计算机毕业设计Python+Spark知识图谱高考志愿推荐系统 高考数据分析 高考可视化 高考大数据 大数据毕业设计
《Spark高考推荐系统》开题报告
一、选题背景及意义
1. 选题背景
随着我国高考制度的不断完善和大数据技术的飞速发展,高考志愿填报已成为考生和家长高度关注的重要环节。传统的志愿填报方式依赖于考生和家长手动查找和对比各种信息,不仅效率低下且容易出错。同时,由于信息不对称和缺乏有效的决策支持工具,很多考生和家长在填报志愿时感到迷茫和困惑。因此,开发一款基于大数据和机器学习技术的高考志愿推荐系统显得尤为重要。
2. 研究意义
(1)解决高考志愿填报的痛点:高考志愿填报是一个复杂而重要的过程,需要综合考虑多种因素。基于Spark的高考推荐系统可以提供个性化的志愿推荐,帮助考生和家长更好地理解和选择适合自己的志愿,从而解决信息不对称和决策支持不足的问题。
(2)提高志愿填报的效率和准确性:利用大数据和机器学习技术,对历年高考数据进行分析和挖掘,为考生提供更加准确和全面的志愿推荐,显著提高志愿填报的效率和准确性。
(3)推动大数据和人工智能技术在教育领域的应用和发展:本系统的研究和开发不仅有助于提高高考志愿填报的效率和准确性,还能推动大数据和人工智能技术在教育领域的应用和发展,为未来的教育改革提供有益的借鉴。
(4)促进教育公平:系统综合考虑考生的兴趣、能力、成绩等多种因素,提供个性化的志愿推荐,避免单一因素导致的决策偏差,从而促进教育公平。
二、研究目标及内容
1. 研究目标
本研究旨在开发一款基于Spark平台的高考志愿推荐系统,通过大数据和机器学习技术,为考生提供个性化的志愿推荐服务,解决高考志愿填报中的痛点问题,提高志愿填报的效率和准确性。
2. 研究内容
(1)数据采集与预处理:使用Python爬虫技术采集历年高考数据(包括省控线、专业线、学校信息、专业信息等),并进行数据清洗和预处理,确保数据的准确性和完整性。
(2)推荐算法研究:研究并应用协同过滤算法(基于用户和基于物品两种模式)、内容过滤算法和混合推荐算法等,结合高考志愿填报的具体场景,确定最适合的推荐算法。
(3)系统架构设计:设计基于Spark平台的推荐系统架构,包括数据采集模块、预处理模块、推荐引擎模块和可视化展示模块等,确保系统的稳定性和高效性。
(4)系统实现与测试:使用SpringBoot、Vue.js等前后端分离技术实现系统,并使用MySQL数据库进行数据存储和管理。通过测试验证系统的可行性和有效性,确保系统能够稳定运行并满足用户需求。
三、研究方法及技术路线
1. 研究方法
(1)文献调研:通过查阅相关文献和资料,了解高考志愿推荐系统的研究现状和发展趋势,为本研究提供理论支持。
(2)数据采集与预处理:使用Python爬虫技术采集高考数据,并进行数据清洗和预处理,确保数据的准确性和完整性。
(3)算法研究与应用:研究并应用协同过滤算法、内容过滤算法和混合推荐算法等,结合高考志愿填报的具体场景进行算法优化和改进。
(4)系统实现与测试:使用SpringBoot、Vue.js等前后端分离技术实现系统,并使用MySQL数据库进行数据存储和管理。通过测试验证系统的可行性和有效性。
2. 技术路线
(1)数据采集:使用Python的requests框架采集高考数据API接口的历年高考数据。
(2)数据预处理:对数据进行清洗、去重、归一化等预处理操作,确保数据的准确性和一致性。
(3)推荐算法实现:利用Spark平台的MLlib库实现协同过滤算法、内容过滤算法和混合推荐算法等,结合高考志愿填报的具体场景进行算法优化和改进。
(4)系统实现:使用SpringBoot作为后端框架,Vue.js作为前端框架,实现前后端分离的系统架构。使用MySQL数据库进行数据存储和管理,并使用Echarts进行数据的可视化展示。
(5)系统测试:对系统进行全面的功能测试和性能测试,确保系统能够稳定运行并满足用户需求。
四、预期成果及创新点
1. 预期成果
(1)开发一款基于Spark平台的高考志愿推荐系统,为考生提供个性化的志愿推荐服务。
(2)通过测试和验证,确保系统的可行性和有效性,提高高考志愿填报的效率和准确性。
(3)撰写详细的毕业论文,总结研究成果和经验教训,为未来的研究和应用提供参考。
2. 创新点
(1)基于Spark平台的数据处理:利用Spark平台的高效计算能力,对海量高考数据进行快速处理和分析,提高系统的处理速度和准确性。
(2)混合推荐算法的应用:结合协同过滤算法和内容过滤算法的优点,采用混合推荐算法进行志愿推荐,提高推荐的准确性和个性化

































在编写关于《Spark高考推荐系统》的推荐算法Scala代码时,我们通常需要考虑使用Apache Spark的MLlib库,该库提供了多种机器学习算法的实现,包括用于推荐系统的协同过滤算法。以下是一个简化的示例,展示了如何使用Spark的ALS(交替最小二乘法)算法来实现一个基本的推荐系统。
请注意,这个例子假设你已经有了用户-项目评分数据(在高考推荐系统中,这可能转化为用户-专业或用户-学校偏好数据),并且这些数据已经被加载到Spark的DataFrame中。
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.recommendation.ALS
import org.apache.spark.sql.functions._ object SparkCollegeRecommendation { def main(args: Array[String]): Unit = { // 初始化SparkSession val spark = SparkSession.builder() .appName("Spark College Recommendation System") .master("local[*]") // 在这里修改为你的Spark集群配置 .getOrCreate() // 假设DataFrame "ratings"已经加载,包含columns: userId, collegeId, rating // 示例数据加载(这里仅为示例,实际应从数据源加载) // val ratings = spark.createDataFrame(Seq( // (1, 1, 4.0), (1, 2, 2.0), (2, 1, 5.0), (2, 3, 3.0), (3, 2, 2.0), (3, 3, 5.0) // )).toDF("userId", "collegeId", "rating") // 实例化ALS算法 val als = new ALS() .setMaxIter(10) // 最大迭代次数 .setRegParam(0.01) // 正则化参数 .setUserCol("userId") .setItemCol("collegeId") .setRatingCol("rating") // 训练模型 val model = als.fit(ratings) // 进行预测 // 假设我们想要预测用户1对学院4的评分 val userId = 1 val collegeIds = Array(4) val userRecs = model.recommendForAllUsers(10).filter($"userId" === userId) val specificPredictions = model.recommendForUser(userId, 1) .collect() .filter(_.products.exists(_.id == collegeIds(0))) .map(_.products.find(_.id == collegeIds(0)).get.rating) // 输出预测结果 println(s"Predictions for user $userId on college ${collegeIds(0)}: ${specificPredictions.headOption.getOrElse(0.0)}") println("Top 10 recommendations for user 1:") userRecs.show(truncate = false) // 停止SparkSession spark.stop() }
}请注意,上面的代码有几个关键点:
- SparkSession:这是Spark SQL和DataFrame API的入口点。
- ALS:这是Apache Spark MLlib中用于协同过滤的类。
- DataFrame:
ratingsDataFrame应该包含用户ID、学院ID和评分三列。 - 模型训练和预测:使用ALS模型进行训练,并为用户生成推荐或预测特定项目的评分。
此外,请注意,上面的specificPredictions部分假设了我们对特定用户的特定学院进行了预测,但在实际情况下,你可能需要调整这部分代码以适应你的具体需求。
还需要注意的是,由于示例中并未实际加载数据,你需要根据你的数据源修改数据加载部分。在实际应用中,数据可能来自CSV文件、数据库或其他数据源。
相关文章:
计算机毕业设计Python+Spark知识图谱高考志愿推荐系统 高考数据分析 高考可视化 高考大数据 大数据毕业设计
《Spark高考推荐系统》开题报告 一、选题背景及意义 1. 选题背景 随着我国高考制度的不断完善和大数据技术的飞速发展,高考志愿填报已成为考生和家长高度关注的重要环节。传统的志愿填报方式依赖于考生和家长手动查找和对比各种信息,不仅效率低下且容…...

【python】文件
在python中可以通过文件操作,将数据保存到计算机硬盘中文件,可以包含文本数据,也可以包含二进制数据(图片,视频,音频等)。 目录 前言 正文 一、基本语法 1、函数open()打开file 返回一个文件对象 1.1、文件路径 1&a…...

《Attention Is All You Need》核心观点及概念
这个文件据说是一篇很厉害的AI论文,https://arxiv.org/pdf/1706.03762 这篇论文《Attention Is All You Need》确实是AI领域中的一个里程碑,它改变了我们处理语言的方式。 下面小编会用简单的语言来解释这篇文章的核心观点和学术概念,并告诉大家它为什么很厉害。 核心观点…...

【中项】系统集成项目管理工程师-第9章 项目管理概论-9.9价值交付系统
前言:系统集成项目管理工程师专业,现分享一些教材知识点。觉得文章还不错的喜欢点赞收藏的同时帮忙点点关注。 软考同样是国家人社部和工信部组织的国家级考试,全称为“全国计算机与软件专业技术资格(水平)考试”&…...
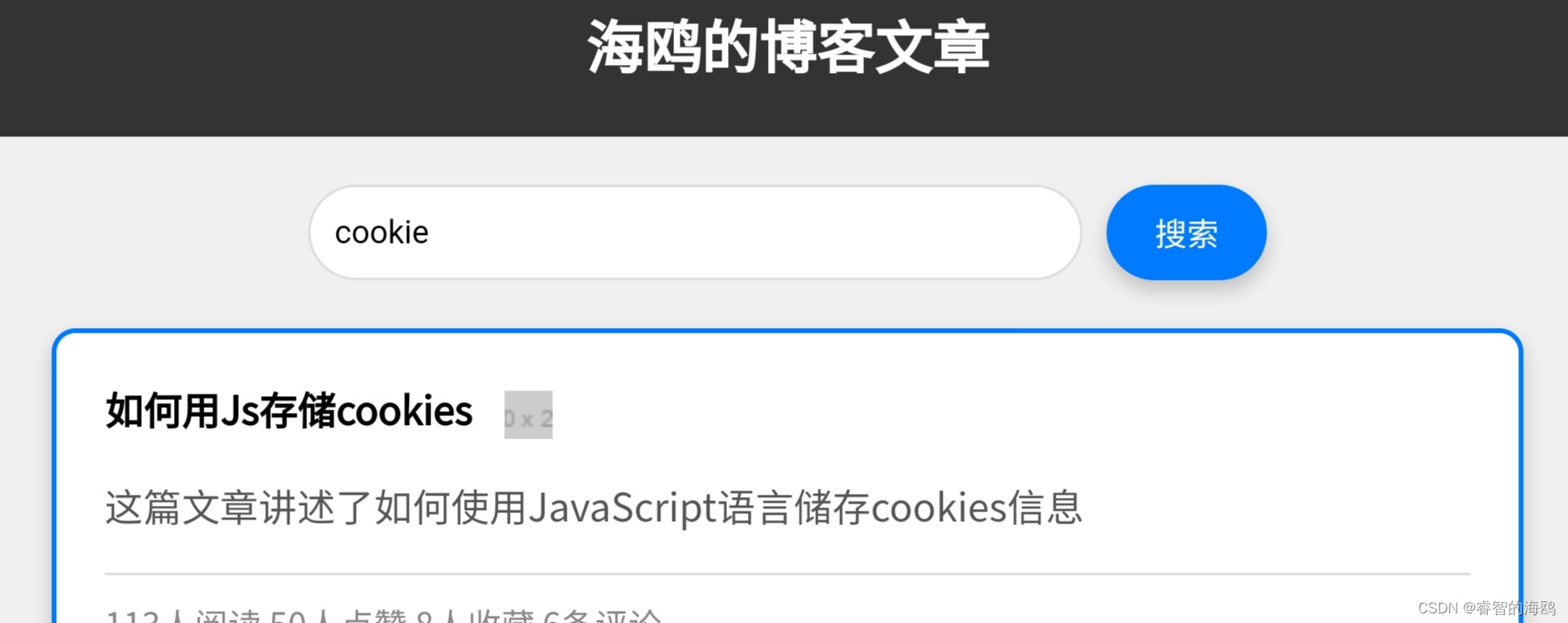
JS+H5美观的带搜索的博客文章列表(可搜索多个参数)
实现 美观的界面(电脑、手机端界面正常使用)多参数搜索(文章标题,文章简介,文章发布时间等)文章链接跳转 效果图 手机端 电脑端 搜索实现 搜索功能实现解释 定义文章数据: 文章数据保存在一个 JavaScri…...
)
牛客周赛 Round 54 (c++题解)
比赛地址 : 牛客竞赛_ACM/NOI/CSP/CCPC/ICPC算法编程高难度练习赛_牛客竞赛OJ A 输出o的个数; #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0); #define endl \n using namespace std; typedef long long LL;inlin…...

htsjdk库Genotype及相关类介绍
在 HTSJDK 库中,处理基因型的主要类包括 Genotype、FastGenotype、GenotypeBuilder 以及相关的类和接口。以下是这些类和接口的详细介绍: Genotype 类 主要功能 表示基因型:Genotype 类用于表示个体在特定变异位置上的基因型。基因型是对个体在变异位置上的等位基因组合的…...
 洛谷)
C++ 最短路(spfa) 洛谷
拉近距离 题目背景 我是源点,你是终点。我们之间有负权环。 ——小明 题目描述 在小明和小红的生活中,有 N 个关键的节点。有 M 个事件,记为一个三元组 (Si,Ti,Wi),表示从节点 Si 有一个事件可以转移到 Ti,事件…...

MySQL的数据类型
文章目录 数据类型分类整型bit类型浮点类型字符串类型charvarchar 日期和时间类型enum和set find_ in_ set 数据类型分类 整型 在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。 可以通过UNSIGNED来说明某个字段是无符号的。 在MySQL中如…...

xss漏洞(四,xss常见类型)
本文仅作为学习参考使用,本文作者对任何使用本文进行渗透攻击破坏不负任何责任。 前言: 1,本文基于dvwa靶场以及PHP study进行操作,靶场具体搭建参考上一篇: xss漏洞(二,xss靶场搭建以及简单…...

繁简之争:为什么手机芯片都是 ARM
RISC 和 CISC 指令集 之前的文章《揭秘 CPU 是如何执行计算机指令的》中说到,如果从软件的角度来讲,CPU 就是一个执行各种计算机指令(Instruction Code)的逻辑机器。 计算机指令集是计算机指令的集合,包括各种类型的…...

【nnUNetv2进阶】十九、nnUNetv2 使用ResidualEncoder训练模型
nnunet使用及改进教程。 【nnUNetv2实践】一、nnUNetv2安装 【nnUNetv2实践】二、nnUNetv2快速入门-训练验证推理集成一条龙教程 【nnUNetv2进阶】三、nnUNetv2 自定义网络-发paper必会-CSDN博客 其他网络改进参考: 【nnUNetv2进阶】四、nnUNetv2 魔改网络-小试牛刀-加入…...

Unity3D ShaderGraph 场景扫描光效果实现详解
引言 在Unity3D游戏开发中,创建吸引人的视觉效果是提升游戏沉浸感的关键之一。场景扫描光效果,作为一种动态且富有表现力的视觉元素,能够为游戏场景增添不少亮点。通过Unity的ShaderGraph工具,我们可以轻松地实现这种效果&#x…...

JS中运算符优先级
优先级顺序从高到低为: 括号 ()成员访问 . 和 函数调用 ()一元运算符 !、、-、~乘法 *、除法 /、取余 %加法 、减法 -位移运算符 <<、>>、>>>比较运算符 <、<、>、>等于 、不等于 !、严格等于 、严格不等于 !位与 &位异或 ^位…...

分享6款有助于写论文能用到的软件app!
在学术写作中,选择合适的软件和工具可以大大提高效率和质量。以下是六款有助于写论文的软件app推荐,其中特别重点介绍千笔-AIPassPaPer这款AI原创论文写作平台。 1. 千笔-AIPassPaPer 千笔-AIPassPaPer是一款功能全面且高效的AI原创论文写作平台。它能…...

Python图形验证码的识别:一步步详解
在Web开发和自动化测试中,图形验证码的识别是一项常见且重要的任务。图形验证码作为防止自动化攻击的一种手段,通过随机生成包含字符或数字的图片来增加用户验证的难度。然而,对于需要自动化处理的场景,如Web自动化测试或爬虫&…...
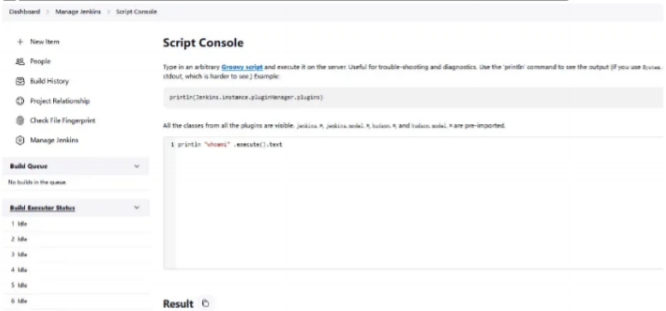
Jenkins未授权访问漏洞
Jenkins未授权访问漏洞 默认情况下 Jenkins面板中用户可以选择执行脚本界面来操作一些系统层命令,攻击者可通过未授权访问漏洞或者暴力破解用户密码等进入后台管理服务,通过脚本执行界面从而获取服务器权限。 一、使用以下fofa语法进行产品搜索 port&…...

什么情况下跑代码内存才会爆
内存爆掉(即内存溢出)通常是由于代码在处理数据或计算时消耗了过多的内存资源,导致系统内存不足。以下是一些常见场景和代码示例,可能会导致内存爆掉: 1. 超大数据集加载: 加载非常大的数据集到内存中(特…...

基于arcpro3.0.2运行报错问题:不能加载文件System.Text.Encoding.CodePages, Version=8.0.0.0
基于arcpro3.0.2运行报错问题:不能加载文件System.Text.Encoding.CodePages, Version8.0.0.0 报错问题描述: 基于arcpro3.0.2运行报错问题: Could not load file or assembly System.Text.Encoding.CodePages, Version8.0.0.0 解决办法: 重新拷贝打包生…...

elk+filebeat+kafka集群部署
实验框架图 192.168.124.10 es1 192.168.124.20 es2 192.168.124.30 losgtash kibana 192.168.124.50 MySQL nginx httpd 上一篇做完es1和es2以及192.168.124.30的部署 在192.168.124.50做配置部署 开启MySQL、nginx、http 因为nginx和http默认端口为80࿰…...

技术赋能音频自由:qmcdump开源工具破解QQ音乐加密格式全解析
技术赋能音频自由:qmcdump开源工具破解QQ音乐加密格式全解析 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump …...

PasteMD在技术文档整理中的应用:快速将接口说明转为标准Markdown
PasteMD在技术文档整理中的应用:快速将接口说明转为标准Markdown 1. 技术文档整理的痛点与解决方案 在日常开发工作中,技术文档的编写和维护往往是最容易被忽视却又至关重要的环节。特别是接口文档,它们通常以多种形式存在:代码…...

社区居家养老实训室设备配置与空间布局
社区居家养老实训室是衔接养老服务理论与实操的核心载体,其设备配置需贴合居家养老实际场景,空间布局需兼顾实操便利性与场景真实性,以下结合实操需求,分模块给出具体可落地的配置与布局方案,适配各类院校及培训机构建…...

Z-Image-Turbo镜像实战教程:开箱即用,9步生成高清图片
Z-Image-Turbo镜像实战教程:开箱即用,9步生成高清图片 1. 为什么选择Z-Image-Turbo镜像 如果你正在寻找一个能快速生成高质量图片的AI工具,Z-Image-Turbo镜像可能是目前最省心的选择。这个镜像最大的优势在于它已经预置了完整的32GB模型权重…...

Phi-3 Forest Lab应用场景:科研人员实验设计思路启发助手
Phi-3 Forest Lab应用场景:科研人员实验设计思路启发助手 1. 引言:当科研思路遇到“森林智者” 你有没有过这样的时刻?面对一个全新的研究课题,实验方案想了三天三夜,却总觉得思路打不开,或者陷入了某个细…...
)
WPF项目实战视频《四》(主要为项目实战API设计)
30.WPF项目实战(创建数据库)31.WPF项目实战(工作单元)32.WPF项目实战(待办事项接口)33.WPF项目实战(配置)34.WPF项目实战(备忘录接口)35.WPF项目实战…...

StructBERT语义分析工具实测:一键判断句子相似度,支持GPU加速
StructBERT语义分析工具实测:一键判断句子相似度,支持GPU加速 1. 工具核心价值 StructBERT语义分析工具是一款专为中文文本设计的本地化语义相似度计算解决方案。不同于传统的关键词匹配方法,该工具基于阿里巴巴开源的StructBERT-Large模型…...

技术赋能B端拓客:号码核验行业的迭代与价值升级,氪迹科技法人股东号码核验筛选,阶梯式价格
2026年,B端市场竞争日趋激烈,拓客逻辑已从“规模扩张”转向“价值深耕”,“精准、高效、低成本”成为所有拓客团队的核心追求。号码核验作为B端拓客的前置基础性环节,其服务质量直接决定线索价值、人力效能与投入回报比࿰…...

MiniCPM-o-4.5-nvidia-FlagOS开源镜像:FlagOS软件栈赋能的NVIDIA GPU原生推理方案
MiniCPM-o-4.5-nvidia-FlagOS开源镜像:FlagOS软件栈赋能的NVIDIA GPU原生推理方案 想快速体验一个能看懂图片、还能跟你聊天的AI助手吗?今天要介绍的MiniCPM-o-4.5-nvidia-FlagOS开源镜像,就是一个开箱即用的多模态AI解决方案。它基于FlagOS…...

OpenClaw节日营销助手:gemma-3-12b-it自动生成祝福语与发送邮件
OpenClaw节日营销助手:gemma-3-12b-it自动生成祝福语与发送邮件 1. 为什么需要节日营销自动化? 去年端午节前夜,我盯着电脑屏幕上的200多个客户邮箱地址发呆。每个客户都需要个性化的节日祝福,但手动编写和发送至少需要6小时。当…...