【机器学习基础】Scikit-learn主要用法

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开源库如Scikit-learn、TensorFlow和PyTorch。本专栏介绍机器学习的相关算法以及基于Python的算法实现。
文章目录
- 一、Scikit-learn概述
- 二、Scikit-learn主要用法
- (一)基本建模流程
- (二)加载数据集
- (三)划分数据集
- (四)数据预处理
- (五)构建并拟合模型
- (六)评估模型
- (七)模型优化
- 三、Scikit-learn案例
一、Scikit-learn概述
Scikit-learn是基于NumPy、SciPy和Matplotlib的开源Python机器学习包,它封装了一系列数据预处理、机器学习算法、模型选择等工具,是数据分析师首选的机器学习工具包。
自2007年发布以来,scikit-learn已经成为Python重要的机器学习库了,scikit-learn简称sklearn,支持包括分类,回归,降维和聚类四大机器学习算法。还包括了特征提取,数据处理和模型评估三大模块。

二、Scikit-learn主要用法
符号标记:
| 符号 | 意义 | 符号 | 意义 |
|---|---|---|---|
X_train | 训练数据 | y_train | 训练集标签 |
X_test | 测试数据 | y_test | 测试集标签 |
X | 完整数据 | y | 数据标签 |
(一)基本建模流程

总体处理流程可以分为:加载数据集、数据预处理、数据集划分、模型估计器创建、模型拟合、模型性能评估
(二)加载数据集
1. 导入工具包
from sklearn import datasets, preprocessing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
2. 加载数据
Scikit-learn支持以NumPy的arrays对象、Pandas对象、SciPy的稀疏矩阵及其他可转换为数值型arrays的数据结构作为其输入,前提是数据必须是数值型的。
sklearn.datasets模块提供了一系列加载和获取著名数据集如鸢尾花、波士顿房价、Olivetti人脸、MNIST数据集等的工具,也包括了一些toy data如S型数据等的生成工具。
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
(三)划分数据集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=12, stratify=y, test_size=0.3)

将完整数据集的70%作为训练集,30%作为测试集,并使得测试集和训练集中各类别数据的比例与原始数据集比例一致(stratify分层策略),另外可通过设置shuffle=True提前打乱数据。
(四)数据预处理
1. 数据变换
使⽤Scikit-learn进行数据标准化:
# 导入数据标准化工具包
from sklearn.preprocessing import StandardScaler
# 构建转换器实例
scaler = StandardScaler()
# 拟合及转换
scaler.fit_transform(X_train)
Z-Score标准化: x ∗ = x − μ σ σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 , μ = 1 m ∑ i = 1 m x ( i ) x^*=\frac{x-\mu}{\sigma} \\[2ex] \sigma^2=\frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)^2,\mu=\frac{1}{m}\sum_{i=1}^mx^{(i)} x∗=σx−μσ2=m1i=1∑m(x(i)−μ)2,μ=m1i=1∑mx(i) 处理后的数据均值为0,方差为1。
使用Scikit-learn进行数据变换:
-
最小最大标准化:
MinMaxScaler
归一化(最大 - 最小规范化): x ∗ = x − x min x max − x min x^*=\frac{x-x_{\min}}{x_{\max}-x_{\min}} x∗=xmax−xminx−xmin 将数据映射到 [ 0 , 1 ] [0,1] [0,1] 区间 -
One-Hot编码:
OneHotEncoder -
归一化:
Normalizer -
二值化(单个特征转换):
Binarizer -
标签编码:
LabelEncoder -
缺失值填补:
Imputer -
多项式特征生成:
PolynomialFeatures
2. 特征选择
from sklearn import feature_selection as fs
过滤式(Filter),保留得分排名前k的特征(top k方式)。
fs.SelectKBest(score_func, k)
封装式(Wrap- per),结合交叉验证的递归特征消除法,自动选择最优特征个数。
fs.RFECV(estimator, scoring=“r2”)
嵌入式(Embedded),从模型中自动选择特征,任何具有coef_或者feature_importances_的基模型都可以作为estimator参数传入。
fs.SelectFromModel(estimator)
(五)构建并拟合模型
1. 监督学习算法——回归
from sklearn.linear_model import LinearRegression
# 构建模型实例
lr = LinearRegression(normalize=True)
# 训练模型
lr.fit(X_train, y_train)
# 作出预测
y_pred = lr.predict(X_test)
- LASSO:
linear_model.Lasso - Ridge:
linear_model.Ridge - ElasticNet:
linear_model.ElasticNet - 回归树:
tree.DecisionTreeRegressor
2. 监督学习算法——分类
from sklearn.tree import DecisionTreeClassifier
# 构建模型实例
clf = DecisionTreeClassifier(max_depth=5)
# 训练模型
clf.fit(X_train, y_train)
# 作出预测
y_pred = clf.predict(X_test)
y_prob = clf.predict_proba(X_test)
使用决策树分类算法解决二分类问题,y_prob为每个样本预测为“0”和“1”类的概率。
- 逻辑回归:
linear_model.LogisticRegression - 支持向量机:
svm.SVC - 朴素贝叶斯:
naive_bayes.GaussianNB - K近邻:
neighbors.NearestNeighbors
3. 监督学习算法——集成学习
sklearn.ensemble模块包含了一系列基于集成思想的分类、回归和离群值检测方法。
from sklearn.ensemble import RandomForestClassifier
# 构建模型实例
clf = RandomForestClassifier(n_estimators=20)
# 训练模型
clf.fit(X_train, y_train)
# 作出预测
y_pred = clf.predict(X_test)
y_prob = clf.predict_proba(X_test)
- AdaBoost(适应提升算法):
ensemble.AdaBoostClassifier
ensemble.AdaBoostRegressor - GBboost(梯度提升算法):
ensemble.GradientBoostingClassifier
ensemble.GradientBoostingRegressor
4. 无监督学习算法——k-means
sklearn.cluster模块包含了一系列无监督聚类算法。
from sklearn.cluster import KMeans
# 构建模型实例
kmeans = KMeans(n_clusters=3, random_state=0)
# 训练模型
kmeans.fit(X_train)
# 作出预测
kmeans.predict(X_test)
- DBSCAN:
cluster.DBSCAN - 层次聚类:
cluster.AgglomerativeClustering - 谱聚类:
cluster.SpectralClustering
5. 无监督学习算法——降维
sklearn.decomposition模块包含了一系列无监督降维算法。
from sklearn.decomposition import PCA
# 导入PCA库,设置主成分数量为3,n_components代表主成分数量
pca = PCA(n_components=3)
# 训练模型
pca.fit(X)
# 投影后各个特征维度的方差比例(这里是三个主成分)
print(pca.explained_variance_ratio_)
# 投影后的特征维度的方差
print(pca.explained_variance_)
(六)评估模型
sklearn.metrics模块包含了一系列用于评价模型的评分函数、损失函数以及成对数据的距离度量函数。
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred)
对于测试集而言,y_test即是y_true,大部分函数都必须包含真实值y_true和预测值y_pred。
1. 回归模型评价
- 平均绝对误差MAE:
metrics.mean_absolute_error() - 均方误差MSE:
metrics.mean_squared_error() - 决定系数R²:
metrics.r2_score()
2. 分类模型评价
- 正确率:
metrics.accuracy_score() - 各类精确率:
metrics.precision_score() - F1值:
metrics.f1_score() - 对数损失或交叉熵损失:
metrics.log_loss() - 混淆矩阵:
metrics.confusion_matrix - 含多种评价的分类报告:
metrics.classification_report
(七)模型优化
1. 交叉验证
from sklearn.model_selection import cross_val_score
clf = DecisionTreeClassifier(max_depth=5)
scores = cross_val_score(clf, X_train, y_train, cv=5, scoring=’f1_weighted’)
使用5折交叉验证对决策树模型进行评估,使用的评分函数为F1值。
sklearn提供了部分带交叉验证功能的模型类如LassoCV、LogisticRegressionCV等,这些类包含cv参数。

2. 超参数调优⸺网格搜索
from sklearn.model_selection import GridSearchCV
from sklearn import svm
svc = svm.SVC()
params = {'kernel':['linear','rbf'],'C':[1, 10]}
grid_search = GridSearchCV(svc, params, cv=5)
grid_search.fit(X_train, y_train)
grid_search.best_params_
在参数网格上进行穷举搜索,方法简单但是搜索速度慢(超参数较多时),且不容易找到参数空间中的局部最优。
3. 超参数调优⸺随机搜索
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
svc = svm.SVC()
param_dist = {'kernel':['linear','rbf'], 'C':randint(1, 20)}
random_search = RandomizedSearchCV(svc, param_dist, n_iter=10)
random_search.fit(X_train, y_train)
random_search.best_params_
在参数子空间中进行随机搜索,选取空间中的100个点进行建模(可从scipy.stats常见分布如正态分布norm、均匀分布uniform中随机采样得到),时间耗费较少,更容易找到局部最优。
三、Scikit-learn案例
可参考:Python数据分析实验四:数据分析综合应用开发
应用Scikit-Learn库中的逻辑回归对Scikit-Learn自带的乳腺癌(from sklearn.datasets import load_breast_cancer)数据集进行分类,并分别评估每种算法的分类性能。为了进一步提升算法的分类性能,能否尝试使用网格搜索和交叉验证找出每种算法较优的超参数。
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()#用训练集训练模型估计器estimator
lgr.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=lgr.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
print("测试集的分类准确率为:",lgr.score(X_test,y_test))
print(" ")
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names)) #网格搜索与交叉验证相结合的逻辑回归算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_lgr={'C':[0.01,0.1,1,10,100],'max_iter':[100,200,300],'solver':['liblinear','lbfgs']}
kf=KFold(n_splits=5,shuffle=False)grid_search_lgr=GridSearchCV(lgr,params_lgr,cv=kf)
grid_search_lgr.fit(X_train,y_train)
grid_search_y_pred=grid_search_lgr.predict(X_test)
print("Accuracy:",grid_search_lgr.score(X_test,y_test))
print("best params:",grid_search_lgr.best_params_)

另外,推荐一个Scikit-learn学习网站:Scikit-learn中文社区
相关文章:
【机器学习基础】Scikit-learn主要用法
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,…...
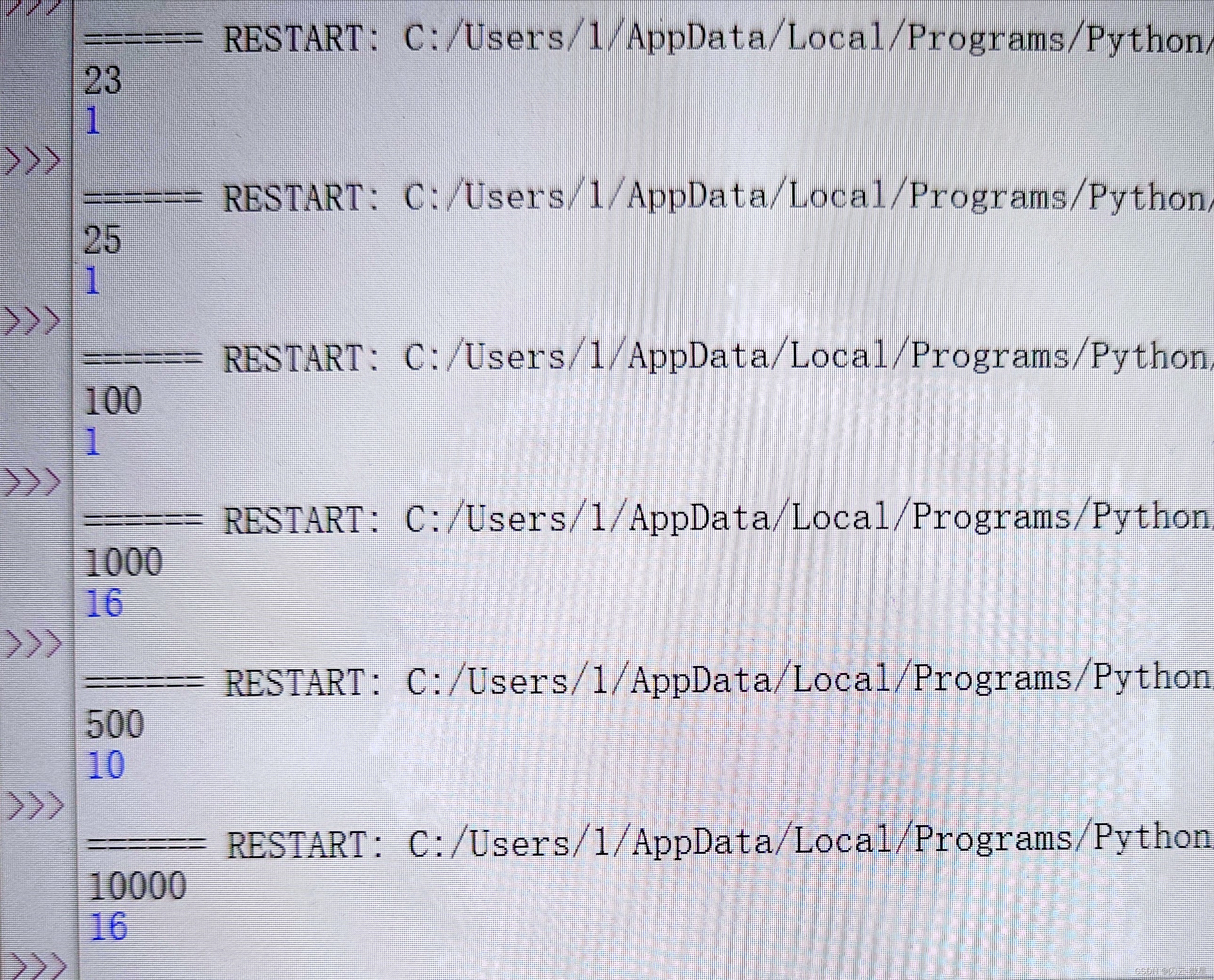
python-素数回文数的个数(赛氪OJ)
[题目描述] 求 11 到 n 之间(包括 n),既是素数又是回文数的整数有多少个。输入: 一个大于 11 小于 10000 的整数 n。输出: 11 到 n 之间的素数回文数个数。样例输入1 23 样例输出1 1 提示: 回文数指左右对…...
-网格划分算法)
OCC 网格化(二)-网格划分算法
目录 一、概述 二、详解 1. 线性偏转 (Linear Deflection) 2. 角偏转 (Angular Deflection) 三、示例 3.1 示例1 3.2 示例2 一、概述 在 Open CASCADE Technology (OCC) 中默认的网格划分算法BRepMesh_IncrementalMesh有两个主要的选项来定义三角剖分—线性和角偏转。 …...

pyecharts模块
PyEcharts 一个基于ECharts库的Python封装库,它使得开发者可以方便地在Python环境中创建交互式的图表,包括折线图、柱状图、饼图、地图等多种可视化效果。 优点: 易用性:PyEcharts提供了简单易懂的API,通过链式调用…...

深⼊理解指针(3)
1. 字符指针变量 2. 数组指针变量 3. ⼆维数组传参的本质 4. 函数指针变量 5. 函数指针数组 6. 转移表 1. 字符指针变量 在指针的类型中我们知道有⼀种指针类型为字符指针 ⼀般使⽤: char* 这两种方式都是把字符串中的首字符的地址赋值给pc。 在这串代码中 str1内容的地…...

黑马头条vue2.0项目实战(四)——首页—文章列表
目录 1. 头部导航栏 1.1 页面布局 1.2 样式调整中遇到的问题 2. 频道列表 2.1 页面布局 2.2 样式调整 2.3 展示频道列表 3. 文章列表 3.1 思路分析 3.2 使用 List 列表组件 3.3 加载文章列表数据 3.4 下拉刷新 3.5 设置上下padding固定头部和频道列表 3.6 记住列…...

UE5.4内容示例(4)UI_UMG - 学习笔记
https://www.unrealengine.com/marketplace/zh-CN/product/content-examples 《内容示例》是学习UE5的基础示例,可以用此熟悉一遍UE5的功能 UI示例 UI_UMG :基本UMGUI_CommonUI :UMG多层应用UI_SlatePostBuffer UI :FX的示例&…...

C#实现数据采集系统-配置文件化
系统优化-配置 配置信息ip端口,还有点位信息,什么的都是直接在代码里直接写死,添加点位,修改配置,比较麻烦,每次修改都需要重新生成打包。 所以将这些配置都改成配置文件,这样只需要修改配置文件,程序无须修改,即可更新。 配置代码: 如果我们有100个采集,一个个去…...

Java面试题 -- 为什么重写equals就一定要重写hashcode方法
在回答这个问题之前我们先要了解equals与hascode方法的本质是做什么的 1. equals方法 public boolean equals(Object obj) {return (this obj);}我们可以看到equals在不重写的情况下是使用判断地址值是否相同 所以默认的 equals 的逻辑就是判断的双方是否引用了一个对象&am…...

J031_使用TCP协议支持与多个客户端同时通信
一、需求文档 使用TCP协议支持与多个客户端同时通信。 1.1 Client package com.itheima.tcp2;import java.io.DataOutputStream; import java.io.OutputStream; import java.net.Socket; import java.util.Scanner;public class Client {public static void main(String[] a…...
)
二分查找(精确查找、范围搜索)
目录 1. 二分查找概述2. 精确查找2.1 【left,right】2. 2 【left,right) 3. 范围查找总结 1. 二分查找概述 二分查找法,也称为二分搜索法或折半查找法,是一种在有序数组中查找特定元素的搜索算法。其基本思想是&#x…...

软件工程简记
文章目录 一、软件工程要点之软件设计二、UML(Unified Modeling Language,统一建模语言)(一)UML 的整体分类与部分功能(二)UML 各类图的具体内容三、开发模型(一)多种开发模型的特点与问题四、设计模式(一)设计模式的总体概念与原则(二)软件结构设计原则(三)常见…...

【深度学习】【语音TTS】OpenVoice v2,测评,中英文语料,Docker镜像,对比GPT-SoVITS、FishAudio、BertVITS2
https://github.com/myshell-ai/OpenVoice/blob/main/docs/USAGE.md 实际体验OpenVoice v2的TTS效果。 文章目录 环境启动 jupyter代码代码分析主要模块和功能测试一些别的中文和中英文混合总结优点缺点对比GPT-SoVITS、FishAudio、BertVITS2使用我的Docker镜像快速体验OpenVo…...

Kotlin OpenCV 图像图像50 Haar 级联分类器模型
Kotlin OpenCV 图像图像50 Haar 级联分类器模型 1 OpenCV Haar 级联分类器模型2 Kotlin OpenCV Haar 测试代码 1 OpenCV Haar 级联分类器模型 Haar级联分类器是一种用于对象检测(如人脸检测)的机器学习算法。它由Paul Viola和Michael Jones在2001年提出…...

嗖嗖移动业务大厅(Java版)
首先对此项目说明一下,我只完成了项目的基本需求,另外增加了一个用户反馈的功能,但是可能项目中间使用嗖嗖这个功能还有一些需要完善的地方,或者还有一些小bug,就当给大家参考一下了,希望谅解。代码我也上传…...

hcia复习笔记
一、OSI 七层模型 应用层:为应用程序提供服务,如文件传输、电子邮件等。 表示层:数据格式转换、加密解密、压缩解压缩。 会话层:建立、维护和管理会话。 传输层:提供端到端的可靠或不可靠的数据传输服务࿰…...

pycharm中安装、使用扩展工具,以QT Designer为例
pycharm中安装、使用扩展工具,以QT Designer为例 第一步,下载QT Designer安装包。找到QT Designer.exe所在位置,复制路径 第二步,打开Pycharm,选择Setting,找到扩展工具(External Tools…...

【Rust光年纪】Rust语言实用库汇总:从机器翻译到全文搜索引擎
优秀的Rust语言库探索:机器翻译、音频编解码和全文搜索引擎 前言 Rust语言在近年来迅速崛起,成为了一种备受欢迎的系统级编程语言。随着其生态系统的不断丰富,涌现出了许多优秀的库和工具。本文将重点介绍几个用于Rust语言的重要库…...

学习笔记 - 二极管的参数与选型
二极管 普通二极管: 1N4148(高频开关二极管) 整流二极管: 1N4007 1A 1000V1N5408 3A 1000V 肖特基二极管 (白线边为阴极) SS14 SS34 SS54 常见肖特基二极管参数 快恢复二极管 FR107 FR207 FR307 UF4007 可以用快恢复二…...

PMP--冲刺--易混概念
文章目录 十大知识领域一、整合管理项目管理计划与项目文件的区分: 二、范围管理三、进度管理赶工与快速跟进的区分:赶工增加资源,以最小的成本代价来压缩进度工期;快速跟进,将正常情况下按顺序进行的活动或阶段改为至…...

基于 JiuwenClaw AgentTeam 集群模式的年会策划实战:从源码部署到多智能体协作落地
目录 摘要 一、引言:JiuwenClaw AgentTeam 让复杂任务迎刃而解 1.1 为什么选择年会策划作为 AgentTeam 实战场景 1.2 本文实战目标 二、JiuwenClaw 概述 2.1 JiuwenClaw 的核心特性 2.2 JiuwenClaw 的系统架构 2.3 JiuwenClaw 的三种运行模式 2.3.1 规划模…...

IC场景XR全息通信_CSDN
6G IC场景XR/全息通信技术深度分析 摘要: 6G时代的沉浸式通信(Immersive Communication, IC)是实现"存在感"传输的核心场景,其中XR与全息通信技术对网络提出了Tbps级速率和亚毫秒级延迟的极限需求。本文从技术需求量化、…...

对比官方价格体验Taotoken活动价带来的直接成本节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格体验 Taotoken 活动价带来的直接成本节省 在开发与使用大模型 API 的过程中,成本是每个开发者与团队都需要…...

PiliPlus:用Flutter重新定义你的B站观影体验
PiliPlus:用Flutter重新定义你的B站观影体验 【免费下载链接】PiliPlus PiliPlus 项目地址: https://gitcode.com/gh_mirrors/pi/PiliPlus 在众多视频平台中,B站以其独特的社区文化和丰富内容生态深受用户喜爱。然而,官方客户端的一些…...

NovelForge:AI长篇小说创作引擎,结构化写作与知识图谱实战
1. 项目概述:一个为长篇创作而生的AI写作伙伴如果你和我一样,是一个对长篇故事创作充满热情,但又时常被海量设定、角色关系、情节推进和前后一致性搞得焦头烂额的作者,那么NovelForge的出现,可能正是我们一直在等待的“…...

在自动化客服场景中利用Taotoken实现多模型智能路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服场景中利用Taotoken实现多模型智能路由 对于构建智能客服系统的产品团队而言,核心挑战之一是如何在保证服…...

Modbus RTU 与 Modbus TCP 深入指南-附录:快速参考表
十五、附录:快速参考表 15.1 Modbus RTU 帧示例速查 操作请求帧(十六进制)响应帧示例读线圈(1个)01 01 00 00 00 01 CRC01 01 01 01 CRC读离散输入01 02 00 00 00 01 CRC01 02 01 00 CRC读保持寄存器(1个…...

BrowserClaw:容器化浏览器自动化平台部署与爬虫实战指南
1. 项目概述:一个浏览器自动化与数据抓取的瑞士军刀最近在折腾一些数据采集和自动化测试的活儿,发现一个挺有意思的开源项目,叫BrowserClaw。这名字起得挺形象,“浏览器之爪”,一听就知道是跟浏览器自动化、网页抓取相…...

摄像头驱动调试避坑指南:用示波器快速定位I2C不通、MIPI无信号问题
摄像头驱动调试避坑指南:用示波器快速定位I2C不通、MIPI无信号问题 当摄像头模组在硬件调试阶段出现异常时,软件工程师往往会陷入"配置检查-重新烧录-再检查"的死循环。实际上,80%的摄像头初始化失败问题源于硬件信号层面的异常。本…...

Firefly开源中文大模型:指令微调、部署与领域适配实战
1. 项目概述:一个专为中文优化的开源大语言模型最近在开源社区里,Firefly(流萤)这个项目引起了我的注意。它不是一个通用框架,而是一个经过精心指令微调的大语言模型系列。简单来说,你可以把它理解为一个“…...