Redis 与 Scrapy:无缝集成的分布式爬虫技术

1. 分布式爬虫的概念
分布式爬虫系统通过将任务分配给多个爬虫节点,利用集群的计算能力来提高数据抓取的效率。这种方式不仅可以提高爬取速度,还可以在单个节点发生故障时,通过其他节点继续完成任务,从而提高系统的稳定性和可靠性。
2. Scrapy 简介
Scrapy 是一个用于快速抓取 web 数据的 Python 框架。它提供了一个异步处理的架构,可以轻松地处理大规模数据抓取任务。Scrapy 的主要特点包括:
- 异步处理:利用 Twisted 异步网络库,Scrapy 可以同时处理多个请求,提高数据抓取的效率。
- 强大的选择器:Scrapy 使用 lxml 或 cssselect 作为选择器,可以方便地从 HTML/XML 页面中提取数据。
- 中间件支持:Scrapy 支持下载中间件和蜘蛛中间件,允许开发者在请求和响应处理过程中插入自定义逻辑。
- 扩展性:Scrapy 可以轻松地与各种存储后端(如数据库、文件系统)集成。
3. Redis 简介
Redis 是一个开源的内存数据结构存储系统,用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串、哈希、列表、集合等。Redis 的主要特点包括:
- 高性能:Redis 的数据存储在内存中,读写速度快。
- 高可用性:通过主从复制和哨兵系统,Redis 可以提供高可用性。
- 数据持久化:Redis 支持 RDB 和 AOF 两种持久化方式,确保数据的安全性。
- 丰富的数据类型:Redis 支持字符串、列表、集合、有序集合、散列等多种数据类型。
4. Scrapy-Redis 架构
Scrapy-Redis 是 Scrapy 与 Redis 的集成库,它将 Scrapy 的爬虫任务和结果存储在 Redis 中。这种架构的主要优势包括:
- 分布式处理:通过 Redis,Scrapy-Redis 可以将爬虫任务分配到多个爬虫节点,实现分布式处理。
- 去重:利用 Redis 的集合数据类型,Scrapy-Redis 可以轻松实现 URL 的去重。
- 任务队列:Redis 作为任务队列,可以存储待抓取的 URL,避免重复抓取。
5. Scrapy-Redis 组件
Scrapy-Redis 架构主要由以下几个组件构成:
- Redis 服务器:作为数据存储和任务队列的后端。
- Scrapy 爬虫:执行实际的数据抓取任务。
- Scrapy-Redis 扩展:提供 Scrapy 与 Redis 之间的集成功能。
6. 实现 Scrapy-Redis 架构
以下是实现 Scrapy-Redis 架构的基本步骤和示例代码:
首先,需要安装 Scrapy 和 Scrapy-Redis。可以通过 pip 安装.
在 Scrapy 项目的 settings.py 文件中。
接下来,定义一个 Scrapy 爬虫,并使用 Redis 存储爬取结果。
import scrapy
from scrapy import Request
from scrapy.utils.project import get_project_settings
from scrapy.exceptions import NotConfigured
from twisted.internet import reactor
from twisted.internet.error import TimeoutError
from twisted.internet.defer import inlineCallbacks
from scrapy.http import HtmlResponse
from scrapy.utils.response import response_status_messagefrom scrapy_redis.spiders import RedisSpiderclass ProxyMiddleware(object):def __init__(self, proxyHost, proxyPort, proxyUser, proxyPass):self.proxyHost = proxyHostself.proxyPort = proxyPortself.proxyUser = proxyUserself.proxyPass = proxyPass@classmethoddef from_crawler(cls, crawler):settings = crawler.settingsreturn cls(proxyHost=settings.get('PROXY_HOST'),proxyPort=settings.get('PROXY_PORT'),proxyUser=settings.get('PROXY_USER'),proxyPass=settings.get('PROXY_PASS'))def process_request(self, request, spider):proxy = f"{self.proxyUser}:{self.proxyPass}@{self.proxyHost}:{self.proxyPort}"request.meta['proxy'] = proxyclass MySpider(RedisSpider):name = 'example'redis_key = 'example:start_urls'def start_requests(self):yield scrapy.Request(url=self.start_urls[0], callback=self.parse)def parse(self, response):for href in response.css('a::attr(href)').getall():yield response.follow(href, self.parse_item)def parse_item(self, response):item = {'domain_id': response.url,'domain_name': response.url,}yield item# settings.py
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300,
}DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'SCHEDULER = 'scrapy_redis.scheduler.Scheduler'SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue'
SCHEDULER_QUEUE_LIMIT = 10000REDIS_URL = 'redis://localhost:6379'DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.ProxyMiddleware': 100,
}PROXY_HOST = "www.16yun.cn"
PROXY_PORT = "5445"
PROXY_USER = "16QMSOML"
PROXY_PASS = "280651"
7.结论
Scrapy-Redis 架构通过将 Scrapy 的爬虫任务和结果存储在 Redis 中,实现了高效的数据抓取。这种架构不仅提高了数据抓取的效率,还增强了系统的可扩展性和稳定性。通过合理的配置和优化,可以进一步发挥 Scrapy-Redis 架构的优势,满足大规模数据抓取的需求。
相关文章:
Redis 与 Scrapy:无缝集成的分布式爬虫技术
1. 分布式爬虫的概念 分布式爬虫系统通过将任务分配给多个爬虫节点,利用集群的计算能力来提高数据抓取的效率。这种方式不仅可以提高爬取速度,还可以在单个节点发生故障时,通过其他节点继续完成任务,从而提高系统的稳定性和可靠性…...

大厂linux面试题攻略四之Linux网络服务(一)
一、Linux网络服务-SSH服务 1.哪些设置能够提升SSH远程管理的安全等级? ssh的登录验证方式 ssh的登录端口和监听设置: 配置文件: /etc/ssh/sshd_config #Port 22 #ssh服务默认监听端口 #ListenAddress 0.0.0.0 #ssh服务…...

【Pulling fs layer】Linux使用docker-compose的时候,一直Pulling fs layer
当Docker在拉取镜像时卡在“pulling fs layer”阶段,可以通过重启Docker服务来解决。 具体步骤如下: 首先,尝试重启Docker服务。可以通过运行以下命令来重启Docker服务: systemctl restart docker 这个命令会重启Docker服务…...

最新保姆级教程使用WildCard开通Claude3升级ChatGPT4.0(2024.8)
如何使用 WildCard 服务注册 Claude3 随着 Claude3 的震撼发布,最强 AI 模型的桂冠已不再由 GPT-4 独揽。Claude3 推出了三个备受瞩目的模型:Claude 3 Haiku、Claude 3 Sonnet 以及 Claude 3 Opus,每个模型都展现了卓越的性能与特色。其中&a…...

layui 乱入前端
功能包含 本实例代码为部分傻瓜框架,插入引用layui。因为样式必须保证跟系统一致,所以大部分功能都是自定义的。代码仅供需要用layui框架,但原项目又不是layui搭建的提供解题思路。代码较为通用 自定义分页功能自定义筛选列功能行内编辑下拉、…...
中国十大顶级哲学家,全球公认的伟大思想家颜廷利:人类为何拥有臀部
人类为何拥有臀部?若众生皆无此部位,又如何能寻得一处真正属于自己的“座位”?在博大精深的中国传统文化中,汉字“座”与“坐”均蕴含“土”字元素。在易经的智慧里,作为五行之一的“土”,象征着人类社会的…...

Threejs中导入GLTF模型克隆后合并
很多场景中会需要同一个模型很多次,但是如果多次加载同一个模型会占用很高的带宽,导致加载很慢,因此就需要使用clone,也就是加载一个模型后,其他需要使用的地方使用clone的方式复制出多个同样的模型,再改变…...

今日arXiv最热大模型论文:北京大学最新综述:视觉大模型中的漏洞与攻防对抗
近年来,视觉语言大模型(LVLM)在文本转图像、视觉问答等任务中大放异彩,背后离不开海量数据、强大算力和复杂参数的支撑。 但是!大模型看似庞大的身躯背后却有一颗脆弱的“心脏”,极易受到攻击。攻击者可以…...
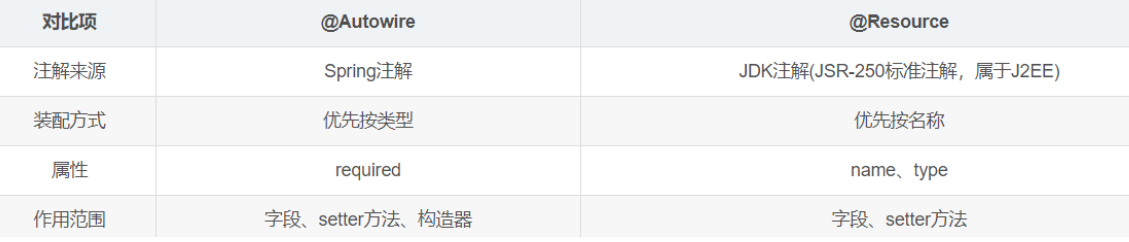
为什么IDEA中使用@Autowired会被警告
我们在使用IDEA编码时,如果用到了Autowired注解注入bean,会发现IDEA会给代码标个波连线,鼠标移动上去,会发下idea提示:不推荐使用Filed injection,这是Spring的核心DI(Dendency Injection&#…...

uniapp使用cover-view,使用@click无效
最近要做直播详情页面,用的是第三方直播链接,需要在该页面上放两个按钮,点击按钮需要弹出相关商品及优惠券。类似于抖音直播页面。 第三方链接使用的是web-view进行展示。由于该组件优先级太高,正常的前端组件无法在该页面浮现展…...

Postman 接口测试工具简易使用指南
一、Postman是什么? 我通过kimi问了这样一个问题,它给我的回答是这样的: 它的回答也算比较中规中矩,简单的说postman实际上就是一款接口测试工具,同时它还可以编写对应的测试脚本以及自动生成对应的API文档,结合我的习惯来说&am…...

Move生态:从Aptos和Sui到Starcoin的崛起
区块链技术自诞生以来,已经经历了多个发展阶段和技术迭代。近年来,随着智能合约平台的不断演进,以Move语言为核心的生态系统逐渐崭露头角。Move语言以其安全性、灵活性和高效性吸引了大量开发者和项目方的关注。在Move生态中,Apto…...

MacOS DockerDesktop配置文件daemon.json的位置
如果因为通过可视化页面修改配置错误导致客户端启动不起来,可以去找对应的配置文件通过 vim 修改后重启客户端 cd ~/.docker/...

从光速常数的可变性看宇宙大爆炸的本质
基于先前关于光速本质的讨论,让我们从函数图像看看宇宙大爆炸到底是什么。 先前已经讨论过,在量子尺度上,长度的实际对应物是频率的差异,因为只有频率差异才能在这个尺度上区分相邻时空的两点,而两点之间“差异的大小”…...

敢不敢跟我一起搭建一个Agent!不写一行代码,10分钟搞出你的智能体!纯配置也能真正掌握AI最有潜力的技术?AI圈内人必备技能
说一千道一万,不如实地转一转。学了那么久的AI Agent的概念了,是时候该落地一个Agent看看自己的掌握程度了对不对,我们都理解大脑是自动节能的,但是知识的确需要倒逼自己一把才能真的掌握,不瞒大家说,笔者对…...

vue3和vite双向加持,uni-app性能爆表,众绑是否有计划前端升级到vue3!
uni-app官方已经开始不支持vue2了,而且即将适配的鸿蒙next原生系统,也不支持vue2打包,CRMEB是否有计划跟上潮流呢,如果有会在什么时间呢,有准确的时间表吗?我们非常期待得到答案! 新版 uni-app…...

2024年最强网络安全学习路线,详细到直接上清华的教材!
关键词:网络安全入门、渗透测试学习、零基础学安全、网络安全学习路线 首先咱们聊聊,学习网络安全方向通常会有哪些问题前排提示:文末有CSDN官方认证Python入门资料包 ! 1、打基础时间太长 学基础花费很长时间,光语…...

人脸识别又进化:扫一下 我就知道你得了啥病
未来,扫下你的脸,可能就知道你得啥病了。没在瞎掰,最近的一项研究成果,还真让咱看到了一点眉目。北大的一个研究团队,搞出来一个 AI ,说是用热成像仪扫一下脸,就能检测出有没有高血压、糖尿病和…...

yolov8标注细胞、识别边缘、计算面积、灰度值计算
一、数据标注 1. 使用labelme软件标注每个细胞的边界信息,标注结果为JSON格式 2. JSON格式转yolo支持的txt格式 import json import os import glob import os.path as osp此函数用来将labelme软件标注好的数据集转换为yolov5_7.0sege中使用的数据集:param jsonfi…...
WEB前端11-Vue2基础01(项目构建/目录解析/基础案例)
Vue2基础(01) 1.Vue2项目构建 步骤一:安装前端脚手架 npm install -g vue/cli步骤二:创建项目 vue ui步骤三:运行项目 npm run serve步骤四:修改vue相关的属性 DevServer | webpack //修改端口和添加代理 const { defineCo…...

Bidili Generator效果展示:宠物肖像生成——毛发细节+神态捕捉实测
Bidili Generator效果展示:宠物肖像生成——毛发细节神态捕捉实测 1. 引言:当AI遇见宠物肖像 你有没有想过,给自家宠物拍一张专业级的肖像照?不是那种随手一拍的生活照,而是能捕捉到它们独特神态、展现每一根毛发细节…...

手把手教你用QEMU+GDB调试RISC-V中断:以蜂鸟E200 ECLIC为例
从零构建RISC-V中断调试实战:基于QEMU与蜂鸟E200 ECLIC的深度解析 第一次在QEMU中成功捕获到中断向量跳转时,GDB窗口里那个闪烁的mtvec地址让我兴奋得差点打翻咖啡——这比看任何理论文档都直观十倍。作为从ARM Cortex-M转型RISC-V的嵌入式开发者&#x…...

零代码驯服Qwen-2.5VL:LLaMA-Factory图形界面实战指南
1. 为什么你需要零代码驯服Qwen-2.5VL 想象一下,你手里有一台能看懂图片的AI机器人,但它总把工业零件认成厨房用具。传统解决方法需要你租用几十张显卡,像炼丹一样折腾几个月——但现在,有了LLaMA-Factory的图形界面,这…...
)
QT事件过滤器实战:如何用eventFilter拦截鼠标移动事件(附完整代码)
QT事件过滤器实战:如何精准拦截鼠标移动事件 在QT开发中,事件处理机制是GUI编程的核心。当我们需要对特定控件的事件流进行精细化控制时,事件过滤器(eventFilter)提供了一种优雅的解决方案。不同于直接重写事件处理函数,事件过滤器…...

深入解析DHT11单总线通信:如何通过时序控制实现稳定数据传输?
1. DHT11单总线通信的基本原理 第一次用DHT11传感器时,我被它只用一根线就能传数据惊到了。这就像两个人打电话,不需要复杂的线路,只要一根电话线就能聊天气温湿度。DHT11采用的单总线协议(1-Wire Protocol)就是这样一…...
)
告别云端排队!用你的RTX 3060笔记本,15分钟搞定本地图生视频(FramePack保姆级配置)
用RTX 3060笔记本玩转AI视频创作:FramePack本地化实战指南 当在线AI视频生成服务需要排队等待时,拥有6GB显存的RTX 3060笔记本用户其实可以解锁更高效的创作方式。本文将带你探索如何利用FramePack这一创新工具,在消费级硬件上实现高质量的图…...

ViGEmBus虚拟游戏手柄驱动:重构Windows输入控制生态的核心引擎
ViGEmBus虚拟游戏手柄驱动:重构Windows输入控制生态的核心引擎 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 一、价值定位:虚拟设备…...

SPI总线抽象架构设计与实现
## 1. SPI总线抽象架构设计### 1.1 设计目标与架构分层 SPI总线抽象设计主要解决三个核心问题: 1. 总线与设备解耦:通过分层设计实现硬件无关性 2. 快速切换硬件/模拟SPI:统一接口规范支持多种实现方式 3. 跨平台移植性:核心逻辑与…...

差点被这套AI工具搞离职...搞懂MCP和Skill后,我发现宇宙的尽头是“写小作文”
剥开神秘面纱前两天,隔壁组的新人小王差点被开除。这小子为了赶进度,搞了个瞎折腾的操作:把公司一个十几万行的老旧核心项目,一股脑全扔进 Cursor 里,连哄带骗地让 AI 帮他重构。结果呢?跑出来的代码简直是…...

DeOldify图像上色服务快速上手:3步搭建个人老照片修复站
DeOldify图像上色服务快速上手:3步搭建个人老照片修复站 1. 为什么选择DeOldify图像上色服务 黑白老照片承载着珍贵的记忆,但随着时间的流逝,这些影像逐渐褪色。传统的手工上色方法不仅耗时耗力,而且成本高昂。现在,…...