最新口型同步技术EchoMimic部署
EchoMimic是由蚂蚁集团推出的一个 AI 驱动的口型同步技术项目,能够通过人像面部特征和音频来帮助人物“对口型”,生成逼真的动态肖像视频。
EchoMimic的技术亮点在于其创新的动画生成方法,它不仅能够通过音频和面部关键点单独驱动图像动画,还能结合这两种方式,通过音频信号和面部关键点的组合来生成逼真的“说话的头部”视频。
EchoMimic支持单独使用音频或面部标志点生成肖像视频,也支持将音频和人像照片相结合,实现更自然、流畅的对口型效果。
EchoMimic支持多语言,包括中文普通话、英语,以及适应唱歌等场景。
github项目地址:https://github.com/BadToBest/EchoMimic。
一、环境安装
1、python环境
建议安装python版本在3.10以上。
2、pip库安装
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3、模型下载:
git lfs install
git clone https://huggingface.co/BadToBest/EchoMimic
二、功能测试
1、运行测试:
(1)python代码调用测试audio2video
import argparse
import os
import random
import platform
import subprocess
from datetime import datetime
from pathlib import Pathimport cv2
import numpy as np
import torch
from diffusers import AutoencoderKL, DDIMScheduler
from omegaconf import OmegaConf
from PIL import Imagefrom src.models.unet_2d_condition import UNet2DConditionModel
from src.models.unet_3d_echo import EchoUNet3DConditionModel
from src.models.whisper.audio2feature import load_audio_model
from src.pipelines.pipeline_echo_mimic import Audio2VideoPipeline
from src.utils.util import save_videos_grid, crop_and_pad
from src.models.face_locator import FaceLocator
from moviepy.editor import VideoFileClip, AudioFileClip
from facenet_pytorch import MTCNN# Check and add FFmpeg path if necessary
ffmpeg_path = os.getenv('FFMPEG_PATH')
if ffmpeg_path is None and platform.system() in ['Linux', 'Darwin']:try:result = subprocess.run(['which', 'ffmpeg'], capture_output=True, text=True)if result.returncode == 0:ffmpeg_path = result.stdout.strip()print(f"FFmpeg is installed at: {ffmpeg_path}")else:print("FFmpeg is not installed. Please download ffmpeg-static and export to FFMPEG_PATH.")print("For example: export FFMPEG_PATH=/musetalk/ffmpeg-4.4-amd64-static")except Exception as e:print(f"Error finding ffmpeg: {e}")
else:if ffmpeg_path and ffmpeg_path not in os.getenv('PATH'):print("Adding FFMPEG_PATH to PATH")os.environ["PATH"] = f"{ffmpeg_path}:{os.environ['PATH']}"def parse_args():parser = argparse.ArgumentParser()parser.add_argument("--config", type=str, default="./configs/prompts/animation.yaml")parser.add_argument("-W", type=int, default=512)parser.add_argument("-H", type=int, default=512)parser.add_argument("-L", type=int, default=1200)parser.add_argument("--seed", type=int, default=420)parser.add_argument("--facemusk_dilation_ratio", type=float, default=0.1)parser.add_argument("--facecrop_dilation_ratio", type=float, default=0.5)parser.add_argument("--context_frames", type=int, default=12)parser.add_argument("--context_overlap", type=int, default=3)parser.add_argument("--cfg", type=float, default=2.5)parser.add_argument("--steps", type=int, default=30)parser.add_argument("--sample_rate", type=int, default=16000)parser.add_argument("--fps", type=int, default=24)parser.add_argument("--device", type=str, default="cuda")return parser.parse_args()def select_face(det_bboxes, probs):"""Select the largest face with a detection probability above 0.8."""if det_bboxes is None or probs is None:return Nonefiltered_bboxes = [det_bboxes[i] for i in range(len(det_bboxes)) if probs[i] > 0.8]if not filtered_bboxes:return Nonereturn max(filtered_bboxes, key=lambda x: (x[3] - x[1]) * (x[2] - x[0]))def main():args = parse_args()config = OmegaConf.load(args.config)weight_dtype = torch.float16 if config.weight_dtype == "fp16" else torch.float32device = args.deviceif "cuda" in device and not torch.cuda.is_available():device = "cpu"infer_config = OmegaConf.load(config.inference_config)############# Initialize models #############vae = AutoencoderKL.from_pretrained(config.pretrained_vae_path).to("cuda", dtype=weight_dtype)reference_unet = UNet2DConditionModel.from_pretrained(config.pretrained_base_model_path, subfolder="unet").to(dtype=weight_dtype, device=device)reference_unet.load_state_dict(torch.load(config.reference_unet_path, map_location="cpu"))unet_kwargs = infer_config.unet_additional_kwargs or {}denoising_unet = EchoUNet3DConditionModel.from_pretrained_2d(config.pretrained_base_model_path,config.motion_module_path if os.path.exists(config.motion_module_path) else "",subfolder="unet",unet_additional_kwargs=unet_kwargs).to(dtype=weight_dtype, device=device)denoising_unet.load_state_dict(torch.load(config.denoising_unet_path, map_location="cpu"), strict=False)face_locator = FaceLocator(320, conditioning_channels=1, block_out_channels=(16, 32, 96, 256)).to(dtype=weight_dtype, device="cuda")face_locator.load_state_dict(torch.load(config.face_locator_path))audio_processor = load_audio_model(model_path=config.audio_model_path, device=device)face_detector = MTCNN(image_size=320, margin=0, min_face_size=20, thresholds=[0.6, 0.7, 0.7], factor=0.709, post_process=True, device=device)############# Initiate pipeline #############scheduler = DDIMScheduler(**OmegaConf.to_container(infer_config.noise_scheduler_kwargs))pipe = Audio2VideoPipeline(vae=vae,reference_unet=reference_unet,denoising_unet=denoising_unet,audio_guider=audio_processor,face_locator=face_locator,scheduler=scheduler,).to("cuda", dtype=weight_dtype)date_str = datetime.now().strftime("%Y%m%d")time_str = datetime.now().strftime("%H%M")save_dir_name = f"{time_str}--seed_{args.seed}-{args.W}x{args.H}"save_dir = Path(f"output/{date_str}/{save_dir_name}")save_dir.mkdir(exist_ok=True, parents=True)for ref_image_path, audio_paths in config["test_cases"].items():for audio_path in audio_paths:seed = args.seed if args.seed is not None and args.seed > -1 else random.randint(100, 1000000)generator = torch.manual_seed(seed)ref_name = Path(ref_image_path).stemaudio_name = Path(audio_path).stemfinal_fps = args.fps#### Prepare face maskface_img = cv2.imread(ref_image_path)face_mask = np.zeros((face_img.shape[0], face_img.shape[1]), dtype='uint8')det_bboxes, probs = face_detector.detect(face_img)select_bbox = select_face(det_bboxes, probs)if select_bbox is None:face_mask[:, :] = 255else:xyxy = np.round(select_bbox[:4]).astype('int')rb, re, cb, ce = xyxy[1], xyxy[3], xyxy[0], xyxy[2]r_pad = int((re - rb) * args.facemusk_dilation_ratio)c_pad = int((ce - cb) * args.facemusk_dilation_ratio)face_mask[rb - r_pad : re + r_pad, cb - c_pad : ce + c_pad] = 255r_pad_crop = int((re - rb) * args.facecrop_dilation_ratio)c_pad_crop = int((ce - cb) * args.facecrop_dilation_ratio)crop_rect = [max(0, cb - c_pad_crop), max(0, rb - r_pad_crop), min(ce + c_pad_crop, face_img.shape[1]), min(re + r_pad_crop, face_img.shape[0])]face_img = crop_and_pad(face_img, crop_rect)face_mask = crop_and_pad(face_mask, crop_rect)face_img = cv2.resize(face_img, (args.W, args.H))face_mask = cv2.resize(face_mask, (args.W, args.H))ref_image_pil = Image.fromarray(face_img[:, :, [2, 1, 0]])face_mask_tensor = torch.Tensor(face_mask).to(dtype=weight_dtype, device="cuda").unsqueeze(0).unsqueeze(0).unsqueeze(0) / 255.0video = pipe(ref_image_pil,audio_path,face_mask_tensor,width=args.W,height=args.H,duration=args.L,num_inference_steps=args.steps,cfg_scale=args.cfg,generator=generator,audio_sample_rate=args.sample_rate,context_frames=args.context_frames,fps=final_fps,context_overlap=args.context_overlap).videosvideo_save_path = save_dir / f"{ref_name}_{audio_name}_{args.H}x{args.W}_{int(args.cfg)}_{time_str}.mp4"save_videos_grid(video, str(video_save_path), n_rows=1, fps=final_fps)# Add audio to generated videowith_audio_path = save_dir / f"{ref_name}_{audio_name}_{args.H}x{args.W}_{int(args.cfg)}_{time_str}_withaudio.mp4"video_clip = VideoFileClip(str(video_save_path))audio_clip = AudioFileClip(audio_path)final_video = video_clip.set_audio(audio_clip)final_video.write_videofile(str(with_audio_path), codec="libx264", audio_codec="aac")print(f"Saved video with audio to {with_audio_path}")if __name__ == "__main__":main()(2)python代码调用测试audio2pose
未完......
更多详细的内容欢迎关注:杰哥新技术

相关文章:
最新口型同步技术EchoMimic部署
EchoMimic是由蚂蚁集团推出的一个 AI 驱动的口型同步技术项目,能够通过人像面部特征和音频来帮助人物“对口型”,生成逼真的动态肖像视频。 EchoMimic的技术亮点在于其创新的动画生成方法,它不仅能够通过音频和面部关键点单独驱动图像动画&a…...

程序设计基础(c语言)_补充_1
1、编程应用双层循环输出九九乘法表 #include <stdio.h> #include <stdlib.h> int main() {int i,j;for(i1;i<9;i){for(j1;j<i;j)if(ji)printf("%d*%d%d",j,i,j*i);elseprintf("%d*%d%-2d ",j,i,j*i);printf("\n");}return 0…...
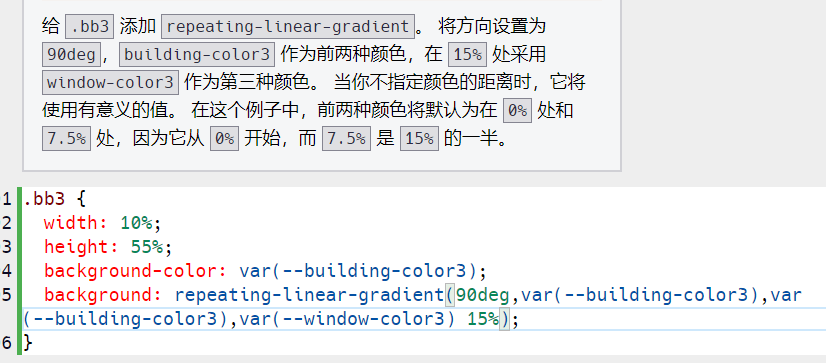
8.4 day bug
bug1 忘记给css变量加var 复制代码到通义千问,解决 bug2 这不是我的bug,是freecodecamp的bug 题目中“ 将 --building-color2 变量的颜色更改为 #000” “ 应改为” 将 #000 变量的颜色更改为 --building-color2 “ bug3 又忘记加var(–xxx) 还去问…...

【Material-UI】Autocomplete中的禁用选项:Disabled options
文章目录 一、简介二、基本用法三、进阶用法1. 动态禁用2. 提示禁用原因3. 复杂的禁用条件 四、最佳实践1. 一致性2. 提供反馈3. 优化性能 五、总结 Material-UI的Autocomplete组件提供了丰富的功能,包括禁用特定选项的能力。这一特性对于限制用户选择、提供更好的用…...

Pytest测试报告生成专题
在 pytest 中,你可以使用多个选项生成不同格式的测试报告。以下是几种常用的生成测试报告的方法: 1. 生成简单的测试结果文件 你可以使用 pytest 的 --junitxml 选项生成一个 XML 格式的测试报告,这个报告可以与 CI/CD 工具集成。 pytest --junitxml=report.xml这将在当前…...

QT 笔记
HTTPS SSL配置 下载配置 子父对象 QTimer *timer new QTimer; // QTimer inherits QObject timer->inherits("QTimer"); // returns true timer->inherits("QObject"); // returns true timer->inherits("QAbst…...

【redis 第七篇章】动态字符串
一、概述 string 类型底层实现的简单动态字符串 sds,是可以修改的字符串。它采用预分配冗余空间的方式来减少内存的频繁分配。 二、SDS动态字符串 动态字符串 是以 \0 为分隔符。最大容量 是 redis 主动分配的一块内存空间,实际存储内容 是具体的存的数…...

rk3588 部署yolov8.rknn
本文从步骤来记录在rk3588芯片上部署yolov8模型 主机:windows10 VMware Workstation 16 Pro 硬件:RK3588 EVB板 模型: RK3588.rknn 软件开发环境: c cmake step1: 主机上执行: 将rknn_model_zoo 工程文件下载…...
【正点原子i.MX93开发板试用连载体验】中文提示词的训练
本文首发于电子发烧友论坛:【正点原子i.MX93开发板试用连载体验】基于深度学习的语音本地控制 - 正点原子学习小组 - 电子技术论坛 - 广受欢迎的专业电子论坛! 好久没有更新了,今天再来更新一下。 我们用前面提到的录音工具录制了自己的中文语音&#…...

WordPress资源下载类主题 CeoMax-Pro_v7.6绕授权开心版
CeoMax-Pro强大的功能 在不久的将来Ta能实现你一切幻想!我们也在为此而不断努力。适用于资源站、下载站、交易站、素材站、源码站、课程站、cms等等等等,Ta 为追求极致的你而生。多风格多样式多类型多行业多功能 源码下载:ceomax-pro7.6.zip…...

使用GCC编译Notepad++的插件
Notepad的本体1是支持使用MSVC和GCC编译的2,但是Notepad插件的官方文档3里却只给出了MSVC的编译指南4。 网上也没有找到相关的讨论,所以我尝试在 Windows 上使用 MinGW,基于 GCC-8.1.0 的 posix-sjlj 线程版本5,研究一下怎么编译…...
)
技术周总结 2024.07.29 ~ 08.04周日(MyBatis, 极限编程)
文章目录 一、08.01 周四1.1)mybatis的 xml文件中的 ${var} 和 #{var}的区别? 二、08.03 周六2.1)极限编程核心价值观核心实践实施极限编程的好处极限编程的挑战适用场景 三、08.04 周日3.1)《计算机信息系统安全保护等级划分准则…...

C语言调试宏全面总结(六大板块)
C语言调试宏进阶篇:实用指南与案例解析C语言调试宏高级技巧与最佳实践C语言调试宏的深度探索与性能考量C语言调试宏在嵌入式系统中的应用与挑战C语言调试宏在多线程环境中的应用与策略C语言调试宏在并发编程中的高级应用 C语言调试宏进阶篇:实用指南与案…...

unity万向锁代数法解释
unity的矩阵旋转乘法顺序是yxz 旋转x的90度的矩阵: 1 0 0 0 0 -1 0 1 0旋转y和z的矩阵假设角度为y和z,矩阵略不写了 按顺序乘完yxz之后结果是 cos(y-z) sin(y-z) 0 0 0 -1 -sin(y-z) cos(y-z) 0这个结果和Rx(pi/2) *Rz(某个角度)的结果是一个形式,Rx和…...

stm32入门学习10-I2C和陀螺仪模块
(一)I2C通信 (1)通信方式 I2C是一种同步半双工的通信方式,同步指的是通信双方时钟为一个时钟,半双工指的是在同一时间只能进行接收数据或发送数据,其有一条时钟线(SCL)…...

GDB常用指令
GDB调试:GDB调试的是可执行文件,在gcc编译时加入-g参数,告诉gcc在编译时加入调试信息,这样gdb才能调试这个被编译的文件。此外还会加上-Wall参数尽量显示所有警告信息。 GDB命令格式: 1、start:程序在第一…...

Nginx 高级 扩容与高效
Nginx高级 第一部分:扩容 通过扩容提升整体吞吐量 1.单机垂直扩容:硬件资源增加 云服务资源增加 整机:IBM、浪潮、DELL、HP等 CPU/主板:更新到主流 网卡:10G/40G网卡 磁盘:SAS(SCSI) HDD(机械…...

pythonflaskMYSQL自驾游搜索系统32127-计算机毕业设计项目选题推荐(附源码)
目 录 摘要 1 绪论 1.1研究背景 1.2爬虫技术 1.3flask框架介绍 2 1.4论文结构与章节安排 3 2 自驾游搜索系统分析 4 2.1 可行性分析 4 2.2 系统流程分析 4 2.2.1数据增加流程 5 2.3.2数据修改流程 5 2.3.3数据删除流程 5 2.3 系统功能分析 5 2.3.1 功能性分析 6 2.3.2 非功…...

C++ vector的基本使用(待补全)
std::vector 是C标准模板库(STL)中的一个非常重要的容器类,它提供了一种动态数组的功能。能够存储相同类型的元素序列,并且可以自动管理存储空间的大小,以适应序列大小变化,处理元素集合的时候很灵活 1. vector的定义 构造函数声…...

Java 属性拷贝 三种实现方式
第一种 List<OrederPayCustomer> orederPayCustomerList this.list(queryWrapper); List<CustomerResp>customerRespListnew ArrayList<>();for (OrederPayCustomer orederPayCustomer : orederPayCustomerList) {CustomerResp customerResp new Custome…...

Claude Code 官方回应代码泄漏:这次,他们没有“甩锅人”
这两天,Claude Code 的“代码泄漏”事件在技术圈引发了不少讨论。各种版本的故事层出不穷,甚至还有营销号声称“新员工背锅被开除”。但从官方回应来看,事情的走向,其实完全不一样。👉 Claude Code 团队,正…...
)
WinForm实战:C#如何优雅地调用外部exe并传递多个参数(附完整代码示例)
WinForm实战:C#如何优雅地调用外部exe并传递多个参数(附完整代码示例) 在Windows桌面应用开发中,经常需要与其他程序进行交互。想象这样一个场景:你正在开发一个数据可视化工具,需要调用Python脚本处理原始…...
)
UE5 C++ 新手避坑指南:从零搭建汽车交互项目(含PhysXVehicles模块配置)
UE5 C 汽车交互开发实战:从模块配置到物理驾驶系统 第一次打开UE5的C项目时,那种既兴奋又忐忑的心情至今记忆犹新。作为一个从蓝图转向C开发的"半路出家"程序员,我清楚地记得在配置PhysXVehicles模块时踩过的那些坑——莫名其妙的编…...

原料杂乱难管理?合并功能一键搞定
在制造行业的日常运营中,进销存管理的核心痛点往往藏在细节里——尤其是生产环节的领料流程,却常常成为拖慢效率、造成损耗的“隐形绊脚石”。很多企业在生产计划落地时,都会遇到这样的困境:同一份生产计划单中,不同成…...

2026届必备的AI辅助写作平台解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能论文工具正渐渐在学术写作流程里掺杂进来,变成研究者提高效率的管用帮手…...

一体化数字引擎 驱动机械设备非标项目精益盈
机械设备行业正进入深度数字化转型期,非标定制与项目型制造企业普遍面临项目成本失控、进度不透明、变更响应慢、售后价值难挖掘等核心痛点。传统分散式管理与复杂业务场景脱节,导致交付延迟、利润流失、协同效率低下。面向非标设备行业的数字化管理需求…...
 - 恢复编排)
Veeam Recovery Orchestrator 13 P1 (Windows) - 恢复编排
Veeam Recovery Orchestrator 13 P1 (Windows) - 恢复编排 Veeam Data Platform | 面向混合云和多云的 备份和恢复 监控和分析 恢复编排 请访问原文链接:https://sysin.org/blog/veeam-recovery-orchestrator-13/ 查看最新版。原创作品,转载请保留出处…...

5个React条件渲染技巧:从基础到实战的完整指南
5个React条件渲染技巧:从基础到实战的完整指南 【免费下载链接】react-fundamentals Material for my React Fundamentals Workshop 项目地址: https://gitcode.com/gh_mirrors/re/react-fundamentals React条件渲染是构建动态用户界面的核心技能,…...

终极解决方案:让Mac通过Android USB网络共享高速上网的HoRNDIS驱动
终极解决方案:让Mac通过Android USB网络共享高速上网的HoRNDIS驱动 【免费下载链接】HoRNDIS Android USB tethering driver for Mac OS X 项目地址: https://gitcode.com/gh_mirrors/ho/HoRNDIS 还在为Mac无法直接使用Android手机的USB网络共享功能而烦恼吗…...

3大核心技术深度解析:Windows Defender Control开源项目的架构与实践指南
3大核心技术深度解析:Windows Defender Control开源项目的架构与实践指南 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defen…...