队列实现及leetcode相关OJ题
上一篇写的是栈这一篇分享队列实现及其与队列相关OJ题
文章目录
- 一、队列概念及实现
- 二、队列源码
- 三、leetcode相关OJ
一、队列概念及实现
1、队列概念
队列同栈一样也是一种特殊的数据结构,遵循
先进先出的原则,例如:想象在独木桥上走着的人,先上去的人定是先从独木桥上下来,为啥说是特殊呢?因为它只允许在对尾插入数据(简称入队,然后在对头删除数据(简称出队),只允许在这两端进行插入和删除操作
而基于它的特性选择链表实现还是数组实现更好呢?
当然选链表实现比较好,因为数组在头删除时需要移动大量的数据,时间复杂度为O(N),而用链表头删时间复杂度为O(1),那么有人会说那链表的尾插时间复杂度不也是O(N)吗,因为每次都要找尾节点
其实可以创建两个指针,一个指向对头,一个指向队尾,这样就不用每次都找尾了,时间复杂度也是O(1)。由于是多个数据,选择用结构体将其封装起来,而我们在链表每次访问长度的时候时间复杂度都为O(N),因此再在这个队列结构体中定义一个size表示队列大小
队列结构定义
typedef int QDataType;
typedef struct QNode
{struct QNode* next;QDataType data;
}QNode;
队列中的元素是每个节点,而每个节点又有多个数据存放下一个节点地址的next,存放每个节点数据的data,相当于队列里面它的成员又是一个结构体然后还有表示队列大小的size
typedef struct Queue
{//Queue结构体中成员又包含结构体QNode* head;//头指针指向头节点QNode* tail;//尾指针指向尾节点int size;//队列中节点的个数
}Queue;
队列实现
队列初始化
void QInit(Queue* pq)
{
// 传过来的时候就怕传一个空地址过来,那么队列都没有还怎么对其操作assert(pq);pq->head = pq->tail = NULL;//pq->size = 0;
}
队列销毁
void QDestroy(Queue* pq)
{assert(pq);assert(pq->head!=NULL);//对都为空那么就不用再释放了while (pq->head){QNode* next = pq->head->next;free(pq->head);pq->head = next;}pq->head = pq->tail = NULL;pq->size = 0;
}
入队
void QPush(Queue* pq, QDataType x)
{assert(pq);//先创建一个队列里面元素的节点,QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail\n");return;}newnode->data = x;newnode->next = NULL;//如果队列为空时,那么就直接将节点插入进来即可if (pq->head == NULL){pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = pq->tail->next;}//入队之后队列长度就要增一pq->size++;
}出队
void QPop(Queue* pq)
{assert(pq);assert(pq->head != NULL);//队列不空才出队//队列中只有一个元素的时候,这时也就是对头指针和队尾指针指向同一个节点if (pq->tail == pq->head){free(pq->head);pq->head = pq->tail = NULL;}//找到头节点的下一个节点else{QNode* next = pq->head->next;free(pq->head);pq->head = next;}//出队之后队列长度会减一pq->size--;
}
判空
bool QEmpty(Queue* pq)
{assert(pq);return pq->head == NULL;//直接返回对头指针,对头指针为空的话队列即为空
}取对头元素
QDataType QFront(Queue* pq)
{assert(pq);assert(pq->head);return pq->head->data;
}
取队尾元素
QDataType QTail(Queue* pq)
{assert(pq);assert(pq->head);return pq->tail->data;
}
获取队列长度
int QSize(Queue* pq)
{assert(pq);assert(pq->head);//由于size直接获得队列大小,因此直接返回size即可return pq->size;
}
二、队列源码
Queue.h
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>typedef int QDataType;
typedef struct QNode
{struct QNode* next;QDataType data;
}QNode;typedef struct Queue
{//Queue结构体中成员又包含结构体QNode* head;//头指针QNode* tail;int size;//队列中节点的个数
}Queue;
//初始化
void QInit(Queue* pq);
//销毁队列
void QDestroy(Queue* pq);
//入队
void QPush(Queue* pq, QDataType x);
//出队
void QPop(Queue* pq);
//判空
bool QEmpty(Queue* pq);
//获取对头
QDataType QFront(Queue* pq);
//队大小
int QSize(Queue* pq);
//返回队尾元素
QDataType QTail(Queue* pq);queue.c
void QInit(Queue* pq)
{
// 传过来的时候就怕传一个空地址过来,那么队列都没有还怎么对其操作assert(pq);pq->head = pq->tail = NULL;//pq->size = 0;
}
void QDestroy(Queue* pq)
{assert(pq);//assert(pq->head!=NULL);//对头都为空那么就不用再释放了while (pq->head){QNode* next = pq->head->next;free(pq->head);pq->head = next;}pq->head = pq->tail = NULL;pq->size = 0;
}void QPush(Queue* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail\n");return;}newnode->data = x;newnode->next = NULL;if (pq->head == NULL){pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = pq->tail->next;}pq->size++;
}void QPop(Queue* pq)
{assert(pq);assert(pq->head != NULL);if (pq->tail == pq->head){free(pq->head);pq->head = NULL;}else{QNode* next = pq->head->next;free(pq->head);pq->head = next;}pq->size--;
}bool QEmpty(Queue* pq)
{assert(pq);return pq->head == NULL;
}QDataType QFront(Queue* pq)
{assert(pq);assert(pq->head);return pq->head->data;
}int QSize(Queue* pq)
{assert(pq);assert(pq->head);return pq->size;
}QDataType QTail(Queue* pq)
{assert(pq);assert(pq->head);return pq->tail->data;
}test.c
#include"Queue.h"int main()
{Queue pq;QInit(&pq);QPush(&pq, 1);QPush(&pq, 2);QPush(&pq, 3);QPush(&pq, 4);/*while (!QEmpty(&pq)){printf("%d ", QFront(&pq));QPop(&pq);}*/printf("%d ", QTail(&pq));printf("%d ", QSize(&pq));QDestroy(&pq);return 0;
}
三、leetcode相关OJ
1、用队列实现栈

由于队列是先进先出,栈是先进后出
具体思想那么要用队列来实现栈就要保证最先进栈的要最后出栈,可是队列又是先进先出,要保证队列最后一个先出去的话,那么让那个不为空的队列其队尾为止前面的元素依次倒入另外一个队列中,然后取出这个数据那个那么就用两个队列才能完成
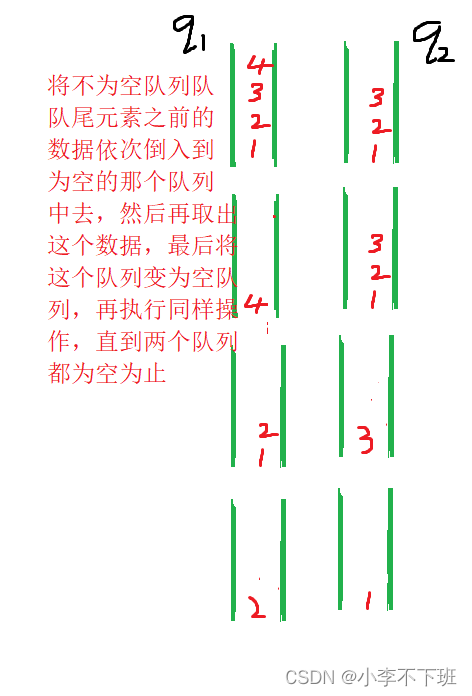
而队列就是我上面写的咯
QDataType QTail(Queue* pq)
{assert(pq);assert(pq->head);return pq->tail->data;
}
//栈里有两个队列
typedef struct {Queue q1;Queue q2;
} MyStack;//创建这个栈是要返回栈的地址的
//那么就malloc一个栈出来
//如果不向内存动态申请一个栈而是直接创建一个栈,那么创建的栈就是一个临时变量,它出了这个函数空间就会自动
MyStack* myStackCreate() {MyStack*st = (MyStack*)malloc(sizeof(MyStack));if(st == NULL){perror("malloc fail\n");return NULL;}else{//创建栈之后需要将栈结构体成员中的连个队列也初始化而这个队列又是一个结构体,且要改变队列内容就需传结构体地址传过去//st是栈的结构体指针村的是栈的地址,对->访问它的成员,得到队列q1,q2,由于是用队列实现栈所以操作其实都是队列实现的,相当于操作的是队列,然后&st->q1就是传队列地址QInit(&st->q1);QInit(&st->q2);return st;}
}//入栈是往队列不为空的那个里面入,
//最开始两个队列都是空就随便入一个,但是后面再入栈时就要往不为空的那个队列里面入数据。
void myStackPush(MyStack* obj, int x) {if(!QEmpty(&obj->q1)){QPush(&obj->q1,x);}else{QPush(&obj->q2,x);}
}//栈是一个后进先出的特殊数据结构,且每次要出数据只能从栈顶出
//而队列是一种先进先出的特殊数据结构,且出数据只能在对头出,而我们要用对列来实现这个栈,我们只有将不为空的 那个队列中队尾元素之前的元素倒入那个为空的队列中,然后将原来那个不为空队列的队尾元素保存下来,最后将其出掉,然后如果再次调用出栈这个函数接口,那么也是一样的操作
//这里出队不是将那些元素丢掉,而是将这些出队元素入到原本为空的那个队列中
//
int myStackPop(MyStack* obj) {Queue*empty = &obj->q1;//这里先默认q1为空队列Queue*nonempty = &obj->q2;if(!QEmpty(&obj->q1))//然后再判断队列q1是否为空,队列q1如果不为空,那么队列q2就是空咯{empty = &obj->q2;nonempty = &obj->q1;}//将不为空的队列nonempty中对头元素先入到原来为空的队列empty中去,然后再将对头元素出掉,出到只剩下一个元素为止while(QSize(nonempty)>1){//将要出的数据反手就入到empty空的队列中去QPush(empty,QFront(nonempty));//然后再出数据QPop(nonempty);}int top = QFront(nonempty);QPop(nonempty);return top;}//返回栈顶元素,其实就是返回不为空队列nonempty这个队尾数据
int myStackTop(MyStack* obj) {Queue*empty = &obj->q1;Queue*nonempty = &obj->q2;if(!QEmpty(&obj->q1)){empty = &obj->q2;nonempty = &obj->q1;}return QTail(nonempty);
}//判断栈是否为空就是判断两个队列中是否还有元素,其中一个还有都不为空
bool myStackEmpty(MyStack* obj) {return QEmpty(&obj->q1) &&QEmpty(&obj->q2);
}//销毁栈不嫩一下子就将栈释放了,因为如果一下子就将栈释放了的话,你是释放了你这个栈里面的成员q1,q2,但是人家q1,q2里安他自己还有数据啊,这样造成了内存泄漏不得行
//而是一个先销毁队列中的数据然后再释放栈void myStackFree(MyStack* obj) {QDestroy(&obj->q1);QDestroy(&obj->q2);free(obj);
}2、leetcode用栈实现队列

思想:用两个栈实现,一个栈进行入队操作,另一个栈进行出队操作 出队操作:当出队的栈不为空是,直接进行出栈操作,如果为空,需要把入队的栈元素全部导入到出队的栈,然后再进行出栈操作
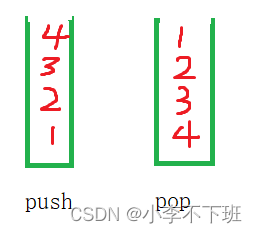
//由于栈最先进去的数据要最后才能获得 //假设1,2,3,4是按顺序依次入队那么它的出队顺序也是1,2,3,4
//要用栈来实现队列那么就要让原来的数据以逆序4,3
,2,1的方式存储到栈中然后每次出栈顶的数据就可以实现队列的先进先出,而一个栈明显行不通,这时让一个栈用来实现入队,栈push用来模拟入队,那么进栈也就是1,2,3,4,将从push栈依次得到的数据倒入pop栈中,pop栈中进栈就是4,3,2,1那么从栈pop中拿到的数据也就是同进队时的顺序一样的1,2,3,4,在push栈向pop栈中倒数据时要保证pop栈为空方可倒不然如果pop栈里还有元素4,这时又从push栈中倒数据5,那么这个4就要在5后面出队,这就不符合对的先进先出了;
代码实现
typedef int STDataType;
typedef struct STNode
{STDataType* a;int top;int capacity;
}ST;
void StackInit(ST* st)
{assert(st);st->a = (STDataType*)malloc(sizeof(STDataType)*4);if (st->a == NULL){printf("malloc fail\n");exit(-1);}st->capacity = 4;st->top = 0;
}
//销毁
void StackDestory(ST* st)
{assert(st);free(st->a);st->a = NULL;st->top = st->capacity = 0;
}
//进栈
void StackPush(ST* st, STDataType x)
{assert(st);if (st->top == st->capacity){STDataType* tmp = (STDataType*)realloc(st->a,st->capacity*2*(sizeof(STDataType) ));if (tmp == NULL){printf("realloc fail\n");exit(-1);}else{st->a = tmp;st->capacity *= 2;}}st->a[st->top] = x;st->top++;
}
//出栈
void StackPop(ST* st)
{assert(st);assert(st->top > 0);st->top--;
}
//判空
bool StackEmpty(ST* st)
{assert(st);return st->top == 0;
}
//获取栈顶元素
STDataType StackTop(ST* st)
{assert(st);assert(st->top > 0);return st->a[st->top-1];
}
//获取栈的大小
int StackSize(ST* st)
{assert(st);return st->top;
}//栈的结构体定义
//先定义两个栈出来
//和用对列实现栈类似typedef struct {//push栈用来模拟入队//pop栈用来模拟出队ST push;ST pop;
} MyQueue;//这里也和用队列实现栈类似
MyQueue* myQueueCreate() {MyQueue*pq = (MyQueue*)malloc(sizeof(MyQueue));if(pq == NULL){perror("malloc fail");return NULL;}StackInit(&pq->push);StackInit(&pq->pop);return pq;
}//队列是先进先出的特殊数据结构
//栈是先进后出,并且在栈顶插入和删除//直接往push中入数据,不用管push是否为空
void myQueuePush(MyQueue* obj, int x) {StackPush(&obj->push,x);
}//导入数据时注意pop栈为空才倒
int myQueuePop(MyQueue* obj) {if(StackEmpty(&obj->pop)){while(!StackEmpty(&obj->push)){StackPush(&obj->pop,StackTop(&obj->push));StackPop(&obj->push);}}int front = StackTop(&obj->pop);StackPop(&obj->pop);return front;
}//每次返回pop栈顶元素就是对头元素
int myQueuePeek(MyQueue* obj) {if(StackEmpty(&obj->pop)){while(!StackEmpty(&obj->push)){StackPush(&obj->pop,StackTop(&obj->push));StackPop(&obj->push);}}return StackTop(&obj->pop);
}//两个栈为空队列才为空
bool myQueueEmpty(MyQueue* obj) {return StackEmpty(&obj->push) && StackEmpty(&obj->pop);
}//先销毁栈再释放队列
void myQueueFree(MyQueue* obj) {StackDestory(&obj->pop);StackDestory(&obj->push);free(obj);
}由于这时用C语言实现的需要自己手写一个栈。
队列是一种特殊的数据结构,在后面学习二叉树还会用到,因此还是要将其掌握熟练
相关文章:
队列实现及leetcode相关OJ题
上一篇写的是栈这一篇分享队列实现及其与队列相关OJ题 文章目录一、队列概念及实现二、队列源码三、leetcode相关OJ一、队列概念及实现 1、队列概念 队列同栈一样也是一种特殊的数据结构,遵循先进先出的原则,例如:想象在独木桥上走着的人&am…...
【Log4j2远程命令执行复现CVE-2021-12-09】
目录 一、前言 二、漏洞环境构建 三、复现过程 一、前言 Log4j2是基于log4j这个java日志处理组件进行二次开发和改进而来的。也是目前最常用的日志框架之一,在之前的博客中(http://t.csdn.cn/z9um4)我们阐述了漏洞的原理和大致的利用方…...
Jenkins 平台搭建 | 为 Jenkins 配置 nginx 反向代理
以 Centos7 系统为例,详细记录一下 Jenkins 搭建流程。 参考官网:https://www.jenkins.io/doc/book/installing/linux/#red-hat-centos Install Jenkins 从 redhat-stable yum 存储库中安装 LTS(长期支持) 版本,该版…...

【云原生】Docker 架构及工作原理
一、Docker 概述二、Client 客户端三、Docker 引擎四、Image 镜像五、Container 容器六、镜像分层可写的容器层七、Volume 数据卷八、Registry 注册中心九、总结一、Docker 概述 Docker 是一个开发、发布和运行应用程序的开放平台。Docker使您能够将应用程序与基础架构分离&am…...
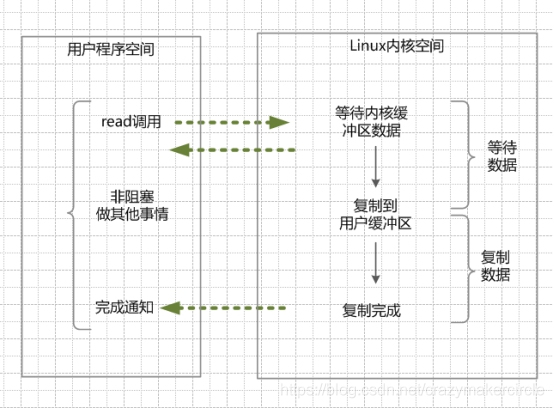
【Java 】Java NIO 底层原理
文章目录1、 Java IO读写原理1.1 内核缓冲与进程缓冲区1.2 java IO读写的底层流程2、 四种主要的IO模型3、 同步阻塞IO(Blocking IO)4、 同步非阻塞NIO(None Blocking IO)5、 IO多路复用模型(I/O multiplexing)6、 异步…...

Vue基础27之VueUI组件
Vue基础27Vue UI组件库移动端常用 UI 组件库PC 端常用 UI 组件库Element-ui插件基本使用安装引入并使用main.jsApp.vue按需引入安装 babel-plugin-componentbabel.config.jsmain.jsApp.vueVue UI组件库 移动端常用 UI 组件库 Vant https://youzan.github.io/vant Cube UI htt…...

第35篇:Java代码规范全面总结
编程规范目的是帮助我们编写出简洁、可维护、可靠、可测试、高效、可移植的代码,提高产品代码的质量。 适当的规范和标准绝不是消灭代码内容的创造性、优雅性,而是限制过度个性化, 以一种普遍认可的统一方式一起做事,提升协作效率,降低沟通成本。 代码的字里行间流淌的是软…...

Cookie和Session详解
目录 前言: Session详解 Cookie和Session区别和关联 服务器组织会话的方式 使用Tomcat实现登录成功跳转到欢迎页面 登录前端页面 登录成功后端服务器 重定向到欢迎页面 抓包分析交互过程 小结: 前言: Cookie之前博客有介绍过&#x…...
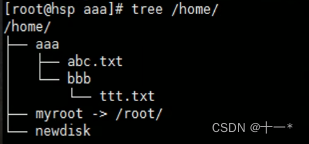
Linux之磁盘分区、挂载
文章目录一、Linux分区●原理介绍●硬盘说明查看所有设备挂载情况挂载的经典案例二、磁盘情况查询基本语法应用实例磁盘情况-工作实用指令一、Linux分区 ●原理介绍 Linux来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,…...
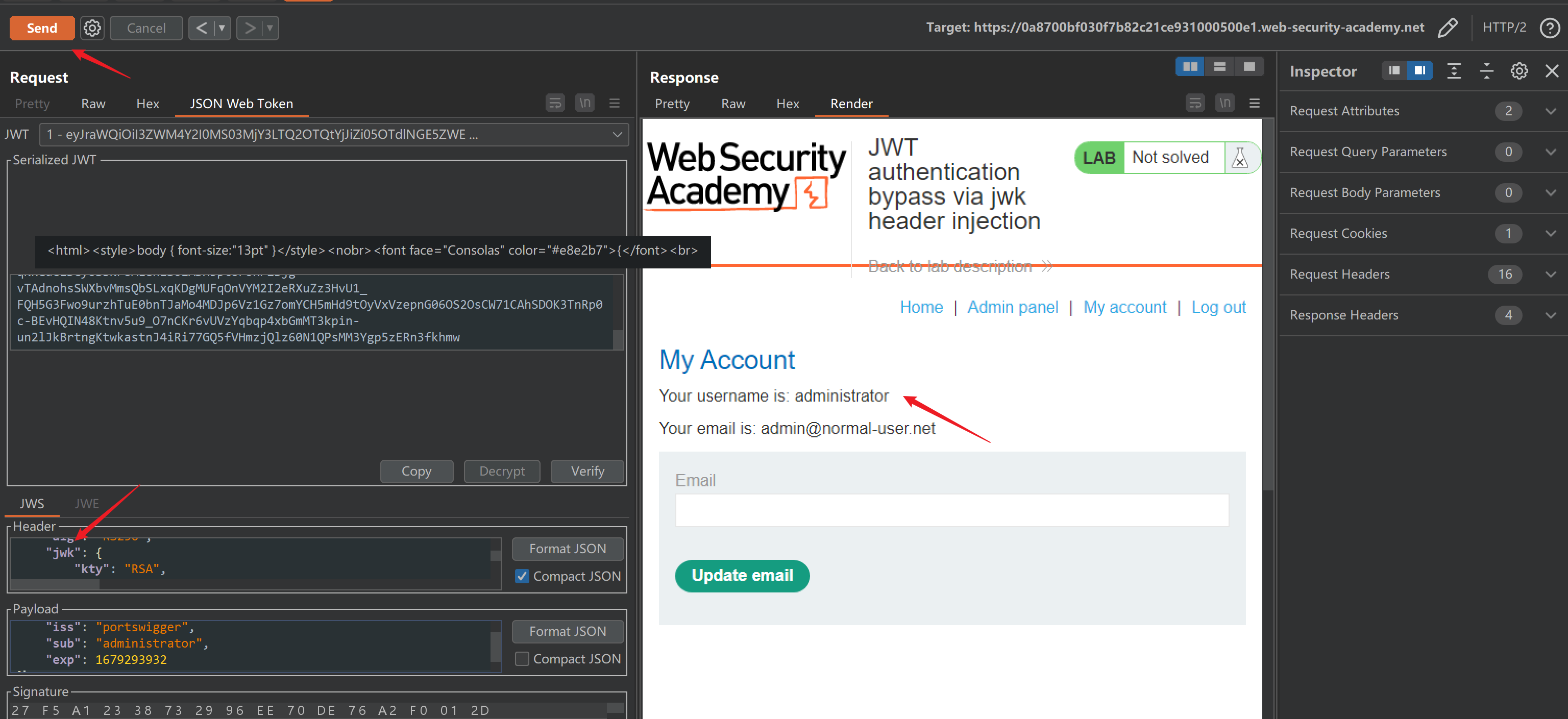
web渗透之jwt 安全问题
前言JWT 全称 JSON Web Token,是一种标准化格式,用于在系统之间发送加密签名的 JSON 数据。原始的 Token 只是一个 uuid,没有任何意义。JWT 包含了部分业务信息,减少了 Token 验证等交互操作,效率更高JWT组成JWT 由三部…...

好用的5款国产低代码平台介绍
一、云程低代码平台 云程低代码平台是一款基于springboot、vue.js技术的企业级低代码开发平台,平台采用模型驱动、高低码融合、开放扩展等设计理念,基于业务建模、流程建模、表单建模、报表建模、大屏建模等可视化建模工具,通过拖拉拽零代码方…...

【前端学习记录】webpack学习之mini-css-extract-plugin插件
前言 最近在学习尚硅谷的webpack5课程,看到mini-css-extract-plugin这个插件的时候,感觉很有帮助,之前都没有在css这方面深入思考过,课程中的一些记录写在下面 为什么需要优化CSS Css 文件目前被打包到 js 文件中,当…...

FPGA基于RIFFA实现PCIE采集HDMI传输,提供工程源码和QT上位机
目录1、前言2、RIFFA理论基础3、设计思路和架构4、vivado工程详解5、上板调试验证并演示6、福利:工程代码的获取1、前言 PCIE是目前速率很高的外部板卡与CPU通信的方案之一,广泛应用于电脑主板与外部板卡的通讯,PCIE协议极其复杂,…...

SpringBoot解析指定Yaml配置文件
再来个文章目录 文章目录前言1、自定义配置文件2、配置对象类3、YamlPropertiesSourceFactory下面还有投票,帮忙投个票👍 前言 最近在看某个开源项目代码并准备参与其中,代码过了一遍后发现多个自定义的配置文件用来装载业务配置代替数据库…...
C++基础算法③——排序算法(选择、冒泡附完整代码)
排序算法 1、选择排序 2、冒泡排序 1、选择排序 基本思想:从头至尾扫描序列,每一趟从待排序元素中找出最小(最大)的一个元素值,然后与第一个元素交换值,接着从剩下的元素中继续这种选择和交换方式,最终得到一个有序…...

《高质量C/C++编程》读书笔记一
前言 这本书是林锐博士写的关于C/C编程规范的一本书,我打算写下一系列读书笔记,当然我并不打算全盘接收这本书中的内容。 良好的编程习惯,规范的编程风格可以提高代码的正确性、健壮性、可靠性、效率、易用性、可读性、可扩展性、可复用性…...

【完美解决】python flask如何直接加载html,css,js,image等下载的网页模板
python flask如何直接加载下载的网页模板问题解决办法问题 本人网页开发小白,刚学了用flask,下载了一套网页模板,启动一个网页的确很简单,但是发现无论怎么改这里的 static_folder值都无法找到CSS,JS,IMAGE,FONT等资源 app Flas…...
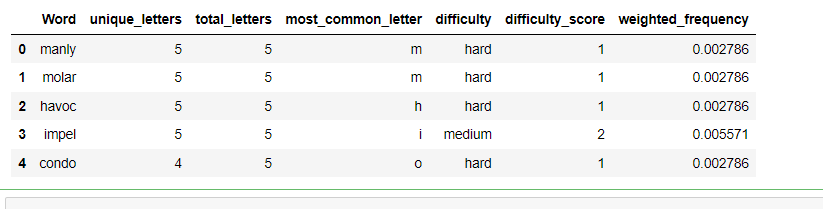
2023美赛C题【分析思路+代码】
以下内容为我个人的想法与实现,不代表任何其他人。 文章目录问题一数据预处理时间序列模型创建预测区间单词的任何属性是否影响报告的百分比?如果是,如何影响?如果不是,为什么不是?问题二问题三难度评估模型…...

考研复试6 编译原理
第一章 编译器简介 1. 编译器的核心功能 把源代码翻译成目标代码 2. 编译器设计两个原则: 语义相同;以某种可察觉的方式改进输入程序 3. 编译器内部结构 前端:依赖于源语言,与目标机器无关。将输入的代码映射到 IR。包括分析部…...
uni-app:登录与支付--用户信息
用户信息 实现用户头像昵称区域的基本布局 在 my-userinfo 组件中,定义如下的 UI 结构: <template><view class"my-userinfo-container"><!-- 头像昵称区域 --><view class"top-box"><image src"…...

深度解析Node.js iCalendar生成器:企业级日历事件架构设计
深度解析Node.js iCalendar生成器:企业级日历事件架构设计 【免费下载链接】ics iCalendar (ics) file generator for node.js 项目地址: https://gitcode.com/gh_mirrors/ic/ics 在现代化的企业应用和分布式系统中,日历事件的标准化生成与管理已…...

Nano Banana进阶指南:从动漫角色到真人手办场景的AI创意融合
1. Nano Banana创意工作流全解析 第一次接触Nano Banana时,我就被它强大的图像生成能力震撼了。但真正让我着迷的,是它能够将动漫角色、真人cosplay和手办场景这三个看似独立的元素完美融合的能力。这种"三位一体"的创作方式,不仅打…...
)
新手避坑指南:在Ubuntu 20.04 ROS Noetic下搞定宇树Z1机械臂Gazebo仿真(附依赖安装全流程)
宇树Z1机械臂ROS仿真全流程避坑指南:从零搭建到Gazebo控制 第一次在Ubuntu 20.04上配置宇树Z1机械臂的ROS Noetic仿真环境时,我几乎踩遍了所有可能的坑——依赖版本冲突、编译报错、环境变量配置错误...如果你也在经历类似的痛苦,别担心&…...

5分钟终极指南:Windows虚拟手柄驱动ViGEmBus完整教程
5分钟终极指南:Windows虚拟手柄驱动ViGEmBus完整教程 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows系统上享受专业级的游戏控制体…...
)
企业财务系统集成指南:如何用诺诺开放平台API搞定电子发票全流程(从签约到开票)
企业财务系统集成指南:诺诺开放平台电子发票全流程实战 当财务数字化转型成为企业降本增效的刚需,电子发票作为交易闭环的关键环节,其系统集成质量直接影响业务流畅度。本文将带您全景式拆解从商务对接到技术落地的完整链路,避开那…...

Apache Flink Agents 0.2.1 发布公告
Apache Flink 社区很高兴地宣布发布 Apache Flink Agents 0.2 系列的首个缺陷修复版本。 此版本包含 3 项缺陷和漏洞修复以及一些对Flink-Agents 0.2的小幅改进。下面列出了所有缺陷修复和改进内容(不包括构建基础设施和构建稳定性方面的改进)。如需查看…...

DeTikZify:AI驱动的科研图表代码自动化解决方案
DeTikZify:AI驱动的科研图表代码自动化解决方案 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 一、科研绘图的隐形痛点:我…...

等保三级Java安全改造全周期实录,从代码审计到渗透验证的12个生死关卡
第一章:等保三级Java安全改造的合规基线与生命周期全景图等保三级对Java应用提出了覆盖身份鉴别、访问控制、安全审计、通信保密性、代码安全及可信执行环境的全维度要求。其合规基线并非静态清单,而是贯穿需求分析、设计开发、测试验证、上线部署与持续…...

PyTorch 2.8镜像高算力适配:10核CPU调度策略优化,避免I/O瓶颈拖慢训练
PyTorch 2.8镜像高算力适配:10核CPU调度策略优化,避免I/O瓶颈拖慢训练 1. 镜像核心优势与硬件适配 PyTorch 2.8深度学习镜像经过深度优化,专为高性能计算场景设计。这个环境最显著的特点是完美适配了10核CPU与RTX 4090D显卡的协同工作&…...

Qwen3.5-9B-AWQ-4bit参数调优实战:温度=0.7时中文回答质量与响应速度平衡点
Qwen3.5-9B-AWQ-4bit参数调优实战:温度0.7时中文回答质量与响应速度平衡点 1. 模型概述与参数调优背景 Qwen3.5-9B-AWQ-4bit是一个支持图像理解的多模态模型,能够结合上传图片与文字提示词输出中文分析结果。在实际应用中,我们发现温度参数…...