第100+18步 ChatGPT学习:R实现SVM分类
基于R 4.2.2版本演示
一、写在前面
有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。
答曰:可!用GPT或者Kimi转一下就得了呗。
加上最近也没啥内容写了,就帮各位搬运一下吧。
二、R代码实现SVM分类
(1)导入数据
我习惯用RStudio自带的导入功能:


(2)建立SVM模型(默认参数)
# Load necessary libraries
library(caret)
library(kernlab)
library(pROC)
library(ggplot2)# Assume 'data' is your dataframe containing the data
# Set seed to ensure reproducibility
set.seed(123)# Split data into training and validation sets (80% training, 20% validation)
trainIndex <- createDataPartition(data$X, p = 0.8, list = FALSE)
trainData <- data[trainIndex, ]
validData <- data[-trainIndex, ]# Train the SVM model
svmModel <- ksvm(X ~ ., data = trainData, type = "C-svc", kernel = "rbfdot", prob.model = TRUE)# Predict on the training and validation sets
trainPredict <- predict(svmModel, trainData, type = "probabilities")[,1]
validPredict <- predict(svmModel, validData, type = "probabilities")[,1]# Convert predictions to binary using 0.5 as threshold
trainPredictBinary <- ifelse(trainPredict > 0.5, 1, 0)
validPredictBinary <- ifelse(validPredict > 0.5, 1, 0)# Compute ROC objects
trainRoc <- roc(response = as.numeric(trainData$X) - 1, predictor = trainPredict)
validRoc <- roc(response = as.numeric(validData$X) - 1, predictor = validPredict)# Plot ROC curves using ggplot2
trainRocPlot <- ggplot(data = data.frame(fpr = 1 - trainRoc$specificities, tpr = trainRoc$sensitivities), aes(x = fpr, y = tpr)) +geom_line(color = "blue") +geom_area(aes(ifelse(fpr <= 1, fpr, NA)), fill = "blue", alpha = 0.2) +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Training ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.1, label = paste("Training AUC =", round(auc(trainRoc), 2)), hjust = 0.5, color = "blue")validRocPlot <- ggplot(data = data.frame(fpr = 1 - validRoc$specificities, tpr = validRoc$sensitivities), aes(x = fpr, y = tpr)) +geom_line(color = "red") +geom_area(aes(ifelse(fpr <= 1, fpr, NA)), fill = "red", alpha = 0.2) +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Validation ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.2, label = paste("Validation AUC =", round(auc(validRoc), 2)), hjust = 0.5, color = "red")# Display plots
print(trainRocPlot)
print(validRocPlot)# Calculate confusion matrices based on 0.5 cutoff for probability
confMatTrain <- table(trainData$X, trainPredict >= 0.5)
confMatValid <- table(validData$X, validPredict >= 0.5)# Function to plot confusion matrix using ggplot2
plot_confusion_matrix <- function(conf_mat, dataset_name) {conf_mat_df <- as.data.frame(as.table(conf_mat))colnames(conf_mat_df) <- c("Actual", "Predicted", "Freq")p <- ggplot(data = conf_mat_df, aes(x = Predicted, y = Actual, fill = Freq)) +geom_tile(color = "white") +geom_text(aes(label = Freq), vjust = 1.5, color = "black", size = 5) +scale_fill_gradient(low = "white", high = "steelblue") +labs(title = paste("Confusion Matrix -", dataset_name, "Set"), x = "Predicted Class", y = "Actual Class") +theme_minimal() +theme(axis.text.x = element_text(angle = 45, hjust = 1), plot.title = element_text(hjust = 0.5))print(p)
}# Now call the function to plot and display the confusion matrices
plot_confusion_matrix(confMatTrain, "Training")
plot_confusion_matrix(confMatValid, "Validation")# 提取混淆矩阵的值,确保它们的命名与你的混淆矩阵布局一致
fp_train <- confMatTrain[1, 1]
tn_train <- confMatTrain[1, 2]
tp_train <- confMatTrain[2, 1]
fn_train <- confMatTrain[2, 2]fp_valid <- confMatValid[1, 1]
tn_valid <- confMatValid[1, 2]
tp_valid <- confMatValid[2, 1]
fn_valid <- confMatValid[2, 2]# 训练集指标
acc_train <- (tp_train + tn_train) / sum(confMatTrain)
error_rate_train <- 1 - acc_train
sen_train <- tp_train / (tp_train + fn_train) # 灵敏度
sep_train <- tn_train / (tn_train + fp_train) # 特异度
precision_train <- tp_train / (tp_train + fp_train) # 精确度
F1_train <- 2 * (precision_train * sen_train) / (precision_train + sen_train)
MCC_train <- (tp_train * tn_train - fp_train * fn_train) / sqrt((tp_train + fp_train) * (tp_train + fn_train) * (tn_train + fp_train) * (tn_train + fn_train))
auc_train <- roc(response = trainData$X, predictor = trainPredict)$auc# 验证集指标
acc_valid <- (tp_valid + tn_valid) / sum(confMatValid)
error_rate_valid <- 1 - acc_valid
sen_valid <- tp_valid / (tp_valid + fn_valid) # 灵敏度
sep_valid <- tn_valid / (tn_valid + fp_valid) # 特异度
precision_valid <- tp_valid / (tp_valid + fp_valid) # 精确度
F1_valid <- 2 * (precision_valid * sen_valid) / (precision_valid + sen_valid)
MCC_valid <- (tp_valid * tn_valid - fp_valid * fn_valid) / sqrt((tp_valid + fp_valid) * (tp_valid + fn_valid) * (tn_valid + fp_valid) * (tn_valid + fn_valid))
auc_valid <- roc(response = validData$X, predictor = validPredict)$auc# Print Metrics
cat("Training Metrics\n")
cat("Accuracy:", acc_train, "\n")
cat("Error Rate:", error_rate_train, "\n")
cat("Sensitivity:", sen_train, "\n")
cat("Specificity:", sep_train, "\n")
cat("Precision:", precision_train, "\n")
cat("F1 Score:", F1_train, "\n")
cat("MCC:", MCC_train, "\n")
cat("AUC:", auc_train, "\n\n")cat("Validation Metrics\n")
cat("Accuracy:", acc_valid, "\n")
cat("Error Rate:", error_rate_valid, "\n")
cat("Sensitivity:", sen_valid, "\n")
cat("Specificity:", sep_valid, "\n")
cat("Precision:", precision_valid, "\n")
cat("F1 Score:", F1_valid, "\n")
cat("MCC:", MCC_valid, "\n")
cat("AUC:", auc_valid, "\n")结果输出(随便挑的):





效果一般般。
三、SVM调参
ksvm 函数是 kernlab 包中的一个函数,用于在 R 语言中构建和训练支持向量机(SVM)模型。以下是 ksvm 的一些主要参数和选项,这些参数允许你定制和优化SVM的训练过程:
formula:一种符号描述的模型公式,指示如何将变量应用到分析中。
data:包含数据的数据框(data frame)。
type:模型类型,包括:
"C-svc":C-支持向量分类。
"nu-svc":Nu-支持向量分类。
"C-bsvc":不平衡分类。
"spoc-svc":结构化输出和输出校正。
"kbb-svc":基于核的二进制分类。
"C-svr":C-支持向量回归。
"nu-svr":Nu-支持向量回归。
"eps-svr":ε-支持向量回归。
"C-bsvr":不平衡回归。
"lp":线性规划。
kernel:核函数类型,包括:
"rbfdot":径向基函数核。
"polydot":多项式核。
"vanilladot":线性核。
"tanhdot":双曲正切核。
"laplacedot":拉普拉斯核。
"besseldot":贝塞尔核。
"anovadot":ANOVA核。
"splinedot":样条核。
C:错误的成本,用于C-支持向量分类和回归,较大的值表示对错误的惩罚增加。一般从 0.1 到 1000,具体取值可以通过交叉验证来确定。常用的实验值包括 1, 10, 100 等。
sigma(用于 RBF 核):高斯核的宽度参数。sigma 的理想取值高度依赖于数据的分布和特征的尺度(即特征的范围或方差)。因此,没有固定的“最佳”取值范围,而是需要根据具体情况来确定。常见的做法包括:
基于数据的启发式方法:一个常见的启发式方法是将 sigma 设置为特征空间中点到点距离的中值或平均值的函数。另一种方法是将 sigma 设置为特征标准差的倒数。
试错法(Trial and Error):在实际应用中,可以通过试验一系列的 sigma 值来观察模型性能的变化。例如,可以在对数尺度上均匀尝试,如 0.01, 0.1, 1, 10 等。
degree:多项式核函数的度数。
scale:核函数的缩放参数。
offset:核函数的偏移量。
prob.model:是否计算概率估计,适用于分类任务。
cross:进行交叉验证的次数,用于模型选择和参数优化。
na.action:缺失数据的处理策略。
shrinking:是否使用启发式方法来加速计算。
tol:收敛容忍度,用于优化算法。
epsilon(用于 SVR):ε-支持向量回归中的损失函数边缘宽度。
fitted:是否返回拟合值。
scaled:是否对数据进行标准化处理。
feature.out:是否输出模型中使用的特征。
大家自个调吧,我不调了。
五、最后
至于怎么安装,自学了哈。
数据嘛:
链接:https://pan.baidu.com/s/1rEf6JZyzA1ia5exoq5OF7g?pwd=x8xm
提取码:x8xm
相关文章:
第100+18步 ChatGPT学习:R实现SVM分类
基于R 4.2.2版本演示 一、写在前面 有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。 答曰:可!用GPT或者Kimi转一下就得了呗。 加上最近也没啥内容写了,就帮各位搬运一下吧。 二、R代码实现SVM分类 (1&a…...

react函数学习——useState函数
在 React 中,useState 是一个钩子(hook),用于在函数组件中添加状态管理功能。它返回一个数组,包含两个元素: 当前状态值(selectedValue):这是状态的当前值。更新状态的函…...

方天云智慧平台系统 GetCompanyItem SQL注入漏洞复现
0x01 产品简介 方天云智慧平台系统,作为方天科技公司的重要产品,是一款面向企业全流程的业务管理功能平台,集成了ERP(企业资源规划)、MES(车间执行系统)、APS(先进规划与排程)、PLM(产品生命周期)、CRM(客户关系管理)等多种功能模块,旨在通过云端服务为企业提供…...

C语言同时在一行声明指针和整型变量
如果这么写, int *f, g; 并没有声明2个指针,编译器自己会识别,f是一个指针,g是一个整型变量; void CTszbView::OnDraw(CDC* pDC) {CTszbDoc* pDoc GetDocument();ASSERT_VALID(pDoc);// TODO: add draw code for nat…...

thinkphp框架远程代码执行
一、环境 vulfocus网上自行下载 启动命令: docker run -d --privileged -p 8081:80 -v /var/run/docker.sock:/var/run/docker.sock -e VUL_IP192.168.131.144 8e55f85571c8 一定添加--privileged不然只能拉取环境首页不显示 二、thinkphp远程代码执行 首页&a…...

【公式】博弈论中的核心算法:纳什均衡公式解析
博弈论中的核心算法:纳什均衡公式解析 纳什均衡的基本概念 纳什均衡是博弈论中的一个核心概念,它描述了一个博弈中所有参与者都无法通过单方面改变自己的策略来增加收益的状态。在纳什均衡状态下,每个参与者的策略都是对其他参与者策略的最优反应。纳什均衡的公式可以表示…...

计算机网络面试题2
WebSocket相关知识 什么是WebSocket? WebSocket是一种基于TCP连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据 WebSocket和HTTP有什么区别? 1.WebSocket是双向通信协议,HTTP是单向通信协议 2.WebSocket使用ws://或者wss:/…...

Linux网络——深入理解传入层协议TCP
目录 一、前导知识 1.1 TCP协议段格式 1.2 TCP全双工本质 二、三次握手 2.1 标记位 2.2 三次握手 2.3 捎带应答 2.4 标记位 RST 三、四次挥手 3.1 标记位 FIN 四、确认应答(ACK)机制 五、超时重传机制 六 TCP 流量控制 6.1 16位窗口大小 6.2 标记位 PSH 6.3 标记…...

快速搞定分布式RabbitMQ---RabbitMQ进阶与实战
本篇内容是本人精心整理;主要讲述RabbitMQ的核心特性;RabbitMQ的环境搭建与控制台的详解;RabbitMQ的核心API;RabbitMQ的高级特性;RabbitMQ集群的搭建;还会做RabbitMQ和Springboot的整合;内容会比较多&#…...
)
5万字长文吃透快手大数据面试题及参考答案(持续更新)
目录 Flink为什么用aggregate()不用process() 为什么使用aggregate() 为什么不用process() 自定义UDF, UDTF实现步骤,有哪些方法?UDTF中的ObjectInspector了解吗? 自定义UDF实现步骤 自定义UDTF实现步骤 UDTF中的ObjectInspector Spark Streaming和Flink的区别 Flu…...

WordPress原创插件:启用关闭经典编辑器和小工具
WordPress原创插件:启用关闭经典编辑器和小工具 主要功能 如图所示,用于启用或禁用经典编辑器和经典小工具,以替代Gutenberg编辑器。 插件下载 https://download.csdn.net/download/huayula/89592822...

萝卜快跑:自动驾驶的先锋与挑战
萝卜快跑:自动驾驶的先锋与挑战 萝卜快跑作为自动驾驶领域的重要参与者,被视为自动驾驶的先锋。它代表了自动驾驶技术在实际应用中的重要突破,为人们的出行方式带来了革新。萝卜快跑的发展展示了自动驾驶技术的巨大潜力,如提高交通…...

得到xml所有label 名字和数量 get_xml_lab.py,get_json_lab.py
import os import xml.etree.ElementTree as ETrootdir2 r"F:\images3\xmls" file_list os.listdir(rootdir2) # 列出文件夹下所有的目录与文件# 初始化字典 classes_dict {}for file_name in file_list:path os.path.join(rootdir2, file_name)if os.path.isfi…...
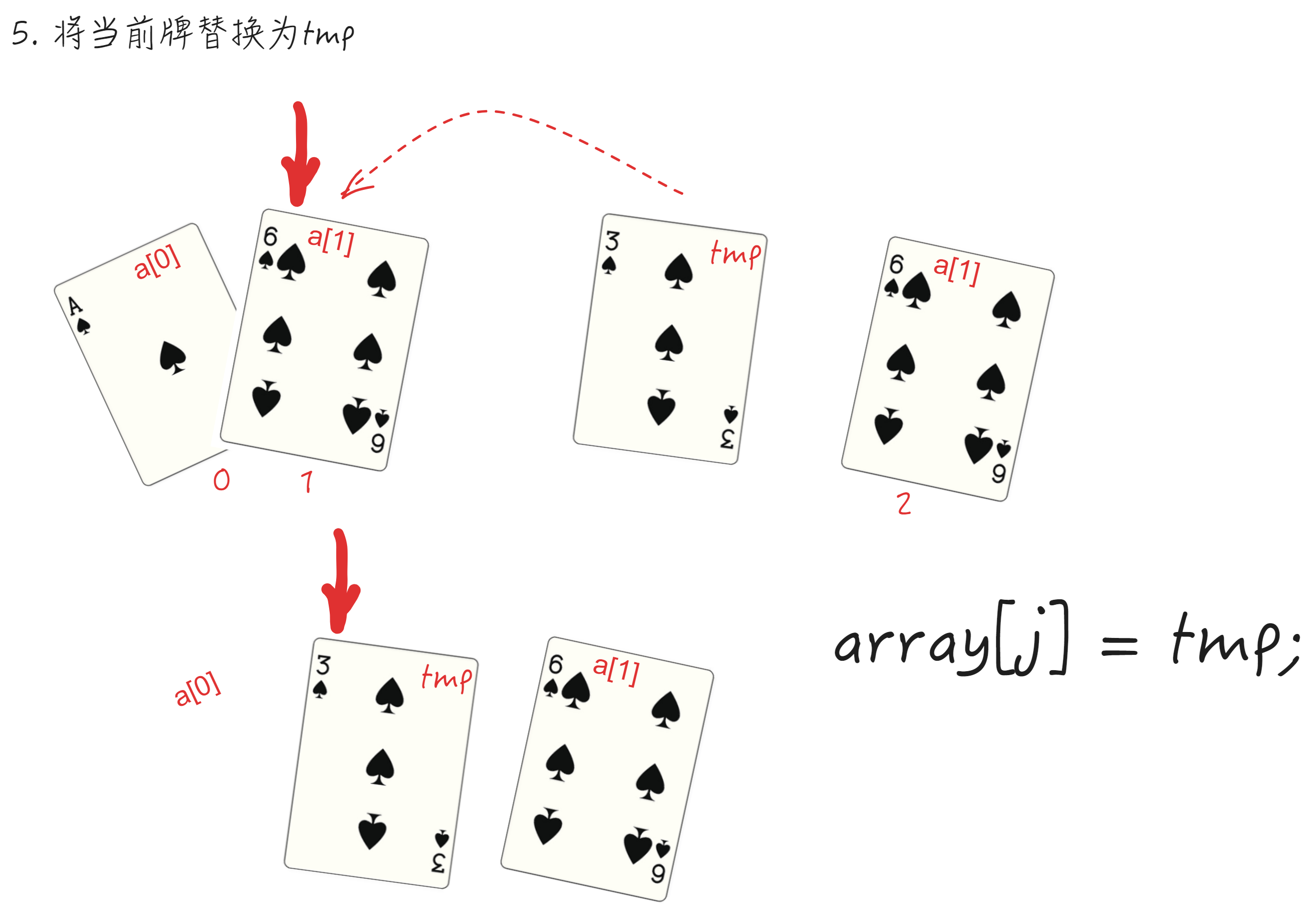
数据结构算法-排序(二)
插入排序 插入排序核心 假设数组中的一部数据已经排好序,要插入的数据和这些数据进行比较,直到找到合适的位置插入新数据。 插入排序步骤 插入排序主要有以下步骤构成: 假设有序,我们假设**a[0]**已经排好序待插入的数据为a[j]…...

Linux安装与配置
下载VMware 首先我们需要下载一个叫VMware的软件: 进入官方下载,地址:https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html选择与自己电脑版本适配的VMware版本【 输入许可证密钥 MC60H-DWHD5-H80U9-6V85…...
AI赋能交通治理:非机动车监测识别技术在城市街道安全管理中的应用
引言 城市交通的顺畅与安全是城市管理的重要组成部分。非机动车如自行车、电动车、摩托车等在城市交通中扮演着重要角色,但同时也带来了管理上的挑战。尤其是在机动车道上误入非机动车的现象,不仅影响交通秩序,还可能引发交通事故。思通数科…...

水电站泄洪放水预警广播系统解决方案
一、背景 在现代水利工程管理中,水电站泄洪放水预警广播系统扮演着至关重要的角色。这一系统不仅关系到水电站的安全运行,也直接关系到下游地区人民群众的生命财产安全。因此,设计一套完善、高效、可靠的泄洪放水预警广播系统显得尤为必要。…...

【Django】ajax和django接口交互(获取新密码)
文章目录 一、需求1. 效果图 二、实验1. 写get接口后端2. 写html后端3. 写前端4. 测试 一、需求 1. 效果图 二、实验 1. 写get接口后端 写views import string import random def getnewpwd(request):words list(string.ascii_lowercasestring.ascii_uppercasestring.digi…...

Logback 日志打印导致程序崩溃的实战分析
在软件开发和运维中,日志记录是必不可少的一环,帮我们追踪程序的行为,定位问题所在。然而,有时日志本身却可能成为问题的根源。本文将通过一个真实的案例来探讨 Logback 日志系统中的一个常见问题,当并发量大ÿ…...

新加坡 Numen Cyber 与香港光环云数据有限公司达成战略合作
新加坡本土网络安全公司 Numen Cyber 宣布与香港光环云数据有限公司(简称“光环云香港”)建立战略合作伙伴关系。此次合作将重点放在云服务器和云服务业务场景的安全领域。 Numen Cyber,作为一家致力于为客户提供专业网络安全服务和一体化安…...

PyTorch神经网络初始化实战:解决梯度消失、对称性陷阱与LSTM失谐
神经网络初始化看似只是模型训练前的一个“小动作”,但我在带团队做工业级视觉检测项目时,亲眼见过三次因初始化不当导致的全线返工:一次是产线缺陷识别模型在验证集上准确率突然掉到42%,查了三天才发现权重全初始化为0.1…...

FFXIV国际服中文汉化工具:5步实现终极中文游戏体验
FFXIV国际服中文汉化工具:5步实现终极中文游戏体验 【免费下载链接】FFXIVChnTextPatch 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIVChnTextPatch 还在为《最终幻想14》国际服的英文界面而烦恼吗?想要体验国际服的最新内容,却…...
)
告别野指针和内存泄漏:用Cppcheck给你的C/C++项目做个免费‘体检’(附VS项目集成教程)
用Cppcheck为C/C项目构建自动化代码质量防护网 在软件开发领域,代码质量直接影响着产品的稳定性和安全性。对于C/C这类系统级语言来说,内存泄漏、野指针等问题往往潜伏在代码深处,直到运行时才突然爆发。而静态代码分析工具就像一位经验丰富的…...

Microsoft Defender双零日在野利用全解析:从BlueHammer到RedSun的终端沦陷之路
前言 2026年5月20日,微软安全响应中心(MSRC)发布紧急安全公告,承认旗下Microsoft Defender存在两个已被野外利用超过一个月的零日漏洞——CVE-2026-41091与CVE-2026-45498。同日,美国国土安全部下属的网络安全与基础设施安全局(CISA)将这两个…...

Taotoken 的 Token Plan 套餐如何帮助我们预测并锁定开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 Token Plan 套餐如何帮助我们预测并锁定开发成本 作为项目管理者,确保研发预算的可预测性是保障项目平稳推…...

UPS电源部分
1.法国最好的ups 施耐德电器 美国最好的ups 伊顿 瑞士最好的ups ABB 日本最好的ups 三菱电器 台湾是 台达电子 对的吗2.施耐德电气 (Schneider Electric):虽然公司总部在法国,但其UPS业务的核心是旗下的APC(美国电力转换公司&…...

戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进
戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 在戴森球计划的工厂建设中,蓝图设计…...

别再死记硬背了!用Multisim仿真软件,5分钟搞懂三极管放大电路的静态工作点设置与失真分析
用Multisim玩转三极管放大电路:静态工作点设置与失真分析实战指南 刚接触模拟电路时,三极管放大电路就像一道难以逾越的门槛。那些密密麻麻的公式、抽象的特性曲线,让多少电子工程专业的学生在深夜实验室里抓耳挠腮。但今天,我要告…...
)
别再让串口中断拖慢你的STM32F407了!手把手教你配置UART4的DMA收发(附完整代码)
STM32F407 UART4 DMA通信实战:突破串口中断的性能瓶颈 如果你正在使用STM32F407的UART4进行数据通信,却频繁遇到系统响应迟缓的问题,很可能是因为传统的串口中断方式正在消耗大量CPU资源。每次收发一个字节都触发中断,当数据量大…...

终极网站性能优化指南:publiccode.asia 加载速度提升10个技巧
终极网站性能优化指南:publiccode.asia 加载速度提升10个技巧 【免费下载链接】publiccode.asia-legacy Website of https://publiccode.asia 项目地址: https://gitcode.com/gh_mirrors/pu/publiccode.asia-legacy 想要让你的网站像闪电一样快速加载吗&…...