大数据核心概念与技术架构简介
大数据基本概念
大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。

大数据特征:
·数据量大:一般以P(1000个TB)、E(100万个TB)或Z(10亿个TB)为计量单位
·数据类型繁多:包括结构化、半结构化和非结构化的数据,数据来源多样,文本、日志、视频、图片、地理位置等;
·价值密度低:大数据所具备的巨大体量,使其所包含信息较少。因此需要利用通过数据分析与机器学习更快速的挖掘出有价值的数据,带来更多的商业价值。
·速度快:数据增长速度快、并要求处理速度快、对时效性要求也高,海量数据的处理需求不再局限在离线计算当中。
·真实性:数据的真实性和可信赖度差异较大,因此数据分析的精确度也有所不同。
大数据平台本质上就是对海量数据从采集、存储、计算、应用、管理、运维的多方位、多维度的组合研究设计,从而建设合理、高效的大数据平台架构。
开局一张图:
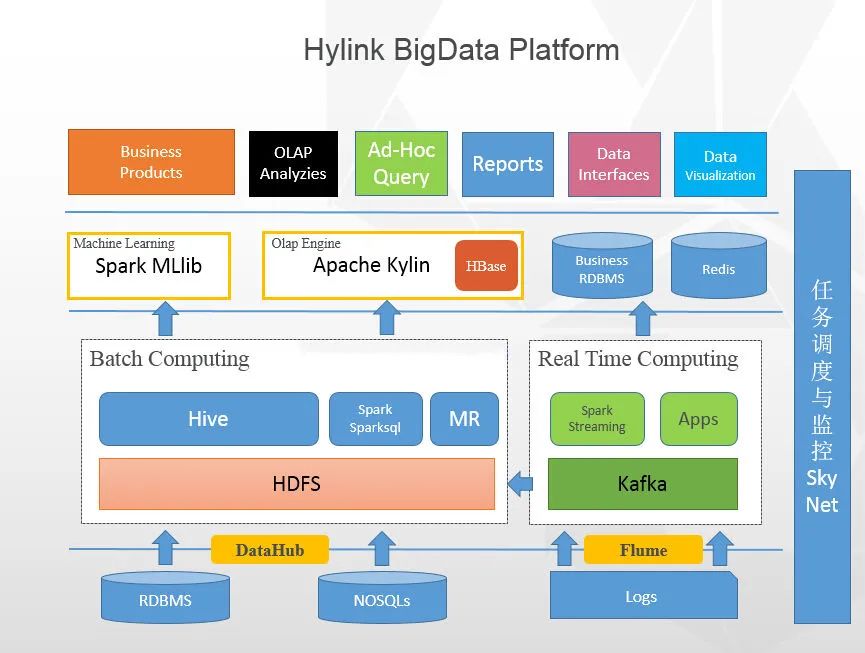
这是某公司使用的大数据平台架构图,大部分公司应该都差不多。
从这张大数据的整体架构图上看来,大数据的核心层应该是:数据采集层、数据存储与分析层、数据共享层、数据应用层,可能叫法有所不同,本质上的角色都大同小异。
所以下面就按这张架构图上的线索,慢慢来剖析一下,大数据的核心技术都包括什么。
大数据采集
数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些简单的清洗,清除不合理和错误的数据,对重要的信息进行修复,保证数据的完整性。数据源的种类比较多:
1、网站日志
作为互联网行业,网站日志占的份额最大,网站日志存储在多台网站日志服务器上,一般是在每台网站日志服务器上部署flume agent,实时的收集网站日志并存储到HDFS上。
2、业务数据库
业务数据库的种类也是多种多样,有Mysql、Oracle、SqlServer等,这时候,我们迫切的需要一种能从各种数据库中将数据同步到HDFS上的工具,Sqoop是一种,但是Sqoop太过繁重,而且不管数据量大小,都需要启动MapReduce来执行,而且需要Hadoop集群的每台机器都能访问业务数据库;应对此场景,淘宝开源的DataX,是一个很好的解决方案,有资源的话,可以基于DataX之上做二次开发,就能非常好的解决。

当然,Flume通过配置与开发,也可以实时的从数据库中同步数据到HDFS。
3、来自于Ftp/Http的数据源
有可能一些合作伙伴提供的数据,需要通过Ftp/Http等定时获取,DataX也可以满足该需求。
4、其他数据源
比如一些手工录入的数据,需要提供一个接口或小程序,即可完成。
大数据存储与分析
目前,HDFS是大数据环境下数据仓库/数据平台最完美的数据存储解决方案。离线数据分析与计算,也就是对实时性要求不高的部分,Hive是最优选择。
- 具有丰富的数据类型、内置函数;
- 压缩比非常高的ORC文件存储格式;
- 非常方便的SQL支持。
以上的优点使得Hive在基于结构化数据上的统计分析远远比MapReduce要高效的多,一句SQL可以完成的需求,开发MapReduce可能需要上百行代码;
当然,使用Hadoop框架自然而然也提供了MapReduce接口,如果乐意开发Java,或者对SQL不熟,那么也可以使用MapReduce来做分析与计算;
Spark是这两年非常火的,经过实践,其性能的确比MapReduce要好很多,而且和Hive、Yarn结合的越来越好,因此,支持使用Spark和SparkSQL来做分析和计算。
大数据管理技术
大数据共享
这里的数据共享,其实指的是前面数据分析与计算后的结果存放的地方,其实就是关系型数据库和NOSQL数据库;前面使用Hive、MR、Spark、SparkSQL分析和计算的结果,存储在HDFS上,但大多业务和应用不可能直接从HDFS上获取数据,因此,需要一个数据共享的地方,使得各业务和产品能方便的获取数据。
和数据采集层到HDFS刚好相反,需要一个从HDFS将数据同步至其他目标数据源的工具,DataX刚好可以满足,另外,一些实时计算的结果数据也可以直接写入数据共享。
实时数据计算
现在业务对数据仓库实时性的需求越来越高,比如:实时的了解网站的整体流量;实时的获取一个广告的曝光和点击等场景。在海量数据下,依靠传统数据库和传统实现方法基本完成不了,需要的是一种分布式的、高吞吐量的、延时低的、高可靠的实时计算框架,Storm在这块是比较成熟了,其次是Spark Streaming,相比Storm延时性高一点。
Spark Streaming使用时,一般由Flume在前端日志服务器上收集网站日志和广告日志,实时的发送给Spark Streaming,由Spark Streaming完成统计,将数据存储至Redis,业务通过访问Redis实时获取。
任务调度与监控
在数据仓库/数据平台中,有各种各样非常多的程序和任务,比如:数据采集任务、数据同步任务、数据分析任务等。这些任务除了定时调度,还存在非常复杂的任务依赖关系,比如:数据分析任务必须等相应的数据采集任务完成后才能开始;数据同步任务需要等数据分析任务完成后才能开始。因此,需要一个完善的任务调度与监控系统,作为数据仓库/数据平台的中枢,负责调度和监控所有任务的分配与运行。
大数据平台的整体架构
大数据平台的整体架构如下图所示。
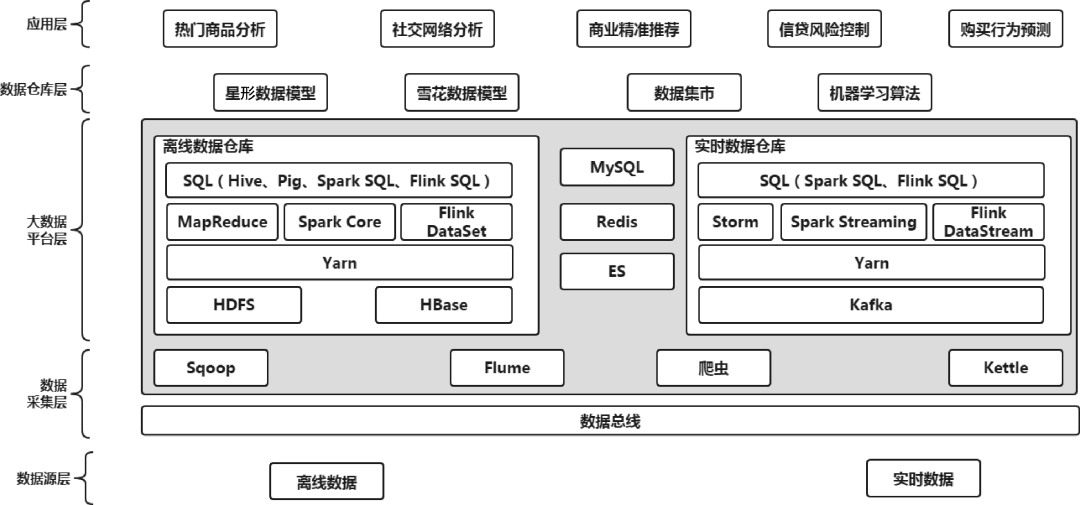
大数据平台的总体架构可以分为5层:数据源层、数据采集层、大数据平台层、数据仓库层和应用层。
上图是基于Lambda架构构建的大数据平台,这也是目前构建大数据平台的主流方式。
Lambda架构存在的最主要问题是需要维护离线与实时两套计算系统,从而导致批量与实时计算结果数据口径不一致。另外,维护两套计算系统增加了系统开发和维护的成本。
数据源层
数据源层的主要功能是提供各种需要的业务数据,例如用户订单数据、交易数据、系统的日志数据等。
尽管数据源的种类多种多样,但在大数据平台体系中可以把它们划分成两大类:
- 离线数据源:用于大数据离线计算。
- 实时数据源:用于大数据实时计算。
数据采集层
有了底层数据源提供的数据,就需要使用ETL工具完成数据的抽取、转换和加载。
Hadoop体系中就提供了这样的组件,例如:
- 使用Sqoop完成大数据平台与关系型数据库的数据交换;
- 使用Flume完成对日志数据的采集。
除了大数据平台体系本身提供的这些组件,爬虫也是一种典型的数据采集方式。当然也可以使用第三方的数据采集工具,如DataX和CDC完成数据的采集工作。
为了降低数据源层和数据采集层之间的耦合度,可以在这两层之间加入数据总线。数据总线并不是必需的,它的引入只是为了在进行系统架构设计时,降低层与层之间的耦合度。
大数据平台层
大数据平台层是整个大数据体系中最核心的一层,用于完成大数据的存储和大数据的计算。由于大数据平台可以被看作数据仓库的一种实现方式,进而又可以分为离线数据仓库和实时数据仓库。
1. 基于大数据技术的离线数据仓库的实现方式
数据采集层得到数据后,通常先将数据存储在HDFS或HBase中。然后,由离线计算引擎(如MapReduce、Spark Core、Flink DataSet)完成离线数据的分析与处理。为了在平台上对各种计算引擎进行统一的管理和调度,可以把这些计算引擎都运行在Yarn上。
接下来,可以使用Java程序或Scala程序来完成数据的分析与处理。为了简化应用的开发,在大数据平台体系中,也支持使用SQL语句来处理数据,即提供了各种数据分析引擎,例如Hadoop体系中的Hive,其默认的行为是Hive on MapReduce。这样就可以在Hive中书写标准的SQL语句,从而由Hive将其转换为MapReduce,进而运行在Yarn上,以处理大数据。
常见的大数据分析引擎除了Hive,还有Spark SQL和Flink SQL。
2. 基于大数据技术的实时数据仓库的实现方式
数据采集层得到实时数据后,为了进行数据的持久化,同时保证数据的可靠性,可以将采集的数据存入消息系统Kafka,进而由各种实时计算引擎(如Storm、Spark Stream和Flink DataStream进行处理)。
和离线数据仓库一样,这些计算引擎可以运行在Yarn上,同时支持使用SQL语句对实时数据进行处理。
离线数据仓库和实时数据仓库在实现的过程中,可能会用到一些公共的组件,例如,使用MySQL存储的元信息,使用Redis进行缓存,使用ElasticSearch(简称ES)完成数据的搜索等。
数据仓库层
有了大数据平台层的支持就可以进一步搭建数据仓库层了。在搭建数据仓库时,可以基于星形模型或雪花模型搭建。关于数仓的内容后续会专门写一篇文章介绍,这里不在赘述。
应用层
有了数据仓库层的各种数据模型和数据后,就可以基于这些模型和数据实现各种各样的应用场景了。例如热门商品分析、社交网络分析、商业精准推荐、信贷风险控制及购买行为预测等。以下是常见的大数据应用场景:
1、业务产品(CRM、ERP等)
业务产品所使用的数据,已经存在于数据共享层,直接从数据共享层访问即可;
2、报表(FineReport、业务报表)
同业务产品,报表所使用的数据,一般也是已经统计汇总好的,存放于数据共享层;
3、即席查询
即席查询的用户有很多,有可能是数据开发人员、网站和产品运营人员、数据分析人员、甚至是部门老大,他们都有即席查询数据的需求;这种即席查询通常是现有的报表和数据共享层的数据并不能满足他们的需求,需要从数据存储层直接查询。
即席查询一般是通过SQL完成,最大的难度在于响应速度上,使用Hive有点慢,可以用SparkSQL,它的响应速度较Hive快很多,而且能很好的与Hive兼容。
当然,也可以使用Impala,只是平台中会再多一个框架。
4、OLAP
目前,很多的OLAP工具不能很好的支持从HDFS上直接获取数据,都是通过将需要的数据同步到关系型数据库中做OLAP,但如果数据量巨大的话,关系型数据库显然不行;
这时候,需要做相应的开发,从HDFS或者HBase中获取数据,完成OLAP的功能;比如:根据用户在界面上选择的不定的维度和指标,通过开发接口,从HBase中获取数据来展示。
5、其它数据接口
这种接口有通用的,有定制的。比如:一个从Redis中获取用户属性的接口是通用的,所有的业务都可以调用这个接口来获取用户属性。
大数据平台各层推演
存储计算
先讲讲最核心的大数据存储和计算。这里就不得不引入Hadoop这个框架。Hadoop是大数据存储和计算的鼻祖了,现在大多开源的大数据框架都依赖Hadoop或者与它能很好的兼容。
关于Hadoop,我们需要了解他们是什么、什么原理、使用场景、如何使用:
- HDFS、MapReduce
- NameNode、DataNode
- JobTracker、TaskTracker
- Yarn、ResourceManager、NodeManager
对于大数据的处理,必须了解和会使用的就是SQL。
使用SQL处理分析Hadoop上的数据,方便、高效、易上手、更是趋势。不论是离线计算还是实时计算,越来越多的大数据处理框架都在积极提供SQL接口。
而Hive则是数据仓库工具。通过Hive命令行可以对数据进行创建表、删除表、往表中加载数据、分区、将表中数据下载到本地等操作。
HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。此时我们认知中的关于大数据平台架构至少包含以下部分:

Hive把MapReduce作为执行引擎,会发现其实执行会有些慢,所以很多SQL on Hadoop的框架越来越多,目前主流的开源OLAP计算引擎包括:Sparksql、Presto、Kylin、Impala、Druid、Clickhouse 等。因此这几个框架也扩充了数据计算层的多样性。

大数据采集
那我们如何将数据存储到HDFS上呢?这里就需要涉及数据的采集、转化、加载了。我们知道数据的来源多种多样,结构化的、半结构化和非结构化的,不同数据源也就会有不同的采集工具。例如:
·Hadoop框架自带的命令:HDFS PUT命令、HDFS API
·Sqoop:是一个主要用于Hadoop/Hive与传统关系型数据库·Oracle/MySQL/SQLServer等之间进行数据交换的开源框架。就像Hive把SQL翻译成MapReduce一样,Sqoop把你指定的参数翻译成MapReduce,提交到·Hadoop运行,完成Hadoop与其他数据库之间的数据交换。
·Flume:是一个分布式的海量日志采集和传输框架,因为“采集和传输框架”,所以它并不适合关系型数据库的数据采集和传输。
·Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。因此,如果你的业务有这些数据源的数据,并且需要实时的采集,那么就应该考虑使用Flume。
·Data X:阿里开源的关系性数据库采集交换数据的工具
此时我们认知中关于大数据平台架构会包含:

大数据应用
以上我们已经了解了大数据从采集、存储、计算的技术架构和原理了,接下来我们就可以将计算好的数据同步和应用到其他系统中去。而这一步反向数据输出的技术工具可以是和我们数据采集转换时使用的工具是一样的,也可以是计算层的使用的框架。
而对于数据的应用,根据不同的业务属性和场景,大致会分为BI平台、应用系统、数据开发平台、数据分析挖掘等。至此,大数据架构就会包含:

实时和离线
关于大数据的应用场景,我们知道有时候需要离线数据就可以了,但有些时候也需要实时的数据,所以我们在大数据的存储、计算时,同样也需要离线和实时的两套方案。
关于实时数据传输,目前比较主流的就是使用Kafka框架,它是一种分布式发布订阅消息的系统,用来处理流数据。这种架构下,将数据分为生产者和消费者。实时的场景下,Kafka充当着将数据从生产者流通到消费者的管道角色,借此吞吐量大的优势,以此实现数据及时获取和传输。离线的场景下,HDFS也可以作为数据其中消费者,通过Kafka将数据同步到HDFS。
而对于实时的数据计算,其实也分为绝对实时和准实时两种场景。绝对实时的延迟要求一般在毫秒级,准实时的延迟要求一般在秒、分钟级。对于需要绝对实时的业务场景,用的比较多的是Storm,对于其他准实时的业务场景,可以是Storm,也可以是Spark Streaming、Flink。
至此,大数据平台架构演变成了:

大数据任务调度
以上会发现大数据平台的任务越来越多了,不仅仅是分析任务,数据采集、数据交换同样是一个个的任务。这些任务中,有的是定时触发,有的则需要依赖其他任务来触发。当平台中有几百上千个任务需要维护和运行时候,仅仅靠crontab这样简单的脚本执行任务是远远不够了,这时便需要一个调度监控系统来完成这件事。调度监控系统是整个数据平台的中枢系统,类似于AppMaster,负责分配和监控任务。像这样的框架常用的就有Apache Oozie、Azkaban㩐。这时数据架构就会包含:

大数据监控和管理
大数据从采集、存储、计算、应用的过程中,程序任务是可能会出现很多问题的,例如:
1. 需要知道在数据流水线的任何步骤中数据都不会丢失。因此,需要监控每个程序正在处理的数据量,以便尽快检测到任何异常;
2. 需要有对数据质量进行测试的机制,以便在数据中出现任何意外值时,接收到告警信息;
3. 需要监控应用程序的运行时间,以便每个数据源都有一个预定义的ETA,并且会对延迟的数据源发出警报;
4. 需要管理数据血缘关系,以便我们了解每个数据源的生成方式,以便在出现问题时,我们知道哪些数据和结果会受到影响;
5. 需要系统自动处理合法的元数据变更,并能够发现和报告非法元数据变更;
6. 需要对应用程序进行版本控制并将其与数据相关联,以便在程序更改时,知道相关数据如何相应地更改。
就此我们发现,我们需要对数据进行全方位的管理,包括数据监控、数据质量检测、元数据管理、血缘关系管理、异常处理、版本控制。
这里涉及到监控预警的平台例如grafana、promethus等;保证数据质量,数据治理是比不可少的,这里涉及元数据管理、血缘关系管理、数据标准管理等的数据治理平台例如Altas、Data Hub等,当然各企业也可以是自研的管理平台和工具。
就此,数据架构就会包含如下:

大数据安全
除此之外,数据的安全是必不可少的,仅包含用户访问权限、数据资源权限管理、审计等。目前市面上也有这样的框架,例如Apache Ranger、Sentry等

云基础架构
随着业务的发展,各种大数据应用程序或任务被添加到大数据系统中后,你会发现配置机器和设置生产部署的过程非常繁琐,并且有很多的坑要踩。这个时候可能就需要考虑一下云计算平台了。通过在统一框架中运行,利用云计算易于配置和部署,弹性扩展,资源隔离,高资源利用率,高弹性,自动恢复等优势,它们将大大降低复杂性并提高运行效率。例如云基础架构K8S。此时,大数据平台架构就变成了:

总结
本文介绍了大数据的相关概念、平台架构以及各层之间的功能关系,简明的串讲了从采集、存储、计算、应用、管理、运维等多方位的大数据平台架构中应该包含的模块和常见的技术框架,供大家参考。
相关文章:
大数据核心概念与技术架构简介
大数据基本概念 大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 大数据特征: 数据量大:一般以P(1000个TB&a…...

快排 谁在中间
原题 Whos in the Middle FJ is surveying his herd to find the most average cow. He wants to know how much milk this median cow gives: half of the cows give as much or more than the median; half give as much or less. FJ正在调查他的牛群,以找到最…...

ORA-00911: invalid character
场景: 调用接口查询oracle的数据库数据时报错ORA-00911: invalid character,但是sql语句没有问题放在navicat控制台中运行也没有问题,但是代码中跑就会报无效字符集 分析: 代码中Oracle的语法解析器比较严格,比如句…...

Pytorch实现线性回归Linear Regression
借助 PyTorch 实现深度神经网络 - 线性回归 - 第 2 周 | Coursera 线性回归预测 用PyTorch实现线性回归模块 创建自定义模块(内含一个线性回归) 训练线性回归模型 对于线性回归,特定类型的噪声是高斯噪声 平均损失均方误差函数:…...

十八次(虚拟主机与vue项目、samba磁盘映射、nfs共享)
1、虚拟主机搭建环境准备 将原有的nginx.conf文件备份 [rootserver ~]# cp /usr/local/nginx/conf/nginx.conf /usr/local/nginx/conf/nginx.conf.bak[rootserver ~]# grep -Ev "#|^$" /usr/local/nginx/conf/nginx.conf[rootserver ~]# grep -Ev "#|^$"…...

P1340 兽径管理 题解|最小生成树
题目大意 洛谷中链接 推荐文章:并查集入门 原文 约翰农场的牛群希望能够在 N N N 个草地之间任意移动。草地的编号由 1 1 1 到 N N N。草地之间有树林隔开。牛群希望能够选择草地间的路径,使牛群能够从任一 片草地移动到任一片其它草地。 牛群可在…...

Python,Maskrcnn训练,cannot import name ‘saving‘ from ‘keras.engine‘ ,等问题集合
Python版本3.9,tensorflow2.11.0,keras2.11.0 问题一、module keras.engine has no attribute Layer Traceback (most recent call last):File "C:\Users\Administrator\Desktop\20240801\代码\test.py", line 16, in <module>from mrc…...

Linux常用工具
文章目录 tar打包命令详解unzip命令:解压zip文件vim操作详解netstat详解df命令详解ps命令详解find命令详解 tar打包命令详解 tar命令做打包操作 当 tar 命令用于打包操作时,该命令的基本格式为: tar [选项] 源文件或目录此命令常用的选项及…...

AI未来的发展如何
AI(人工智能)的发展前景非常广阔,随着技术的不断进步和应用场景的不断拓展,AI将在多个领域发挥重要作用。以下是对AI发展前景的详细分析: 一、技术突破与创新 生成式AI的兴起:以ChatGPT为代表的生成式AI技…...

若依替换首页上的logo
...

sed的使用示例
场景:使用sed将多个空格变成单空格,再使用cut来切分得到需要的结果 得到后面这个文件名: ls ./ drwxr-x— 2 root root 6 Jul 18 9:00 7b40f1412d83c1524af7977593607f15 drwxr-x— 2 root root 6 Jul 18 14:00 50af29cef2c65a9d28905a3ce831bcb7 drwxr-x— 2 root root 6 Jul…...

学历不是障碍:大专生如何成功进入软件测试行业
摘要: 在当今技术驱动的职场环境中,软件测试已成为一个关键的职业领域。尽管许多人认为高学历是进入这一行业的先决条件,但实际上,大专学历的学生同样有机会在软件测试领域取得成功。本文将探讨大专生如何通过技能提升、实践经验和…...

文件解析漏洞—IIS解析漏洞—IIS6.X
目录 方式 1:目录解析 方式 2:畸形文件解析 方式 3:PUT 上传漏洞(123.asp;.jpg 解析成 asp) 环境:Windows server 2003 添加 IIS 管理工具——打开 IIS——添加网站 创建完成之后,右击创建的…...

Sqlmap中文使用手册 - Brute force模块参数使用
目录 1. Brute force模块的帮助文档2. 各个参数的介绍2.1 --common-tables2.2 --common-columns2.3 --common-files 1. Brute force模块的帮助文档 Brute force:These options can be used to run brute force checks--common-tables Check existence of common tables--c…...

ubuntu20.04 开源鸿蒙源码编译配置
替换华为源 sudo sed -i "shttp://.*archive.ubuntu.comhttp://repo.huaweicloud.comg" /etc/apt/sources.list && sudo sed -i "shttp://.*security.ubuntu.comhttp://repo.huaweicloud.comg" /etc/apt/sources.list 安装依赖工具 如果是ubun…...

程序员面试 “八股文”在实际工作中是助力、阻力还是空谈?
“八股文”在实际工作中是助力、阻力还是空谈? 作为现在各类大中小企业面试程序员时的必问内容,“八股文”似乎是很重要的存在。但“八股文”是否能在实际工作中发挥它“敲门砖”应有的作用呢?有IT人士不禁发出疑问:程序员面试考…...

广告从用户点击开始到最终扣费的过程
用户点击广告 用户在网页或移动应用上看到广告,并点击广告。这一事件触发了整个广告处理流程。 广告请求触发 用户点击广告后,客户端(如浏览器、APP)向广告系统发送广告点击请求。请求通常包含以下信息: 用户ID 设备信…...

Linux系统编程-信号进程间通信
目录 异步(Asynchronous) 信号 数据结构 1.kill 2.alarm 3.pause 4.setitimer 5.abort 信号集(sigset_t类型) 1.sigemptyset 2.sigfillset 3.sigaddset 4.sigdelset 5.sigismember 信号屏蔽 1.sigprocmask 2.sigpending 3.sigsus…...
是什么?)
Attention Module (SAM)是什么?
SAM(Spatial Attention Module,空间注意力模块)是一种在神经网络中应用的注意力机制,特别是在处理图像数据时,它能够帮助模型更好地关注输入数据中不同空间位置的重要性。以下是关于SAM的详细解释: 1. 基本…...

【C语言】堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤: 1. 建堆 升序:建大堆 降序:建小堆 原因分析: 若升序建小堆时间复杂度是O(N^2) 升序建大堆,时间复杂度O(N*logN) 所以升序建大堆…...

003、TinyML与传统ML、边缘AI的区别与联系
TinyML与传统ML、边缘AI的区别与联系 从一次“模型跑死”的现场说起 上周帮一个做智能门锁的团队调模型,他们用MobileNetV2在STM32F4上做人脸检测。板子一上电,串口疯狂打印“HardFault”,复位后连RTOS都起不来。我一看代码,好家伙,直接把一个4MB的TFLite模型塞进了256K…...

分数阶傅里叶变换在声纳阵列分析中的应用与优化
1. 分数阶傅里叶变换在声纳阵列分析中的核心价值在水下声学工程领域,准确计算声纳阵列的辐射模式一直是个技术难点。传统FFT算法虽然计算效率高,但在处理特定方位角的辐射特性时存在明显的精度局限。2005年日本防卫厅技术研究本所的这项研究,…...

基于fnos-apps框架构建智能对话应用:从技能编排到生产部署
1. 项目概述:一个为现代对话应用而生的开源工具箱最近在折腾一个基于大语言模型的客服机器人项目,在集成各种外部工具和API时,遇到了一个老生常谈的问题:每个工具都有自己的调用方式、认证逻辑和错误处理,代码里很快就…...

算力入门:从FLOPS到PUE全解析
算力入门:FLOPS、TFLOPS、EFLOPS、算力规模、能效比、PUE 全解 算力(计算能力)是衡量计算机系统性能的关键指标,尤其在科学计算、人工智能和大数据处理等领域至关重要。本指南将逐步解释FLOPS、TFLOPS、EFLOPS、算力规模、能效比和PUE这些核心概念,帮助您快速入门。所有内…...

OpenClaw:让 AI 从 “对话” 走向 “实干” 的开源智能体
在人工智能技术快速发展的今天,大语言模型的对话能力已日趋成熟,但 “能说不能做” 的痛点始终制约着 AI 的实际应用价值。2026 年,一款名为 OpenClaw(社区昵称 “小龙虾 AI”)的开源项目迅速走红,它以 “真…...

如何免费获取全球50+图书馆古籍资源:BookGet数字古籍下载完整指南
如何免费获取全球50图书馆古籍资源:BookGet数字古籍下载完整指南 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget 还在为寻找古籍文献而烦恼吗?想要从哈佛、国会图书馆等全球知名…...

双强联袂,数智共舞 | 中聚信 × 金蝶启联巅峰对话,共探财税未来新航道
3 月 26 日,由金蝶软件(中国)有限公司、贵州启联科技有限公司联合主办,中聚信财税技术研究中心协办的「AI 时代 先进管理用金蝶」主题峰会,在贵阳国际生态会议中心圆满落幕。这场聚焦制造企业数字化转型与 AI 赋能管理…...

混合原型验证:软硬件协同的芯片设计革命
1. 混合原型验证:从割裂到统一的芯片设计革命在芯片设计的漫长周期里,硬件工程师和软件工程师常常像是在两个平行世界里工作。硬件团队埋头于RTL编码、综合、布局布线,最终将设计烧录进FPGA原型板,进行物理层面的调试和性能测试。…...

Linux桌面便签工具终极指南:Sticky如何重新定义你的信息管理方式
Linux桌面便签工具终极指南:Sticky如何重新定义你的信息管理方式 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否曾在忙碌的工作中突然闪现一个灵感,却因为切换…...

从“抄答案”到“会解题”:我是如何利用头歌实训平台,真正掌握Python数据分析的?
从“抄答案”到“会解题”:我的Python数据分析思维进阶之路 记得第一次打开头歌实训平台的Python数据分析题目时,我像大多数初学者一样,迫不及待地寻找"正确答案"。复制、粘贴、运行——看到绿色通过提示的瞬间,以为自己…...