数据结构和算法(1):数组
目录
- 概述
- 动态数组
- 二维数组
- 局部性原理
- 越界检查
概述
定义
在计算机科学中,数组是由一组元素(值或变量)组成的数据结构,每个元素有至少一个索引或键来标识
In computer science, an array is a data structure consisting of a collection of elements (values or variables), each identified by at least one array index or key
因为数组内的元素是连续存储的,所以数组中元素的地址,可以通过其索引计算出来,例如:
int[] array = {1,2,3,4,5}
知道了数组的数据起始地址 BaseAddressBaseAddressBaseAddress,就可以由公式 BaseAddress+i∗sizeBaseAddress + i * sizeBaseAddress+i∗size 计算出索引 iii 元素的地址
- iii 即索引,在 Java、C 等语言都是从 0 开始
- sizesizesize 是每个元素占用字节,例如 intintint 占 444,doubledoubledouble 占 888
小测试
byte[] array = {1,2,3,4,5}
已知 array 的数据的起始地址是 0x7138f94c8,那么元素 3 的地址是什么?
答:0x7138f94c8 + 2 * 1 = 0x7138f94ca
空间占用
Java 中数组结构为
- 8 字节 markword
- 4 字节 class 指针(压缩 class 指针的情况)
- 4 字节 数组大小(决定了数组最大容量是 2322^{32}232)
- 数组元素 + 对齐字节(java 中所有对象大小都是 8 字节的整数倍[^12],不足的要用对齐字节补足)
例如
int[] array = {1, 2, 3, 4, 5};
的大小为 40 个字节,组成如下
8 + 4 + 4 + 5*4 + 4(alignment)
随机访问性能
即根据索引查找元素,时间复杂度是 O(1)O(1)O(1)
逻辑大小和物理大小
数组的物理大小是它的数组单元的总数,或者说是在创建数组的时候,用来指定其容量的数字。
数组的逻辑大小,是它当前已供应用程序使用的项的数目。
当数组总是满的时候,不用担心他俩的区别,但是这种情况很少。
通常,逻辑大小的物理大小会告诉我们数组状态的几件重要的事:
- 如果逻辑大小为0,数组为空,则说明该数组不包含数据项;
- 如果数组包含的数据项,数组最后一项的索引为逻辑大小减1;
- 如果逻辑大小等于物理大小,数组已经被数据填满。
动态数组
java 版本
import java.util.Arrays;
import java.util.Iterator;
import java.util.function.Consumer;
import java.util.stream.IntStream;/*** @author Ethan* @date 2023/3/20* @description*/
public class Ds01DynamicArray implements Iterable<Integer> {/*** 逻辑大小*/private int size = 0;/*** 容量*/private int capacity = 8;/*** 初始化数组为空*/private int[] array = {};/*** 向任意位置添加元素** @param index 索引位置* @param element 待添加元素*/public void add(int index, int element) {// 检查容量大小,不够要扩容checkAndGrow();// 如果插入的位置效益逻辑大小,那么要先把位置腾出来,索引位置以后得元素都要后移一位if (index >= 0 && index < size) {// 向后挪动, 空出待插入位置,使用数组的copy方法// 从哪书分别是源数组、源数组起始位置、目标数组、目标数组的起始位置、copy元素个数System.arraycopy(array, index,array, index + 1, size - index);}// 在指定位置插入元素array[index] = element;// 逻辑大小+1size++;}/*** 向最后位置 [size] 添加元素** @param element 待添加元素*/public void addLast(int element) {// 复用任意位置添加元素,插入位置是逻辑大小add(size, element);}/*** 容量检查,不够进行扩容*/private void checkAndGrow() {// 容量检查if (size == 0) {array = new int[capacity];} else if (size == capacity) {// 进行扩容, 1.5 1.618 2capacity += capacity >> 1;int[] newArray = new int[capacity];System.arraycopy(array, 0,newArray, 0, size);array = newArray;}}/*** 从 [0 .. size) 范围删除元素** @param index 索引位置* @return 被删除元素*/public int remove(int index) { // [0..size)// 要删除的元素int removed = array[index];// 如果要删除的元素索引小于逻辑大小-1,那么把目标索引的后面元素都向前移动一位if (index < size - 1) {// 向前挪动System.arraycopy(array, index + 1,array, index, size - index - 1);}// 逻辑大小-1size--;return removed;}/*** 查询元素** @param index 索引位置, 在 [0..size) 区间内* @return 该索引位置的元素*/public int get(int index) {return array[index];}/*** 遍历方法1** @param consumer 遍历要执行的操作, 入参: 每个元素*/public void foreach(Consumer<Integer> consumer) {// 使用Consumer把拿到的元素交给调用者来使用,具体使用方法取决于调用者for (int i = 0; i < size; i++) {// 提供 array[i]// 返回 voidconsumer.accept(array[i]);}}/*** 遍历方法2 - 迭代器遍历,这个类要实现Iterator接口*/@Overridepublic Iterator<Integer> iterator() {// 使用匿名内部类,直接返回一个迭代器,实现接口的两个方法return new Iterator<Integer>() {int i = 0;@Overridepublic boolean hasNext() { // 有没有下一个元素return i < size;}@Overridepublic Integer next() { // 返回当前元素,并移动到下一个元素return array[i++];}};}/*** 遍历方法3 - stream 遍历** @return stream 流*/public IntStream stream() {return IntStream.of(Arrays.copyOfRange(array, 0, size));}}
- 这些方法实现,都简化了 index 的有效性判断,假设输入的 index 都是合法的
插入或删除性能
**头部位置:**因为要把头部后面的元素都移动一位,所以时间复杂度是 O(n)O(n)O(n);
**中间位置:**一样要移动指定索引位置后的元素,所以时间复杂度是 O(n)O(n)O(n)
**尾部位置:**可直接通过索引找到最后一个元素,且不需要移动元素,所以时间复杂度是 O(1)O(1)O(1)(均摊来说)
二维数组
所谓的二维数组就是数组中的数组,数组嵌套数组。如下:
int[][] array = {{11, 12, 13, 14, 15},{21, 22, 23, 24, 25},{31, 32, 33, 34, 35},
};
内存图如下
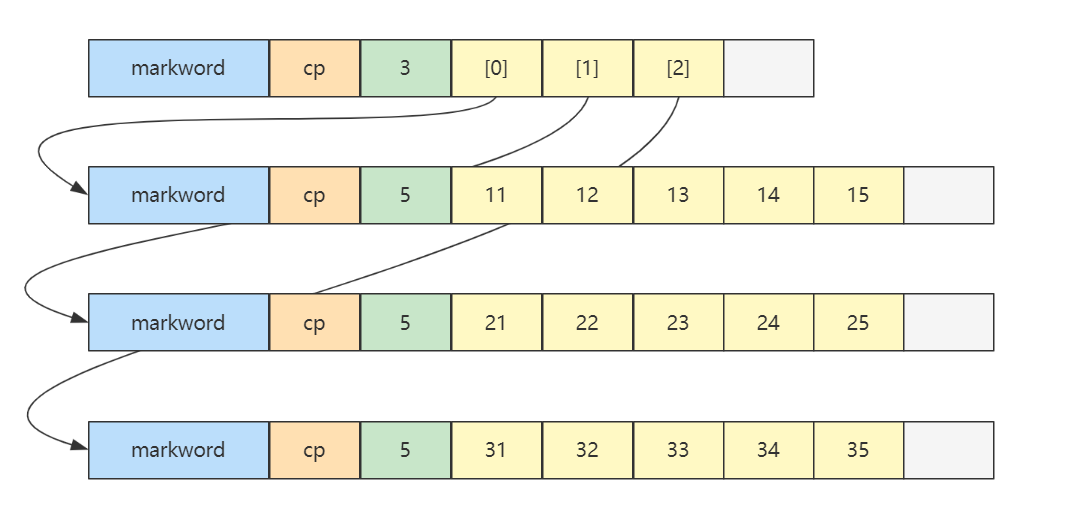
-
最上面的二维数组占 32 个字节,其中 array[0],array[1],array[2] 三个元素分别保存了指向三个一维数组的引用
-
三个一维数组各占 40 个字节
-
它们在内层布局上是连续的
更一般的,对一个二维数组 Array[m][n]Array[m][n]Array[m][n]
- mmm 是外层数组的长度,可以看作 row 行
- nnn 是内层数组的长度,可以看作 column 列
- 当访问 Array[i][j]Array[i][j]Array[i][j],0≤i<m,0≤j<n0\leq i \lt m, 0\leq j \lt n0≤i<m,0≤j<n时,就相当于
- 先找到第 iii 个内层数组(行)
- 再找到此内层数组中第 jjj 个元素(列)
小测试
Java 环境下(不考虑类指针和引用压缩,此为默认情况),有下面的二维数组
byte[][] array = {{11, 12, 13, 14, 15},{21, 22, 23, 24, 25},{31, 32, 33, 34, 35},
};
已知 array 对象起始地址是 0x1000,那么 23 这个元素的地址是什么?
答:
- 起始地址 0x1000
- 外层数组大小:16字节对象头 + 3元素 * 每个引用4字节 + 4 对齐字节 = 32 = 0x20
- 第一个内层数组大小:16字节对象头 + 5元素 * 每个byte1字节 + 3 对齐字节 = 24 = 0x18
- 第二个内层数组,16字节对象头 = 0x10,待查找元素索引为 2
- 最后结果 = 0x1000 + 0x20 + 0x18 + 0x10 + 2*1 = 0x104a
局部性原理
这里只讨论空间局部性
- cpu 读取内存(速度慢)数据后,会将其放入高速缓存(速度快)当中,如果后来的计算再用到此数据,在缓存中能读到的话,就不必读内存了
- 缓存的最小存储单位是缓存行(cache line),一般是 64 bytes,一次读的数据少了不划算啊,因此最少读 64 bytes 填满一个缓存行,因此读入某个数据时也会读取其临近的数据,这就是所谓空间局部性
对效率的影响
比较下面 ij 和 ji 两个方法的执行效率
int rows = 1000000;
int columns = 14;
int[][] a = new int[rows][columns];StopWatch sw = new StopWatch();
sw.start("ij");
ij(a, rows, columns);
sw.stop();
sw.start("ji");
ji(a, rows, columns);
sw.stop();
System.out.println(sw.prettyPrint());
ij 方法
public static void ij(int[][] a, int rows, int columns) {long sum = 0L;for (int i = 0; i < rows; i++) {for (int j = 0; j < columns; j++) {sum += a[i][j];}}System.out.println(sum);
}
ji 方法
public static void ji(int[][] a, int rows, int columns) {long sum = 0L;for (int j = 0; j < columns; j++) {for (int i = 0; i < rows; i++) {sum += a[i][j];}}System.out.println(sum);
}
执行结果
0
0
StopWatch '': running time = 96283300 ns
---------------------------------------------
ns % Task name
---------------------------------------------
016196200 017% ij
080087100 083% ji
可以看到 ij 的效率比 ji 快很多,为什么呢?
- 缓存是有限的,当新数据来了后,一些旧的缓存行数据就会被覆盖
- 如果不能充分利用缓存的数据,就会造成效率低下
以 ji 执行为例,第一次内循环要读入 [0,0][0,0][0,0] 这条数据,由于局部性原理,读入 [0,0][0,0][0,0] 的同时也读入了 [0,1]...[0,13][0,1] ... [0,13][0,1]...[0,13],如图所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ap5uUytD-1679319472567)(.\imgs\image-20221104164329026.png)]](https://img-blog.csdnimg.cn/66107833323a44959bf3906d06981c61.png)
但很遗憾,第二次内循环要的是 [1,0][1,0][1,0] 这条数据,缓存中没有,于是再读入了下图的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zuvKO099-1679319472568)(.\imgs\image-20221104164716282.png)]](https://img-blog.csdnimg.cn/5f6383ae6f7c4e40b79aa40e3b204e3c.png)
这显然是一种浪费,因为 [0,1]...[0,13][0,1] ... [0,13][0,1]...[0,13] 包括 [1,1]...[1,13][1,1] ... [1,13][1,1]...[1,13] 这些数据虽然读入了缓存,却没有及时用上,而缓存的大小是有限的,等执行到第九次内循环时
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q4dHdf2Y-1679319472568)(.\imgs\image-20221104164947154.png)]](https://img-blog.csdnimg.cn/304e3084862c4da69e306390a50f50e4.png)
缓存的第一行数据已经被新的数据 [8,0]...[8,13][8,0] ... [8,13][8,0]...[8,13] 覆盖掉了,以后如果再想读,比如 [0,1][0,1][0,1],又得到内存去读了
同理可以分析 ij 函数则能充分利用局部性原理加载到的缓存数据
举一反三
-
I/O 读写时同样可以体现局部性原理
-
数组可以充分利用局部性原理,那么链表呢?
答:链表不行,因为链表的元素并非相邻存储
越界检查
java 中对数组元素的读写都有越界检查,类似于下面的代码
bool is_within_bounds(int index) const
{ return 0 <= index && index < length();
}
- 代码位置:
openjdk\src\hotspot\share\oops\arrayOop.hpp
只不过此检查代码,不需要由程序员自己来调用,JVM 会帮我们调用
相关文章:
数据结构和算法(1):数组
目录概述动态数组二维数组局部性原理越界检查概述 定义 在计算机科学中,数组是由一组元素(值或变量)组成的数据结构,每个元素有至少一个索引或键来标识 In computer science, an array is a data structure consisting of a col…...
python+django+vue全家桶鲜花商城售卖系统
重点: (1) 网上花店网站中各模块功能之间的的串联。 (2) 网上花店网站前台与后台的连接与同步。 (3) 鲜花信息管理模块中鲜花的发布、更新与删除。 (4) 订单…...
一文带你领略 WPA3-SAE 的 “安全感”
引入 WPA3-SAE也是针对四次握手的协议。 四次握手是 AP (authenticator) 和 (supplicant)进行四次信息交互,生成一个用于加密无线数据的秘钥。 这个过程发生在 WIFI 连接 的 过程。 为了更好的阐述 WPA3-SAE 的作用 …...
Python解题 - CSDN周赛第38期
又来拯救公主了。。。本期四道题还是都考过,而且后面两道问哥在以前写的题解里给出了详细的代码(当然是python版),直接复制粘贴就可以过了——尽管这样显得有失公允,考虑到以后还会出现重复的考题,所以现在…...
Android绘制——自定义view之onLayout
简介 在自定义view的时候,其实很简单,只需要知道3步骤: 测量——onMeasure():决定View的大小,关于此请阅读《Android自定义控件之onMeasure》布局——onLayout():决定View在ViewGroup中的位置绘制——onD…...

用Qt画一个温度计
示例1 以下是用Qt绘制一个简单的温度计的示例代码: #include <QPainter> #include <QWidget> #include <QApplication> class Thermometer : public QWidget { public:Thermometer(QWidget *parent 0); protected:void paintEvent(QPaintEvent …...
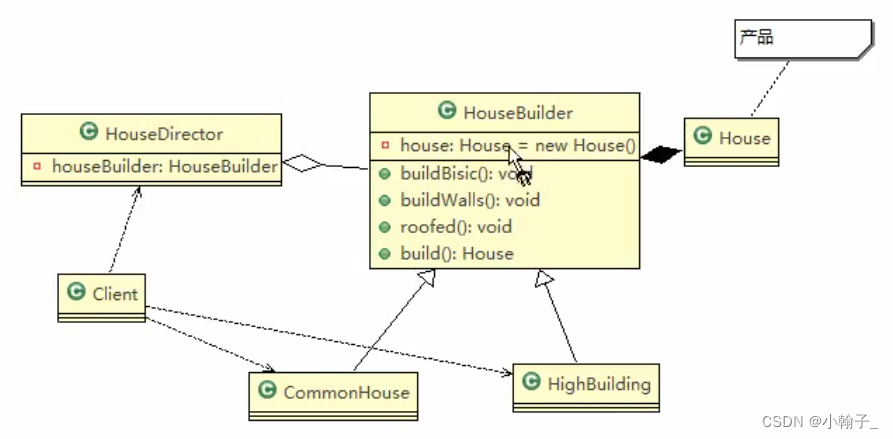
Java设计模式 04-建造者模式
建造者模式 一、 盖房项目需求 1)需要建房子:这一过程为打桩、砌墙、封顶 2)房子有各种各样的,比如普通房,高楼,别墅,各种房子的过程虽然一样,但是要求不要相同的. 3)请编写程序,完成需求. …...

安语未公告于2023年3月20日发布
因一些特殊原因,凡事都是有开始,高潮和结束三大过程,做出以下决定: 所有对 安语未文章 为之热爱、鞭策、奉献,和支持过的开发者: 注:所有资源以及资料都会正常下载和查看 如需联系࿱…...

进销存是什么?如何选择进销存系统?
什么是进销存?进销存软件概念起源于上世纪80年代,由于电算化的普及,计算机管理的推广,不少企业对于仓库货品的进货,存货,出货管理,有了强烈的需求,进销存软件的发展从此开始。 进入…...

基于BP神经网络的图像跟踪,基于BP神经网络的细胞追踪识别
目录 摘要 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络激活函数及公式 基于BP神经网络的细胞识别追踪 matab编程代码 效果 结果分析 展望 摘要 智能驾驶,智能出行是现代社会发展的趋势之一,其中,客量预测对智能出行至关重要,…...
Java面试总结篇
引用介绍 1.线程安全不安全的概念 线程安全: 指多个线程在执行同一段代码的时候采用加锁机制,使每次的执行结果和单线程执行的结果都是一样的,不存在执行程序时出现意外结果。 线程不安全: 是指不提供加锁机制保护,有可能出现多个线程先后更改数据造成所得到的数据是脏…...
100天精通Python(可视化篇)——第80天:matplotlib绘制不同种类炫酷柱状图代码实战(簇状、堆积、横向、百分比、3D柱状图)
文章目录0. 专栏导读1. 普通柱状图2. 簇状柱形图3. 堆积柱形图4. 横向柱状图5. 横向双向柱状图6. 百分比堆积柱形图7. 3D柱形图8. 3D堆积柱形图9. 3D百分比堆积柱形图0. 专栏导读 🏆🏆作者介绍:Python领域优质创作者、CSDN/华为云/阿里云/掘金…...

【Java】UDP网络编程
文章目录前言DatagramSocketDatagramPacket注意事项与区别代码演示前言 UDP(user datagram protocol)的中文叫用户数据报协议,属于传输层。 UDP是面向非连接的协议,它不与对方建立连接,而是直接把我要发的数据报发给对…...
Springboot源代码总结
前言 编写微服务,巩固知识 文章目录 前言springboot原理springboot启动流程SpringBoot自动配置底层源码解析自动配置到底配了什么?自动配置类条件注解Starter机制@ConditionalOnMissingBeanSpringBoot启动过程源码解析构造SpringApplication对象SpringBoot完整的配置优先级s…...
JVM监控搭建
文章目录JVM监控搭建整体架构JolokiaTelegrafInfluxdbGrafanaJVM监控搭建 整体架构 JVM 的各种内存信息,会通过 JMX 接口进行暴露。 Jolokia 组件负责把 JMX 信息翻译成容易读取的 HTTP 请求。Telegraf 组件作为一个通用的监控 agent,和 JVM 进程部署在…...

java中如何优化大量的if...else...
目录 策略模式(Strategy Pattern) 工厂模式(Factory Pattern) 映射表(Map) 数据驱动设计(Data-Driven Design) 策略模式(Strategy Pattern) 将每个条件分…...
24. linux系统基础
两个进程间想通讯,必须要通过内核,今天讲的信号其实本质也是讲进程间通讯的意思,那么你为什么可以在shell环境下,可以和一个进程发kill-9啊? shell是不是相当于一个进程?你自己运行的那个进程是不是也相当于…...

【C++】面试101,二叉搜索树的最近公共祖先,在二叉树中找到两个节点的最近公共祖先,序列化二叉树,重建二叉树,输出二叉树的右视图,组队竞赛,删除公共字符
目录 1.二叉搜索树的最近公共祖先 2.在二叉树中找到两个节点的最近公共祖先 3.序列化二叉树 4.重建二叉树 5.输出二叉树的右视图 6.组队竞赛 7.删除公共字符 1.二叉搜索树的最近公共祖先 这是一个简单的问题,因为是二叉搜索树(有序)&am…...

Java常见面试题及解答
Java常见面试题及解答1 面向对象的三个特征2 this,super关键字3 基础数据类型4 public、protected、default、private5 接口6 抽象类6.1 抽象类和接口的区别7 重载(overload)、重写(override)8 final、finalize、final…...
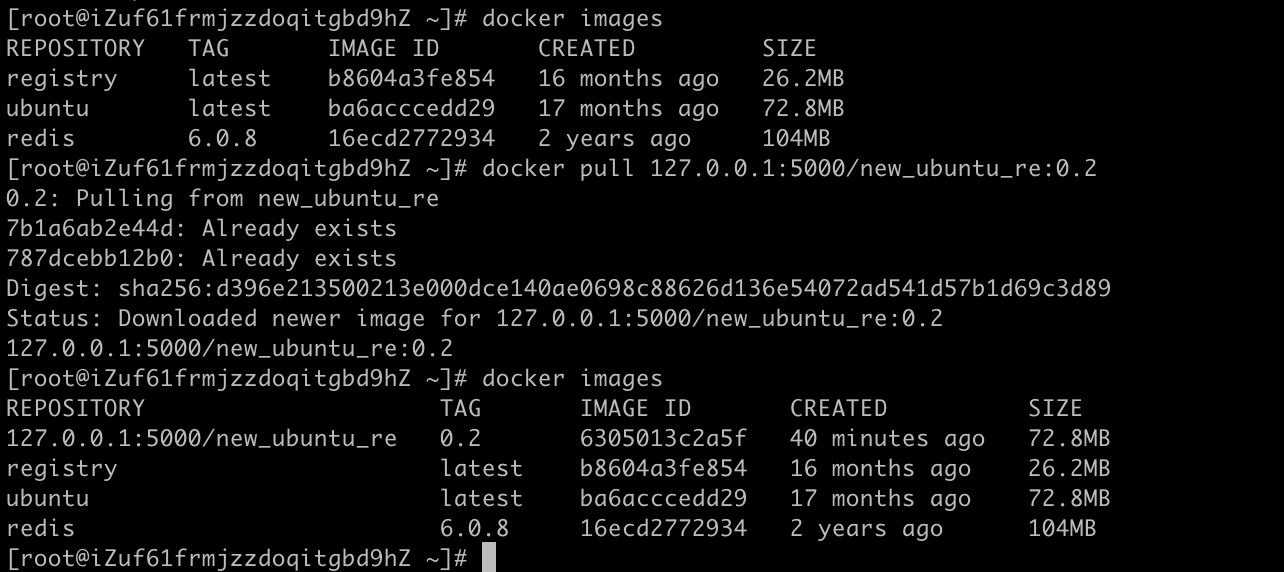
【Docker】镜像的原理定制化镜像
文章目录镜像是什么UnionFS(联合文件系统)Docker镜像加载原理制作本地镜像 docker commit -m"提交的描述信息" -a"作者" 容器ID 要创建的目标镜像名:[标签名]案例演示ubuntu安装vim本地镜像发布到阿里云本地镜像发布到阿里云流程将本…...

气电版通用自动分选机:圆柱电芯测试分选的精准之选
在新能源产业蓬勃发展的当下,圆柱电芯作为重要的储能元件,其生产过程中的质量把控至关重要。内阻和电压作为衡量电芯性能的关键指标,直接关系到电芯的使用寿命、充放电效率以及安全性。气电版通用自动分选机凭借其卓越的性能和精准的分选能力…...

PowerToys Image Resizer:告别繁琐,三秒搞定图片批量处理
PowerToys Image Resizer:告别繁琐,三秒搞定图片批量处理 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trendin…...

嵌入式开发中数据结构的优化与应用实践
1. 数据结构在嵌入式开发中的核心价值作为一名在嵌入式领域摸爬滚打十年的老兵,我深刻体会到数据结构就像瑞士军刀里的各种工具——选对工具能让工作事半功倍。在资源受限的MCU环境中,一个精心选择的数据结构可能意味着程序能否流畅运行和内存是否会爆掉…...

Git二分法精准定位Bug
Git二分法定位Bug的原理Git二分法基于二分查找算法,通过自动在提交历史中不断缩小范围,定位引入Bug的特定提交。其核心是利用git bisect命令,结合测试脚本或手动验证,高效识别问题根源。准备工作确保本地仓库有完整的提交历史&…...

永磁同步电机矢量控制仿真避坑指南:从PI参数整定到SVPWM模块优化
永磁同步电机矢量控制仿真避坑指南:从PI参数整定到SVPWM模块优化 在工业自动化和电力驱动领域,永磁同步电机(PMSM)凭借其高效率、高功率密度和优异的动态性能,已成为众多应用场景的首选。然而,要实现PMSM的…...

Windows驱动存储深度管理:从问题诊断到系统优化的完整解决方案
Windows驱动存储深度管理:从问题诊断到系统优化的完整解决方案 【免费下载链接】DriverStoreExplorer Driver Store Explorer [RAPR] 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 问题发现:驱动管理中的隐形痛点与风险 系…...

一篇大模型Agents工作流优化最新综述
过去,人们总希望一个LLM直接把任务做完;现在,一个更现实的方向正在浮现——针对不同任务设计不同工作流,并让系统在执行前、执行中乃至执行后持续优化这条链路。 近日,Rensselaer Polytechnic Institute(RP…...

Windows ISO制作与补丁集成自动化工具实战指南:从手动操作到批量部署的效率革命
Windows ISO制作与补丁集成自动化工具实战指南:从手动操作到批量部署的效率革命 【免费下载链接】Win_ISO_Patching_Scripts Win_ISO_Patching_Scripts 项目地址: https://gitcode.com/gh_mirrors/wi/Win_ISO_Patching_Scripts 在数字化时代,系统…...

Open-Shell-Menu:让Windows界面回归高效与个性化的开源解决方案
Open-Shell-Menu:让Windows界面回归高效与个性化的开源解决方案 【免费下载链接】Open-Shell-Menu Classic Shell Reborn. 项目地址: https://gitcode.com/gh_mirrors/op/Open-Shell-Menu 当项目经理王工在Windows 11电脑上第5次点击"所有应用"按钮…...

钢链数智,赋能实业——千匠网络钢铁产业电商系统,破解行业困局,激活钢铁增长新动能
钢铁行业作为国民经济的支柱产业,贯穿基建、制造、房地产、机械装备等核心领域,正处于从“规模扩张”向“质量提升”转型的关键阶段:从铁矿开采、冶炼轧制、钢材加工,到多级分销、终端采购、工程交付,全链路环节繁杂、…...