db / _doc / _mget
{"docs": [{"_id": 1},{"_id": 2}]
}批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
- 第一行参数为指定操作的类型及操作的对象(index,type和id)
- 第二行参数才是操作的数据
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}- actionName:表示操作类型,主要有create,index,delete和update
批量创建文档create
POST _bulk {"create": {"_index": "article","_type": "_doc","_id": 3}
} {"id": 3,"title": "白起老师1","content": "白起老师666","tags": ["java", "面向对象"],"create_time": 1554015482530
} {"create": {"_index": "article","_type": "_doc","_id": 4}
} {"id": 4,"title": "白起老师2","content": "白起老师NB","tags": ["java", "面向对象"],"create_time": 1554015482530
}普通创建或全量替换index
POST _bulk {"index": {"_index": "article","_type": "_doc","_id": 3}
} {"id": 3,"title": "图灵徐庶老师(一)","content": "图灵学院徐庶老师666","tags": ["java", "面向对象"],"create_time": 1554015482530
} {"index": {"_index": "article","_type": "_doc","_id": 4}
} {"id": 4,"title": "图灵诸葛老师(二)","content": "图灵学院诸葛老师NB","tags": ["java", "面向对象"],"create_time": 1554015482530
}- 如果原文档不存在,则是创建
- 如果原文档存在,则是替换(全量修改原文档)
批量删除delete
POST _bulk {"delete": {"_index": "article","_type": "_doc","_id": 3}
} {"delete": {"_index": "article","_type": "_doc","_id": 4}
}批量修改update
POST _bulk {"update": {"_index": "article","_type": "_doc","_id": 3}
} {"doc": {"title": "ES大法必修内功"}
} {"update": {"_index": "article","_type": "_doc","_id": 4}
} {"doc": {"create_time": 1554018421008}
}DSL语言高级查询
DSL概述
Domain Specific Language:领域专用语言
Elasticsearch provides a ful1 Query DSL based on JSON to define queries
Elasticsearch提供了基于JSON的DSL来定义查询。
DSL由叶子查询子句和复合查询子句两种子句组成。

无查询条件
无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有
GET / es_db / _doc / _search
{"query": {"match_all": {}}
}叶子条件查询
模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现
- match : 通过match关键词模糊匹配条件内容
- prefix : 前缀匹配
- regexp : 通过正则表达式来匹配数据
match的复杂用法
match条件还支持以下参数:
- query : 指定匹配的值
- operator : 匹配条件类型
- and : 条件分词后都要匹配
- or : 条件分词后有一个匹配即可(默认)
- minmum_should_match : 指定最小匹配的数量
精确匹配
- term : 单个条件相等
- terms : 单个字段属于某个值数组内的值
- range : 字段属于某个范围内的值
- exists : 某个字段的值是否存在
- ids : 通过ID批量查询
组合条件查询(多条件查询)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件
- bool : 各条件之间有and,or或not的关系
- must : 各个条件都必须满足,即各条件是and的关系
- should : 各个条件有一个满足即可,即各条件是or的关系
- must_not : 不满足所有条件,即各条件是not的关系
- filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高
- constant_score : 不计算相关度评分
must/filter/shoud/must_not 等的子条件是通过 term/terms/range/ids/exists/match 等叶子条件为参数的
注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当是多个条件时,对应的是一个数组
连接查询(多文档合并查询)
- 父子文档查询:parent/child
- 嵌套文档查询: nested
查询DSL和过滤DSL
区别

query DSL
在查询上下文中,查询会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?”
如何验证匹配很好理解,如何计算相关度呢?ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。
filter DSL
在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”
答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
过滤上下文 是在使用filter参数时候的执行环境,比如在bool查询中使用must_not或者filter
另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
Query方式查询:案例
term
根据名称精确查询姓名 term, term查询不会对字段进行分词查询,会采用精确匹配
注意: 采用term精确查询, 查询字段映射类型属于为keyword.
举例:
POST / es_db / _doc / _search
{"query": {"term": {"name": "admin"}}
}match
根据备注信息模糊查询 match, match会根据该字段的分词器,进行分词查询
举例:
POST / es_db / _doc / _search
{"from": 0,"size": 2,"query": {"match": {"address": "广州"}}
}multi_match
多字段模糊匹配查询与精准查询 multi_match
POST / es_db / _doc / _search
{"query": {"multi_match": {"query": "张三","fields": ["address", "name"]}}
}query_string
- 未指定字段条件查询 query_string , 含 AND 与 OR 条件
POST / es_db / _doc / _search
{"query": {"query_string": {"query": "广州 OR 长沙"}}
}- 指定字段条件查询 query_string , 含 AND 与 OR 条件
POST / es_db / _doc / _search
{"query": {"query_string": {"query": "admin OR 长沙","fields": ["name", "address"]}}
}范围查询
注:json请求字符串中部分字段的含义
range:范围关键字
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时间
POST / es_db / _doc / _search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}分页、输出字段、排序综合查询
POST / es_db / _doc / _search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}},"from": 0,"size": 2,"_source": ["name", "age", "book"], // 显示哪几个字段"sort": {"age": "desc" // 排序字段}
}Filter Context 对数据进行过滤
Filter过滤器方式查询,它的查询不会计算相关性分值,也不会对结果进行排序, 因此效率会高一点,查询的结果可以被缓存。
POST / es_db / _doc / _search
{"query": {"bool": {"filter": {"term": {"age": 25}}}}
}总结
match
match:模糊匹配,需要指定字段名,但是输入会进行分词,比如"hello world"会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
term
term: 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询"hello world",结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有"hello world"的字样,而不是查询字段中包含"hello world"的字样。当保存数据"hello world"时,elasticsearch会对字段内容进行分词,"hello world"会被分成hello和world,不存在"hello world",因此这里的查询结果会为空。这也是term查询和match的区别。
match_phase
match_phase:会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以"hello world"为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that world不满足,world hello也不满足条件。
query_string
query_string:和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛
文档映射
ES中映射可以分为动态映射和静态映射
动态映射
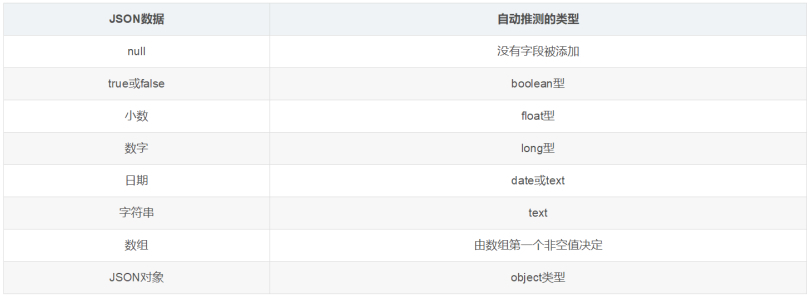
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下:
删除原创建的索引:DELETE /es_db
创建索引:PUT /es_db
创建文档(ES根据数据类型, 会自动创建映射)
PUT / es_db / _doc / 1
{"name": "Jack","sex": 1,"age": 25,"book": "java入门至精通","address": "广州小蛮腰"
}获取文档映射:GET /es_db/_mapping
静态映射
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射
设置文档映射
PUT / es_db {"mappings": {"properties": {"name": {"type": "keyword","index": true,"store": true},"sex": {"type": "integer","index": true,"store": true},"age": {"type": "integer","index": true,"store": true},"book": {"type": "text","index": true,"store": true},"address": {"type": "text","index": true,"store": true}}}
}核心类型(Core datatype)
字符串:string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索。
数值型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
keyword 与 text 映射类型的区别
将 book 字段设置为 keyword 映射 (只能精准查询, 不能分词查询,能聚合、排序)
将 book 字段设置为 text 映射能模糊查询, 能分词查询,不能聚合、排序
POST / es_db / _doc / _search
{"query": {"term": {"book": "elasticSearch入门至精通"}}
}创建静态映射时指定text类型的ik分词器
设置ik分词器的文档映射
- 先删除之前的es_db
- 再创建新的es_db
- 定义ik_smart的映射
PUT / es_db
{"mappings": {"properties": {"name": {"type": "keyword","index": true,"store": true},"sex": {"type": "integer","index": true,"store": true},"age": {"type": "integer","index": true,"store": true},"book": {"type": "text","index": true,"store": true,"analyzer": "ik_smart","search_analyzer": "ik_smart"},"address": {"type": "text","index": true,"store": true}}}
}分词查询
POST / es_db / _doc / _search
{"query": {"match": {"address": "广"}}
}POST / es_db / _doc / _search {"query": {"match": {"address": "广州"}}
}对已存在的mapping映射进行修改
具体方法
1)如果要推倒现有的映射, 你得重新建立一个静态索引
2)然后把之前索引里的数据导入到新的索引里
3)删除原创建的索引
4)为新索引起个别名, 为原索引名
POST _reindex // 命令
{"source": {"index": "db_index" // 来源数据},"dest": {"index": "db_index_2" //目标数据}
}DELETE /db_index // 删除原来的索引PUT /db_index_2 /_alias /db_index // 对新建的索引重新命名注意: 通过这几个步骤就实现了索引的平滑过渡,并且是零停机
Elasticsearch乐观并发控制
在数据库领域中,有两种方法来确保并发更新,不会丢失数据:
悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
举例
再以创建一个文档为例 ES老版本
PUT /db_index /_doc /1
{"name": "Jack","sex": 1,"age": 25,"book": "Spring Boot 入门到精通","remark": "hello world"
}实现_version乐观锁更新文档,根据版本去查询
PUT /db_index /_doc /1?version=1
{"name": "Jack","sex": 1,"age": 25,"book": "Spring Boot 入门到精通","remark": "hello world"
}ES新版本(7.x)不使用version进行并发版本控制 if_seq_no=版本值&if_primary_term=文档位置
- _seq_no:文档版本号,作用同_version
- _primary_term:文档所在位置
POST /es_sc/_searchDELETE /es_scPOST /es_sc/_doc/1
{"id": 1,"name": "图灵学院","desc": "图灵学院白起老师","create_date": "2021-02-24"
}POST /es_sc/_update/1
{"doc": {"name": "图灵教育666"}
}// 下面这两个有一个能执行成功,一个执行不成功,因为seq_no版本号变了
POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{"doc": {"name": "图灵学院1"}
}POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{"doc": {"name": "图灵学院2"}
}ES集群环境搭建
将安装包分发到其他服务器上面
修改elasticsearch.yml
node1.baiqi.cn 服务器使用baiqi用户来修改配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/datacd /usr/local/es/elasticsearch-7.6.1/configrm -rf elasticsearch.ymlvim elasticsearch.yml
cluster.name: baiqi-es
node.name: node1.baiqi.cn
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node1.baiqi.cn
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小
node1.baiqi.cn使用baiqi用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2gnode2与node3修改es配置文件
node2.baiqi.cn与node3.baiqi.cn也需要修改es配置文件
node2.baiqi.cn使用baiqi用户执行以下命令修改es配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/datacd /usr/local/es/elasticsearch-7.6.1/configvim elasticsearch.yml
cluster.name: baiqi-es
node.name: node2.baiqi.cn
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node2.baiqi.cn
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"node3.baiqi.cn使用baiqi用户执行以下命令修改配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/datacd /usr/local/es/elasticsearch-7.6.1/configvim elasticsearch.yml
cluster.name: baiqi-es
node.name: node3.baiqi.cn
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node3.baiqi.cn
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"查看集群状态:
GET _cat/nodes?v
GET _cat/health?v相关文章:
ElasticSearch-第二天
目录 文档批量操作 批量获取文档数据 批量操作文档数据 DSL语言高级查询 DSL概述 无查询条件 叶子条件查询 模糊匹配 match的复杂用法 精确匹配 组合条件查询(多条件查询) 连接查询(多文档合并查询) 查询DSL和过滤DSL 区别 query DSL filter DSL Query方式查…...
【AI大比拼】文心一言 VS ChatGPT-4
摘要:本文将对比分析两款知名的 AI 对话引擎:文心一言和 OpenAI 的 ChatGPT,通过实际案例让大家对这两款对话引擎有更深入的了解,以便大家选择合适的 AI 对话引擎。 亲爱的 CSDN 朋友们,大家好!近年来&…...

美团笔试-3.18
1、捕获敌人 小美在玩一项游戏。该游戏的目标是尽可能抓获敌人。 敌人的位置将被一个二维坐标 (x, y) 所描述。 小美有一个全屏技能,该技能能一次性将若干敌人一次性捕获。 捕获的敌人之间的横坐标的最大差值不能大于A,纵坐标的最大差值不能大于B。 现在…...

【12】SCI易中期刊推荐——计算机信息系统(中科院4区)
🚀🚀🚀NEW!!!SCI易中期刊推荐栏目来啦 ~ 📚🍀 SCI即《科学引文索引》(Science Citation Index, SCI),是1961年由美国科学信息研究所(Institute for Scientific Information, ISI)创办的文献检索工具,创始人是美国著名情报专家尤金加菲尔德(Eugene Garfield…...

好不容易约来了一位程序员来面试,结果人家不做笔试题
感觉以后还是不要出面试题这环节好了。好不容易约来了一位程序员来面试。刚递给他一份笔试题,他一看到要做笔试题,说不做笔试题,有问题面谈就好了,搞得我有点尴尬,这位应聘者有3年多工作经验。关于程序员岗位ÿ…...

这几个过时Java技术不要再学了
Java 已经发展了近20年,极其丰富的周边框架打造了一个繁荣稳固的生态圈。 Java现在不仅仅是一门语言,而且还是一整个生态体系,实在是太庞大了,从诞生到现在,有无数的技术在不断的推出,也有很多技术在不断的…...

EEPROM芯片(24c02)使用详解(I2C通信时序分析、操作源码分析、原理图分析)
1、前言 (1)本文主要是通过24c02芯片来讲解I2C接口的EEPROM操作方法,包含底层时序和读写的代码; (2)大部分代码是EEPROM芯片通用的,但是其中关于某些时间的要求,是和具体芯片相关的,和主控芯片和外设芯片都有关系&…...
Django4.0新特性-主要变化
Django 4.0于2021年12月正式发布,标志着Django 4.X时代的来临。参考Django 4.0 release notes | Django documentation | Django Python 兼容性 Django 4.0 将支持 Python 3.8、3.9 与 3.10。强烈推荐并且仅官方支持每个系列的最新版本。 Django 3.2.x 系列是最后…...

MySQL高级面试题整理
1. 执行流程 mysql客户端先与服务器建立连接Sql语句通过解析器形成解析树再通过预处理器形成新解析树,检查解析树是否合法通过查询优化器将其转换成执行计划,优化器找到最适合的执行计划执行器执行sql 2. MYISAM和InNoDB的区别 MYISAM:不支…...

【Java】面向对象三大基本特征
【Java】面向对象三大基本特征 1.封装 On Java 8:研发程序员开发一个工具类,该工具类仅向应用程序员公开必要的内容,并隐藏内部实现的细节。这样可以有效地避免该工具类被错误的使用和更改,从而减少程序出错的可能。彼此职责划分清晰&#x…...
蓝桥杯C++组怒刷50道真题(填空题)
🌼深夜伤感网抑云 - 南辰Music/御小兮 - 单曲 - 网易云音乐 🌼多年后再见你 - 乔洋/周林枫 - 单曲 - 网易云音乐 18~22年真题,50题才停更,课业繁忙,有空就更,2023/3/18/23:01写下 目录 👊填…...

Shell自动化管理 for ORACLE DBA
1.自动收集每天早上9点到晚上8点之间的AWR报告。 auto_awr.sh #!/bin/bash# Set variables ORACLE_HOME/u01/app/oracle/product/12.1.0/dbhome_1 ORACLE_SIDorcl AWR_DIR/home/oracle/AWR# Set date format for file naming DATE$(date %Y%m%d%H%M%S)# Check current time - …...
Unity学习日记13(画布相关)
目录 创建画布 对画布的目标图片进行射线检测 拉锚点 UI文本框使用 按钮 按钮导航 按钮触发事件 输入框 实现单选框 下拉菜单 多选框选项加图片 创建画布 渲染模式 第一个,保持画布在最前方,画布内的内容显示优先级最高。 第二个,…...

初阶C语言:冒泡排序
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。1.冒泡排序关于冒泡排序我们在讲…...

带头双向循环链表
在前面我们学习了单链表,发现单链表还是有一些不够方便,比如我们要尾插,需要遍历一遍然后找到它的尾,这样时间复炸度就为O(N),现在我们引入双向带头链表就很方便了,我们先看看它的结构。通过观察,我们发现一…...

C#中的DataGridView中添加按钮并操作数据
背景:最近在项目中有需求需要在DataGridView中添加“删除”、“修改”按钮,用来对数据的操作以及显示。 在DataGridView中显示需要的按钮 首先在DataGridView中添加需要的列,此列是用来存放按钮的。 然后在代码中“画”按钮。 if (e.Column…...

WEB安全 PHP基础
WEB安全 PHP基础 PHP简述 PHP(全称:PHP:Hypertext Preprocessor,即"PHP:超文本预处理器")是一种通用开源脚本语言。 在一个php文件中可以包括以下内容: PHP 文件可包含文本、HTML、…...
基础篇:07-Nacos注册中心
1.Nacos安装部署 1.1 下载安装 nacos官网提供了安装部署教程,其下载链接指向github官网,选择合适版本即可。如访问受阻可直接使用以下最新稳定版压缩包:📎nacos-server-2.1.0.zip,后续我们也可能会更改为其他版本做更…...
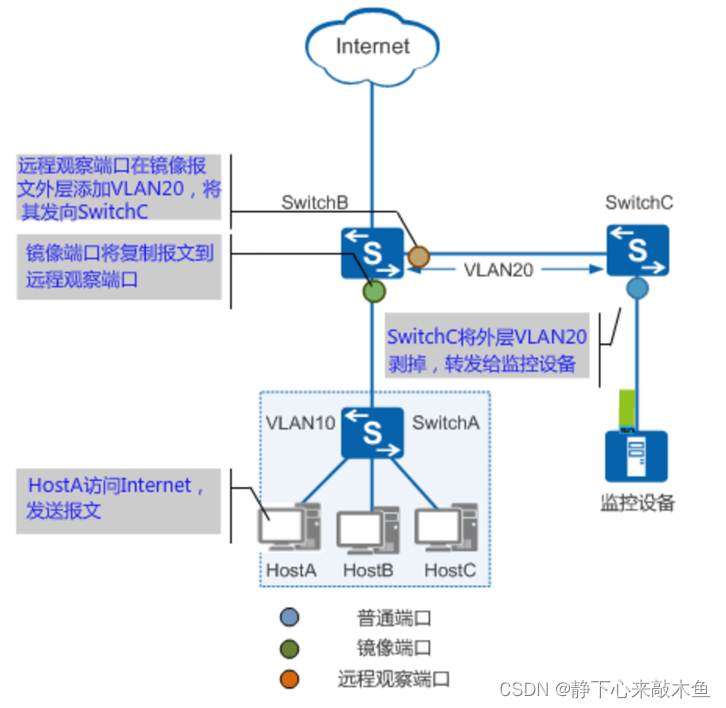
端口镜像讲解
目录 端口类型 镜像方向 观察端口位置 端口镜像实现方式 流镜像 Vlan镜像 MAC镜像 配置端口镜像 配置本地观察端口 配置远程流镜像(基于流镜像) 端口镜像是指将经过指定端口的报文复制一份到另一个指定端口,便于业务监控和故障定位…...
图形视图框架QGraphicsScene(场景,概念)
QGraphicsScene 该类充当 QGraphicsItems 的容器。它与 QGraphicsView 一起使用,用于在 2D 表面上可视化图形项目,例如线条、矩形、文本甚至自定义项目。 QGraphicsScene具有的功能: 提供用管理大量数据项的高速接口传播事件到每一个图形项…...

LoRa Feather固件设计:ESP32-S3多外设协同与低功耗调度
1. 项目概述“LoRa Feather”并非一个官方发布的标准化嵌入式库,而是由开发者基于 Adafruit LoRa FeatherWing(如 RFM95W/RFM96W 模块)与 ESP32-S3(特别是带 TFT 显示屏的 Adafruit Feather ESP32-S3 Reverse)硬件平台…...

GeoServer REST API实战:手把手教你用Python封装自己的批量发布工具
GeoServer REST API深度封装:Python自动化发布框架设计与实战 1. 为什么需要自定义GeoServer发布工具? 在GIS项目实施过程中,我们经常面临数百个地理数据文件需要快速发布的场景。传统手动操作不仅效率低下(单个文件平均耗时2分钟…...

ROS2编译报错CMake未找到diagnostic_updater:从诊断工具缺失到精准安装
1. 当CMake告诉你找不到diagnostic_updater时发生了什么 第一次看到这个报错的时候,我也是一头雾水。明明代码是从GitHub上clone下来的标准功能包,怎么一编译就报错呢?那个红色的"CMake Error"特别扎眼,就像开车时突然亮…...

保姆级教程:在Windows上用Python 3.10.7一键部署SenseVoice语音识别API
Windows平台Python 3.10.7环境下的SenseVoice语音识别API全流程部署指南 语音识别技术正在改变我们与设备交互的方式。对于开发者而言,快速搭建一个可靠的语音识别服务是许多AI应用开发的第一步。SenseVoice作为开源的语音识别解决方案,以其轻量级和易用…...
的自动化部署)
别再用手动执行SQL了!用SpringBoot + Flyway搞定多数据库(MySQL/Oracle/PostgreSQL)的自动化部署
SpringBoot Flyway:多数据库自动化部署的终极解决方案 当你的产品需要同时支持MySQL、Oracle和PostgreSQL三种数据库时,最头疼的问题是什么?是每次部署都要手动执行不同的SQL脚本,还是担心不同环境下数据库结构不一致导致的诡异b…...

突破工厂建设瓶颈:FactoryBluePrints蓝图库带来的自动化生产革命
突破工厂建设瓶颈:FactoryBluePrints蓝图库带来的自动化生产革命 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints FactoryBluePrints是戴森球计划的开源工厂蓝图…...

Altium Designer 实战指南:高效创建与优化PCB封装库
1. Altium Designer封装库基础入门 刚接触PCB设计时,我最头疼的就是封装库的创建。记得第一次画板子,因为电阻封装画错导致整批板子返工,那种挫败感至今难忘。现在用Altium Designer做封装就像搭积木一样简单,关键是要掌握正确的方…...

从v4l2-ctl命令到media拓扑:手把手教你调试RK3568上的OV8858摄像头图像
RK3568平台OV8858摄像头深度调试实战:从硬件链路到图像优化的全流程解析 当你在RK3568平台上调试OV8858摄像头时,是否遇到过这样的场景:设备树配置看似正确,但摄像头输出的图像却出现花屏、颜色异常或干脆没有信号?作为…...

打破游戏边界:Sunshine构建你的无缝云游戏体验
打破游戏边界:Sunshine构建你的无缝云游戏体验 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下这样的场景:你在客厅的智能电视上玩着3A大作&#x…...
)
从零上手平头哥剑池CDK:手把手教你搭建第一个RISC-V调试工程(附断点设置技巧)
从零上手平头哥剑池CDK:手把手教你搭建第一个RISC-V调试工程(附断点设置技巧) 第一次接触RISC-V架构和平头哥的开发环境,难免会有些无从下手。作为一个过来人,我清楚地记得当初为了跑通第一个调试工程,花了…...