Python爬虫技术 第31节 持续集成和自动化部署
持续集成和自动化部署
Git版本控制
Git 是一个非常流行的分布式版本控制系统,用于跟踪对项目文件的修改。对于爬虫项目来说,使用Git可以帮助你管理代码的不同版本,协同开发,并且可以在出现问题时回滚到之前的版本。
基本操作:
- 安装Git: 在你的操作系统上安装Git。
- 初始化仓库: 使用
git init命令在一个目录下初始化一个新的Git仓库。 - 添加文件: 使用
git add <file>添加文件到暂存区。 - 提交更改: 使用
git commit -m "commit message"提交更改到仓库。 - 查看状态: 使用
git status查看当前仓库的状态。 - 查看历史记录: 使用
git log查看提交的历史记录。 - 撤销更改: 使用
git reset HEAD <file>撤销最近一次暂存的更改。 - 分支管理: 使用
git branch <branch-name>创建新分支,git checkout <branch-name>切换分支。 - 合并分支: 使用
git merge <branch-name>合并分支。 - 推送代码: 使用
git push origin <branch-name>将本地分支推送到远程仓库。
CI/CD流程
持续集成(CI)和持续部署(CD)是现代软件开发中不可或缺的部分,它们可以帮助开发者自动检测错误、构建应用、测试以及部署应用到生产环境。
CI/CD工具:
- Jenkins: 一款开源的CI/CD服务器,支持插件扩展,适合复杂的工作流。
- GitHub Actions: GitHub提供的自动化工作流服务,非常适合基于GitHub的项目。
- GitLab CI/CD: GitLab自带的CI/CD工具,易于集成。
- Travis CI: 一种云服务,提供持续集成和持续交付服务。
基本步骤:
-
编写测试用例:
- 编写单元测试来确保爬虫功能正确无误。
- 使用工具如
pytest或unittest来编写和运行测试。
-
设置CI配置文件:
- 在项目的根目录创建一个
.gitlab-ci.yml或.github/workflows文件。 - 配置构建、测试、部署等任务。
- 在项目的根目录创建一个
-
构建和测试:
- 在每次提交后自动触发构建过程。
- 运行测试用例确保没有引入新的错误。
-
自动化部署:
- 设置自动部署到测试或生产环境的流程。
- 可以使用环境变量来安全地存储敏感信息,如数据库连接字符串或API密钥。
-
监控和反馈:
- 监控爬虫的运行情况。
- 如果发生错误,通过邮件或者消息通知团队成员。
示例配置文件: 假设我们使用GitHub Actions作为CI工具,下面是一个简单的.github/workflows/python-app.yml文件示例:
name: Python CIon:push:branches: [ main ]pull_request:branches: [ main ]jobs:build:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v2- name: Set up Python 3.9uses: actions/setup-python@v2with:python-version: 3.9- name: Install dependenciesrun: |python -m pip install --upgrade pippip install -r requirements.txt- name: Run testsrun: |pip install pytestpytest
以上就是关于使用Git进行版本控制以及设置CI/CD流程的基本介绍。你可以根据自己的需求选择合适的工具和服务来进行具体的实施。
假设你已经设置好了GitHub Actions,并且想要进一步完善CI/CD流程。以下是一个更详细的GitHub Actions配置文件示例,它包括了Python爬虫项目的构建、测试、以及自动化部署的步骤。
首先,我们需要确保爬虫项目中有一个requirements.txt文件,列出所有需要安装的依赖包。然后,在项目的根目录下创建一个名为.github/workflows/python-app.yml的文件,并填入以下内容:
name: Python CI/CDon:push:branches: [ main ]pull_request:branches: [ main ]jobs:build:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v2- name: Set up Python 3.9uses: actions/setup-python@v2with:python-version: 3.9- name: Install dependenciesrun: |python -m pip install --upgrade pippip install -r requirements.txt- name: Run testsrun: |pip install pytestpytest- name: Lint code baserun: |pip install flake8flake8 . --count --select=E9,F63,F7,F82 --show-source --statisticsflake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statisticsdeploy:needs: buildruns-on: ubuntu-latestif: github.event_name == 'push' && github.ref == 'refs/heads/main'steps:- name: Checkout repositoryuses: actions/checkout@v2- name: Set up Python 3.9uses: actions/setup-python@v2with:python-version: 3.9- name: Install dependenciesrun: |python -m pip install --upgrade pippip install -r requirements.txt- name: Deploy to serverenv:SSH_HOST: ${{ secrets.SSH_HOST }}SSH_USER: ${{ secrets.SSH_USER }}SSH_KEY: ${{ secrets.SSH_KEY }}run: |ssh-keyscan -t rsa $SSH_HOST >> ~/.ssh/known_hostsecho "$SSH_KEY" > private.keychmod 600 private.keyscp -i private.key -r . $SSH_USER@$SSH_HOST:/path/to/deploy/directoryssh -i private.key $SSH_USER@$SSH_HOST "cd /path/to/deploy/directory; python3 your_crawler.py"
解析上述配置文件
-
触发条件 (
on):- 当有新的提交被推送到
main分支时触发构建。 - 当有新的拉取请求针对
main分支时触发构建。
- 当有新的提交被推送到
-
构建 (
build):- 检出代码。
- 安装Python 3.9。
- 安装依赖。
- 运行单元测试。
- 执行代码格式检查 (linting)。
-
部署 (
deploy):- 只有当构建成功并且有新的提交被推送到
main分支时才触发部署。 - 再次检出代码。
- 安装依赖。
- 通过SSH将代码部署到服务器,并运行爬虫脚本。
- 只有当构建成功并且有新的提交被推送到
注意事项
-
环境变量 (
secrets):- 需要在GitHub仓库的Settings -> Secrets -> Actions中设置
SSH_HOST、SSH_USER和SSH_KEY。 SSH_KEY应该是经过加密处理的私钥。
- 需要在GitHub仓库的Settings -> Secrets -> Actions中设置
-
部署路径 (
/path/to/deploy/directory):- 替换成实际的服务器路径。
-
爬虫脚本 (
your_crawler.py):- 替换成你的爬虫脚本名称。
这个配置文件涵盖了从构建到部署的整个流程。你可以根据实际情况调整其中的细节。如果你的部署目标不是通过SSH连接的服务器,而是其他的平台(如Docker容器、Kubernetes集群等),则需要相应地修改部署部分的步骤。
为了进一步优化CI/CD流程,我们可以考虑以下几个方面:
- 安全性增强: 确保敏感信息(如API密钥、数据库密码等)不直接出现在代码或配置文件中。
- 资源管理和成本控制: 对于云服务的使用,比如AWS、GCP等,要确保资源被适当地管理和成本得到控制。
- 错误处理和重试机制: 对于部署过程中可能出现的失败,增加错误处理和重试逻辑。
- 通知系统: 当构建或部署失败时,向相关人员发送通知。
- 日志记录和监控: 记录重要的事件和日志,以便于调试和监控。
下面是一个更完善的GitHub Actions配置文件示例,包括了上述的一些改进点:
name: Python CI/CDon:push:branches: [ main ]pull_request:branches: [ main ]jobs:build:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v2- name: Set up Python 3.9uses: actions/setup-python@v2with:python-version: 3.9- name: Install dependenciesrun: |python -m pip install --upgrade pippip install -r requirements.txt- name: Run testsrun: |pip install pytestpytest- name: Lint code baserun: |pip install flake8flake8 . --count --select=E9,F63,F7,F82 --show-source --statisticsflake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statisticsdeploy:needs: buildruns-on: ubuntu-latestif: github.event_name == 'push' && github.ref == 'refs/heads/main'steps:- name: Checkout repositoryuses: actions/checkout@v2- name: Set up Python 3.9uses: actions/setup-python@v2with:python-version: 3.9- name: Install dependenciesrun: |python -m pip install --upgrade pippip install -r requirements.txt- name: Deploy to serverid: deployenv:SSH_HOST: ${{ secrets.SSH_HOST }}SSH_USER: ${{ secrets.SSH_USER }}SSH_KEY: ${{ secrets.SSH_KEY }}run: |ssh-keyscan -t rsa $SSH_HOST >> ~/.ssh/known_hostsecho "$SSH_KEY" > private.keychmod 600 private.keyscp -i private.key -r . $SSH_USER@$SSH_HOST:/path/to/deploy/directoryssh -i private.key $SSH_USER@$SSH_HOST "cd /path/to/deploy/directory; python3 your_crawler.py"- name: Notify on failureif: ${{ always() && steps.deploy.outcome == 'failure' }}run: |# Example of sending an email notificationecho "Deployment failed, notifying team."echo "Send email or other notification here."- name: Cleanupif: ${{ always() }}run: |rm -f private.key
解析更新后的配置文件
-
通知系统 (
Notify on failure):- 当部署步骤失败时,可以发送邮件或使用其他方式通知团队成员。
- 这里仅做示例展示,你需要根据实际情况替换为实际的通知逻辑。
-
清理 (
Cleanup):- 删除临时生成的私钥文件,以提高安全性。
其他可能的优化
- 使用缓存 (
cache): 对于大型项目而言,安装依赖可能耗时较长。可以考虑使用GitHub Actions的缓存功能来加速安装过程。 - 并行执行 (
concurrency): 如果你的项目中有多个独立的任务,可以考虑让它们并行执行,以缩短整体构建时间。 - 动态配置 (
strategy): 如果有多个环境需要部署,可以使用strategy来定义不同的部署策略。
这些改进措施可以根据你的具体需求进行调整。如果你有特定的需求或想要实现的功能,请告诉我,我可以帮助你进一步定制化这个配置文件。
相关文章:

Python爬虫技术 第31节 持续集成和自动化部署
持续集成和自动化部署 Git版本控制 Git 是一个非常流行的分布式版本控制系统,用于跟踪对项目文件的修改。对于爬虫项目来说,使用Git可以帮助你管理代码的不同版本,协同开发,并且可以在出现问题时回滚到之前的版本。 基本操作&a…...
(第2版)课后习题答案)
数据结构(C语言版)(第2版)课后习题答案
数据结构(C语言版)(第2版)课后习题答案 李冬梅 2015.3 目 录 第 1 章 绪论 1 第 2 章 线性表 5 第 3 章 栈和队列 13 第 4 章 串、数组和广义表 26 第 5 章 树和二叉树 33 第 6 章 图 43 第 7 章 查找 54 第 8 章 排序 65…...
的分析总结及进一步提问)
打开轮盘锁问题(LeetCode)的分析总结及进一步提问
打开轮盘锁问题分析总结,及进一步提问:请给出一组最小步数下的号码序列组合 题目描述 你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’ 。每个拨轮可以自由…...

python——joblib进行缓存记忆化-对计算结果缓存
问题场景 在前端多选框需要选取多个数据进行后端计算。 传入后端是多个数据包的对应路径。 这些数据包需要按一定顺序运行,通过一个Bag(path).get_start_time() 可以获得一个float时间值进行排序,但由于数据包的特性,这一操作很占用性能和时…...

Linux文件管理
系列文章目录 提示:仅用于个人学习,进行查漏补缺。 1.Linux介绍、目录结构、文件基本属性、Shell 2.Linux常用命令 3.Linux文件管理 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1…...

《Unity3D网络游戏实战》学习与实践--制作一款大乱斗游戏
角色类 基类Base Human是基础的角色类,它处理“操控角色”和“同步角色”的一些共有功能;CtrlHuman类代表“操控角色”,它在BaseHuman类的基础上处理鼠标操控功能;SyncHuman类是“同步角色”类,它也继承自BaseHuman&…...
文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《考虑源-荷不确定性的省间电力现货市场潮流风险概率评估》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源…...

Pinterest 选择采用 TiDB
原文来源: https://tidb.net/blog/9f000c95 作者:Pinterest 公司高级软件工程师 Alberto Ordonez Pereira ;高级工程经理 Lianghong Xu 声明:本文转载于 https://medium.com/pinterest-engineering/tidb-adoption-…...

【Python】 如何用 Docker 打包一个 Python 脚本
这是我父亲 日记里的文字 这是他的生命 留下留下来的散文诗 几十年后 我看着泪流不止 可我的父亲已经 老得像一个影子 🎵 许飞《父亲写的散文诗》 如何用 Docker 打包一个 Python 脚本 Docker 是一个开源的容器化平台,允许开发者将…...
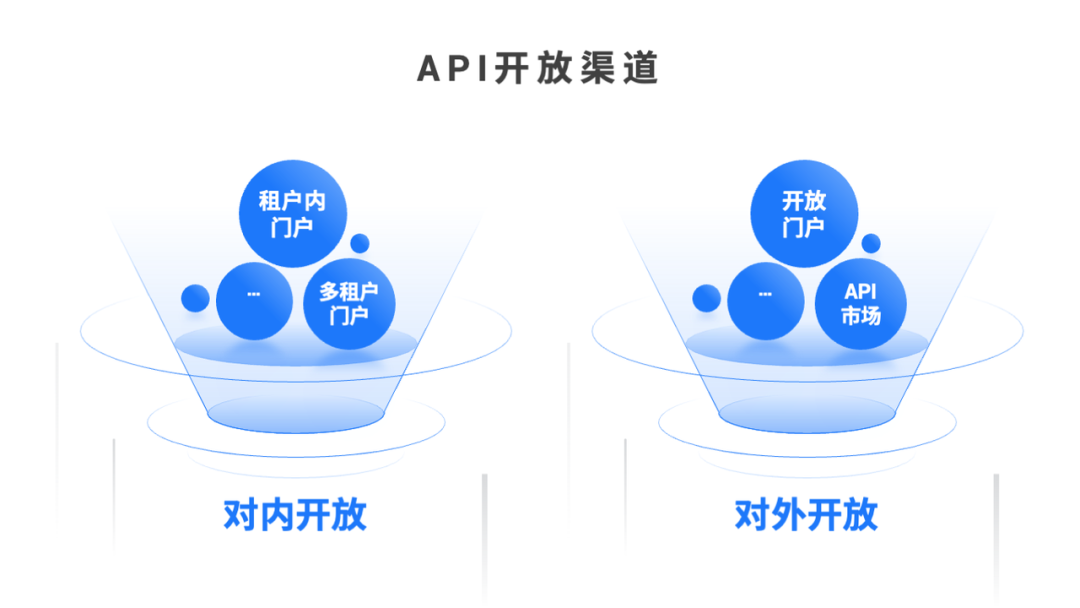
从“幕后”到“台前”:一文读懂API经济如何促进企业的创新与增长
API(Application Programming Interface,应用程序接口)指一组定义软件程序如何与其他组件、服务或系统交互的规范。在传统的IT语境中,API往往更多承担前后端对接或应用系统间内部集成渠道的作用。但在当今大数据与智能化的时代&am…...

解锁PDF新姿势:2024年PDF转图片工具精选
随着数字化办公的普及和文档处理需求的日益增长,PDF转图片工具已成为日常工作中不可或缺的一部分。这些工具不仅帮助用户轻松地将PDF文件转换为图片格式,还提供了丰富的编辑、转换和批量处理功能,极大地提高了工作效率。 1.福昕PDF转换大师&…...
Node.js(8)——Express的基本使用
监听GET请求 通过app.get()方法,可以监听客户端GET请求,具体语法: app.get(请求URL,function(req,res){处理函数}) 监听POST请求 语法: app.post(请求URL,function(req,res){处理函数}) 把内容响应给客户端 通过res.send()方法…...
Linux--应用层协议HTTP
HTTP协议 HTTP协议(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最为广泛的一种网络协议,它基于TCP/IP通信协议来传送数据,规定了浏览器与服务器之间数据传输的规则,确保数据能够在网络源头…...

Flux:Midjourney的新图像模型挑战者
--->更多内容,请移步“鲁班秘笈”!!<--- Black Forest Labs是一家由前Stability.ai开发人员创立的AI初创公司,旨在为图像和视频创建尖端的生成式 AI 模型。这家初创公司声称,其第一个模型系列Flux.1为文本到图像…...

RabbitMQ高级特性 - 消费者消息确认机制
文章目录 RabbitMQ 消息确认机制背景消费者消息确认机制概述手动确认(RabbitMQ 原生 SDK)手动确认(Spring-AMQP 封装 RabbitMQ SDK)AcknowledgeMode.NONEAcknowledgeMode.AUTO(默认)AcknowledgeMode.MANUAL…...
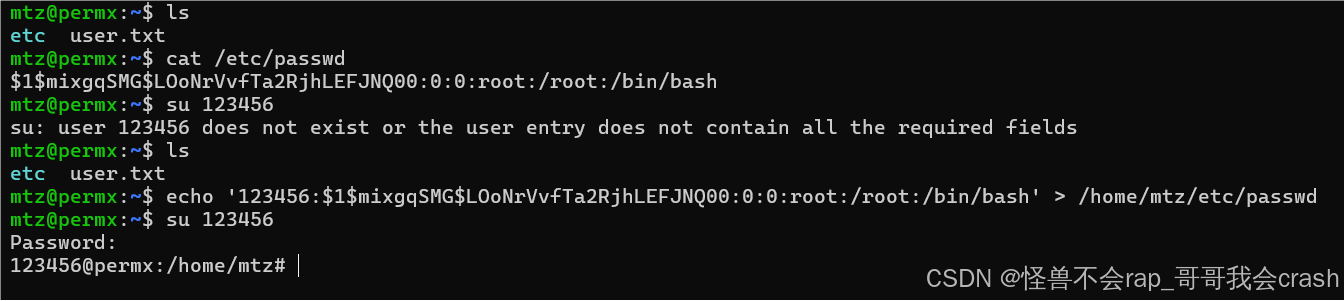
PermX-htb
0x01 立足 信息收集 端口扫描 nmap -sSCV -Pn 10.10.11.23 正常开启22和80端口 访问web页面 并没有看到有攻击点 这个页面可先记录一会儿有需要的话可以尝试xss获取cookie 域名扫描 ffuf -w 1.txt -u http://permx.htb/ -H Host:FUZZ.permx.htb 这里用的ffuf扫描工具 扫出了…...
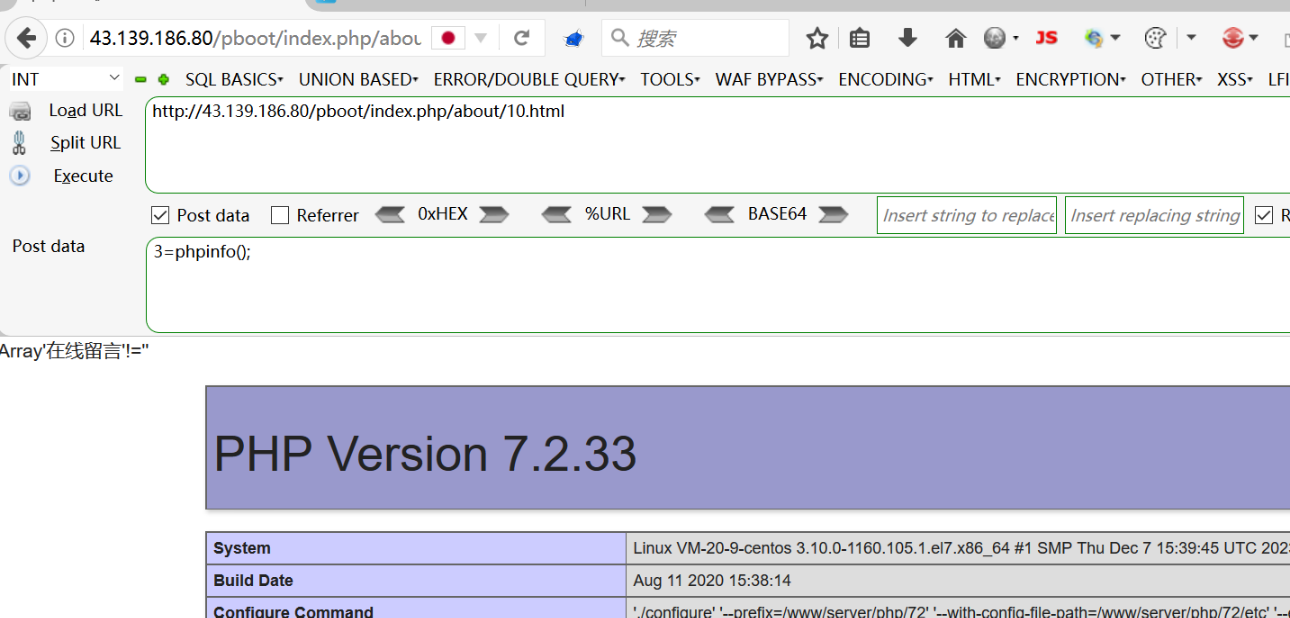
解密RCE漏洞:原理剖析、复现与代码审计实战
在网络安全领域,远程代码执行(RCE)漏洞因其严重性和破坏力而备受关注。RCE漏洞允许攻击者在目标系统上执行任意代码,从而掌控整个系统,带来极大的安全风险。理解RCE漏洞的工作原理,并掌握其复现与代码审计技…...
)
打造智能家居:用React、Node.js和WebSocket构建ESP32设备控制面板(代码说明)
一、项目概述 在物联网(IoT)时代,智能设备的远程控制变得越来越重要。本文介绍了一个构建智能设备控制面板的项目,允许用户通过 Web 应用来控制多个 ESP32 设备。用户可以通过该面板查看设备列表,实时了解设备状态&am…...
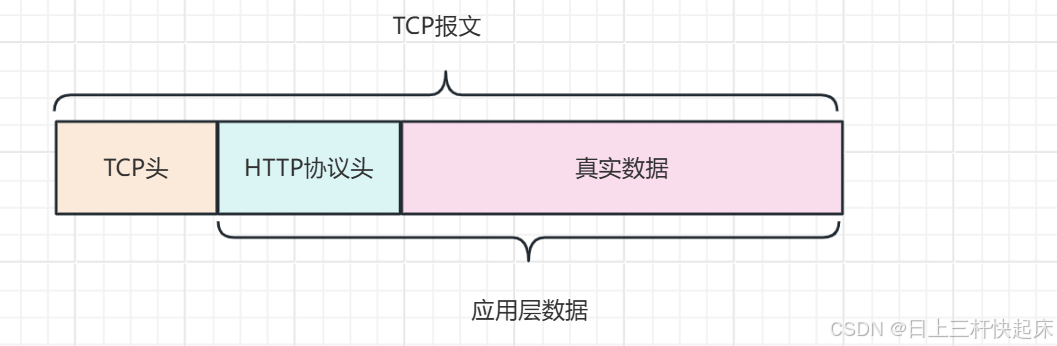
计网:从输入URL到网页显示期间发生了什么
1、URL包含的信息 我们输入的url中包含着一些信息: http:表示的此次我们使用的什么协议/www.baidu.com:表示的是我们想要访问的服务器名称,也就是域名dir3/home.html:表示我们所要访问的资源 2、通过DNS解析URL获得I…...

龚宇引以为傲的“爆款制造营”,爱奇艺怕是要爽约了
文:互联网江湖 作者:刘致呈 人们经常用人红戏不红,来形容毯星,综艺上咋咋呼呼,一提都知道,可问及代表作,不好意思,这个真没有。 今年的爱奇艺,貌似也迎来了这一宿命。 …...

测试文章标题最终版
测试文章内容这是一篇测试文章...

113. 强制使用 Letsencrypt ECDSA 和 DNS-01 续期挑战的默认 HTTPS Rancher 证书
Environment 环境 2.9 Situation 地理位置A self-signed default Rancher certificate is currently used and will be migrated to a stronger Let’s Encrypt ECDSA-386 certificate using the DNS-01 renewal challenge. 目前使用自签名默认的牧场证书,并将通过…...

FadCam 安卓后台视频录制应用,支持屏幕关闭录制,多画质高帧率,隐私保护,适配个人安防与事件记录等正当用途
大家好,我是大飞哥。在个人安防、事件记录、现场取证等场景中,普通安卓录屏应用大多需要保持屏幕常亮,不仅容易暴露录制行为,还会快速消耗电量,无法满足隐蔽、长效录制的需求,而部分后台录制工具又存在隐私…...

OpenClaw人人养虾:LiteLLM 统一网关
LiteLLM 是一个开源的 LLM API 统一网关(Unified Gateway),支持 100 模型提供商,提供统一的 OpenAI 兼容 API 格式。 安装 LiteLLM pip 安装 pip install litellm[proxy] Docker 安装 docker run -p 4000:4000 \-e OPENAI_AP…...

实战应用:基于快马平台构建企业级9-1免费安装预约系统
今天想和大家分享一个很实用的实战项目——基于InsCode(快马)平台构建的企业级9-1免费安装预约系统。这个系统特别适合家电维修、家居安装这类服务型企业使用,能大大提升客户预约体验和内部管理效率。 项目背景与需求分析 最近帮朋友公司做技术咨询,他…...

实战指南:基于快马平台快速开发并部署班级宠物园应用官方下载门户
最近学校想推广一个班级宠物园的教育应用,需要快速搭建一个官方下载页面。作为技术负责人,我尝试用InsCode(快马)平台来快速实现这个需求,整个过程比想象中顺利很多。 项目规划与结构设计 首先明确页面需要包含的几个核心模块:顶部…...

突破限制与全版本支持:MediaCreationTool.bat重新定义Windows安装介质制作
突破限制与全版本支持:MediaCreationTool.bat重新定义Windows安装介质制作 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreatio…...
)
别再死磕手册了!用Vivado 2023.1手把手教你配置Aurora 64B/66B IP核(附完整复位时序图)
Vivado 2023.1实战:Aurora 64B/66B IP核配置全流程解析 在FPGA高速通信领域,Aurora协议凭借其轻量级、高带宽的特性成为众多工程师的首选。但对于初学者而言,官方文档PG074中复杂的复位时序和参数配置往往让人望而生畏。本文将基于Vivado 202…...

炉石传说自动化工具:从效率提升到策略优化的全栈解决方案
炉石传说自动化工具:从效率提升到策略优化的全栈解决方案 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 问题引入:重构游戏体验…...

Legacy iOS Kit终极指南:让旧款iOS设备重获新生的完整解决方案
Legacy iOS Kit终极指南:让旧款iOS设备重获新生的完整解决方案 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-K…...