大数据|使用Apache Spark 删除指定表中的指定分区数据
文章目录
- 概述
- 方法 1: 使用 Spark SQL 语句
- 方法 2: 使用 DataFrame API
- 方法 3: 使用 Hadoop 文件系统 API
- 方法 4: 使用 Delta Lake
- 使用注意事项
- 常见相关问题及处理
- 结论
概述
Apache Spark 是一个强大的分布式数据处理引擎,支持多种数据处理模式。在处理大型数据集时,经常需要对数据进行分区,以提高处理效率。有时,为了维护数据或优化查询性能,需要删除指定表中的指定分区数据。本文档将介绍如何使用 Spark SQL 和 DataFrame API 来删除指定表中的指定分区数据,并提供使用时的注意事项以及常见相关问题及其处理方法。
方法 1: 使用 Spark SQL 语句
描述:
通过 Spark SQL 的 ALTER TABLE 语句来删除指定的分区数据。
示例:
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("DeletePartitionData").getOrCreate()// 删除 partition 为 'partition_col = 'value''
spark.sql(s"ALTER TABLE myTable DROP IF EXISTS PARTITION (partition_col='value')")
注意事项:
- 此命令只从元数据中删除分区,不会自动删除底层存储系统中的文件。
- 确保在执行此操作前,您已经备份了相关数据。
方法 2: 使用 DataFrame API
描述:
使用 DataFrame API 过滤掉不需要的数据,并将过滤后的结果重写到原表中。
示例:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.Datasetval spark = SparkSession.builder().appName("DeletePartitionData").getOrCreate()// 加载表
val df: Dataset[Row] = spark.table("myTable")// 过滤掉不需要的分区
val filteredDf = df.filter($"partition_col" !== "value")// 重写表
filteredDf.write.mode("overwrite").insertInto("myTable")
注意事项:
- 使用 DataFrame API 重写表可能会导致大量的 I/O 操作,因此如果表很大,这可能不是最有效的方法。
- 在使用 DataFrame API 时,请确保有足够的资源来处理可能的重写操作。
方法 3: 使用 Hadoop 文件系统 API
描述:
直接访问底层存储系统(如 HDFS),使用 Hadoop 文件系统 API 来删除指定分区的文件。
示例:
import org.apache.hadoop.fs.{FileSystem, Path}val spark = SparkSession.builder().appName("DeletePartitionData").getOrCreate()// 获取文件系统的实例
val fs = FileSystem.get(spark.sparkContext.hadoopConfiguration)// 分区路径
val partitionPath = new Path("/path/to/your/partition/value")// 删除分区
fs.delete(partitionPath, true) // 第二个参数表示是否递归删除目录
注意事项:
- 确保您有足够的权限来删除 HDFS 中的文件。
- 在删除分区之前,请确保备份了相关的数据。
方法 4: 使用 Delta Lake
描述:
Delta Lake 是一个开源的存储层,可以提供 ACID 事务性操作、统一的事务日志、schema 演进等功能。使用 Delta Lake,可以直接删除指定分区的数据。
示例:
import org.apache.spark.sql.DeltaConfig
import org.apache.spark.sql.delta.DeltaTableval spark = SparkSession.builder().appName("DeletePartitionData").config(DeltaConfig.enableDeltaLogging()).getOrCreate()// 加载 Delta 表
val deltaTable = DeltaTable.forPath(spark, "/path/to/delta/table")// 删除指定分区的数据
deltaTable.delete($"partition_col" === "value")
注意事项:
- 对于支持 ACID 事务的表,推荐使用 Delta Lake 或其他支持事务的存储层来进行数据操作。
使用注意事项
- 性能问题:
- 使用 DataFrame API 重写表可能会导致大量的 I/O 操作,因此如果表很大,这可能不是最有效的方法。
- 在使用 DataFrame API 时,请确保有足够的资源来处理可能的重写操作。
- ACID 事务:
- 如果您的表支持 ACID 事务(例如使用 Hive 或 Delta Lake),那么可以使用更安全的方式来处理删除操作。
- 对于支持 ACID 事务的表,推荐使用 Delta Lake 或其他支持事务的存储层来进行数据操作。
- 备份数据:
- 在执行任何删除操作之前,请确保已经备份了相关数据。
- 对于重要的数据操作,建议先创建备份副本,以免发生意外情况。
- Schema 兼容性:
- 确保在删除分区数据前后表的 schema 保持一致。
- 权限管理:
- 确保具有足够的权限来执行文件系统的操作或数据库的操作。
- 测试:
- 在生产环境中执行删除操作前,在测试环境中验证逻辑的正确性。
- 日志记录:
- 记录所有的删除操作以便于审计和回溯。
常见相关问题及处理
问题: 执行删除分区后,重新插入数据失败,提示 target directory already exists。
原因: 即使您使用了 ALTER TABLE ... DROP IF EXISTS PARTITION 命令,Spark SQL 本身并不会删除底层存储系统中的实际文件。
处理方法:
- 使用 Hadoop 文件系统 API 或者 Hadoop 命令手动删除底层存储系统中的分区目录。
- 重新插入数据前,确认底层存储系统中的分区目录已被删除。
示例代码:
import org.apache.hadoop.fs.{FileSystem, Path}val spark = SparkSession.builder().getOrCreate()// 获取文件系统的实例
val fs = FileSystem.get(spark.sparkContext.hadoopConfiguration)// 分区路径
val partitionPath = new Path("/path/to/your/partition/value")// 删除分区
fs.delete(partitionPath, true) // 第二个参数表示是否递归删除目录// 重新插入数据
val newData = Seq((1, "data1", "value"), (2, "data2", "value")).toDF("id", "data", "partition_col")
newData.write.mode("append").partitionBy("partition_col").format("parquet").saveAsTable("myTable")
结论
通过以上方法和技术,您可以有效地删除 Apache Spark 中指定表的指定分区数据。根据您的具体需求和环境,选择最适合的方式进行操作。同时,请注意遵守上述注意事项,以避免潜在的问题。
相关文章:

大数据|使用Apache Spark 删除指定表中的指定分区数据
文章目录 概述方法 1: 使用 Spark SQL 语句方法 2: 使用 DataFrame API方法 3: 使用 Hadoop 文件系统 API方法 4: 使用 Delta Lake使用注意事项常见相关问题及处理结论 概述 Apache Spark 是一个强大的分布式数据处理引擎,支持多种数据处理模式。在处理大型数据集时…...

OSPF动态路由协议实验
首先地址划分 一个骨干网段分成三个,r1,r2,r5三个环回网段 ,总共要四个网段 192.168.1.0/24 192.168.1.0/26---骨干网段 192.168.1.0/28 192.168.1.16/28 192.168.1.32/28 备用 192.168.1.64/28 192.168.1.64/26---r1环回 192.1…...
的理解)
tcp中accept()的理解
源码 参数理解 NAMEaccept, accept4 - accept a connection on a socketSYNOPSIS#include <sys/types.h> /* See NOTES */#include <sys/socket.h>int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);#define _GNU_SOURCE …...
让我们逐行重现 GPT-2:第 1 部分
欢迎来到雲闪世界。Andrej Karpathy 是人工智能 (AI) 领域的顶尖研究人员之一。他是 OpenAI 的创始成员之一,曾领导特斯拉的 AI 部门,目前仍处于 AI 社区的前沿。 在第一部分中,我们重点介绍如何实现 GPT-2 的架构。虽然 GPT-2 于 2018 年由 …...

第十九天内容
上午 1、构建vue发行版本 2、java环境配置 jdk软件包路径: https://download.oracle.com/java/22/latest/jdk-22_linux-x64_bin.tar.gz 下午 1、安装tomcat软件 tomcat软件包路径: https://dlcdn.apache.org/tomcat/tomcat-10/v10.1.26/bin/apache-to…...
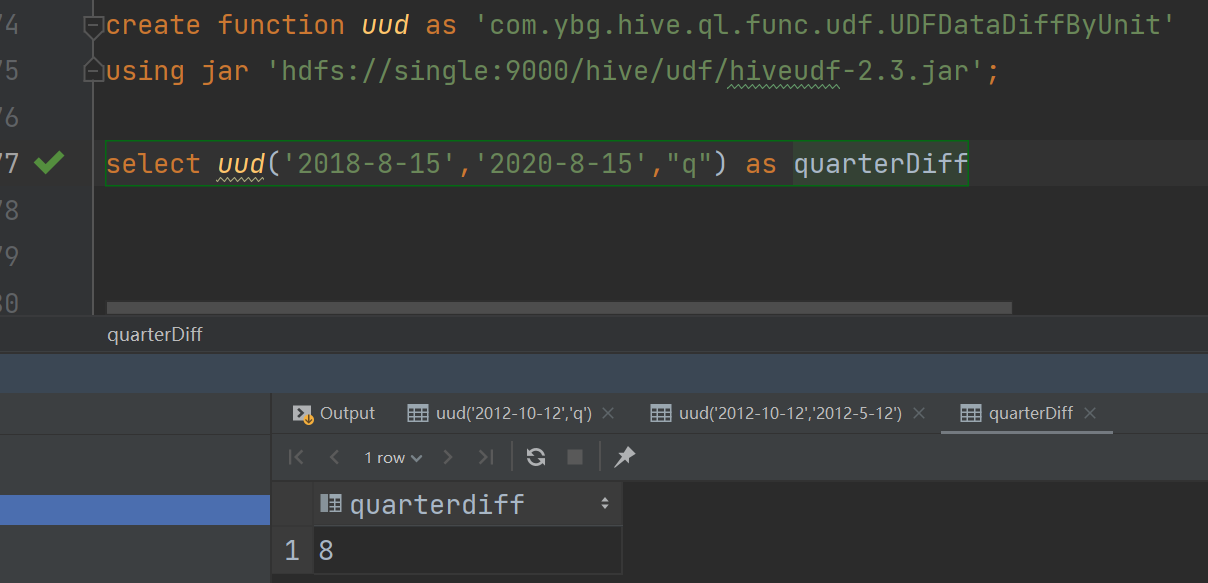
Hive之扩展函数(UDF)
Hive之扩展函数(UDF) 1、概念讲解 当所提供的函数无法解决遇到的问题时,我们通常会进行自定义函数,即:扩展函数。Hive的扩展函数可分为三种:UDF,UDTF,UDAF。 UDF:一进一出 UDTF:一进多出 UDAF:…...

jdk1.8中HashMap为什么不直接用红黑树
最开始使用链表的时候,空间占用比较少,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。 参考资料: https://blog.51cto.com/u_13294304/3075723...

消息推送只会用websocket、轮询?试试SSE,轻松高效。
SSE介绍 HTTP Server-Sent Events (SSE) 是一种基于 HTTP 的服务器推送技术,它允许服务器向客户端推送数据,而无需客户端发起请求。以下是 HTTP SSE 的主要特点: 单向通信: SSE 是一种单向通信协议,服务器可以主动向客户端推送数据,而客户端只能被动接收数据。 持久连接: SS…...

Spring-Retry 框架实战经典重试场景
Spring-Retry框架是Spring自带的功能,具备间隔重试、包含异常、排除异常、控制重试频率等特点,是项目开发中很实用的一种框架。 1、引入依赖 坑点:需要引入AOP,否则会抛异常。 xml <!-- Spring-Retry --> <dependency&…...

人工智能在医疗领域的应用与挑战
随着人工智能技术的不断发展,其在医疗领域的应用也越来越广泛。从辅助诊断到治疗决策,人工智能正在逐步改变着传统的医疗模式。然而,人工智能在医疗领域的应用也面临着诸多挑战,如数据隐私、伦理道德等问题。本文将探讨人工智能在…...
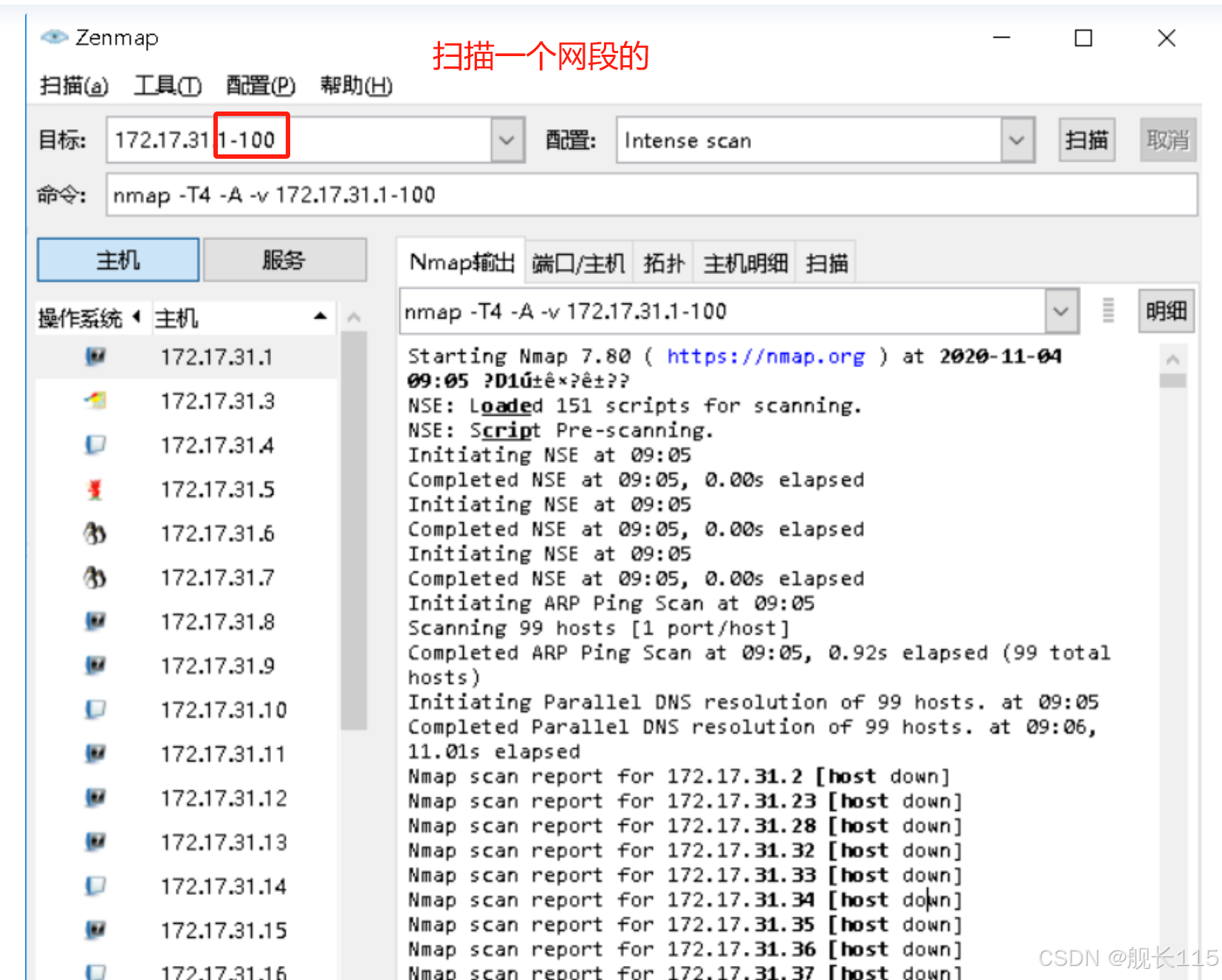
Windows下nmap命令及Zenmap工具的使用方法
一、Nmap简介 nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。确定哪些服务运行在哪些连接端,并且推断计算机运行哪个操作系统(这是亦称 fingerprinting)。它是网络管理员必用的软件之一,以及用以评…...

深入了解-什么是CUDA编程模型
CUDA(Compute Unified Device Architecture,统一计算架构)是NVIDIA推出的一种面向GPU的并行计算平台和编程模型。它允许开发者利用NVIDIA的GPU进行通用目的的并行计算,从而加速应用程序的运行速度。CUDA编程模型为开发者提供了强大…...

111111111111111111
11111111111111111111...

环境如何搭建部署Nacos
这里我使用的是Centos7, Nacos 依赖 Java环境来运行。如果您是从代码开始构建并运行Nacos,还需要为此配置 Maven环境,请确保是在以下版本环境中安装使用 ## 1、下载安装JDK wget https://download.oracle.com/java/17/latest/jdk-17_linux-x6…...

什么是 5G?
什么是 5G? 5G 是第五代无线蜂窝技术,与以前的网络相比,它提供了更高的上传和下载速度、更一致的连接以及更高的容量。5G 比目前流行的 4G 网络更快、更可靠,并有可能改变我们使用互联网访问应用程序、社交网络和信息的方式。例如…...

优化冗余代码:提升前端项目开发效率的实用方法
目录 前言代码复用与组件化模块化开发与代码分割工具辅助与自动化结束语 前言 在前端开发中,我们常常会遇到代码冗余的问题,这不仅增加了代码量,还影响了项目的可维护性和开发效率。还有就是有时候会接到紧急业务需求,要求立马完…...

SpringCloud Alibaba 微服务(四):Sentinel
目录 前言 一、什么是Sentinel? Sentinel 的主要特性 Sentinel 的开源生态 二、Sentinel的核心功能 三、Sentinel 的主要优势与特性 1、丰富的流控规则 2、完善的熔断降级机制 3、实时监控和控制台 4、多数据源支持 5、扩展性强 四、Sentinel 与 Hystrix …...
)
Python 3.12新功能(1)
Python 3.12正式发布已经很久了,我才将主要电脑的Python版本从3.11升级到最新。最近刚好工作没有那么紧张了,就来领略下这个最新版本中的新特性。 改善了错误消息 Python作为一门编程语言,简单易学容易上手,童叟无欺,深…...

c++STL容器中vector的使用,模拟实现及迭代器使用注意事项和迭代器失效问题
目录 前言: 1.vector的介绍及使用 1.2 vector的使用 1.2 1 vector的定义 1.2 2 vector iterator(迭代器)的使用 1.2.3 vector 空间增长问题 1.2.4 vector 增删查改 1.2.5vector 迭代器失效问题。 2.vector模拟实现 2.1 std::vect…...

Android笔试面试题AI答之Activity常见考点
Activity的常见考点可以总结如下: 生命周期管理:理解Activity在不同情况下(如屏幕旋转、配置更改、用户操作等)的生命周期变化,包括但不限于onCreate、onStart、onResume、onPause、onStop和onDestroy等回调方法。 启…...

为Cursor AI Agent构建专用HTTP客户端:扩展智能体联网能力实战
1. 项目概述:一个为Cursor AI Agent定制的HTTP客户端 如果你和我一样,深度使用Cursor作为日常开发的主力工具,那你肯定对它的“Agent”功能又爱又恨。爱的是,它能理解你的意图,帮你生成代码、重构函数、甚至写测试&…...

Vcpkg不只是个安装器:在Windows上用它为你的C++项目打造可复现的构建环境
Vcpkg工程化实践:构建可复现的C开发环境 在大型C项目中,依赖管理一直是开发者面临的痛点之一。不同团队成员使用不同版本的第三方库,CI服务器上的构建环境与本地开发环境不一致,这些问题常常导致"在我机器上能运行"的尴…...

ARM AMBA总线演进史:从AHB到AXI,再到CHI和ACE,我们经历了什么?
ARM AMBA总线演进史:从AHB到AXI,再到CHI和ACE的技术脉络解析 二十年前,当ARM首次提出AMBA总线架构时,恐怕很少有人能预见它会在今天的SoC设计中占据如此核心的地位。从最初的AHB到如今的CHI,AMBA总线的每一次迭代都精准…...

117.YOLOv5/v8数学原理+CSPDarknet架构,CUDA117环境一键部署
摘要 YOLO(You Only Look Once)系列算法是目标检测领域最主流的实时检测框架,其核心思想是将目标检测任务转化为一个端到端的回归问题。 本文从数学原理出发,系统阐述YOLOv5/v8的架构演进与核心机制,并提供一个从数据准备、模型训练到ONNX部署的完整可运行案例。 文章所有…...
)
告别语法冲突!用SLR分析法搞定编译原理中的移进/归约难题(附FOLLOW集实战)
告别语法冲突!用SLR分析法搞定编译原理中的移进/归约难题(附FOLLOW集实战) 当你第一次尝试构建LR(0)分析表时,是否遇到过这样的报错:"状态I2存在移进/归约冲突"?这种既想移进又想归约的矛盾&…...

ARM-MPU实战:从寄存器配置到内存安全防护
1. ARM-MPU基础概念与核心价值 第一次接触ARM-MPU时,我盯着开发板反复确认了三遍接线——明明程序逻辑完全正确,却总是莫名其妙进入HardFault中断。后来才发现是某个野指针改写了关键数据区,这种隐蔽的错误让我意识到内存保护的重要性。ARM-M…...

ComfyUI图像修复终极指南:5个高效技巧解决安装与使用难题
ComfyUI图像修复终极指南:5个高效技巧解决安装与使用难题 【免费下载链接】comfyui-inpaint-nodes Nodes for better inpainting with ComfyUI: Fooocus inpaint model for SDXL, LaMa, MAT, and various other tools for pre-filling inpaint & outpaint areas…...

终极指南:如何快速解决Windows应用程序运行库缺失问题
终极指南:如何快速解决Windows应用程序运行库缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的情况:下载了…...

新手父母必备:开源婴儿护理知识库架构与核心技能解析
1. 项目概述:一个为新手父母量身定制的技能宝库如果你是一位即将迎来新生命,或者刚刚升级为父母的朋友,面对那个软软糯糯的小家伙,除了满心的喜悦,是不是也时常感到一丝手足无措?喂奶、拍嗝、哄睡、洗澡、抚…...
)
从.axf到.bin:ARM Compiler 6.14链接与格式转换的隐藏细节(Keil MDK实战)
从.axf到.bin:ARM Compiler 6.14链接与格式转换的隐藏细节(Keil MDK实战) 当你在Keil MDK中点击"Build"按钮时,背后发生的远不止简单的代码翻译。对于使用STM32的嵌入式工程师而言,理解从源代码到最终烧录文…...