Elasticsearch中的倒排索引是什么?它如何工作?
倒排索引是Elasticsearch中用于快速全文搜索的关键数据结构。它的工作原理包括:
1、索引创建: 对文档中的每个唯一单词创建一个索引条目。
2、文档列表: 每个索引条目都指向包含该单词的文档列表。
3、快速查找: 在搜索时,快速定位包含搜索词的所有文档。
Elasticsearch集群中的主节点和数据节点的角色。
在Elasticsearch集群中,主节点和数据节点有以下角色:
1、主节点: 负责集群的管理和控制,如创建或删除索引,跟踪哪些节点是活动的。
2、数据节点: 存储数据,并执行数据相关的操作,如CRUD(创建、读取、更新、删除)、搜索和聚合。
Elasticsearch是如何实现数据分片的?
Elasticsearch通过以下方式实现数据分片:
1、自动分片: 将数据自动分配到多个节点上,以实现数据的水平扩展。
2、分片策略: 支持自定义分片数量,以优化性能和资源利用。
3、副本机制: 每个分片可以有一个或多个副本,以提高数据可用性和搜索性能。
Elasticsearch中的映射(mapping)和它的重要性。
映射是Elasticsearch中定义文档如何存储和索引的过程。它的重要性包括:
1、字段类型定义: 确定每个字段的数据类型,如整数、字符串、日期等。
2、索引定制: 定制特定字段的索引方式,如全文搜索、精确值匹配。
3、优化搜索: 通过正确的映射,提高搜索操作的效率和准确性。
Elasticsearch的聚合(Aggregations)功能是什么?
聚合功能是Elasticsearch中用于提供数据统计和分析的一种强大工具。它允许用户执行复杂的数据分析,如求和、平均值、最小/最大值、直方图等。
Elasticsearch中,什么是节点(Node)和集群(Cluster)?
在Elasticsearch中:
1、节点(Node): 是集群中的一个服务器,负责存储数据并参与集群的索引和搜索功能。
2、集群(Cluster): 是多个节点的集合,它们一起工作,共享数据,并提供跨节点的联合索引和搜索功能。
Elasticsearch中文本分析的过程。
Elasticsearch中的文本分析过程包括:
1、分词(Tokenization): 将文本分解成单独的词汇或词条。
2、标准化(Normalization): 将词条转换为标准形式,如小写化。
3、过滤(Filtering): 移除停用词,应用同义词等。
4、分析器(Analyzer): 结合分词器和过滤器,对文本进行全面分析。
Elasticsearch中如何处理数据的一致性问题?
在Elasticsearch中处理数据一致性的方法包括:
1、写入确认机制: 使用写入确认(write acknowledgment)来确保数据在多个节点间正确复制。
2、版本控制: 每个文档更新都有一个版本号,帮助处理并发修改。
3、副本分配策略: 合理配置副本数量,以提高系统的容错能力。
Elasticsearch中的“近实时”(NRT)搜索是如何实现的?
Elasticsearch的“近实时”(NRT)搜索是通过以下方式实现的:
1、刷新机制: 定期执行刷新操作,使得最近的写入对搜索可见。
2、Lucene索引: 基于Lucene索引技术,提供高效的搜索能力。
3、分布式架构: 利用其分布式架构快速处理和检索大量数据。
Elasticsearch中,如何优化大量数据的索引性能?
优化Elasticsearch中大量数据的索引性能的方法包括:
1、批量操作(Bulk API): 使用批量API进行数据索引,减少网络开销和I/O操作。
2、调整刷新频率: 调整索引的刷新间隔,以减少对性能的影响。
3、硬件优化: 提高硬件性能,如使用更快的硬盘和增加内存。
相关文章:

ElasticSearch 面试题及答案整理,最新面试题
Elasticsearch中的倒排索引是什么?它如何工作? 倒排索引是Elasticsearch中用于快速全文搜索的关键数据结构。它的工作原理包括: 1、索引创建: 对文档中的每个唯一单词创建一个索引条目。 2、文档列表: 每个索引条目都指向包含该单词的文档列表。 3、快速查找: 在搜索时,…...

Java基本语法学习的案例练习
本文是在学习过C语言后,开始进行Java学习时,对于基本语法的一些案例练习。案例内容来自B站黑马编程课 1.HelloWorld 问题介绍;请编写程序输出“HelloWorld”. public class HelloWorld { public static void main(String[] args) { System.out.print…...

FPGA实现LCD12864控制
目录 注意! a) 本工程采用野火征途PRO开发板,外接LCD12864部件进行测试。 b) 有偿提供代码!!!可以定制功能!!!有需要私信!!! c) 本文测试采用…...

mysql 批量执行sql语句脚本
有时候我们需要批量执行多个数据库的创建和数据创建执行可以通过下面脚本批量创建和执行脚本。我们只需要在sql命令行或者客户端执行下面一个脚本批量创建执行多个库的创建和执行 xxxxinit.sql create user root% identified by test; mysql -h 192.168.17.7 -u root -p mysq…...

【Git】Git概述
一、Git的基本概念和特点 基本概念: 仓库(Repository):Git存储代码的基本单位,包含项目的所有文件和历史提交记录。Git支持本地仓库和远程仓库,本地仓库存储在开发者的计算机上,而远程仓库通常…...

【图解网络】学习记录
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 TCP/IP 网络模型有哪几层?键入网址到网页显示,期间发生了什么?Linux 系统是如何收发网络包的?NAPIHTTP 是什么&#…...
【Vulnhub系列】Vulnhub_Seattle_003靶场渗透(原创)
【Vulnhub系列靶场】Vulnhub_Seattle_003靶场渗透 原文转载已经过授权 原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io) 一、环境准备 1、从百度网盘下载对应靶机的.ova镜像 2、在VM中选择【打开】该.ova 3、选择存储路径࿰…...

java: 错误: 无效的源发行版:17
错误现象: java: 错误: 无效的源发行版:17 背景:在配置一个springboot项目时候,报出这个错误,错误提示信息很简单,很模糊。 排查:百度后,推测大概率就是pom文件的配置问题…...

【Python机器学习】k-近邻算法简单实践——识别手写数字
为了简化理解,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小32*32的黑白图像,并转换成文本格式 准备数据:将图像转换为测试向量 实际图像存储在trainingDigits的2000个例子和testDigits中的900个测试数据 我们…...
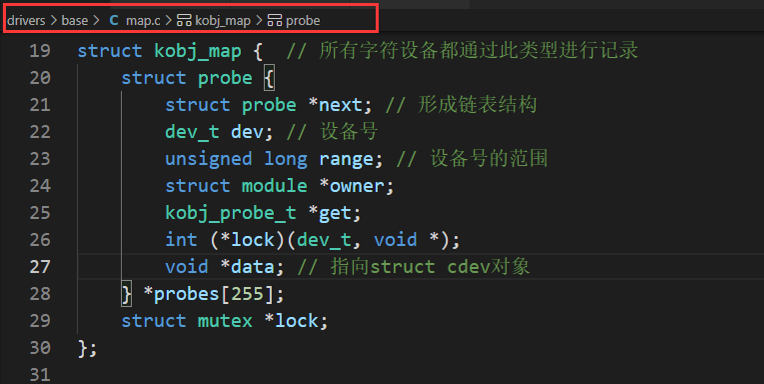
Linux源码阅读笔记14-IO体系结构与访问设备
IO体系结构 与外设通信通常称为输入输出,一般缩写为I/O。在实现外设IO的时候,内核必须处理三个可能出现的问题: 必须根据具体的设备类型和模型,使用各种方法对硬件寻址。内核必须向用户应用程序和系统工具提供访问各种设备的方法…...

只出现一次的数字-位运算
题目描述: 个人题解: 代码实现: class Solution { public:int singleNumber(vector<int>& nums) {int ret 0;for (auto e: nums) ret ^ e;return ret;} };复杂度分析: 时间复杂度:O(n),其中 n…...

pyqt designer使用spliter
1、在designer界面需要使用spliter需要父界面不使用布局,减需要分割两个模块选中,再点击spliter分割 2、在分割后,再对父界面进行布局设置 3、对于两边需要不等比列放置的,需要套一层 group box在最外层进行分割...
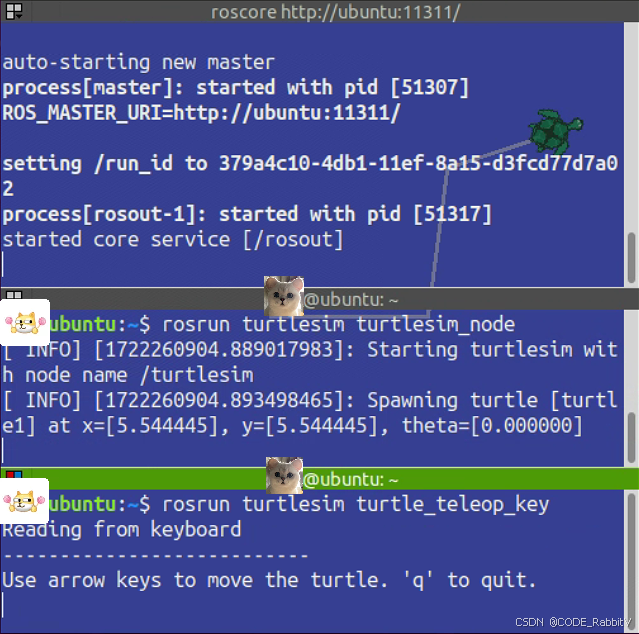
【ROS 最简单教程 002/300】ROS 集成开发环境安装 (虚拟机版): Noetic
💗 有遇到安装问题可以留言呀 ~ 当时踩了挺多坑,能帮忙解决的我会尽力 ! 1. 安装操作系统环境 Linux ❄️ VM / VirtualBox Ubuntu20.04 👉 保姆级图文安装教程指路,有经验的话 可以用如下资源自行安装 ITEMREFERENCE…...
防洪评价报告编制方法与水流数学模型建模技术
原文链接:防洪评价报告编制方法与水流数学模型建模技术https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247610610&idx2&sn432d30cb40ec36160d635603c7f22c96&chksmfa827115cdf5f803ddcaa03a21e3721d6949d6a336062bb38170e3f9d5bd4d391cc36cc…...

【Python学习手册(第四版)】学习笔记10-语句编写的通用规则
个人总结难免疏漏,请多包涵。更多内容请查看原文。本文以及学习笔记系列仅用于个人学习、研究交流。 本文较简单,5-10分钟即可阅读完成。介绍Python基本过程语句并讨论整体语法模型通用规则(冒号、省略、终止、缩进、其他特殊情况࿰…...

Flink笔记整理(五)
Flink笔记整理(五) 文章目录 Flink笔记整理(五)七、处理函数(最底层最常用最灵活)7.1基本处理函数(ProcessFunction)处理函数的功能和使用ProcessFunction解析 7.2按键分区处理函数&…...

数据分析概要【数据分析---偏企业】
各位大佬好 ,这里是阿川的博客,祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 数据分析概要前 必看 Python 初阶 Python–语言基础…...

PDF编辑器大分享,这三款加速PDF编辑!
嘿,各位办公室的小伙伴们,今儿咱们来聊聊那些让咱们文员生活变得更加轻松愉快的神器——PDF编辑器!作为每天跟文档打交道的“文字魔术师”,选对工具那可真是事半功倍啊。今天,我就从我的亲身体验出发,给大伙…...

Python --Pandas库基础方法(2)
文章目录 Pandas 变量类型的转换查看各列数据类型改变数据类型 重置索引删除行索引和切片seriesDataFrame取列按行列索引选择loc与iloc获取 isin()选择query()的使用排序用索引排序使用变量值排序 修改替换变量值对应数值的替换 数据分组基于拆分进行筛选 分组汇总引用自定义函…...

Linux驱动开发:proc接口原理、实现与调试实战
1. 项目概述:为什么需要了解proc接口?在Linux驱动开发这条路上,很多开发者朋友都曾有过这样的困惑:我的驱动模块加载成功了,设备也识别了,但怎么才能直观地看到它内部的工作状态、配置参数,或者…...

大规模集群中的ksync:性能测试与资源占用优化策略
大规模集群中的ksync:性能测试与资源占用优化策略 【免费下载链接】ksync Sync files between your local system and a kubernetes cluster. 项目地址: https://gitcode.com/gh_mirrors/ks/ksync 在当今云原生开发环境中,Kubernetes文件同步工具…...

G-Helper:释放华硕笔记本性能的免费开源轻量控制神器
G-Helper:释放华硕笔记本性能的免费开源轻量控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exp…...

3分钟掌握AlwaysOnTop:让关键窗口始终置顶的Windows神器
3分钟掌握AlwaysOnTop:让关键窗口始终置顶的Windows神器 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否曾经在编写代码时需要同时查看API文档,却被…...

Unity ShaderGraph环境搭建避坑指南:URP/HDRP渲染管线匹配
1. 为什么“环境搭建”是ShaderGraph学习路上第一个真坑 很多人点开Unity ShaderGraph教程,第一眼看到“创建Sub Graph”“连接Base Color节点”,心里一热:这不就是拖拖拽帖?比写HLSL简单多了!结果双击打开Shader Gra…...

GPT-4的1.8T参数与2%激活率:MoE架构原理与工程真相
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“大模型已突破算力瓶颈”的佐证,也常被误读为“GPT-4只用360亿参数&#x…...

从Polar靶场“中等”难度题,聊聊新手CTFer最容易踩的5个Web安全坑
从Polar靶场“中等”难度题,聊聊新手CTFer最容易踩的5个Web安全坑 当你第一次踏入CTF的Web安全领域,Polar靶场的中等难度题目就像一座看似平缓却暗藏陷阱的山峰。许多新手在这里反复跌倒,不是因为技术门槛过高,而是忽略了那些本该…...

【ChatGPT】光纤激光器及其控制系统深度拆解、信息图10张、爆炸图10张、C++代码框架增强版Mermaid 流程图、时序图、类图与成员说明
作者简介:许冲,主要分享各领域系统/设备拆解、代码框架、信息图、爆炸图。深度拆解信息图...

鸿蒙云端相册页面构建:我的相册横向滚动与空间占用模块详解
鸿蒙云端相册页面构建:我的相册横向滚动与空间占用模块详解 前言 在 HarmonyOS 6.0 应用开发中,云端相册类页面的相册管理和存储空间分析是用户深度使用的核心功能模块。本文将以“云端相册”应用中的“我的相册”横向滚动列表和“空间占用”存储分析模块…...

WireUI颜色选择器和日期选择器:提升用户体验的利器 [特殊字符][特殊字符]
WireUI颜色选择器和日期选择器:提升用户体验的利器 🎨📅 【免费下载链接】wireui TallStack UI components 项目地址: https://gitcode.com/gh_mirrors/wi/wireui WireUI颜色选择器和日期选择器是Laravel Livewire应用中提升用户体验的…...