如何通过 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移
01 引言
随着大数据技术的飞速发展,Apache Kafka 作为一种高吞吐量、低延迟的分布式消息系统,已经成为企业实时数据处理的核心组件。然而,随着业务的扩展和技术的发展,企业面临着不断增加的存储成本和运维复杂性问题。为了更好地优化系统性能和降低运营成本,企业开始寻找更具优势的消息系统解决方案。其中,AutoMQ [1] 作为一种基于云重新设计的消息系统,凭借其显著的成本优势和弹性能力,成为了企业的理想选择。
1.1 AutoMQ 介绍
AutoMQ 基于云重新设计了 Kafka,将存储分离至对象存储,在保持与 Apache Kafka 100% 兼容的前提下,为用户提供高达10倍的成本优势和百倍的弹性优势。AutoMQ 通过构建在S3上的流存储库 S3Stream,将存储卸载至云厂商提供的共享云存储 EBS 和 S3,提供低成本、低延时、高可用、高可靠和无限容量的流存储能力。与传统的Shared Nothing 架构相比,AutoMQ 采用了 Shared Storage 架构,显著降低了存储和运维的复杂性,同时提升了系统的弹性和可靠性。AutoMQ 的设计理念和技术优势使其成为替换企业现有 Kafka 集群的理想选择。通过采用 AutoMQ,企业可以显著降低存储成本,简化运维,并实现集群的自动扩缩容和流量自平衡,从而更高效地应对业务需求的变化。 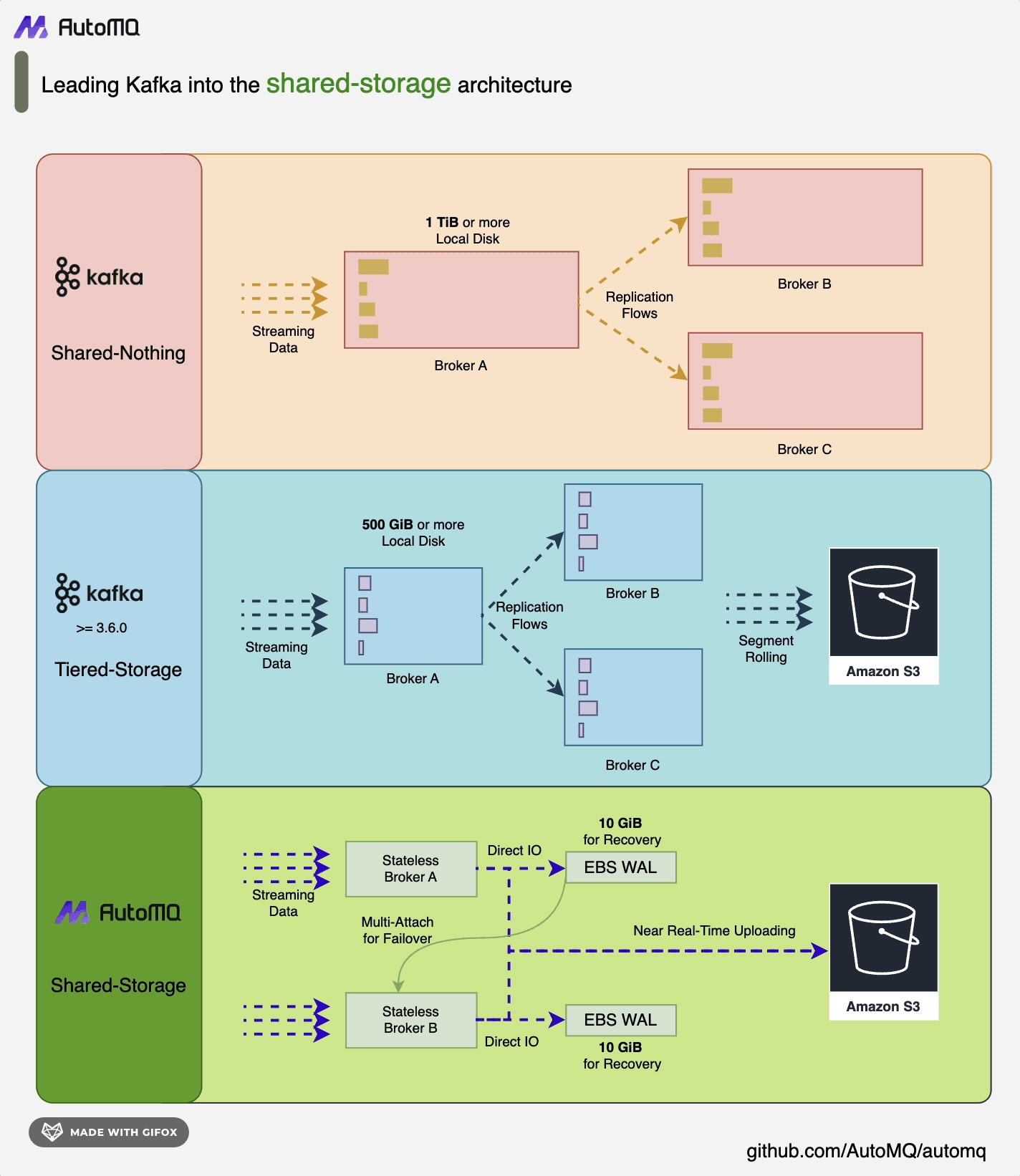
1.2 CloudCanal 概述
CloudCanal [2] 是一款数据同步、迁移工具,帮助企业构建高质量数据管道,具备实时高效、精确互联、稳定可拓展、一站式、混合部署、复杂数据转换等优点。CloudCanal 支持数据迁移、数据同步、结构迁移和同步、数据校验和订正等功能,能够满足企业在数据管理过程中对于数据质量和稳定性的高要求。通过消费源端数据源的增量操作日志,CloudCanal 可以准实时地在对端数据源重放操作,以达到数据同步的目的。
1.3 数据迁移的必要性
在企业的日常运营中,数据系统的升级和迁移是不可避免的。例如,当企业的电商平台面临流量激增和数据量爆炸式增长时,现有的 Kafka 集群可能无法满足需求,导致性能瓶颈和存储成本的显著增加。为了应对这些挑战,企业可能决定迁移到更具成本效益和弹性的 AutoMQ 系统。在这种迁移过程中,全量同步和增量同步都是关键步骤。全量同步可以将 Kafka 中的所有现有数据迁移到 AutoMQ,确保基础数据的完整性。增量同步则在全量同步完成后,实时捕捉和同步 Kafka 中的新增和变更数据,确保在迁移过程中,两个系统之间的数据保持一致。接下来,我将以增量同步为例,详细介绍如何使用 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移,确保数据在迁移过程中保持一致和完整。
02 前置条件
在进行数据迁移之前,需要确保以下前提条件已经满足。本文将以一个 Kafka 节点和一个 AutoMQ 节点为例,演示增量同步的过程。
Kafka 节点:一个已部署并运行的 Kafka 节点,确保 Kafka 节点能够正常接收和处理消息,Kafka节点的网络配置允许与 CloudCanal 服务通信。
AutoMQ 节点:一个已部署并运行的 AutoMQ 节点,确保 AutoMQ 节点能够正常接收和处理消息,AutoMQ 节点的网络配置允许与 CloudCanal 服务通信。
CloudCanal 服务: 已部署和配置好的 CloudCanal 服务。
03 部署 AutoMQ、kafka 以及 CloudCanal
3.1 部署 AutoMQ
参考 AutoMQ 官网文档: QuickStart | AutoMQ [3]
3.2 部署 Kafka
参考 Apache Kafka 官方文档:QuickStart | Kafka [4]
3.3 部署 CloudCanal
安装与启动
1. 安装基础工具
## ubuntu
sudo apt update
sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
sudo apt-get install -y lsof
sudo apt-get install -y bc
sudo apt-get install -y p7zip-full2. 下载安装包登录 CloudCanal 官方网站 [5],点击下载私有部署版按钮,获取软件包下载链接。下载并解压到文件夹/opt/
cd /opt
# 下载
wget -cO cloudcanal.7z "${软件包下载链接}"
# 解压
7z x cloudcanal.7z -o./cloudcanal_home
cd cloudcanal_home/install_on_dockerinstall_on_docker目录内容包括
- 镜像: images 目录下四个 tar 结尾的压缩文件
- docker 容器编排文件: docker-compose.yml 文件
- 脚本:一些管理 CloudCanal 容器以及维护的脚本
3. 准备 Docker 环境请确保以下端口未被占用

如果你没有 docker 和 docker compose 环境,可参考 Docker 官方文档 [6] (版本 17.x.x 及以上)。也可直接使用目录中提供的脚本进行安装:
## ubuntu,进入 install_on_docker 目录
bash ./support/install_ubuntu_docker.sh- 启动 CloudCanal,执行安装脚本以启动:
## ubuntu
bash install.sh出现如下标识即安装成功

激活 CloudCanal
安装成功后,你可以通过 http://{ip}:8111 在浏览器中访问 CloudCanal 的控制台。
注意:如果无法正常访问页面,可以尝试通过脚本更新当前 CloudCanal 的版本,可使用如下命令:
# 进入安装目录
cd /opt/cloudcanal_home/install_on_docker
# 停止当前 CloudCanal
sudo bash stop.sh
# 更新并启动新的 CloudCanal
sudo bash upgrade.sh1. 进入登录界面后,通过试用账号登录
账号: test@clougence.com
密码: clougence2021
默认验证码: 777777
2. 登录成功,需要激活 CloudCanal 账号即可正常使用。申请免费许可证并激活: 许可证获取 | CloudCanal [7],激活成功后,主界面状态为:

04 数据迁移过程
4.1 准备源端 Kafka 数据
可以选择如下方式:
- CloudCanal 提供的 Mysql->Kafka 数据同步过程,参考:MySQL 到 Kafka 同步 | CloudCanal [8]
- 通过 Kafka SDK 准备数据
- 通过 Kafka 提供的脚本手动生产消息
这里我将通过 Kafka SDK 的方式进行数据准备,下面是参考代码:
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutionException;public class KafkaTest {private static final String BOOTSTRAP_SERVERS = "${kafka_broker_ip:port}"; //修改为你自己的 Kafka 节点地址private static final int NUM_TOPICS = 50;private static final int NUM_MESSAGES = 500;public static void main(String[] args) throws Exception {KafkaTest test = new KafkaTest();test.createTopics();test.sendMessages();}// 创建50个 Topic,格式为 Topic-npublic void createTopics() {Properties props = new Properties();props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);try (AdminClient adminClient = AdminClient.create(props)) {List<NewTopic> topics = new ArrayList<>();for (int i = 1; i <= NUM_TOPICS; i++) {topics.add(new NewTopic("Topic-" + i, 1, (short) 1));}adminClient.createTopics(topics).all().get();System.out.println("Topics created successfully");} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}// 为50个 Topic-n 分别发送序号从1到1000共一千条消息,消息格式为 Json格式public void sendMessages() {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {for (int i = 1; i <= NUM_TOPICS; i++) {String topic = "Topic-" + i;for (int j = 1; j <= NUM_MESSAGES; j++) {String key = "key-" + j;String value = "{\"userId\": " + j + ", \"action\": \"visit\", \"timestamp\": " + System.currentTimeMillis() + "}";ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);producer.send(record, (RecordMetadata metadata, Exception exception) -> {if (exception == null) {System.out.printf("Sent message to topic %s partition %d with offset %d%n", metadata.topic(), metadata.partition(), metadata.offset());} else {exception.printStackTrace();}});}}System.out.println("Messages sent successfully");}}
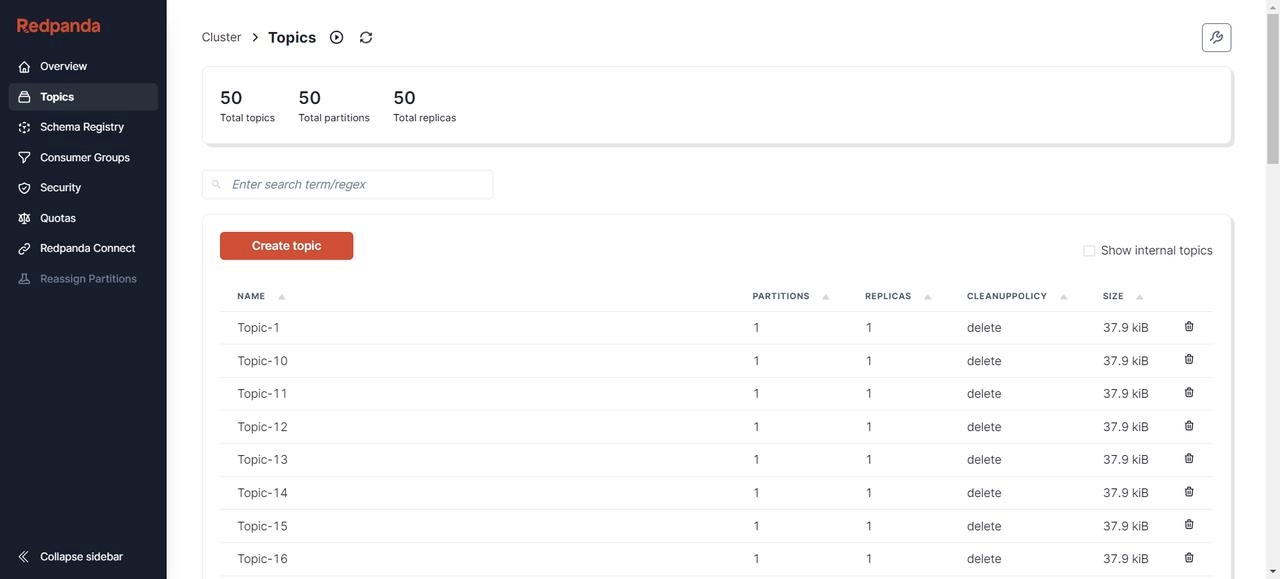
}创建完成后,可以通过各种可视化工具查看 Kafka 节点状态,比如 Redpanda Console [9]、Kafdrop [10] 等。这里我选择 Redpanda Console,可以看到当前已经有了 50 个Topic,并且每个 Topic 下有500条初始消息。
其中消息的格式为 Json:
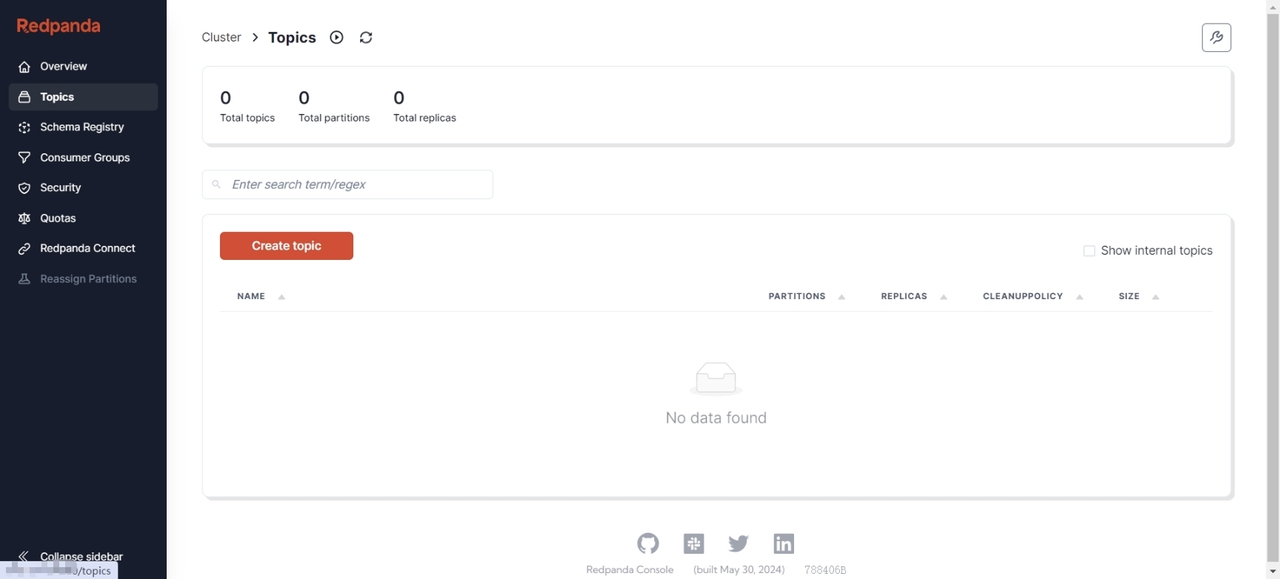
{"action": "INSERT/UPDATE/DELETE","bid": 1,"before": [],"data": [{"id":"string data","username":"string data","user_id":"string data","ip":"string data","request_time":"1608782968300","request_type":"string data"}],"db": "access_log_db","schema": "","table":"access_log","dbValType": {"id":"INT","username":"VARCHAR","user_id":"INT","ip":"VARCHAR","request_time":"TIMESTAMP","request_type":"VARCHAR",},"jdbcType": {"id":"0","username":"0","user_id":"0","ip":"0","request_time":"0","request_type":"0",},"entryType": "ROWDATA","isDdl": false,"pks": ["id"],"execTs": 0,"sendTs": 0,"sql": ""}并且,AutoMQ 节点当前并无任何数据:
添加 CloudCanal 数据源
CloudCanal 界面上方 数据源管理 -> 新增数据源 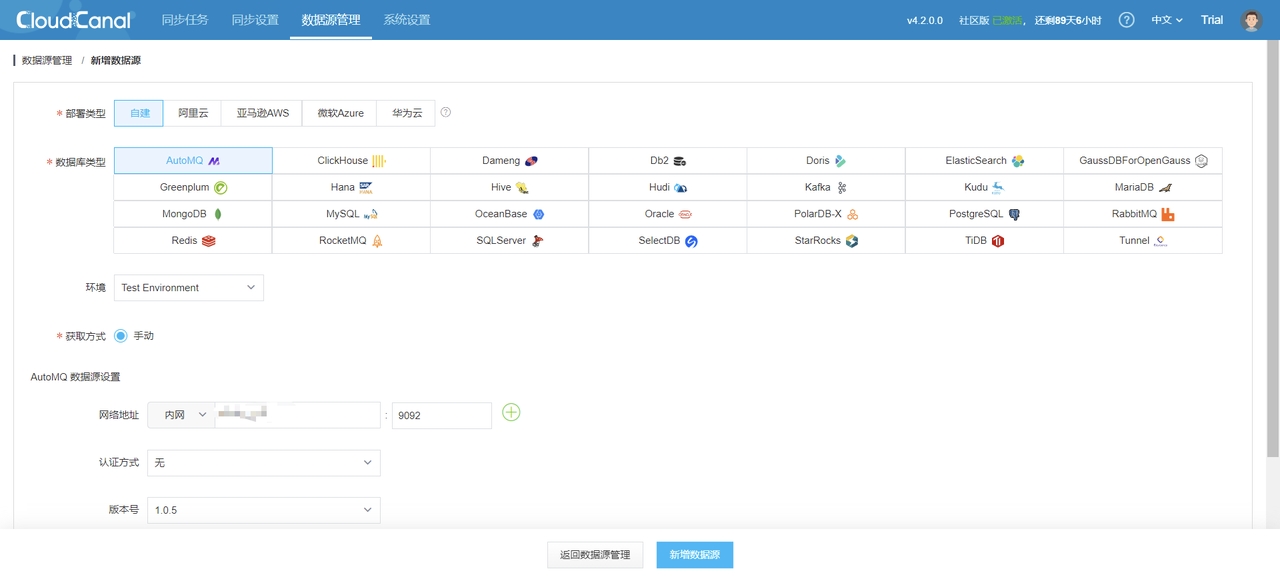
同理增加 Kafka 数据源,并对两个节点都进行连接测试,可以得到如下结果: 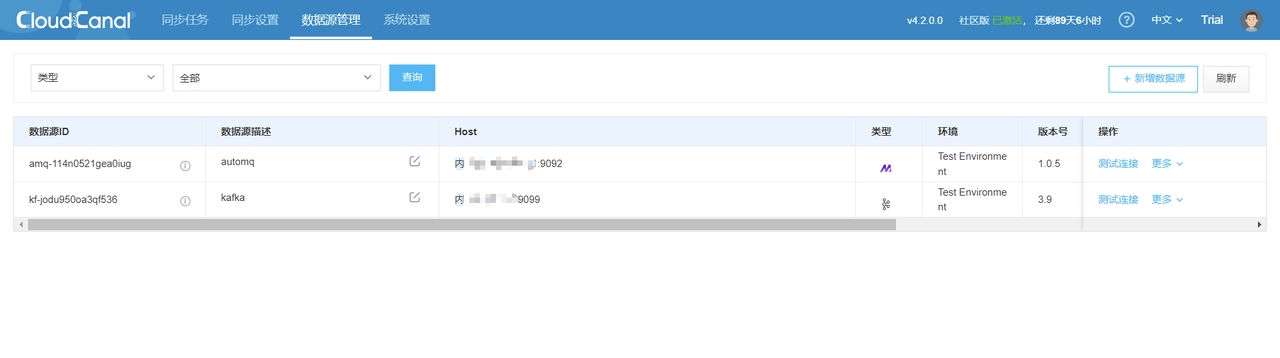
4.3 创建数据迁移任务
1. CloudCanal 界面上方 同步任务->创建任务 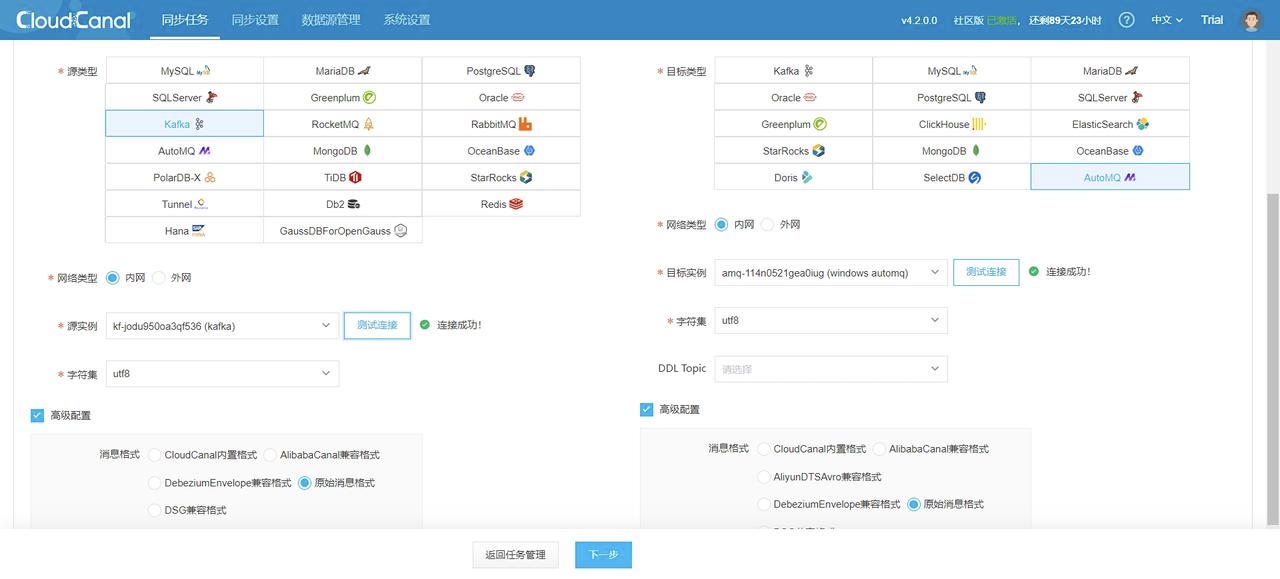
2. 选择任务规格,这取决于你需要迁移的数据量大小: 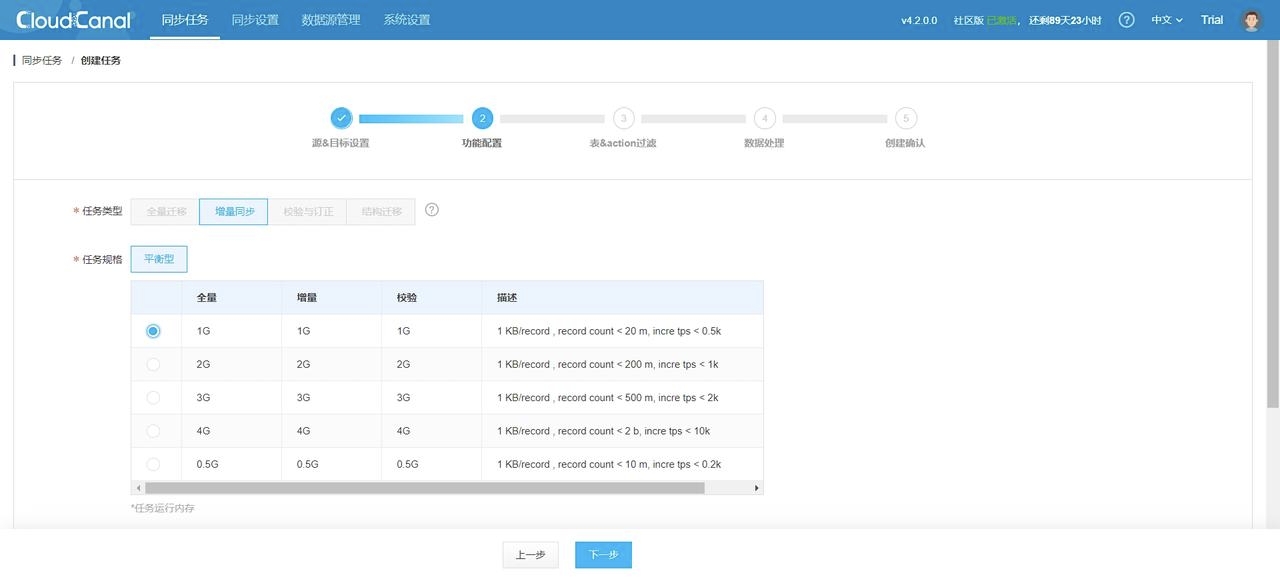
3. 选择需要进行数据迁移的 Topics: 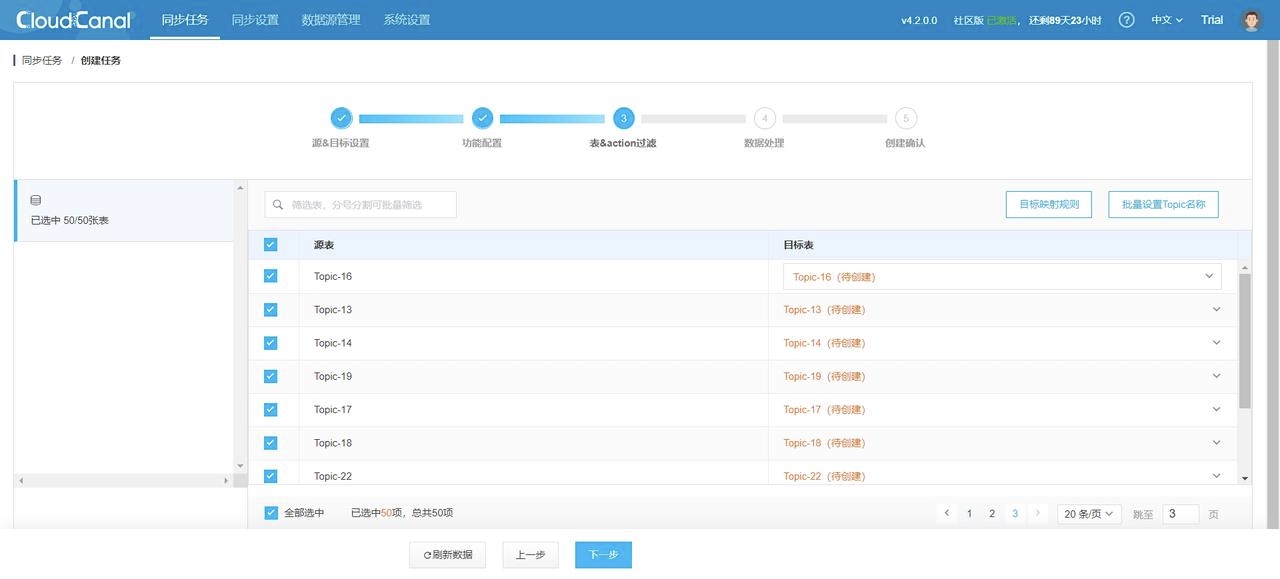
4. 任务确定: 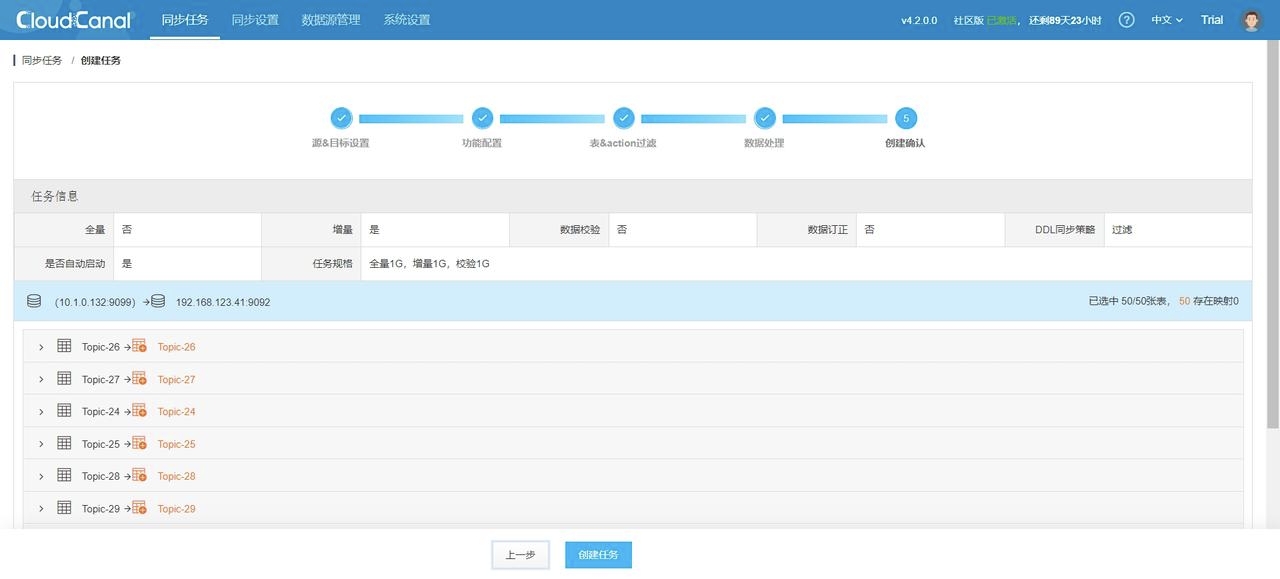
5. 任务创建完成后默认自动启动,会跳转到任务列表,你还需要更改源数据源配置以开启心跳配置,能及时更新任务状态,步骤为 任务详情->源数据源配置->修改配置->生效配置: 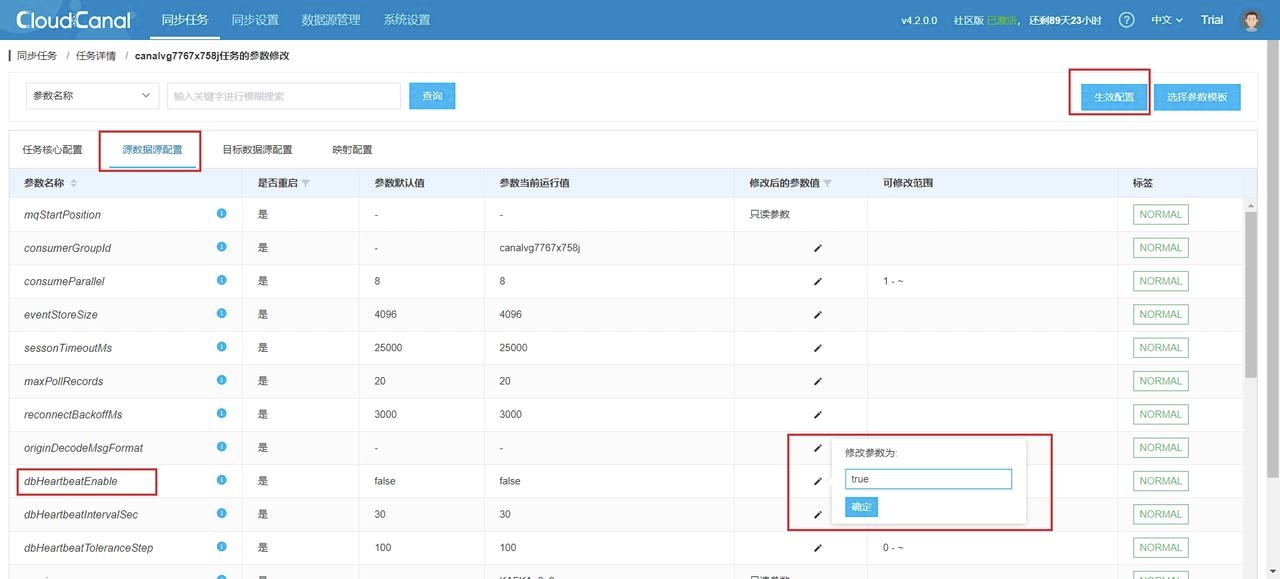
6. 随后等待任务重启完成,即可看到如下情况: 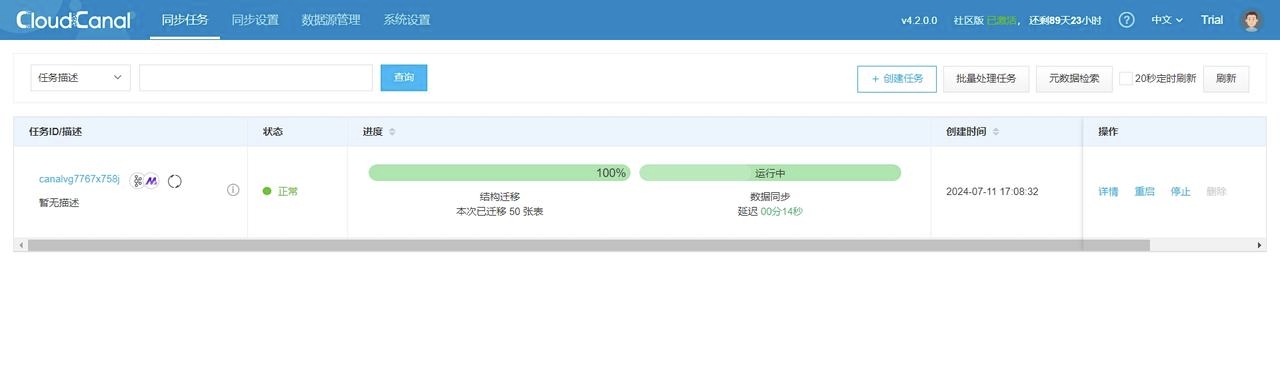
注意:如果遇到关于连接问题以及任务延迟过高等问题可以参考 CloudCanal 官方文档:FAQ 索引 | CloudCanal [11]
7. 验证 AutoMQ 中是否已经正确创建了 Topic 结构 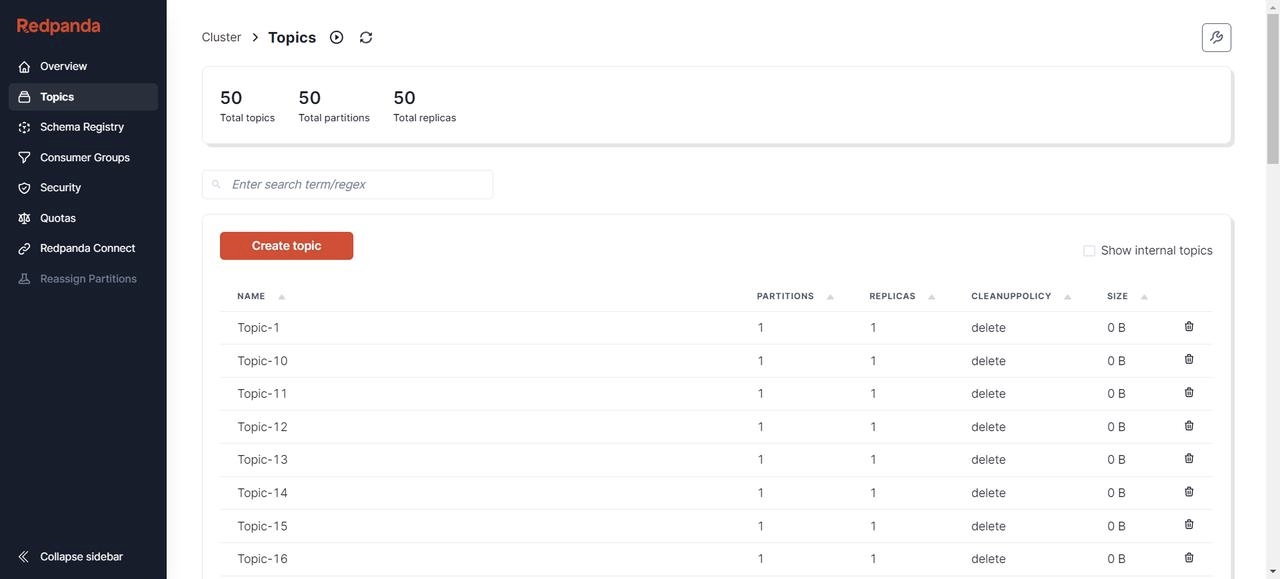
4.4 准备增量数据
任务已经正常运行,接下来我们需要准备增量数据,使得迁移任务能够将增量数据同步到 AutoMQ。这里我们仍然通过 Kafka SDK 新增数据。新增数据之后,我们可以通过 任务详情->增量同步->查看日志->任务运行日志 中查看任务执行情况:
2024-07-11 17:16:45.995 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.995 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.996 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.996 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.996 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.997 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.997 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.997 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.998 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.998 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.998 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
2024-07-11 17:16:45.999 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:6405 验证迁移结果
验证AutoMQ是否正确同步到消息: 
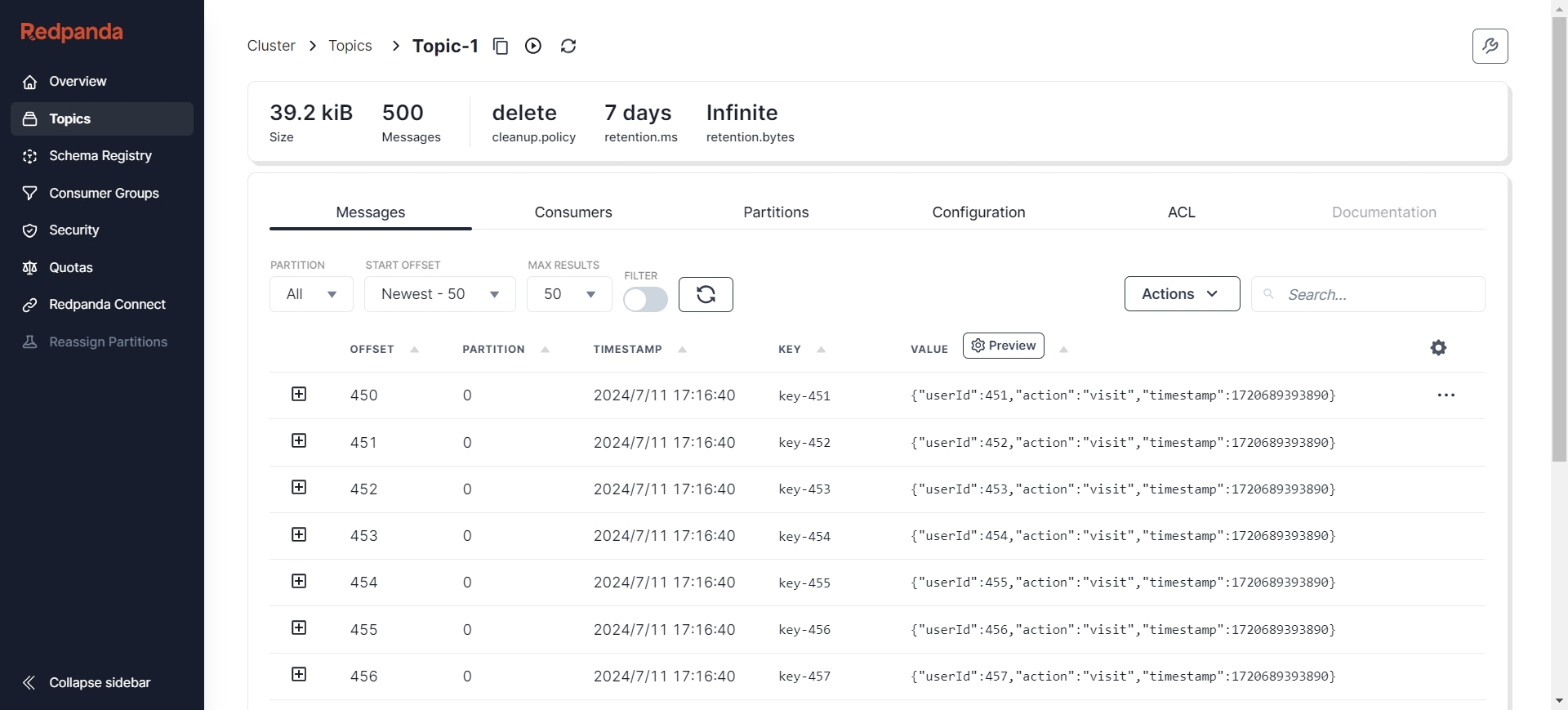
多次新增数据后依旧正常完成迁移: 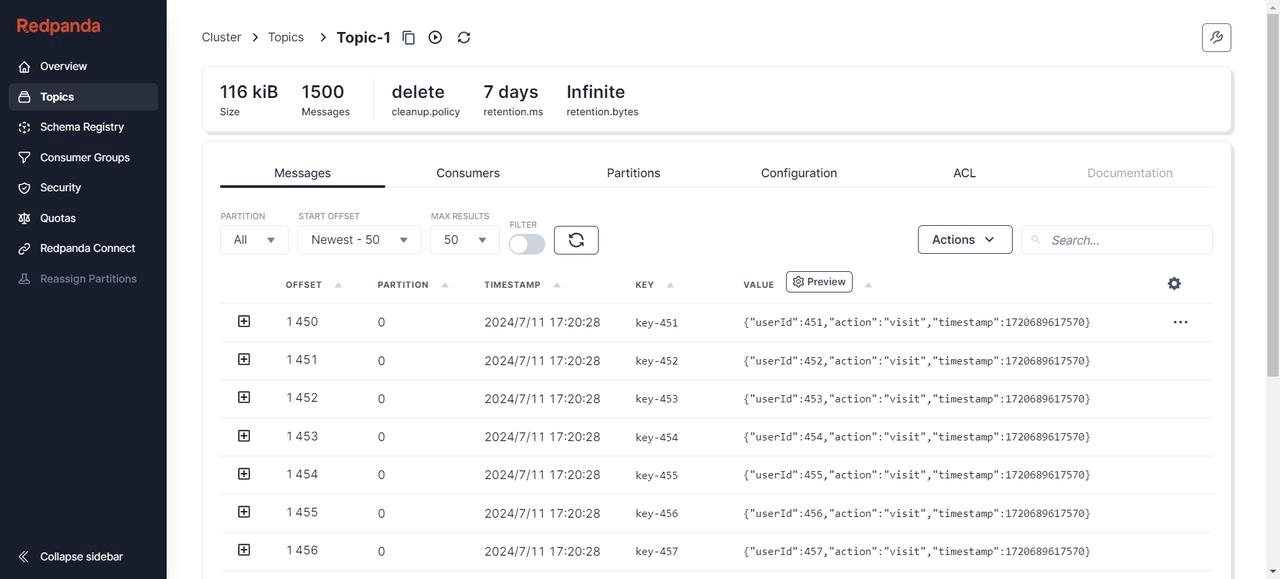
可以看到在增量同步任务执行期间对 Kafka 新增的数据都已经同步到了 AutoMQ 中。至此,我们的迁移过程已经全部完成。
06 总结
随着企业数据规模的不断扩大和业务需求的多样化,数据迁移和同步变得尤为重要。通过本文的介绍,我们详细探讨了如何利用 CloudCanal 实现从 Kafka 到 AutoMQ 的增量同步数据迁移,以应对存储成本和运维复杂性的问题。在迁移过程中,增量同步技术确保了数据的一致性和业务的连续性,为企业提供了一个高效、可靠的解决方案。希望本文能够为你在数据迁移和同步方面提供有价值的参考和指导,帮助实现系统的平滑过渡和性能优化!
引用
[1] AutoMQ: https://docs.automq.com/zh/docs/automq-opensource/HSiEwHVfdiO7rWk34vKcVvcvn2Z
[2] CloudCanal: https://www.clougence.com/?src=cc-doc
[3] QuickStart | AutoMQ: https://docs.automq.com/zh/docs/automq-opensource/EvqhwAkpriAomHklOUzcUtybn7g
[4] QuickStart | Kafka: https://kafka.apache.org/quickstart
[5] CloudCanal 官方网站: https://www.clougence.com/?src=cc-doc-install-linux
[6] Docker 官方文档: https://docs.docker.com/engine/install/
[7] 许可证获取 | CloudCanal: https://www.clougence.com/cc-doc/license/license_use
[8] MySQL 到 Kafka 同步 | CloudCanal: https://www.clougence.com/cc-doc/bestPractice/mysql_kafka_sync
[9] Redpanda Console: https://redpanda.com/redpanda-console-kafka-ui
[10] Kafdrop: https://github.com/obsidiandynamics/kafdrop
[11] FAQ 索引 | CloudCanal: https://www.clougence.com/cc-doc/faq/cloudcanal_faq_list
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com?utm_source=openwrite
相关文章:
如何通过 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移
01 引言 随着大数据技术的飞速发展,Apache Kafka 作为一种高吞吐量、低延迟的分布式消息系统,已经成为企业实时数据处理的核心组件。然而,随着业务的扩展和技术的发展,企业面临着不断增加的存储成本和运维复杂性问题。为了更好地…...

详解Qt 之QPainterPath
文章目录 前言QPainterPath 与 QPainter 的区别QPainterPath 的主要函数和成员成员函数构造函数和析构函数路径操作布尔运算几何计算 示例代码示例 1:绘制简单路径示例 2:使用布尔运算合并路径示例 3:计算路径长度和角度 更多用法... 总结 前…...

深入理解Apache Kylin:从概念到实践
深入理解Apache Kylin:从概念到实践 引言 Apache Kylin 是一个分布式分析引擎,专为在大规模数据集上进行快速多维分析(OLAP)设计。自2015年开源以来,Kylin 已经成为许多企业在大数据分析领域的首选工具。本文将从概念…...

vue3框架Arco Design输入邮箱选择后缀
使用: <a-form-item field"apply_user_email" label"邮箱:" ><email v-model"apply_user_email" class"inputborder topinputw"></email> </a-form-item>import email from /componen…...

制作镜像
1.镜像 image: 是一个文件,包含了微型操作系统、核心代码(可执行程序)、依赖环境(库) 2.仓库 repository: 存放镜像文件的地方 3.容器: container :是运行镜像的地方--…...
进阶)
Kylin系列(二)进阶
Kylin系列(二)进阶 目录 简介Kylin架构深入解析 Kylin架构概述核心组件 高级Cube设计 Cube设计原则Cube优化策略 实时数据分析 实时数据处理流程实时Cube构建 高级查询与优化 查询优化技术SQL优化 Kylin与BI工具集成 Tableau集成Power BI集成 监控与调优 系统监控性能调优 常…...

Maven实战.依赖(依赖范围、传递性依赖、依赖调解、可选依赖等)
文章目录 依赖的配置依赖范围传递性依赖传递性依赖和依赖范围依赖调解可选依赖最佳实践排除依赖归类依赖优化依赖 依赖的配置 依赖会有基本的groupId、artifactld 和 version等元素组成。其实一个依赖声明可以包含如下的一些元素: <project> ...<depende…...

关于React17的setState
不可变值 state必须在构造函数中定义 在setState之前不能修改state的值,不要直接修改state,使用不可变值 可能是异步更新 直接使用时异步的 this.setState({count: this.state.count 1 }, () > {console.log(count by callback, this.state.count) // 回调函…...

2024华为OD机试真题-英文输入法Python-C卷D卷-100分
2024华为OD机试题库-(C卷+D卷)-(JAVA、Python、C++) 题目描述 主管期望你来实现英文输入法单词联想功能,需求如下: 依据用户输入的单词前缀,从已输入的英文语句中联想出用户想输入的单词。 按字典序输出联想到的单词序列,如果联想不到,请输出用户输入的单词前缀。 注意 英…...

magento2 安装win环境和linux环境
win10 安装 安装前提,php,mysql,apach 或nginx 提前安装好 并且要php配置文件里,php.ini 把错误打开 display_errorsOn开始安装 检查环境 填写数据库信息 和ssl信息,如果ssl信息没有,则可以忽略 填写域名和后台地址࿰…...

【城市数据集】世界城市数据库和访问门户工具WUDAPT
世界城市数据库和访问门户工具WUDAPT WUDAPTLCZ分类具体步骤参考 在 城市气候研究中,用于描述城市特征的数据集一般采用基于类别的传统方法,将城市地区分为数量有限的类型,从而导致精确度下降。越来越多的新数据集以亚米微尺分辨率描述城市的…...

网络爬虫必备工具:代理IP科普指南
文章目录 1. 网络爬虫简介1.1 什么是网络爬虫?1.2 网络爬虫的应用领域1.3 网络爬虫面临的主要挑战 2. 代理IP:爬虫的得力助手2.1 代理IP的定义和工作原理2.2 爬虫使用代理IP的必要性 3. 代理IP的类型及其在爬虫中的应用3.1 动态住宅代理3.2 动态数据中心…...

JMeter接口测试-5.JMeter高级使用
JMeter高级使用 案例: 用户登录后-选择商品-添加购物车-创建订单-验证结果 问题: JMeter测试中,验证结果使用断言,但断言都是固定的内容假如要判断的内容(预期内容)是在变化的, 有时候还是不确定的, 那该怎么办呢? 解决&…...

网络安全大模型开源项目有哪些?
01 Ret2GPT 它是面向CTF二进制安全的工具,结合ChatGPT API、Retdec和Langchain进行漏洞挖掘,它能通过问答或预设Prompt对二进制文件进行分析。 https://github.com/DDizzzy79/Ret2GPT 02 OpenAI Codex 它是基于GPT-3.5-turbo模型,用于编写…...

【赠书第18期】人工智能B2B落地实战:基于云和Python的商用解决方案
文章目录 前言 1 方案概述 2 方案实施 2.1 云平台选择 2.2 Python环境搭建 2.3 应用开发与部署 2.4 应用管理 2.5 安全性与隐私保护 3 方案优势与效益 4 推荐图书 5 粉丝福利 前言 随着云计算技术的快速发展,越来越多的企业开始将业务迁移至云端&#x…...

《昇思25天学习打卡营第24天》
接续上一天的学习任务,我们要继续进行下一步的操作 构造网络 当处理完数据后,就可以来进行网络的搭建了。按照DCGAN论文中的描述,所有模型权重均应从mean为0,sigma为0.02的正态分布中随机初始化。 接下来了解一下其他内容 生成…...

KeePass密码管理工具部署
KeePass密码管理工具部署 安装包下载入口 双击执行,根据提示完成安装: 安装完成后如图:...

C#中导出dataGridView数据为Excel
C#中导出dataGridView数据为Excel #region 导出Excel功能函数 /// <summary> /// dataGridView 导出Excel功能函数 /// </summary> /// <param name"dataView">dataGridView数据表</param> /// <param name"filePath">路径…...

算法学习6——贪心算法
什么是贪心算法? 贪心算法是一种在每一步选择中都采取当前状态下最优或最有利的选择的算法。其核心思想是通过一系列局部最优选择来达到全局最优解。贪心算法广泛应用于各种优化问题,如最短路径、最小生成树、背包问题等。 贪心算法的特点 局部最优选…...

【C++】标准库:介绍string类
string 一.string类介绍二.string类的静态成员变量三.string类的常用接口1.构造函数(constructor)2.析构函数(destructor)3.运算符重载(operator)1.operator2.operator[]3.operator4.operator 4.string的四…...

AArch64虚拟化调试:HDFGWTR2_EL2寄存器详解与应用
1. AArch64系统寄存器与虚拟化调试概述在Armv8/v9架构中,系统寄存器是处理器核心的控制中枢,负责管理处理器的各种关键功能和行为。AArch64架构通过异常级别(EL0-EL3)实现了严格的权限分级机制,其中EL2作为Hypervisor层…...
 终极指南:显卡驱动彻底清理的完整解决方案)
Display Driver Uninstaller (DDU) 终极指南:显卡驱动彻底清理的完整解决方案
Display Driver Uninstaller (DDU) 终极指南:显卡驱动彻底清理的完整解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/displa…...

jquery.inputmask插件介绍
目录 一、什么是 jQuery.inputmask? 主要应用场景 二、快速上手 1. 引入依赖文件 2. 基础用法 3. 掩码字符定义 三、高级功能 1. 自定义占位符 2. 完成回调 3. 扩展自定义字符 4. 重复掩码 5. 移除默认占位符 四、配合 Vue.js 使用 五、更多实用示例 …...

实时洞察,视觉赋能:国内情绪识别API公司推荐及计算机视觉流派深度解析
引言在人工智能与各行业深度融合的今天,通过非接触方式理解用户情绪、生理状态与心理倾向,已成为人机交互、安全防控、健康管理等领域的关键能力。本文围绕提供情绪识别类API的公司类型,梳理国内情绪识别的主流技术路径,并重点解析…...

保姆级教程:用UltraISO给U盘刻录Ubuntu 22.04启动盘,一次成功不踩坑
零基础实战:用UltraISO打造Ubuntu 22.04启动盘的终极指南 第一次接触Linux系统安装的新手,往往会在制作启动盘这一步遇到各种意想不到的问题。U盘明明已经刻录完成,却在启动时出现黑屏、报错甚至根本无法识别——这些困扰过无数初学者的坑&am…...

终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查
终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue Contin…...

7.跨品牌手机刷机原理深度解析|BL 解锁机制 + 分区读写 + 故障修复全方案
摘要 本文系统性地阐述主流品牌智能手机(华为、小米、OPPO、vivo、一加、苹果)刷机与维修的核心原理与操作流程。针对不同品牌底层架构差异,提供从Bootloader解锁、Recovery刷写到系统固件注入的完整技术方案。所有操作步骤均基于实际硬件环境验证,包含完整可运行的Python…...

动态图神经网络实现多商品时序协同预测
1. 项目概述:为什么传统时序模型在多商品预测中频频“掉链子”你有没有遇到过这样的场景:一家区域连锁超市的运营团队,每天盯着几十种SKU的销售数据发愁——酸奶销量突然飙升,但库存系统还在按上周的均值补货;新款保温…...

免费去图片水印app排行榜怎么选?2026一键去水印工具推荐
日常生活中,我们经常会遇到需要去除图片水印的情况——无论是保存他人分享的精美图片、整理素材库,还是为了个人使用和内容二次创作。市场上有许多去水印工具,但质量参差不齐,收费模式也各不相同。本文为你盘点了2026年最实用的免…...

蒙古语AI语音落地难?ElevenLabs最新v3.2模型支持率提升至98.7%,但90%开发者忽略这5个编码陷阱
更多请点击: https://intelliparadigm.com 第一章:蒙古语AI语音落地的现实困境与技术拐点 蒙古语作为中国少数民族语言中使用人口较多、语法高度黏着、音系复杂的阿尔泰语系代表,其AI语音技术长期受限于低资源特性——标准语音数据集不足50小…...