CIFAR-10 数据集图像分类与可视化
数据准备
CIFAR-10 and CIFAR-100 datasets (toronto.edu)在上述网站中下载Python版本的CIFAR-10数据集。

下载后的压缩包解压后会得到几个文件如下:

对应的data_batch_1 ~ data_batch_5 是划分好的训练数据,每个文件里包含10000张图片,test_batch 是测试集数据,也包含10000张图片。他们的结构是一样的,需要分别对这些data_bach进行处理。
查阅相关文献可知,对应的data_batch都是使用的pickle库进行处理获得的。所以在处理该文件时,也需要使用pickle库进行读取。
编写一段代码脚本,将原来文件拆解成图片,并将训练集图片与测试集图片分别保存在train和test文件夹中可以得到如下图所示结果。


如上图所示,可知对应的训练集数据为5万张,测试集数据为1万张。
对应代码运行结果如下图所示

TIP:其他可选方案,其实torchvision库中的CIFAR库是可以直接加载的。使用代码torchvision.datasets.CIFAR10就可以直接调用库中的数据集。在此,直接下载完全部图片后再进行处理,会更加方便。
torchvision.datasets.CIFAR10用于加载 CIFAR-10 数据集。参数包括:
root:数据集存放的根目录。
train:True 表示加载训练集,False 表示加载测试集。
download:是否下载数据集,如果设置为 True,数据集将会被自动下载到 root 目录下。
transform:用于对数据进行转换的操作。
对上述数据集中数据进行归一化、图像增强等操作。
import torchvision.transforms as transforms# 定义图像预处理操作
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4), # 随机裁剪,数据增强transforms.RandomHorizontalFlip(), # 随机水平翻转,数据增强transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化
])使用随机裁剪、水平翻转技术进行数据增强操作,提高后续模型的特征提取能力。
模型构建
使用 PyTorch 构建卷积神经网络模型。设计合适的网络结构,包括卷积层、池化层、全连接层等。搭建的卷积神经网络结构图如下所示
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear, Flattenclass Module(nn.Module):def __init__(self):super(Module, self).__init__()self.model1 = Sequential( # 效果同上Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xif __name__ == '__main__':# 验证网络正确性model = Module()input = torch.ones((64, 3, 32, 32))output = model(input)print(output.shape) # torch.Size([64, 10])该卷积神经网络包含了一个卷积层 (Conv2d),输入通道数为3,输出通道数为32,卷积核大小为5x5,使用零填充(padding=2)。一个最大池化层 (MaxPool2d),池化窗口大小为2x2。另一个卷积层,输入通道数为32,输出通道数为32,卷积核大小为5x5,同样使用零填充。另一个最大池化层,池化窗口大小为2x2。还有一个卷积层,输入通道数为32,输出通道数为64,卷积核大小为5x5,零填充。再接一个最大池化层,池化窗口大小为2x2。
然后是将特征展平的层 (Flatten),用于将卷积层输出的特征张量展平成一维向量。
接着是一个全连接层 (Linear),输入大小为1024,输出大小为64。
最后是另一个全连接层,输入大小为64,输出大小为10。这里的10代表着输出类别的数量。
后面函数解释:
def forward(self, x)是模型的前向传播函数,定义了数据从输入到输出的流程。
x = self.model1(x):这里将输入数据 x 输入到 model1 中,进行前向传播计算。
return x:返回模型的输出结果。
if __name__ == '__main__'::这是Python中的常用写法,用于判断当前脚本是否作为主程序执行。
model = Module():创建了一个模型对象 model,实例化了前面定义的 Module 类。
input = torch.ones((64, 3, 32, 32)):创建了一个大小为64x3x32x32的张量作为输入数据,表示64个样本,每个样本的图像大小为32x32,通道数为3(假设是RGB图像)。
output = model(input):将输入数据输入到模型中进行前向传播计算,得到输出结果。
print(output.shape):打印输出结果的形状,这里输出的形状为 torch.Size([64, 10]),表示有64个样本,每个样本对应一个长度为10的输出向量,其中每个元素表示对应类别的预测分数或概率。
对应构建的卷积神经网络结构图如下图所示:

模型训练
定义损失函数和优化器。将数据集分为训练集和验证集。在训练集上训练模型,通过验证集调整模型参数,避免过拟合。
# 6损失函数
loss_fn = nn.CrossEntropyLoss()# 7优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 8设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练的轮数损失函数、优化器如上所示,损失函数使用交叉熵损失函数,优化器中学习率learning rate为0.01,优化器使用SGD优化器。
模型评估
使用测试集评估模型性能,计算准确率等指标。

随着训练次数增加,模型在测试集上面的整体损失LOSS一直在下降,正确率一直在提升。训练准确率在第34轮训练时到达66.7%
可视化展示
通过表格展示准确率等实验结果。绘制准确率和损失函数随训练轮次变化的曲线图。随机选取部分图像,展示模型的预测结果和真实标签。
此处的可视化使用了tensorboard展示板结合日志文件进行展示
tensorboard --logdir=logslogs代表着日志文件对应的文件夹所在位置
使用上面代码进行读取代码运行产生的日志文件。

TIP:日志文件所在的文件夹路径中不能存在中文路径,否则会报错。





import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
import matplotlib.pyplot as plt
import numpy as np# 加载测试数据集
test_data = CIFAR10(root="data", train=False, transform=transforms.ToTensor(), download=True)
test_loader = DataLoader(test_data, batch_size=16, shuffle=True)# 定义类别名称
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']# 加载模型
model = torch.load(r"C:\Users\Lenovo\Desktop\计算机视觉实验\实验2\CIFAR-10\200轮训练权重\model_34.pth") # 假设模型保存在 model.pth 中# 设置模型为评估模式
model.eval()# 从测试数据集中随机选择一批图像和标签
images, labels = next(iter(test_loader))# 对图像进行预测
with torch.no_grad():outputs = model(images)_, predicted = torch.max(outputs, 1)# 将图像、预测结果和真实标签组合在一起并展示
fig, axes = plt.subplots(4, 4, figsize=(12, 12))
for i, ax in enumerate(axes.flat):image = images[i].permute(1, 2, 0) # 将图像从 (C, H, W) 转换为 (H, W, C)label = labels[i]prediction = predicted[i]ax.imshow(image)ax.axis('off')ax.set_title(f'Predicted: {classes[prediction]}, Actual: {classes[label]}',fontsize=10)plt.show()
识别效果如上图所示.
相关文章:
CIFAR-10 数据集图像分类与可视化
数据准备 CIFAR-10 and CIFAR-100 datasets (toronto.edu)在上述网站中下载Python版本的CIFAR-10数据集。 下载后的压缩包解压后会得到几个文件如下: 对应的data_batch_1 ~ data_batch_5 是划分好的训练数据,每个文件里包含10000张图片,test…...

没有了高项!!2024软考下半年软考高级哪个最容易考过?
距离2024上半年软考考试结束已经有一段时间了,有不少小伙伴都在开始准备下半年软考了,值得注意的是:近日各省陆续公布了2024上半年软考合格名单。那么,软考高级通过率到底如何?先来看看吧! 一、上半年软考通…...
)
用户自定义Table API Connector(Sources Sinks)
目录 概述 Metadata Planning Runtime 扩展点 动态表工厂(Dynamic Table Factories) 动态表(Dynamic Table) 动态表源(Dynamic Table Source) 扫描表源(Scan Table Source) 查找表源(Lookup Table Source) 动态表接收器(Dynamic Table Sink) 编码/解码…...

自闭症儿童能否摘帽?摘帽成功的秘诀揭秘
自闭症,这一曾经被视为不可逆转的障碍,如今在科学的进步与社会的关注下,正逐步展现出被“摘帽”的可能性。那么,自闭症儿童真的能完全摆脱这一标签,实现真正的“摘帽”吗?答案是肯定的,关键在于…...
主题巴巴WordPress主题合辑打包下载+主题巴巴SEO插件
主题巴巴WordPress主题合辑打包下载,包含博客一号、博客二号、博客X、门户一号、门户手机版、图片一号、杂志一号、自媒体一号、自媒体二号和主题巴巴SEO插件。...

git把本地文件上传远程仓库的流程
下载git,并创建一个仓库,这里着重介绍怎么把本地文件上传参考 正确执行步骤:在你需要上传的文件夹空白处下,右键鼠标,点击git bash here $ git init初始化当前目录 $ git status看一下当前分支里面有什么,…...

基于springboot+vue+uniapp的养老院管理系统小程序
开发语言:Java框架:springbootuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包&#…...

el-popover实现点击空白区域关闭,弹窗区域不关闭
难点: 普通方法会无法关闭,虚拟触发会导致选一个关一个,不用visible显示的方法太麻烦。 所以结合其他人的方法,使用手动监听判断的方法(点击蓝色区域看参考,这大佬vue2的,我vue3) 注…...

Disjoint Set Union
Problem One : 维护区间连通块 F - Range Connect MST (atcoder.jp) 暴力模拟的话,就是基于 Kruskal 的思想,按 c c c 从小到大排序,对于每次询问,枚举检查 j ∈ [ l , r ] j\in [l,r] j∈[l,r] ,只要 j j j 与 …...

手写 Hibernate ORM 框架 05-基本效果测试
手写 Hibernate 系列 手写 Hibernate ORM 框架 00-hibernate 简介 手写 Hibernate ORM 框架 00-环境准备 手写 Hibernate ORM 框架 01-注解常量定义 手写 Hibernate ORM 框架 02-实体 Bean 定义,建表语句自动生成 手写 Hibernate ORM 框架 03-配置文件读取, 数…...

Unity材质球自动遍历所需贴图
Unity材质球自动遍历所需贴图 文章目录 Unity材质球自动遍历所需贴图一、原理二、用法1.代码:2.使用方法 一、原理 例如一个材质球名为:Decal_Text_Cranes_01_Mat , 然后从全局遍历出:Decal_Text_Cranes_01_Albedo赋值给材质球的…...

C++那些事之结构化绑定
C那些事之结构化绑定 在聊结构化绑定之前,有几个面试问题,看看你会不会? 如何使用结构化绑定访问自定义类的私有成员?如何使用结构化绑定修改自定义类的成员呢? 这几个题目估计没几个人能答上来,题目与答案…...

ECRS工时分析软件:工业工程精益生产的智慧引擎
在工业工程学的广阔领域中,程序分析一直扮演着至关重要的角色。其中,ECRS四大原则——取消、合并、重排、简化,作为程序分析的核心,旨在通过优化生产过程,实现成本的节省和精益生产的目标。如今,随着科技的…...

大语言模型的核心岗位及其要求
一、核心岗位 研究科学家(Research Scientist): 负责制定研究计划,探索新算法和模型架构。数据科学家(Data Scientist): 进行数据收集、分析和预处理。机器学习工程师(Machine Lear…...

【屏驱MCU】RT-Thread 文件系统接口解析
本文主要介绍【屏驱MCU】基于RT-Thread 系统的文件系统原理介绍与代码接口梳理 目录 0. 个人简介 && 授权须知1. 文件系统架构1.1 虚拟文件系统目录架构 2. menuconfig 分析3. 代码接口分析3.1 DFS框架挂载目录3.2 【FAL抽象层】分区表和设备表3.3 如何将【文件路径】挂…...

进程管理工具top ps
概述 top 和 ps 是 Linux 系统中两个非常重要的用于管理和监控进程的命令工具。以下是它们的主要功能和区别: 1. 动静 2. 整体 & 详细 top: 动态视图:top 提供了一个实时动态更新的视图,能够持续显示系统中当前正在运行的进程…...

2年社招冲击字节,一天三面斩获offer
在工作满两年的时间选择了求变,带着运气和实力以社招身份重新看今天的互联网环境,从结果看还是复合预期的。 整个面试的流程还挺快的。周中让招聘专员给投递了简历。问什么时候面试,申请了一个周日,直接安排三面。下周周中就开启…...

oppo,埃科光电25届秋招,快手25届技术人才专项计划等几千家企业岗位内推
oppo,埃科光电25届秋招,快手25届技术人才专项计划等几千家企业岗位内推 ①【OPPO】25届秋招开启! 内推简历优先筛选! 【岗位类别】AI/算法类,软件类,硬件类,工程技术类,品牌策划类&a…...
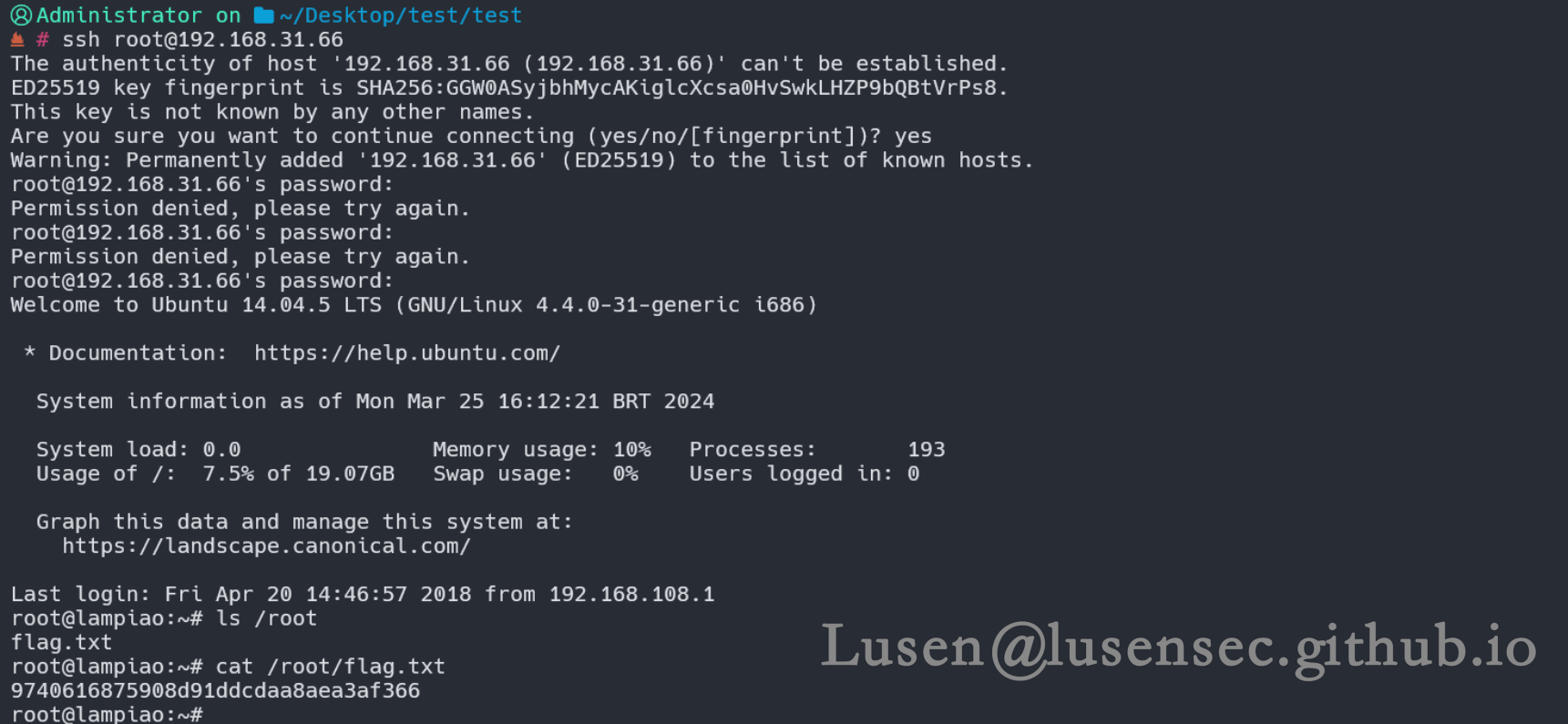
【Vulnhub系列】Vulnhub Lampiao-1 靶场渗透(原创)
【Vulnhub系列靶场】Vulnhub Lampiao-1靶场渗透 原文转载已经过授权 原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io) 一、主机发现 二、端口扫描 三、web框架 四、web渗透 1、信息收集 2、目录扫描 获得版本信息7.56 3、获取shell …...

MySQL:ORDER BY 排序查询
通过 ORDER BY 条件查询语句可以查询到符合用户需求的数据,但是查询到的数据一般都是按照数据最初被添加到表中的顺序来显示。 基本语法 在MySQL中,排序查询主要通过ORDER BY子句实现。其基本语法如下: SELECT column1, column2, ... FR…...

人脸模糊实战指南:YOLOv8+SAM三重模糊工业级方案
1. 项目概述:为什么一张脸的模糊处理,比你想象中更难也更重要我做图像隐私处理相关项目快八年了,从最早用Photoshop手动框选、拖拽高斯模糊图层,到后来写脚本调OpenCV的Haar级联检测器,再到如今用YOLOv8SAM组合做像素级…...

基于OpenClaw的GitHub趋势智能监控器:自动化追踪与AI摘要推送
1. 项目概述:一个为开发者打造的GitHub趋势智能监控器 作为一名长期泡在GitHub上的开发者,我深知每天手动刷“Trending”页面有多低效。热门项目层出不穷,但真正值得关注的往往就那么几个,而且很容易被淹没在信息流里。直到我遇到…...

Cursor插件实现网页数据AI就绪:从智能抓取到实时搜索的完整方案
1. 项目概述:将任意网页转化为AI就绪数据的Cursor插件 如果你经常用Cursor写代码、做研究,或者处理网络数据,那你肯定遇到过这样的场景:看到一个网页,想把里面的内容扒下来,整理成结构化的Markdown或者JSO…...

HiveWE:基于C++20模块化架构的下一代魔兽争霸III地图创作引擎
HiveWE:基于C20模块化架构的下一代魔兽争霸III地图创作引擎 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE HiveWE作为开源社区驱动的魔兽争霸III地图编辑器,通过现代C20模块化架构重…...

如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南
如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预…...

APK Installer终极指南:如何在Windows上快速安装安卓应用?
APK Installer终极指南:如何在Windows上快速安装安卓应用? 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows上安装安卓应用而烦恼吗…...

PEX8796实战解析:从芯片特性到PCIe扩展设计的关键考量
1. PEX8796芯片基础认知与核心特性 第一次拿到PEX8796这颗PCIe交换芯片时,我盯着密密麻麻的引脚图发了半小时呆。作为PLX(现已被博通收购)的经典产品,这颗芯片在工业控制、服务器扩展等领域已经默默服役了十余年。实测中发现&…...

青年教师评副高‘捷径’:这6本被低估的SSCI,认可度不输顶刊!
01 Academic Medicine期刊分区影响因子自引率年文章数教育学1区5.211.5%252篇投稿参考:美国医学院协会(AAMC)官方期刊,审稿周期 2–3 个月,录用率≈20%;可选非 OA 模式免版面费,适合具有实践转…...
实战分配指南(MDK/IAR双环境))
告别内存焦虑!STM32H743全系列SRAM(ITCM/DTCM/AXI)实战分配指南(MDK/IAR双环境)
STM32H743内存优化实战:从理论到精准分配的完整指南 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。STM32H743作为STMicroelectronics推出的高性能微控制器系列,其复杂的内存架构既带来了性能优势,也增加了开发难…...

从原型到优化:基于LoRa SX1278与STM32的音频对讲系统实战剖析
1. 项目背景与原型机搭建 记得第一次用STM32F103C8T6驱动LoRa SX1278模块时,手边只有个简易麦克风模块和杜邦线。当时就想做个能传语音的无线对讲系统,没想到后来踩了这么多坑。这个项目最核心的三部分就是ADC采集声音、SPEEX压缩音频、LoRa传输数据&am…...