DNS查询服务器的基本流程以及https的加密过程
DNS查询服务器的基本流程,能画出图更好,并说明为什么DNS查询为什么不直接从单一服务器查询ip,而是要经过多次查询,多次查询不会增加开销么(即DNS多级查询的优点)?
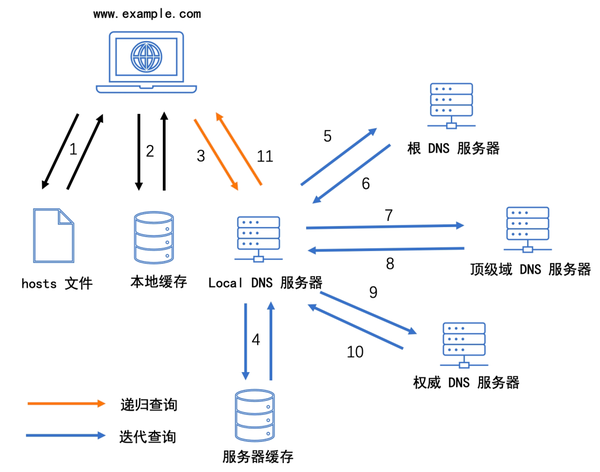
- 用户发起请求:
- 用户在浏览器中输入一个域名(如
www.example.com)。 - 浏览器将该请求发送到本地DNS解析器(通常位于用户的操作系统中)。
- 本地DNS解析器查询本地缓存:
- 本地DNS解析器首先检查其缓存中是否已有该域名的IP地址。
- 如果缓存中有有效的记录,则直接返回IP地址,流程结束。
- 查询递归DNS服务器:
- 如果本地缓存中没有记录,本地DNS解析器将请求转发给递归DNS服务器(通常由用户的ISP提供)。
- 递归DNS服务器也会检查其缓存,并在缓存未命中时进行递归查询。
- 递归DNS服务器查询根DNS服务器:
- 递归DNS服务器向根DNS服务器发送查询请求。
- 根DNS服务器不会直接返回IP地址,而是返回顶级域(如
.com)的权威DNS服务器的地址。 - 查询顶级域名(TLD)DNS服务器:
- 递归DNS服务器根据根DNS服务器的回应,向TLD DNS服务器(如
.com的权威DNS服务器)发送查询请求。 - TLD DNS服务器返回该域名的权威DNS服务器的地址。
- 查询权威DNS服务器:
- 递归DNS服务器向权威DNS服务器发送查询请求。
- 权威DNS服务器返回该域名的最终IP地址。
- 返回IP地址给用户:
- 递归DNS服务器将获得的IP地址缓存,并返回给本地DNS解析器。
- 本地DNS解析器再将IP地址返回给用户的浏览器。
- 浏览器向IP地址发送请求:
- 浏览器使用获得的IP地址与目标服务器建立连接,并请求网页内容。
使用多级查询的优点:
分布式架构提高可靠性和性能:
- 避免单点故障:如果DNS仅依赖单一服务器,当该服务器故障时,所有域名解析请求将无法完成。通过分布式架构,可以避免这种情况,提高系统的可靠性。
- 负载均衡:将查询请求分布到多个服务器上,可以有效分散负载,避免单个服务器过载,从而提高整体性能。
2. 缓存提高效率:
- 递归查询中的缓存:递归DNS服务器会缓存查询结果,这意味着后续相同的查询请求可以直接从缓存中获取,无需再次进行全程查询,显著减少查询时间和负载。
- 浏览器和操作系统缓存:本地缓存也能减少网络请求次数,加快域名解析速度。
3. 逐级查询优化管理:
- 分层结构便于管理:DNS采用层级结构(根、TLD、权威服务器),便于管理和更新。例如,根服务器只需知道TLD服务器的地址,而TLD服务器只需知道其下域名的权威服务器地址。
- 安全性:分层查询可以提高系统的安全性和抗攻击能力。攻击者难以同时攻击所有层级的服务器,从而提高系统的安全性。
4. 全球范围内的可扩展性:
- 地域分布:DNS服务器分布在全球各地,能够更快响应用户的查询请求。根服务器和TLD服务器的地理分布使得查询请求可以在用户所在区域得到快速处理,减少网络延迟。
https的加密与认证过程
- 客户端发起连接请求:
-
- 客户端向服务器发送连接请求,请求建立安全连接。这个请求是明文的 HTTP 请求,但是以
https://开头的 URL。
- 客户端向服务器发送连接请求,请求建立安全连接。这个请求是明文的 HTTP 请求,但是以
- 服务器发送数字证书:
-
- 服务器收到客户端的连接请求后,会将自己的数字证书发送给客户端。数字证书中包含了服务器的公钥以及相关的信息。
- 客户端验证证书:
-
- 客户端收到服务器的证书后,会验证证书的有效性。这包括验证证书是否由可信任的证书颁发机构(CA)签发,证书是否在有效期内,以及服务器的域名是否与证书中的域名匹配等。
- 客户端生成对称密钥:
-
- 如果服务器的证书验证通过,客户端会生成一个对称密钥(称为会话密钥),用于后续的数据加密和解密过程。
- 客户端使用服务器公钥加密对称密钥:
-
- 客户端使用服务器的公钥加密生成的对称密钥,并将其发送给服务器。这个过程是使用非对称加密算法,确保只有服务器持有的私钥可以解密这个对称密钥。
- 服务器解密对称密钥:
-
- 服务器收到客户端发送的加密密钥后,使用自己的私钥对其进行解密,得到对称密钥。
- 建立安全连接:
-
- 客户端和服务器都拥有了相同的对称密钥,它们可以使用对称密钥进行加密和解密。
- 之后的通信过程中,客户端和服务器使用对称密钥进行数据加密和解密,保障通信的安全性。
- 客户端发送加密请求:
-
- 客户端发送加密请求,包括需要访问的资源等信息。这些请求数据在传输过程中会使用对称密钥进行加密。
- 服务器处理请求并返回加密响应:
-
- 服务器接收到客户端的请求后,进行相应的处理,并将响应数据使用对称密钥进行加密后返回给客户端。
- 客户端解密响应:
-
- 客户端接收到服务器的加密响应后,使用对称密钥进行解密,得到原始的响应数据。

TCP和UDP的主要区别是什么
需要从不同的角度来回答
参考:
- 连接
-
- TCP: 面向连接的传输层协议,传输数据前需建立连接。
- UDP: 无需连接,即时传输数据。
- 服务对象
-
- TCP: 一对一的服务,一条连接只有两个端点。
- UDP: 支持一对一、一对多、多对多的交互通信。
- 可靠性
-
- TCP: 可靠交付数据,无差错、不丢失、不重复、按序到达。
- UDP: 尽最大努力交付,不保证可靠交付数据,但可基于UDP实现可靠传输协议(如QUIC)。
- 拥塞控制、流量控制
-
- TCP: 有拥塞控制和流量控制机制,保证传输安全性。
- UDP: 没有拥塞控制,即使网络拥堵也不会调整发送速率。
- 首部开销
-
- TCP: 首部长度较长,可变(最少20字节,选项字段增加)。
- UDP: 固定8字节,开销较小。
- 传输方式
-
- TCP: 流式传输,无边界,保证顺序和可靠性。
- UDP: 每个包独立发送,有边界,可能丢包和乱序。
- 分片处理
-
- TCP: 大数据分片在传输层,丢失时只需传输丢失的分片。
- UDP: 大数据分片在IP层,接收后在IP层组装,再传输给传输层。
TCP 和 UDP 应用场景:
- TCP: FTP文件传输,HTTP/HTTPS等需要可靠数据传输的场景。
- UDP: DNS、SNMP等少量数据通信,视频、音频流传输,广播通信等。
(这些点都可以展开来说)
GET和POST请求的区别
语义
- GET: 请求指定的资源,请求参数以查询字符串形式附加在URL后面,长度限制较为严格。
- POST: 向指定资源提交数据,数据包含在请求体中,可以传输大量数据,且格式不限于ASCII字符。
安全性
- GET: 请求参数暴露在URL中,可能被浏览器缓存、历史记录等记录和存储,不适合传输敏感信息。
- POST: 请求参数在请求体中,不会被浏览器缓存或保存,更适合传输敏感信息。
数据类型
- GET: 参数仅支持ASCII字符,长度限制(通常在几千字节以内),不适合传输大数据。
- POST: 无数据类型限制,适合传输大数据和复杂数据类型(如文件上传)。
幂等性( 幂等性指的是同一请求的重复执行不会产生不同的结果)
- GET: 幂等,多次请求同一URL返回相同结果。
- POST: 非幂等,多次请求可能产生不同的结果(如提交订单)。
缓存处理
- GET: 可以被缓存,浏览器可以直接使用缓存数据。
- POST: 默认不会被缓存,需要服务器指定缓存策略。
使用场景
- GET: 用于请求数据、查询操作,对请求结果的幂等性要求较高的场景。
- POST: 用于提交表单、上传文件、进行状态变更等需要发送数据的场景。
什么是跨域,什么情况下会发生跨域,有什么解决办法
跨域指的是在浏览器中运行的脚本试图访问不同源(即不同的域、协议或端口)的资源时所遇到的安全限制问题。具体来说,浏览器出于安全考虑,限制了来自不同源的页面间的互操作性,防止恶意网站利用用户登录状态等进行跨站攻击。
跨域问题通常在以下情况下会出现:
- 不同的协议:比如从
http://example.com发送请求到https://api.example.com。 - 不同的域名:比如从
http://example.com发送请求到http://api.anotherdomain.com。 - 不同的端口:比如从
http://example.com:3000发送请求到http://example.com:4000。
解决方案:
CORS(跨域资源共享):
- 服务器端设置响应头:在服务端的响应中添加
Access-Control-Allow-Origin头部,指定允许访问的源。例如:Access-Control-Allow-Origin: *表示允许所有源访问。
JSONP(JSON with Padding):
- JSONP 是一种通过动态创建
<script>标签来加载包含 JSON 数据的响应的方法。由于<script>标签不受同源策略限制,可以用来绕过跨域问题。不过使用 JSONP 需要注意安全性问题和仅适用于 GET 请求的限制。
Nginx代理:
- 使用Nginx作为代理服务器和用户交互,用户就只需要在80端口上进行交互就可以了,这样就避免了跨域问题。
相关文章:
DNS查询服务器的基本流程以及https的加密过程
DNS查询服务器的基本流程,能画出图更好,并说明为什么DNS查询为什么不直接从单一服务器查询ip,而是要经过多次查询,多次查询不会增加开销么(即DNS多级查询的优点)? 用户发起请求:用户…...

后台管理系统(springboot+vue3+mysql)
系列文章目录 1.SpringBoot整合RabbitMQ并实现消息发送与接收 2. 解析JSON格式参数 & 修改对象的key 3. VUE整合Echarts实现简单的数据可视化 4. List<HashMap<String,String>>实现自定义字符串排序(key排序、Val…...

Android经典面试题之Kotlin中 if 和 let的区别
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 在Kotlin中,if和let虽然有时候用来处理相似的情景,但它们实际上是用于不同的场景并具有不同的性质。下面我们来详细对比…...

python inf是什么意思
INF / inf:这个值表示“无穷大 (infinity 的缩写)”,即超出了计算机可以表示的浮点数的范围(或者说超过了 double 类型的值)。例如,当用 0 除一个整数时便会得到一个1.#INF / inf值;相应的,如果…...

Cursor搭配cmake实现C++程序的编译、运行和调试
Cursor搭配cmake实现C程序的编译、运行和调试 Cursor是一个开源的AI编程编辑器,开源地址https://github.com/getcursor/cursor ,它其实是一个集成了Chat-GPT的VS Code。 关于VS Code和VS的对比可以参考这篇文章VS Code 和 Visual Studio 哪个更好&…...
)
C#-了解ORM框架SqlSugar并快速使用(附工具)
目录 一、配置 二、操作步骤 1、根据配置映射数据库对象 2、实体配置 3、创建表 4、增删改查 增加数据 删除数据 更新数据 查询数据 5、导航增删改查 增加数据 删除数据 更新数据 查询数据 6、雪花ID 三、工具 SqlLite可视化工具 MySQL安装包 MySQL可视化…...

巴黎奥运会 为啥这么抠?
文|琥珀食酒社 作者 | 朱珀 你是不是挺无语的 这奥运会还没有开始呢 吐槽大会就停不下来了 接近40度的高温 公寓没有空调 奥运巴士也没空调 连郭晶晶老公霍启刚 这种见惯大场面的也破防了 你可能会问 好不容易搞个奥运会 干嘛还要抠抠搜搜的呀 在咱们看…...

Python日期和时间处理库之pendulum使用详解
概要 在处理日期和时间时,Python 标准库中的 datetime 模块虽然功能强大,但有时显得过于复杂且缺乏一些便捷功能。为了解决这些问题,Pendulum 库应运而生。Pendulum 是一个 Python 日期和时间处理库,它在 datetime 模块的基础上进行了扩展,提供了更加友好的 API 和更多的…...
如何通过 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移
01 引言 随着大数据技术的飞速发展,Apache Kafka 作为一种高吞吐量、低延迟的分布式消息系统,已经成为企业实时数据处理的核心组件。然而,随着业务的扩展和技术的发展,企业面临着不断增加的存储成本和运维复杂性问题。为了更好地…...

详解Qt 之QPainterPath
文章目录 前言QPainterPath 与 QPainter 的区别QPainterPath 的主要函数和成员成员函数构造函数和析构函数路径操作布尔运算几何计算 示例代码示例 1:绘制简单路径示例 2:使用布尔运算合并路径示例 3:计算路径长度和角度 更多用法... 总结 前…...

深入理解Apache Kylin:从概念到实践
深入理解Apache Kylin:从概念到实践 引言 Apache Kylin 是一个分布式分析引擎,专为在大规模数据集上进行快速多维分析(OLAP)设计。自2015年开源以来,Kylin 已经成为许多企业在大数据分析领域的首选工具。本文将从概念…...

vue3框架Arco Design输入邮箱选择后缀
使用: <a-form-item field"apply_user_email" label"邮箱:" ><email v-model"apply_user_email" class"inputborder topinputw"></email> </a-form-item>import email from /componen…...

制作镜像
1.镜像 image: 是一个文件,包含了微型操作系统、核心代码(可执行程序)、依赖环境(库) 2.仓库 repository: 存放镜像文件的地方 3.容器: container :是运行镜像的地方--…...
进阶)
Kylin系列(二)进阶
Kylin系列(二)进阶 目录 简介Kylin架构深入解析 Kylin架构概述核心组件 高级Cube设计 Cube设计原则Cube优化策略 实时数据分析 实时数据处理流程实时Cube构建 高级查询与优化 查询优化技术SQL优化 Kylin与BI工具集成 Tableau集成Power BI集成 监控与调优 系统监控性能调优 常…...

Maven实战.依赖(依赖范围、传递性依赖、依赖调解、可选依赖等)
文章目录 依赖的配置依赖范围传递性依赖传递性依赖和依赖范围依赖调解可选依赖最佳实践排除依赖归类依赖优化依赖 依赖的配置 依赖会有基本的groupId、artifactld 和 version等元素组成。其实一个依赖声明可以包含如下的一些元素: <project> ...<depende…...

关于React17的setState
不可变值 state必须在构造函数中定义 在setState之前不能修改state的值,不要直接修改state,使用不可变值 可能是异步更新 直接使用时异步的 this.setState({count: this.state.count 1 }, () > {console.log(count by callback, this.state.count) // 回调函…...

2024华为OD机试真题-英文输入法Python-C卷D卷-100分
2024华为OD机试题库-(C卷+D卷)-(JAVA、Python、C++) 题目描述 主管期望你来实现英文输入法单词联想功能,需求如下: 依据用户输入的单词前缀,从已输入的英文语句中联想出用户想输入的单词。 按字典序输出联想到的单词序列,如果联想不到,请输出用户输入的单词前缀。 注意 英…...

magento2 安装win环境和linux环境
win10 安装 安装前提,php,mysql,apach 或nginx 提前安装好 并且要php配置文件里,php.ini 把错误打开 display_errorsOn开始安装 检查环境 填写数据库信息 和ssl信息,如果ssl信息没有,则可以忽略 填写域名和后台地址࿰…...

【城市数据集】世界城市数据库和访问门户工具WUDAPT
世界城市数据库和访问门户工具WUDAPT WUDAPTLCZ分类具体步骤参考 在 城市气候研究中,用于描述城市特征的数据集一般采用基于类别的传统方法,将城市地区分为数量有限的类型,从而导致精确度下降。越来越多的新数据集以亚米微尺分辨率描述城市的…...

网络爬虫必备工具:代理IP科普指南
文章目录 1. 网络爬虫简介1.1 什么是网络爬虫?1.2 网络爬虫的应用领域1.3 网络爬虫面临的主要挑战 2. 代理IP:爬虫的得力助手2.1 代理IP的定义和工作原理2.2 爬虫使用代理IP的必要性 3. 代理IP的类型及其在爬虫中的应用3.1 动态住宅代理3.2 动态数据中心…...

NHSE终极指南:掌握动物森友会存档编辑的5大核心技术
NHSE终极指南:掌握动物森友会存档编辑的5大核心技术 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE NHSE(New Horizons Save Editor)作为《集合啦!动…...

Python性能优化实战:8个核心技巧提升代码执行效率
1. 项目概述:为什么你的Python代码跑得慢?“Python慢”,这几乎是每个刚入门的开发者都会听到的“刻板印象”。确实,作为一门解释型、动态类型的语言,在纯粹的执行速度上,Python很难与C、C这类编译型语言正面…...

GEO优化的两大误区:你是在“交学费”还是在“抢红利”?
当AI搜索成为用户的新入口,一批先行者已经吃到了红利。但更多人,还在两个极端之间摇摆。 你有没有遇到过这样的情况? 刷到某个同行,因为上了DeepSeek或豆包的推荐,咨询量翻了几倍。你也心动,开始研究GEO&a…...

课堂教学PPT模板平台深度测评与选用指南
一、引言:PPT—— 课堂教学的重要辅助工具在当今的课堂教学中,PPT 已经成为了教师们不可或缺的 “魔法道具”。一份精心设计的 PPT,就像一位无声的助教,能够将抽象的知识变得直观形象,将枯燥的内容变得生动有趣。它不仅…...
)
别再让日志拖慢你的服务器!深入对比C++同步与异步日志的性能差异(附TinyWebServer实测)
C服务器日志性能优化实战:同步与异步方案深度对比 当你的Web服务器开始承载真实流量时,那些看似无害的日志语句可能正在悄悄吞噬着系统性能。我曾在一个电商促销日亲眼目睹,由于同步日志的阻塞导致服务器响应时间从50ms飙升到800ms࿰…...

UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案
UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案 【免费下载链接】UxPlay AirPlay Unix mirroring server 项目地址: https://gitcode.com/gh_mirrors/uxp/UxPlay UxPlay是一款功能强大的AirPlay Unix镜像服务器,它让Linux、macOS和Unix系统能…...

Legacy Update完整指南:让老旧Windows系统重获安全更新的5步教程
Legacy Update完整指南:让老旧Windows系统重获安全更新的5步教程 【免费下载链接】LegacyUpdate Get back online, activate, and install updates on your legacy Windows PC 项目地址: https://gitcode.com/gh_mirrors/le/LegacyUpdate 还在为Windows XP、…...

链游3.0时代:GameFi+NFT+SocialFi如何引爆万亿级“数字乌托邦“?
——区块链游戏开发的全栈解密与商业落地指南引言:当游戏世界开始"造富" 当Axie Infinity的玩家在菲律宾靠打怪月入过万,当Decentraland的虚拟土地拍出243万美元天价,当StepN的运动鞋NFT创造45天回本神话——链游已不再是加密圈的小…...

SpringBoot+Vue房屋买卖平台源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化
Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化 【免费下载链接】bpmn-process-designer bpmn-js 工具库 项目地址: https://gitcode.com/gh_mirrors/bp/bpmn-process-designer Bpmn Process Designer是一款基于bpmn-js的强大流程设计器工具…...