转转上门履约服务拆分库表迁移实践
文章目录
- 1 背景
- 2 数据迁移方案
- 2.1 方案一:双写新旧库
- 2.2 方案二:灰度开关切换新旧库
- 3 迁移细节
- 3.1 业务代码改造
- 3.2 数据同步
- 3.3 数据一致性校验
- 4 总结
- 5 参考资料
1 背景
随着业务不断发展,一个服务中部分功能模块适合沉淀下来作为通用的基础能力。作为通用的基础能力,对提供的服务可用性和稳定性有较高的要求,因此把该部分功能模块拆分出来,单独一个服务是比较好的选择。为了更好的与业务服务物理隔离,不仅需要从代码层面拆分,数据库层面也需要拆分。在做技术方案设计时面临着以下几个问题:
- 迁移过程中是否允许停服?如果停服,停服时间窗口如何做到尽可能短?
- 旧库表数据如何迁移到新库?
- 迁移后如何保证旧库表数据与新库表数据一致?
2 数据迁移方案
面向C端用户的场景,我们可能会脱口而出一个数据双写的方案。面向B端用户场景,可能直接暴力停服迁移。很多时候线上业务场景都是读多写少,如果把上面两个方案折衷一下也是一个不错的迁移方案。
下面介绍两个数据迁移方案,一个是大家耳熟能详的数据双写,另一个是以短暂写入失败为代价的开关控制迁移方案。
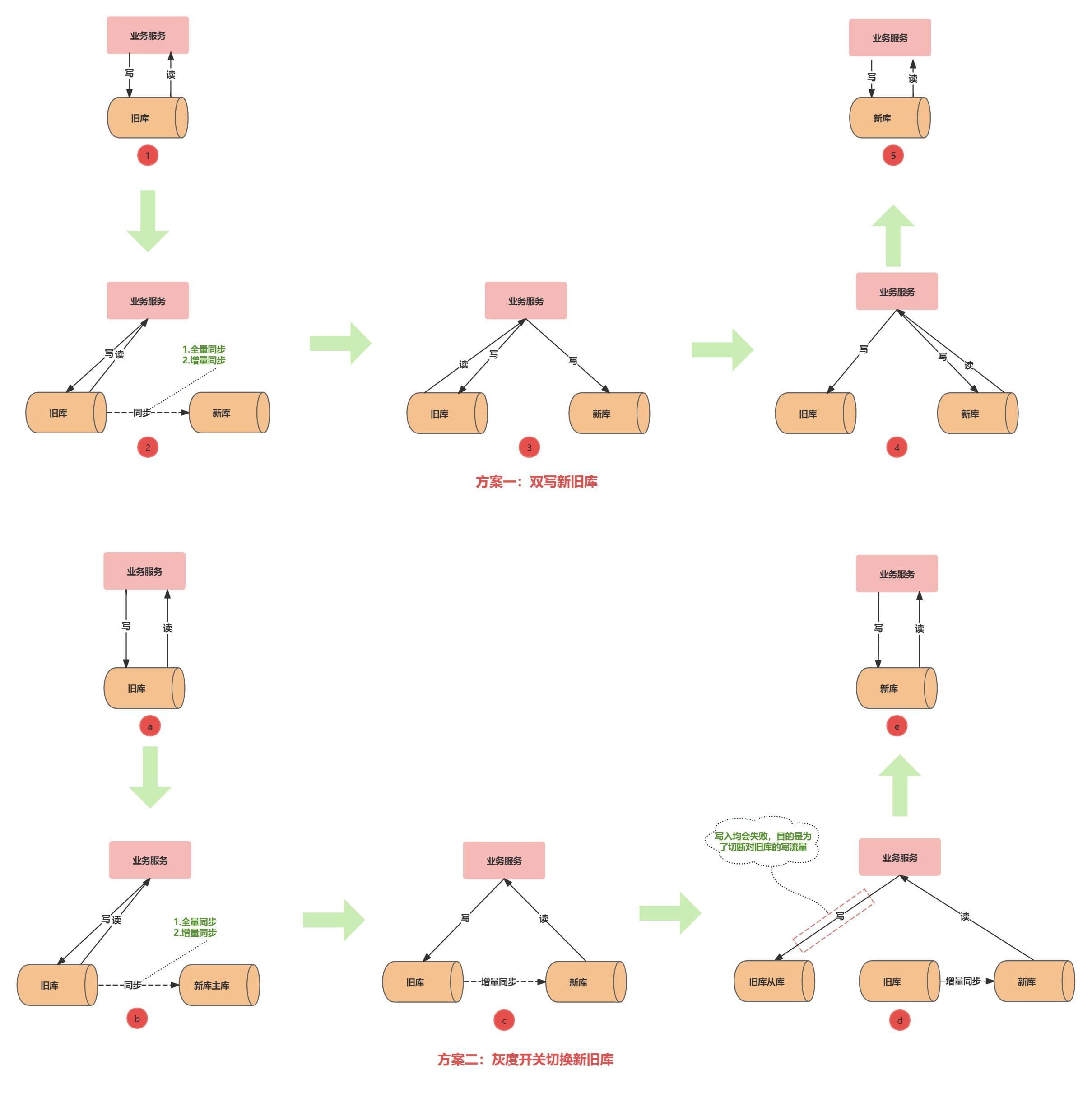
2.1 方案一:双写新旧库
双写的迁移流程如下图所示:
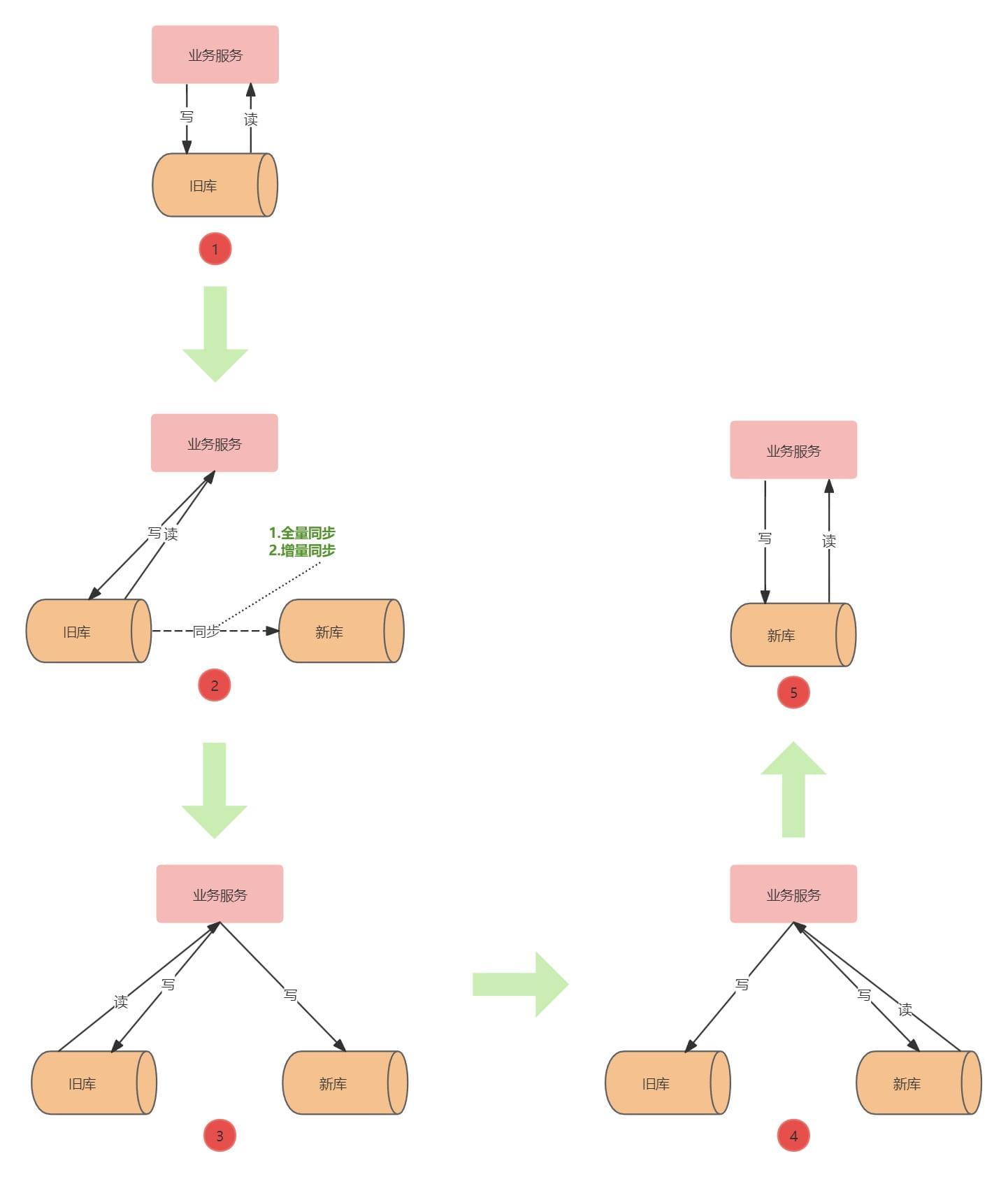
- ②新旧库数据同步:由DBA协助完成旧库表数据迁移到新库,并使用增量同步工具把旧库表数据同步到新库。
- ③开启双写:业务服务迁库代码改造上线,在业务写入低峰期校验新库与旧库表数据一致后,DBA断开旧库与新库的同步,业务服务同步开启写新库开关,开始双写。
- ④读新库:校验新库与旧库表数据一致后,读流量切换到新库进行数据验证,验证期间有问题可以随时切换回旧库。
- ⑤代码清理:读写流量全量切换新库,下线写旧库代码。
采用双写方案迁移库表可以做到用户无感知的平滑切换,验证过程中发现问题可以及时回滚。
双写引入了多个数据源,项目中如果使用了事务,面临着跨库事务,对事务代码块的改动成本相对较大。同时还面临着同步双写和异步双写的选择:
- 同步双写:新旧库的数据一致性有保障,写新库失败会影响现有的业务。
- 异步双写:写新库失败会导致数据不一致,不影响现有业务,需要额外的补偿方案保证新旧库数据的最终一致。
2.2 方案二:灰度开关切换新旧库
该方案不涉及双写,在代码里根据开关控制使用新库还是旧库,切换流程如下图所示:
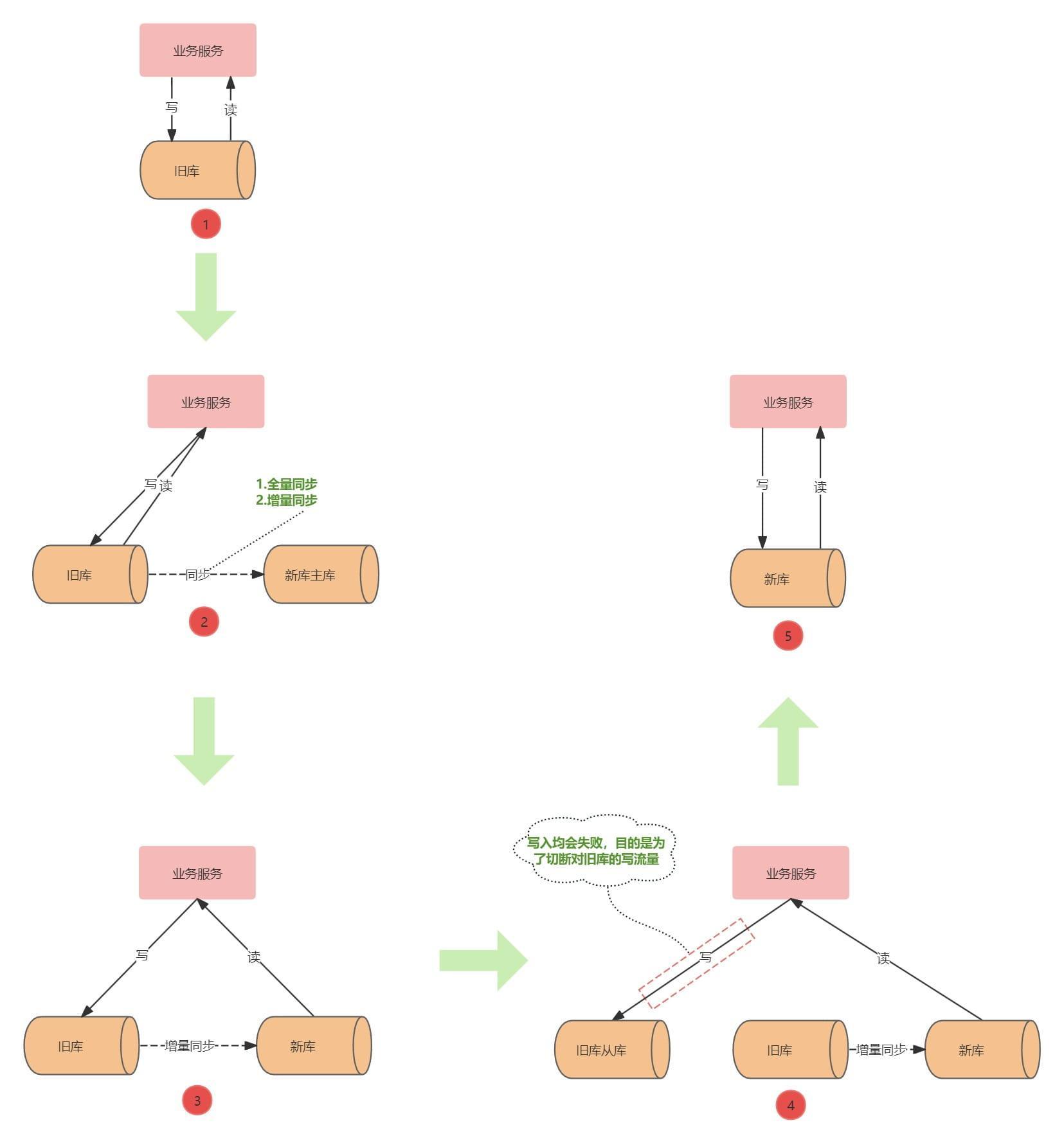
- ②新旧库数据同步:DBA协助先将旧库表数据迁移到新库,然后再使用增量同步工具把旧库表数据同步到新库。
- ③验证读新库:改造好的业务服务部署后,新库与旧库保持增量同步,开启读新库开关,读流量切换到新库进行验证,验证过程出现问题可以通过控制开关切回读旧库数据
- ④新旧库切换:整个切换流程的核心,改造好的业务服务上线。先切断对旧库的写入流量,让新库与旧库的增量同步追平,同时校验新库与旧库表数据的一致性,一致时便可把写流量切换到新库。
- ⑤代码清理:业务服务读写流量均切换到新库。
④为什么要把写流量切换到旧库的从库?
写流量切换到旧库的从库目的是为了断开对旧库相应表的写入流量,营造相对“静止”的环境让新库可以追上旧库。切断对旧库写入流量的方式有很多,选择写从库的方式来主要为了让开关都收拢到一处。
除此之外,我们可以对数据库帐号授权的形式来实现写流量的断开:
REVOKE INSERT, UPDATE, DELETE ON database_name.table_name FROM 'username';
从上述步骤中可以看到该方案有个硬伤:有短暂的停服过程。优点是确保迁移到新库的数据一定与旧库一致的,对有使用事务的场景,不需要考虑跨库事务,代码改造成本低。
3 迁移细节
我们要改造的业务服务代码中涉及声明式事务和编程式事务,为了降低跨库事务带来的改造成本,并结合上门履约的业务场景——业务数据写入多集中于白天,我们最终采用了“灰度开关切换新旧库”方案。
3.1 业务代码改造
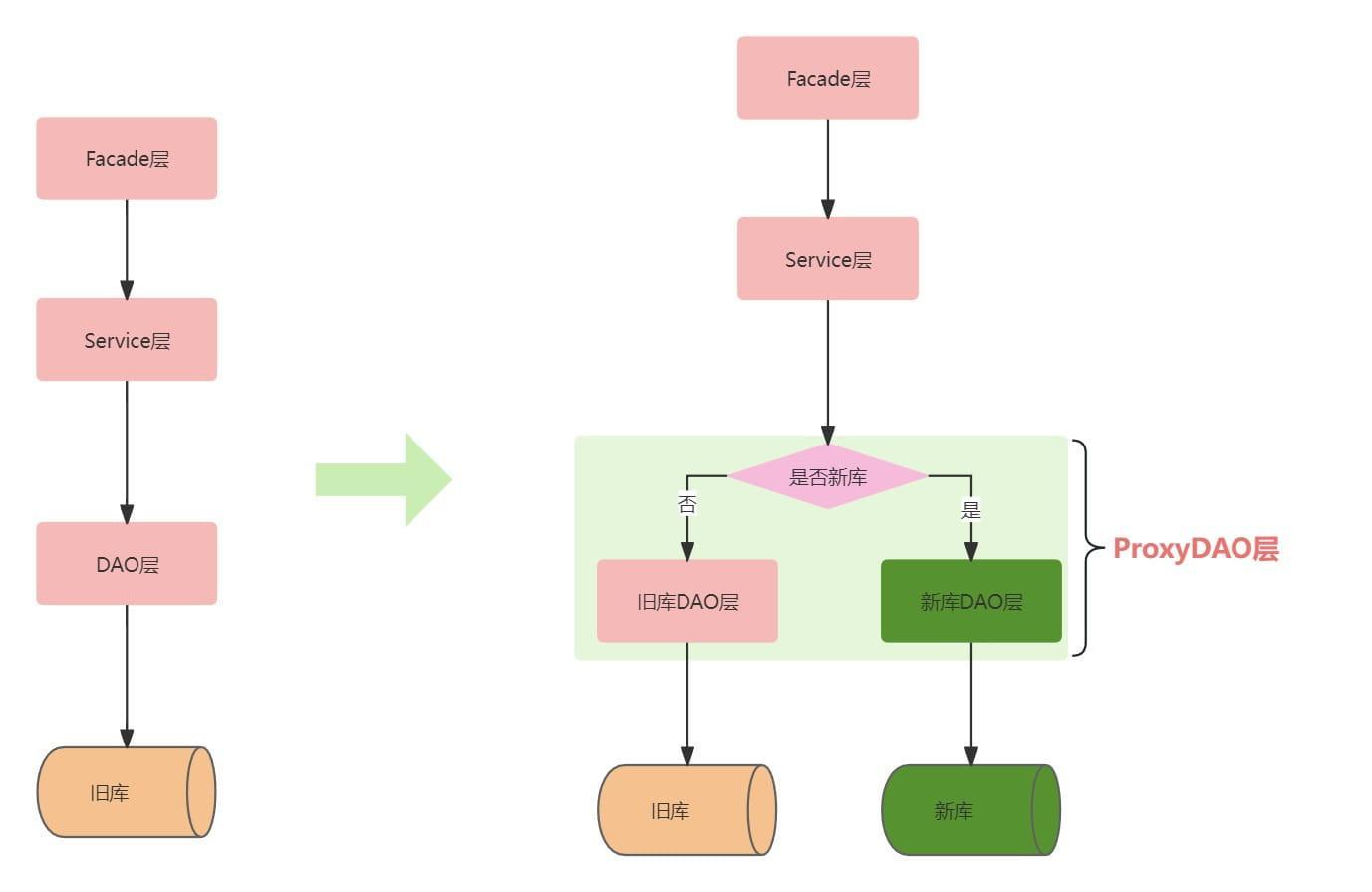
需要迁移的表数量不多,实现时对DAO层代码进行改造,抽取ProxyDAO层,原来对DAO层的方法调用全部替换成ProxyDAO,ProxyDAO层代码植入开关控制代码,根据开关决定访问新库旧库。
3.2 数据同步
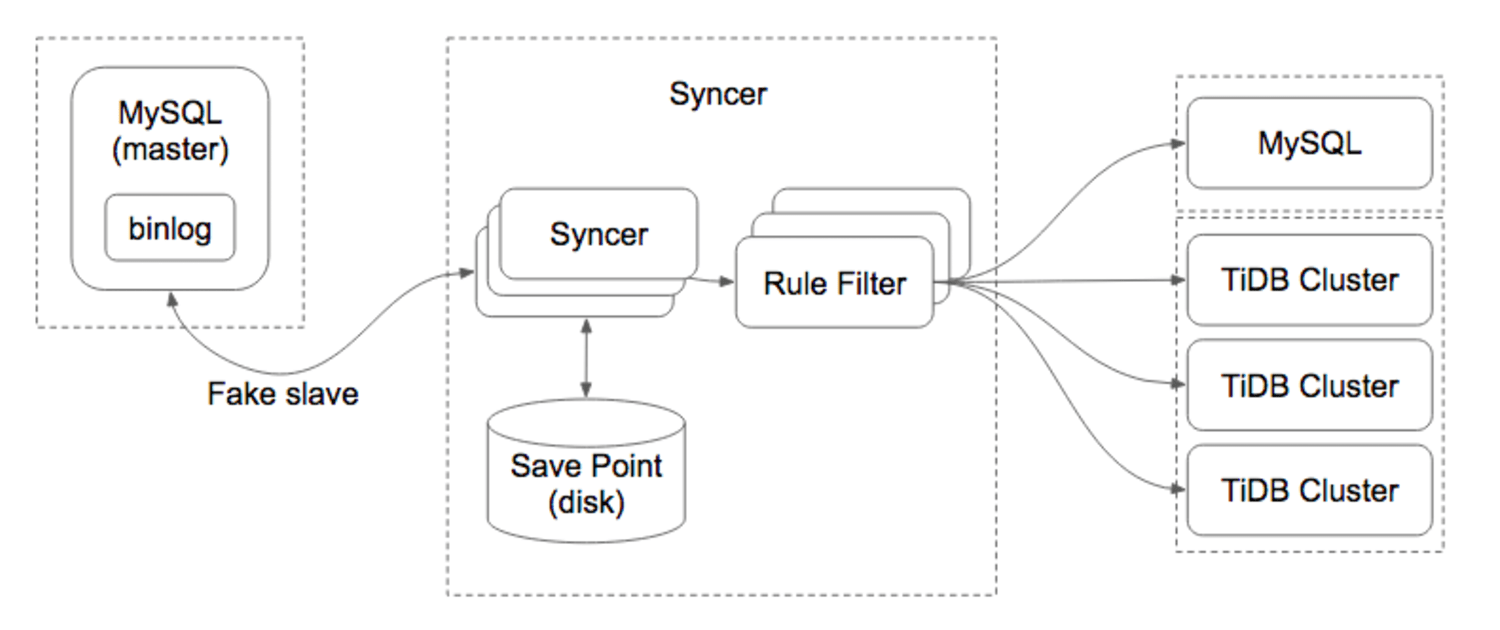
创建好新库后,DBA将旧库需要迁移的表数据全量同步一次到新库,然后使用PingCAP的数据导入工具——Syncer,使用该工具进行数据增量同步需要满足以下前提:
- 5.5 < MySQL 版本 < 8.0
- 开启binlog,并且格式为
ROW,且binlog_row_image必须设置为为FULL
从Syncer架构图不难看出:同步时Syncer把自己伪装成一个 MySQL Slave,和 MySQL Master 进行通信,然后不断读取 MySQL binlog,进行 binlog 事件解析,规则过滤和数据同步。
3.3 数据一致性校验
不管是双写还是灰度开关切换新旧库的方案,都绕不开数据一致性校验。数据不一致如何产生的?
双写新旧库可能产生数据不一致的场景:
- 图-5③:DBA检测新旧库无差异后关闭同步,写新库开关未开启前旧库来了写入的流量
- 图-5③/④:双写后使用异步方式双写新库写入失败
灰度开关切换新旧库可能产生数据不一致的场景:
- 图-5c/d:数据同步工具挂了
我们所使用的迁移方案需要重点关注新旧库的同步情况,为此我们做了2层数据校验:
- DBA在旧库写流量关闭后对数据进行一致性校验
- 业务服务写个定时任务定期去抽样校验
MySQL主从模式下可以通过show slave status 命令查看主从延迟情况,根据Seconds_Behind_Master的值是否为0来判定是否有延迟,有延迟2个库的数据肯定不一致。上面提到我们增量同步使用的是Syncer,它只是伪装成从库,并不是真正的从库,使用MySQL主从模式下数据一致性校验方法行不通了,因此借助了PingCAP官方提供的sync-diff-inspector工具进行数据一致性校验。
sync-diff-inspector工具架构图如下所示:
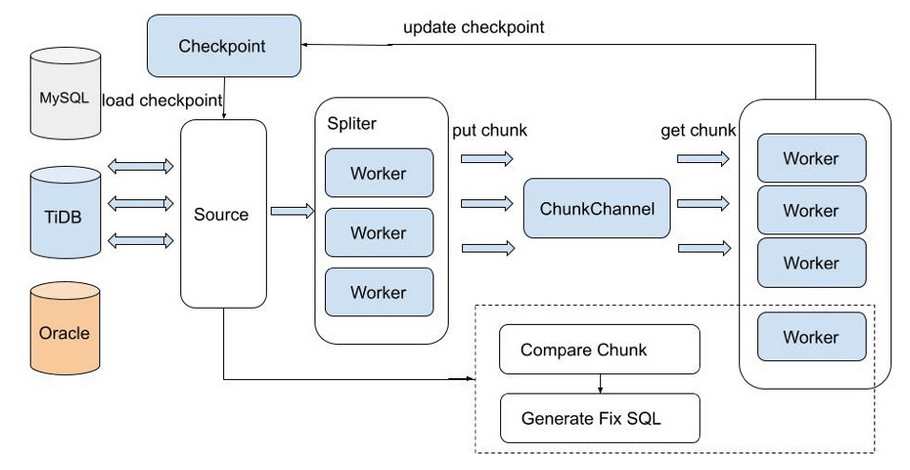
sync-diff-inspector校验流程主要分以下步骤:
- 对需要比较的表数据使用多线程方式划分为多个chunk,采用生产者-消费者模型将划分的chunk放入队列里
- 消费者线程从队列取出划分好的chunk,对这个chunk的上下游数据对比,计算出checksum
- 某个chunk的上下游checksum如果不一致,则对该chunk二分法方式找出不一致的数据,生成修复SQL
使用sync-diff-inspector工具对新旧库表全量校验后数据基本可以保障一致,不过该工具使用的前提是需要保证数据校验期间被校验的表上下游都没有数据写入。从校验工具的工作原理来看,校验耗时跟数据量成正比,迁移的数据越多校验时间越长,如果对全量数据的校验,校验周期会变得特别长。
根据目前业务现状,已经到终态的冷数据基本不会有写入操作。为尽可能缩短写入失败时间,业务数据校验的重点放在近期修改过的数据。冷数据不需要每次一致性校验时都参与进来。可以根据更新时间作为筛选条件,在新旧库抽取最近一段时间内修改过的数据,逐行对比数据是否一致,校验流程如下图所示:
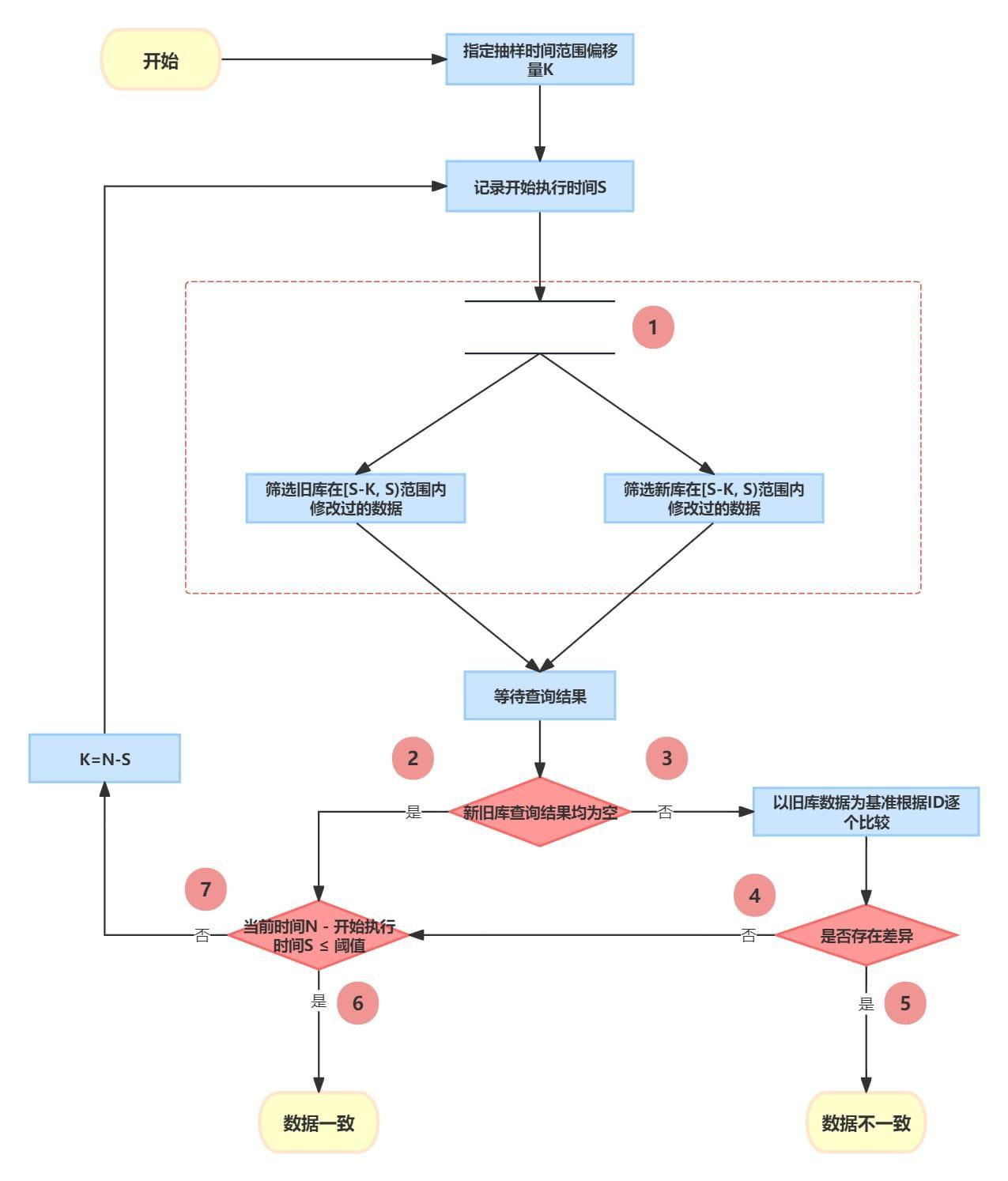
对旧库和新库按照更新时间筛选数据时,使用多线程并发的方式取数,尽可能减少时间差。
根据更新时间筛选数据时,我们可能很自然的写出了下面的SQL:
select * from table where update_time >= X;
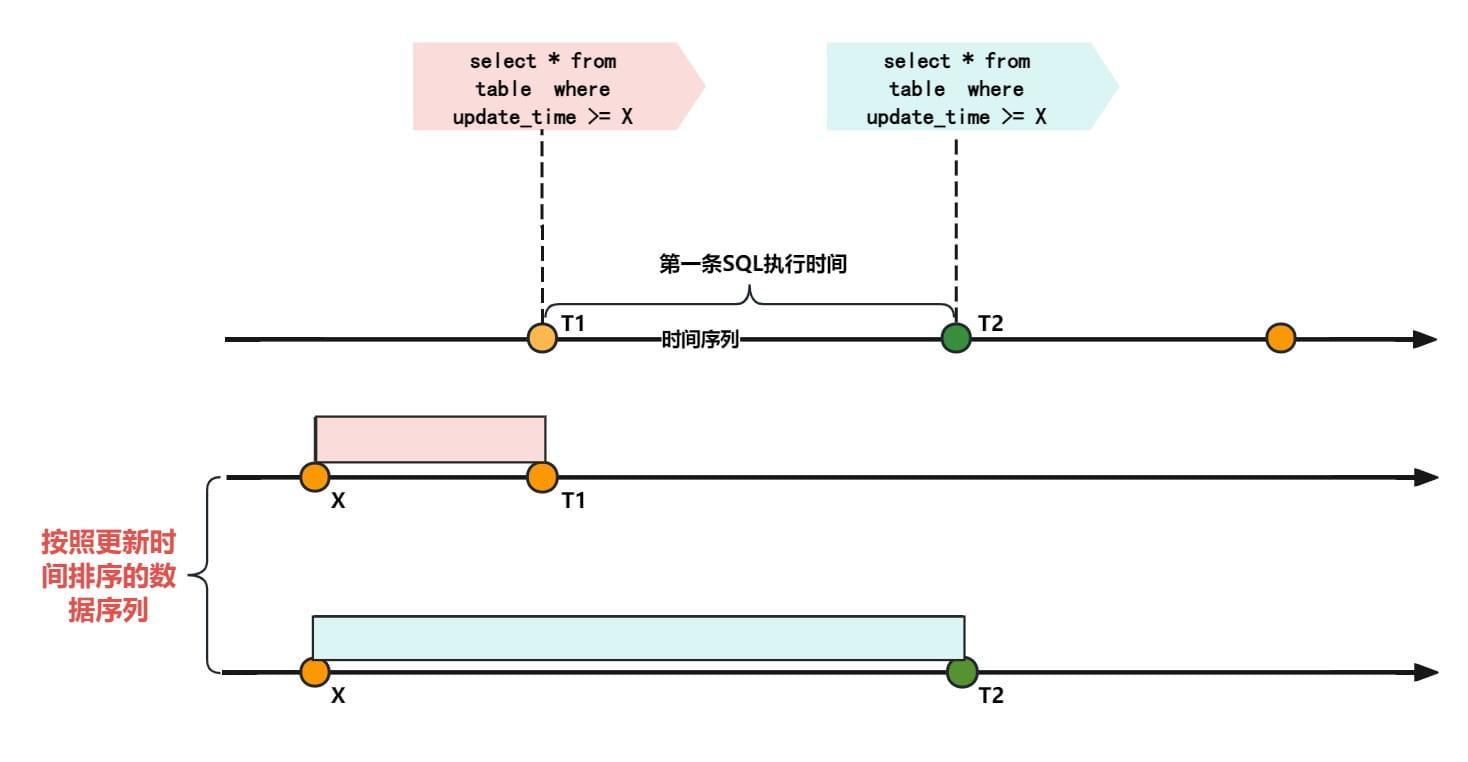
这个SQL如果使用单线程串行的方式执行,后面执行查出来的结果大概率会跟先执行的不一样。因为SQL筛选数据本身也会有耗时,特别是筛选时间范围比较大的时候,需要扫描更多的数据,耗费的时间越长。SQL筛选数据期间修改的数据,对先执行的SQL来说是不可见的。
校验时先对冷数据做一次全量校验,之后每次都是校验最近修改的,这样可以大大缩小查询范围,缩短校验数据一致性的时间。查询条件使用了上界和下界限定条件,保障了统计口径是一致的。校验代码消耗的时间,作为下一次迭代使用的时间偏移量,当“新旧库查询结果都为空”时表明最近都没有数据写入,并且N-S的时间差足够小,是可以认为两个库的表数据是一致的,这个时候把流量自动切换到新库可以实现平滑迁库。
N-S的时间差在什么量级?
初始时这个时间差会比较大,整个迭代过程中首次使用的更新时间筛选范围一般是最大的,除非一次取数时间加上程序校验时间的耗时比初始指定的偏移量K大。更新时间筛选范围会随着迭代越来越小,在写流量低峰期,SQL查出的数据也会越来越少,直至查不出数据。这个时间差差不多就是一条根据更新时间查数据的时间。如果更新时间是索引,查询的时间范围很小,N-S的时间差最优情况下是在毫秒级的。
4 总结
最终我们采用保守的方式——旧库写流量切换从库,没有使用平滑切换的方案。以业务数据校验为主,DBA层数据校验为辅完成数据的迁移。整个过程读流量正常,写流量在切换到旧库从库 → 新旧库增量数据一致性校验 → 写流量切换到新库期间会失败,流量低谷期写入失败时间不超过5秒。
我们选择短暂停服的技术方案,这个方案虽然不是最优的,但是会跟业务更匹配,方案简单,改造成本低,对业务影响范围更小。技术方案的选择一定是贴合实际业务场景的,脱离业务场景的所谓最优方案不过是空中楼阁,当真正踏出登楼第一步时可能就坍塌了。
服务拆分&数据迁移对技术功底要求不那么高,并不需要使用高深的技术,更多的是考验一个人细心程度,对每个细节的深入思考与把控。失之毫厘,差之千里,一个细节没处理好,可能就会带来灾难性问题。
大家还有什么好的平滑迁移数据的方法欢迎到评论区留言。
5 参考资料
- 解析 TiDB 在线数据同步工具 Syncer
- PingCAP 文档
关于作者
张莲祥,转转上门履约业务研发工程师
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~
相关文章:
转转上门履约服务拆分库表迁移实践
文章目录 1 背景2 数据迁移方案2.1 方案一:双写新旧库2.2 方案二:灰度开关切换新旧库 3 迁移细节3.1 业务代码改造3.2 数据同步3.3 数据一致性校验 4 总结5 参考资料 1 背景 随着业务不断发展,一个服务中部分功能模块适合沉淀下来作为通用的…...

upload-labs 1-19关 攻略 附带项目下载地址 小白也能看会
本文章提供的工具、教程、学习路线等均为原创或互联网收集,旨在提高网络安全技术水平为目的,只做技术研究,谨遵守国家相关法律法规,请勿用于违法用途,如有侵权请联系小编处理。 环境准备: 1.靶场搭建 下…...

如何设置SQL Server的端口:详细步骤指南
如何设置SQL Server的端口:详细步骤指南 在SQL Server中,配置端口是确保数据库服务能够正确通信的重要步骤。无论是为了提高安全性还是满足特定的网络配置需求,正确设置SQL Server的端口都是必要的。本文将详细介绍如何设置SQL Server的端口…...

昇思25天学习打卡营第16天|Diffusion扩散模型,DCGAN生成漫画头像
Diffusion扩散模型 关于扩散模型(Diffusion Models)有很多种理解,本文的介绍是基于denoising diffusion probabilistic model (DDPM),DDPM已经在(无)条件图像/音频/视频生成领域取得…...
【吊打面试官系列-Dubbo面试题】Dubbo SPI 和 Java SPI 区别?
大家好,我是锋哥。今天分享关于 【Dubbo SPI 和 Java SPI 区别?】面试题,希望对大家有帮助; Dubbo SPI 和 Java SPI 区别? JDK SPI JDK 标准的 SPI 会一次性加载所有的扩展实现,如果有的扩展吃实话很耗时&…...
)
7.31 Day13 网络散记(http,https...)
http固定对应80端口 https固定对应443端口...

LumaLabs 用例和应用分析
介绍 LumaLabs AI 是一家尖端技术公司,通过创新使用人工智能 (AI) 和神经渲染技术,彻底改变了 3D 内容创作领域。本报告深入探讨了 LumaLabs AI 的各种用例和应用,重点介绍了其在不同行业中的能力、优势和潜在影响。 LumaLabs AI 概述 LumaL…...
)
leetcode88.合并两个有序数组(简单题!)
思路:合并两个数组,再进行排序(利用快速排序) class Solution(object):def quicksort(self, num, i, j):if i>j: # 跳出循环的条件要出来return left iright jtemp num[i]while left < right:while left < right and…...

鸿蒙(HarmonyOS)DatePicker+TimePicker时间选择控件
一、操作环境 操作系统: Windows 11 专业版、IDE:DevEco Studio 3.1.1 Release、SDK:HarmonyOS 3.1.0(API 9) 二、效果图 可实现两种选择方式,可带时分选择,也可不带,使用更加方便。 三、代码 SelectedDateDialog…...

2024年和2025年CFA FRM CAIA ESG自己整理的资料
本人金融女一枚,CFA FRM CAIA ESG已过,研究生学历,职位投资经理。从事金融快5年了,月薪30000,周未双休五险一金。工作很充实也很累,每天失眠,思考了很久,还是决定离职了,…...

AMD第二季度财报:数据中心产品销售激增,接近总收入一半
#### 财报亮点 7月30日,AMD公布了截至6月29日的第二季度财务业绩,利润超过了华尔街的预期。根据TechNews的报道,最值得注意的是,AMD现在近一半的销售额来自于数据中心产品,而非传统的PC芯片、游戏主机或是工业与汽车嵌…...

ThreadLocal详解及ThreadLocal源码分析
提示:ThreadLocal详解、ThreadLocal与synchronized的区别、ThreadLocal的优势、ThreadLocal的内部结构、ThreadLocalMap源码分析、ThreadLocal导致内存泄漏的原因、要避免内存泄漏可以用哪些方式、ThreadLocal怎么解决Hash冲突问题、避免共享的设计模式、ThreadLoca…...
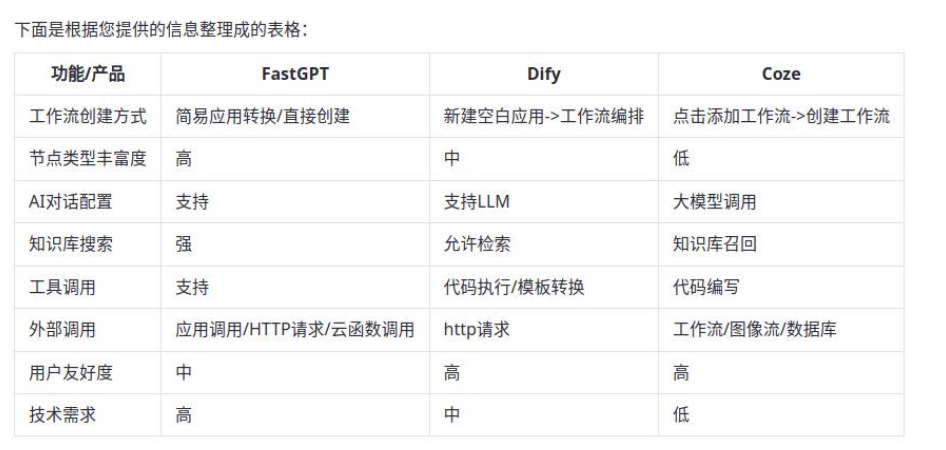
FastGPT、Dify、Coze产品功能对比分析
在当前的人工智能领域,模型接入、应用发布、应用构建、知识库和工作流编排等功能是衡量一个AI平台综合能力的重要指标。本文将对FastGPT、Dify和Coze这三款产品的功能进行详细对比分析,以帮助用户更好地了解它。 订阅模式及市场概况 在订阅模式及市场概…...

【Linux】缓冲区的理解
目录 一、实验现象二、初步认知缓冲区2.1 缓冲区的刷新策略2.2 缓冲区在哪里 三、缓冲区模拟实现四、再次全面理解缓冲区4.1 用户强制刷新缓冲区(fflush/fsync) 一、实验现象 我们先来看一个现象: 在显示器中打印内容时,fprintf先打印出来,w…...

基于单片机的电梯控制系统的设计
摘 要: 本文提出了一种基于单片机的电梯控制系统设计 。 设计以单片机为核心,通过使用和设计新型先进的硬件和控制程序来模拟和控制整个电梯的运行,在使用过程中具有成本低廉、 维护方便、 运行稳定 、 易于操作 、 安全系数高等优点 。 主要设计思路是…...

IP-GUARD文档云备份服务器迁移数据操作说明
一、功能简介 使用文档云备份过程可能出现需要迁移旧数据到新目录的情况(如一开始存储目录设置 不合理,之后变更存储目录),下面介绍迁移备份数据到新目录的方法,迁移后可正常查看、 下载、删除原备份文件。 二、同一计算机上迁移存储目录 当仅需要将存储目录迁移到同一计…...

linux常用命令ls详细说明
目录 1.ls的基本功能就是显示当前目录的文件和目录 2.ls输出是按照字母顺序排列的 3.默认不显示隐藏内容,加上参数-a可以显示隐藏的文件和文件夹 4.-R参数可以地柜列出当前目录以及它包含的字目录中的文件 5.-l参数辉显示长列表,也可以显示文件更多信…...
数据的存储)
Python3网络爬虫开发实战(4)数据的存储
文章目录 一、文本文件存储1. os 文件 mode2. TXT3. JSON4. CSV 二、数据库存储1. SQLAlchemy2. MongoDB3. Redis1) 键操作2) 字符串操作3) 列表操作4) 集合操作5) 有序集合操作6) 散列操作 4. Elasticsearch1) 检索数据:利用 elasticsearch-analysis-ik 进行分词2)…...

《C++基础入门与实战进阶》专栏介绍
🚀 前言 本文是《C基础入门与实战进阶》专栏的说明贴(点击链接,跳转到专栏主页,欢迎订阅,持续更新…)。 专栏介绍:以多年的开发实战为基础,总结并讲解一些的C/C基础与项目实战进阶内…...
- 数据清洗)
每天一个数据分析题(四百五十)- 数据清洗
数据在真正被使用前需进行必要的清洗,使脏数据变为可用数据。下列不属于“脏数据”的是() A. 重复数据 B. 错误数据 C. 交叉数据 D. 缺失数据 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据…...

基于春联生成模型的Python爬虫数据采集与内容生成系统
基于春联生成模型的Python爬虫数据采集与内容生成系统 用技术传承文化,让AI助力创作 1. 项目背景与价值 春节是中国人最重要的传统节日,而春联则是春节文化中不可或缺的一部分。每年春节,家家户户都会贴上新的春联,表达对新年的美…...

开源工具实现游戏存档编辑:虚幻引擎存档处理全指南
开源工具实现游戏存档编辑:虚幻引擎存档处理全指南 【免费下载链接】uesave 项目地址: https://gitcode.com/gh_mirrors/ue/uesave 在游戏开发与玩家体验中,虚幻引擎的存档文件往往以二进制格式存储,这给数据修改、备份与分析带来了挑…...

Excel办公必备4个技巧:格式转换、隔列插入、限制编辑、文本数字分离
在日常办公中,Excel是我们使用频率最高的软件之一,但很多人只掌握了最基础的录入和简单计算功能,遇到一些“卡脖子”的小问题就束手无策,不得不手动折腾半天。其实,Excel中隐藏着不少实用的小技巧,能帮你轻…...

BiliTools:全能B站资源管理工具,让离线学习与内容备份无忧
BiliTools:全能B站资源管理工具,让离线学习与内容备份无忧 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持视频、音乐、番剧、课程下载……持续更新 项目地址: https://gitcode.com/GitHub_Tren…...

TTL串口设计及其注意事项
一、TTL串口设计概述我们常见的处理器(单片机)引出来的串口是UART、USART,其中有没有S取决于有没有时钟信号(SLK),出来的电平是TTL电平,常见的UART串口设计有3线串口设计,单线串口设计ÿ…...
)
告别设备标识混乱!用uniappx插件Ba-IdCode-U一站式获取OAID/AndroidID/IMEI(附隐私合规指南)
跨平台开发者的设备标识管理实战:从混乱到合规的完整解决方案 每次启动新项目时,开发者们是否总在纠结该用哪种设备标识?OAID、AndroidID还是IMEI?国内厂商的兼容性问题怎么解决?隐私合规的红线又在哪里?本…...
)
GIL已死,GIL万岁?——2024大厂Python并发岗面试题库首发(含性能压测对比数据)
第一章:GIL已死,GIL万岁?——2024大厂Python并发岗面试题库首发(含性能压测对比数据)一道高频真题:为什么 asyncio.run() 启动的协程无法被 multiprocessing.Process 并发执行? 该问题直指 Pyth…...

Windows 11下用VSCode+CMake+MinGW编译OpenCV 4.8.0,保姆级避坑指南
Windows 11下用VSCodeCMakeMinGW编译OpenCV 4.8.0全流程实战 最近在Windows 11上配置OpenCV开发环境时,发现很多教程都存在版本过时或Win11特有兼容性问题。本文将分享一套经过验证的最新工具链组合:VSCode 1.85CMake 3.28MinGW-w64 12.2OpenCV 4.8.0。不…...

抖音视频批量下载神器:3分钟搞定复杂内容管理的终极方案
抖音视频批量下载神器:3分钟搞定复杂内容管理的终极方案 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 抖音作为全球最受欢迎的短视频平台,每天产生海量的精彩内容。然而,…...

CCS:Code Composer Studio 12.8.1 窗口颜色改为深色
Code Composer Studio (CCS) 基于 Eclipse 平台开发,要将其界面改为深色模式,最推荐且有效的方法是安装 Eclipse Color Theme 插件。以下是针对 CCS 12.8.1 的具体操作步骤:🛠️ 第一步:安装主题插件在 CCS 菜单栏中&a…...