如何在Python中使用网页抓取API获得Google搜索结果
SERP是搜索引擎结果页的缩写,它是你在百度、谷歌、Bing等搜索引擎中提交查询后所得到的页面。搜索引擎需要给所有页面做排序,把最能解决我们需求的页面展示给我们,企业会非常关注结果页的排序,也就是本企业内容的自然排名情况。手工研究这个结果,非常困难,一般都会借助一些成熟产品、或者集成SERP API接口,例如:
- Serpapi-Google搜索,快速、简单和完整的抓取Google、百度、Bing、易趣、雅虎、沃尔玛等和其他搜索引擎的数据
- Serpdog搜索引擎数据抓取,该API为企业和开发者提供了一种迅速且高效的途径来搜集搜索引擎的数据,可在线体验
- Bright Data – SERP API,通过该API,用户可以获取搜索结果、排名信息、广告数据、关键词建议等,帮助他们深入了解市场动态、分析竞争对手、调整SEO策略等。
本文讲述另外一种方法,如何通过网页抓取API来获取结果,而不是直接使用SERP API。
什么是网页抓取API?
网页抓取(即网络抓取、网站抓取、网络数据提取)是指从目标网站收集公共网络数据的自动化流程。不必手动采集数据,使用网页抓取工具几秒钟就可以获取大量信息。
网页抓取API通常用于分析竞争对手、市场趋势,获取消费者行为的宝贵见解等场景,是企业营销自动化的必需品。
网页抓取API是否存在风险?可以阅读《网页抓取API是否存在风险》一文。
定制化获取SERP信息的过程
本文主要用Scraperbox 公司提供的网页抓取API示例使用过程。一般网页抓取API包括如下几个过程:抓取 –> 解析 –> 结构化存储 –>数据分析。
集成网页抓取API
对于此示例,让我们创建一个调用 ScraperBox API 的 Python 程序,确保YOUR_API_KEY用您的 API 密钥替换:
import urllib.parseimport urllib.requestimport sslssl._create_default_https_context = ssl._create_unverified_context# Urlencode the URLurl = urllib.parse.quote_plus("https://www.google.com/search?q=用幂简集成搜索API")# Create the query URL.query = "https://api.scraperbox.com/scrape"query += "?api_key=%s" % "YOUR_API_KEY"query += "&url=%s" % url# Call the API.request = urllib.request.Request(query)raw_response = urllib.request.urlopen(request).read()html = raw_response.decode("utf-8")print(html)谷歌和大多数网站一样,并不太喜欢自动化程序获取搜索结果页面。
一个解决方案是通过设置正常的标题来掩盖我们是自动化程序的事实User-Agent。
...request = urllib.request.Request(query)# Set a normal User Agent headerrequest.add_header('User-Agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36')raw_response = urllib.request.urlopen(request).read()# Read the repsonse as a utf-8 stringhtml = raw_response.decode("utf-8")print(html)request = urllib.request.Request(query)用户BeautifulSoup解析数据
想要从页面中提取实际的搜索结果。先要弄清楚如何访问搜索结果,启动了 Chrome 并检查了 Google 搜索结果页面:
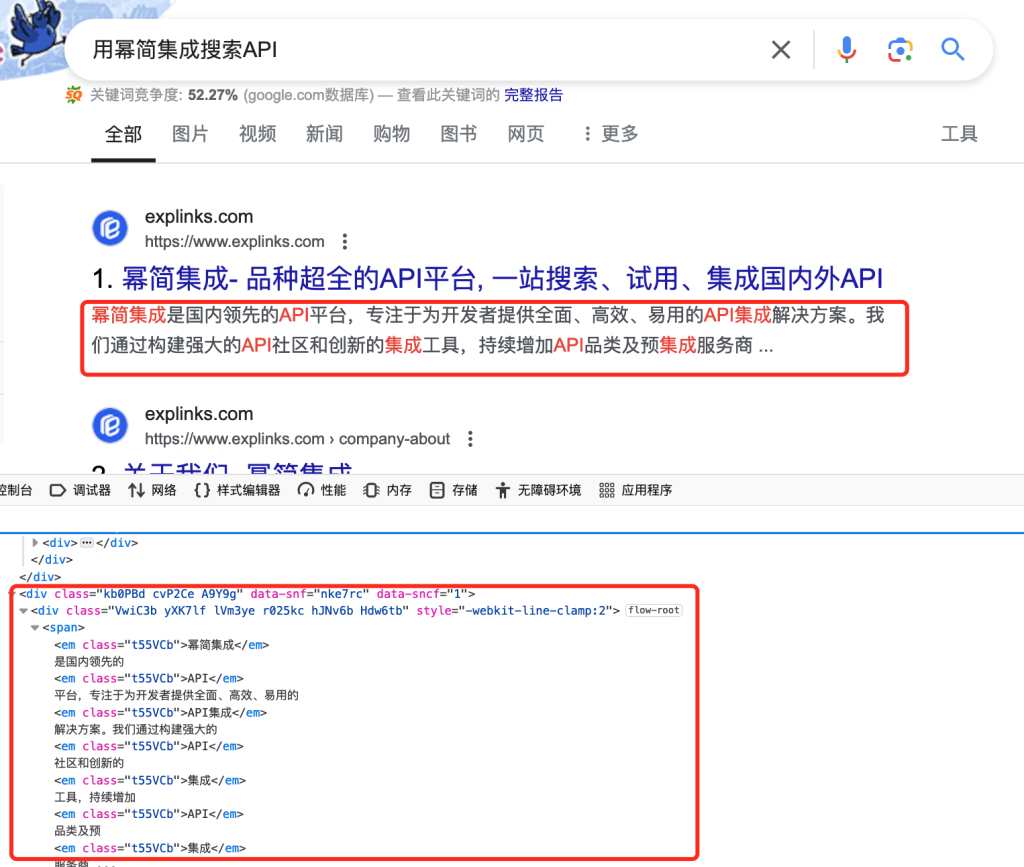
我们可以使用这些信息通过 BeautifulSoup 提取搜索结果。
# Construct the soup objectsoup = BeautifulSoup(html, 'html.parser')# Find all the search result divsdivs = soup.select("#search div.g")for div in divs:# For now just print the text contents.print(div.get_text() + "\n\n")当我检查页面时,我发现搜索标题包含在h3标签中。我们可以利用这些信息来提取标题。
# Find all the search result divsdivs = soup.select("#search div.g")for div in divs:# Search for a h3 tagresults = div.select("h3")# Check if we have found a resultif (len(results) >= 1):# Print the titleh3 = results[0]print(h3.get_text())</code></pre>按此方式解析其它要素。
其它两个步骤比较简单,不再讲解。
抓取大量页面时,被拦截怎么办?
Google 很快就会发现这是一个机器人并做出 IP拦截 。
方案一:以非常稀疏的方式进行抓取,并在每次请求之间等待 10 秒。但是,如果您需要抓取大量搜索查询,那么这不是最佳解决方案。
方案二:另一个解决方案是购买 IP代理服务器。这样你就可以从不同的 IP 地址抓取数据。但这里又有一个问题。很多人想抓取 Google 搜索结果,因此大多数代理已被 Google 屏蔽。
方案三:再一种方法是购买住宅IP代理,这些 IP 地址与真实用户无法区分。
相关文章:
如何在Python中使用网页抓取API获得Google搜索结果
SERP是搜索引擎结果页的缩写,它是你在百度、谷歌、Bing等搜索引擎中提交查询后所得到的页面。搜索引擎需要给所有页面做排序,把最能解决我们需求的页面展示给我们,企业会非常关注结果页的排序,也就是本企业内容的自然排名情况。手…...

Postman高频面试题及答案汇总(接口测试必备)
Postman在软件测试的面试中,可以说是必考题了,既然是高频考题,当然得为粉丝宝宝们整理一波题库喽~ 一、Postman在工作中使用流程是什么样的? 二、你使用过Postman的哪些功能? 三、Postman如何管理测试环境ÿ…...

JavaEE 初阶(13)——多线程11之“定时器”
目录 一. 什么是“定时器” 二. 标准库的定时器 三. 定时器的实现 MyTimer 3.1 分析思路 1. 创建执行任务的类。 2. 管理任务 3. 执行任务 3.2 线程安全问题 四. 拓展 一. 什么是“定时器” 定时器是软件开发中的一个重要组件,类似于一个“闹钟”࿰…...

2024最新全开源付费进群系统源码二开修复版 支持易支付
内容目录 一、详细介绍二、效果展示1.部分代码2.效果图展示 三、学习资料下载 一、详细介绍 全开源付费进群系统源码,开源无加密无授权,优化电脑端访问布局,支持dai理,对接易支付通道,dai理可以配置自己易支付接口&am…...

【奥顺苹果CMS二开泛目录4.X版】PHP站群程序新增首页堆砌关键词新增四套seo模板
演示站(赠送四套模板): https://macfan.qdwantong.com https://macfan2.qdwantong.com https://macfan3.qdwantong.com https://macfan4.qdwantong.com 4.X版程序特色功能: 后台除了可以设置干扰码、转码、插入符号和拼音这…...

day06 项目实践:router,axios
vue组件的生命周期钩子 今天几乎没有讲什么新内容,就是一起做项目,只有一个小小的知识点,就是关于vue组件的生命周期钩子,其中最重要的四个函数—— beforeCreate():组件创建之间执行 created():组件创建…...

⌈ 传知代码 ⌋ 基于矩阵乘积态的生成模型
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...
软件测试必备技能
在软件测试领域,以下是一些必备的技能和能力,可以帮助你成为一名优秀的软件测试工程师: 1. 测试基础知识: 熟悉软件测试的基本概念、原则和流程,包括不同类型的测试(如单元测试、集成测试、系统测试&#…...

TL3568编译uboot报错
编译uboot前,需要 ① sudo apt-get install device-tree-compiler 否则会报“ERROR: No dtc” ② sudo apt install python 装个Python2,否则会报“ERROR: No python2”...

qiankun 微前端 隔离子应用样式,解决 ant-design-vue 子应用样式污染问题(已落地)
样式冲突产生原因 先分析乾坤qiankun 构建之后,会根据你的配置 给每个子应用生成一个id, 当加载到对应子应用的时候,就把内容放到对应的id 标签里去, 这样能有效的隔离 js 代码,但是样式是加载在全局的 所以 当两个子…...
一个前后端分离架构的低代码开发平台,支持微服务架构,支持开发SAAS项目(附源码)
前言 在当前的企业软件开发领域,开发者常常面临着代码重复性高、开发效率低、项目周期长等挑战。现有的软件解-决方案往往难以满足快速变化的市场需求,特别是在SAAS项目、企业信息管理系统(MIS)、内部办公系统(OA&…...

whisper+whisperx ASR加对齐
忘了怎么安装了,这里记录一下整理出来的类,不过这个 from chj.comm.pic import *import json import whisper import whisperx import gcclass Warp_whisper:def __init__(self, language"zh", device"cuda", compute_type"fl…...

【已解决】YOLOv8加载模型报错:super().__init__(torch._C.PyTorchFileReader(name_or_buffer))
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

中国象棋 纯网页前端 演示与下载
https://andi.cn/app/chess/...

学习大数据DAY29 python基础语法2
目录 调试---debug tuple(元组) set(集合) dict(字典) 转换 推导式 上机练习 3 函数 参数 不定长参数 值传递与引用传递 局部和全局变量 上机练习 4 调试---debug 1. 先设置断点 2. 点击调试…...

自动化测试常用函数(Java方向)
目录 一、元素的定位 1.1 cssSelector 1.2 xpath 1.2.1 获取HTML页面所有的节点 1.2.2 获取HTML页面指定的节点 1.2.3 获取⼀个节点中的直接子节点 1.2.4 获取⼀个节点的父节点 1.2.5 实现节点属性的匹配 1.2.6 使用指定索引的方式获取对应的节点内容 二、操作测试对…...

申瓯通信设备有限公司在线录音管理系统(复现过程)
漏洞简介 申瓯通信设备有限公司在线录音管理系统 index.php接口处存在任意文件读取漏洞,恶意攻击者可能利用该漏洞读取服务器上的敏感文件,例如客户记录、财务数据或源代码,导致数据泄露 一.复现过程 fofa搜索语句:title"在线录音管…...

【C++进阶学习】第十一弹——C++11(上)——右值引用和移动语义
前言: 前面我们已经将C的重点语法讲的大差不差了,但是在C11版本之后,又出来了很多新的语法,其中有一些作用还是非常大的,今天我们就先来学习其中一个很重要的点——右值引用以及它所扩展的移动定义 目录 一、左值引用和…...

JavaScript 监听 localStorage 的变化
使用 JavaScript 监听 localStorage 的变化 在Web开发中,localStorage是一种非常常用的本地存储机制。它允许我们在浏览器中存储键值对数据,即使用户关闭了浏览器或刷新页面,数据也不会丢失。但是,有时我们需要实时监控 localStorage 的变化,以便能够及时做出响应。在本文中,我…...

Java 中 HashMap 和 Hashtable 的联系
目录 相同 不同 1. 继承的父类不同 2. 线程安全性不同 3. 包含的 contains 方法不同 4. toString方法不同 5. 是否允许null值不同 6. 计算hash值的方式不同 7. 计算索引位置的方法不同 8. 初始化容量不同 9. 扩容方式不同 10. 内部存储策略不同(此处讨论…...

Neovim集成ChatGPT:AI编程助手插件配置与实战指南
1. 项目概述:当Neovim遇上ChatGPT,一个插件如何重塑你的编码体验 如果你是一个Neovim的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经听说过或者正在寻找一个完美的结合点。 jackMort/ChatGPT.nvim 这个项目&…...

终极指南:3分钟解决Windows安装iPhone网络共享驱动难题
终极指南:3分钟解决Windows安装iPhone网络共享驱动难题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mi…...

HDiffPatch实际应用案例:APK文件差异化和Android应用商店优化
HDiffPatch实际应用案例:APK文件差异化和Android应用商店优化 【免费下载链接】HDiffPatch a C\C library and command-line tools for Diff & Patch between binary files or directories(folder); cross-platform; runs fast; create small delta/differentia…...
)
别再对着乱码发愁了!手把手教你用Python解码AIS VDM暗码(附完整代码)
从AIS暗码到可读数据:Python实战解析指南 当你第一次看到类似!AIVDM,1,1,,A,169DvlgP1R8KPtvFBfOCt3?h0RT,0*03这样的字符串时,可能会感到一头雾水。这串看似随机的字符实际上是AIS(船舶自动识别系统)传输的VDM(VHF Data-link Message)报文,…...

Neo-Launcher数据库架构:数据存储和管理的深度解析
Neo-Launcher数据库架构:数据存储和管理的深度解析 【免费下载链接】Neo-Launcher Neo-Launcher 项目地址: https://gitcode.com/gh_mirrors/ne/Neo-Launcher Neo-Launcher是一款由Neo Collective开发的开源启动器应用,其高效的数据存储和管理系统…...

Narrative-craft:工程化叙事框架的设计、实现与集成指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Narrative-craft”,作者是chengjialu8888。光看名字,你可能会觉得这又是一个讲“叙事”或者“故事创作”的抽象工具。但点进去仔细研究后,我发现它远不止于此。这…...

superpowers skill 3.1: using-git-worktrees
智能体工作流 安装 $ npx skills add https://github.com/obra/superpowers --skill using-git-worktrees摘要 具有智能目录选择和安全验证的隔离 Git 工作树。 通过检查现有目录、CLAUDE.md 偏好设置或询问用户来自动检测工作树目录位置;支持项目本地ÿ…...
 的6个高阶用法,数据分析师必看)
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看 在数据分析的日常工作中,缺失值处理就像是一道无法回避的数学题。许多刚入行的分析师会条件反射般地输入.fillna(0),这就像用创可贴处理所有伤口——有…...

开关电源EMC设计:从原理到实践的关键技术
1. 开关电源EMC设计基础 开关电源因其高效率和小型化优势,在现代电子设备中广泛应用。然而,高频开关动作带来的电磁干扰(EMI)问题不容忽视。作为一名电源工程师,我经常需要面对各种EMC挑战。记得有一次,我们团队设计的工业电源模块…...

告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境
告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh…...